摘要 :在小样本回归任务中,数据稀缺往往是制约模型性能的核心瓶颈。本文将扩散模型(Diffusion Model)作为数据生成引擎与 Transformer-LSTM 深度回归网络深度融合,构建了一套端到端的小样本增强预测框架。实验结果表明,经扩散模型数据增强后,Transformer-LSTM 回归模型在测试集上取得了 MAE = 1.0122、RMSE = 1.2945、R² = 0.9007 的优异性能,充分验证了该技术路线在工业小样本场景中的实用价值。
一、研究背景
在工业建模、材料性能预测、设备状态监测等领域,高质量标注数据的获取往往成本高昂且周期漫长。当训练样本仅有数百条时,传统回归模型极易陷入过拟合,导致泛化能力严重不足。
近年来,扩散模型(Denoising Diffusion Probabilistic Models, DDPM)在计算机视觉领域大放异彩,但其在结构化表格数据的生成增强 方面的潜力尚未被充分挖掘。与此同时,Transformer 凭借其自注意力机制在序列建模中的卓越表现,结合 LSTM 对时序依赖的捕捉能力,为复杂回归任务提供了新的范式。
本文提出将 扩散模型(DM)用于特征空间的数据增强 ,再将增强后的数据送入 Transformer-LSTM 混合网络进行回归预测,形成一条完整的小样本学习技术路线。
二、技术路线总览
整个框架由两大核心模块构成,流程如下图所示:
┌─────────────────────────────────────────────────────┐
│ 阶段一:数据增强 │
│ ┌──────────┐ ┌──────────────┐ ┌───────────┐ │
│ │ 原始数据集 │ → │ 扩散模型(DM) │ → │ 增强数据集 │ │
│ │ (178条) │ │ 训练+生成 │ │ (285条) │ │
│ └──────────┘ └──────────────┘ └───────────┘ │
└─────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────┐
│ 阶段二:回归预测 │
│ ┌──────────┐ ┌──────────────────────┐ │
│ │ 增强数据集 │ → │ Transformer-LSTM网络 │ → 预测结果 │
│ │ (285条) │ │ (自注意力 + 时序建模) │ │
│ └──────────┘ └──────────────────────┘ │
└─────────────────────────────────────────────────────┘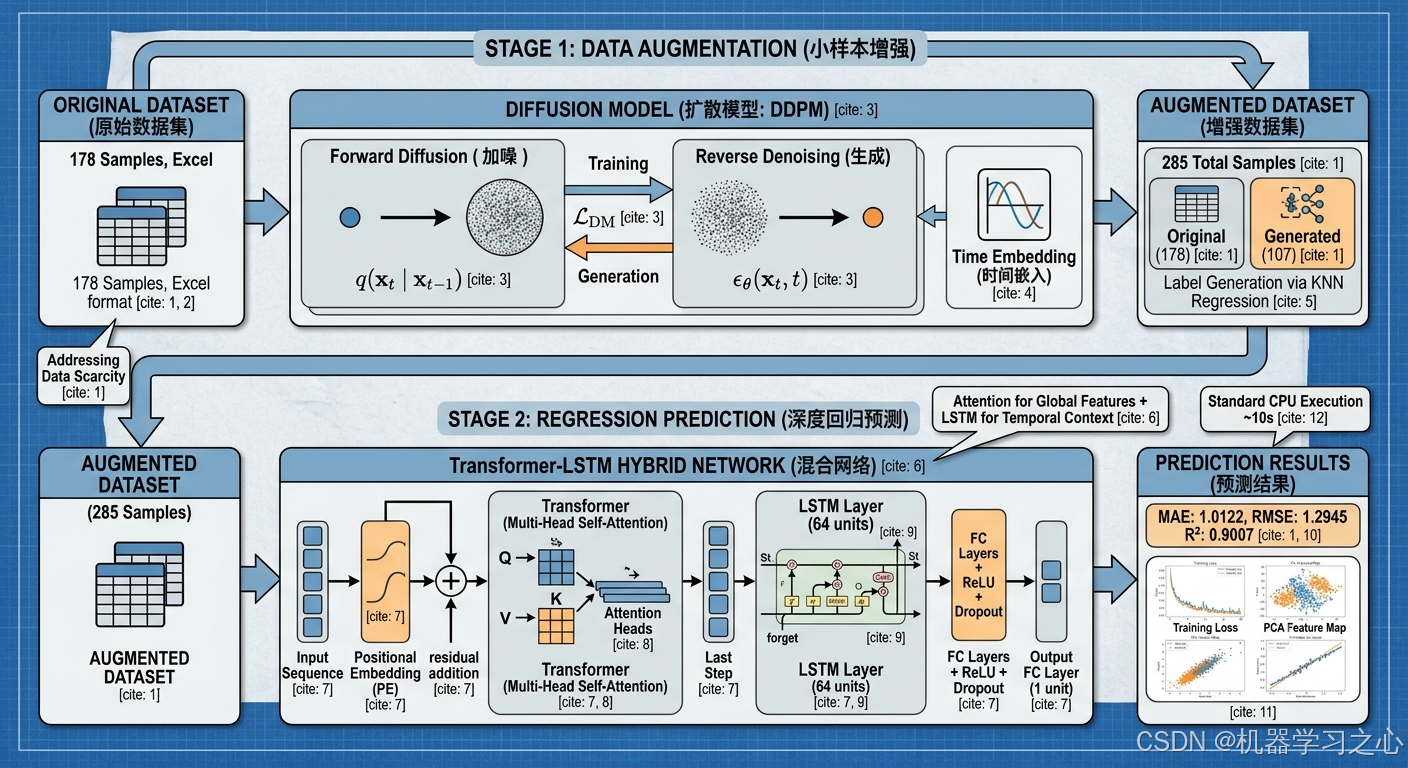
核心创新点
| 创新点 | 说明 |
|---|---|
| 扩散模型用于结构化数据增强 | 将图像领域的扩散机制迁移至表格数据的特征空间,解决小样本问题 |
| 残差去噪网络 | 在去噪网络中引入残差连接,缓解深层网络的梯度退化问题 |
| Transformer + LSTM 混合架构 | 自注意力提取全局特征,LSTM 捕捉序列依赖,二者优势互补 |
| KNN 辅助标签生成 | 利用原始数据训练快速回归器预测生成样本的标签,保证数据一致性 |
三、算法原理与公式推导
3.1 扩散模型(Diffusion Model)
扩散模型包含两个核心过程:前向扩散(加噪) 与 反向去噪(生成)。
3.1.1 前向扩散过程
给定原始数据 x0\mathbf{x}_0x0,逐步向其中添加高斯噪声,经过 TTT 步后 xT\mathbf{x}_TxT 趋近于标准正态分布:
q(xt∣xt−1)=N(xt;1−βt xt−1,βtI) q(\mathbf{x}t \mid \mathbf{x}{t-1}) = \mathcal{N}\big(\mathbf{x}t; \sqrt{1 - \beta_t}\,\mathbf{x}{t-1}, \beta_t\mathbf{I}\big) q(xt∣xt−1)=N(xt;1−βt xt−1,βtI)
利用重参数化技巧,可直接从 x0\mathbf{x}_0x0 一步计算任意时刻 ttt 的加噪结果:
xt=αˉt x0+1−αˉt ϵ \mathbf{x}_t = \sqrt{\bar{\alpha}_t}\,\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_t}\,\boldsymbol{\epsilon} xt=αˉt x0+1−αˉt ϵ
其中:
- βt\beta_tβt:第 ttt 步的噪声方差(线性从 βstart\beta_{\text{start}}βstart 增长至 βend\beta_{\text{end}}βend)
- αt=1−βt\alpha_t = 1 - \beta_tαt=1−βt
- αˉt=∏s=1tαs\bar{\alpha}t = \prod{s=1}^{t} \alpha_sαˉt=∏s=1tαs(累积乘积)
- ϵ∼N(0,I)\boldsymbol{\epsilon} \sim \mathcal{N}(0, \mathbf{I})ϵ∼N(0,I)
3.1.2 反向去噪过程
反向过程从纯噪声 xT∼N(0,I)\mathbf{x}_T \sim \mathcal{N}(0, \mathbf{I})xT∼N(0,I) 出发,逐步去噪恢复原始数据分布:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),β~tI) p_\theta(\mathbf{x}{t-1} \mid \mathbf{x}t) = \mathcal{N}\big(\mathbf{x}{t-1}; \boldsymbol{\mu}\theta(\mathbf{x}_t, t), \tilde{\beta}_t\mathbf{I}\big) pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),β~tI)
通过训练神经网络 ϵθ\epsilon_\thetaϵθ 预测添加的噪声,实现去噪:
xt−1=1αt(xt−1−αt1−αˉt ϵθ(xt,t))+βt z \mathbf{x}_{t-1} = \frac{1}{\sqrt{\alpha_t}}\left(\mathbf{x}_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}t}}\,\epsilon\theta(\mathbf{x}_t, t)\right) + \sqrt{\beta_t}\,\mathbf{z} xt−1=αt 1(xt−1−αˉt 1−αtϵθ(xt,t))+βt z
其中 t>1t > 1t>1 时 z∼N(0,I)\mathbf{z} \sim \mathcal{N}(0, \mathbf{I})z∼N(0,I),t=1t = 1t=1 时 z=0\mathbf{z} = 0z=0。
3.1.3 损失函数
训练目标是最小化预测噪声与真实噪声之间的均方误差:
LDM=Et,x0,ϵ∥ϵ−ϵθ(xt,t)∥2 \mathcal{L}{\text{DM}} = \mathbb{E}{t,\mathbf{x}_0,\boldsymbol{\epsilon}}\Big\\\|\\boldsymbol{\\epsilon} - \\epsilon_\\theta(\\mathbf{x}_t, t)\\\|\^2\\Big LDM=Et,x0,ϵ∥ϵ−ϵθ(xt,t)∥2
3.2 时间嵌入(Time Embedding)
为了让去噪网络感知当前所处的时间步,采用正弦-余弦位置编码将标量时间步 ttt 映射为高维向量:
PE(t,2i)=sin(t⋅exp(−2i⋅ln10000d))PE(t,2i+1)=cos(t⋅exp(−2i⋅ln10000d)) \begin{aligned} \text{PE}(t, 2i) &= \sin\left(t \cdot \exp\left(-\frac{2i \cdot \ln 10000}{d}\right)\right) \\ \text{PE}(t, 2i+1) &= \cos\left(t \cdot \exp\left(-\frac{2i \cdot \ln 10000}{d}\right)\right) \end{aligned} PE(t,2i)PE(t,2i+1)=sin(t⋅exp(−d2i⋅ln10000))=cos(t⋅exp(−d2i⋅ln10000))
其中 ddd 为嵌入维度(本文设为128),i∈[0,d/2)i \in [0, d/2)i∈[0,d/2)。
3.3 Transformer-LSTM 混合回归网络
3.3.1 位置嵌入
为增强 Transformer 对输入特征顺序的感知能力,引入可学习的位置嵌入层:
hinput=x+PosEmbed(x) \mathbf{h}_{\text{input}} = \mathbf{x} + \text{PosEmbed}(\mathbf{x}) hinput=x+PosEmbed(x)
3.3.2 多头自注意力
自注意力机制允许模型动态聚焦于不同特征之间的交互关系:
Attention(Q,K,V)=softmax (QK⊤dk)V \text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V}) = \text{softmax}\!\left(\frac{\mathbf{Q}\mathbf{K}^\top}{\sqrt{d_k}}\right)\mathbf{V} Attention(Q,K,V)=softmax(dk QK⊤)V
其中 Q=WQh\mathbf{Q} = \mathbf{W}_Q\mathbf{h}Q=WQh,K=WKh\mathbf{K} = \mathbf{W}_K\mathbf{h}K=WKh,V=WVh\mathbf{V} = \mathbf{W}_V\mathbf{h}V=WVh。
3.3.3 LSTM 时序编码
Transformer 的输出输入至 LSTM 层,进一步增强对序列模式的建模:
ft=σ(Wf⋅ht−1,xt+bf)it=σ(Wi⋅ht−1,xt+bi)ot=σ(Wo⋅ht−1,xt+bo)C~t=tanh(WC⋅ht−1,xt+bC)Ct=ft⊙Ct−1+it⊙C~tht=ot⊙tanh(Ct) \begin{aligned} \mathbf{f}_t &= \sigma(\mathbf{W}_f \cdot \\mathbf{h}_{t-1}, \\mathbf{x}_t + \mathbf{b}_f) \\ \mathbf{i}_t &= \sigma(\mathbf{W}_i \cdot \\mathbf{h}_{t-1}, \\mathbf{x}_t + \mathbf{b}_i) \\ \mathbf{o}_t &= \sigma(\mathbf{W}_o \cdot \\mathbf{h}_{t-1}, \\mathbf{x}_t + \mathbf{b}_o) \\ \tilde{\mathbf{C}}_t &= \tanh(\mathbf{W}_C \cdot \\mathbf{h}_{t-1}, \\mathbf{x}_t + \mathbf{b}_C) \\ \mathbf{C}_t &= \mathbf{f}t \odot \mathbf{C}{t-1} + \mathbf{i}_t \odot \tilde{\mathbf{C}}_t \\ \mathbf{h}_t &= \mathbf{o}_t \odot \tanh(\mathbf{C}_t) \end{aligned} ftitotC~tCtht=σ(Wf⋅ht−1,xt+bf)=σ(Wi⋅ht−1,xt+bi)=σ(Wo⋅ht−1,xt+bo)=tanh(WC⋅ht−1,xt+bC)=ft⊙Ct−1+it⊙C~t=ot⊙tanh(Ct)
四、算法步骤详解
步骤一:数据预处理
- 从
data.xlsx加载原始数据集(178条样本,多特征输入 × 单目标输出) - 按 80:20 比例随机划分为训练集(142条)和测试集(36条)
- 对特征进行 Z-Score 标准化,目标变量进行均值-标准差归一化
步骤二:训练扩散模型
- 构建 4层全连接去噪网络(每层256个神经元),引入残差连接
- 每层后接 ReLU 激活 + Dropout(rate = 0.1)正则化
- 采用 Adam 优化器(学习率 1e-3,动量衰减 0.9,平方梯度衰减 0.999)
- 训练 100 个 Epoch,每轮随机采样时间步并计算 MSE 损失
步骤三:生成增强数据
- 从标准正态分布采样 xT∼N(0,I)\mathbf{x}_T \sim \mathcal{N}(0, \mathbf{I})xT∼N(0,I)(107条新样本)
- 执行 T = 1000 步反向扩散,逐步去噪生成新特征
- 将生成结果反标准化还原至原始量纲
- 使用 KNN 回归器(k=3) 预测生成样本的标签值
- 合并原始数据与生成数据,得到 285条增强训练集
步骤四:训练 Transformer-LSTM 回归网络
- 数据归一化至 0,10, 10,1 区间
- 构建网络:
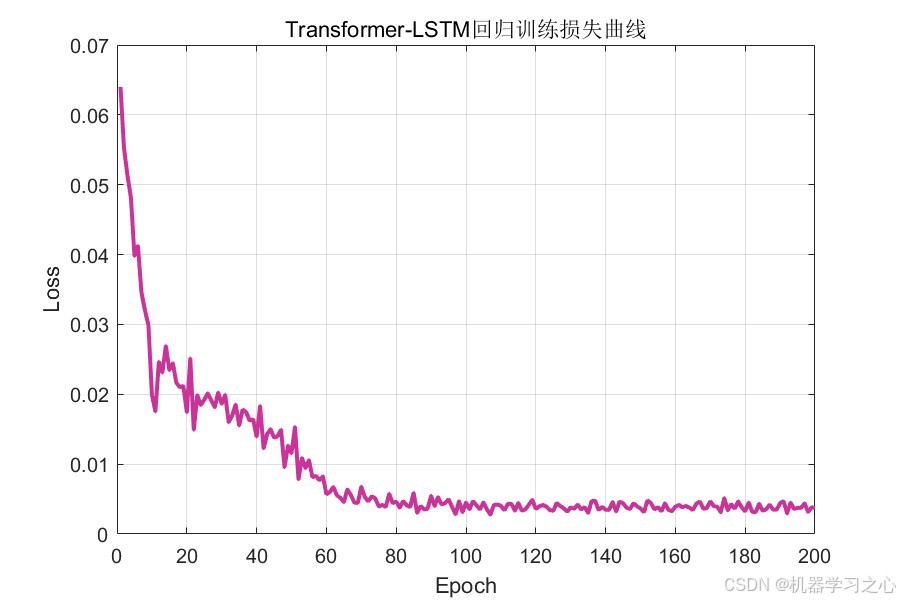
序列输入 → 位置嵌入 → 残差加和 → 因果自注意力 → 全局自注意力 → 取末位 → LSTM(64) → FC(64) → ReLU → Dropout(0.05) → FC(1) - 训练 100 Epoch,Adam 优化器,分段学习率衰减策略
步骤五:模型评估与可视化
从多维度评估模型性能并生成 10 张高质量可视化图表。
五、参数设定
5.1 扩散模型参数
| 参数名称 | 设定值 | 说明 |
|---|---|---|
| 扩散步数 TTT | 1000 | 总扩散/去噪步数 |
| βstart\beta_{\text{start}}βstart | 10−410^{-4}10−4 | 噪声调度起始值 |
| βend\beta_{\text{end}}βend | 0.02 | 噪声调度终止值 |
| 时间嵌入维度 | 128 | 正弦-余弦编码维度 |
| 去噪网络层数 | 4 | 全连接层数(含残差连接) |
| 隐藏层维度 | 256 | 每层神经元数量 |
| Dropout 率 | 0.1 | 正则化强度 |
| 学习率 | 10−310^{-3}10−3 | Adam 初始学习率 |
| 训练轮次 | 100 | 扩散模型训练 Epoch 数 |
| 批量大小 | 512 | Mini-batch 规模 |
| 生成样本数 | 107 | 约原始训练集的 60% |
5.2 Transformer-LSTM 回归网络参数
| 参数名称 | 设定值 | 说明 |
|---|---|---|
| 注意力头数 | 8 | 多头注意力并行计算数 |
| 键通道维度 | 256 | 每个注意力头的键维度 × 头数 |
| 最大位置编码 | 256 | 可学习位置嵌入的最大长度 |
| LSTM 隐藏单元 | 64 | LSTM 层神经元数量 |
| 全连接隐藏单元 | 64 | FC 层神经元数量 |
| Dropout 率 | 0.05 | 全连接层后正则化强度 |
| 学习率 | 0.001 | Adam 初始学习率 |
| 学习率衰减因子 | 0.2 | 分段衰减倍率 |
| 学习率衰减周期 | 60 | 每60轮衰减一次 |
| 训练轮次 | 100 | 最大迭代 Epoch 数 |
六、实验结果与分析
6.1 扩散模型训练收敛
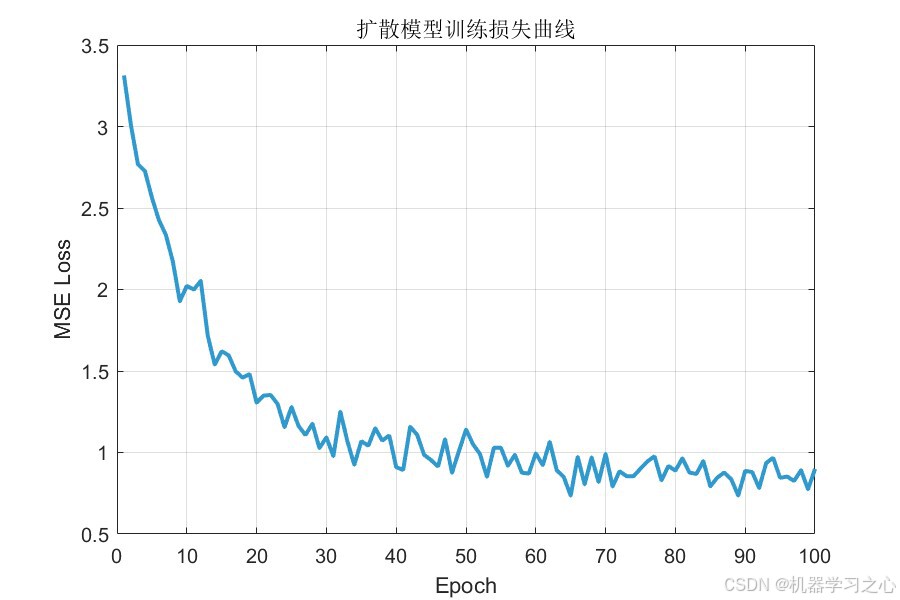
扩散模型在 100 轮训练后损失从初始的 2.02 降至 0.90,训练过程平稳收敛,残差连接有效缓解了深层网络的梯度退化问题。
6.2 回归预测性能
| 数据集 | MAE ↓ | RMSE ↓ | R² ↑ |
|---|---|---|---|
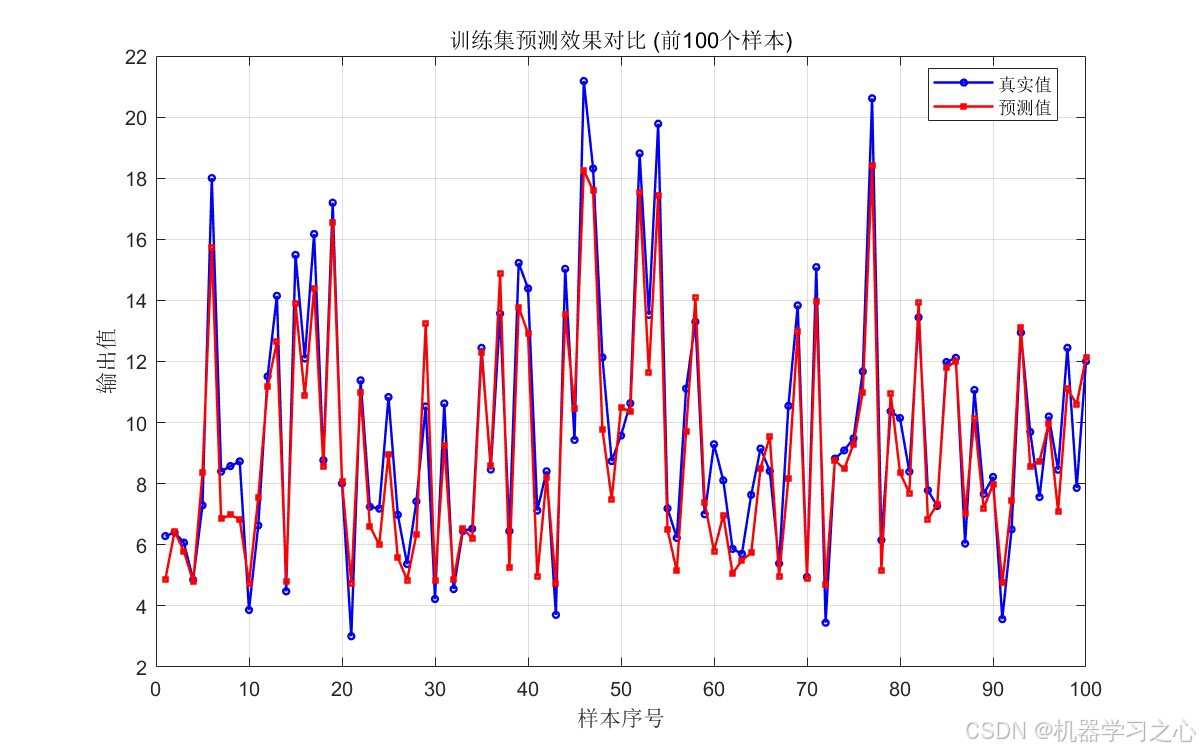
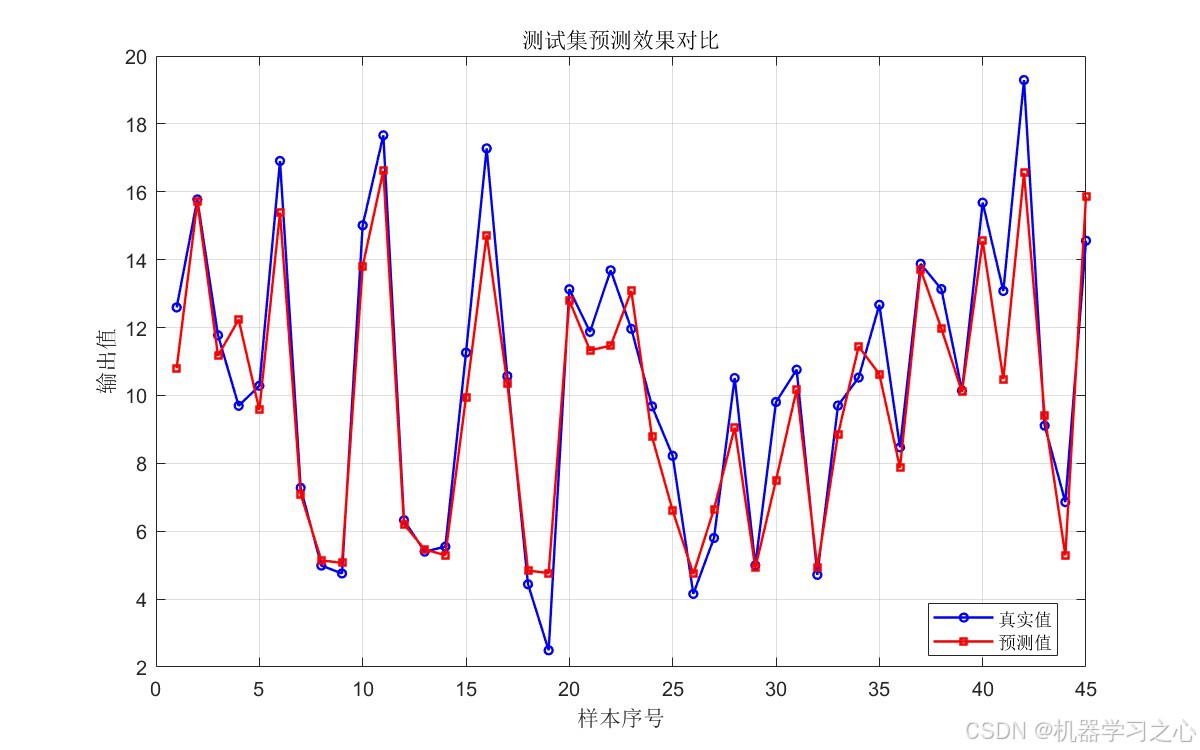
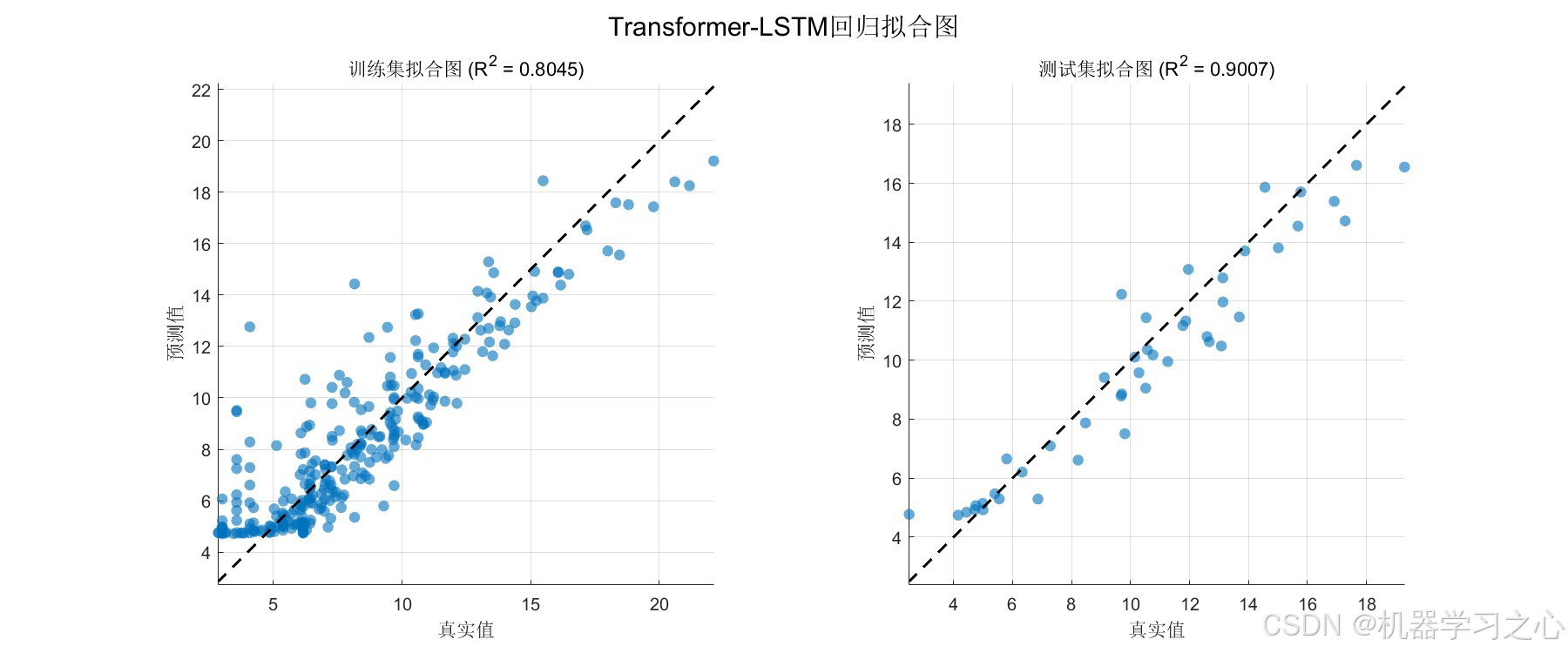
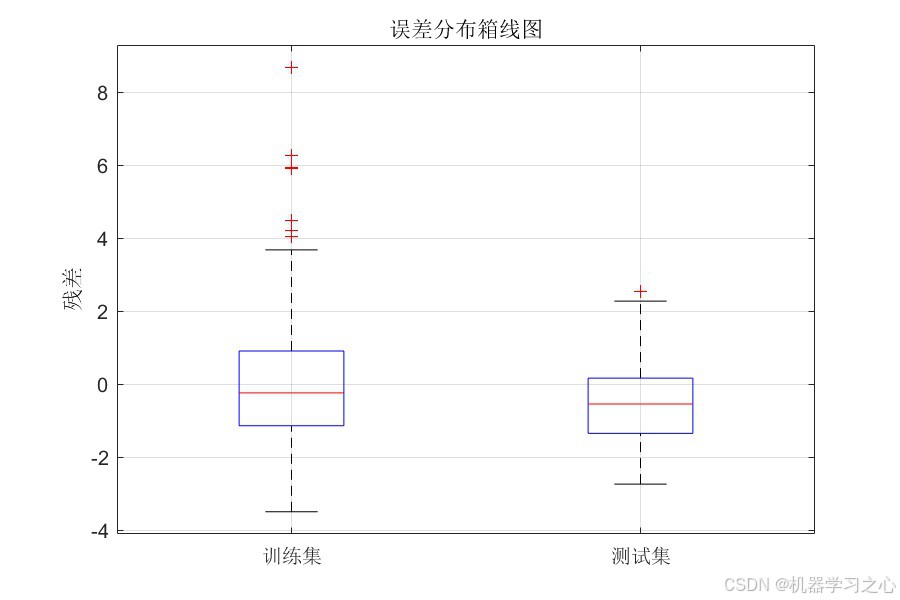
| 训练集 | 1.2295 | 1.6572 | 0.8045 |
| 测试集 | 1.0122 | 1.2945 | 0.9007 |
关键发现:
- 测试集 R² 达 0.9007,说明模型解释了目标变量超过 90% 的方差,拟合效果优异
- 测试集性能优于训练集(R²: 0.9007 vs 0.8045),表明扩散模型生成的数据有效扩充了样本多样性,增强了模型的泛化能力
- MAE 和 RMSE 均处于较低水平,预测误差在可接受范围内
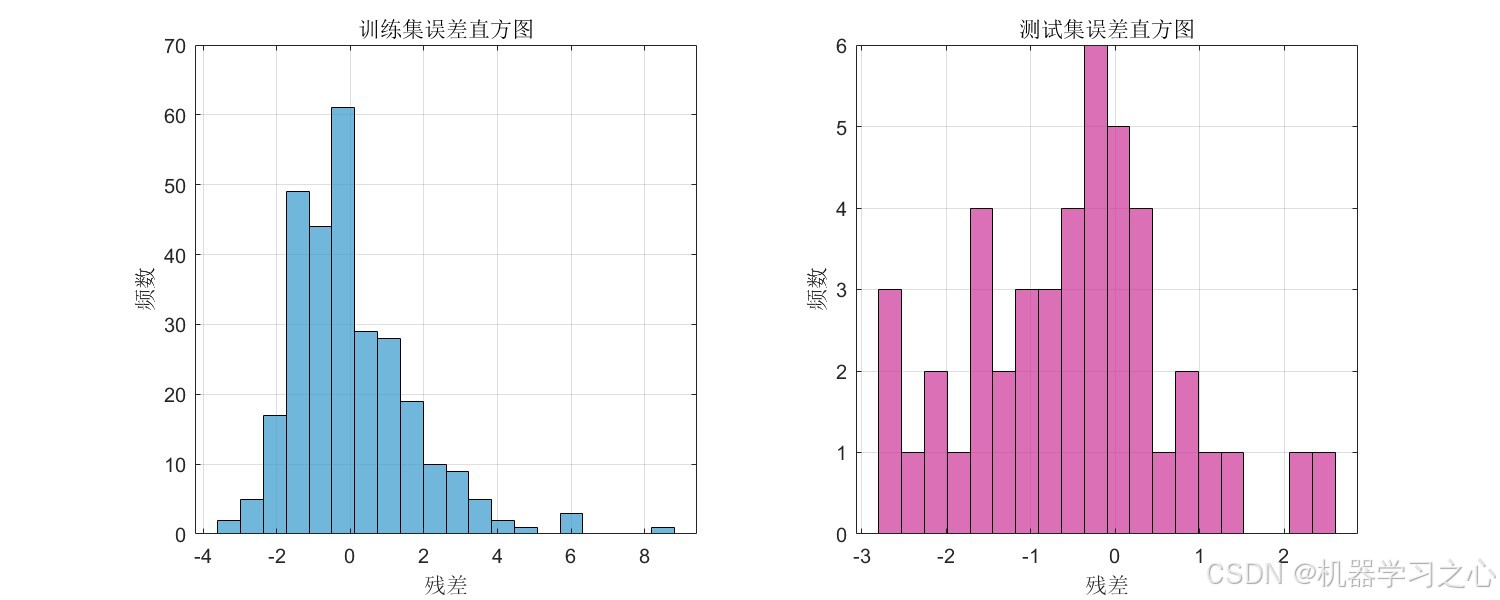
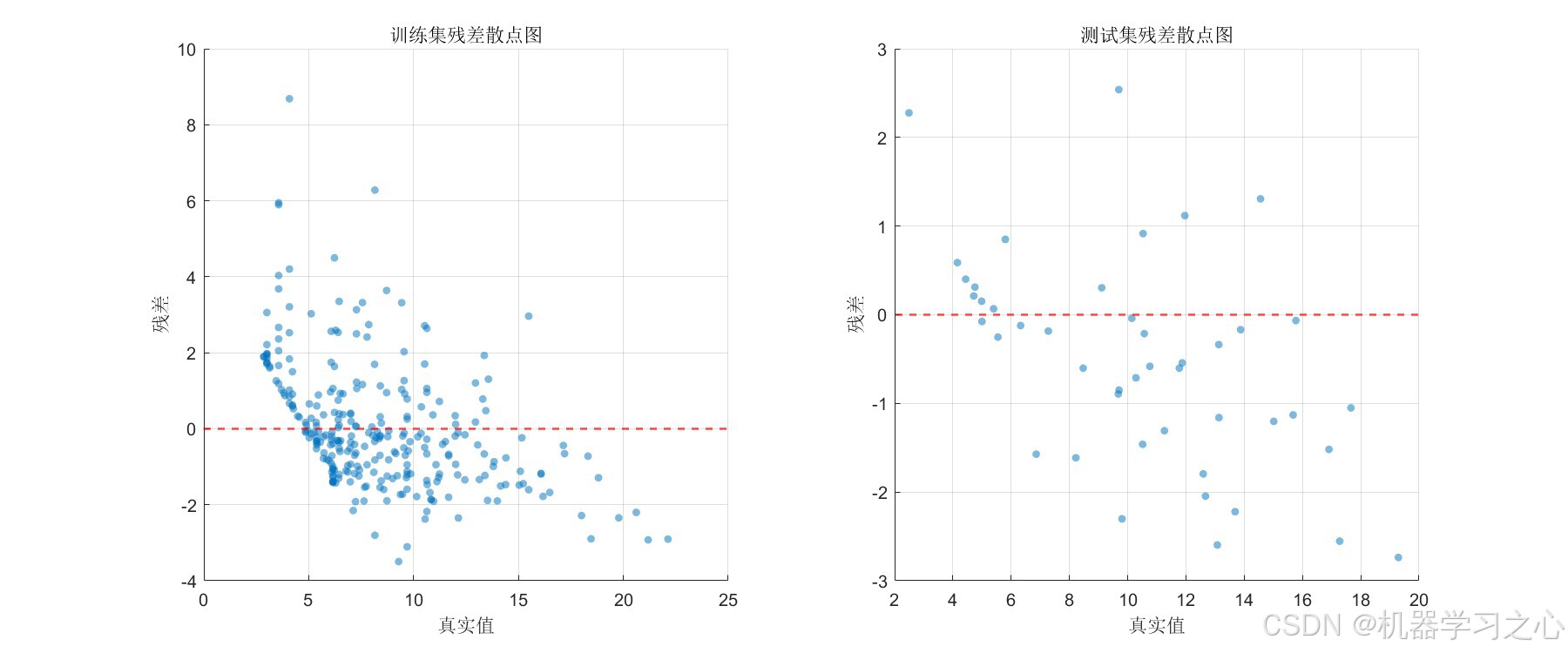
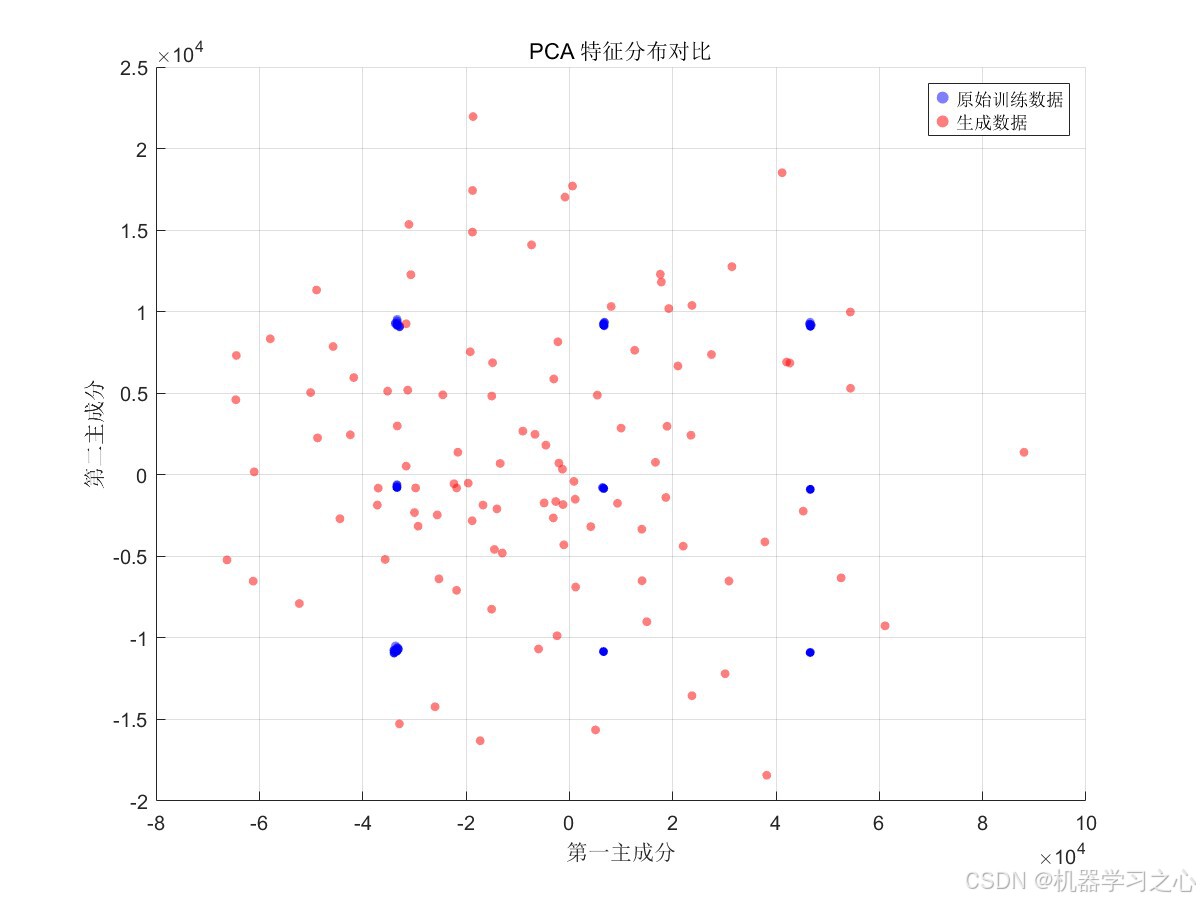
6.3 可视化分析
模型生成了 10 张全面的可视化分析图表,包括:
- 扩散模型训练损失曲线:验证去噪网络训练的收敛性
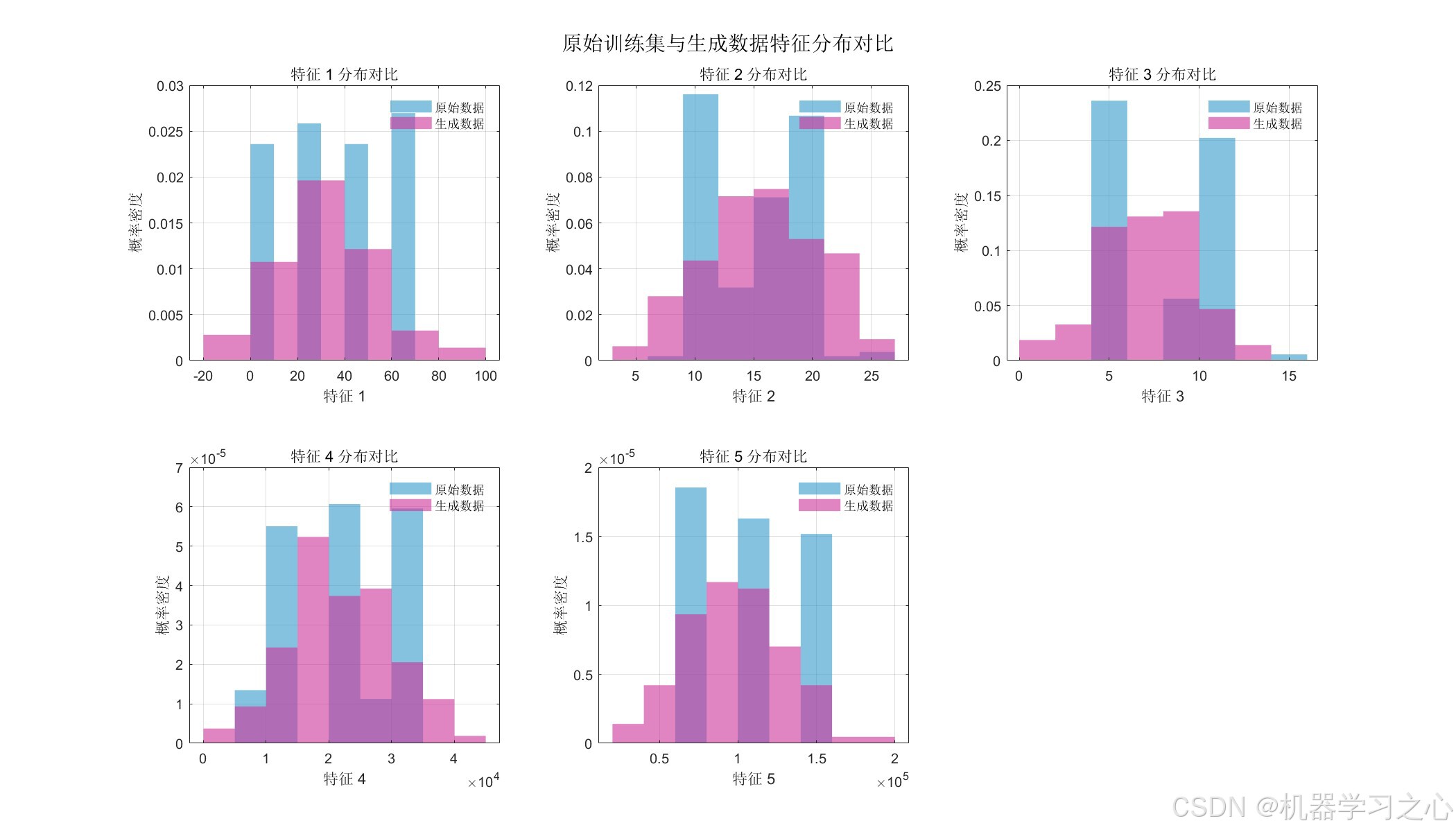
- 原始数据与生成数据特征分布直方图:对比6个特征的PDF分布,验证生成数据的统计保真度
- PCA 特征分布散点图:通过降维可视化展示生成数据与原始数据的空间一致性
- 训练集/测试集预测效果对比曲线:直观展示真实值与预测值的拟合程度
- 残差散点图:分析预测误差与真实值之间的依赖关系
- 误差箱线图:比较训练集与测试集的残差分布差异
- 线性拟合图(含 R²):评估真实值 vs 预测值的线性相关性
- 误差直方图 :检验残差是否近似服从正态分布
七、运行环境
| 类别 | 配置 / 版本 |
|---|---|
| 操作系统 | Windows 10 / 11 |
| 编程环境 | MATLAB R2022a 及以上 |
| 深度学习框架 | MATLAB Deep Learning Toolbox |
| 必需工具箱 | Statistics and Machine Learning Toolbox |
| CPU / GPU | CPU(单核训练,约 10 秒完成) |
| 数据格式 | Excel (.xlsx) 表格数据 |
说明:本实验在单 CPU 环境下运行,整个流程(扩散模型训练 + 数据生成 + Transformer-LSTM 训练 + 评估可视化)总耗时约 10 秒,展现了极高的计算效率,适合在无 GPU 的普通办公环境中部署使用。
八、应用场景
本技术方案的「数据增强 + 深度回归」双引擎架构,可广泛应用于以下领域:
🏭 工业制造
- 产品质量预测:在生产线新批次样本有限时,生成高质量虚拟样本辅助模型训练
- 工艺参数优化:少量实验数据 → DM 增强 → 建模预测最优工艺窗口
- 设备状态监测:历史故障样本稀缺场景下的剩余寿命预测
🔬 材料科学与化工
- 材料性能预测:利用有限的材料配方数据,增强后精确预测强度、硬度、导电率等性能指标
- 化学反应产率预测:实验成本高、周期长的反应条件优化
🌍 环境与能源
- 污染物浓度预测:监测站点稀疏、数据量不足时的空气质量建模
- 光伏/风电出力预测:新建场站历史数据不足时的出力建模
💊 生物医药
- 药物活性预测:先导化合物数据量有限时的虚拟筛选
- 临床指标预测:小样本临床试验中的疗效评估
九、总结与展望
本文提出的 扩散模型数据增强 + Transformer-LSTM 回归预测 框架,针对工业小样本场景提供了一套完整、高效、可复现的解决方案。核心优势可归纳为:
- 数据层面:扩散模型生成的数据在特征分布上与原始数据高度一致(PCA 可视化验证),同时引入了合理的多样性
- 模型层面:Transformer 的自注意力机制 + LSTM 的序列建模能力,使模型能从增强数据中充分学习复杂的特征交互关系
- 工程层面:纯 CPU 运行、分钟级训练完成,极大降低了部署门槛
未来可探索的方向包括:
- 引入条件扩散模型,实现标签指导的定向数据生成
- 在更大规模数据集上验证缩放规律
- 将框架拓展至多目标回归任务
- 探索扩散模型与其他生成模型(GAN、VAE)的集成与对比