为什么用 Skill 做需求澄清
背景:PRD 到 AI Coding 的断层
传统的软件开发流程中,PRD(产品需求文档)是写给开发者的。开发者作为人,具备一种关键能力:自动脑补。PRD 说"支持批量删除",开发者会自动推断:应该有个全选框、应该有二次确认、删除完列表要刷新。这些细节 PRD 没写,但人知道。
AI 不具备这种能力。AI 不会脑补------它要么根据训练数据中"最常见"的写法猜测,要么直接忽略。一个"支持批量操作"的需求,AI 可能不会加二次确认,不会处理部分失败的情况,不会考虑全选后翻页的行为差异。
这就是断层:PRD 的隐含假设无法被 AI 消费。
需求澄清的目的,就是把这些隐含假设显式化,变成 AI 能直接使用的精确规格说明。
什么是需求澄清
需求澄清是一个结构化的信息补全过程:
- 输入:PRD 文档(面向人的、有隐含假设的)
- 过程:从 5 个维度(范围边界、交互流程、异常边界、数据规则、非功能需求)系统性提问
- 输出:澄清文档(面向 AI 的、无隐含假设的)
澄清文档和 PRD 的关键区别:
| PRD | 澄清文档 | |
|---|---|---|
| 读者 | 人(开发者、测试) | AI(代码生成工具) |
| 隐含假设 | 大量(人不写也懂) | 零(所有细节显式化) |
| 异常处理 | 通常不写 | 每个场景都有定义 |
| 字段约束 | 粗略("手机号") | 精确(11位数字,必填,唯一性校验,错误提示"该手机号已注册") |
| 空状态 | 不提 | 每个列表/表单都有定义 |
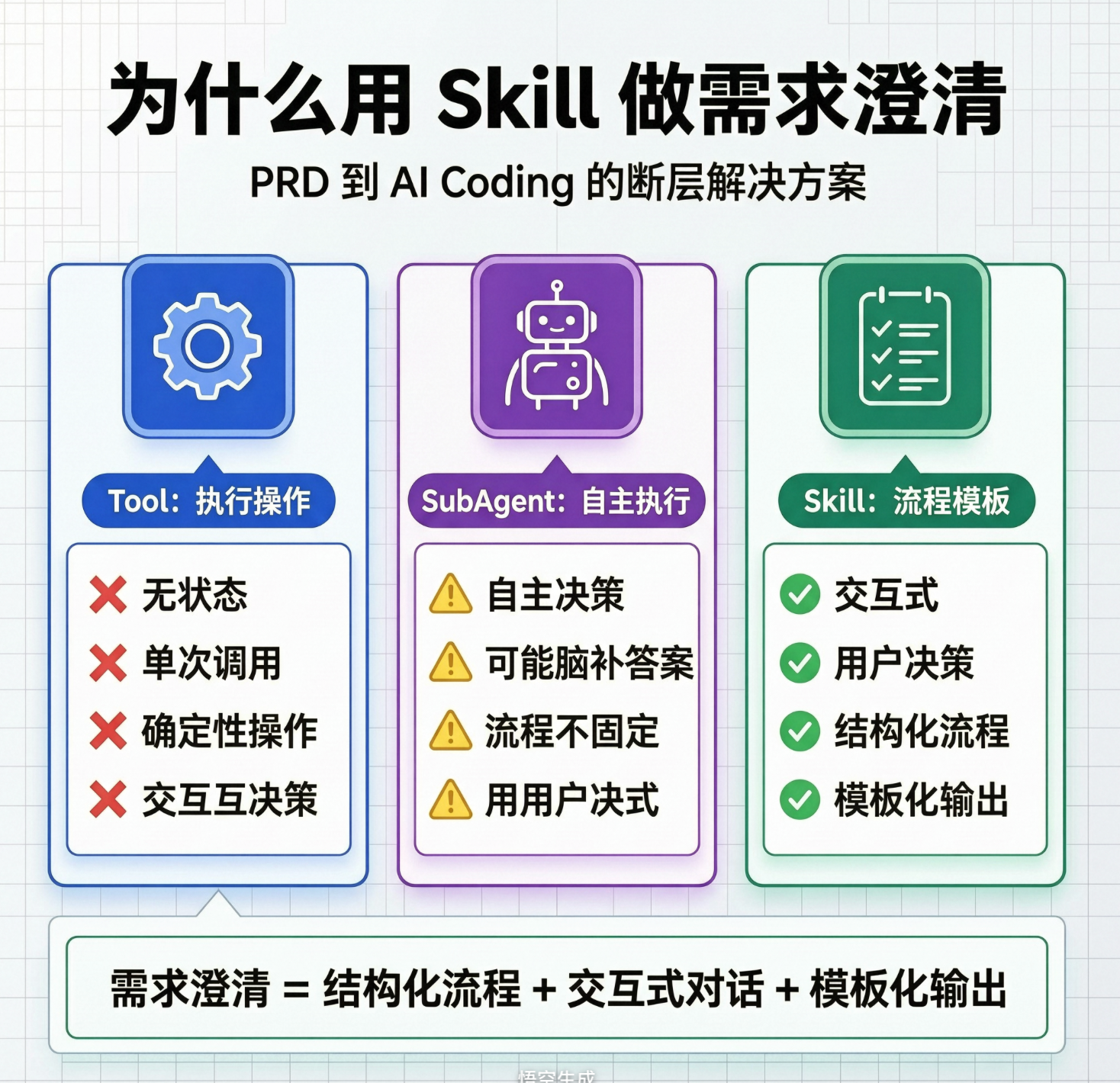
为什么选择 Skill 而不是 Tool 或 SubAgent
在 Claude Code 生态中有三种扩展机制,各有不同的能力边界。需求澄清的特征决定了它只能用 Skill 来做。
三种机制的本质区别
Tool:执行操作
Tool 的本质是"给输入,出结果"。它是一个函数:f(input) -> output。比如:
search_table("用户表")→ 返回匹配的表列表run_sql("SELECT * FROM users")→ 返回查询结果
Tool 是无状态的------每次调用独立,不记忆上下文,不管理流程。它适合做具体的、可重复的、确定性的操作。
SubAgent:自治执行
SubAgent 的本质是"给任务,自主完成"。它是一个独立的 Agent 实例,有自己的上下文、工具访问权限和决策能力。比如:
- "分析这个代码库的架构,找出性能瓶颈" → SubAgent 自主探索、分析、返回结论
- "把这组测试用例跑通" → SubAgent 自主执行、调试、修复
SubAgent 是自治的------它自己决定怎么做、用什么工具、什么时候完成。适合复杂的、需要多步自主判断的任务。
Skill:流程模板
Skill 的本质是"按模板,引导用户走完流程"。它是一组结构化的指令,由主 Agent 执行,用户深度参与。比如:
- brainstorming:引导用户从模糊想法到具体设计
- TDD:引导开发者先写测试、再写实现、再重构
- 需求澄清:引导用户逐维度补全 PRD 的隐含假设
Skill 是交互式的------每一步都需要用户输入,Agent 按模板引导,不替用户做决策。
需求澄清的特征矩阵
| 特征 | 需求澄清的实际情况 | Tool 匹配度 | SubAgent 匹配度 | Skill 匹配度 |
|---|---|---|---|---|
| 交互模式 | 多轮对话,一问一答 | ❌ 单次调用 | ⚠️ 可以但不擅长 | ✅ 天然支持 |
| 用户决策 | 强依赖,每个答案都需要人确认 | ❌ 无用户参与 | ❌ 会自己脑补 | ✅ 强制等用户回答 |
| 流程标准化 | 5 个维度,固定顺序 | ❌ 无流程概念 | ⚠️ 可能跳过维度 | ✅ checklist 保证完整 |
| 外部 API | 不需要 | ❌ Tool 的价值就是调 API | ❌ 能力浪费 | ✅ 不需要额外工具 |
| 输出格式 | 结构化文档 | ⚠️ 可以但不灵活 | ⚠️ 格式不统一 | ✅ 模板化输出 |
| 与主流程衔接 | 澄清完直接进 coding | ❌ 结果孤立 | ⚠️ 需要手动传递 | ✅ 主 Agent 自然衔接 |
为什么 Tool 不行
需求澄清不是一个"输入→输出"的操作。它的核心困难不是执行,而是问对问题。
Tool 可以搜索表、执行 SQL、调接口------这些都是确定性的操作。但"删除操作是否需要二次确认?"这个问题,不是 Tool 能回答的,也不是 Tool 能问出来的。Tool 没有流程编排能力,无法根据前一个答案决定下一个问题。
如果强行用 Tool 做,大概会变成:clarify_requirements(prd_text) → 返回一堆问题。然后呢?谁来问用户?谁来记录答案?谁来保证 5 个维度都覆盖到了?这些问题 Tool 解决不了。
为什么 SubAgent 不行
SubAgent 最大的问题是自治。需求澄清不能自治------它必须让用户做决策。
如果用 SubAgent 做需求澄清,有两种可能:
-
SubAgent 自己脑补答案:它根据训练数据推断"删除操作通常需要二次确认",然后自己填上。这就不是"澄清"了,而是"猜测"。用户看到的是一份看起来完整的文档,但每个答案都是 AI 替用户决定的------比 PRD 更危险。
-
SubAgent 反复向用户提问:但它缺乏流程模板约束,提问顺序可能混乱,可能遗漏某个维度,可能同一个问题换个说法问两遍。SubAgent 的强项是自主探索,不是按部就班地走流程。
为什么 Skill 正好
Skill 的三个特性与需求澄清的三个需求一一对应:
1. 模板驱动 ↔ 维度覆盖
Skill 定义了 5 个维度和每个维度的检查清单。Agent 按模板走,不会遗漏。每个维度有提问模板,确保问题结构化。这是 Tool 做不到的流程保证,也是 SubAgent 容易丢失的结构约束。
2. 交互式执行 ↔ 用户决策
Skill 天然是一问一答的。Agent 问一个维度的问题 → 等用户回答 → 总结确认 → 进入下一个维度。用户始终是决策者,Agent 只是引导者。这是 SubAgent 做不到的交互保证。
3. 主 Agent 执行 ↔ 无缝衔接
Skill 在主 Agent 中执行,不需要启动独立进程。需求澄清的结果直接在主 Agent 的上下文中,下一步可以直接交给 coding Skill 使用,不需要"把结果传过去"。这是 SubAgent 做不到的衔接保证。
一句话总结
需求澄清 = 结构化流程 (保证不遗漏)+ 交互式对话 (保证用户决策)+ 模板化输出(保证可消费)。这三点恰好是 Skill 的能力边界,而 Tool 只能做操作,SubAgent 太自治。选对机制,事半功倍。