
请君浏览
-
- 前言
- [一、HTTP 协议概述](#一、HTTP 协议概述)
-
- [1.1 认识 URL](#1.1 认识 URL)
- [1.2 urlencode 与 urldecode](#1.2 urlencode 与 urldecode)
- [二、HTTP 请求与响应格式](#二、HTTP 请求与响应格式)
-
- [2.1 请求格式](#2.1 请求格式)
- [2.2 响应格式](#2.2 响应格式)
- [2.3 手工验证:用 netcat 发送 HTTP 请求](#2.3 手工验证:用 netcat 发送 HTTP 请求)
- [三、HTTP 方法](#三、HTTP 方法)
-
- [3.1 GET 与 POST 的核心区别](#3.1 GET 与 POST 的核心区别)
- [3.2 表单提交:GET 还是 POST](#3.2 表单提交:GET 还是 POST)
- [四、HTTP 状态码与重定向](#四、HTTP 状态码与重定向)
-
- [4.1 状态码速查](#4.1 状态码速查)
- [4.2 重定向的底层机制](#4.2 重定向的底层机制)
- [五、HTTP 常见 Header](#五、HTTP 常见 Header)
-
- [5.1 核心 Header 一览](#5.1 核心 Header 一览)
- [5.2 有趣的 User-Agent 历史](#5.2 有趣的 User-Agent 历史)
- [5.3 Connection 字段与长连接的工程意义](#5.3 Connection 字段与长连接的工程意义)
- [六、实现 HTTP 服务器------从 Hello World 到完整 Web 后端](#六、实现 HTTP 服务器——从 Hello World 到完整 Web 后端)
-
- [6.1 Hello World------最小可行版本](#6.1 Hello World——最小可行版本)
- [6.2 扩展一:支持请求路径解析和静态文件返回](#6.2 扩展一:支持请求路径解析和静态文件返回)
- [6.3 扩展二:支持 POST 请求------解析表单和 JSON](#6.3 扩展二:支持 POST 请求——解析表单和 JSON)
- [6.4 扩展三:完整的 HTTP 请求响应流水线](#6.4 扩展三:完整的 HTTP 请求响应流水线)
- 七、常见问题与避坑指南
-
- [7.1 Header 和 Body 之间的空行丢失](#7.1 Header 和 Body 之间的空行丢失)
- [7.2 Content-Length 与实际 Body 长度不匹配](#7.2 Content-Length 与实际 Body 长度不匹配)
- [7.3 浏览器多发出一个 /favicon.ico 请求](#7.3 浏览器多发出一个 /favicon.ico 请求)
- [7.4 URL 路径包含 `..` 导致目录穿越](#7.4 URL 路径包含
..导致目录穿越)
- [八、MIME 类型与 Content-Type](#八、MIME 类型与 Content-Type)
-
- [8.1 为什么需要 Content-Type](#8.1 为什么需要 Content-Type)
- [8.2 常见的 Content-Type 场景对照](#8.2 常见的 Content-Type 场景对照)
- [九、浏览器缓存机制------304 Not Modified 的原理](#九、浏览器缓存机制——304 Not Modified 的原理)
-
- [9.1 基于时间的缓存:Last-Modified + If-Modified-Since](#9.1 基于时间的缓存:Last-Modified + If-Modified-Since)
- [9.2 基于内容的缓存:ETag + If-None-Match](#9.2 基于内容的缓存:ETag + If-None-Match)
- [9.3 Cache-Control:让浏览器跳过"验证"步骤](#9.3 Cache-Control:让浏览器跳过"验证"步骤)
- 总结
- [附录:HTTP 版本演进简史](#附录:HTTP 版本演进简史)
- 尾声
前言
之前我们定义了私有应用层协议,体会了 Encode/Decode + 序列化/反序列化 的设计模式。但实际的互联网世界中,HTTP 才是应用层协议的事实标准------它统一了浏览器与服务器之间的通信规则,也统一了我们使用的几乎每一个 Web API。理解了 HTTP 的底层格式,再去看 Flask、Spring Boot、Express 这些 Web 框架,你会发现它们不过是在 HTTP 报文上面包了一层便利的 API。
本文将从 HTTP 协议的请求/响应格式出发,逐一拆解 URL、请求方法、状态码、常用 Header、Connection 长连接等核心概念,亲手实现一个支持 GET 和 POST 的最简 HTTP 服务器,并逐步扩展为能返回静态文件、解析表单数据的功能完备的 Web 服务器。读完本文,你将彻底理解 HTTP 协议的底层约定,并能从头写出一个可被浏览器访问的真实 Web 后端。
一、HTTP 协议概述
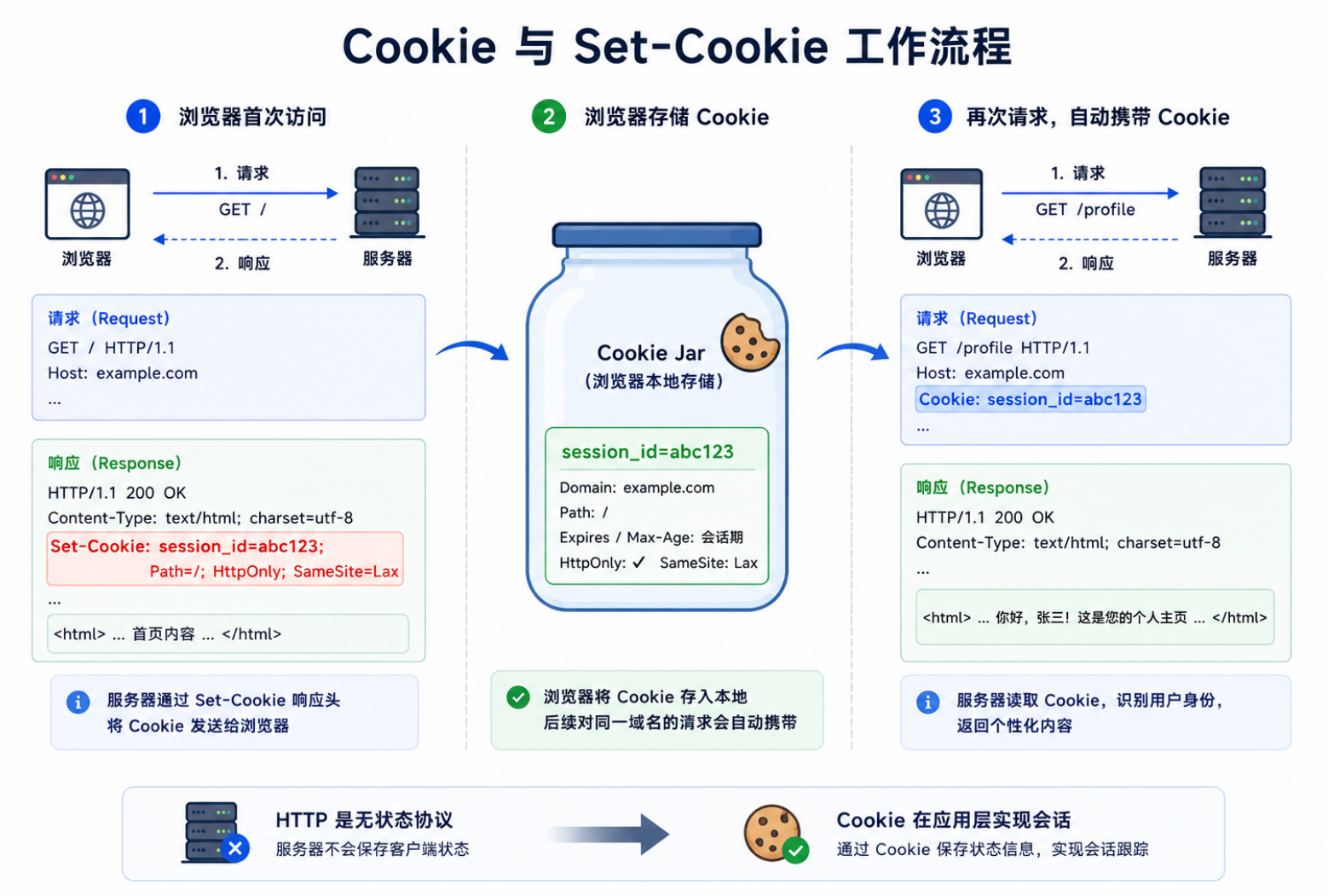
HTTP(HyperText Transfer Protocol,超文本传输协议) 定义了客户端(通常是浏览器)与服务器之间的通信格式。它是无连接、无状态的协议------每次请求独立,服务器不保留客户端的上一次状态(会话功能由 Cookie 等机制在上层实现)。
HTTP 协议是客户端与服务器之间通信的基础。客户端通过 HTTP 协议向服务器发送请求,服务器收到请求后处理并返回响应。这种"一次请求-一次响应"的模式,构成了现代互联网应用的全部交互基础。
HTTP 本质上就是上一篇自定义协议的"标准化版本":请求 = 首行 + Header + Body,响应也是一样。理解了上一篇的 Encode/Decode 模式,HTTP 只是把报文格式换成了标准的写法------用
\r\n分隔、用Content-Length确定 Body 长度。
HTTP 之所以能成为互联网的"普通话",关键在于它找到了简单性和表达力之间的最佳平衡点。协议设计者面临一个经典矛盾:太简单了表达不了复杂需求(如早期的 Gopher 协议只能浏览纯文本菜单),太复杂了实现门槛太高(如 CORBA 和 SOAP,最终被 RESTful JSON 取代)。HTTP 的选择是:用纯文本首行和 Header 表达元信息(人类可读、方便调试),用 Content-Length 精确界定 Body 长度(解决粘包),Body 本身则可以是任意二进制数据(不限制内容类型)。这三层设计让 HTTP 同时服务了静态网页、API 调用、文件上传、视频流和 WebSocket 双向通信------同一套协议,负载了互联网 80% 以上的流量。
另一个容易被忽略的事实是:HTTP 的无状态设计是一种刻意的取舍,而非缺陷。服务器不保存客户端状态,意味着每个请求都是自包含的------服务器不需要为每个连接分配内存来记住"之前发生了什么"。这使得一台 Web 服务器可以同时处理数万连接而不会内存耗尽。状态管理被"外包"给了上层机制:Cookie(客户端存储会话 ID)、数据库(服务器持久化状态)、Token(JWT 等自包含认证凭证)。这种分层思想贯穿了整个互联网架构------下层提供简洁可靠的传输,上层按需添加功能。
1.1 认识 URL
平时说的"网址"就是 URL(Uniform Resource Locator)。以 http://www.example.com:8080/index.html?name=zhangsan#chapter2 为例:
http://www.example.com:8080/index.html?name=zhangsan#chapter2
└┬┘ └────┬──────┘└┬┘└────┬────┘└──────┬──────┘└───┬──┘
协议 域名/IP 端口 路径 查询字符串(query) 片段标识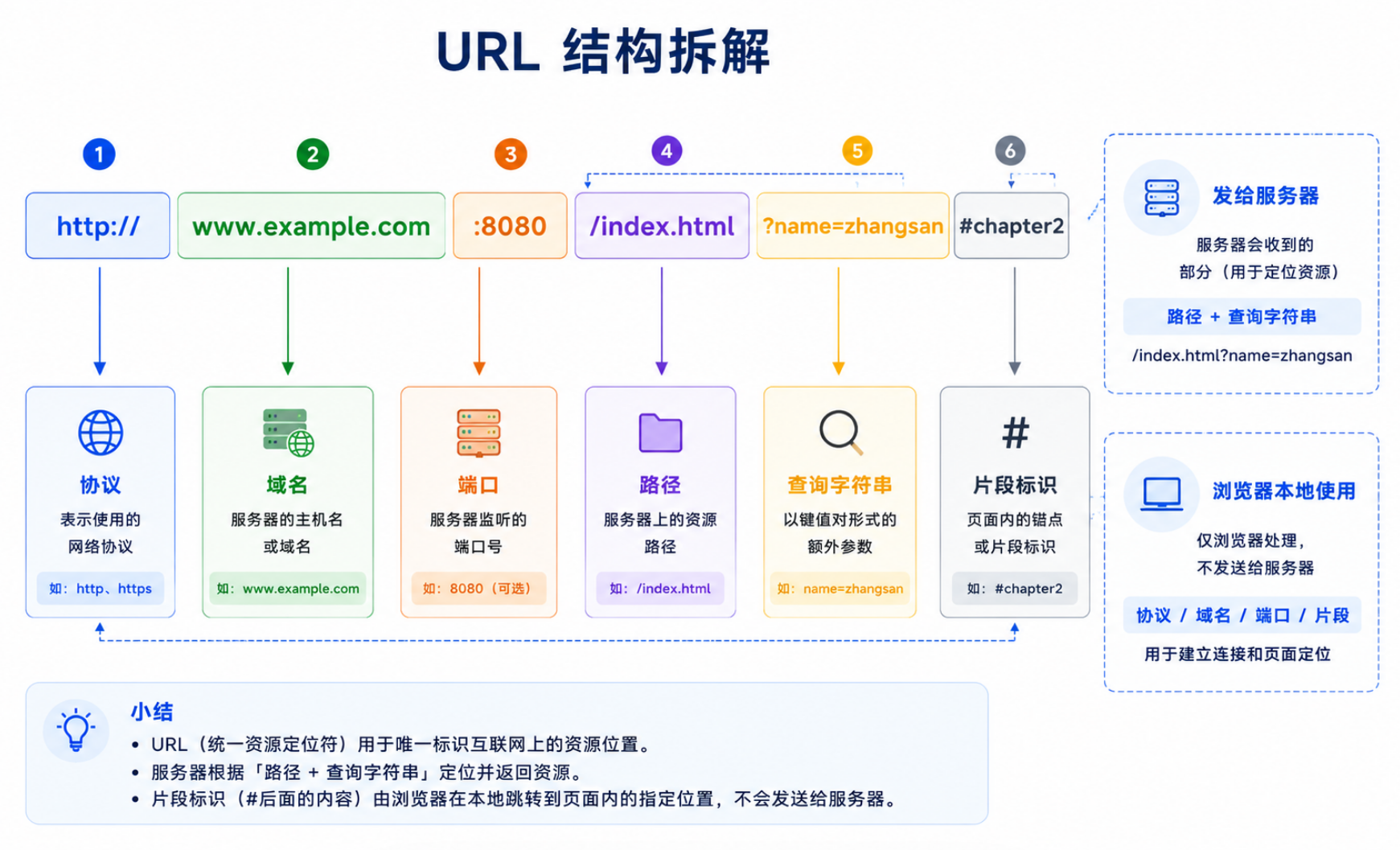
| 组成部分 | 示例 | 说明 | 是否发给服务器 |
|---|---|---|---|
| 协议 | http:// |
也可是 https://。本质上只是告诉浏览器用哪个端口和是否加密 |
❌ |
| 域名/IP | www.example.com |
通过 DNS 解析获得服务器的 IP 地址 | ❌(IP 在 TCP 连接时用) |
| 端口 | :8080 |
省略时默认 80(HTTP)或 443(HTTPS) | ❌(TCP 连接时用) |
| 路径 | /index.html |
服务器上的资源路径。这是 Web 服务器"路由"的核心 | ✅ |
| 查询字符串 | ?name=zhangsan |
传给服务器的参数,格式为 key=value&key=value |
✅ |
| 片段标识 | #chapter2 |
页面内部锚点定位 | ❌ 不发送 |
为什么 fragments 不发给服务器?因为它的作用是页面内部的导航------浏览器拿到完整的 HTML 后,自己滚动到
id="chapter2"的位置。这对于纯静态页面完全在客户端完成,不需要服务器参与。
URL 的设计看似简单,背后却包含了网络工程的几个核心洞察。最值得关注的是协议与资源的分离 :URL 的前半部分(协议、域名、端口)告诉浏览器"怎么找到服务器",后半部分(路径、查询字符串)告诉服务器"你要什么资源"。这种分离让同一台服务器可以同时服务多个完全不同的 Web 应用(通过不同的路径前缀),也为后来的反向代理和 API 网关奠定了基础------Nginx 看到 /api/ 开头的路径转发给后端服务,看到 /static/ 直接从磁盘返回文件,看到 / 返回前端 SPA 页面。所有这一切都基于对 URL 路径的解析,一行代码都不用改后端------这正是"关注点分离"在协议层的体现。
1.2 urlencode 与 urldecode
URL 中 /、?、:、&、= 等字符有特殊含义。如果参数本身包含这些字符(如搜索 C++ 中的 +),必须转义。转义规则:将字符的每个字节用 16 进制表示,前面加 %:
| 字符 | 转义后 | 说明 |
|---|---|---|
+ |
%2B |
+ 在 URL 中常被解析为空格(历史原因) |
| 空格 | %20(或 +) |
%20 是标准写法,+ 是表单提交的遗留写法 |
/ |
%2F |
不加转义会被误解为路径分隔符 |
? |
%3F |
不加转义会被误解为查询字符串起点 |
& |
%26 |
不加转义会被误解为参数分隔符 |
= |
%3D |
不加转义会被误解为键值分隔符 |
中 (UTF-8: E4 B8 AD) |
%E4%B8%AD |
中文和其他非 ASCII 字符全部需要转义 |
cpp
// urldecode 的简单实现
#include <cctype>
std::string UrlDecode(const std::string &src)
{
std::string ret;
for (size_t i = 0; i < src.size(); i++)
{
if (src[i] == '%' && i + 2 < src.size() && isxdigit(src[i+1]) && isxdigit(src[i+2]))
{
// %XY → 把 XY 当作 16 进制解析
char hex[3] = {src[i+1], src[i+2], 0};
ret += static_cast<char>(strtol(hex, nullptr, 16));
i += 2;
}
else if (src[i] == '+')
ret += ' '; // 表单提交中 + 代表空格
else
ret += src[i];
}
return ret;
}二、HTTP 请求与响应格式
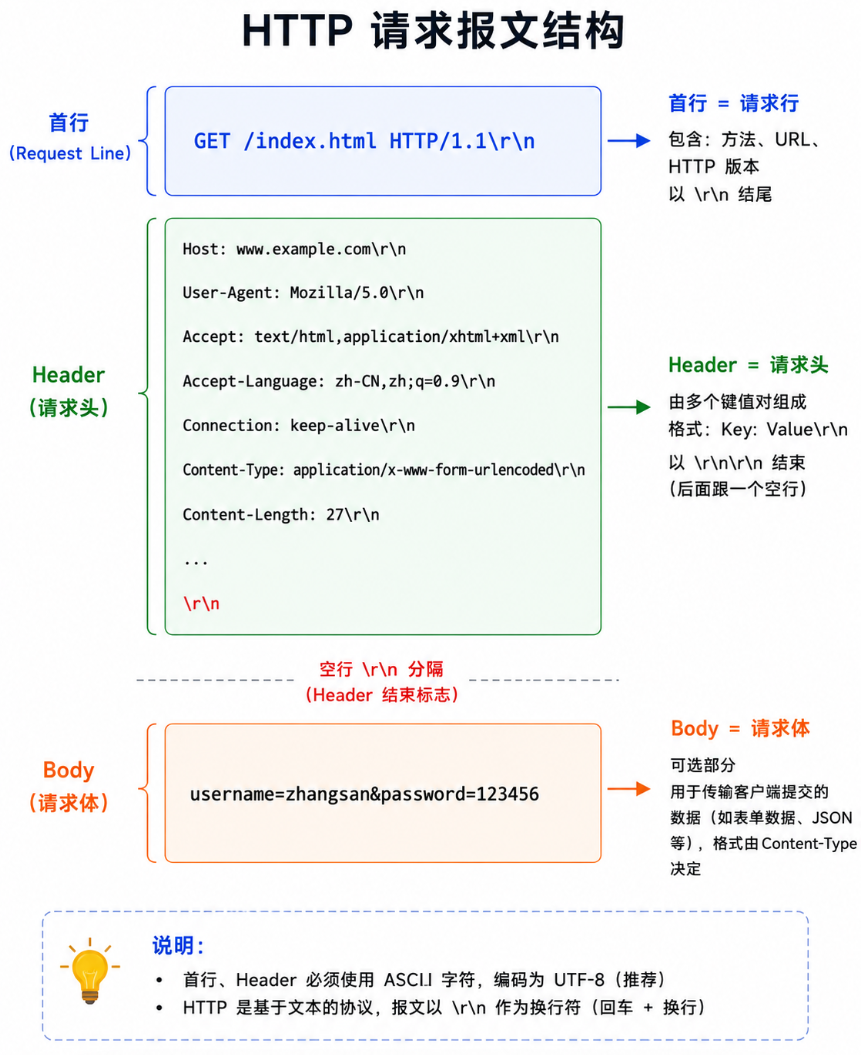
HTTP 协议的核心是三部分:首行(请求行/状态行)+ Header + Body 。首行和 Header 都是纯文本、以 \r\n 结尾,Header 和 Body 之间用一个空行(即 \r\n\r\n)分隔。
2.1 请求格式
GET /index.html HTTP/1.1\r\n ← 首行(请求行)
Host: www.example.com\r\n ← Header
User-Agent: Mozilla/5.0\r\n
Accept: text/html\r\n
Content-Length: 27\r\n
\r\n ← 空行(Header 结束标志)
username=zhangsan&password=123456 ← Body(可选)| 部分 | 格式 | 说明 | 示例 |
|---|---|---|---|
| 首行 | [方法] [URL路径] [版本]\r\n |
空格分隔,版本通常是 HTTP/1.1 或 HTTP/1.0 |
GET /api/user HTTP/1.1 |
| Header | 键: 值\r\n |
若干行键值对,冒号后必须有一个空格。遇到空行结束 | Content-Type: text/html |
| Body | 任意数据 | Body 长度由 Content-Length 指定,没有 Body 时此项为空 |
{"name":"zhangsan"} |
2.2 响应格式
HTTP/1.1 200 OK\r\n ← 首行(状态行)
Content-Type: text/html\r\n ← Header
Content-Length: 20\r\n
Connection: keep-alive\r\n
\r\n ← 空行
<h1>hello world</h1> ← Body| 部分 | 格式 | 说明 | 示例 |
|---|---|---|---|
| 首行 | [版本] [状态码] [状态描述]\r\n |
状态描述是给人看的,程序只看状态码 | HTTP/1.1 404 Not Found |
| Header | 键: 值\r\n |
与请求 Header 格式完全一致 | Content-Type: text/html |
| Body | 任意数据 | 如 HTML、JSON、图片的二进制数据 | <html>... |
请求和响应结构高度对称。掌握这个模板,意味着你能手工构造任何 HTTP 报文------无论是用 C++ 写 Web 服务器,还是用 Python socket 测试 API,还是在终端用
nc(netcat)发送裸 HTTP 请求调试后端。
HTTP 协议格式中有一个极其精妙但容易被忽视的设计:首行和 Header 用 \r\n 结尾,Header 和 Body 之间用空行 \r\n\r\n 分隔。 这意味着 HTTP 报文的解析只需要一个简单的字符串匹配------找到第一个 \r\n 就是首行,继续找直到遇到连续两个 \r\n(即一个空行),之前的所有行都是 Header,之后的所有字节都是 Body。不需要复杂的二进制解析器,不需要定义长度前缀(Body 的长度用 Content-Length 这个普通 Header 字段指定),甚至不需要专门的库------一个会写 C 语言字符串处理的大学生就能实现一个基本的 HTTP 解析器。这个设计决策是 HTTP 能迅速普及的关键因素:协议越容易实现,采用它的开发者就越多。
与 HTTP 相反的反面教材是早期的 HTTP/2 之前的很多二进制协议------它们用自定义的帧格式、复杂的位域编码,实现起来需要专门的状态机和很多页的 RFC。这类协议在学术界很优雅,在工业界却输给了 HTTP 的纯文本主义。这就是为什么"人类可读"在协议设计中不是锦上添花------当开发者能在终端直接看到 GET / HTTP/1.1 并理解它的含义时,调试时间从天级别降到了分钟级别。
2.3 手工验证:用 netcat 发送 HTTP 请求
bash
# 终端1:启动一个 TCP 监听
$ nc -l 9999
# 终端2:用浏览器访问 http://127.0.0.1:9999
# 终端1 会打印浏览器发来的完整 HTTP 请求:
GET / HTTP/1.1
Host: 127.0.0.1:9999
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
Accept: text/html,application/xhtml+xml,...
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9这个实验非常直观:你看到的每一行都是浏览器自动生成的 HTTP Header。理解了这些 Header 的含义,你就理解了浏览器的心思。
三、HTTP 方法

HTTP 方法定义了对资源的操作语义。最常用的两个是 GET 和 POST------它们俩占了 HTTP 请求的 95% 以上。
| 方法 | 用途 | Body | 幂等 | 典型场景 |
|---|---|---|---|---|
| GET | 请求指定资源 | 通常无 | ✅ | 访问网页、搜索、API 查询("给我用户id=5的数据") |
| POST | 提交数据给服务器 | 有 | ❌ | 表单提交、登录、文件上传、新建资源 |
| HEAD | 与 GET 相同但只返回 Header | 无 | ✅ | 检查资源是否存在或是否被修改 |
| PUT | 上传文件到指定位置 | 有 | ✅ | RESTful API 更新资源("把id=5的用户信息改成这个") |
| DELETE | 删除指定资源 | 通常无 | ✅ | RESTful API 删除资源 |
| OPTIONS | 查询服务器对此 URL 支持的方法 | 无 | ✅ | CORS 预检请求(跨域AJAX的前置检查) |
3.1 GET 与 POST 的核心区别
| 对比维度 | GET | POST |
|---|---|---|
| 参数位置 | URL 的查询字符串中(?key=value) |
Body 中 |
| 长度限制 | URL 长度有限(浏览器/服务器限制,约 2KB~8KB) | 无明确限制 |
| 安全性 | 参数暴露在 URL 中,不适合传密码 | 参数在 Body 中,相对隐蔽(但仍需 HTTPS!) |
| 缓存 | 浏览器可以缓存 GET 结果 | 通常不缓存 |
| 书签 | 可以书签保存(参数在 URL 中) | 不能书签(参数在 Body 中) |
| 幂等 | 多次请求结果相同 | 多次请求可能创建多条记录 |
关键理解:POST 的"安全性"仅限于 URL 不可见------如果不用 HTTPS,POST Body 中的密码同样是明文传输,中间路由器可以完整看到。HTTP 层面的安全 = HTTPS,不是 GET vs POST。
3.2 表单提交:GET 还是 POST
HTML <form> 标签的 method 属性决定了提交方式:
html
<!-- GET 表单 → 参数拼接在 URL 中 -->
<form action="/search" method="GET">
<input name="q" type="text">
<input type="submit">
</form>
<!-- 提交后浏览器 URL 变为: /search?q=用户输入的内容 -->
<!-- POST 表单 → 参数放在 Body 中 -->
<form action="/login" method="POST">
<input name="username" type="text">
<input name="password" type="password">
<input type="submit">
</form>
<!-- 提交后 URL 不变,用户名和密码在 Body 中传输 -->四、HTTP 状态码与重定向
4.1 状态码速查
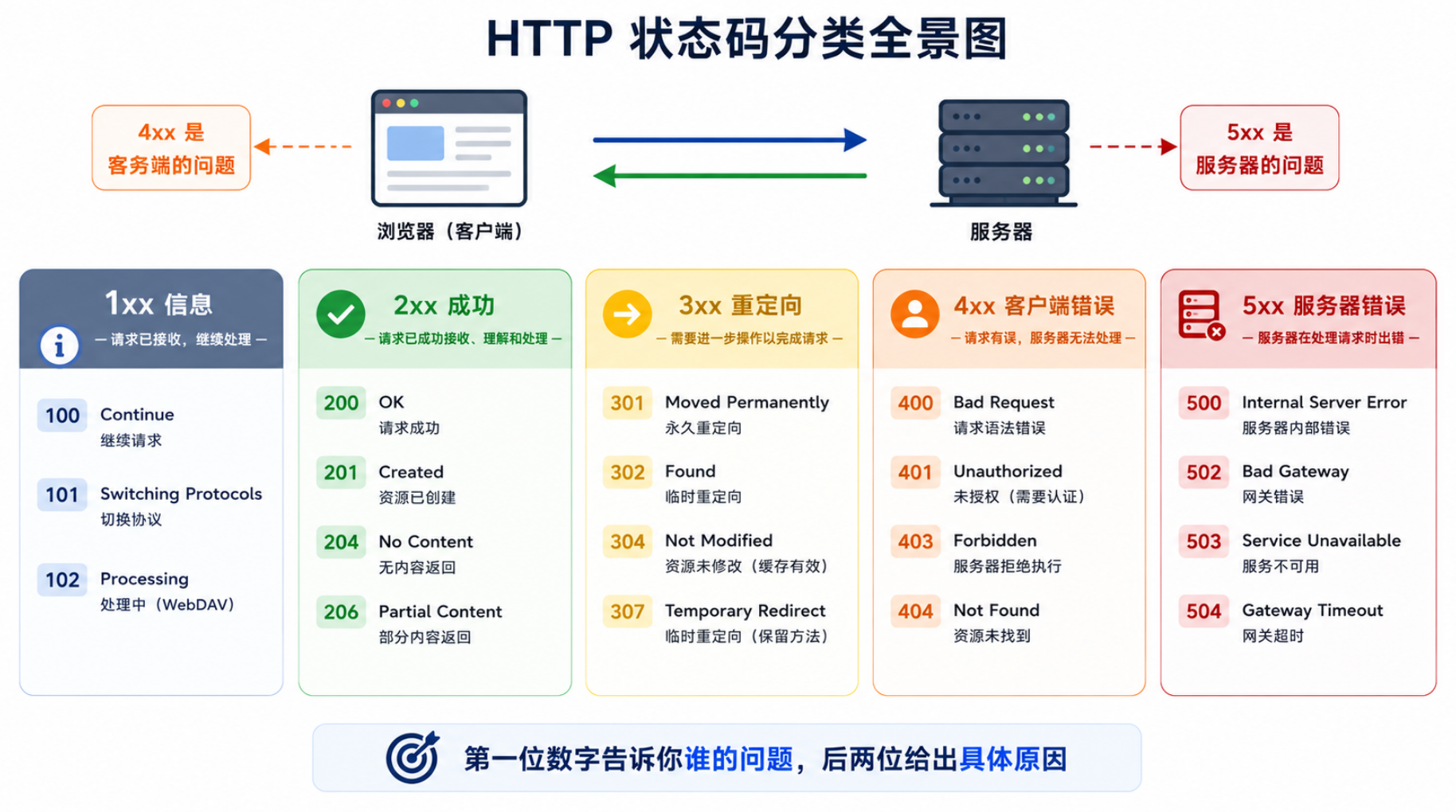
状态码三位数字,第一位表示响应类别。标准状态码有几十个,但日常开发接触的主要是这几个:
| 类别 | 范围 | 含义 |
|---|---|---|
| 1xx | 100~199 | 信息性状态码------服务器收到请求,继续处理 |
| 2xx | 200~299 | 成功------请求被正常处理 |
| 3xx | 300~399 | 重定向------需要进一步操作 |
| 4xx | 400~499 | 客户端错误------请求有问题 |
| 5xx | 500~599 | 服务器错误------服务器出了问题 |
最常用的状态码:
| 状态码 | 含义 | 何时出现 | 你能做什么 |
|---|---|---|---|
| 200 | OK | 请求成功 | 正常处理 |
| 201 | Created | POST 创建资源成功 | 返回新资源的 URL |
| 204 | No Content | 删除成功,无返回内容 | 告诉客户端操作完成即可 |
| 301 | Moved Permanently | 资源永久迁移 | 浏览器自动跳转并缓存新地址 |
| 302 | Found | 资源临时迁移 | 浏览器跳转但不缓存 |
| 304 | Not Modified | 客户端缓存的资源未过期 | 浏览器直接用本地缓存 |
| 400 | Bad Request | 请求格式错误(JSON 格式非法等) | 告诉用户输入有问题 |
| 401 | Unauthorized | 未登录或认证失败 | 跳转到登录页 |
| 403 | Forbidden | 已登录但无权访问 | 显示"没有权限" |
| 404 | Not Found | 资源不存在 | 显示 404 页面 |
| 500 | Internal Server Error | 服务器代码抛异常了 | 检查服务端日志 |
| 502 | Bad Gateway | 代理/网关从上游收到无效响应 | 检查上游服务是否正常 |
| 503 | Service Unavailable | 服务器过载或维护中 | 稍后重试 |
4.2 重定向的底层机制
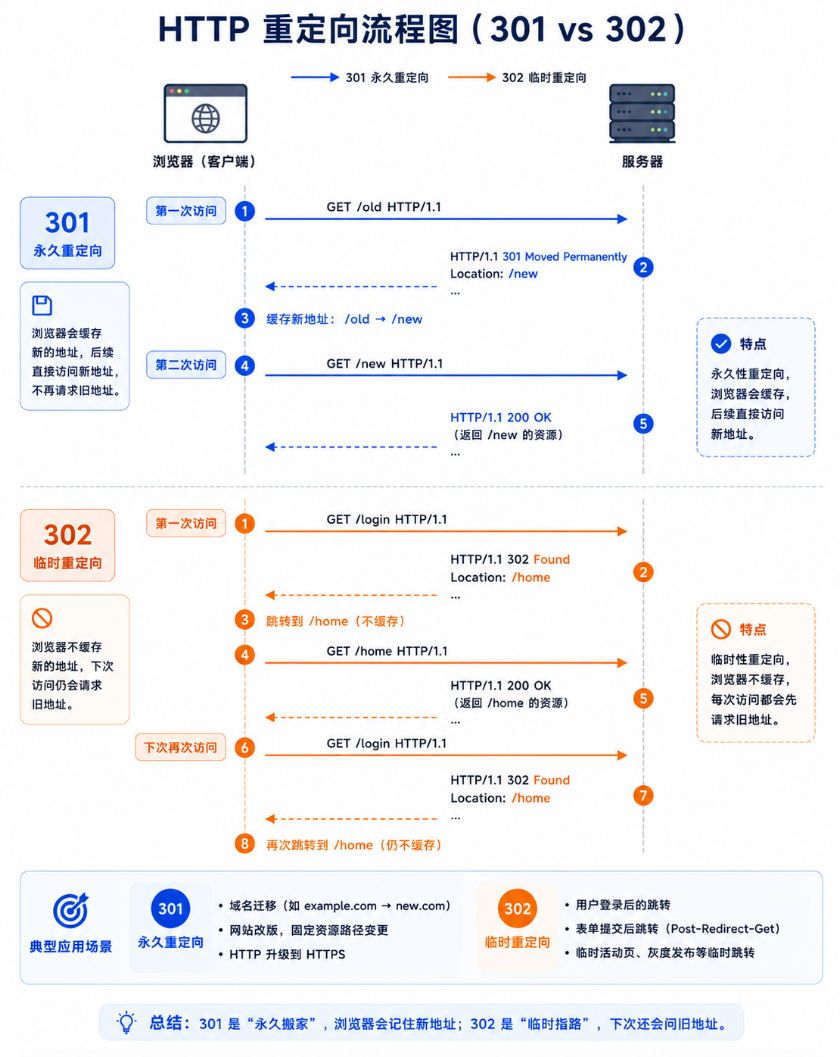
http
HTTP/1.1 301 Moved Permanently\r\n
Location: https://www.new-url.com\r\n
\r\n301(永久)vs 302(临时)的核心差异在浏览器行为:
| 特性 | 301(永久重定向) | 302(临时重定向) |
|---|---|---|
| 浏览器缓存 | 缓存重定向目标------下次直接去新 URL | 不缓存------每次都问一次原 URL |
| 搜索引擎 | 更新索引,用新 URL 替换旧 URL | 保持旧 URL,但内容从新 URL 获取 |
| 典型场景 | 域名迁移、HTTP→HTTPS 升级 | 登录成功后跳转到首页、Post/Redirect/Get 模式 |
| 代码实现 | sprintf(response, "HTTP/1.1 301 Moved Permanently\r\nLocation: %s\r\n\r\n", new_url); |
sprintf(response, "HTTP/1.1 302 Found\r\nLocation: %s\r\n\r\n", new_url); |
面试常见问题:"Post/Redirect/Get 模式是什么?"------用户 POST 表单提交后,服务器返回 302 重定向到一个 GET 页面。好处是:用户按 F5 刷新时,浏览器重新 GET 而不是重新 POST(重新 POST 会导致重复提交,比如扣了两次款)。
状态码体系还有一个更深层的设计智慧:它把"成功"和"失败"的定义权交给了服务器,而不是网络层。 TCP 层面的成功只意味着"字节流到达了",但 HTTP 层面的 200 才代表"请求被正确理解、资源存在、处理成功"。这三层校验链------TCP 的 ACK 确认字节到达、HTTP 的 200 确认语义正确、应用层的业务逻辑码确认业务操作成功------共同构成了 Web 服务的可靠性基础。当你在生产环境中看到大量 5xx 时,你知道是后端出了问题(而不是网络不通);看到大量 4xx 时,你知道是客户端发了错误的请求。这种故障定位能力正是 HTTP 状态码体系赋予的。
五、HTTP 常见 Header
Header 是 HTTP 协议的"元数据层"------它不直接承载业务数据,但决定了数据如何被传输、缓存和解释。
5.1 核心 Header 一览
| Header | 方向 | 含义 | 示例 |
|---|---|---|---|
Host |
请求 | 目标主机和端口 | Host: www.example.com:8080 |
Content-Type |
双向 | Body 的 MIME 类型 | text/html;charset=utf-8, application/json |
Content-Length |
双向 | Body 的字节数 | Content-Length: 1024 |
User-Agent |
请求 | 客户端的软件环境(浏览器/操作系统) | Mozilla/5.0 (Windows NT 10.0...) |
Accept |
请求 | 客户端能接收的响应类型 | Accept: text/html,image/webp |
Accept-Encoding |
请求 | 支持的压缩格式 | Accept-Encoding: gzip, deflate, br |
Accept-Language |
请求 | 偏好的语言 | Accept-Language: zh-CN,zh;q=0.9 |
Referer |
请求 | 当前请求的来源页面 URL | Referer: https://www.example.com/prev |
Location |
响应 | 配合 3xx 状态码,指定重定向目标 | Location: /new-url |
Cookie |
请求 | 客户端存储的会话信息 | Cookie: session_id=abc123;theme=dark |
Set-Cookie |
响应 | 服务器设置 Cookie | Set-Cookie: session_id=abc123; Path=/ |
Connection |
双向 | 连接管理 | keep-alive(保持) 或 close(关闭) |
Cache-Control |
响应 | 缓存策略 | Cache-Control: max-age=3600 |
Authorization |
请求 | 认证信息 | Authorization: Basic QWxhZGRpbjpvcGVu... |
Server |
响应 | 服务器软件类型 | Server: nginx/1.18.0 |
Last-Modified |
响应 | 资源最后修改时间 | Last-Modified: Mon, 23 Jan 2023 13:27:56 GMT |
5.2 有趣的 User-Agent 历史
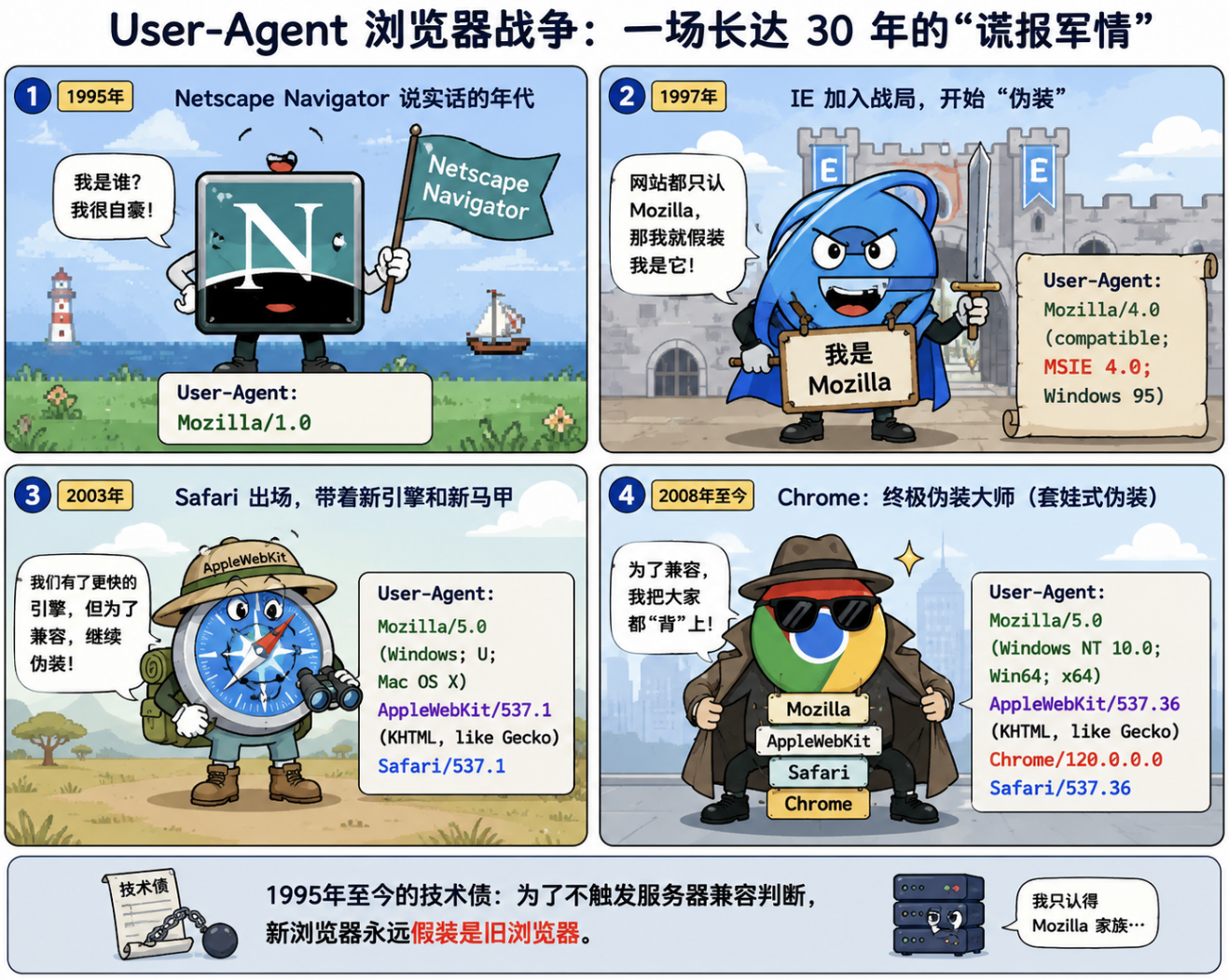
你可能注意到 Chrome 的 User-Agent 写着 Mozilla/5.0 ... AppleWebKit/537.36 ... Chrome/91 ... Safari/537.36------为什么一个 Chrome 浏览器要同时声称自己是 Mozilla、AppleWebKit、Safari?
这是一部浏览器战争的活化石:
- 最开始是 Netscape Navigator(Mozilla)
- IE 为了兼容,声称自己是 "Mozilla"
- Safari 基于 KHTML 渲染引擎(AppleWebKit)
- Chrome 基于 WebKit 分支(Blink),但为了不触发"Safari 专用"的服务器端判断,保留了 AppleWebKit 和 Safari 的标记
这个"谎报军情"的 User-Agent 传统从 1995 年延续至今,因为无数服务器端代码依赖它做浏览器兼容判断。这就是技术债在协议层的体现------为了向前兼容,新版本永远在假装自己是老版本。
HTTP Header 的设计中还有一个值得深思的工程原则:扩展性优先于完备性。 HTTP 的 Header 没有预定义的固定列表------任何人都可以添加自定义 Header(如 X-Request-ID 用于分布式链路追踪)。服务器对不认识的 Header 默认忽略,而不是报错。这个设计让 HTTP 可以在不修改协议规范的情况下被无限扩展:缓存控制(Cache-Control)、跨域资源共享(Access-Control-Allow-Origin)、安全策略(Content-Security-Policy)、性能优化(Link: <style.css>; rel=preload)------都是通过新的 Header 字段逐步引入的,没有一个需要修改 HTTP 协议本身。相比之下,很多"设计得更好"的协议因为 Header 列表是封闭的,每次加新功能都需要升级协议版本号,导致碎片化和兼容性问题。开放扩展、忽略未知------这个原则是 HTTP 长寿的秘诀之一。
5.3 Connection 字段与长连接的工程意义
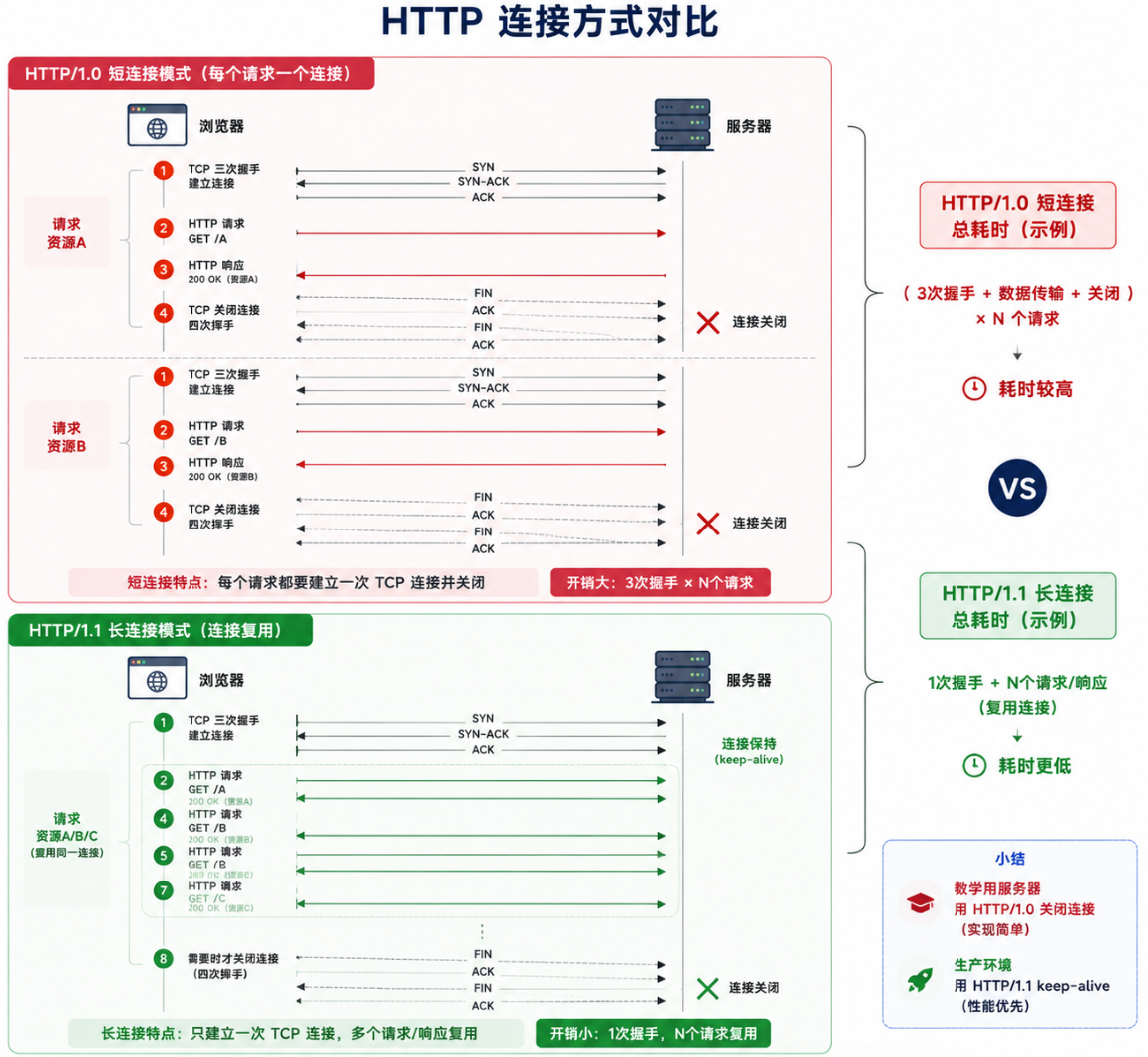
| 值 | 出现 | 默认行为 | 你该怎么做 |
|---|---|---|---|
Connection: keep-alive |
HTTP/1.1 | 默认保持连接,一个 TCP 连接上复用多个请求 | ❌ 不用手动设 |
Connection: close |
HTTP/1.0 | 请求/响应完成后立即关闭 TCP | ✅ 如果不想处理长连接,直接设这个 |
| 不加 Connection | HTTP/1.1 | 等同于 keep-alive |
✅ 默认就是长连接 |
cpp
// HTTP/1.0 的显式长连接
GET /page1.html HTTP/1.0\r\n
Connection: keep-alive\r\n
\r\n
// HTTP/1.1 的默认长连接------想关就显式设 close
GET /page1.html HTTP/1.1\r\n
Host: www.example.com\r\n
Connection: close\r\n // 告诉服务器:这次请求完成后关闭 TCP
\r\n工程决策: 在实现 HTTP 服务器时,最简单的做法是用
HTTP/1.0格式响应,不加Connection: keep-alive------浏览器收到 HTTP/1.0 响应后默认关闭连接。这样做虽然性能稍低(每个请求一个 TCP 连接),但代码逻辑极简,不需要处理连接复用、超时管理等复杂问题。大部分教学用 HTTP 服务器都这么设计。
六、实现 HTTP 服务器------从 Hello World 到完整 Web 后端
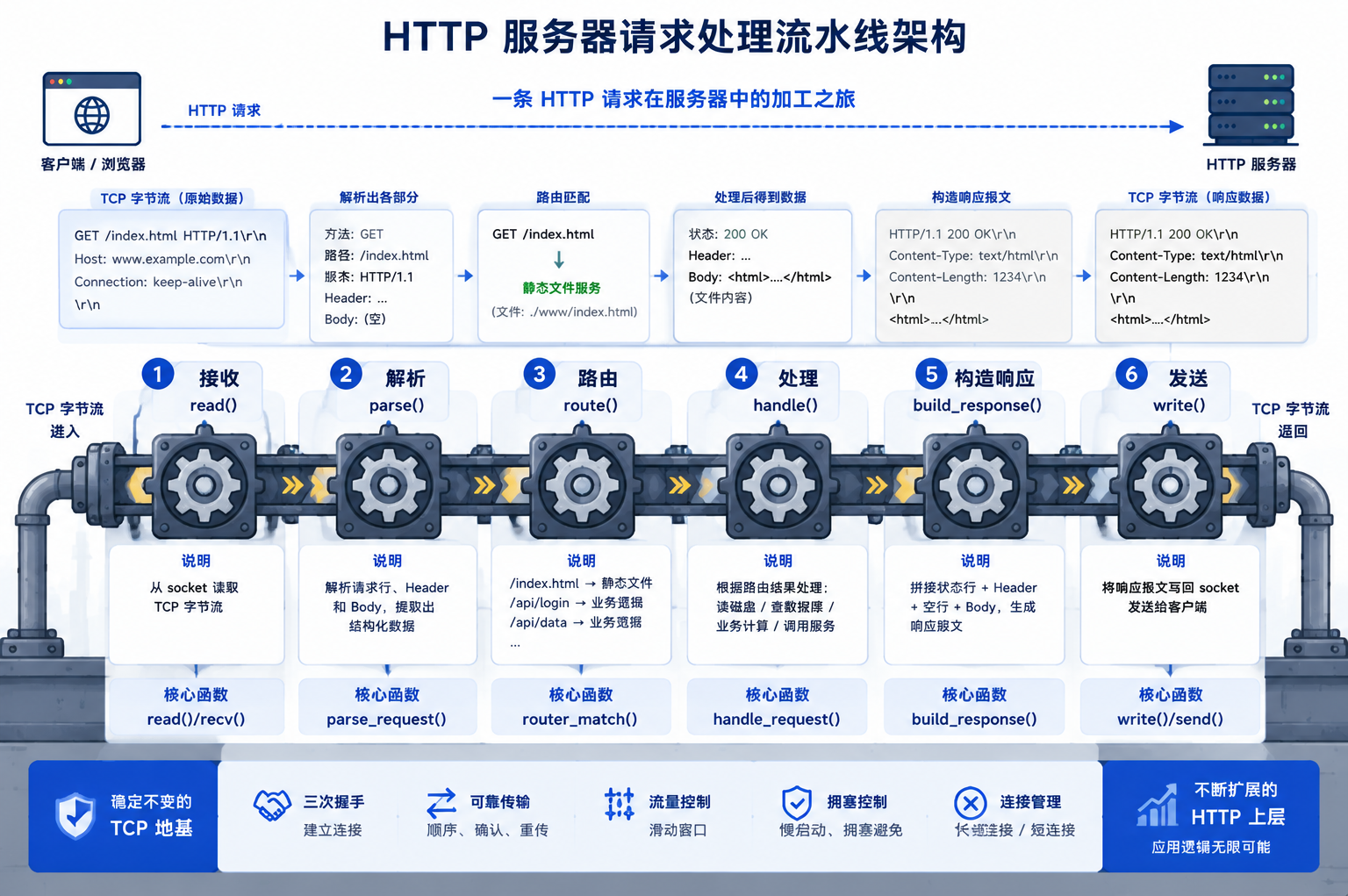
现在把我们之前写的 TCP 服务器框架改造为功能完备的 HTTP 服务器。核心流水线:接收 → 解析 → 路由 → 处理 → 构造响应 → 发送。
在动手写代码之前,先聊一个概念性问题:为什么你要手写 HTTP 服务器,而不是直接用现成的? 答案不是"造轮子",而是穿透抽象层 。使用 Flask 或 Express 时,你写 @app.route('/') 然后返回一个字符串,一切都很简单------但你也完全不知道浏览器发来的原始 HTTP 报文长什么样、Header 里有什么、Body 怎么被解析的。当你在生产环境中遇到一个奇怪的浏览器兼容性问题(比如某旧版 IE 发来的请求 Header 里多了一个从未见过的字段导致解析失败),你翻遍框架文档也找不到答案------因为框架把这些细节全部封装掉了。手写一次 HTTP 服务器的价值在于:你以后用任何 Web 框架时,脑子里都能浮现出底层在做什么。 这种心智模型一旦建立,调试效率的提升远超写代码的那几个小时。
6.1 Hello World------最小可行版本
cpp
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main(int argc, char* argv[])
{
if (argc != 3)
{
printf("usage: ./http_server [ip] [port]\n");
return 1;
}
// TCP 三部曲:socket → bind → listen
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd < 0) { perror("socket"); return 1; }
struct sockaddr_in addr;
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = inet_addr(argv[1]);
addr.sin_port = htons(atoi(argv[2]));
if (bind(fd, (struct sockaddr*)&addr, sizeof(addr)) < 0) {
perror("bind"); return 1;
}
if (listen(fd, 10) < 0) {
perror("listen"); return 1;
}
for (;;)
{
struct sockaddr_in client_addr;
socklen_t len = sizeof(client_addr);
int client_fd = accept(fd, (struct sockaddr*)&client_addr, &len);
if (client_fd < 0) { perror("accept"); continue; }
// 接收完整的 HTTP 请求
char input_buf[1024 * 10] = {0};
ssize_t read_size = read(client_fd, input_buf, sizeof(input_buf) - 1);
if (read_size < 0) { close(client_fd); continue; }
// 打印请求内容(调试用)
printf("[Request]\n%s\n", input_buf);
// 构造 HTTP 响应:HTTP/1.0 200 + Content-Length + Body
const char* hello = "<h1>hello world</h1>";
char response[1024] = {0};
sprintf(response,
"HTTP/1.0 200 OK\n"
"Content-Length: %lu\n"
"\n"
"%s",
strlen(hello), hello);
write(client_fd, response, strlen(response));
close(client_fd);
}
return 0;
}这段代码的每一步都有讲究:
| 步骤 | 代码 | 为什么这样写 |
|---|---|---|
input_buf[1024*10] |
10KB 缓冲区一次性读 | HTTP 请求通常小于 10KB,避免复杂的循环读取 |
HTTP/1.0 而非 1.1 |
响应行用 HTTP/1.0 |
告诉浏览器"我不会 keep-alive",浏览器不会在同一个 TCP 连接上发第二条请求 |
Content-Length |
精确计算 strlen(hello) |
浏览器需要知道 Body 何时结束。不写这个会导致浏览器挂起等待 |
两个 \n\n |
Header 和 Body 之间 | 第一个 \n 是 Content-Length 行的结束,第二个 \n 是标志 Header 结束的空行 |
编译运行后,在浏览器输入 http://127.0.0.1:9090,就能看到 "hello world" 页面。服务端终端会打印浏览器发来的完整请求文本------这是理解 HTTP 协议最好的方式:亲眼看到浏览器到底发了什么。
这个 Hello World 版本虽然只有几十行,但它完整地走通了 HTTP 通信的全链路。停下来思考一下浏览器和你写的服务器之间发生了什么:浏览器解析你在地址栏输入的 http://127.0.0.1:9090,提取出 IP 地址 127.0.0.1 和端口 9090,通过 TCP 三次握手与你的服务器建立连接,然后发送一个符合 HTTP/1.1 标准的请求报文。你的服务器调用 read 把它读出来,调用 sprintf 拼接了一个符合 HTTP/1.0 标准的响应报文,调用 write 发回去。浏览器收到后解析状态行 HTTP/1.0 200 OK------确认请求成功,解析 Content-Length: 20------知道 Body 有 20 字节,然后从空行之后取出 <h1>hello world</h1>,交给 HTML 渲染引擎。整个过程涉及应用层、传输层、网络层、链路层四层协议栈的协作,但站在 HTTP 层面的你,只需要关心两件事:收到的字符串怎么解析,要回的字符串怎么拼。 这就是协议分层的威力------下层负责可靠传输,上层只关心语义。
6.2 扩展一:支持请求路径解析和静态文件返回
下面添加上一篇中的 GetFileContent 函数,根据浏览器请求的路径返回对应的 HTML 文件:
cpp
// 读取二进制文件内容
std::string GetFileContent(const std::string &path)
{
std::ifstream in(path, std::ios::binary);
if (!in.is_open()) return "";
in.seekg(0, in.end);
int filesize = in.tellg();
in.seekg(0, in.beg);
std::string content;
content.resize(filesize);
in.read((char*)content.c_str(), filesize);
in.close();
return content;
}
// 解析 HTTP 请求首行,提取路径
// "GET /index.html HTTP/1.1\r\n..." → "/index.html"
std::string ParsePath(const std::string &request)
{
size_t start = request.find(' ') + 1; // 方法后的第一个空格
size_t end = request.find(' ', start); // URL 后的空格
if (start == std::string::npos || end == std::string::npos)
return "/";
return request.substr(start, end - start);
}
// 根据文件后缀判断 Content-Type
std::string GetContentType(const std::string &path)
{
if (path.ends_with(".html")) return "text/html";
if (path.ends_with(".css")) return "text/css";
if (path.ends_with(".js")) return "application/javascript";
if (path.ends_with(".png")) return "image/png";
if (path.ends_with(".jpg") || path.ends_with(".jpeg"))
return "image/jpeg";
if (path.ends_with(".json")) return "application/json";
return "text/plain"; // 默认
}
// 在 accept 拿到 client_fd 之后:
std::string path = ParsePath(input_buf);
if (path == "/") path = "/index.html"; // 默认首页
std::string root_dir = "./www"; // Web 根目录
std::string full_path = root_dir + path;
std::string content = GetFileContent(full_path);
if (content.empty())
{
// 文件不存在 → 404
const char* body = "<h1>404 Not Found</h1><p>The requested URL was not found on this server.</p>";
char response[1024];
sprintf(response,
"HTTP/1.0 404 Not Found\n"
"Content-Type: text/html\n"
"Content-Length: %lu\n"
"\n"
"%s",
strlen(body), body);
write(client_fd, response, strlen(response));
}
else
{
// 文件存在 → 200 + 正确的 Content-Type
std::string ctype = GetContentType(full_path);
char response_header[512];
sprintf(response_header,
"HTTP/1.0 200 OK\n"
"Content-Type: %s\n"
"Content-Length: %lu\n"
"\n",
ctype.c_str(), content.size());
// 先发 Header
write(client_fd, response_header, strlen(response_header));
// 再发 Body(二进制安全,用 write 而非字符串函数)
write(client_fd, content.c_str(), content.size());
}为什么写 Body 要用
write(content.c_str(), content.size())而不是sprintf? 因为 HTML/CSS/JS/图片文件内容中可能包含\0(二进制文件)或导致sprintf格式串问题。content.size()是二进制安全的长度。
这个扩展让服务器从"只会说 Hello World"进化到了"能提供任何文件"。这正是 Web 服务器最原始的功能------静态文件服务 。Nginx 和 Apache 的核心工作就是做这件事:根据请求 URL 在磁盘上找到对应文件,设置正确的 Content-Type,然后发出去。我们实现了一个最简版本,但它已经包含了生产级 Web 服务器的核心逻辑:路径解析、文件系统安全(防止目录穿越)、MIME 类型匹配、二进制安全传输。理解了这个,你就理解了 Nginx 配置文件中 root /var/www/html; 到底做了什么。
6.3 扩展二:支持 POST 请求------解析表单和 JSON
POST 的数据在 Body 中。关键步骤:解析 Content-Length → 读取 Body → 根据 Content-Type 选择解析方式。
cpp
// 解析 POST Body
int GetContentLength(const std::string &request)
{
const char* key = "Content-Length: ";
size_t pos = request.find(key);
if (pos == std::string::npos) return 0;
pos += strlen(key);
size_t end = request.find("\r\n", pos);
return std::stoi(request.substr(pos, end - pos));
}
// 获取 Header 结束位置后的 Body
std::string GetBody(const std::string &request)
{
size_t pos = request.find("\r\n\r\n"); // 空行
if (pos == std::string::npos) return "";
return request.substr(pos + 4); // 跳过 "\r\n\r\n"
}
// 解析 URL 编码的表单数据: "key1=value1&key2=value2"
std::map<std::string, std::string> ParseFormData(const std::string &body)
{
std::map<std::string, std::string> result;
std::istringstream iss(body);
std::string pair;
while (std::getline(iss, pair, '&'))
{
size_t eq = pair.find('=');
if (eq != std::string::npos)
result[pair.substr(0, eq)] = pair.substr(eq + 1);
}
return result;
}
// 使用示例:处理登录表单的 POST 请求
int content_length = GetContentLength(input_buf);
std::string body = GetBody(input_buf);
auto form = ParseFormData(body);
std::string username = form["username"];
std::string password = form["password"];
// 验证逻辑...6.4 扩展三:完整的 HTTP 请求响应流水线
把上述各部分串联起来,就是一个功能完备的 Web 服务器主循环:
① read(client_fd) → 拿到 HTTP 请求文本
② ParsePath(request) → "/index.html"
③ if GET: 读文件返回 → if POST: 解析Body执行业务
④ 构造响应文本(状态行 + Header + 空行 + Body)
⑤ write(client_fd) → 浏览器渲染
⑥ close(client_fd) 或 保持连接继续读| 步骤 | 输入 | 输出 | 核心函数 |
|---|---|---|---|
| 接收 | TCP 字节流 | HTTP 请求文本 | read(client_fd, ...) |
| 解析 | 请求文本 | 方法 + 路径 + Header + Body | ParsePath GetContentLength |
| 路由 | 方法 + 路径 | 业务处理函数 | if(path=="/api/user"){...} |
| 响应 | 处理结果 | HTTP 响应文本 | sprintf(response, "HTTP/1.0 200...") |
| 发送 | 响应文本 | TCP 字节流 | write(client_fd, ...) |
在继续之前,停下来回顾一下我们到目前为止构建了什么。从 Hello World 到 POST 解析,这个 HTTP 服务器的功能演进揭示了一个重要的工程模式:每一个新功能都是在上一个版本的基础上,在特定环节插入新的处理逻辑。 socket→bind→listen→accept 的 TCP 底层从来没有变过,变的是对 HTTP 报文的解析深度和对不同路径/方法的处理策略。这就是为什么我们花那么多精力学 TCP------因为它是稳定的地基。地基牢固了,上面盖什么房子(HTTP、WebSocket、自定义协议)都只是"怎么解析报文"的问题。
七、常见问题与避坑指南
7.1 Header 和 Body 之间的空行丢失
现象: 浏览器一直转圈(pending),服务器日志显示已 write 但页面加载不出来。
原因: sprintf(response, "HTTP/1.0 200 OK\r\nContent-Length: 20\r\n%s", body); 少了一个 \r\n------浏览器以为 Header 还没结束,一直在等"空行"。
解决: sprintf(response, "HTTP/1.0 200 OK\r\nContent-Length: 20\r\n\r\n%s", body); 在 Content-Length 行后面必须有两个连续的 \r\n。
7.2 Content-Length 与实际 Body 长度不匹配
现象: 页面内容被截断,或者浏览器显示"连接被重置"。
原因: Content-Length 告诉浏览器"Body 有 500 字节",但实际只发了 300 字节。浏览器接收 300 字节后继续阻塞等待剩下 200 字节------等不到就会超时断开。
解决: 用 strlen(body) 或 .size() 精确计算,不使用硬编码数字。对于中文内容,注意 strlen 计算的是字节数而非字符数。
7.3 浏览器多发出一个 /favicon.ico 请求
现象: 服务器日志中除了预期的请求之外,总有一个 GET /favicon.ico HTTP/1.1。
原因: 浏览器默认请求网站图标以显示在标签页上。这不是 bug,是正常行为。
解决: 在根目录放一个 favicon.ico 文件,或者返回 404 忽略该日志。
7.4 URL 路径包含 .. 导致目录穿越
现象: 攻击者请求 GET /../etc/passwd HTTP/1.1,服务器返回了系统敏感文件。
原因: 简单拼接 root_dir + path 没有过滤 ..,导致可以访问 Web 根目录之外的文件。
解决: 解析完路径后,过滤 .. 或使用 realpath 检查最终路径是否在 Web 根目录内:
cpp
// 防止目录穿越攻击
std::string SafePath(const std::string &root, const std::string &path)
{
// 简单方案:过滤 ".."
if (path.find("..") != std::string::npos)
return "";
return root + path;
}八、MIME 类型与 Content-Type
8.1 为什么需要 Content-Type
浏览器收到响应 Body 后,需要判断这是 HTML(解析并渲染)、图片(直接显示)、CSS(解析后应用样式)、JavaScript(执行)、还是 JSON(交给 AJAX 回调)。这个判断的依据就是 Content-Type 头部。
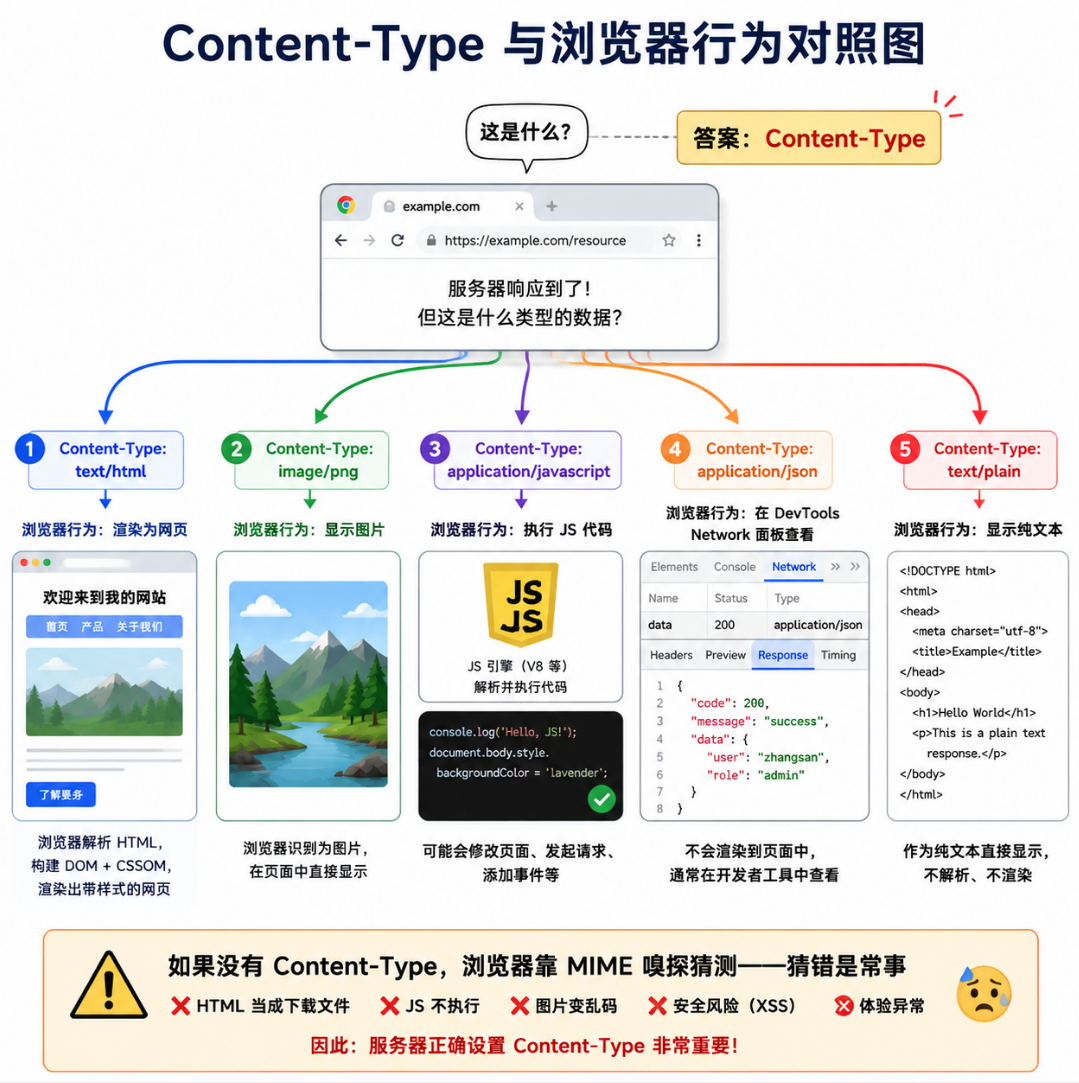
| Content-Type | Body 内容 | 浏览器行为 |
|---|---|---|
text/html |
HTML 文档 | 解析 DOM 树,渲染页面 |
text/css |
CSS 样式表 | 应用样式到页面 |
application/javascript |
JavaScript 代码 | 交给 JS 引擎执行 |
image/png |
PNG 图片 | 直接渲染显示 |
application/json |
JSON 数据 | 交给 fetch 或 XMLHttpRequest 的回调 |
application/x-www-form-urlencoded |
URL 编码的表单数据 | POST 请求 Body 的默认格式 |
text/plain |
纯文本 | 按文本原样显示,不解析 |
multipart/form-data |
包含文件上传的表单 | 浏览器按边界分隔符解析各字段 |
如果服务器不返回
Content-Type,浏览器会尝试MIME 嗅探 (根据 Body 的前几个字节猜测类型),但猜错是常有的事。永远不要依赖浏览器的猜测------自己显式设置正确的Content-Type。
8.2 常见的 Content-Type 场景对照
| 场景 | 正确的 Content-Type |
|---|---|
| 返回一个 HTML 页面 | text/html; charset=utf-8 |
| 返回 API 的 JSON 响应 | application/json |
| 返回一段 CSS 文件 | text/css |
| 返回一张图片(浏览器直接显示) | image/png 或 image/jpeg |
| 让浏览器下载文件而非直接显示 | application/octet-stream(通用二进制流) |
POST 表单提交(<form> 标签) |
application/x-www-form-urlencoded |
| POST JSON 数据(AJAX/fetch) | application/json |
上传文件(<input type="file">) |
multipart/form-data |
九、浏览器缓存机制------304 Not Modified 的原理

理解 HTTP 缓存能帮你写出秒开的页面,也能帮你排查"明明改了代码为什么浏览器还是显示旧的"这类问题。
缓存是计算机科学中解决性能问题的万能钥匙------从 CPU 的多级缓存到 Redis 的内存缓存,再到 CDN 的边缘节点,本质上都是"把经常访问的数据放在离使用者更近的地方"。HTTP 的缓存机制是这一思想的经典实现:浏览器第一次请求资源时拿到 Last-Modified 或 ETag,下次请求时带上 If-Modified-Since 或 If-None-Match,服务器比较后发现资源没变,返回一个零 Body 的 304 响应------几毫秒的往返时间相比几百毫秒的完整下载,用户体验天差地别。更激进的做法是 Cache-Control: max-age=31536000------告诉浏览器"这个资源一年内不会变,直接本地读取,别来问我"。配合前端构建工具给文件名加 hash(app.a3f2b1c.js),可以做到"只要内容变了文件名就变,只要文件名没变内容就不会变"的完美缓存策略。
9.1 基于时间的缓存:Last-Modified + If-Modified-Since
首次请求:
浏览器 → GET /style.css HTTP/1.1
服务器 → 200 OK + Last-Modified: Mon, 23 Jan 2023 13:27:56 GMT + Body(style.css)
第二次请求(浏览器缓存未过期,但需要验证):
浏览器 → GET /style.css HTTP/1.1 + If-Modified-Since: Mon, 23 Jan 2023 13:27:56 GMT
服务器检查文件修改时间:
如果未修改 → 304 Not Modified(无 Body,极小响应,浏览器直接用本地缓存)
如果已修改 → 200 OK + 新的 Last-Modified + 新的 Body304 响应体为空------它的作用只是告诉浏览器"你的缓存没问题,继续用"。这比重新发送整个文件快几十倍。
9.2 基于内容的缓存:ETag + If-None-Match
Last-Modified 的问题:文件内容改了但又改回去了(比如撤销编辑),修改时间变了但内容没变。ETag 用内容的哈希值代替时间:
ETag: "3f80f-1b6-5f4e2512a4100" ← 文件内容的 hash(通常是 MD5 或 SHA1)浏览器下次请求时带 If-None-Match: "3f80f-1b6-5f4e2512a4100",服务器比对 hash------相同返回 304,不同返回 200 + 新内容 + 新 ETag。
9.3 Cache-Control:让浏览器跳过"验证"步骤
对于绝对不会变的资源(如带版本号的静态文件 app.v1.2.3.js),可以直接告诉浏览器"直接缓存,不用每次验证":
http
Cache-Control: max-age=31536000 ← 缓存一年(31536000 秒)这样浏览器在一年之内都不会为这个资源发送 HTTP 请求------页面加载秒出。
总结
HTTP 协议的核心就是表格式的东西------记住这个模板你就永远会手写 HTTP:
| 卡片 | 格式 | 示例 |
|---|---|---|
| 请求行 | 方法 URL 版本 |
GET /index.html HTTP/1.1 |
| 状态行 | 版本 状态码 描述 |
HTTP/1.1 200 OK |
| Header | 键: 值\r\n |
Content-Type: text/html |
| 空行 | \r\n(单独一行) |
分隔 Header 和 Body |
| Body | 任意内容 | HTML / JSON / 图片二进制 |
无论多复杂的 Web 应用------无论是 Google 的搜索结果页还是你的博客后台------底层 HTTP 通信都是这五个元素的排列组合。掌握了它们,你就拿到了理解整个 Web 世界的钥匙。

最后,让我们跳出具体的技术细节,从更高的视角审视一下 HTTP。HTTP 协议诞生于 1991 年------那时互联网还是学术界的小圈子,网页只有纯文本。三十多年过去,它承载了视频流、实时通信、文件上传、API 调用、微服务间通信,甚至物联网设备的数据上报。一个 1991 年设计的协议如何能支撑 2026 年的互联网?答案在于 HTTP 的版本兼容性策略 :HTTP/1.1 服务器可以理解 HTTP/1.0 的请求(忽略不认识的 Header),HTTP/2 服务器可以通过 ALPN 协商降级到 HTTP/1.1,HTTP/3 可以通过 HTTP Alternative Services 告诉浏览器"下次用 QUIC 连我"。每一个新版本都不是"替换"旧版本,而是"扩展"------老旧客户端可以继续用 HTTP/1.0 访问同一个服务器,新客户端自动升级到 HTTP/2 或 HTTP/3。这种渐进式升级策略是所有长寿协议(HTTP、TCP/IP、TLS)的共同特征:不要设计一个完美的协议然后强迫所有人升级,而是设计一个能容忍不完美的协议并允许渐进式进化。
动手试试
- 改造 HTTP 服务器,支持 301 重定向------访问
/old时自动跳转到/new。观察浏览器地址栏的变化。- 给服务器增加 Cookie 支持------第一次访问时
Set-Cookie: visit_count=1,后续每次请求从请求 Header 的Cookie中读取出visit_count并递增返回(提示:用std::map维护 IP→访问次数的映射,sprintf构造Set-Cookie头)。- 用
nc(netcat)手工构造一条 HTTP 请求发给你的服务器:printf "GET / HTTP/1.0\r\n\r\n" | nc 127.0.0.1 9090,观察返回的原始 HTTP 响应。- 给你的服务器增加 304 缓存支持------读取文件的修改时间(
stat系统调用),如果浏览器发来的If-Modified-Since时间晚于或等于文件修改时间,返回 304 Not Modified 而不发送 Body。
预告: 我们将进入 TCP 传输控制协议的可靠传输机制------三次握手四次挥手的状态机、确认应答、超时重传、滑动窗口与拥塞控制。理解 TCP 才能理解 HTTP 为什么有时候快有时候慢。
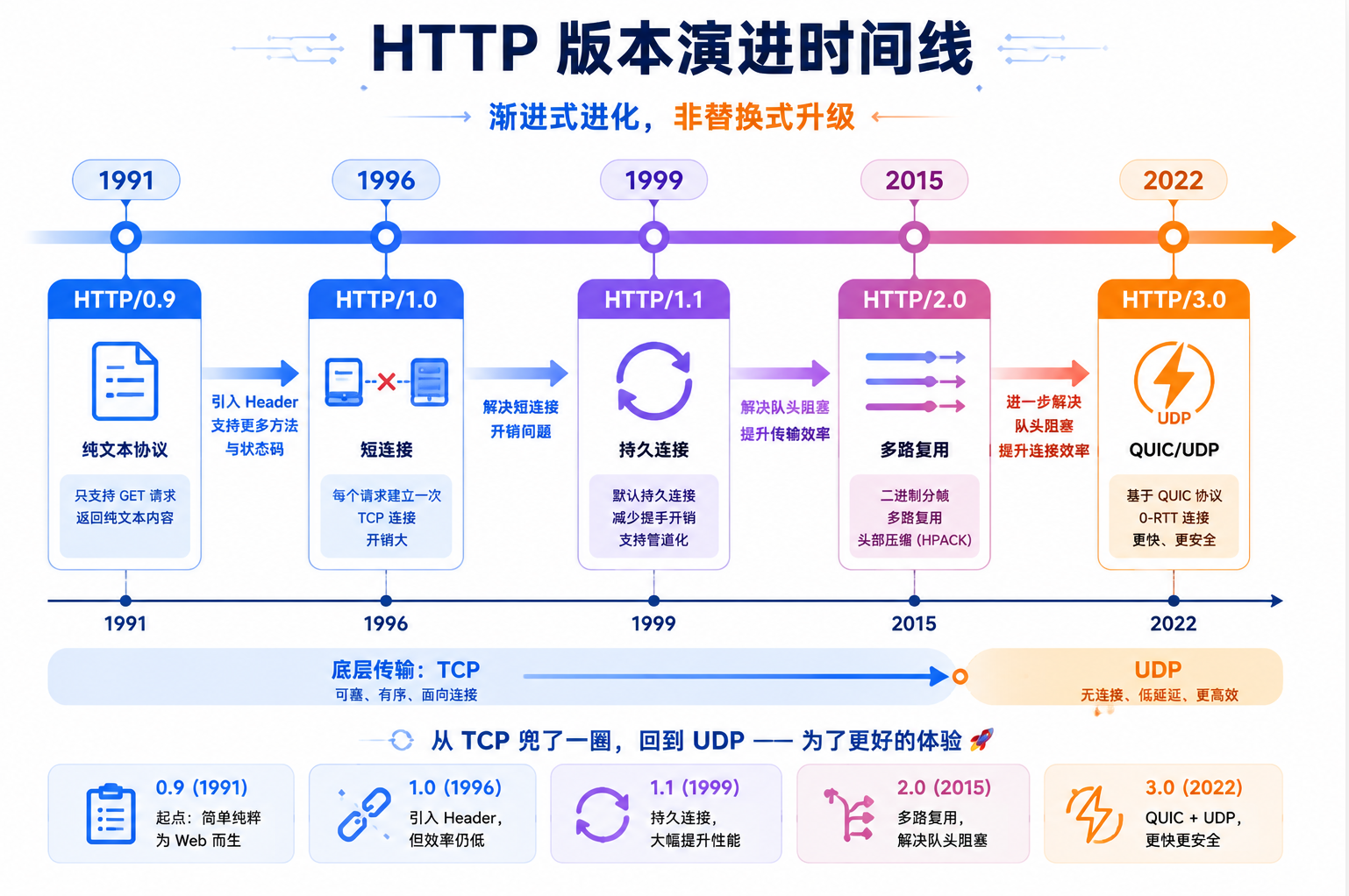
附录:HTTP 版本演进简史
理解 HTTP 的演进历史,能帮你理解为什么今天的 HTTP 这么复杂。
| 版本 | 年份 | 核心特性 | 致命局限 | 底层传输 |
|---|---|---|---|---|
| 0.9 | 1991 | 仅 GET,仅 HTML,无 Header | 只能请求一个 HTML 文件 | TCP |
| 1.0 | 1996 | POST/HEAD,Header,状态码,缓存 | 每个请求一个新 TCP 连接 | TCP |
| 1.1 | 1999 | 持久连接,管道化,Host 头(虚拟主机),分块传输编码 | 队头阻塞------一个请求卡住,后续全部排队 | TCP |
| 2.0 | 2015 | 多路复用,二进制帧,头部压缩(HPACK),服务器推送 | TCP 层的丢包导致所有流阻塞 | TCP |
| 3.0 | 2022 | 基于 QUIC(UDP),0-RTT 连接建立,消除 TCP 队头阻塞,连接迁移(WiFi→4G 不断开) | 部署复杂度高(UDP 被部分网络封堵,CPU 开销比 TCP 高) | UDP(QUIC) |
HTTP/3.0 从 TCP 转向 UDP + QUIC------这正是 23 篇 UDP 协议详解中所说的"在 UDP 之上自建可靠性"。三十年时间,底层传输从 TCP 兜了一圈回到 UDP,但上层的可靠性被 QUIC 重新实现了一遍------只是这次比 TCP 做得更好。
HTTP 版本的演进史对我们还有一个重要的启示:协议设计是一场没有终点的权衡。 HTTP/1.0 的短连接简单但效率低;HTTP/1.1 的 keep-alive 提高了效率但引入了队头阻塞;HTTP/2 的多路复用解决了队头阻塞却受限于 TCP 层的丢包重传;HTTP/3 转向 QUIC(基于 UDP)彻底解决了 TCP 队头阻塞但又面临 UDP 被部分网络封堵的部署难题。每一步都是"用一个新问题换一个老问题"。知道每个版本解决了什么、牺牲了什么,比记住每个版本的名字重要得多------因为你将来参与设计的任何技术方案,本质上也是在做同样的权衡。
尾声
本章讲解就到此结束了,若有纰漏或不足之处欢迎大家在评论区留言或者私信,同时也欢迎各位一起探讨学习。感谢您的观看!