video2text Windows 安装部署教程
找了下本地视频转文字的工具,都是各种限制,于是自己写了个自用的工具。如果你觉得有用,欢迎在 GitHub 上给个 Star!
- 完全免费,无时长限制,可批量转写视频和音频
- 基于 Whisper large-v3,高准确率
- 集成 Ollama / NVIDIA 大模型,自动生成摘要
- 图形界面 + 命令行,Windows 绿色版已打包
- 批量转写 + 总结,输出 TXT/SRT/VTT/JSON
- 完全开源:video2text GitHub 仓库
一、界面
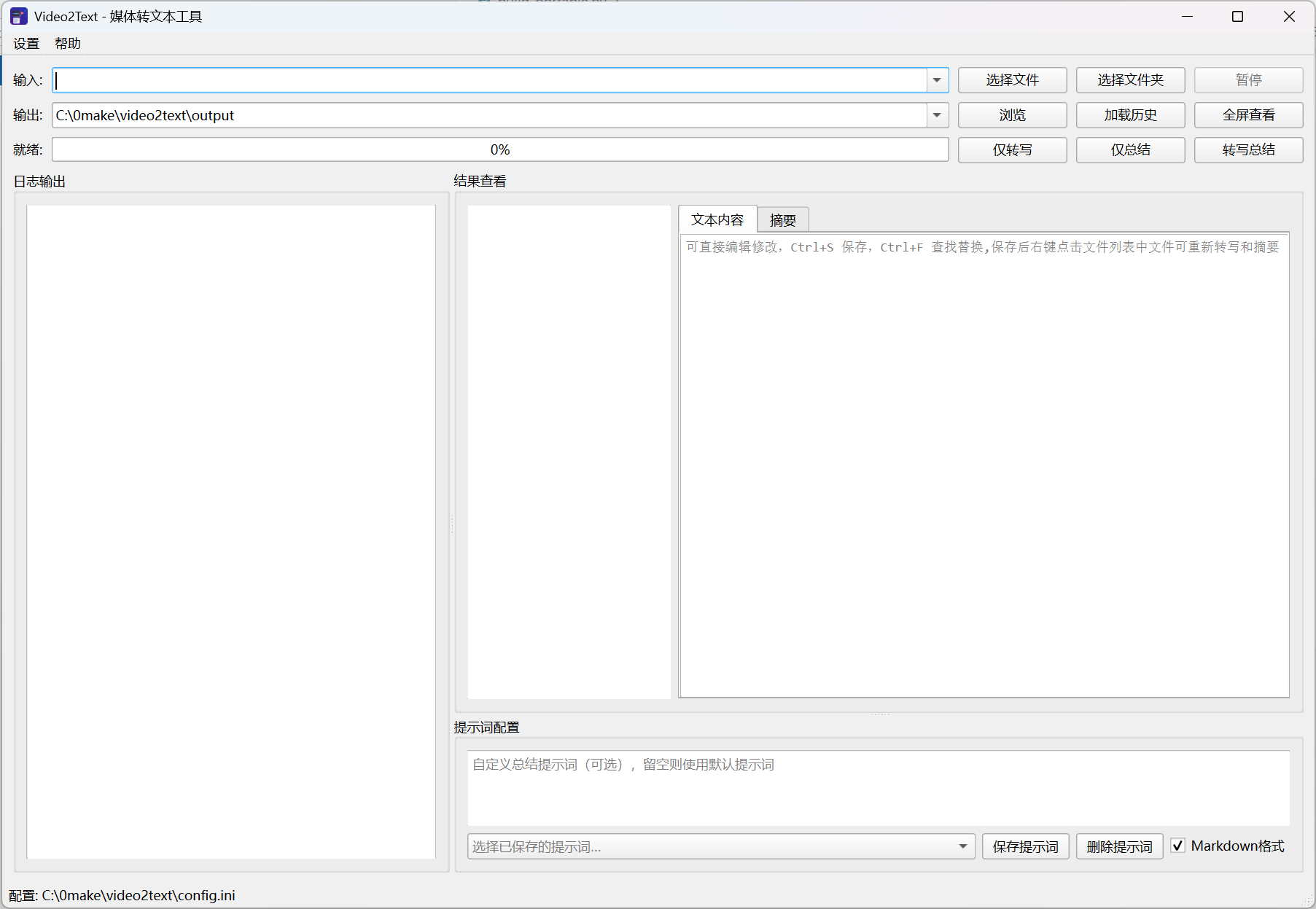
主界面GUI
- 仅转写:Whisper提取语音,输出原文、字幕,不生成AI总结
- 仅总结:读取已有文稿,本地大模型生成摘要
- 转写总结:一键执行语音转写+AI摘要整套流程
- 左侧日志区:实时打印加载、报错、显存、任务耗时等运行日志
- 右上结果区
- 文本内容:原文编辑,
Ctrl+S保存、Ctrl+F查找,右键重转文件 - 摘要页:AI产出文案,支持手动修改
- 文本内容:原文编辑,
- 右下提示词区
- 自定义摘要提示词,可保存/删除模板;勾选Markdown自动格式化导出
工作流程简介
video2text 的处理流程分为两个阶段:
- 语音转写:输入视频/音频 → Whisper large-v3 模型 → 输出 TXT/SRT/VTT/JSON 文本
- 智能总结:转写文本 → Ollama 本地模型 / NVIDIA 在线模型 → 输出 Markdown 格式摘要
两个阶段可独立运行,也可以一键完成。
二、安装前的准备:系统要求与组件
在安装 video2text 这一本地视频转文字工具前,请先确认你的电脑满足以下条件。
2.1 最低配置与推荐配置
| 项目 | 最低要求 | 推荐配置 |
|---|---|---|
| 操作系统 | Windows 10 64位 | Windows 11 64位 |
| 磁盘空间 | 20 GB 可用空间 | 30 GB 以上(含模型文件) |
| 内存(RAM) | 8 GB | 16 GB 及以上 |
| 显卡 | 无(CPU模式可用但很慢) | NVIDIA 显卡(6GB显存以上) + CUDA |
注意:AMD 显卡暂不支持 GPU 加速。CPU 模式可以运行会比较慢。
显卡信息参考(nvidia-smi 输出示例):
以下为 nvidia-smi 输出示例,请以你电脑上的实际输出为准
- Driver Version: 572.83:NVIDIA 显卡驱动版本,video2text 依赖驱动提供的 CUDA 运行时。驱动版本过低可能导致 GPU 无法被识别。
- CUDA Version: 12.8:此驱动支持的最高 CUDA 版本。Whisper 和各类深度学习模型在 CUDA 12.x 下均可正常工作。
| NVIDIA-SMI 572.83 | Driver Version: 572.83 | CUDA Version: 12.8 |
|---|---|---|
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| MIG M. | ||
| =================================== | ================================ | ======================== |
| 0 NVIDIA GeForce RTX 4060 WDDM | 00000000:01:00.0 Off | N/A |
| N/A 41C P5 5W / 140W | 365MiB / 8188MiB | 0% Default |
| N/A |
如果驱动版本和 CUDA 版本太低也可能无法使用 GPU 加速。建议先在命令行执行
nvidia-smi确认显卡状态。
2.2 需要下载哪些文件
video2text 本地视频转文字工具的安装包体积较大,已上传至 123 云盘,内含以下组件:
| 组件 | 大小 | 是否下载 |
|---|---|---|
| video2text 程序包 | ~3 GB | 必须 |
large-v3 语音转文字模型 |
~3 GB | 可选,建议下载,自己有其它模型也行 |
Ollama 安装包和本地模型(qwen2.5:7b) |
~6 GB | 可选,看总结用不用 Ollama |
请使用支持保留目录结构的解压工具(如 7-Zip 或 Bandizip)解压压缩包,确保文件夹结构完整。
下载地址:
text
合并下载:
[video2text] 包括video2text程序包,语音转文字模型,ollama安装包和本地模型qwen2.5:7b
链接:https://1840674647.share.123pan.cn/123pan/7CfNTd-SE7j3?pwd=viWa#
提取码:viWa
分开下载:
[video2text_portable_windows_*.zip] 程序包
链接:https://1840674647.share.123pan.cn/123pan/7CfNTd-4Ovdh?pwd=1234#
提取码:1234
[large-v3.zip] 语音转文字模型
链接:https://1840674647.share.123pan.cn/123pan/7CfNTd-nk8vh?pwd=1234#
提取码:1234
[ollama] 安装包和本地模型
链接:https://1840674647.share.123pan.cn/123pan/7CfNTd-DR8dh?pwd=1234#
提取码:1234三、详细安装步骤
以下按顺序介绍 video2text 本地视频转文字工具的完整安装流程。
3.1 部署 video2text 本地视频转文字程序
第一步:解压程序包
将 video2text_portable_windows_*.zip 解压到你希望存放程序的位置,例如 D:\video2text。该程序为绿色版,无需安装,不会写入注册表,解压即用。解压后目录结构如下:
text
D:\video2text\
├── video2text.exe ← 主程序
├── video2text.bat ← 启动脚本(自动设置工作目录)
├── config.ini ← 配置文件
├── .env ← 环境变量配置(存放 API Key,需手动创建)
├── docs ← 文档
├── assets\ ← 图标资源
├── ffmpeg\ ← 内置 FFmpeg
├── models\ ← 模型目录(需要放入模型文件)
├── output\ ← 输出目录(可选)
├── logs\ ← 日志目录
└── README.md ← 说明文档第二步:放入语音识别模型
将下载的 large-v3.zip 解压到程序目录下的 models 文件夹中。确保解压后模型文件位于 models\large-v3\ 子目录下,且包含以下核心文件:
text
D:\video2text\models\
└── large-v3\
├── config.json
├── model.bin ← 核心模型文件(约 2.9 GB)
├── preprocessor_config.json
├── tokenizer.json
└── vocabulary.json放好模型后就可以使用视频转文本功能了。
需要使用其它模型的可以到 Hugging Face 上找,按照上面目录结构放好,再到配置文件中设置。
3.2 总结模型安装
video2text 支持两种总结服务:NVIDIA 在线模型和本地 Ollama 模型,按需选择其一即可。选择可以到软件设置>编辑配置>总结>单选框选择
3.2.1 NVIDIA 在线(使用在线 NVIDIA 模型总结)
需要先在 NVIDIA Build 注册账号并创建 API Key(目前大部分模型免费使用)。获取 Key 后在程序目录下新建一个名为 .env 的文本文件(注意文件名以点开头,无扩展名)。用记事本打开,按需添加以下内容:
ini
# NVIDIA API Key(使用在线 NVIDIA 模型总结时需要)
NVIDIA_API_KEY=nvapi-你的API密钥保存文件。程序启动时会自动读取该文件中的环境变量。API Key 也可以通过系统环境变量设置,效果相同(系统环境变量优先级高于 .env 文件)。NVIDIA 提供有很多免费的模型,如果网络访问有问题需要自行解决。
3.2.2 安装 Ollama(使用本地模型总结)
Ollama 是一个本地大语言模型运行框架,video2text 使用它来生成文本摘要。
本文以
qwen2.5:7b-instruct-q4_K_M为例进行安装演示,该模型实际总结效果一般,推荐优先使用 NVIDIA 在线模型。
第一步:运行安装程序
双击 OllamaSetup.exe,按提示完成安装。安装过程无需手动配置,会自动完成。
第二步:解压预下载模型
找到下载好的 models.zip 文件,将其解压到 C:\Users\你的用户名\.ollama 目录下。确保解压后的目录结构如下:
text
C:\Users\你的用户名\.ollama\
└── models\
└── blobs\ ← 模型数据文件
└── manifests\ ← 模型清单文件第三步:启动 Ollama 服务
方式一:在开始菜单找到 Ollama 图标并启动。
方式二:按 Win + R 打开运行窗口,输入 cmd,执行 ollama serve。
启动后系统托盘会出现 Ollama 图标,表示服务已就绪。
如果需要使用 Ollama 在线云服务模型(如 deepseek-v3.1:671b-cloud、gpt-oss:120b-cloud),需注册账号并在 .env 文件中配置 OLLAMA_API_KEY:
ini
# Ollama API Key(使用带认证的 Ollama 服务时可选配置)
OLLAMA_API_KEY=你的API密钥3.3 验证安装是否成功
完成以上所有步骤后,按顺序验证各组件是否正常工作:
-
启动 video2text:
- 双击
video2text.exe或video2text.bat启动程序。 - 程序主窗口应正常显示,标题为「Video2Text - 视频转文本工具」。
- 底部状态栏会显示当前使用的配置文件路径。
- 双击
-
快速测试(可选):
- 选择一个短小的视频文件(1-2 分钟即可)。
- 点击「仅转写」按钮,观察日志面板是否有输出、进度条是否推进。
- 转写完成后,右侧面板应显示转写文本。
- 点击「仅总结」按钮,确认能正常生成摘要。
四、使用教程
本节演示如何使用 video2text 本地视频转文字工具完成第一次转写和总结。
4.1 启动界面说明
双击 video2text.exe 即可打开图形界面(GUI)。也可以双击 video2text.bat 启动,它会自动将工作目录切换到程序所在位置。
程序启动后显示主窗口(默认 1200x800),从上到下分为以下区域:
| 区域 | 说明 |
|---|---|
| 菜单栏 | 设置(编辑配置、收藏目录)、帮助(捐赠支持、关于) |
| 输入行 | 视频文件/文件夹选择、常用目录下拉框、全屏查看按钮 |
| 输出行 | 输出目录设置、浏览、加载历史、暂停按钮 |
| 进度行 | 进度条、进度标签、三个操作按钮(仅转写/仅总结/转写总结) |
| 左侧面板 | 日志输出(实时显示运行日志,Consolas 等宽字体) |
| 右侧面板上部 | 结果查看(文件列表 + 转写文本/摘要标签页 + 查找替换栏) |
| 右侧面板下部 | 提示词配置(自定义总结提示词及模板管理) |
| 状态栏 | 显示配置路径、操作反馈信息 |
4.2 选择一个视频,点击"转写总结"
选择视频文件
- 选择文件 :点击「选择文件」按钮,在弹出的对话框中选择一个或多个视频文件(按住
Ctrl或Shift多选)。选中多个文件后,输入框显示「已选择 N 个文件」。 - 选择文件夹:点击「选择文件夹」按钮,选择一个文件夹后程序会自动递归扫描其中所有支持格式的视频,并弹出选择对话框。对话框显示找到的所有视频文件,每个文件前有复选框,默认全部勾选。可通过「全选」/「取消全选」按钮批量操作,勾选需要处理的文件后点击「确定」。
支持的视频格式 (共 17 种):
.mp4 .avi .mov .mkv .flv .wmv .webm .ts .mts .m4v .3gp .mpeg .mpg .vob .ogv .rm .rmvb
常用目录收藏
输入框和输出框均为可编辑下拉框,会显示已收藏的常用目录。通过菜单「设置 → 收藏」可以:
- 收藏当前输入/输出文件夹为常用目录
- 右键点击下拉列表中的目录条目可删除单个收藏
- 通过菜单可批量移除所有输入或输出目录收藏
设置输出目录
点击「浏览」按钮选择转写结果的保存位置。默认输出目录为程序所在目录下的 output 文件夹。如果是通过「选择文件夹」导入视频,程序会自动在 output 下创建以源文件夹命名的子目录。
执行转写总结
界面提供三种操作模式:
| 按钮 | 功能 | 说明 |
|---|---|---|
| 仅转写 | 语音 → 文字 | 使用 faster-whisper 模型将视频中的语音转为文字,结果保存到输出目录 |
| 仅总结 | 文字 → 摘要 | 对当前「文本内容」标签页中的文字进行 AI 摘要(需要 Ollama 或 NVIDIA API)。也支持对直接粘贴到文本框中的独立文字进行总结 |
| 转写总结 | 语音 → 文字 → 摘要 | 先转写,完成后自动对每段转写文本进行摘要,一步完成全流程 |
操作过程中的说明:
- 进度条会实时更新,显示「已完成数/总数」
- 日志面板会实时输出处理信息,包括每段视频的转写进度、耗时等
- 转写过程中可点击「暂停」按钮暂停,当前音频分段完成后再暂停;暂停后按钮变为「继续」,点击继续恢复处理
- 任务完成或失败时,日志面板会显示统计信息(成功/失败数量)
- 处理期间按钮状态会自动切换:转写/总结/文件选择按钮禁用,暂停按钮启用
4.3 查看结果(编辑、查找替换、全屏查看器、书签)
文件列表
操作完成后,右侧面板的文件列表会显示所有已处理的视频文件名。点击文件名可切换查看对应的转写文本和摘要。
转写文本(「文本内容」标签页)
- 显示该视频的完整转写文本(Consolas 等宽字体)
- 文本可编辑:可以直接修改转写结果中的错别字或格式问题
- Ctrl+S 保存 :编辑后按
Ctrl+S可将修改保存到文件 - Ctrl+F 查找替换 :按
Ctrl+F打开查找替换栏,支持关键词搜索(当前匹配项高亮为橙色,其余高亮为黄色)和替换/全部替换操作 - 编辑后的文本可通过右键菜单「重新总结」按钮重新生成摘要
摘要(「摘要」标签页)
- 显示 AI 生成的摘要内容
- 文本可编辑:摘要内容支持直接编辑修改
- Ctrl+S 保存 :编辑后按
Ctrl+S可将修改保存到文件 - Ctrl+F 查找替换:同样支持查找替换功能
右键菜单
在文件列表中右键点击某个文件,可选择:
- 重新转写:对选中的视频重新执行转写(需要原始视频文件仍在原路径)
- 重新总结:对选中的视频重新执行总结(需要已存在转写文件)。如果在「文本内容」标签页中编辑过文本,会使用编辑后的文本进行总结
全屏结果查看器
点击主界面的「全屏查看」按钮,可打开独立的结果查看窗口,提供更舒适的浏览体验。窗口默认 1400x900,支持独立的文件浏览、搜索、书签等功能。
全屏查看器详细功能(点击展开)
工具栏:
| 控件 | 说明 |
|---|---|
| 字体大小 | 数值调节框,也可用 Ctrl++/Ctrl+- 调节(范围 8-32pt,默认 14pt),Ctrl+0 重置为默认 |
| 主题 | 下拉框切换「浅色」/「深色」主题,选择会自动保存 |
| 搜索 | Ctrl+F 打开/关闭搜索栏 |
| 全屏 | 按 F11 切换全屏,Esc 退出全屏 |
| 添加书签 | Ctrl+B 在当前位置添加书签 |
| 书签面板 | Ctrl+Shift+B 显示/隐藏书签侧栏 |
| 文件夹模式 | Ctrl+D 切换文件夹模式(树形视图) |
文件过滤:
左侧面板顶部有文件过滤输入框,输入关键词可实时过滤文件列表,便于在大量结果中快速定位。
搜索功能:
- 按
Ctrl+F打开搜索栏,输入关键词后自动搜索(300ms 防抖,避免大文件卡顿) - 按
F3或Ctrl+G跳转到下一个匹配项 - 按
Shift+F3或Ctrl+Shift+G跳转到上一个匹配项 - 按
Enter跳转到下一个匹配项 - 按
Esc关闭搜索栏(全屏状态下按两次Esc退出全屏) - 搜索栏右侧显示匹配计数(如「3/15」)
- 当前匹配项高亮为橙色,其他匹配项高亮为黄色(深色主题下自动适配配色)
书签系统:
- 在转写文本或摘要中定位到需要标记的位置,按
Ctrl+B添加书签 - 书签自动记录:文件名、内容类型(转写/摘要)、光标位置、上下文预览(前后各 30-70 字符)、时间戳
- 重复位置检测:同一文件同一位置不会重复添加书签
- 按
Ctrl+Shift+B打开书签面板,包含以下功能:- 书签计数显示(如「共 10 个书签」或「显示 3 / 共 10 个书签」)
- 关键词过滤:输入框实时过滤书签(搜索范围包括文件名、路径、类型、内容、备注)
- 日期过滤:下拉框按添加日期筛选
- 排序方式:按添加时间 / 按文件名 / 按内容类型
- 双击书签条目跳转到对应文件和位置
- 右键菜单:跳转到位置、复制书签信息、编辑备注、全选、反选、删除选中
- 底部按钮:删除、批量删除、清空
- 失效检测:自动检测已删除文件的书签,提示清理
- 跨目录导航:如果书签对应的文件不在当前目录中,会提示切换目录
- 书签数据跨会话自动保存(存储在
bookmarks.json)
Markdown 渲染:
摘要标签页使用 Markdown 渲染显示,支持:标题、表格、代码块(带语法高亮)、引用块、有序/无序列表(含嵌套)、链接、加粗/斜体等格式。自动过滤不安全的 HTML 标签(<script>、<style>、<iframe>)。
文件夹模式:
- 按
Ctrl+D切换到文件夹模式,左侧文件列表变为树形结构 - 按子目录分层展示,目录节点加粗并显示子视频数量(如
subfolder (3)) - 子文件夹默认折叠,点击展开
窗口状态持久化:
窗口大小、工具栏位置、分栏比例等状态会自动保存到 result_viewer.ini,下次打开时自动恢复。
五、进阶技巧:自定义提示词与命令行使用
5.1 自定义提示词模板
主界面底部的「提示词配置」区域用于自定义总结时使用的提示词。
使用方法:
- 在文本框中输入自定义提示词(如「请用中文总结以下内容的要点,重点关注技术细节」)。
- 如果留空,将使用默认提示词:「你是一个专业的文本总结助手,擅长提取关键信息并生成简洁准确的总结。」
- 点击「仅总结」或「转写总结」时,会将提示词与转写文本组合后发送给 AI 模型。
模板管理:
- 保存模板:输入提示词后,点击「保存提示词」按钮,在弹出的对话框中输入模板名称即可保存。
- 加载模板:从下拉框中选择已保存的模板名称,提示词会自动填充到文本框。
- 删除模板:选择要删除的模板,点击「删除提示词」并确认。
- 程序会自动记住上次使用的模板,下次启动时自动恢复。
- 模板数据存储在
prompts.json文件中,支持原子写入防止数据损坏。
提示词构建流程: 程序发送给 AI 模型的完整提示由三部分组成:自定义提示词(或默认系统提示)+ Markdown 格式指令 + 转写文本。Markdown 格式指令要求模型以「要点标题 + 内容」的结构输出,确保摘要格式清晰统一。
5.2 配置文件详解(config.ini)
程序目录下的 config.ini 可直接用文本编辑器修改,完整配置如下:
ini
[app]
log_level = INFO # 日志级别: DEBUG/INFO/WARNING/ERROR
[transcription]
model_path = large-v3 # 转写模型名称或路径
device = cuda # 设备: auto/cpu/cuda/mps
language = zh # 语言: auto/zh/en/ja/...
beam_size = 5 # beam search 大小
best_of = 5 # 候选数量
temperature = 0.0 # 温度参数
compute_type = float16 # 计算类型: float16/int8/float32/int8_float16
num_workers = 1 # 工作线程数
vad_filter = True # VAD 过滤
condition_on_previous_text = True # 是否基于前文进行转写(提高连贯性)
word_timestamps = False # 是否生成单词级时间戳
[summarization]
provider = nvidia # 服务商: ollama/nvidia/zhipu
ollama_url = http://127.0.0.1:11434 # Ollama 服务地址
model_name = qwen2.5:7b-instruct-q4_K_M # 模型名称
max_length = 10000 # 最大生成长度
temperature = 0.7 # 温度参数
timeout = 600 # 请求超时时间(秒)
custom_prompt = # 自定义提示词
nvidia_api_url = https://integrate.api.nvidia.com/v1/chat/completions
nvidia_model = openai/gpt-oss-120b
nvidia_max_tokens = 100000
nvidia_temperature = 1.0
nvidia_top_p = 1.0
nvidia_frequency_penalty = 0.0
nvidia_presence_penalty = 0.0
nvidia_mode = multi # NVIDIA 模式: single(单线程)/multi(多线程并发)
nvidia_thread_count = 5 # 多线程模式下的并发线程数
nvidia_stream = false # 是否启用流式输出(仅单线程模式有效)
zhipu_model = glm-4.7 # 智谱模型名称
zhipu_max_tokens = 65536 # 智谱最大生成长度
zhipu_temperature = 1.0 # 智谱温度参数
zhipu_mode = single # 智谱模式: single(单线程)/multi(多线程并发)
zhipu_stream = true # 智谱是否启用流式输出(仅单线程模式有效)
zhipu_thread_count = 5 # 智谱多线程模式下的并发线程数
[preprocessing]
audio_sample_rate = 16000 # 音频采样率
audio_channels = 1 # 音频声道数
max_chunk_duration = 300 # 最大切片时长(秒)
supported_video_formats = .mp4,.avi,.mov,.mkv,.flv,.wmv,.webm,.ts,.mts,.m4v,.3gp,.mpeg,.mpg,.vob,.ogv,.rm,.rmvb
supported_audio_formats = .mp3,.wav,.flac,.aac,.ogg,.m4a,.wma # 支持的音频格式
[output]
output_dir = output # 默认输出目录
transcript_format = txt # 转写格式(可逗号分隔: txt,srt,vtt,json)
summary_format = md # 摘要格式: txt/md
mirror_enabled = False # 是否启用镜像输出(同时保存到源文件目录)
mirror_depth = 1 # 镜像输出时保留的目录层级数
[network]
proxy = # 代理地址(用于 HuggingFace 模型下载)
[paths]
models_dir = models # 模型目录
logs_dir = logs # 日志目录
video_dir = video # 视频目录
[text_processing]
max_gap = 2.0 # 文本合并的最大间隔(秒)
min_length = 50 # 最小文本长度
filler_words = 嗯,啊,呃,嗯嗯,啊啊 # 需要过滤的填充词也可通过环境变量 VIDEO2TEXT_CONFIG 指定自定义配置文件路径。
5.3 命令行使用(CLI)
除图形界面外,也可在命令行中直接使用。在程序所在目录打开终端,使用 video2text.exe 加子命令。不带参数运行时自动启动图形界面。
转写命令:
powershell
.\video2text.exe transcribe <视频文件路径> [选项]| 选项 | 缩写 | 说明 | 默认值 |
|---|---|---|---|
--output-dir |
-o |
输出目录 | output |
--verbose |
-v |
启用 DEBUG 级别详细日志 | 关闭 |
示例:
powershell
.\video2text.exe transcribe "D:\videos\lecture.mp4" -o output总结命令:
powershell
.\video2text.exe summarize <转写文本文件路径> [选项]| 选项 | 缩写 | 说明 | 默认值 |
|---|---|---|---|
--output-dir |
-o |
输出目录 | output |
--verbose |
-v |
启用 DEBUG 级别详细日志 | 关闭 |
示例:
powershell
.\video2text.exe summarize output\lecture.txt -o output完整流程命令:
powershell
.\video2text.exe run-pipeline <视频文件路径> [选项]| 选项 | 缩写 | 说明 | 默认值 |
|---|---|---|---|
--output-dir |
-o |
输出目录 | output |
--verbose |
-v |
启用 DEBUG 级别详细日志 | 关闭 |
示例:
powershell
.\video2text.exe run-pipeline "D:\videos\meeting.mp4" -o output所有转写参数(模型、语言、设备、温度等)和总结参数(模型、温度、最大长度等)均通过程序目录下的
config.ini配置文件设置,详见 [4.2 配置文件详解](#4.2 配置文件详解)。命令行不再支持直接指定这些参数。
其他命令:
powershell
# 查看版本
.\video2text.exe version
# 查看所有命令及用法
.\video2text.exe --help
.\video2text.exe help5.4 输出文件说明
文件命名:
| 类型 | 文件名格式 | 示例 |
|---|---|---|
| 转写文件 | {视频名}.{格式} |
video1.txt、video1.srt |
| 摘要文件 | {视频名}_summary.{格式} |
video1_summary.md |
转写格式:
| 格式 | 说明 |
|---|---|
txt |
可读文本,每行 [HH:MM:SS - HH:MM:SS] 文本,时间戳格式为时:分:秒 |
srt |
SRT 字幕格式,标准序号+时间轴+文本块,可用于视频播放器加载字幕 |
vtt |
WebVTT 字幕格式,以 WEBVTT 头部开始,适用于网页播放器 |
json |
JSON 数组,每项包含 start(秒)、end(秒)、text、confidence(置信度 0-100)、language(语言代码)字段 |
可在
config.ini中设置transcript_format = txt,srt,json同时输出多种格式,用逗号分隔。
摘要格式:
| 格式 | 说明 |
|---|---|
txt |
纯文本格式 |
md |
Markdown 格式(默认),支持标题、列表、加粗、表格、代码块等 |
输出校验: 所有输出文件在写入后会自动校验:SRT 检查序号连续性和时间戳格式、VTT 检查头部和时间戳、JSON 检查必需字段、TXT 检查非空、所有格式检查 UTF-8 编码有效性。
5.5 高级功能
断点续传: 对于长视频(超过 300 秒,可通过 config.ini 的 max_chunk_duration 调整),程序会自动将音频切片分段转写。每完成一个切片会保存检查点到 <输出目录>/.checkpoint/ 目录,如果任务中断(如程序崩溃、手动关闭),下次重新运行相同视频时会自动跳过已完成的切片,从中断处继续。检查点文件使用原子写入(临时文件 + 替换)防止损坏,任务全部完成后自动清理检查点。
暂停/继续: 转写过程中可随时点击「暂停」按钮,当前音频分段完成后再暂停,暂停后按钮变为「继续」。暂停期间不会丢失已完成的进度。
模型自动下载: 首次运行时如果 models/large-v3/ 目录下没有模型文件(或文件不完整),程序会自动从 HuggingFace 下载(约 3GB)。下载支持代理设置(在 config.ini 的 [network] proxy 中配置)、失败自动重试(最多 3 次,指数退避)、下载进度显示在日志面板。
GPU 显存管理: 转写模型加载到 GPU 后会缓存复用(按模型路径+设备+计算类型+线程数作为缓存键),避免重复加载。关闭程序时会自动卸载模型并释放 GPU 显存。如果 GPU 显存不足(CUDA OOM),程序会自动降级:先在同一设备上尝试不同计算类型(float16 → int8 → float32 → int8_float16),如果仍然失败则回退到 CPU 模式(cpu + int8 → cpu + float32)。每次降级前会清理 GPU 缓存。
NVIDIA 多线程总结: 当 nvidia_mode = multi 时,程序使用线程池并发处理多个视频的总结请求(线程数由 nvidia_thread_count 控制),并内置速率限制器(请求间隔最少 1.5 秒)避免触发 API 限流。多线程模式下强制使用非流式输出。
日志系统: 程序运行日志保存在 logs/ 目录下:
| 日志文件 | 级别 | 说明 |
|---|---|---|
app.log |
INFO | 常规运行日志,5MB 轮转,保留 7 份 |
debug.log |
DEBUG | 详细调试日志,10MB 轮转,保留 3 份 |
error.log |
ERROR | 错误日志,10MB 轮转,保留 30 份 |
失败的任务会额外记录到 logs/fail_log.log,包含时间戳、操作模式、视频名称和错误信息。程序崩溃时会写入 logs/crash.log,未捕获的线程异常会写入 logs/thread_error.log。