claude code在接入第三方大模型api时,越用越慢,token耗费剧增的根本原因就是claude code干了一件很狗的事情,它在cch请求头加上了随机数,导致第三方大模型api无法命中缓存,而anthropic自己的api则是直接忽略这个随机的cch请求头。
** 上下文缓存命中的关键是"共享的前缀"相同,而不是整个请求内容(尤其是用户的问题)相同。
这正是它能在真实应用中省钱的精髓所在:固化不变的部分,复用这部分计算,动态变化的部分每次重新计算。
下面用一个具体的例子来说明:
核心机制:前缀匹配,而非全文匹配
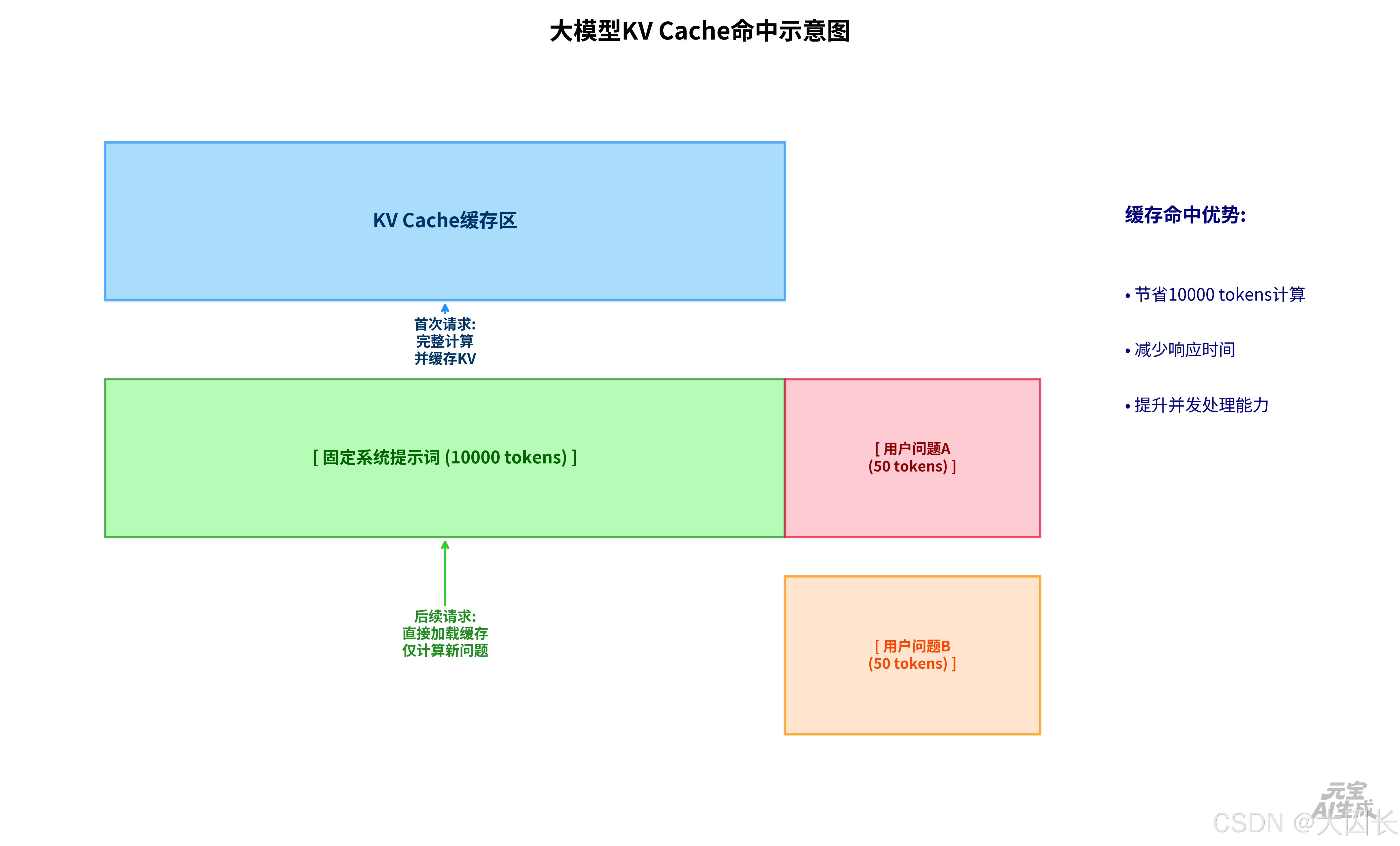
假设你搭建了一个"法律AI助手",它的请求结构是这样的:
[ 固定系统提示词 (10000 tokens) ] + [ 用户的具体问题 (50 tokens) ]- 固定部分 (缓存目标) :你精心编写的法律角色设定、法规条文、回答格式要求等,这部分对所有用户都一模一样。
- 动态部分 (非缓存部分) :用户问的"合同违约金上限是多少?"或"劳动仲裁流程是什么?",每个问题都不同。
开启缓存后的工作流程:
-
首次请求:
- 用户A问:"合同违约金上限是多少?"
- 整个请求变为:巨大且固定的系统提示 + "合同违约金上限是多少?"
- 服务端发现此前缀无缓存,就完整计算了整个前缀,并生成其KV Cache缓存下来,然后继续处理用户问题。
-
后续请求 (缓存命中):
- 用户B问:"劳动仲裁流程是什么?"
- 请求变为:**完全相同**的巨大固定系统提示 + "劳动仲裁流程是什么?"
- 服务端检查发现,前缀"巨大且固定的系统提示"与缓存完全匹配。
- 关键步骤 :直接加载此前缀的KV Cache,完全跳过对那10000 token系统提示的计算。然后,只需计算新输入的"劳动仲裁流程是什么?"这几十个token,并立即开始生成回答。
结论:两次请求的用户问题完全不同,但都命中了缓存,因为缓存基于的是那条不变的系统提示。省下的正是那10000个token的重复计算成本和时间。
如何确保"前缀"相同且命中?
关键在于请求构造的顺序 和缓存断点的位置。
正确做法 ( ✅ ):
总是把最稳定、最共享、最长 的内容放在请求的最前面 ,并把用户相关的动态指令放在最后面。
- 结构 :
[共享文档/知识库] -> [系统提示] -> [对话历史] -> [用户新问题] - 如果使用Anthropic的显式缓存,你可以在系统提示结束、对话历史开始前等位置加
cache_control标记,让缓存断点之前的所有内容都成为可复用的前缀。
错误做法 ( ❌ 会失效 ):
把用户特定的信息放在了最前面。
- 结构 :
[用户ID/时间戳] -> [系统提示] -> [用户问题] - 每个请求的
[用户ID/时间戳]都不同,导致整个前缀不匹配,缓存永远无法命中,完全白费功夫。
总结一句话
上下文缓存就像一个只记得文章"开头"的记忆库。只要两篇文章的开头(前缀)一模一样,不管后边内容如何,它都能直接抄作业,省去重看开头的时间。 你的用户问题,恰恰就是那篇可以千变万化的"后边内容"。