过拟合和剪枝
在之前的文章中我们介绍了决策树的生成和选择划分特征的过程,它在学习的过程中为了尽可能的正确的分类训练样本,会不停地对结点和特征进行划分,因此这会导致整棵树的分支过多。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。因此为了提高决策树模型的泛用性,需要对决策树进行简化,这个过程过程称为剪枝(pruning)。
顾名思义,剪枝就是从树上裁掉一些子树或叶结点, 并将其根结点或父结点作为新的叶结点,从而简化分类树模型.。类似于现实中把树枝剪掉。
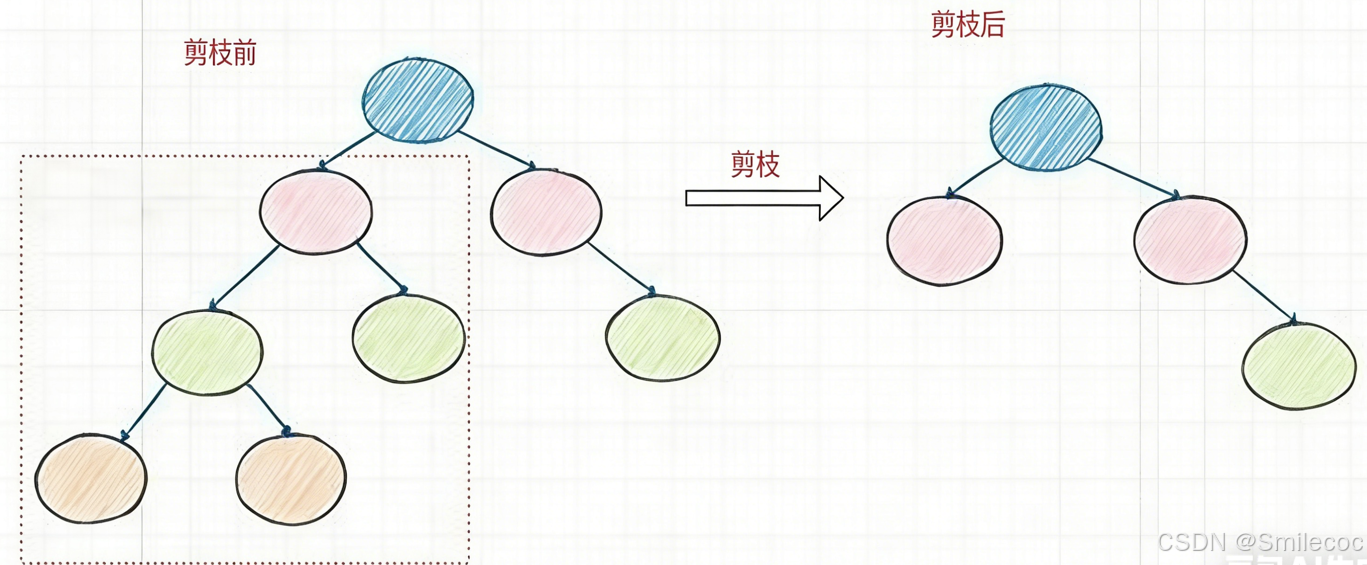
剪枝方法
剪枝的方法一般有两种方法,分别是预剪枝和后剪枝。
- 预剪枝(pre-pruning):预剪枝就是在构造决策树的过程中,先对每个结点在划分前进行估计,若果当前结点的划分不能带来决策树模型泛用性能的提升,则不对当前结点进行划分并且将当前结点标记为叶结点。简单来说思路是边建树,边剪枝
- 后剪枝(post-pruning):后剪枝就是先把整颗决策树构造完毕,然后自底向上的对非叶结点进行考察,若将该结点对应的子树换为叶结点能够带来泛用性能的提升,则把该子树替换为叶结点。简单来说思路是先建树,后剪枝
预剪枝
预剪枝对何时停止决策树的生长有如下几种方法:
- 直接限制树的深度,当树达到一定深度时即停止。例如直接限制树的层数为3层,训练集和测试集准确度达标即可
- 设置划分后结果数量的阈值,当达到当前节点的样本数量小于某个阈值的时候停止。例如在经过划分后某一叶节点样本数小于2个即停止划分。
- 信息增益阈值法:计算每次划分时信息增益的提升,当小于设定的阈值时停止。
- 预留⼀部分数据⽤作"验证集"以进⾏性能评估,在每个节点划分前计算节点在验证集上划分后的精度,判断是否需要划分
预剪枝的优缺点
• 优点: 1.降低过拟合⻛险。2.训练时间和测试时间开销较少
• 缺点:⽋拟合⻛险:有些分⽀的当前划分虽然不能提升泛化性能,但在其基础上进⾏的后续划分却有可能导致性能显著提⾼。类似于地图导航,一种方案可能在前几个路口需要等待一段时间,但是后续可以绕开拥堵路段从而最快到达目的地,使用预剪枝时很有可能就会导致模型没有比较好的效果。
sklearn中如何预剪枝
sklearn中如相关训练参数如下:
- max_depth :树的最大深度,深度大于设定的参数时即停止分枝。
- min_samples_leaf:叶子节点最小样本数,叶子节点里的样本数小于设定的参数时即停止分枝。
- min_samples_split:节点分枝最小样本个数,节点里的样本数小于设定的参数时即停止分枝。
- min_weight_fraction_leaf:叶子节点最小权重和,小于设定的参数时即停止分枝。
- min_impurity_decrease:节点分枝最小纯度增长量,分裂后不纯度下降小于设定的参数时即停止分枝。
- max_leaf_nodes:最大叶子节点数,树最多生成多少个叶子节点,多于设定的参数即停止
后剪枝
相比于预剪枝,后剪枝方法通常可以得到泛化能力更强的决策树,但时间开销更大。常见的后剪枝方法有:
-
代价复杂度剪枝(CCP)(CART 默认剪枝方法)
构造一个综合"树的代价"与"树的复杂度"的损失函数,然后求解,裁掉哪个节点,能让L最小,就裁哪个,这个是最常用的后剪枝方法
-
错误率降低剪枝(REP)
划分训练集 - 验证集:训练集用形成学习到的决策树;验证集用来评估修剪决策树。大致流程可描述为:对于训练集上构建的过拟合决策树,将其应用到验证集中自底向上遍历所有子树进行剪枝,直到针对交叉验证数据集无法进一步降低错误率为止。
-
悲观剪枝(PEP)(C4.5 默认剪枝方法)
C4.5采用的悲观剪枝(PEP)方法,用递归的方式从低往上针对每一个非叶子节点,评估用一个最佳叶子节点去代替这课子树是否有益。如果剪枝后与剪枝前相比其错误率是保持或者下降,则这棵子树就可以被替换掉。
其他的后剪枝方法还有: 最小误差剪枝(MEP),CVP(Critical Value Pruning),OPP(Optimal Pruning)等。
优点:
--后剪枝⽐预剪枝保留了更多的分⽀,⽋拟合风险小,泛化性能往往优于预剪枝决策树
缺点:
-- 训练时间开销⼤:后剪枝过程是在⽣成完全决策树之后进⾏的,需要⾃底向上对所有⾮叶结点逐⼀考察;其训练时间要远⼤于预剪枝决策树
代价复杂度剪枝(CCP,cost_complexity_pruning)
该算法为子树 T t T_t Tt定义了代价(cost)和复杂度(complexity),以及一个可由用户设置的衡量代价与复杂度之间关系的参数 α \alpha α,其中,代价指在剪枝过程中因子树 T t T_t Tt 被叶节点替代而增加的错分样本,复杂度表示剪枝后子树 T t T_t Tt减少的叶节点数, α \alpha α则表示剪枝后树的复杂度降低程度与代价间的关系,定义为:
α = R ( t ) − R ( T t ) ∣ N 1 ∣ − 1 \alpha = \frac{R(t) - R(T_t)}{|N_1| - 1} α=∣N1∣−1R(t)−R(Tt)
其中,
∣ N 1 ∣ |N_1| ∣N1∣:子树 T t T_t Tt 中的叶节点数;
R ( t ) R(t) R(t):节点 t 的错误代价,即将节点 t t t后的分支剪掉后将节点 t t t作为叶节点的错分情况。计算公式为 R ( t ) = r ( t ) ∗ p ( t ) R(t) = r(t) * p(t) R(t)=r(t)∗p(t),其中 r ( t ) r(t) r(t) 为结点 t t t 的错分样本率, p ( t ) p(t) p(t) 为落入结点 t 的样本占所有样本的比例;
R ( T t ) R(T_t) R(Tt):子树 T t Tt Tt 错误代价,即保留子树 T t Tt Tt时的错分情况。计算公式为 R ( T t ) = ∑ R ( i ) R(T_t) = \sum R(i) R(Tt)=∑R(i), i i i 为子树 T t T_t Tt 的叶节点。
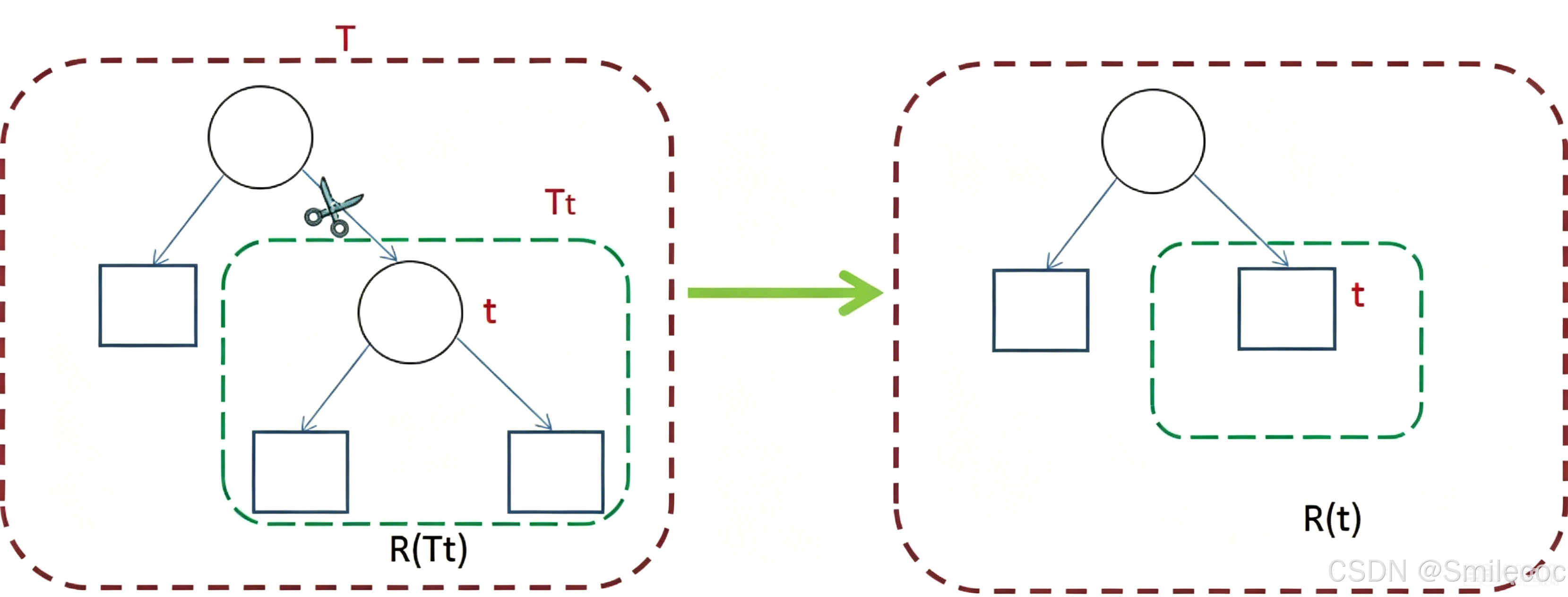
CCP 剪枝算法分为两个步骤:
-
对于完全决策树 T T T 的每个非叶结点计算 α \alpha α 值,循环剪掉具有最小 α \alpha α 值的子树,直到剩下根节点。在该步可得到一系列的剪枝树 { T 0 , T 1 , T 2 , ... , T m } \{T_0, T_1, T_2, \dots, T_m\} {T0,T1,T2,...,Tm},其中 T 0 T_0 T0 为原有的完全决策树, T m T_m Tm 为根结点, T i + 1 T_{i+1} Ti+1 为对 T i T_i Ti 进行剪枝的结果;
-
从子树序列中,根据真实的误差估计选择最佳决策树。
接下来我们结合一个实际的例子来看一下。如下为一个决策树的非叶结点 T 4 T4 T4部分,每个节点下的数字左边为分类正确的样本数,右边的数字为错误的样本数。
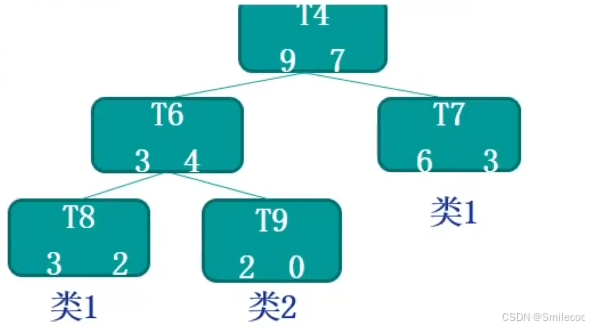
假设已有的数据有 60 条,那么
R ( t ) = r ( t ) ⋅ p ( t ) = ( 7 16 ) ⋅ ( 16 60 ) = 7 60 R ( T t ) = ∑ R ( i ) = ( 2 5 ) ( 5 60 ) + ( 0 2 ) ( 2 60 ) + ( 3 9 ) ( 9 60 ) = 5 60 α = R ( t ) − R ( T t ) ∣ N 1 ∣ − 1 = 1 60 \begin{aligned} R(t) &= r(t) \cdot p(t) = \left(\frac{7}{16}\right) \cdot \left(\frac{16}{60}\right) = \frac{7}{60} \\ R(T_t) &= \sum R(i) = \left(\frac{2}{5}\right)\left(\frac{5}{60}\right) + \left(\frac{0}{2}\right)\left(\frac{2}{60}\right) + \left(\frac{3}{9}\right)\left(\frac{9}{60}\right) = \frac{5}{60} \\ \alpha &= \frac{R(t) - R(T_t)}{|N_1| - 1} = \frac{1}{60} \end{aligned} R(t)R(Tt)α=r(t)⋅p(t)=(167)⋅(6016)=607=∑R(i)=(52)(605)+(20)(602)+(93)(609)=605=∣N1∣−1R(t)−R(Tt)=601
这样就计算出了非叶节点 T 4 T4 T4的 α \alpha α 值,可以和我们设定的超参数 α \alpha α比较决定是否剪枝。例如我们设定的超参数 α = 1 30 \alpha=\frac{1}{30} α=301,则在 T 4 T4 T4处剪枝,反之超参数 α = 1 120 \alpha=\frac{1}{120} α=1201,则在 T 4 T4 T4处不进行剪枝。
这个例子中得到一系列的剪枝树如下:
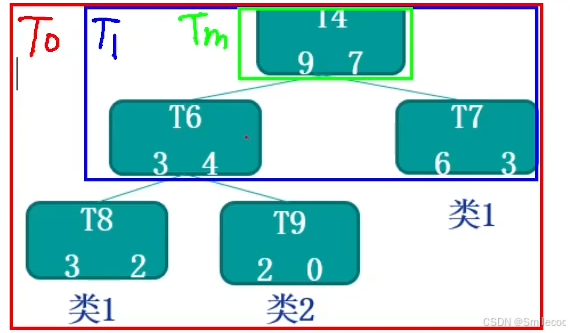
那么代价复杂度剪枝(CCP)的 α \alpha α值如何设定呢?
当 α = 0 \alpha=0 α=0时, 即不考虑复杂度, 这时完整树即为最优,不会进行剪枝操作。随着设置的 α \alpha α变大,决策树也从繁变简,训练集会从过拟合慢慢向欠拟合过渡,因此我们可以将所有的 α \alpha α训练模型后传入训练集和测试集并计算分类的准确率,并选出可以使训练集结果最优的 α \alpha α值。
如下结果中, α = 0.015 \alpha=0.015 α=0.015时测试集准确率最高,训练集准确率也可达到96%左右,即可作为最优 α \alpha α参数
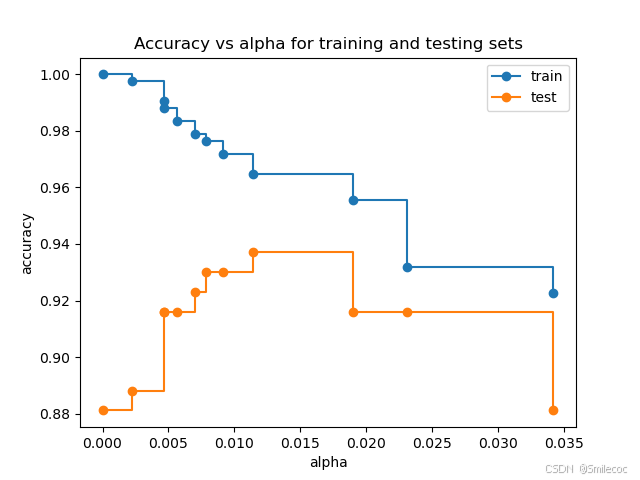
具体的代码和步骤可参考官方文档:https://scikit-learn.org/stable/auto_examples/tree/plot_cost_complexity_pruning.html#sphx-glr-auto-examples-tree-plot-cost-complexity-pruning-py
错误率降低剪枝 (REP,Reduced-Error Pruning )
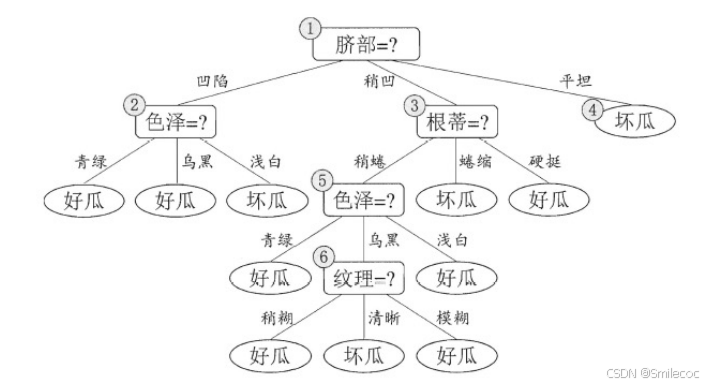
REP剪枝是一种比较简单的后剪枝方法。在该方法中,数据被分成训练集和测试集(验证集)。判断是否剪枝的依据是测试集在剪枝前后是否分类的准确率更高,或称为精度。如果在某一个节点剪枝后,验证集的准确率变化不大或者更优,则进行剪枝。
如下判断西瓜好坏的决策树使用REP剪枝的流程:
完整的决策树:
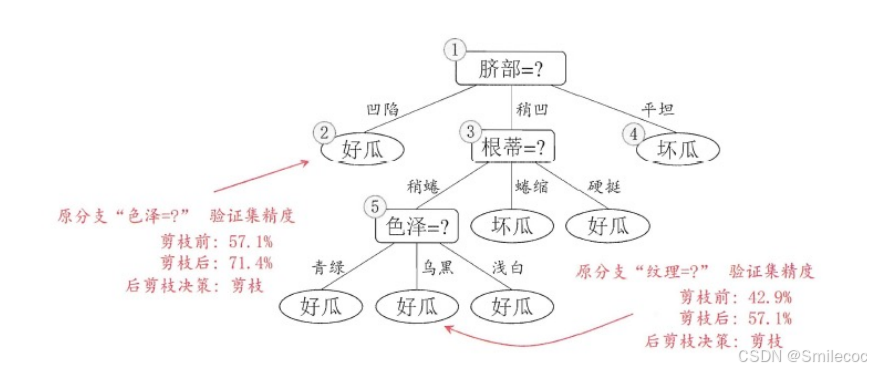
自底向上计算剪枝前后的分类正确率,并决定是否剪枝
悲观剪枝(PEP,Pessimistic Error Pruning)
PEP是根据剪枝前后的错误率来判定子树的修剪。不需要验证集,只用训练集;同时剪枝自顶向下
PEP假设在节点处的错分样本数量服从二项分布,该方法引入了统计学上连续修正的概念弥补REP中的缺陷,在评价子树的训练错误公式中添加了一个常数,假定每个叶子节点都自动对实列的某个部分进行错误的分类。
把一颗子树(具有多个叶子节点)的分类用一个叶子节点来替代的话,在训练集上的误判率肯定是上升的,但是在新数据上不一定。于是我们需要把子树的误判计算加上一个经验性的惩罚因子。对于一颗叶子节点,它覆盖了N个样本,其中有E个错误,那么该叶子节点的错误率为(E+0.5)/N。这个0.5就是惩罚因子,那么一颗子树,它有L个叶子节点,那么该子树的误判率估计为:
e = ∑ E i + 0.5 ∗ L ∑ N i e = \frac{\sum E_i + 0.5*L}{\sum N_i} e=∑Ni∑Ei+0.5∗L
其中: E i E_i Ei为该节点错误的个数, N i N_i Ni为该节点样本的个数, L L L为叶子节点个数
剪枝后,该节点概率误判率 e e e为 ( E + 0.5 ) / N (E+0.5)/N (E+0.5)/N,因此叶子节点的误判次数均值 E t E_t Et为:
e t = E + 0.5 N e_t = \frac{E + 0.5}{N} et=NE+0.5
E t = N ⋅ e t = N ⋅ E + 0.5 N = E + 0.5 E_t = N \cdot e_t = N \cdot \frac{E + 0.5}{N} = E + 0.5 Et=N⋅et=N⋅NE+0.5=E+0.5
剪枝前,服从伯努利分布,误判均值 E E E和标准差:
N = ∑ N i N = \sum N_i N=∑Ni
e T = ∑ E i + 0.5 ⋅ L ∑ N i = ∑ E i + 0.5 ⋅ L N e_T = \frac{\sum E_i + 0.5 \cdot L}{\sum N_i} = \frac{\sum E_i + 0.5 \cdot L}{N} eT=∑Ni∑Ei+0.5⋅L=N∑Ei+0.5⋅L
E T = N ⋅ e T = N ⋅ ∑ E i + 0.5 ⋅ L N = ∑ E i + 0.5 ⋅ L E_T = N \cdot e_T = N \cdot \frac{\sum E_i + 0.5 \cdot L}{N} = \sum E_i + 0.5 \cdot L ET=N⋅eT=N⋅N∑Ei+0.5⋅L=∑Ei+0.5⋅L
δ = N ⋅ e T ⋅ ( 1 − e T ) = E T ⋅ ( N − E T ) \delta = \sqrt{N \cdot e_T \cdot (1 - e_T)} = \sqrt{E_T \cdot (N - E_T)} δ=N⋅eT⋅(1−eT) =ET⋅(N−ET)
判断是否剪枝条件:
E t < E T i + δ E_t < E_{T_i} + \delta Et<ETi+δ 即剪枝
依旧使用如下例子来判断是否剪枝:
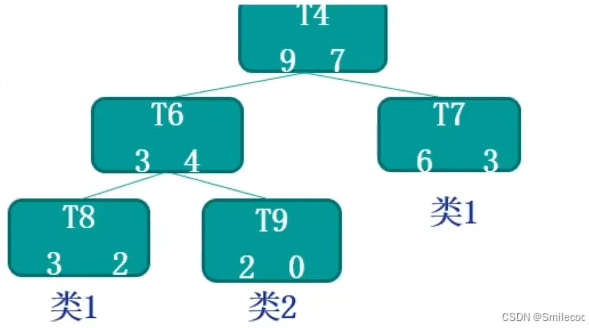
比如T4这棵子树的误差率:
( 3 + 2 ) + 0.5 × 3 16 = 6.5 16 = 0.40625 \frac{(3+2)+0.5\times 3}{16} = \frac{6.5}{16} = 0.40625 16(3+2)+0.5×3=166.5=0.40625
子树误差率的标准误差:
16 × 0.40625 × ( 1 − 0.40625 ) = 1.96 \sqrt{16 \times 0.40625 \times (1-0.40625)} = 1.96 16×0.40625×(1−0.40625) =1.96
子树替换为一个叶节点后,其误差率为:
7 + 0.5 16 = 0.46875 \frac{7+0.5}{16} = 0.46875 167+0.5=0.46875
因为 6.5 + 1.96 > 7.5 6.5 + 1.96 > 7.5 6.5+1.96>7.5,所以决定将子树T4替换为一个叶子节点。
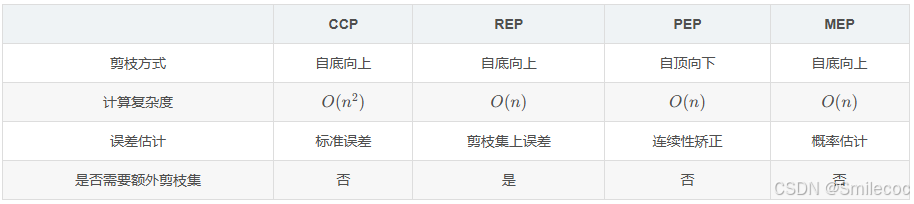
几种常用的决策树后剪枝方法对比如下:
更多文章可搜索:Smilecoc的杂货铺
参考文章:
https://cs.nju.edu.cn/liyf/aml23/Lecture06.pdf
https://blog.csdn.net/San_pi_sama/article/details/126844566
https://blog.csdn.net/San_pi_sama/article/details/126903428
https://www.bbbdata.com/text/38
《现代决策树模型及其编程实践:从传统决策树到深度决策树》