关于linux kernel 代码中,错误码一律是负数编码,这个事情困扰我很长时间。
应用程序员写的错误码一律为正数,为什么内核要标新立异呢? 而且当时看不出任何有价值的东西。
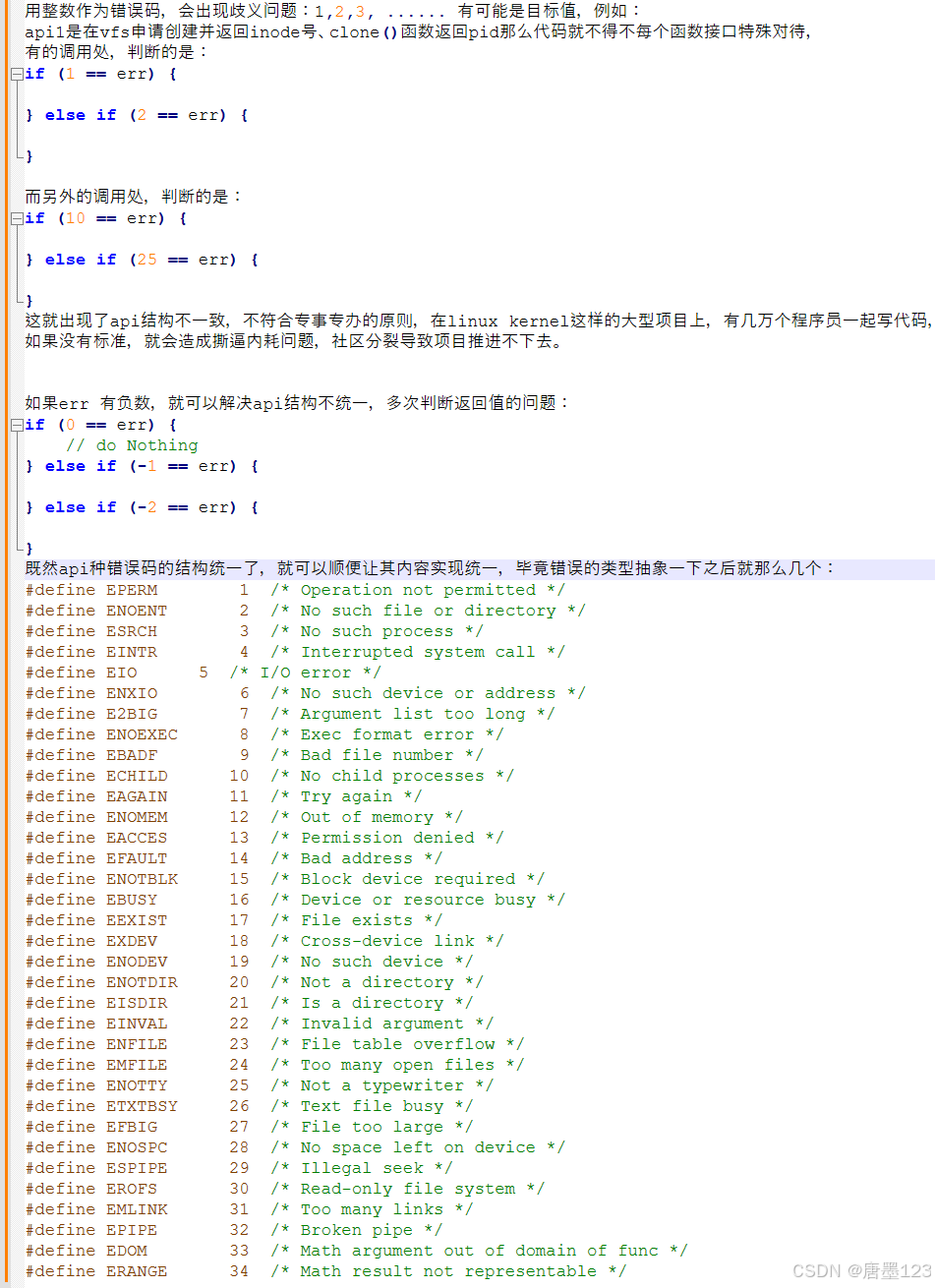
后面在研究linux kernel2.6论证过这样设计的原因是图一:避免没有标准导致社区分裂。
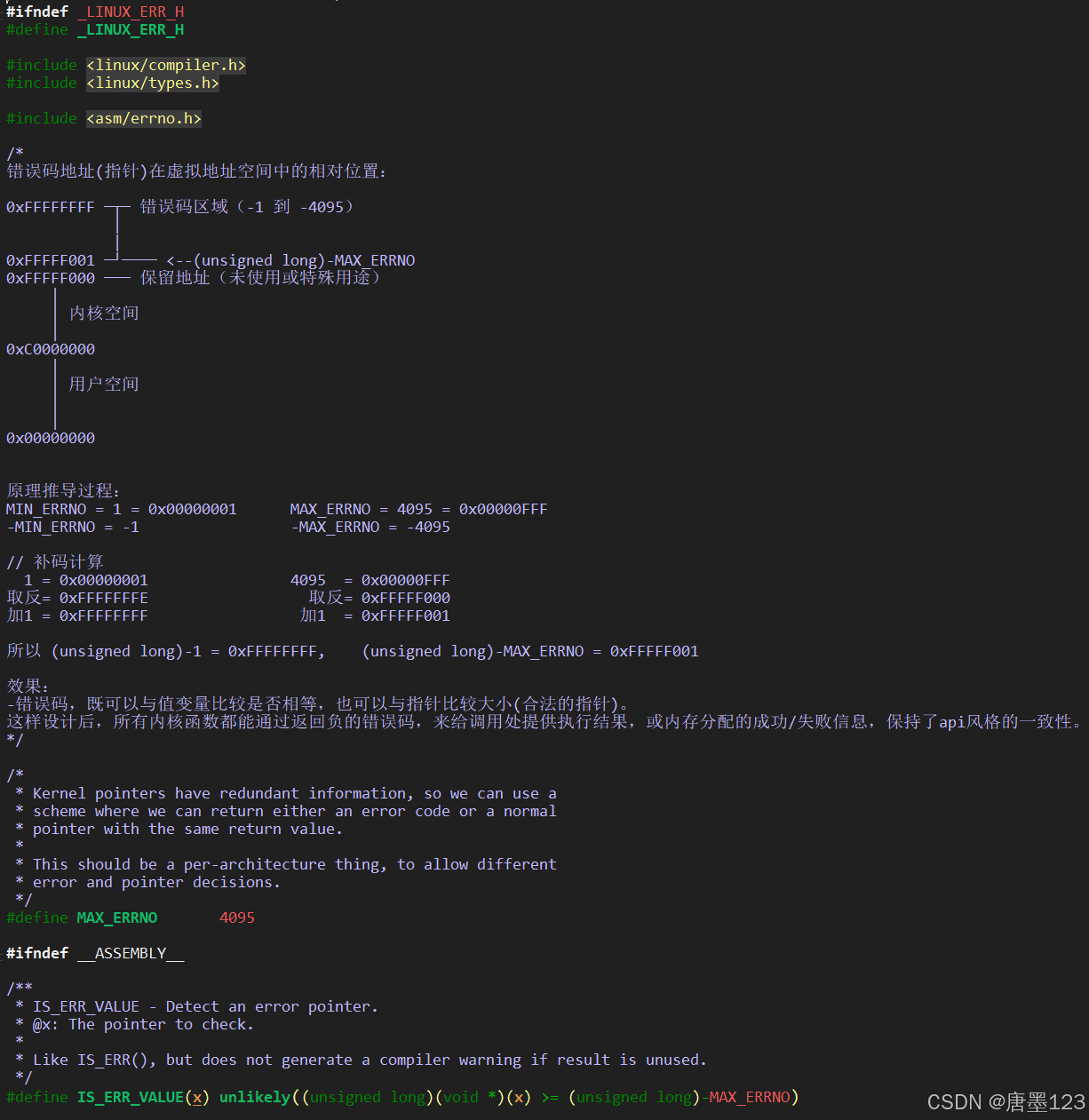
当我在阅读linux kernel 7.0的代码的时候,思维深度有所加深,于是有了图2的论证。
linux kernel 这种设计如此精妙且精彩,一石三鸟、鬼斧神工。
内核里面,没有一个字符是随便写的,内核3000万行代码里面随便拎出来2行,那都是有理论支撑,应该且只能这样去设计。