从 JS 引擎执行原理理解数据类型:栈内存、堆内存与作用域
📢 本文从 JavaScript 引擎编译执行的底层视角出发,带你理解原始类型和引用类型在内存中的真实面貌,彻底搞懂
null、undefined、Number、Symbol等数据类型的本质。
导读
本文适合以下读者:
- ✅ 学过 JS 基础,知道 7 种数据类型,但说不清为什么原始类型存栈、引用类型存堆
- ✅ 背过
nullvsundefined的区别,但换个问法就犹豫 - ✅ 了解变量提升和暂时性死区,但不知道它们和执行上下文的关系
- ✅ 想用一条完整的推导链把零散的知识点串起来,而不是死记硬背
阅读路线建议:
javascript
第一节(执行上下文)→ 第二节(var/let/const)→ 第三节(栈堆内存)
↓
第四节(null vs undefined)
第五节(Number 精度 & BigInt)
第六节(Symbol 唯一性)
↓
第七节(全景总结)🔗 第一节是整篇文章的地基------你需要先理解"编译阶段和执行阶段",后面的所有结论才能顺理成章地推导出来。如果时间有限,至少把第一节读完再跳到感兴趣的章节。
前言
学 JS 数据类型时,我背过不少结论:
- "原始类型存在栈里,引用类型存在堆里"
- "null 是主动赋值的空,undefined 是未定义"
- "0.1 + 0.2 不等于 0.3,因为浮点数精度问题"
背是背下来了,但每次遇到变体题目还是会犹豫------因为我不知道这些结论是怎么推导出来的。
后来我换了一个角度:不再从"结论"出发,而是从 JS 引擎执行代码的那一刻开始,一步步往下推。神奇的事情发生了------那些需要死记硬背的知识点,突然串成了一条完整的链条。
这篇文章就是我的推导过程。希望能帮你用同样的方式,真正"理解"而不是"记住"这些概念。
一、JS 引擎如何执行代码?------ 两个阶段
当我们写下一段代码时,JS 引擎并不是逐行执行的,而是分为两个阶段:
js
console.log(a); // undefined(不是报错!)
var a = 10;
console.log(a); // 101.1 创建阶段(编译阶段)
JS 引擎会先把整段代码扫描一遍,做两件事:
- 创建全局执行上下文(Global Execution Context)
- 在变量环境中注册变量名(注意:此时只注册名字,还没有赋值)
🧪 为什么这个例子用
var? 因为var在创建阶段就会被初始化为undefined,最能直观展示"声明"和"赋值"是两个独立阶段。let/const也是两个阶段,但行为不同------后面会详细对比。
javascript
┌─────────────────────────────────────────────┐
│ 全局执行上下文 │
│ │
│ 变量环境(Variable Environment) │
│ ┌──────────────┐ │
│ │ a: undefined │ ← 只声明,未赋值 │
│ └──────────────┘ │
│ │
│ 词法环境(Lexical Environment) │
│ ┌──────────────┐ │
│ │ (empty) │ ← let/const 在此注册 │
│ └──────────────┘ │
└─────────────────────────────────────────────┘1.2 执行阶段
引擎逐行执行代码,对变量进行赋值和操作:
ini
第1行: console.log(a) → 从变量环境取到 a = undefined → 输出 undefined
第2行: a = 10 → 变量环境中 a 更新为 10
第3行: console.log(a) → 输出 10💡 这就是变量提升(Hoisting)的本质:不是代码被移动到了顶部,而是编译阶段就已经把变量名注册了。
二、变量环境 vs 词法环境:var、let、const 的区别
2.1 var → 存入变量环境(Variable Environment)
js
console.log(a); // undefined
var a = 10;var 声明的变量在创建阶段 就被注册到变量环境,并初始化为 undefined。
2.2 let/const → 存入词法环境(Lexical Environment)
js
console.log(b); // ❌ ReferenceError: Cannot access 'b' before initialization
let b = 20;let/const 声明的变量在创建阶段 也被注册,但不会初始化 ,处于一个叫做 "暂时性死区"(TDZ, Temporal Dead Zone) 的状态。
javascript
┌──────────────────────────────────────────────────┐
│ 全局执行上下文 │
│ │
│ 变量环境(Variable Environment) │
│ ┌──────────────┐ │
│ │ a: undefined │ ← var 声明,立即初始化 │
│ └──────────────┘ │
│ │
│ 词法环境(Lexical Environment) │
│ ┌──────────────┐ │
│ │ b: <TDZ> │ ← let 声明,暂不初始化 │
│ └──────────────┘ │
└──────────────────────────────────────────────────┘2.3 三种声明方式对比
| 特性 | var | let | const |
|---|---|---|---|
| 存储位置 | 变量环境 | 词法环境 | 词法环境 |
| 初始化时机 | 创建阶段立即初始化 | 执行到声明语句时初始化 | 执行到声明语句时初始化 |
| 是否有 TDZ | ❌ 无 | ✅ 有 | ✅ 有 |
| 重复声明 | ✅ 允许 | ❌ 报错 | ❌ 报错 |
| 块级作用域 | ❌ 无 | ✅ 有 | ✅ 有 |
2.4 块级作用域的词法环境
js
{
let x = 10;
const y = 20;
console.log(x, y); // 10, 20
}
console.log(x); // ❌ ReferenceError(块级作用域外不可访问)每个 {} 块都会创建一个新的词法环境:
yaml
┌───────────────────────────┐
│ 全局词法环境 │
│ ┌─────────────────────┐ │
│ │ 块级词法环境 │ │
│ │ ┌────────────────┐ │ │
│ │ │ x: 10 │ │ │
│ │ │ y: 20 │ │ │
│ │ └────────────────┘ │ │
│ └─────────────────────┘ │
└───────────────────────────┘三、栈内存与堆内存:原始类型 vs 引用类型的存储
现在我们知道了变量是怎么被声明和注册的,接下来的问题是:变量的值存在哪里?
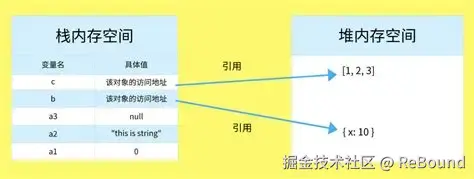
3.1 栈内存(Stack)------ 原始类型的家
栈内存的特点:
- 空间较小,但访问速度快
- 由系统自动分配和释放
- 存储大小固定的数据(原始类型)
csharp
栈内存(Stack)
┌────────────────┐
│ 变量名 │ 值 │
├────────────────┤
│ a │ null │ ← 原始类型,值直接存在栈中
│ b │ 42 │
│ c │ true │
│ d │ "hi" │
└────────────────┘3.2 堆内存(Heap)------ 引用类型的家
堆内存的特点:
- 空间较大,但访问速度相对较慢
- 需要手动管理(JS 中由 GC 垃圾回收器自动处理)
- 存储大小不固定的数据(对象、数组、函数等)
css
栈内存(Stack) 堆内存(Heap)
┌──────────────┐ ┌──────────────────────┐
│ 变量名 │ 值 │ │ 内存地址 │
├──────────────┤ ├──────────────────────┤
│ obj │ 0x01 │ ────────> │ { name: "谢如是" } │
│ obj2 │ 0x01 │ ────────> │ │
└──────────────┘ └──────────────────────┘
↑ ↑
│ 只存引用地址(指针) │ 存储实际数据
└────────────────────────────┘3.3 拷贝式赋值 vs 引用式赋值
理解了栈和堆的区别,就自然理解了两种赋值方式的本质:
js
// ✅ 原始类型:拷贝值(Copy by Value)
let a = null;
let b = a; // 把 null 这个值复制一份给 b
b = 2; // 修改 b,不影响 a
console.log(a); // null
// ✅ 引用类型:拷贝引用地址(Copy by Reference)
let obj = { name: "谢如是" };
let obj2 = obj; // 把 obj 的引用地址复制给 obj2
obj2.company = "字节跳动"; // 通过 obj2 修改堆内存中的对象
console.log(obj); // { name: "谢如是", company: "字节跳动" }
// obj 和 obj2 指向同一块堆内存,所以 obj 也被修改了内存变化图解:
vbscript
原始类型赋值过程: 引用类型赋值过程:
Step 1: let a = null Step 1: let obj = { name: "谢如是" }
┌──────┐ 栈 堆
│ a │ null ┌──────┐ ┌─────────────────┐
└──────┘ │ obj │──> │ { name: "..." } │
└──────┘ └─────────────────┘
Step 2: let b = a Step 2: let obj2 = obj
┌──────┐ 栈 堆
│ a │ null ┌──────┐ ┌─────────────────┐
│ b │ null ← 复制值 │ obj │──> │ { name: "..." } │
└──────┘ │ obj2 │──> │ │
└──────┘ └─────────────────┘
Step 3: b = 2 (同一个对象!)
┌──────┐
│ a │ null
│ b │ 2 ← 只改 b
└──────┘3.4 为什么原始类型存在栈里,引用类型存在堆里?
| 特性 | 原始类型 | 引用类型 |
|---|---|---|
| 大小 | 固定(8 字节左右) | 动态(可能很大) |
| 存储 | 栈内存 | 堆内存 |
| 赋值 | 拷贝值 | 拷贝引用地址 |
| 可变性 | 不可变(创建后值不能修改) | 可变(可以添加/删除属性) |
| 比较 | 比较值是否相等 | 比较引用地址是否相同 |
🔥 关键理解 :原始类型是不可变 的。当你执行
let b = a; b = 2;时,不是把b的值从null改成了2,而是创建了一个新的值2,让b指向它。
四、从执行上下文理解 null 和 undefined
现在我们有了底层视角,再来看 null 和 undefined,就清晰多了。
4.1 undefined:引擎的"占位符"
js
let a;
console.log(a); // undefined执行上下文视角:
javascript
创建阶段:
词法环境 → a: <TDZ>(暂时性死区)
执行阶段(执行 let a):
词法环境 → a: undefined ← 引擎自动初始化为 undefinedundefined 是 JS 引擎在变量声明但未赋值时,自动赋予的默认值。
4.2 常见的 undefined 场景
js
// 1. 变量声明未赋值
let a;
console.log(a); // undefined
// 2. 访问对象不存在的属性
let obj = {};
console.log(obj.property); // undefined
// 3. 函数没有返回值
function noReturn() {}
console.log(noReturn()); // undefined
// 4. 数组越界
let arr = [1, 2, 3];
console.log(arr[4]); // undefined💡 底层理解 :当你访问
obj.property时,JS 引擎在对象的属性表中找不到property这个键,就返回undefined------这是语言规范规定的默认行为,不是null。
4.3 null:开发者主动标记的"空"
js
// 场景:处理完一个大对象后,主动释放引用
let largeData = {
list: new Array(1000000).fill("data"), // 100 万个元素
cached: true
};
// 使用完毕,主动断开引用
largeData = null;内存视角:
yaml
Step 1: let largeData = { list: [...], cached: true }
栈 堆
┌───────────┐ ┌──────────────────────────┐
│ largeData │──> │ { list: [100万个元素], │
└───────────┘ │ cached: true } │
└──────────────────────────┘
Step 2: largeData = null
栈 堆
┌───────────┐ ┌──────────────────────────┐
│ largeData │ null │ { list: [100万个元素], │ ← 无引用,等待 GC 回收
└───────────┘ │ cached: true } │
└──────────────────────────┘⚠️ GC 机制 :当堆内存中的对象没有任何变量引用它时,垃圾回收器(Garbage Collector)会在适当的时机回收这块内存。将变量设为
null是告诉 GC:"这块内存我不用了,你可以回收了。"
4.4 null vs undefined 的本质区别
| 维度 | null | undefined |
|---|---|---|
| 谁赋的值 | 开发者主动赋值 | JS 引擎自动赋值 |
| 语义 | "我故意让它为空" | "这个东西还没定义" |
| typeof | "object"(历史遗留 bug) |
"undefined" |
| == 比较 | null == undefined → true |
--- |
| === 比较 | null === undefined → false |
--- |
js
// null 和 undefined 在宽松相等下相等
console.log(null == undefined); // true
console.log(null === undefined); // false
// 实际应用
let user = {
name: "Alice",
address: null // 明确表示:地址字段存在,但值为空
};
console.log(user.address); // null(字段存在,值为空)
console.log(user.age); // undefined(字段根本不存在)五、Number 类型:栈中的 64 位浮点数
5.1 Number 在栈中的存储方式
JavaScript 统一使用 IEEE 754 双精度浮点数(64 位)存储所有数值:
64 位双精度浮点数结构:
┌──────┬────────────┬──────────────────────────────┐
│ 符号 │ 指数 │ 尾数 │
│ 1位 │ 11位 │ 52位 │
└──────┴────────────┴──────────────────────────────┘5.2 经典问题:0.1 + 0.2 ≠ 0.3
js
let a = 0.1;
let b = 0.2;
console.log(a + b); // 0.30000000000000004为什么?因为 0.1 和 0.2 在二进制中是无限循环小数:
scss
0.1 (十进制) = 0.00011001100110011... (二进制,无限循环)
0.2 (十进制) = 0.0011001100110011... (二进制,无限循环)
存储时只能截断保留 52 位尾数 → 精度丢失解决方案:
js
// 方案一:toFixed(返回字符串)
console.log((0.1 + 0.2).toFixed(2)); // "0.30"
// 方案二:转整数计算
console.log((0.1 * 100 + 0.2 * 100) / 100); // 0.3
// 方案三:Number.EPSILON 判断相等
function isEqual(a, b) {
return Math.abs(a - b) < Number.EPSILON;
}
console.log(isEqual(0.1 + 0.2, 0.3)); // true5.3 BigInt:突破 64 位限制
当数值超过 Number.MAX_SAFE_INTEGER(2⁵³ - 1 ≈ 9007 万亿)时,52 位尾数就不够用了,会出现精度丢失:
js
// Number 的精度天花板
console.log(9007199254740992 === 9007199254740993); // true 😱 两个不同的数被认为相等!
// BigInt:用后缀 n 声明,任意精度
const big1 = 9007199254740993n;
const big2 = 9007199254740992n;
console.log(big1 === big2); // false ✅ 精确区分
// 实际场景:处理超大 ID(如雪花算法生成的订单号)
const orderId = 202506131234567890123456789n;
console.log(typeof orderId); // "bigint"💡 BigInt 不使用 64 位浮点数,它可以表示任意精度的整数。但注意:
- BigInt 和 Number 不能混用:
10n + 20→ TypeError- BigInt 没有小数:
10n / 3n→3n(不是 3.333...)
六、Symbol:运行时的唯一标识
6.1 Symbol 的"唯一性"是怎么来的?
Symbol 是 ES6 引入的第七种原始类型。虽然它也是原始类型、也存在栈里,但它有一个独特的行为:每次调用 Symbol() 都会创建一个全新的、唯一的值------即使描述符相同。
js
console.log(Symbol("张志恒") === Symbol("张志恒")); // false
console.log(typeof Symbol("张志恒")); // "symbol"从执行上下文的角度看:
js
const s1 = Symbol("id");
const s2 = Symbol("id");执行到这里时,引擎在词法环境中分别创建了两个 Symbol 值。关键点在于:Symbol("id") 不是一个"查找已存在的 Symbol"的操作,而是一个"创建一个新的 Symbol"的指令 。每执行一次 Symbol(),引擎就在内存中生成一个新的唯一值。这和字符串的行为完全不同------"id" === "id" 永远为 true,因为相同的字符串字面量指向同一个值。
css
词法环境
┌─────────────────────────┐
│ s1: Symbol("id") #ref1 │ ← 第一次执行 Symbol("id"),创建 #ref1
│ s2: Symbol("id") #ref2 │ ← 第二次执行 Symbol("id"),创建 #ref2(不是同一个!)
└─────────────────────────┘💡 和字符串的对比很能说明问题 :
"hello"这个字符串字面量,JS 引擎在编译阶段就确定好了;但Symbol("hello")是一个运行时调用,每次调用都产生新值。这就是为什么 Symbol 能做唯一键------它的"唯一性"是运行时保证的,不是编译时决定的。
6.2 Symbol 的核心应用场景
场景一:避免对象属性名冲突
js
const ID = Symbol("id");
const user = {
[ID]: 12345,
name: "张志恒"
};
console.log(user[ID]); // 12345
console.log(user.ID); // undefined(点语法会把它当成字符串 "ID")场景二:模拟私有属性
js
const _private = Symbol("private");
class MyClass {
constructor() {
this[_private] = "secret";
}
getSecret() {
return this[_private];
}
}
const obj = new MyClass();
console.log(obj.getSecret()); // "secret"
console.log(obj._private); // undefined(无法从外部访问)场景三:自定义迭代行为
js
const collection = {
items: [1, 2, 3],
[Symbol.iterator]() {
let index = 0;
return {
next: () => ({
value: this.items[index],
done: index++ >= this.items.length
})
};
}
};
for (const item of collection) {
console.log(item); // 1, 2, 3
}七、完整总结:从编译到执行的全景图
7.1 JS 引擎执行代码的完整流程
javascript
源代码
│
▼
┌─────────────────────────────────────────────┐
│ 创建阶段(编译) │
│ 1. 创建执行上下文 │
│ 2. var → 变量环境,初始化为 undefined │
│ 3. let/const → 词法环境,进入 TDZ │
│ 4. 函数声明 → 变量环境,绑定函数体 │
└─────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ 执行阶段 │
│ 1. 逐行执行代码 │
│ 2. 赋值操作 → 更新变量环境/词法环境 │
│ 3. 原始类型 → 值存在栈内存 │
│ 4. 引用类型 → 值存在堆内存,栈中存引用地址 │
└─────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ 垃圾回收 │
│ 无引用的堆内存对象 → GC 自动回收 │
│ 手动设为 null → 加速回收 │
└─────────────────────────────────────────────┘7.2 七种原始类型速查表
| 类型 | typeof | 存储位置 | 特点 |
|---|---|---|---|
| Number | "number" |
栈(64位浮点数) | 有精度问题 |
| String | "string" |
栈(或堆) | 不可变 |
| Boolean | "boolean" |
栈 | true/false |
| Undefined | "undefined" |
栈 | 引擎自动赋值 |
| Null | "object" ⚠️ |
栈 | 开发者主动赋值 |
| Symbol | "symbol" |
栈 | 每次创建都唯一 |
| BigInt | "bigint" |
栈 | 任意精度整数 |
7.3 原始类型 vs 引用类型对比
| 特性 | 原始类型 | 引用类型 |
|---|---|---|
| 编译时 | 注册变量名,初始化值 | 注册变量名,初始化值 |
| 运行时存储 | 栈内存(直接存值) | 堆内存(栈中存引用) |
| 赋值方式 | 拷贝值 | 拷贝引用地址 |
| 可变性 | 不可变 | 可变 |
| 比较 | 比较值 | 比较引用地址 |
| 内存回收 | 栈自动释放 | 堆需要 GC 回收 |
结语
写这篇文章的过程中,我最大的感受是:JS 里很多看似零散的知识点,其实都是从同一条主线推导出来的。
那条主线就是------JS 引擎如何执行代码:
- 编译阶段 ,
var进变量环境并初始化为undefined,let/const进词法环境但卡在 TDZ------变量提升和暂时性死区的行为差异,根源就在这里 - 执行阶段 ,遇到赋值才真正写入值。原始类型直接入栈(大小固定、不可变),引用类型则"栈里放地址、堆里放数据"(大小不定、可变)------这解释了拷贝行为、比较行为、以及为什么修改
obj2会影响obj - 回收阶段 ,堆里的数据靠 GC 扫描引用链来回收。
null就是手动掐断引用、告诉 GC "这块可以收了"------而undefined是引擎的默认占位符,语义完全不同
当你把这些串起来之后,Number 的精度问题、Symbol 的唯一性、BigInt 的存在意义......都不再是需要死记的结论,而是顺着这条推导链自然就能得到的答案。
希望这条推导链对你有帮助 ✨
👨💻 作者:ReBound
📅 日期:2026-06-12
🏷️ 标签 :
JavaScript执行上下文内存机制数据类型前端进阶如果觉得有帮助,别忘了点赞、收藏、关注三连哦~ ❤️