Agent 官方给出的定义是:一个大模型不断调用工具为了完成一个给定的任务,直到该任务完成。(An agent is a model calling tools in a loop until a given task is complete.)
这里非常好理解:Tool 就是 Agent 的手脚,Model 是 Agent 的脑子,由脑子控制手脚完成具体的任务,而衔接脑子与手脚的程序叫做 Agent。其实目前各种 AI 落地,说的再花哨就两样东西:一个是 LLM 即大模型,另外一个是 prompt 即提示词!LLM 是基础能力,决定了 AI 的下限。而 prompt 的花样就多了,Tool 是提示词(将工具的功能和执行工具得到的结果以提示词形式告诉大模型,大模型并不会也不能主动执行 Tool,而是由用户本地或者服务器远程的自动化程序来监听大模型给出的格式化的调用命令,从而自动化程序执行替大模型对应的指令,并将执行结果以提示词返回给大模型,如下图,而整个流程叫做 Agent,形象地说明了大模型是通过代理完成工具的调用,而那个自动化程序才是真正的 Agent,负责衔接大模型与 Tool。)
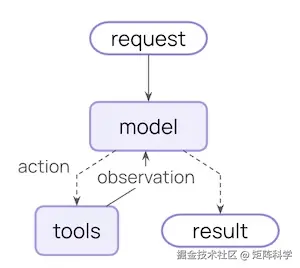
Agent = Model + Harness The job of a harness: get the model the right context at the right time for the given task. A harness is everything around that loop: the model, its prompt, its tools, and any middleware that shapes its behavior.
以上是官方给定的公式,Agent = 大模型 + 约束。Harness 是马具,系带的意思,我这里通俗翻译为约束,即大模型能力很强,幻觉也很多,如果不加以约束控制则无法准确地调用它完成某个任务,我们需要给大模型定规矩,约束好边界,限制大模型乱发挥胡作为。而这些约束就是"在合适的时机给定合适的上下文",包括提示词、工具、中间件,任何能够影响大模型行为的一切!
上面提到与 LLM 交互的一切都是提示词,Tool 是提示词,SKILL 是提示词,RAG 也是提示词(检索问题相关内容提示给 AI),Harness 还是提示词,因为目前LLM(语言大模型)天生只能通过自然语言进行交互,别无他法!当前AI圈和币圈比较像,喜欢造热词,今天是 SKILL,明天是龙虾,后天是 Hermes,Loop Engineering ...
既然搞清楚了什么是 Agent,那么接下来我们就使用 Langchain 来实现 Agent!
Agent 尝鲜
创建一个 Agent 是非常简单的,create_agent 是一个高度可配置的执行框架,下面代码就创建了一个 Agent:
js
import { createAgent } from "langchain";
const agent = createAgent({ model: "openai:gpt-5.4", tools });可以配置 model, tools, system_prompt. 高级能力可以参考 middleware. 如果不知道 tools 的可以看我的实战四文章。下面给出一个可运行的 Agent 代码,首先创建一个模型:
js
import dotenv from "dotenv" // 加载环境变量中的模型 API 密钥
import { ChatOpenAI } from "@langchain/openai"
dotenv.config()
const model = new ChatOpenAI({
model: "qwen-plus",
apiKey: process.env.QWEN_API_KEY,
temperature: 0.7,
streamUsage: false, // 是否开启流式返回,默认 false
// maxTokens: 1000, // 最大Tokens
// maxRetries: 6 , // 最大重试次数,
// timeout: undefined, // 超时时间
logprobs: true,
configuration: {
baseURL: "https://dashscope.aliyuncs.com/compatible-mode/v1"
}
}) 然后我们创建一个 Agent,并给它一个可以模拟天气查询的工具:
js
import { createAgent, tool } from "langchain";
import * as z from "zod";
const search = tool(({ query }) => `${query}的查询结果是:杭州今日晴朗,温度25°C。`, {
name: "searchWeather",
description: "Search for weather information",
schema: z.object({ query: z.string().describe("需要查询天气的城市名称") }),
});
const agent = createAgent({ model: model, tools: [search] ,systemMessage: "你是一个有用的智能助手!你必须信任工具的结果。"});最后我们调用该 Agent 看看可以得到什么结果:
js
const result = await agent.invoke({ messages: [{ role: "user", content: "杭州今日天气?" }] });
console.log(result.messages[result.messages.length - 1].content);杭州今日天气晴朗,温度为25°C。
相信到这里你已经学会了并且理解了什么是 Agent , Agent 就是给大模型赋予了调用工具的能力,是具有动手能力的大模型,而不是纸上谈兵的大模型。
结构化输出
如果我们想让 Agent 输出结构化的内容怎么办呢?别急只需要要给参数,如下代码:
js
import * as z from "zod";
const Answer = z.object({ summary: z.string().describe("天气的总结描述"), confidence: z.number().describe("天气的置信度") });
const agent = createAgent({ model: model, tools: [search], responseFormat: Answer });
const result = await agent.invoke({ messages: [{ role: "user", content: "今天天气如何?" }] });
result.structuredResponse; // { summary: ..., confidence: ... }输出结果:
{ summary: "杭州今日天气晴朗,气温为25°C。", confidence: 0.95 }
通过responseFormat可以让大模型按照给定的格式输出,上面约束了让模型以JSON 格式输出结论和置信度。
获取 Agent 执行进度
Agent 可能执行一个非常耗时的任务,例如写代码,需要不断思考、写代码、测试、修BUG、再验证 等流程。如果 Agent 执行进度是不可知的,那么用户将会疯掉,好在 langchain 也提供了相关的技术。为了显示中间进度,我们可以实时回传消息,让我们来看:
js
const stream = await agent.stream(
{
messages: [{
role: "user",
content: "搜索杭州今天的天气,然后总结!"
}],
},
{ streamMode: "values" }
);
for await (const chunk of stream) {
// Each chunk contains the full state at that point
const latestMessage = chunk.messages.at(-1);
if (latestMessage?.content) {
console.log(`Agent: ${latestMessage.content}`);
} else if (latestMessage?.tool_calls) {
const toolCallNames = latestMessage.tool_calls.map((tc) => tc.name);
console.log(`Calling tools: ${toolCallNames.join(", ")}`);
}
}Agent: 搜索杭州今天的天气,然后总结!
Calling tools: searchWeather
Agent: 杭州的查询结果是:杭州今日晴朗,温度25°C。
Agent: Returning structured response: {"summary":"杭州今日晴朗,温度25°C。","confidence":0.95}
对 Agent 的约束
我们开头讲了Agent = Model + Harness ,Harness 对大模型的执行是非常重要的,那么本节我们将来实战,如何使用 langchain 实现对大模型的约束!
create_agent 具有极高的可扩展性。它的定制化原语(核心基础)就是中间件:每个中间件只专注处理一个特定关注点,在智能体(Agent)循环的恰当时机切入,并且能够与其他任意中间件自由组合。你只需按需取用,不需要的部分直接跳过即可。
常见的业务模式已经作为一等公民(内置)中间件提前构建好了。至于任何个性化的定制需求,往往只需要编写一个中间件就能搞定。
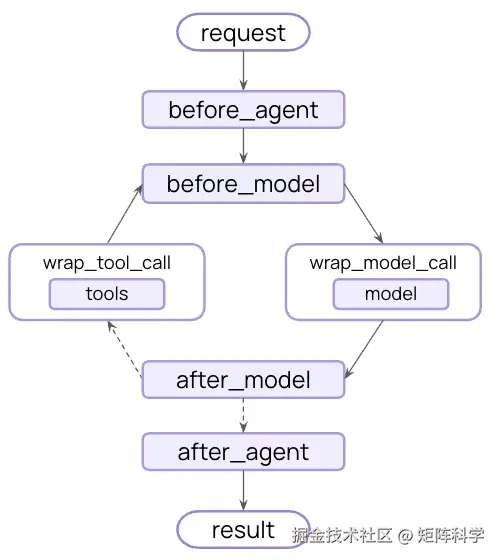
随着代理承担更复杂的工作,他们需要在几个关键领域获得支持。中间件生态系统涵盖了所有这些领域:
约束执行环境
智能体(Agent)只有在能够真正"采取行动"时才具有实用价值,而不仅仅是停留在生成文本上。执行环境为智能体提供了一个专属的工作空间:里面不仅有它可以调用的工具,还有用于在多轮对话中读写文件的文件系统,以及用来运行脚本或 Shell 命令的代码执行环境。下面的各个中间件演示如下,看不懂没关系,关注博主后续的文章,会详细讲解!
执行环境
下面介绍一个中间件------"createFilesystemMiddleware"用于创建包含所有工具和功能的文件系统。
js
import { createAgent } from "langchain";
import { FilesystemMiddleware, StateBackend } from "deepagents";
const agent = createAgent({
model: "anthropic:claude-sonnet-4-6",
tools: [search],
middleware: [new FilesystemMiddleware({ backend: new StateBackend() })],
});这段代码构建了一个以 Claude Sonnet 4.6 为大脑、具备搜索能力的智能体。同时,它通过挂载文件系统中间件和内存状态后端,让智能体拥有了一个虚拟的临时文件系统,能够自主管理长文本和中间数据,非常适合处理需要多步推理和大量信息检索的复杂任务。
-
middleware: [new FilesystemMiddleware({ backend: new StateBackend() })]:这是代码的核心配置。FilesystemMiddleware:文件系统中间件。它赋予了智能体ls(列出文件)、read_file(读取文件)、write_file(写入文件)和edit_file(编辑文件)等工具。当智能体执行search等工具返回大量结果时,它可以将这些长文本保存到"文件"中,避免撑爆上下文窗口,实现高效的上下文工程(Context Engineering)。StateBackend:状态后端。指定了文件系统的底层存储方式。使用StateBackend意味着这些文件是临时存储在智能体的运行状态(内存)中的,通常用于开发和测试阶段的"草稿纸"场景,会话结束后数据不会跨线程持久化。
上下文管理
每次模型调用都有固定的上下文窗口限制。随着智能体(Agent)的运行------不断积累历史对话、工具返回结果以及中间推理步骤------这个窗口很快就会被填满。
为了解决这个问题,系统采用了以下机制:
- 摘要压缩(Summarization) :在窗口溢出前,自动对历史对话进行压缩提炼;
- 记忆(Memory) :在启动时加载持久化的指令,确保关键知识能够跨越不同的会话延续;
- 技能(Skills) :按需动态加载领域知识,而不是在启动时就把所有内容一股脑塞进上下文里。
js
import { FilesystemMiddleware, MemoryMiddleware, SkillsMiddleware, SummarizationMiddleware, StateBackend } from "deepagents";
const backend = new StateBackend();
const model = "anthropic:claude-sonnet-4-6";
const agent = createAgent({
model,
tools: [search],
middleware: [
new FilesystemMiddleware({ backend }),
new SummarizationMiddleware({ model, backend }),
new MemoryMiddleware({ backend, sources: ["./AGENTS.md"] }),
new SkillsMiddleware({ backend, sources: ["./skills/"] }),
],
});以下是代码的逐行解析:
1. 导入核心依赖
- 从
deepagents中导入了四个关键的中间件:FilesystemMiddleware(文件系统)、MemoryMiddleware(长期记忆)、SkillsMiddleware(技能/领域知识)和SummarizationMiddleware(自动摘要),以及用于底层存储的StateBackend。
2. 初始化基础配置
const backend = new StateBackend();:创建一个基于内存状态的临时文件系统后端。后续所有的文件读写、摘要保存都将暂存在这里。const model = "anthropic:claude-sonnet-4-6";:定义智能体使用的大模型,并在后续配置中复用。
3. 创建并配置智能体
-
createAgent({ ... }):初始化智能体,指定了模型和search搜索工具,并在middleware数组中挂载了四个中间件,它们按顺序协同工作:FilesystemMiddleware:赋予智能体虚拟文件系统能力。当搜索工具返回超长文本时,智能体可以将其写入文件,从而避免直接塞入上下文导致溢出。SummarizationMiddleware:自动摘要压缩中间件。当上下文接近窗口上限时,它会自动将旧的历史对话压缩成摘要,释放上下文空间,确保智能体不会因为"健忘"或超出限制而中断任务。MemoryMiddleware:长期记忆中间件。配置了sources: ["./AGENTS.md"],意味着智能体在启动时会加载这个文件中的持久化指令或背景知识,确保跨会话的知识传承。SkillsMiddleware:技能中间件。配置了sources: ["./skills/"],它允许智能体按需动态加载特定领域的专业知识(Skills),而不是在启动时把所有知识都塞进上下文,从而极大节省了 Token 消耗。
总结
这段代码构建了一个高度工程化的智能体。它不仅具备搜索能力,还通过中间件机制实现了 "大结果卸载(Filesystem)" 、 "历史自动压缩(Summarization)" 、 "持久化知识注入(Memory)" 以及 "按需加载技能(Skills)" 。这种架构完美契合了现代 Agent 开发中的上下文工程(Context Engineering)理念,使其能够稳定、高效地处理超长、超复杂的任务。
规划与任务委派
复杂任务往往超出了单个上下文窗口所能处理的极限。通过"任务委派(Delegation)",主智能体可以将庞大的工作拆解为若干子任务,并交由在各自独立上下文中运行的子智能体(Subagents)去处理。这样一来,主智能体就能专注于全局统筹与协调,而非陷入具体的执行细节中。此外,这些子任务还可以并行推进,从而确保主智能体的上下文始终保持整洁与高效。
js
import { createAgent, todoListMiddleware, tool } from "langchain";
import {
createFilesystemMiddleware,
createSubAgentMiddleware,
StateBackend,
} from "deepagents";
import * as z from "zod";
const search = tool(({ query }) => `Search results for: ${query}`, {
name: "search",
description: "Search for a query and return a short summary.",
schema: z.object({ query: z.string() }),
});
const backend = new StateBackend();
const agent = createAgent({
model: "openai:gpt-5.4",
tools: [search],
middleware: [
createFilesystemMiddleware({ backend }),
todoListMiddleware(),
createSubAgentMiddleware({
defaultModel: "anthropic:claude-sonnet-4-6",
defaultTools: [],
subagents: [
{
name: "researcher",
description: "Searches and returns a structured summary.",
systemPrompt:
"Use the search tool to research the question and summarize key points.",
tools: [search],
model: "anthropic:claude-sonnet-4-6",
middleware: [],
},
],
}),
],
});这段代码展示了如何使用 deepagents 框架构建一个具备任务规划 和多智能体协作(Sub-agent Delegation) 能力的复杂 AI 智能体架构。
在这个架构中,主智能体(Orchestrator)负责统筹全局和分配任务,而具体的执行工作则被委托给拥有独立上下文的子智能体。
以下是代码的详细解析:
1. 导入依赖与定义工具
- 从
langchain导入了createAgent、todoListMiddleware(任务规划中间件)和tool工具函数。 - 从
deepagents导入了文件系统中间件、子智能体中间件以及内存状态后端。 - 使用
zod库定义了search工具的输入校验模式(Schema),确保传入的查询参数必须是字符串。
2. 初始化存储后端
const backend = new StateBackend();:创建了一个基于内存的临时文件系统后端,用于存储中间结果和任务状态。
3. 核心配置:中间件管道(Middleware Pipeline)
在 createAgent 中,通过挂载三个核心中间件,赋予了主智能体以下高级能力:
-
createFilesystemMiddleware({ backend }):赋予智能体虚拟文件系统能力。大型工具调用结果(如长文本搜索结果)会自动卸载到文件中,智能体上下文中仅保留轻量级的文件路径引用,从而避免上下文窗口溢出。
-
todoListMiddleware():任务规划引擎。强制智能体在行动前先生成一个结构化的待办事项列表(TodoList),将复杂目标拆解为可验证的原子步骤。这避免了智能体"拍脑袋决策"或随机探索,提高了长任务的执行成功率。
-
createSubAgentMiddleware({ ... }):子智能体协作机制。这是该代码的亮点,它配置了一个名为
researcher的子智能体:- 独立上下文:子智能体拥有独立的上下文窗口和工具集,执行结果会以摘要形式反馈给主智能体,彻底杜绝了上下文污染。
- 专属配置 :为子智能体指定了专用的模型(
anthropic:claude-sonnet-4-6)、系统提示词(systemPrompt)以及专属工具(search)。 - 分工协作 :主智能体可以通过内置的
task工具将研究任务委派给researcher,支持并行执行,大幅提升复杂任务的效率。
总结
这段代码构建了一个"主-子"架构的生产级智能体。主智能体使用 GPT-5.4 作为大脑,负责任务拆解(TodoList)和统筹;当遇到具体的研究任务时,它会将其委派给专门的 researcher 子智能体去执行搜索和总结。结合文件系统卸载机制,这种架构非常适合处理需要多步推理、大量信息检索的超长周期任务。
容错机制
在生产环境中,智能体(Agent)经常会遇到一些在开发阶段极少出现的故障,比如请求频率限制、模型响应超时以及瞬时的 API 错误等。容错中间件会在基础设施层面统一处理这些问题,这样你的工具和业务逻辑就不必在每次调用时都去写一堆 try/catch 错误捕获代码了。
js
import {
createAgent,
modelRetryMiddleware,
tool,
toolRetryMiddleware,
} from "langchain";
import * as z from "zod";
const search = tool(({ query }) => `Search results for: ${query}`, {
name: "search",
description: "Search for a query and return a short summary.",
schema: z.object({ query: z.string() }),
});
const agent = createAgent({
model: "openai:gpt-5.4",
tools: [search],
middleware: [
modelRetryMiddleware({ maxRetries: 3 }),
toolRetryMiddleware({ maxRetries: 2 }),
],
});这段代码展示了如何使用 langchain 框架为 AI 智能体构建高可用性与容错机制(Fault Tolerance) 。
在真实的工程环境中,大模型 API 调用可能会因为网络波动、限流(Rate Limit)或格式错误而失败。这段代码通过挂载两个重试中间件(Retry Middleware),赋予了智能体在遇到错误时自动恢复的能力,从而保证任务的连续性。
以下是代码的详细解析:
1. 导入依赖与定义工具
- 从
langchain导入了createAgent(创建智能体)、tool(定义工具)以及两个核心的重试中间件:modelRetryMiddleware和toolRetryMiddleware。 - 使用
zod库定义了一个名为search的搜索工具,并严格规定了其参数query必须为字符串类型。
2. 核心配置:容错中间件管道
在 createAgent 的配置中,通过 middleware 数组挂载了两个重试机制:
modelRetryMiddleware({ maxRetries: 3 }):
模型调用重试 。当智能体向底层大模型(这里是openai:gpt-5.4)发起推理请求时,如果因为网络超时、API 限流或服务端错误导致失败,该中间件会自动进行重试,最多尝试 3 次。这有效避免了因偶发的网络问题导致整个智能体流程中断。toolRetryMiddleware({ maxRetries: 2 }):
工具执行重试 。当智能体决定调用search工具,但工具在执行过程中抛出异常(例如搜索接口超时或返回了非预期格式的数据)时,该中间件会捕获错误并自动重试,最多尝试 2 次。这提高了智能体与外部世界交互时的鲁棒性。
总结
这段代码构建了一个具备自我修复能力的生产级智能体。它不再是一个"一碰就碎"的脆弱程序,而是能够在模型响应失败或工具执行出错时,按照预设的阈值自动进行重试。这种设计是构建稳定、可靠的 AI Agent 系统的最佳实践之一。
安全护栏(Guardrails)
有些策略是无法仅靠写在提示词(Prompt)里来约束的,它们必须被确定性地强制执行,无论模型做出什么反应。安全护栏会在数据流经智能体循环时进行拦截,在工具返回的结果进入模型上下文之前,提前应用合规规则或内容安全策略。
js
import { createAgent, piiMiddleware, tool } from "langchain";
import * as z from "zod";
const search = tool(({ query }) => `Search results for: ${query}`, {
name: "search",
description: "Search for a query and return a short summary.",
schema: z.object({ query: z.string() }),
});
const agent = createAgent({
model: "openai:gpt-5.4",
tools: [search],
middleware: [piiMiddleware("email")],
});这段代码展示了如何使用 langchain 框架为 AI 智能体配置数据隐私保护机制(PII Protection) 。
在企业级或面向公众的 AI 应用中,防止用户的个人敏感信息(PII,如邮箱、身份证号、信用卡号等)被意外发送给大模型是至关重要的安全合规要求。这段代码通过挂载 piiMiddleware,在数据流向模型之前自动拦截并处理敏感信息。
以下是代码的详细解析:
1. 导入依赖与定义工具
- 从
langchain导入了createAgent(创建智能体)、tool(定义工具)以及核心的piiMiddleware(个人身份信息中间件)。 - 使用
zod库定义了一个search搜索工具,并规定了其输入参数query必须是字符串类型。
2. 核心配置:隐私保护中间件
在 createAgent 的配置中,通过 middleware 数组挂载了隐私保护机制:
-
piiMiddleware("email"):这是一个专门用于拦截和脱敏邮箱地址的中间件。当用户的输入(或工具返回的结果)中包含电子邮件地址时,该中间件会在数据传递给底层大模型(
openai:gpt-5.4)之前进行自动处理。- 作用机制 :它通常会采用替换(Redact)、掩码(Mask)或阻断(Block)等策略。例如,将用户输入中的
user@example.com替换为[REDACT]或u***@example.com,从而确保大模型永远不会接触到真实的邮箱数据,从根本上防止了隐私泄露。
- 作用机制 :它通常会采用替换(Redact)、掩码(Mask)或阻断(Block)等策略。例如,将用户输入中的
总结
这段代码构建了一个具备隐私合规能力的智能体。通过在中间件层拦截敏感数据,它在享受大模型强大推理能力的同时,确保了用户隐私的安全。这种"输入前过滤"的设计模式是构建安全、可信赖 AI Agent 系统的核心最佳实践之一。
人工引导(Steering)
完全的自主性并不总是合适的。通过"人工引导",你可以将人类介入点设置在特定的决策环节------例如在执行破坏性写入、高成本 API 调用,或任何需要人工判断的操作之前------而无需重构你的智能体架构。在这种模式下,智能体会暂停并等待:由人类进行审批、修改或拒绝,随后智能体再继续执行后续操作。
js
import { createAgent, humanInTheLoopMiddleware, tool } from "langchain";
import * as z from "zod";
const search = tool(({ query }) => `Search results for: ${query}`, {
name: "search",
description: "Search for a query and return a short summary.",
schema: z.object({ query: z.string() }),
});
const agent = createAgent({
model: "openai:gpt-5.4",
tools: [search],
middleware: [humanInTheLoopMiddleware({ interruptOn: { writeFile: true } })],
});这段代码展示了如何使用 langchain 框架为 AI 智能体配置人机交互与人工审批机制(Human-in-the-Loop, HITL) 。
在高度自主的 AI 应用中,为了防止智能体在执行危险操作(如删除数据、写入文件、发送邮件等)时产生不可逆的后果,通常需要在关键节点引入人工监督。这段代码通过挂载 humanInTheLoopMiddleware,赋予了智能体在执行特定操作前"暂停并等待人类确认"的能力。
以下是代码的详细解析:
1. 导入依赖与定义工具
- 从
langchain导入了createAgent(创建智能体)、tool(定义工具)以及核心的humanInTheLoopMiddleware(人机交互中间件)。 - 使用
zod库定义了一个search搜索工具,并规定了其输入参数query必须是字符串类型。
2. 核心配置:人工审批中间件
在 createAgent 的配置中,通过 middleware 数组挂载了人机交互机制:
-
humanInTheLoopMiddleware({ interruptOn: { writeFile: true } }):这是该代码的核心配置。它定义了一个中断策略(Interrupt Strategy),告诉中间件在遇到特定工具调用时需要暂停执行。
-
interruptOn:这是一个映射配置,用于指定哪些工具需要人工介入。 -
writeFile: true:表示当智能体决定调用writeFile(写入文件)工具时,执行流程会被强制中断(暂停)。此时,智能体会向用户展示即将执行的操作详情,并等待人工决策。 -
人工决策类型:在暂停状态下,人类通常可以做出三种决策:
- 批准(Approve) :确认操作无误,允许智能体继续执行写入。
- 编辑(Edit) :修改智能体生成的参数(例如修改文件名或写入内容)后再执行。
- 拒绝(Reject) :取消该操作,智能体会收到拒绝反馈并调整后续策略。
-
总结
这段代码构建了一个具备安全控制与人工监督能力 的智能体。它将 search 等只读或低风险操作交由 AI 自主完成,但将 writeFile 等高风险的写操作交由人类把关。这种"AI 提议,人类审批"的设计模式,是构建生产级、高安全性 AI Agent 系统的核心最佳实践。
具体可参考 Middleware resources :
- Middleware overview: how the middleware stack works and when hooks fire
- Prebuilt middleware: full reference with configuration examples
- Custom middleware: write your own hooks for business logic, PII scrubbing, and more