目录
算法的效率
如何衡量一个算法的好坏?看看下面的这个斐波那契数列
cpp
long long Fib(int N)
{
if (N < 3)
return 1;
return Fib(N - 1) + Fib(N - 2);
}斐波那契数列的递归实现方式非常简洁,但简洁一定好吗?那该如何衡量其好与坏呢?
该递归代码效率极低。因为它会重复计算大量子问题。例如计算 Fib(5) 时:
-
Fib(4)和Fib(3)都要各自再递归展开,其中Fib(4)又会调用Fib(3)和Fib(2)...... -
导致同一个数值(如
Fib(3))被多次重复计算。
这种算法的时间复杂度是 O(2^N) (指数级),N=50 时已经慢到无法接受。空间复杂度是 O(N)(递归调用栈深度)。
相比之下,用循环或动态规划实现斐波那契,时间复杂度仅为 O(N),效率高得多。
简洁的不一定高效。衡量算法好坏,要分析其时间复杂度和空间复杂度,避免指数级爆炸的递归写法。
-
时间复杂度:运行时间随输入规模(N)的增长速度。比如递归斐波那契是 O(2^N),太慢。
-
空间复杂度:占用的额外内存随 N 的增长速度。递归版本因调用栈深度为 O(N),也较差。
算法的复杂度
算法在编写成可执行程序后,运行时需要耗费时间资源和空间(内存)资源 。因此衡量一个算法的好坏,一般 是从时间和空间两个维度来衡量的,即时间复杂度和空间复杂度
**时间复杂度主要衡量一个算法的运行快慢,而空间复杂度主要衡量一个算法运行所需要的额外空间。**在计算 机发展的早期,计算机的存储容量很小。所以对空间复杂度很是在乎。但是经过计算机行业的迅速发展,计 算机的存储容量已经达到了很高的程度。所以我们如今已经不需要再特别关注一个算法的空间复杂度
时间复杂度
概念
定义:在计算机科学中,算法的时间复杂度是一个函数 ,它定量描述了该算法的运行时间。一 个算法执行所耗费的时间,从理论上说,是不能算出来的,只有你把你的程序放在机器上跑起来,才能知 道
但是我们需要每个算法都上机测试吗?是可以都上机测试,但是这很麻烦,所以才有了时间复杂度这个 分析方式。一个算法所花费的时间与其中语句的执行次数成正比例,算法中的基本操作的执行次数,为算法 的时间复杂度。
即:找到某条基本语句与问题规模N之间的数学表达式,就是算出了该算法的时间复杂度
cpp
// 请计算一下Func1中++count语句总共执行了多少次?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < N; ++i)
{
for (int j = 0; j < N; ++j)
{
++count;
}
}
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}Func1 执行的基本操作次数 :
F(N)=N^2+2*N+10
N = 10 F(N) = 130
N = 100 F(N) = 10210
N = 1000 F(N) = 1002010
实际中我们计算时间复杂度时,我们其实并不一定要计算精确的执行次数,而只需要大概执行次数,那么这 里我们使用大O的渐进表示法。
大O的渐进表示法
大O符号(Big O notation):是用于描述函数渐进行为的数学符号。
推导大O阶方法:
1、用常数1取代运行时间中的所有加法常数。
2、在修改后的运行次数函数中,只保留最高阶项。
3、如果最高阶项存在且不是1,则去除与这个项目相乘的常数。得到的结果就是大O阶。
使用大O的渐进表示法以后,Func1的时间复杂度为:O(N^2)
N = 10 F(N) = 100
N = 100 F(N) = 10000
N = 1000 F(N) = 1000000
通过上面我们会发现大O的渐进表示法去掉了那些对结果影响不大的项,简洁明了的表示出了执行次数。
另外有些算法的时间复杂度存在最好、平均和最坏情况:
最坏情况:任意输入规模的最大运行次数(上界)
平均情况:任意输入规模的期望运行次数
最好情况:任意输入规模的最小运行次数(下界)
例如:在一个长度为N数组中搜索一个数据x
最好情况:1次找到
最坏情况:N次找到
平均情况:N/2次找到
在实际中一般情况关注的是算法的最坏运行情况,所以数组中搜索数据时间复杂度为O(N)
常见时间复杂度计算举例
实例1
基本操作执行了2N+10次,通过推导大O阶方法知道,时间复杂度为 O(N)
cpp
// 计算Func2的时间复杂度?
void Func2(int N)
{
int count = 0;
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
}实例2
基本操作执行了M+N次,有两个未知数M和N,时间复杂度为 O(N+M)
cpp
// 计算Func3的时间复杂度?
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++k)
{
++count;
}
for (int k = 0; k < N; ++k)
{
++count;
}
printf("%d\n", count);
}实例3
基本操作执行了10次,通过推导大O阶方法,时间复杂度为 O(1)
cpp
// 计算Func4的时间复杂度?
void Func4(int N)
{
int count = 0;
for (int k = 0; k < 100; ++k)
{
++count;
}
printf("%d\n", count);
}实例4.计算strchr的时间复杂度
strchr 的标准实现逻辑 ------即在一个字符串中顺序查找某个字符,最好情况是第一个字符就匹配(1次操作),最坏情况是遍历到末尾或找不到(N 次操作,N 为字符串长度)。时间复杂度一般看最坏。因此时间复杂度为 O(N)。
cpp
// 计算strchr的时间复杂度?
const char * strchr ( const char * str, int character );实例5.BubbleSort的时间复杂度
基本操作执行最好N次,最坏执行了(N*(N+1)/2次,通过推导大O阶方法+时间复杂度一般看最 坏,时间复杂度为 O(N^2):
最好情况 (数组已经有序):第一趟比较 N-1 次,发现没有交换,exchange 保持为 0,直接 break 退出循环。执行次数 = N-1,即 O(N)。
最坏情况 (数组完全逆序):每一趟都要比较和交换。比较次数:(N-1) + (N-2) + ... + 1 = N(N-1)/2,即 N(N-1)/2 ,忽略常数和低阶项后为 O(N²)。
时间复杂度一般看最坏 ,所以冒泡排序的时间复杂度为 O(N²)。
cpp
// 计算BubbleSort的时间复杂度?
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}实例6.BinarySearch的时间复杂度
基本操作执行最好1次,最坏O(logN)次,时间复杂度为 O(logN) ps:logN在算法分析中表示是底 数为2,对数为N。有些地方会写成lgN:
二分查找是在一个 有序数组 里找一个数 x。过程:
先看数组最中间的数 a[mid]
如果它等于 x,就找到了
如果 x 比它小,就只去 左边一半 继续找
如果 x 比它大,就只去 右边一半 继续找
重复以上步骤,直到找到或者区间缩小到没有数字为止
最好情况 :
如果你运气爆棚,第一次就猜中了中间那个数。那只需要 1 次 比较就结束了。所以最好时间复杂度是 O(1)。
最坏情况 :
要找的数在数组最边上,或者根本不在数组里。这时候你会一直缩小查找范围,直到范围变成空。
每次查找后,剩下的数字个数大约是 原来的一半:
刚开始有 n 个数字
第一次比较后,剩 n/2 个
第二次比较后,剩 n/4 个
第三次比较后,剩 n/8 个
...
直到最后剩下 1 个数字,再查一次就确定有没有。
问题来了:从 n 变成 1,你需要除以多少次 2?
这就是数学上的 对数。
假设 n = 16
16 → 8 → 4 → 2 → 1
除了 4 次 2,就到 1 了。
这 4 就是 log₂(16) = 4。
更一般地,需要比较的次数 ≈ log₂(n)。
所以最坏时间复杂度是 O(log N)(这里 log N 默认以 2 为底,但底数不重要,因为常数可以忽略)。
cpp
// 计算BinarySearch的时间复杂度?
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n - 1;
// [begin, end]:begin和end是左闭右闭区间,因此有=号
while (begin <= end)
{
//防止 (begin+end)/2 直接加可能会溢出(当 begin 和 end 都很大时)。
//>> 1 就是除以 2,位运算更快。不影响时间复杂度理解。
int mid = begin + ((end - begin) >> 1);
if (a[mid] < x)
begin = mid + 1;
else if (a[mid] > x)
end = mid - 1;
else
return mid;
}
return -1;
}实例7.阶乘递归Fac的时间复杂度
基本操作递归了N次,时间复杂度为O(N)。
cpp
// 计算阶乘递归Fac的时间复杂度?
long long Fac(size_t N)
{
if (0 == N)
return 1;
return Fac(N - 1) * N;
}实例8.斐波那契递归Fib的时间复杂度
基本操作递归了2^N次,时间复杂度为O(2^N):
递归函数:
如果 N < 3(也就是 N = 1 或 2),直接返回 1。
否则,它会调用自己两次:Fib(N-1) 和 Fib(N-2),然后把两个结果相加。例如:Fib(5) 会去问 Fib(4) 和 Fib(3),而每个又会继续往下拆,直到 Fib(1) 或 Fib(2) 为止。
为什么会很慢?因为 同一个中间结果会被重复计算无数次 。我们拿 Fib(5) 举例:

Fib(3) 被计算了两次。Fib(2) 被计算了三次。Fib(1) 被计算了两次。随着 N 增大,重复计算量 爆炸式增长。
每次函数调用,只要不是 N<3 的终止情况,它都会做一次加法(Fib(N-1) + Fib(N-2))。
我们近似数一数 函数调用的总次数。
第一层:调用 1 次(Fib(N))
第二层:调用 2 次(Fib(N-1)、Fib(N-2))
第三层:调用 4 次(Fib(N-2) 的两个子调用等)
第四层:调用 8 次
...
直到叶子节点(N=1 或 2)为止。
这像一个 满二叉树 ,大约有 2^N 量级的节点(严格来说,斐波那契递归树是接近 2^N,但不是精确满的,但大 O 只看数量级)
所以:基本操作(加法 + 递归调用)的次数 ≈ 2^N 级别。
最好情况:N 很小(比如 1 或 2),直接返回,O(1)。
最坏情况(也是我们要看的一般情况):N 较大时,递归调用次数 ≈ 2^N,所以 时间复杂度 = O(2^N)。
cpp
// 计算斐波那契递归Fib的时间复杂度?
long long Fib(size_t N)
{
if (N < 3)
return 1;
return Fib(N - 1) + Fib(N - 2);
}空间复杂度
空间复杂度也是一个数学表达式,是对一个算法在运行过程中临时占用存储空间大小的量度 。
空间复杂度不是程序占用了多少bytes的空间,因为这个也没太大意义,所以空间复杂度算的是变量的个数。 空间复杂度计算规则基本跟实践复杂度类似,也使用大O渐进表示法。
注意:函数运行时所需要的栈空间(存储参数、局部变量、一些寄存器信息等)在编译期间已经确定好了 ,因 此空间复杂度主要通过函数在运行时候显式申请的额外空间来确定。
实例1:计算BubbleSort的空间复杂度
使用了常数个额外空间,所以空间复杂度为 O(1):
额外开辟的变量只有:
end(循环控制)
exchange(标记是否发生交换)
i(内层循环控制)
这些变量数量固定 ,不会随着输入规模 n 变大而增多。无论 n 是 10 还是 10 万,额外内存始终是 几个字节 。因此:使用了常数个额外空间 → 空间复杂度 O(1)。
cpp
// 计算BubbleSort的时间复杂度?
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}实例2:计算Fibonacci的空间复杂度
动态开辟了N个空间,空间复杂度为 O(N):
空间复杂度分析:
动态开辟了一个长度为 n+1 的 long long 数组
数组占用的空间大小随输入 n 线性增长
除此之外,只用了常数个额外变量(i 等)
因此空间复杂度为 O(N)
cpp
// 计算Fibonacci的空间复杂度?
// 返回斐波那契数列的前n项
long long* Fibonacci(size_t n)
{
if (n == 0)
return NULL;
long long* fibArray = (long long*)malloc((n + 1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray[i - 2];
}
return fibArray;
}实例3:计算阶乘递归Fac的空间复杂度
cpp
long long Fac(size_t N)
{
if (N == 0)
return 1;
return Fac(N - 1) * N;
}递归调用了N次,开辟了N个栈帧,每个栈帧使用了常数个空间。空间复杂度为O(N)
这里顺便理一下什么是栈帧:
每个函数被调用时,计算机需要在内存中(栈区)记录一些信息:
函数的参数(比如 N 的值)
函数返回后要去哪里继续执行(返回地址)
函数的局部变量(这里没有)
这块记录信息的内存区域,就叫做"栈帧"。
可以把栈帧想象成一张"任务纸条":
调用函数时,写一张纸条压在一摞纸条的最上面。
函数返回时,把最上面的纸条扔掉,回到上一张纸条记录的位置。
当你调用 Fac(3) 时,它会这样执行:
Fac(3)调用Fac(2),等待Fac(2)的结果
Fac(2)调用Fac(1),等待Fac(1)的结果
Fac(1)调用Fac(0),等待Fac(0)的结果
Fac(0)返回 1然后
Fac(1)用 1 * 1 = 1 返回
Fac(2)用 1 * 2 = 2 返回
Fac(3)用 2 * 3 = 6 返回
调用 Fac(3) 时,栈帧的变化如下:
| 时刻 | 栈中的栈帧(从上到下) | 深度 |
|---|---|---|
| 刚开始 | 空 | 0 |
| 调用 Fac(3) | Fac(3) | 1 |
| Fac(3) 调用 Fac(2) | Fac(2) → Fac(3) | 2 |
| Fac(2) 调用 Fac(1) | Fac(1) → Fac(2) → Fac(3) | 3 |
| Fac(1) 调用 Fac(0) | Fac(0) → Fac(1) → Fac(2) → Fac(3) | 4 |
| Fac(0) 返回 | 删除 Fac(0) | 3 |
| Fac(1) 返回 | 删除 Fac(1) | 2 |
| Fac(2) 返回 | 删除 Fac(2) | 1 |
| Fac(3) 返回 | 空 | 0 |
关键点 :在 最深 的时刻(Fac(0) 刚被调用但还没返回),栈里有 4 个栈帧(N=3 时深度为 4)。
-
当参数为 N 时,递归会一直调用到 N=0
-
所以最多同时存在的栈帧个数 = N + 1(从 N 到 0 一共 N+1 层)
每一层栈帧占用的空间是 常数 (因为只存参数 N 和返回地址等固定大小的信息)。
那么总占用的额外空间 = (N+1) × 常数 ≈ N × 常数 。在算法分析中,常数忽略,只关心规模 N,所以空间复杂度为 O(N)。
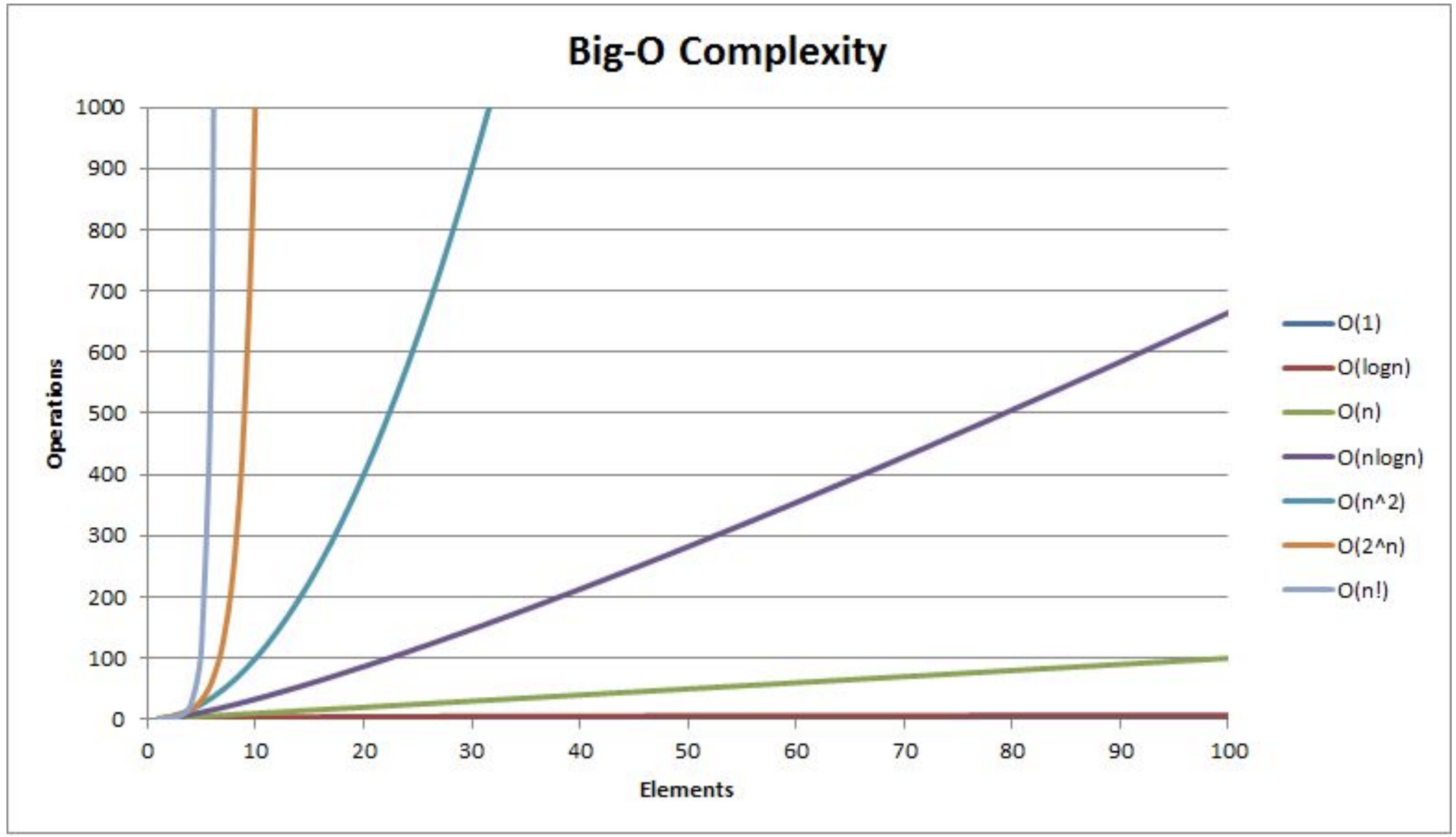
常见复杂度对比
一般算法常见的复杂度如下:
| 表达式 | 大O表示 | 阶名称 |
|---|---|---|
| 5201314 | O(1) | 常数阶 |
| 3n + 4 | O(n) | 线性阶 |
| 3n² + 4n + 5 | O(n²) | 平方阶 |
| 3log₂ n + 4 | O(log n) | 对数阶 |
| 2n + 3n log₂ n + 14 | O(n log n) | n log n 阶 |
| n³ + 2n² + 4n + 6 | O(n³) | 立方阶 |
| 2ⁿ | O(2ⁿ) | 指数阶 |