摘要
云服务器地域选择不能只看云厂商价格,也不能只凭经验判断"用户大概在哪"。当业务访问量上来后,企业更需要基于真实访问日志判断用户来源,再决定主站、静态资源、API服务和灾备节点应该部署在哪些地域。本文围绕离线IP数据库和离线IP数据库部署,拆解云服务行业如何用本地IP解析能力优化服务器位置部署。
一、为什么服务器地域选择要看真实访问来源
云服务部署常见问题是:业务团队按总部所在地开服,后来才发现主要用户来自华东、华南或海外;或者所有请求都打到单一区域,导致跨地域访问延迟高、带宽成本高、故障影响范围大。
CNNIC第57次《中国互联网络发展状况统计报告》显示,截至2025年12月,我国网民规模达11.25亿人,互联网普及率达80.1%;我国5G基站已建成483.8万座,智能算力规模超过1590EFLOPS。用户规模、移动网络和算力设施同时增长,意味着应用服务需要更重视地域分布和访问体验。
Gartner预测,2025年全球公有云终端用户支出将达到7234亿美元,同比增长21.5%;同时,90%的组织将在2027年前采用混合云。对企业来说,多地域、多云、混合云部署会越来越常见,地域选择需要有数据支撑。
二、离线IP数据库适合解决什么问题
在线IP接口适合实时查询,离线IP数据库更适合高并发、本地化、批量日志分析和内部系统部署。比如云服务商、SaaS平台、游戏后台、电商系统每天产生大量访问日志,如果每条日志都调用远程接口,成本和延迟都会增加。
离线IP数据库部署后,企业可以在本地完成IP解析,把访问IP转换成国家、省份、城市、运营商等字段,再与访问量、响应时间、错误率、带宽消耗做关联分析。
典型使用方式包括:
- 统计用户主要来源城市,判断主服务器地域;
- 分析跨区域访问延迟,决定是否增加边缘节点;
- 按运营商维度观察线路质量,优化CDN或BGP线路;
- 对历史日志做批量回放,评估迁移前后的部署策略。
三、应用场景:云服务器地域怎么选
以一家SaaS企业为例,早期服务部署在华北区域,运维团队发现华南用户反馈接口响应慢,但监控只看到平均延迟,没有清楚说明用户从哪里来。
接入离线IP数据库后,团队对近30天Nginx日志做批量解析,发现华东和华南访问量合计占比较高,其中华南地区移动端访问增长明显。进一步结合接口耗时发现,华南用户访问核心API的P95延迟明显高于华北用户。
这时部署策略就比较清晰:主服务可迁移到更接近核心用户的地域,静态资源交给CDN,华南增加只读缓存或API加速节点,华北保留灾备。像IP数据云这类服务提供的离线数据能力,可以用于支撑访问来源分析和部署评估。
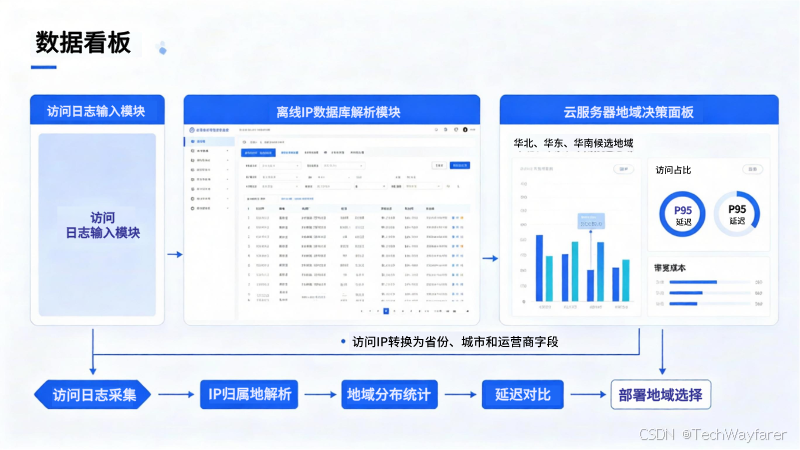
用户访问来源分析-离线IP数据库辅助云服务器地域决策示意图
四、代码实操:用离线IP数据库分析访问来源
下面示例演示如何用本地离线IP数据库解析访问日志,并输出用户来源城市排行。示例使用CSV格式,生产环境可替换为二进制离线库或私有化部署版本。
离线库示例字段:start_ip,end_ip,country,province,city,isp
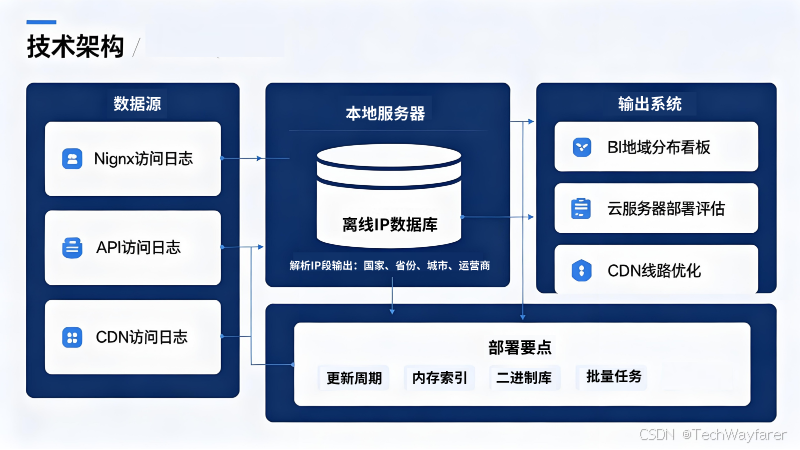
离线IP数据库部署-访问日志分析与云服务器优化架构图
python
import csv
import ipaddress
from bisect import bisect_right
from collections import Counter
def ip_to_int(ip):
return int(ipaddress.ip_address(ip))
def load_ip_database(path):
ranges = []
with open(path, newline="", encoding="utf-8") as file:
reader = csv.DictReader(file)
for row in reader:
try:
ranges.append({
"start": ip_to_int(row["start_ip"]),
"end": ip_to_int(row["end_ip"]),
"country": row.get("country", ""),
"province": row.get("province", ""),
"city": row.get("city", ""),
"isp": row.get("isp", "")
})
except (KeyError, ValueError):
continue
ranges.sort(key=lambda item: item["start"])
starts = [item["start"] for item in ranges]
return ranges, starts
def lookup_ip(ip, ranges, starts):
try:
ip_num = ip_to_int(ip)
except ValueError:
return None
index = bisect_right(starts, ip_num) - 1
if index < 0:
return None
matched = ranges[index]
if matched["start"] <= ip_num <= matched["end"]:
return matched
return None
def parse_access_log_ip(line):
parts = line.split()
if not parts:
return ""
return parts[0]
def analyze_access_source(log_path, ipdb_path, top_n=10):
ranges, starts = load_ip_database(ipdb_path)
city_counter = Counter()
province_counter = Counter()
with open(log_path, encoding="utf-8") as log_file:
for line in log_file:
ip = parse_access_log_ip(line)
location = lookup_ip(ip, ranges, starts)
if not location:
continue
province = location.get("province") or "unknown"
city = location.get("city") or "unknown"
province_counter[province] += 1
city_counter[f"{province}-{city}"] += 1
return {
"top_provinces": province_counter.most_common(top_n),
"top_cities": city_counter.most_common(top_n)
}
if __name__ == "__main__":
result = analyze_access_source(
log_path="access.log",
ipdb_path="offline_ip_database.csv",
top_n=10
)
print("主要省份:")
for province, count in result["top_provinces"]:
print(province, count)
print("主要城市:")
for city, count in result["top_cities"]:
print(city, count)这段代码适合用于日志分析任务,不建议直接放在请求链路中逐行读CSV。生产环境中可以把离线库加载为常驻内存结构,或使用二进制库文件,提高查询速度。若访问量很大,还可以按小时汇总日志,再进入BI系统生成地域分布看板。
五、离线IP数据库部署建议
离线IP数据库部署时,要注意三个问题。
第一,更新周期。IP分配会变化,数据库需要按日、周或月更新,避免长期使用旧数据导致地域判断偏差。
第二,查询性能。高并发服务应避免每次请求读取文件,建议服务启动时加载索引,或使用本地二进制库。
第三,部署边界。IP归属地适合做区域级判断,不适合写成对单个用户的精确位置识别。服务器地域选择应结合访问量、延迟、成本、合规、灾备和业务优先级综合决策。
总结
云服务器地域选择,本质是用真实访问数据决定资源应该离用户多近。离线IP数据库可以把访问日志中的IP转成省份、城市、运营商等结构化字段,帮助企业判断主部署地域、边缘节点、CDN策略和灾备布局。
对云服务和SaaS平台来说,离线IP数据库部署不是单纯的数据接入,而是把访问来源分析纳入容量规划、网络优化和成本控制流程。IP数据云可作为本地化IP解析能力的一部分,辅助企业更稳定地完成服务器位置部署评估。
数据来源
CNNIC:第57次《中国互联网络发展状况统计报告》
Gartner:Worldwide Public Cloud End-User Spending Forecast, 2024-2025