Plant genome data sharing: A call toward fully open access
植物基因组数据共享:呼吁全面开放获取

自 2000 年首个植物基因组发布以来,全球已有1500 余种植物完成基因组测序与组装(谢等人,2024)。这些基因组资源推动了植物生物学与进化领域的研究发展,目前更是成为功能基因组学、群体遗传学、进化分析、作物改良及相关研究方向的重要基础(马克斯等人,2021;宋等人,2023;谢等人,2024)。已有研究梳理了植物基因组研究的发展历程、组装质量与现存技术难题(克西,2019;克雷斯等人,2022;孙等人,2022),同时也提出相关规范,旨在提升数据价值与研究可重复性(博格曼,2012;柯林斯、塔巴克,2014;伯德等人,2020)。
但目前,数据获取壁垒 与共享标准不统一 等问题,仍阻碍着基因组资源的充分复用,也降低了研究可重复性,部分情况甚至违背了数据可发现、可访问、可互操作、可重用的FAIR 原则(威尔金森等人,2016)。因此,有必要对当前植物基因组数据的共享现状开展系统性评估,保障数据可被可靠复用,最大化其科研价值。
为解决上述问题,本研究依托植物基因组数据库 PubPlant,筛选2018---2024 年 发表的 1717 篇植物基因组相关论文开展数据共享现状调研。该时间段涵盖了基因组测序技术与数据共享规范的最新发展。研究统计了原始测序读段、基因组组装序列及基因注释文件的公开情况,结果显示,目前数据公开仍存在明显短板:40.83% 的论文未能将上述三类数据全部对外公开。其中基因注释数据的公开情况最差,未公开占比达 34.07%;原始测序数据与基因组组装序列的未公开占比分别为 16.07% 和 13.28%(图 1A、附表 1)。
理论上,研究人员可基于原始测序数据重新完成基因组组装与基因注释,但受软件版本、参数设置、分析流程等因素影响,很难完全复现已发表的结果;同时,重新运行整套分析流程,还需要普通使用者难以具备的计算资源与专业技术。本文在补充材料中列举了典型案例,直观说明复现工作面临的各类难题(补充方法 1、附表 2)。
本研究还尝试联系论文通讯作者,索取未公开的数据集,结果显示近 70% 的数据申请未能成功 (附表 3),反映出论文发表后获取相关基因组资源的难度极大。此外,2018 至 2024 年的数据公开率虽逐年波动,但整体未见持续改善趋势(图 1B、附表 4),说明植物基因组数据公开不足仍是长期存在的问题。
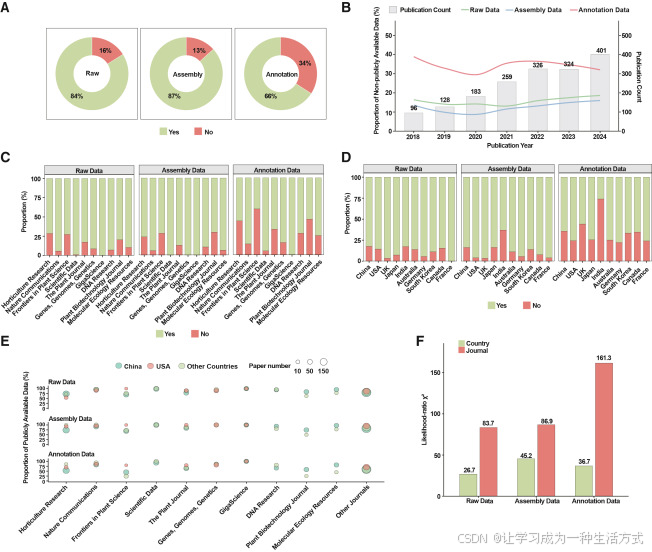
图 1 植物基因组相关论文的数据共享现状总览
(A) 数据集公开与未公开占比。红色(标注 "未公开")代表数据未对外公开的比例,绿色(标注 "已公开")代表数据对外公开的比例。 (B) 2018---2024 年未公开数据的年度变化趋势。横轴为发表年份,左侧纵轴代表未公开数据占比,右侧纵轴代表论文数量。绿色、蓝色、红色曲线分别对应原始测序数据、基因组组装数据、基因注释数据的未公开比例;柱状图上方数字为对应年份的论文总数。 (C) 发文量排名前十期刊的数据公开情况。横轴为期刊名称(按发文总量排序),纵轴为原始测序、组装、注释三类数据集的公开占比。红色代表数据未公开,绿色代表数据已公开。 (D) 发文量排名前十国家的数据公开情况。横轴为国家名称(按发文总量排序),纵轴为原始测序、组装、注释三类数据集的公开占比。红色代表数据未公开,绿色代表数据已公开。 (E) 气泡图:发文量前十期刊与国家的数据公开情况汇总。三张子图分别对应三类数据。横轴为期刊(按发文量排序),纵轴为数据公开率。气泡大小对应各 "期刊 - 国家" 组合的论文数量,颜色区分国家组别(中国、美国及其他国家)。为保证样本量,中国与美国单独统计,其余国家合并归类;图中仅展示论文数大于 5 的组别。 (F) 似然比检验对比国家 与期刊 两大因素的解释力。针对原始数据、组装数据、注释数据三类样本,成对柱状图展示基于菲尔兹校正多元逻辑回归模型 (数据公开情况~国家 + 期刊)计算得到的似然比卡方统计量。卡方值反映剔除某一变量后模型偏差的变化幅度,数值越大,说明该因素对数据公开率差异的解释能力越强。卡方精确值及对应P值详见附表 9。
研究发现,不同期刊、不同国家的论文,其数据公开情况存在显著差异。例如《植物科学前沿》期刊中,基因注释数据未公开比例达 59.6%,原始测序数据与基因组组装数据未公开比例分别为 27.3% 和 28.3%;《园艺研究》的数据未公开率同样偏高。与之相反,《GigaScience》《科学数据》与《自然・通讯》等期刊始终保持较高的数据公开水平,原始测序数据与组装数据尤为突出(图 1C、附表 5)。
从第一作者所属国家来看,印度发表的论文中三类数据未公开比例均处于高位,其中注释数据未公开率接近 75%。法国、德国、美国的数据公开情况整体更优,约 80% 的注释数据可公开获取(图 1D、附表 6)。中国发文量最大,共计 997 篇,数据公开整体处于中等水平,但不同期刊间表现差异显著(图 1E)。
为探究影响三类基因组数据公开的相关因素,本研究开展了一系列统计学分析(附表 7--12)。列联分析(附图 1、附表 8)与气泡图(图 1E)结果显示,同一期刊内部的数据公开率相对稳定,但同一国家内不同期刊之间差异极大 。为验证该规律,本研究构建纳入国家、期刊(分别划分为前十及其他组别)的菲尔兹校正多元逻辑回归模型,并通过似然比检验对比两者解释力(附表 9)。结果表明,针对三类数据,期刊对数据公开情况的影响均显著大于国家(图 1F、附表 9)。
除期刊与国家外,物种分类阶元(科、目)也与数据公开率存在潜在关联,但该相关性仅在注释数据中达到统计学显著水平(附表 10、11)。本研究将基因组大小作为基因组复杂度的参照指标,分析发现其并未对数据公开情况产生明显影响(附表 12、附图 2)。
针对当前植物基因组数据共享面临的严峻问题,本文呼吁科研领域六大相关主体协同行动,推动基因组数据全面开放共享,六大主体分别为:期刊、政策制定机构、数据库平台、论文作者、审稿人与科研读者。
期刊
明确要求并严格落实数据公开规则:期刊应规定作者将所有配套基因组数据(原始测序读段、组装序列、基因注释文件),以及必要的重测序数据、表型数据完整提交至权威公共数据库。数据可用性声明中必须填写有效检索号或其他永久标识符。 若数据集设置延期公开,期刊需要求作者在投稿阶段上传数据备案证明,包括检索编号、数据访问链接、审稿专用链接等,便于编辑与审稿人在同行评审阶段核验数据真实存在。编辑部还需核查检索编号是否可正常访问;必要时,将 "论文发表后同步公开数据" 作为稿件最终录用的条件。 《GigaScience》等期刊已率先推行数据强制存档规则,并对违规行为作出明确约束,有效解决了本研究发现的数据缺失、检索号无效等问题,也为提升数据公开率提供了可借鉴的实践标准。
政策制定机构
1. 制定并推行数据共享指导政策
各国政府与科研资助部门应完善并落实开放数据相关政策,明确数据共享对科研发展的核心价值。欧洲开放科学云等项目已证明,统筹的政策、资金与跨国协作能够有效推动科研数据开放。 配套政策需为核心数据库提供长期稳定经费,支撑数据提交工具、专业审核人员、安全归档存储等运维工作,保障数据共享政策落地且可持续。发文量较大的国家(如中国)应持续建设本土数据库(如国家基因组科学数据中心),保障其长期运维。此类投入不仅能提升数据曝光度、促进国际合作,更能让数据共享全面契合 FAIR 数据原则(威尔金森等人,2016)。
2. 将数据共享纳入项目资助考核要求
以国家自然科学基金委员会为代表的科研资助机构,已逐步强化项目申报中的数据共享要求,未来需进一步完善相关规则。项目申请书必须附上完整的数据管理与共享方案,明确共享数据类型、存档平台与公开时间。 同时建立合规监管机制,在保护涉密信息的前提下,保障优质数据及时对外公开。美国国家科学基金会的管理模式具有参考价值:要求申请人在提交项目时同步附上数据管理方案,并明确项目结题后的数据共享要求。将数据共享纳入项目评审与后续监管体系,可引导科研人员及时、规范地公开研究数据。
数据库平台
1. 强化全球数据整合与互操作性
数据库应采用通用标准格式(如 FASTA、GFF),制定透明统一的数据提交与审核流程,以此推动数据开放。各数据库之间需积极协作、同步数据,实现全球数据互通。 由美国国立生物技术信息中心 GenBank、欧洲核苷酸档案库、日本 DNA 数据库共同组成的国际核苷酸序列数据库协作组(INSDC),是国际协同维护核苷酸序列数据全面性与可访问性的典范。将此类协作模式推广至更多数据库,可进一步提升数据检索与复用效率,助力跨领域研究。
2. 简化数据提交流程
目前基因注释数据提交流程繁琐,是其公开率偏低的重要原因。主流数据库的注释提交往往涉及格式转换、多轮校验(如 GenBank),增加了科研人员的负担。 数据库需优化注释文件的提交工具与流程,增设引导式校验功能、标准化模板;同时搭建面向科研人员的配套服务,如专人协助数据审核、参考生物信息学平台 Galaxy 的馆员式支持模式,降低格式转换难度,提升数据提交成功率。
3. 保障数据长期完整与可访问性
数据库需搭建稳定的长期存储与运维体系,确保数据永久可查。定期更新维护、使用稳定标识符、搭建永久访问页面,可有效避免本研究发现的链接失效、访问异常等问题。即便技术、标准与存储平台迭代升级,持续的运维管理也能最大限度降低数据丢失风险。
论文作者
1. 践行开放科学理念
论文作者是保障研究可重复性与透明度的第一责任人。投稿前或投稿期间,需将全套数据集(原始读段、组装序列、注释文件,以及配套重测序、表型数据)提交至正规公共数据库。 同时附上完整的质控说明,包括基因组组装关键指标、BUSCO 评估结果等,并准确填写数据检索号与访问链接,避免本研究发现的各类填报错误(附表 2)。
2. 优先选择可持续的权威数据库
作者应优先选择覆盖面广、运维稳定的主流公共数据库(如国际核苷酸序列数据库协作组、国家基因组科学数据中心)存档数据。数据存入标准化权威平台,才能够被后续整合至 Ensembl、Phytozome、PLAZA 等综合数据库,借助其标准化注释、基因组浏览器、比较分析工具,进一步提升数据检索率与复用价值。 实验室自建数据库可满足特定使用需求,但仅能作为补充,不可替代中心化公共数据库,否则难以保障数据长期访问与跨平台互通。
审稿人
1. 核验数据的完整性与可访问性
同行评审阶段,审稿人需核查论文配套的原始读段、组装序列(尤其是注释数据)是否完整公开、符合行业规范;验证检索编号能否正常访问,条件允许时核验数据基本完整性。 同时检查论文是否提供完善的质控信息,以此判断存档数据是否达标、能否支撑后续研究复用。
2. 坚守数据共享标准
若发现数据未公开、数据质量不达标或信息填报错误,审稿人应明确指出问题,要求作者补齐数据、修正错误,并将其作为稿件录用的必要条件。本研究发现,论文发表后再索取缺失数据的成功率极低(附表 3),因此审稿环节的严格把关,对保障数据长期可用、维持研究可重复性至关重要。
科研读者
1. 规范引用,尊重数据产出成果
使用公开基因组数据时,需规范引用原始文献与数据来源。规范引用既是对数据产出团队成果的认可,也符合学术伦理与行业规范。
2. 助力完善数据共享体系
科研人员在自身研究中优先选用公开数据集;若发现已发表论文存在链接失效、数据库无法访问等问题,及时向期刊或数据库管理员反馈;同时在所属机构与学术圈内积极倡导开放数据理念,共同完善数据共享生态。
综上,本研究量化分析了当前植物基因组数据在开放共享层面存在的显著短板,尤以注释数据问题最为突出;明确了阻碍数据高效共享的各类现状与影响因素,也凸显了推进改革的紧迫性。 完善数据共享体系并非锦上添花,而是植物基因组学未来发展的必要基础。实现这一目标,需要政策制定机构、数据库、期刊、作者、审稿人、科研读者多方协同发力。搭建开放、透明、高效的数据共享体系离不开全体科研人员的长期共同努力,而这也将充分释放植物基因组学的科研潜力。