SQL 查询终极高阶通鉴:从零基础拆解到工业级多表联查、窗口函数与索引优化
在攻克了 B+ 树索引与 MVCC 事务这两大底层"内功"后,今天我们重新回到"招式"的层面。
在后端开发的世界里,有一句黑话叫"万物皆可 SQL"。无论是单机几万条数据的轻量应用,还是云原生分布式架构下结构复杂的数仓分析,查询(SELECT) 永远占了日常业务的 90% 以上。
为了让你写出的每一行 SQL 见字如面、精准命中 B+ 树索引,同时能完美应对工业级复杂的业务诉求,本期我们将开启一场只增不减、由浅入深的迭代升级之旅。我们将从零基础关键字拆解开始,使用一套统一的工业级生产数据,一路杀到多表联查、窗口函数与索引失效的雷区阵地。
一、 兵器谱大阅兵:SQL 核心关键字的"字面意图"与概念打底
在看复杂的长 SQL 之前,初学者必须先在脑海中对 SQL 常用单词建立起机械性的条件反射。SQL 并不是晦涩的密码,它是一套极其接近英语口语的声明式语言。
下面是我们在接下来的高阶实战中,高频调遣的"黄金兵器谱":
1. 基础数据摘取与过滤
SELECT(我要拿什么) :后面紧跟你要从数据库里挑出来的列名。如果写SELECT *,代表"全都要,把所有列都给我搬出来"。FROM(我去哪里拿):后面紧跟目标数据表的名称,告诉 MySQL 去哪张"Excel表格"里提货。WHERE(单行安检过滤器) :后面紧跟过滤条件。MySQL 在扫描表格时,会拿着这个条件对着每一行记录进行盘问,满足条件的放行,不满足的当场杀掉。LIKE(模糊匹配关键字) :用于字符串搜索。配合通配符%使用(%代表任意长度的任意字符)。例如'张%'代表"必须以张开头,后面是什么我不管";'%张'代表"前面是什么不管,必须以张结尾"。BETWEEN ... AND ...(闭区间范围筛选) :数值或日期的连续范围过滤。例如age BETWEEN 20 AND 30相当于age >= 20 AND age <= 30,两头都包含。
2. 多表联查与集合判定
JOIN ... ON ...(横向拼表传送带) :用于将两张完全不同的表横向拼接。JOIN后面跟第二张表,ON后面跟两条表的关联纽带(如员工表的部门ID = 部门表的主键ID)。IN(孤立值集合圈定) :后面通常跟一个括号列表或子查询结果。只要字段的值落在这个圈子范围内,即算通过。例如dept_id IN (1, 2, 3)。EXISTS(存在性探测探针) :后面跟一个子查询。它不关心子查询捞出来什么具体数据,它只关心"内层子查询能不能查出结果"。只要能查出至少一行,外层条件就成立。
3. 高级统计、控制与排序
GROUP BY(数据切块切堆):按照某一列的特征,把原本扁平的几万条数据切成一个一个的小堆(如按性别、按部门切块),以便对每个小堆进行整体统计。HAVING(聚合小堆总体特征过滤器) :注意它和 WHERE 的天壤之别!WHERE针对的是单行,而HAVING必须跟在GROUP BY后面,针对的是切好块之后的"小堆总体特征"(如:过滤出"平均薪资大于 10000"的那个部门小堆)。ORDER BY(最终排队次序) :对最后留下来的结果集进行排序。后面跟ASC代表升序(从小到大),跟DESC代表倒序/降序(从大到小)。LIMIT(斩断截取器) :做分页或数量控制。LIMIT 5代表"不管前面有多少万条,我只要最终的前 5 条"。
二、 统一宇宙:工业级实战双表环境构建(循序渐进的数据源)
为了让所有的进阶查询、多表联查以及窗口函数拥有完全闭环、可推演的真实上下文,我们在此亲手建立一套统一的工业级生产数据源。请在你的本地 MySQL 中无脑复制执行以下建表与数据插入语句:
1. 盖楼建表与初始数据灌入(SQL 源码)
sql
-- 创建数据库
CREATE DATABASE IF NOT EXISTS company_db;
USE company_db;
-- 1. 创建部门表 (departments)
CREATE TABLE IF NOT EXISTS departments (
id INT AUTO_INCREMENT PRIMARY KEY,
dept_name VARCHAR(50) NOT NULL UNIQUE
);
-- 2. 创建员工表 (employees)
CREATE TABLE IF NOT EXISTS employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
dept_id INT,
salary INT NOT NULL,
status VARCHAR(20) NOT NULL, -- 'active' 或 'inactive'
phone VARCHAR(20),
hire_date DATE NOT NULL
);
-- 3. 灌入部门表初始数据
INSERT INTO departments (id, dept_name) VALUES
(1, '研发部'),
(2, '市场部'),
(3, '财务部'),
(4, '空闲无员部'); -- 这个部门故意不安排任何员工,用于LEFT JOIN测试
-- 4. 灌入员工表初始数据
INSERT INTO employees (id, name, dept_id, salary, status, phone, hire_date) VALUES
(1, '张大', 1, 20000, 'active', '13800000001', '2026-01-10'),
(2, '张二', 1, 18000, 'active', '13800000002', '2026-02-15'),
(3, '张三', 1, 15000, 'active', '13800000003', '2026-03-01'),
(4, '李大', 2, 25000, 'active', '13800000004', '2025-05-20'),
(5, '李二', 2, 12000, 'active', '13800000005', '2025-08-11'),
(6, '王老五', 3, 9000, 'inactive', '13911111111', '2024-01-01'), -- 已离职员工
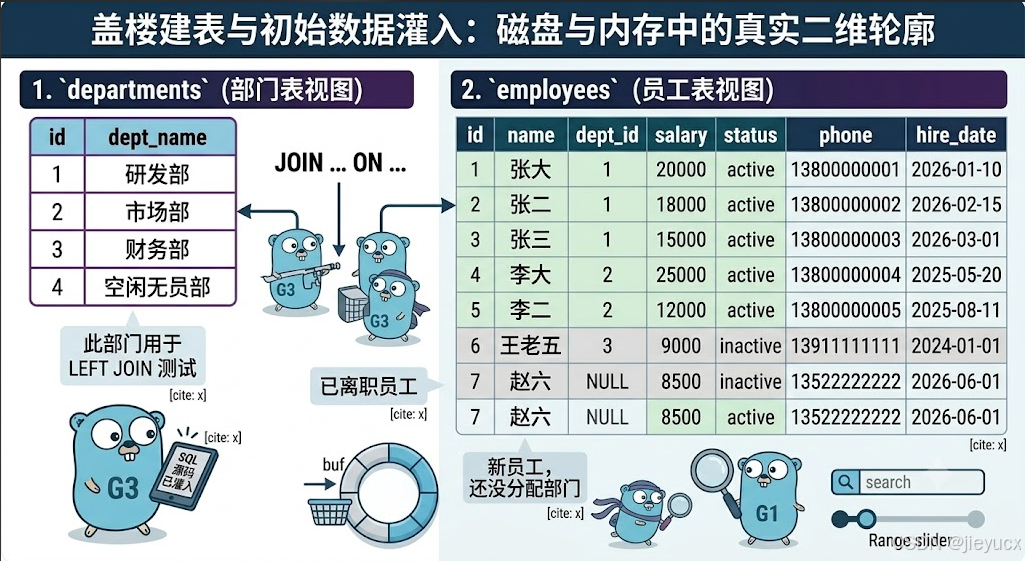
(7, '赵六', NULL, 8500, 'active', '13522222222', '2026-06-01'); -- 新员工,还没分配部门2. 数据在数据库中的真实二维轮廓
执行完毕后,两张表在磁盘与内存中的真实轮廓如下。请在后续阅读所有查询示例时,随时返回此处在脑海中进行数据比对:
① departments(部门表视图)
text
+----+------------+
| id | dept_name |
+----+------------+
| 1 | 研发部 |
| 2 | 市场部 |
| 3 | 财务部 |
| 4 | 空闲无员部 |
+----+------------+② employees(员工表视图)
text
+----+--------+---------+--------+----------+-------------+------------+
| id | name | dept_id | salary | status | phone | hire_date |
+----+--------+---------+--------+----------+-------------+------------+
| 1 | 张大 | 1 | 20000 | active | 13800000001 | 2026-01-10 |
| 2 | 张二 | 1 | 18000 | active | 13800000002 | 2026-02-15 |
| 3 | 张三 | 1 | 15000 | active | 13800000003 | 2026-03-01 |
| 4 | 李大 | 2 | 25000 | active | 13800000004 | 2025-05-20 |
| 5 | 李二 | 2 | 12000 | active | 13800000005 | 2025-08-11 |
| 6 | 王老五 | 3 | 9000 | inactive | 13911111111 | 2024-01-01 |
| 7 | 赵六 | NULL | 8500 | active | 13522222222 | 2026-06-01 |
+----+--------+---------+--------+----------+-------------+------------+
三、 SQL 查询的"灵魂内核":执行顺序与书写顺序的错位
初学者写查询最容易犯的错误,就是以为 SQL 是按照我们书写的顺序从左到右执行的。其实不然,MySQL 内核在解析 SQL 时,有着一套极其严格且完全倒置的执行顺序 。只有看清这个顺序,你才不会在 WHERE 里误用 AS 别名,也不会在 HAVING 和 WHERE 之间产生混乱。
| 书写顺序(你看到的) | 执行顺序(MySQL 内核看到的) | 内核在干什么 |
|---|---|---|
SELECT ... |
4. SELECT 之后确定返回哪些列 |
摘取最终需要的字段,计算表达式和别名。 |
FROM ... |
1. FROM(包括 JOIN) |
先找到这几张表,通过笛卡尔积或关联,拉出一张巨型的临时虚拟表。 |
WHERE ... |
2. WHERE 过滤 |
第一道单行安检。顺着 B+ 树索引或全表扫描,把不符合条件的行无情杀掉。 |
GROUP BY ... |
3. GROUP BY 分组 |
把通过安检的数据,按照某些特征切成一个一个的小堆(聚合)。 |
HAVING ... |
3.1 HAVING 过滤 |
第二道聚合安检 。只针对分组聚合后的小堆总体特征进行过滤。 |
ORDER BY ... |
5. ORDER BY 排序 |
在内存(Sort Buffer)或磁盘中,对最终结果集进行排序。 |
LIMIT ... |
6. LIMIT 分页截断 |
裁切出最后需要的几行,打包扔给客户端。 |
核心死记硬背(踩坑警示) :
WHERE运行在GROUP BY之前,所以WHERE后面绝对不能写聚合函数(如SUM/AVG) ;而SELECT运行在WHERE之后,所以WHERE里面绝对不能使用SELECT里定义的别名!
四、 基础与进阶查询场景:单表里的"闪电战"
现在,我们派出上述学到的基础兵器,对着我们统一的 employees 表进行由浅入深的单表查询演练。
1. 范围与模糊匹配(电商筛选/搜索场景)
- 业务诉求:在员工表里,筛选出薪资在 10000 到 20000 之间,且名字以"张"开头的在职(active)员工。
sql
SELECT id, name, salary
FROM employees
WHERE salary BETWEEN 10000 AND 20000
AND status = 'active'
AND name LIKE '张%';真实运行结果输出:
text
+----+--------+--------+
| id | name | salary |
+----+--------+--------+
| 1 | 张大 | 20000 |
| 2 | 张二 | 18000 |
| 3 | 张三 | 15000 |
+----+--------+--------+- 💡 性能大优化的精髓 :
LIKE '张%'(前缀匹配)由于指明了开头的字符,可以极其完美地命中name列未来可能建立的 B+ 树索引;但如果你在线上写成LIKE '%张'(后缀匹配),MySQL 优化器将彻底放弃索引,被迫退化为极度消耗磁盘 I/O 的全表扫描!
2. 分组聚合与统计(运营报表场景)
- 业务诉求:计算每个部门在职员工的平均薪资,且只展示平均薪资大于 13000 的部门,按平均薪资倒序排列。
sql
SELECT dept_id, AVG(salary) AS avg_salary, COUNT(id) AS emp_count
FROM employees
WHERE status = 'active' -- 1. 先过滤单行状态(王老五因为 inactive 直接被拦截)
GROUP BY dept_id -- 2. 按照部门ID切堆(分类)
HAVING avg_salary > 13000 -- 3. 过滤分组后的总体特征
ORDER BY avg_salary DESC; -- 4. 最终倒序排列真实运行结果输出:
text
+---------+------------+-----------+
| dept_id | avg_salary | emp_count |
+---------+------------+-----------+
| 2 | 18500.0000 | 2 |
| 1 | 17666.6667 | 3 |
+---------+------------+-----------+- 逐行结果校对解释:
- 部门 1(研发部)有三个在职员工,总薪资 20000+18000+15000=5300020000+18000+15000 = 5300020000+18000+15000=53000,平均薪资为 17666.666717666.666717666.6667。满足
HAVING > 13000。 - 部门 2(市场部)有两个在职员工,总薪资 25000+12000=3700025000+12000 = 3700025000+12000=37000,平均薪资为 185001850018500。满足
HAVING > 13000。 - 部门 3(财务部)唯一的员工王老五因为
status = 'inactive',在第一步WHERE时就被无情斩杀,所以部门 3 连进入GROUP BY的资格都没有,结果集中自然不显示。
五、 多表联查(JOIN)场景:企业级业务的无缝缝合
在现代关系型数据库的设计中,为了防止数据冗余,数据被高内聚地拆分在不同的表里。我们需要通过 JOIN 将它们在内存中横向拼接起来。这也是后端开发和技术面试中最喜欢拷问的部分。
1. 内连接(INNER JOIN)------ 精准的"双向奔赴"
- 业务诉求:查询所有员工的名字以及他们对应的部门名称(要求员工必须有部门,部门也必须有该员工)。
sql
SELECT e.name, d.dept_name
FROM employees e
INNER JOIN departments d ON e.dept_id = d.id;真实运行结果输出:
text
+--------+-----------+
| name | dept_name |
+--------+-----------+
| 张大 | 研发部 |
| 张二 | 研发部 |
| 张三 | 研发部 |
| 李大 | 市场部 |
| 李二 | 市场部 |
| 王老五 | 财务部 |
+--------+-----------+- 内核真相(踩坑规避) :看看结果,"赵六"和"空闲无员部"都消失了 !因为赵六的
dept_id是NULL,在departments表里匹配不到记录;而"空闲无员部"在员工表里没有任何人依附。INNER JOIN极其严苛,只有两条表的纽带同时存在且完全相等时,才会输出结果。
2. 左外连接(LEFT JOIN)------ 宽容的"以我为主"(生产环境用得最多)
- 业务诉求:查询所有员工的信息。哪怕这个员工是刚入职、还没分部门的新人(如赵六),也必须无条件列出来。
sql
SELECT e.name, d.dept_name
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.id;真实运行结果输出:
text
+--------+-----------+
| name | dept_name |
+--------+-----------+
| 张大 | 研发部 |
| 张二 | 研发部 |
| 张三 | 研发部 |
| 李大 | 市场部 |
| 李二 | 市场部 |
| 王老五 | 财务部 |
| 赵六 | NULL |
+--------+-----------+- 内核真相 :以
FROM后面的左表employees为绝对基准,左表的所有数据哪怕不满足ON条件,也雷打不动全部展示 。右表departments匹配不上的部分(如赵六对应的部门),MySQL 会极其温柔地自动填入NULL。
3. 多表联查的最高性能铁律:小表驱动大表
当你在写复杂的 A LEFT JOIN B ON ... LEFT JOIN C 时,MySQL 底层通常会采用 Nested-Loop Join(嵌套循环算法)。
- 物理模型 :它像是一层双重
for循环。外层循环每拿出一行数据,就要去内层表的 B+ 树索引里死命梭巡。 - 架构避坑手段 :永远用数据量小的表(或者是被 WHERE 过滤后结果集小的表)作为驱动表(左表) 。同时,右表的被关联字段(如
d.id)必须建立主键或唯一索引。如果右表字段没有索引,双层死循环全表扫描会瞬间引发磁盘 I/O 剧烈抖动,让数据库核心 CPU 直接飙到 100% 发生线上熔断锁死。
六、 子查询与复合查询:错综复杂的"嵌套时空"
1. 条件嵌套(IN 与 EXISTS 的高性能博弈)
- 业务诉求:查询属于"研发部"或"市场部"的所有员工记录。
sql
SELECT * FROM employees
WHERE dept_id IN (
SELECT id FROM departments WHERE dept_name IN ('研发部', '市场部')
);真实运行结果输出:
text
+----+------+---------+--------+--------+-------------+------------+
| id | name | dept_id | salary | status | phone | hire_date |
+----+------+---------+--------+--------+-------------+------------+
| 1 | 张大 | 1 | 20000 | active | 13800000001 | 2026-01-10 |
| 2 | 张二 | 1 | 18000 | active | 13800000002 | 2026-02-15 |
| 3 | 张三 | 1 | 15000 | active | 13800000003 | 2026-03-01 |
| 4 | 李大 | 2 | 25000 | active | 13800000004 | 2025-05-20 |
| 5 | 李二 | 2 | 12000 | active | 13800000005 | 2025-08-11 |
+----+------+---------+--------+--------+-------------+------------+- 🔥 架构师面试必杀技:IN 还是 EXISTS?(性能调优)
上游示例中,括号内的子查询只返回了(1, 2)两个小数据,这时候用IN效率最高。 - 法则 A :如果子查询(括号内)的结果集很小 ,外层主查询数据量大,用
IN。 - 法则 B :如果外层主查询结果集很小 ,子查询数据量极大(比如上百万条),请将其改写为
EXISTS。因为EXISTS底层引入了隐式改写,只要外层有一条记录在内层探测到了满足条件,立刻终止内层扫描,从而实现降维打击式的提速。
七、 现代 SQL 降维打击:窗口函数(Window Functions)
如果说前面的常规 CRUD 是冷兵器,那么 窗口函数(MySQL 8.0+ 倾情支持) 就是现代战争中的"热兵器"。它完美解决了"既要展示每一行明细,又要同时展示这一行在所属群体中的排名或占比"的痛点。
其标准语法为:函数() OVER (PARTITION BY 分组字段 ORDER BY 排序字段)
1. 经典场景:中国机长式的"分组内 Top N 排名"
- 地表最强诉求 :查出每个部门薪资最高的第 1 名员工。 (在没有窗口函数的低版本时代,这需要写出让人痛不欲生、多层嵌套自关联的子查询,性能极差)。
sql
SELECT dept_id, name, salary, dept_rank
FROM (
SELECT dept_id, name, salary,
-- DENSE_RANK() 是窗口函数,它会在每个部门(dept_id)内部按照薪资从高到低打上序号
DENSE_RANK() OVER (PARTITION BY dept_id ORDER BY salary DESC) AS dept_rank
FROM employees
WHERE dept_id IS NOT NULL -- 过滤掉没分部门的赵六
) AS ranked_table
WHERE dept_rank = 1; -- 外层直接精准截取第 1 名真实运行结果输出:
text
+---------+------+--------+-----------+
| dept_id | name | salary | dept_rank |
+---------+------+--------+-----------+
| 1 | 张大 | 20000 | 1 |
| 2 | 李大 | 25000 | 1 |
| 3 | 王老五 | 9000 | 1 |
+---------+------+--------+-----------+- 原理解析与运行校对:
- 内层的
PARTITION BY dept_id让 MySQL 在内存中默默把员工按部门切块(类似于 GROUP BY 但不合并行),ORDER BY salary DESC在块内排好序。 - 研发部(dept_id=1)中张大薪资最高(20000),被打上
dept_rank=1印章;市场部(dept_id=2)中李大最高(25000),打上 1。 - 外层派生表嵌套一层
WHERE dept_rank = 1,将各部门头名直接捞出,干净利落。
2. 经典场景:滚动聚合(计算累计流水账)
- 业务诉求:按入职日期升序排列,累计计算公司随着时间推进、每天的薪资支出总额(滚动累加)。
sql
SELECT hire_date, name, salary,
-- 不写 PARTITION,只写 ORDER BY,代表把全表当成一个大窗口,随着日期推进,动态累加
SUM(salary) OVER (ORDER BY hire_date) AS running_total
FROM employees;真实运行结果输出:
text
+------------+--------+--------+---------------+
| hire_date | name | salary | running_total |
+------------+--------+--------+---------------+
| 2024-01-01 | 王老五 | 9000 | 9000 |
| 2025-05-20 | 李大 | 25000 | 34000 | -- 9000 + 25000
| 2025-08-11 | 李二 | 12000 | 46000 | -- 34000 + 12000
| 2026-01-10 | 张大 | 20000 | 66000 | -- 46000 + 20000
| 2026-02-15 | 张二 | 18000 | 84000 | ...
| 2026-03-01 | 张三 | 15000 | 99000 |
| 2026-06-01 | 赵六 | 8500 | 107500 |
+------------+--------+--------+---------------+八、 避坑指南:让索引瞬间失效的"六大玄学刺客"
即便你的 SQL 语句逻辑再无懈可击、运行结果再精准,如果在编写时触犯了以下六大禁忌,MySQL 优化器就会在一瞬间抛弃辛苦建好的 B+ 树索引,转而走向耗时漫长的全表扫描(Full Table Scan)。在线上千万级 QPS 的生产系统里,这意味着灭顶之灾。
1. 刺客一:在索引列上做任何函数或表达式计算
sql
-- ❌ 恶性示范:让 id 主键索引瞬间失效
SELECT * FROM employees WHERE id + 1 = 4;
-- ❌ 恶性示范:让 hire_date 索引瞬间失效
SELECT * FROM employees WHERE YEAR(hire_date) = 2026;- 底层生产坑点 :B+ 树的叶子节点是按照列的原始值 进行严格排序的。一旦你加上了
YEAR()或+1,MySQL 根本无法预测计算后的值在树的哪个位置,只能放弃查找目录,走向全表扫描。 - 正确防坑改写 :
WHERE hire_date BETWEEN '2026-01-01' AND '2026-12-31'。
2. 刺客二:隐式类型转换(类型不匹配的深水炸弹)
假设你的 phone(手机号)字段在建表时设计的是 VARCHAR(20) 字符串类型:
sql
-- ❌ 线上惨案示范:phone 索引当场报废!
SELECT * FROM employees WHERE phone = 13800000001; - 底层生产坑红包 :由于你传的是数字
138...,而字段是字符串,MySQL 会在后台默默把这一列的所有行自动调用函数转换成数字再比较(相当于触犯了刺客一)。 - 正确防坑改写 :老老实实加上单引号 ,坚守类型对齐:
WHERE phone = '13800000001'。
3. 刺客三:违反"最左前缀法则"
假设你为表建立了一个联合索引(复合索引)包含三个字段:INDEX(a, b, c):
sql
-- ❌ 恶性示范:索引完全失效,全表扫描
SELECT * FROM my_table WHERE b = 2 AND c = 3;- 底层生产坑点 :联合索引在 B+ 树里的物理排序是:先按
a排,a相同的情况下按b排,b相同的情况下按c排。如果你不带老大a玩,直接去查b和c,它们在物理上是完全无序的,目录直接作废。
4. 刺客四:错误使用 OR 导致全盘皆输
sql
-- ❌ 恶性示范:如果 age 没有索引,即使 id 有主键索引,整个查询也会放弃索引!
SELECT * FROM employees WHERE id = 1 OR age = 18;- 正确防坑方案 :如果两列都有索引,可以使用
UNION或者是UNION ALL代替OR进行连接,确保各部分的索引都能被独立复用。
5. 刺客五:NOT IN 与 != 的范围扩大化导致优化器"开小差"
使用 NOT IN、!= 或者 IS NOT NULL 时,如果 MySQL 优化器评估过发现,排除掉的数据只占一小部分,剩下要捞出来的数据占了整张表的 80% 以上,它就会悲观地认为:"反正要捞绝大部分数据,我直接去磁盘顺序扫描全表还快些,省得去索引树里绕弯子了。"
九、 总结:高级查询通用黄金链路
我们在构建工业级高并发系统时,写一条高阶查询的思考链路通常如下:
[ 收到复杂的业务报表/数据需求 ]
│
▼
[ 思考 1. 驱动源头 ] ──► 优先确定 FROM 与 JOIN 的主从表,坚持小表(小数据集)驱动大表
│
▼
[ 思考 2. 闪电拦截 ] ──► 检查 WHERE 条件,确保核心字段全部匹配,斩断"六大刺客"的干扰
│
▼
[ 思考 3. 规整切块 ] ──► 若需要精细化多维分析,利用 GROUP BY 聚合或引入 8.0 窗口函数降维打击
│
▼
[ 思考 4. 精准斩断 ] ──► 无论如何,在后台业务中必须死死加上 LIMIT 分页,绝不兜底全表返回结语:踏入数据库编程的交汇点
到这里,你已经不仅理清了 MySQL 底层的精妙机械构造(B+树与MVCC),更掌握了调遣兵将的最高招式。无论是面对错综复杂的多表联查,还是要求严苛的分组内排名,你手中的 SQL 都能写得既优雅,又快如闪电。
然而,在真实的工业级开发中,SQL 语句很少孤立地在黑窗口里运行。如何将这些强悍的查询招式融入到我们的后端代码中?如何让高并发的 Goroutine 与底层的数据库连接池进行安全的交火与数据交互?
单机数据库的静态招式你已功德圆满,接下来,我们将赋予这些招式流动的生命。
欢迎在评论区留下你的脚印:你在第一次用代码连接数据库时,踩过最让你抓狂的坑是什么?下一期,我们将正式踏入实战的全新维度------《从静态数据到动态代码:手把手带你打通 Go 语言原生的 Database/SQL 与 GORM 框架的编程密码》,我们江湖再见!