PyTorch强化学习实战(13)------噪声网络(NoisyNet-DQN)
0. 前言
在深度强化学习中,探索与利用的权衡一直是一个核心难题。传统的探索策略,如经典的 ε-greedy 或熵正则化,本质上都是在动作空间中添加随机扰动。这种方法虽然简单,但却存在一个根本性问题:每一步的动作扰动都是独立的、无状态的,难以产生持续、连贯的探索行为,尤其在需要多步协调才能发现奖励的稀疏奖励环境中,这种"抖动式"探索往往效率低下。2018 年,DeepMind 研究团队提出了一种全新的探索范式------NoisyNet。该方法将可学习的参数化噪声直接注入神经网络的权重中,使智能体能够在策略空间中实现状态依赖的、时间上一致的探索。本节将深入探讨噪声网络,通过权重噪声注入实现高效探索。本节将解析噪声网络的原理、实现方案,并与经典深度Q网络 (Deep Q-Network, DQN)进行性能对比。
1. 噪声网络
在本节中,我们将针对强化学习的一个核心问题------环境探索------进行改进。论文《Noisy networks for exploration》提出了一种简单而有效的思路------通过训练过程自动学习探索策略,而非依赖预设的探索调度方案。
经典 DQN 通过超参数 ε 来控制探索,该参数随时间从 1.0 (完全随机动作)逐步衰减至 0.1 或 0.02 等较小值。这种方法适用于回合制短、环境稳定的简单场景,但即使如此仍需精细调参才能保证训练效率。
噪声网络方案给出了一个优雅的解决路径:在全连接层权重中注入可训练噪声。该方法通过反向传播自动调整噪声参数 (μ 和 σ),既保持了实现的简洁性,又获得了优异效果。需要注意的是,这与更复杂的"网络自主探索决策"机制(如内在激励、计数探索法等)有本质区别。
研究者提出了两种噪声注入方式,实验结果表明这两种方法都有效,但计算开销不同:
- 独立的高斯噪声:全连接层每个权重对应独立采样的正态分布随机值,噪声参数
μ和σ作为可训练参数与常规权重同步更新,前向传播计算方式与标准线性层相同 - 分解的高斯噪声:为减少随机值采样数量,仅保留两个随机向量(分别对应层输入/输出维度),通过外积运算生成噪声矩阵。这种方式显著降低了计算复杂度
2. 噪声网络实现
在 PyTorch 中,上述两种噪声注入方式都可以通过简单直观的方式实现。我们需要自定义一个 nn.Linear 层,其权重计算公式为: w i , j = μ i , j + σ i , j ⋅ ε i , j w_{i,j}=μ_{i,j}+σ_{i,j}⋅ε_{i,j} wi,j=μi,j+σi,j⋅εi,j,其中 μ μ μ 和 σ σ σ 是可训练的参数,而 ε ∼ N ( 0 , 1 ) ε∼N(0,1) ε∼N(0,1) 是在每次优化步骤后从标准正态分布采样的随机噪声。
(1) 在本节中,我们将直接使用 TorchRL 库中提供的实现。NoisyLinear 类的构造函数创建了所有需要优化的参数:
python
class NoisyLinear(nn.Linear):
def __init__(
self, in_features: int, out_features: int, bias: bool = True,
device: Optional[DEVICE_TYPING] = None, dtype: Optional[torch.dtype] = None,std_init: float = 0.1,
):
nn.Module.__init__(self)
self.in_features = int(in_features)
self.out_features = int(out_features)
self.std_init = std_init
self.weight_mu = nn.Parameter(
torch.empty(out_features, in_features, device=device,
dtype=dtype, requires_grad=True)
)
self.weight_sigma = nn.Parameter(
torch.empty(out_features, in_features, device=device,
dtype=dtype, requires_grad=True)
)
self.register_buffer(
"weight_epsilon",
torch.empty(out_features, in_features, device=device, dtype=dtype),
)
if bias:
self.bias_mu = nn.Parameter(
torch.empty(out_features, device=device, dtype=dtype, requires_grad=True)
)
self.bias_sigma = nn.Parameter(
torch.empty(out_features, device=device, dtype=dtype, requires_grad=True)
)
self.register_buffer(
"bias_epsilon", torch.empty(out_features, device=device, dtype=dtype),
)
else:
self.bias_mu = None
self.reset_parameters()
self.reset_noise()在构造函数中,我们创建了 μ μ μ (均值)和 σ σ σ (标准差)矩阵。该实现虽然继承自 torch.nn.Linear,但直接调用了 nn.Module.__init__() 方法,因此不会自动创建标准 Linear 层的权重和偏置缓冲区。
为了让新矩阵可训练,我们需要将其张量包装为 nn.Parameter 。register_buffer 方法会在网络中创建一个张量,该张量在反向传播期间不会被更新,但会由 nn.Module 机制处理(例如,调用 cuda() 时会将其复制到 GPU)。我们还为层的偏置创建了一个额外的参数和缓冲区。最后,我们调用 reset_parameters() 和 reset_noise() 方法,这两个方法分别用于初始化创建的可训练参数和带有 epsilon 值的缓冲区。
(2) 在接下来的三个方法中,根据论文初始化了可训练参数 μ μ μ 和 σ σ σ:
python
def reset_parameters(self) -> None:
mu_range = 1 / math.sqrt(self.in_features)
self.weight_mu.data.uniform_(-mu_range, mu_range)
self.weight_sigma.data.fill_(self.std_init / math.sqrt(self.in_features))
if self.bias_mu is not None:
self.bias_mu.data.uniform_(-mu_range, mu_range)
self.bias_sigma.data.fill_(self.std_init / math.sqrt(self.out_features))
def reset_noise(self) -> None:
epsilon_in = self._scale_noise(self.in_features)
epsilon_out = self._scale_noise(self.out_features)
self.weight_epsilon.copy_(epsilon_out.outer(epsilon_in))
if self.bias_mu is not None:
self.bias_epsilon.copy_(epsilon_out)
def _scale_noise(self, size: Union[int, torch.Size, Sequence]) -> torch.Tensor:
if isinstance(size, int):
size = (size,)
x = torch.randn(*size, device=self.weight_mu.device)
return x.sign().mul_(x.abs().sqrt_())μ μ μ 的矩阵初始化为均匀随机值。 σ σ σ 的初始值是常数,取决于层中的神经元数量。
对于噪声初始化,我们采用分解的高斯噪声------通过采样两个随机向量并计算其外积来得到 ε ε ε 矩阵。外积是一种线性代数运算,当两个相同大小的向量进行运算时,会生成一个方阵,其中每个元素都是两个向量元素所有可能组合的乘积。
(3) 其余部分很简单:我们重新定义了 nn.Linear 层所需的权重和偏置属性,因此 NoisyLinear 可以在任何使用 nn.Linear 的地方直接使用:
python
@property
def weight(self) -> torch.Tensor:
if self.training:
return self.weight_mu + self.weight_sigma * self.weight_epsilon
else:
return self.weight_mu
@property
def bias(self) -> Optional[torch.Tensor]:
if self.bias_mu is not None:
if self.training:
return self.bias_mu + self.bias_sigma * self.bias_epsilon
else:
return self.bias_mu
else:
return None要将经典 DQN 转换为噪声网络版本,只需将 DQN 网络最后两层的 nn.Linear 替换为 NoisyLinear 层。同时,还需要删除所有与ε-贪婪策略相关的代码。
为监测训练过程中的内部噪声水平,我们可以跟踪噪声层的信噪比 (Signal-to-Noise Ratio, SNR),即 R M S ( μ ) / R M S ( σ ) RMS(μ)/RMS(σ) RMS(μ)/RMS(σ),其中 RMS 表示相应权重的均方根值。在本例中,SNR 反映了噪声层稳态分量是注入噪声的多少倍。
3. 运行结果
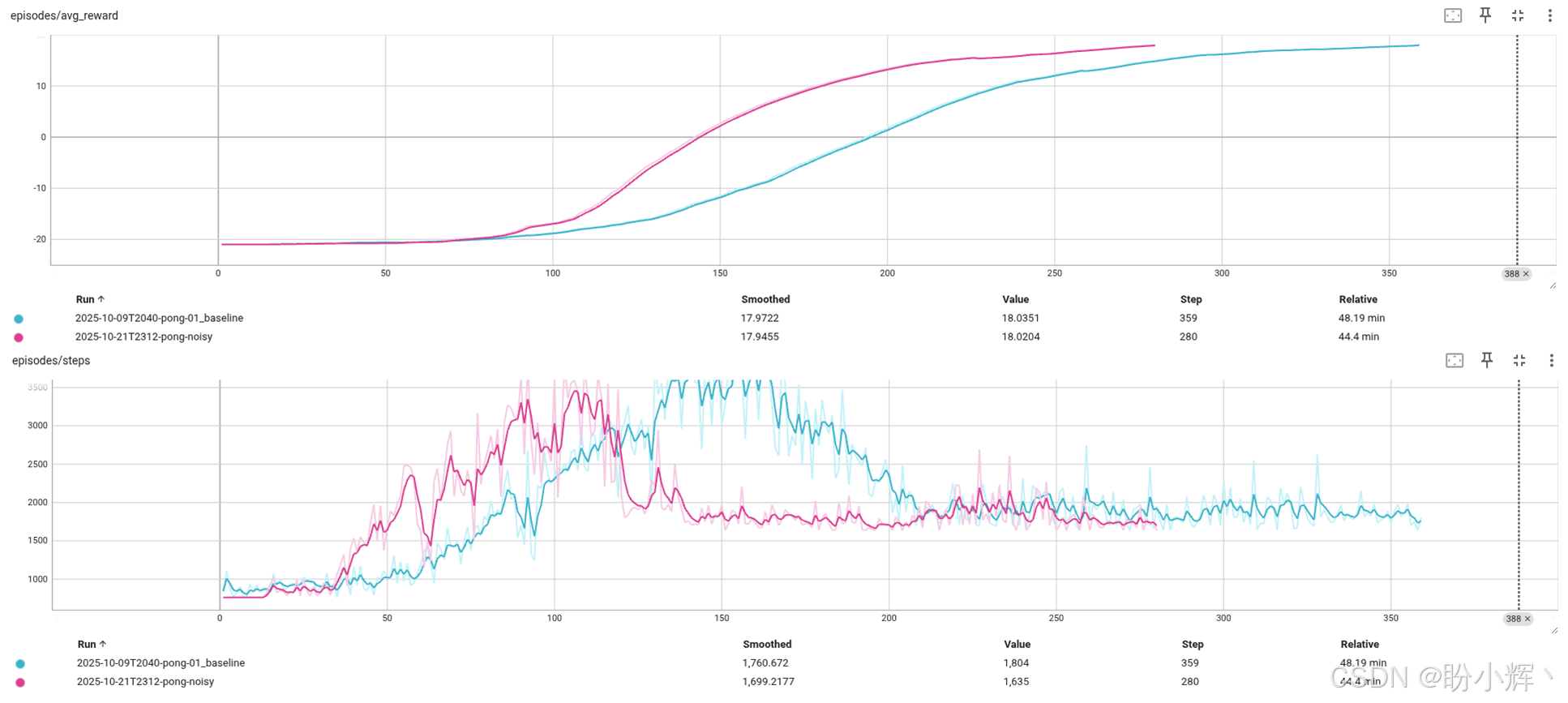
TensorBoard 显示训练动态明显改善。该模型在 250 局游戏后平均得分达到 18,相比基准 DQN 的 350 局有所提升。但由于噪声网络需要额外计算,训练速度稍慢,因此时间效率上的差异不那么显著。但整体而言,结果依然令人满意:
观察信噪比(下图)可以发现,两个网络层的噪声水平都出现了快速下降。
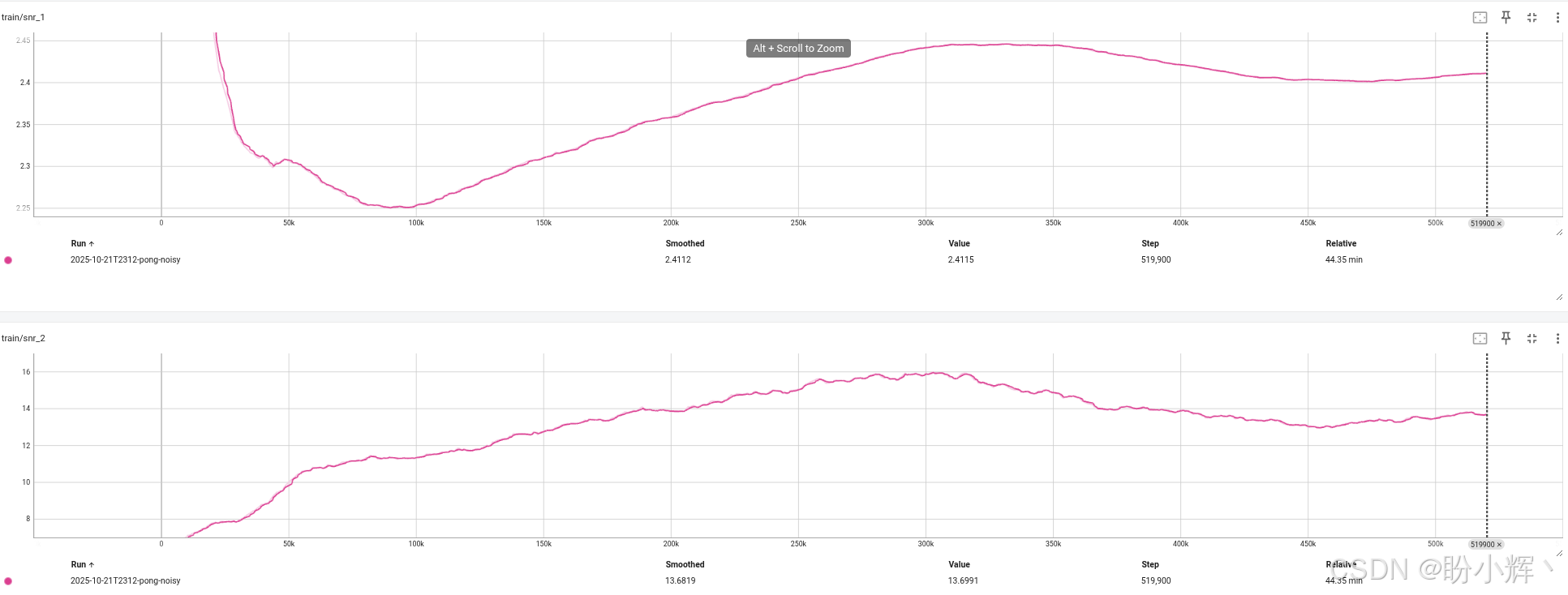
第一层的噪声比从初始的 1/2 降至接近 1/2.6;第二层的噪声水平从初始的 1/4 降至 1/16,但在处理约 45 万帧数据时(此时原始奖励值已接近 20 分),最后一层的噪声水平开始回升,促使智能体加强环境探索。这种现象非常合理------当达到较高分数后,智能体已掌握基本玩法,但仍需通过"动作微调"来进一步提升表现。
4. 超参数调优
经过调优后,最佳参数组合仅用 273 回合就成功解决问题,较经典 DQN 模型有明显提升,达到 21 分所需游戏回合更少,并且在训练过程中,游戏所需的步数较少。
小结
噪声网络 (NoisyNet) 通过在神经网络权重中注入可学习的参数化噪声,实现状态依赖且时间上一致的探索,克服了传统 ε-greedy 等策略在稀疏奖励环境中效率低下的问题。该方法的权重由可训练均值 μ μ μ 和标准差 σ σ σ 加上随机噪声 ε ε ε 构成,噪声可采用独立高斯或分解高斯方式,后者通过外积计算降低计算复杂度。在 PyTorch 中可通过自定义 NoisyLinear 层实现,替换 DQN 最后两层线性层并移除 ε-greedy 即可。实验表明,NoisyNet 在 250 回合后平均得分达 18,优于基准 DQN 的 350 回合,信噪比变化反映了噪声水平的自适应调整。
相关链接
PyTorch强化学习实战(1)------强化学习(Reinforcement Learning,RL)详解
PyTorch强化学习实战(2)------强化学习环境库Gymnasium
PyTorch强化学习实战(3)------Gymnasium API扩展功能
PyTorch强化学习实战(4)------PyTorch基础
PyTorch强化学习实战(5)------PyTorch Ignite 事件驱动机制与实践
PyTorch强化学习实战(6)------交叉熵方法详解与实现
PyTorch强化学习实战(7)------表格学习与贝尔曼方程
PyTorch强化学习实战(8)------Q学习详解与实现
PyTorch强化学习实战(10)------强化学习高级组件