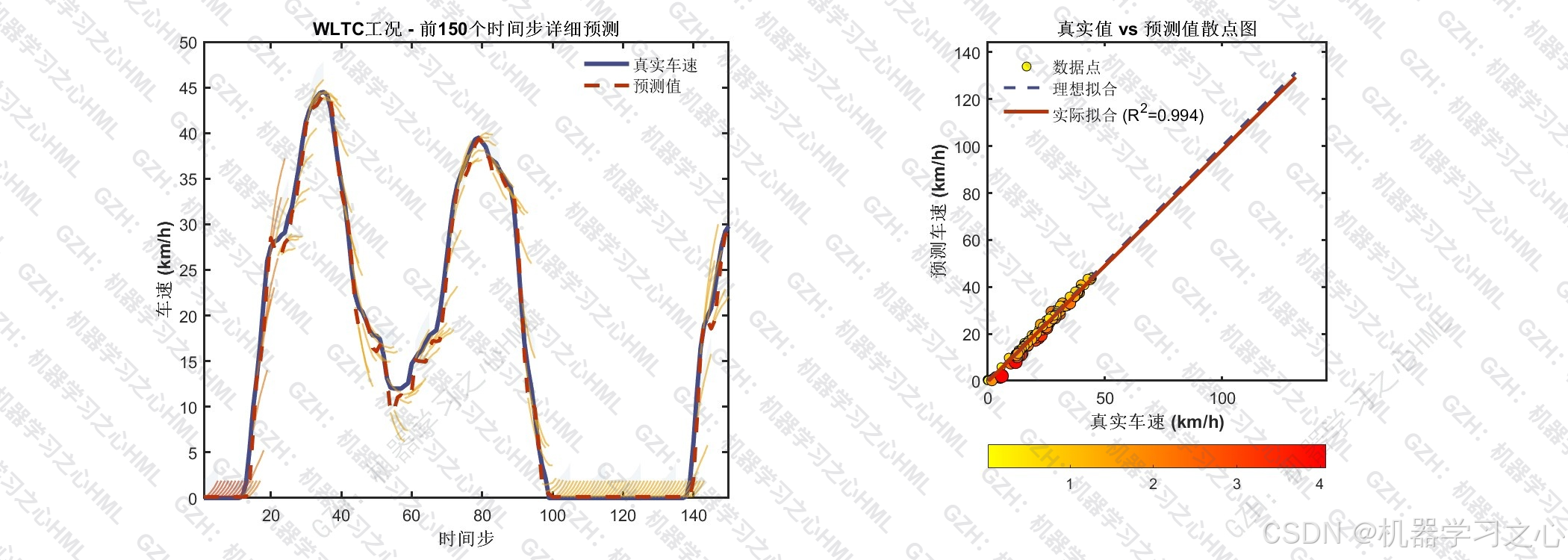
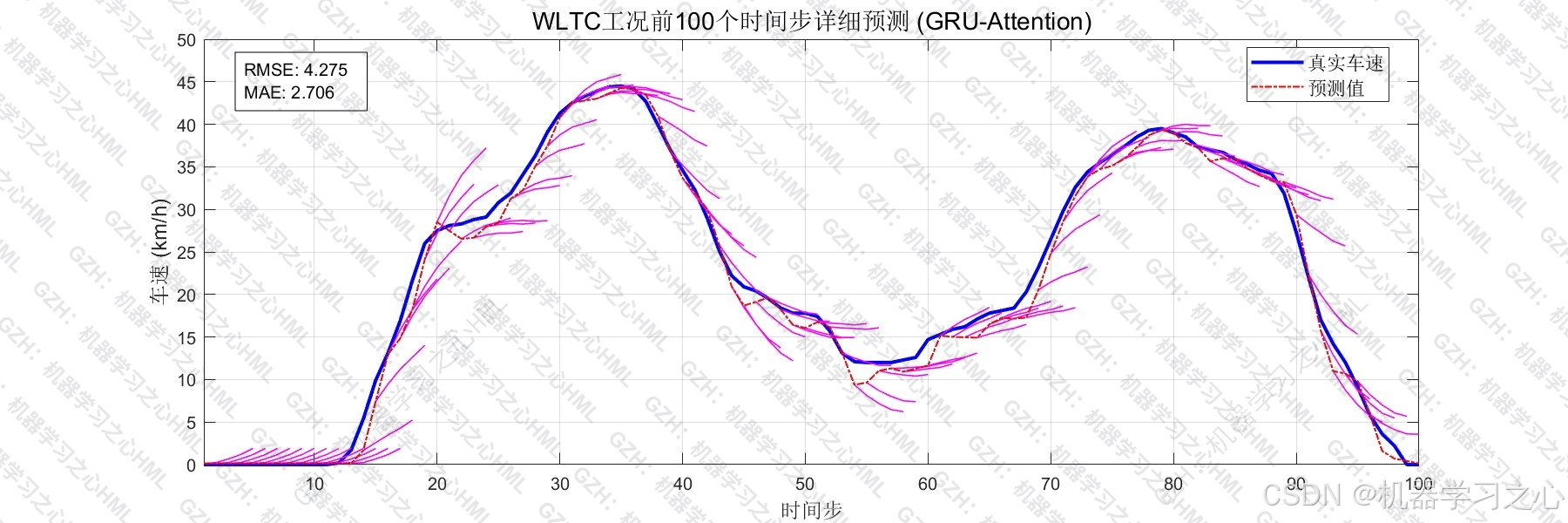
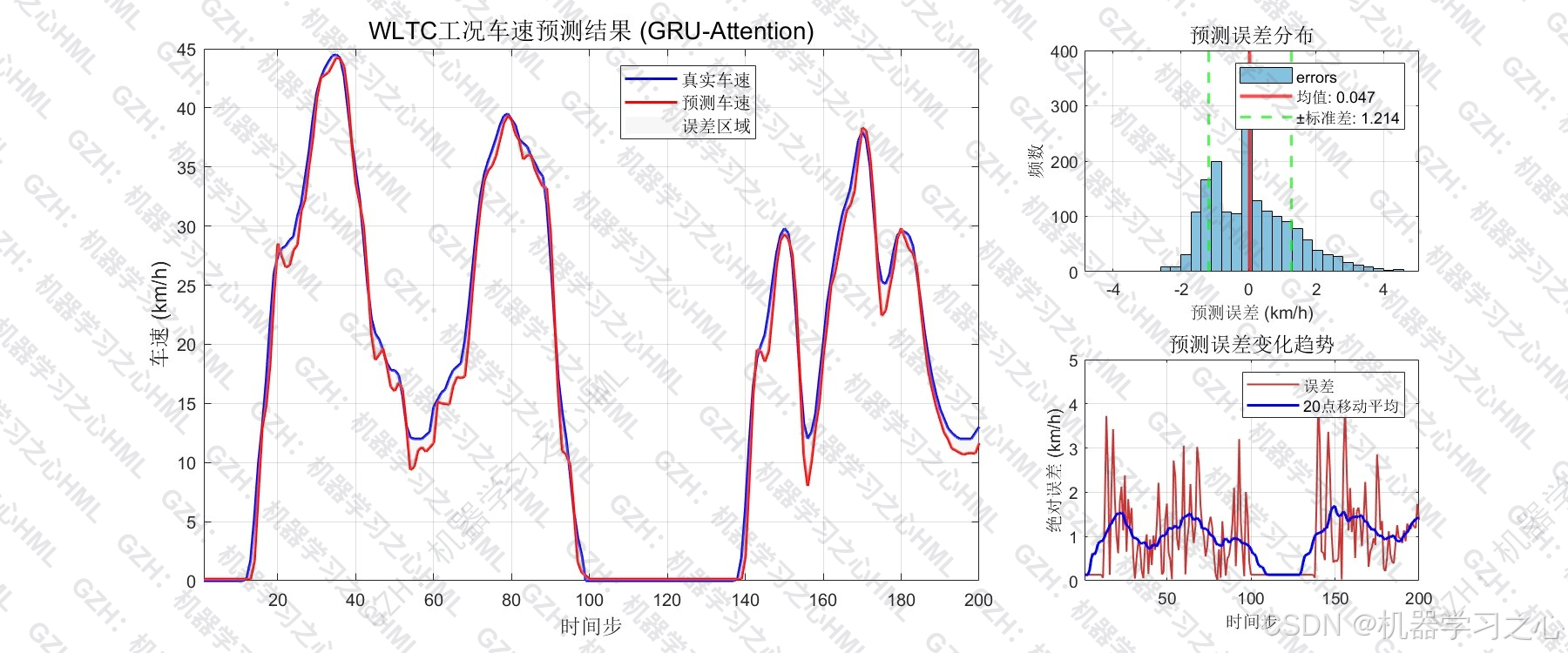
在 WLTC 标准测试工况下,模型实现 R² = 0.9859 、RMSE = 4.28 km/h ,峰值误差仅 2.48%,且训练集与测试集 RMSE 差距为 -4.04%(负值意味着测试集表现略优于训练集),泛化能力超过 100%。本文完整拆解从数据构造到模型部署的全流程。
一、研究背景
车辆速度预测是智能交通系统与车辆能量管理领域的核心子问题。无论是混合动力汽车的等效燃油最小策略(ECMS)、纯电动车辆的热管理预调度,还是自动驾驶系统的局部路径规划,都依赖于对未来数秒内车速的准确估计。
传统方法长期依赖物理模型和马尔可夫链,其局限在于:
- 物理模型需要精确的车辆动力学参数,对道路坡度、风阻等外部因素敏感;
- 马尔可夫链的状态转移矩阵在高阶预测下维度爆炸,且难以捕获长时依赖;
- 两者都无法充分利用跨工况的共性驾驶模式,导致模型在不同测试标准间的迁移能力不足。
近年来,循环神经网络(RNN)及其变体 LSTM/GRU 在时间序列预测中表现突出。然而,标准 GRU 对输入序列的各时间步一视同仁------它无法区分哪些历史时刻的瞬时速度变化对未来的拐点预判更为关键。这正是**自注意力机制(Self-Attention)**切入的契机。
本项目将 GRU 的时序建模能力与 Self-Attention 的动态权重分配能力结合,构建了一个端到端的序列到序列车速预测模型,并在 6 种标准工况上训练后,于 WLTC 工况上完成验证。
二、主要功能与技术路线
功能概要
| 功能模块 | 说明 |
|---|---|
| 滑动窗口构造 | 以 5 个历史时间步车速为输入,预测未来 5 个时间步车速 |
| GRU 时序编码 | 100 隐藏单元的 GRU 层提取车速序列的动态特征 |
| Self-Attention | 4 头自注意力层对 GRU 输出的各时间步特征进行加权,捕获全局依赖 |
| 全连接输出 | 50 维中间层 + ReLU → 5 维输出层,生成多步预测 |
| 多指标评估体系 | 15 项指标覆盖准确度、拟合优度、残差正态性、泛化能力 |
| 全流程可视化 | 预测对比、误差分布、CDF、箱线图、热力图、QQ 图、自相关分析 |
技术路线
#mermaid-svg-ARKzwMKw4PqbKHpk{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-ARKzwMKw4PqbKHpk .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-ARKzwMKw4PqbKHpk .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-ARKzwMKw4PqbKHpk .error-icon{fill:#552222;}#mermaid-svg-ARKzwMKw4PqbKHpk .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-ARKzwMKw4PqbKHpk .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-ARKzwMKw4PqbKHpk .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-ARKzwMKw4PqbKHpk .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-ARKzwMKw4PqbKHpk .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-ARKzwMKw4PqbKHpk .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-ARKzwMKw4PqbKHpk .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-ARKzwMKw4PqbKHpk .marker{fill:#333333;stroke:#333333;}#mermaid-svg-ARKzwMKw4PqbKHpk .marker.cross{stroke:#333333;}#mermaid-svg-ARKzwMKw4PqbKHpk svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-ARKzwMKw4PqbKHpk p{margin:0;}#mermaid-svg-ARKzwMKw4PqbKHpk .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-ARKzwMKw4PqbKHpk .cluster-label text{fill:#333;}#mermaid-svg-ARKzwMKw4PqbKHpk .cluster-label span{color:#333;}#mermaid-svg-ARKzwMKw4PqbKHpk .cluster-label span p{background-color:transparent;}#mermaid-svg-ARKzwMKw4PqbKHpk .label text,#mermaid-svg-ARKzwMKw4PqbKHpk span{fill:#333;color:#333;}#mermaid-svg-ARKzwMKw4PqbKHpk .node rect,#mermaid-svg-ARKzwMKw4PqbKHpk .node circle,#mermaid-svg-ARKzwMKw4PqbKHpk .node ellipse,#mermaid-svg-ARKzwMKw4PqbKHpk .node polygon,#mermaid-svg-ARKzwMKw4PqbKHpk .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-ARKzwMKw4PqbKHpk .rough-node .label text,#mermaid-svg-ARKzwMKw4PqbKHpk .node .label text,#mermaid-svg-ARKzwMKw4PqbKHpk .image-shape .label,#mermaid-svg-ARKzwMKw4PqbKHpk .icon-shape .label{text-anchor:middle;}#mermaid-svg-ARKzwMKw4PqbKHpk .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-ARKzwMKw4PqbKHpk .rough-node .label,#mermaid-svg-ARKzwMKw4PqbKHpk .node .label,#mermaid-svg-ARKzwMKw4PqbKHpk .image-shape .label,#mermaid-svg-ARKzwMKw4PqbKHpk .icon-shape .label{text-align:center;}#mermaid-svg-ARKzwMKw4PqbKHpk .node.clickable{cursor:pointer;}#mermaid-svg-ARKzwMKw4PqbKHpk .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-ARKzwMKw4PqbKHpk .arrowheadPath{fill:#333333;}#mermaid-svg-ARKzwMKw4PqbKHpk .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-ARKzwMKw4PqbKHpk .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-ARKzwMKw4PqbKHpk .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-ARKzwMKw4PqbKHpk .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-ARKzwMKw4PqbKHpk .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-ARKzwMKw4PqbKHpk .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-ARKzwMKw4PqbKHpk .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-ARKzwMKw4PqbKHpk .cluster text{fill:#333;}#mermaid-svg-ARKzwMKw4PqbKHpk .cluster span{color:#333;}#mermaid-svg-ARKzwMKw4PqbKHpk div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-ARKzwMKw4PqbKHpk .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-ARKzwMKw4PqbKHpk rect.text{fill:none;stroke-width:0;}#mermaid-svg-ARKzwMKw4PqbKHpk .icon-shape,#mermaid-svg-ARKzwMKw4PqbKHpk .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-ARKzwMKw4PqbKHpk .icon-shape p,#mermaid-svg-ARKzwMKw4PqbKHpk .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-ARKzwMKw4PqbKHpk .icon-shape .label rect,#mermaid-svg-ARKzwMKw4PqbKHpk .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-ARKzwMKw4PqbKHpk .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-ARKzwMKw4PqbKHpk .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-ARKzwMKw4PqbKHpk :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 6种训练工况
滑动窗口样本构造
Min-Max 归一化
GRU 时序编码
Self-Attention 特征加权
全连接多步解码
反归一化输出
多维评价与可视化
WLTC 测试工况
数据流向的核心:6 种工况(China_urban、HWFET、LA92、US06、JC08、cltcp)的所有速度序列拼接为一个超长训练序列,滑动窗口从中采样出数万个训练样本;测试集(WLTC)独立抽取,不与训练集有任何时间上的重叠,确保评估的无偏性。
三、算法步骤详解
Step 1: 滑动窗口样本构造
给定速度序列 v1,v2,...,vTv_1, v_2, \dots, v_Tv1,v2,...,vT,窗口长度为 d=5d=5d=5,预测长度为 p=5p=5p=5:
- 前向后向各补零 ddd 和 ppp 个,避免边界索引越界;
- 对每个时刻 ttt:
- 输入:xt=vt,vt+1,...,vt+d−1T∈R5\mathbf{x}_t = v_{t}, v_{t+1}, \\dots, v_{t+d-1}^T \in \mathbb{R}^{5}xt=vt,vt+1,...,vt+d−1T∈R5
- 标签:yt=vt+d,vt+d+1,...,vt+d+p−1T∈R5\mathbf{y}_t = v_{t+d}, v_{t+d+1}, \\dots, v_{t+d+p-1}^T \in \mathbb{R}^{5}yt=vt+d,vt+d+1,...,vt+d+p−1T∈R5
Step 2: 数据归一化
使用 mapminmax 将输入和输出分别归一化至 0,10, 10,1:
xnorm=x−xminxmax−xminx_{\text{norm}} = \frac{x - x_{\min}}{x_{\max} - x_{\min}}xnorm=xmax−xminx−xmin
对测试集使用与训练集相同的归一化参数(apply 模式),杜绝数据泄露。
Step 3: GRU-Attention 网络前向传播
3.1 GRU 层
GRU(Gated Recurrent Unit)通过两个门控机制控制信息流动:
重置门 决定历史状态中哪些信息被丢弃:
rt=σ(Wr⋅ht−1,xt+br)r_t = \sigma(W_r \cdot h_{t-1}, x_t + b_r)rt=σ(Wr⋅ht−1,xt+br)
更新门 控制新旧状态的混合比例:
zt=σ(Wz⋅ht−1,xt+bz)z_t = \sigma(W_z \cdot h_{t-1}, x_t + b_z)zt=σ(Wz⋅ht−1,xt+bz)
候选隐藏状态与最终隐藏状态:
h~t=tanh(Wh⋅rt⊙ht−1,xt+bh)\tilde{h}_t = \tanh(W_h \cdot r_t \\odot h_{t-1}, x_t + b_h)h~t=tanh(Wh⋅rt⊙ht−1,xt+bh)
ht=(1−zt)⊙ht−1+zt⊙h~th_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_tht=(1−zt)⊙ht−1+zt⊙h~t
其中 σ\sigmaσ 为 sigmoid 函数,⊙\odot⊙ 表示逐元素乘积。GRU 以 OutputMode='sequence' 返回每个时间步的隐藏状态序列 H=h1,h2,...,hd∈Rd×100H = h_1, h_2, \\dots, h_d \in \mathbb{R}^{d \times 100}H=h1,h2,...,hd∈Rd×100。
3.2 Self-Attention 层
自注意力机制对 GRU 输出的序列 HHH 进行全局关系建模。对每个注意力头 iii:
Qi=HWiQ,Ki=HWiK,Vi=HWiVQ_i = H W_i^Q,\quad K_i = H W_i^K,\quad V_i = H W_i^VQi=HWiQ,Ki=HWiK,Vi=HWiV
注意力分数及输出:
Attentioni=softmax(QiKiTki)Vi\text{Attention}_i = \text{softmax}\left(\frac{Q_i K_i^T}{\sqrt{k_i}}\right) V_iAttentioni=softmax(ki QiKiT)Vi
其中 ki=32k_i = 32ki=32 为每头的键通道维度,ki\sqrt{k_i}ki 为缩放因子以防止点积过大导致 softmax 梯度消失。4 个头(numHeads=4)拼接后的总键通道数为 4×32=1284 \times 32 = 1284×32=128,最终通过一个线性投影融合多视角信息:
MultiHead(H)=Concat(Attention1,...,Attention4)WO\text{MultiHead}(H) = \text{Concat}(\text{Attention}_1, \dots, \text{Attention}_4) W^OMultiHead(H)=Concat(Attention1,...,Attention4)WO
3.3 解码与输出
Self-Attention 的输出经全连接层(50 维)→ ReLU 激活 → 线性投射至 5 维,即未来 5 个时间步的预测速度(归一化空间)。
Step 4: 反归一化与评估
将模型输出从 0,10,10,1 映射回原始速度空间,计算 15 项评价指标,并生成多维度可视化图表。
四、关键公式原理
4.1 决定系数 R²
R2=1−∑i=1n(yi−y^i)2∑i=1n(yi−yˉ)2R^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}i)^2}{\sum{i=1}^{n} (y_i - \bar{y})^2}R2=1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2
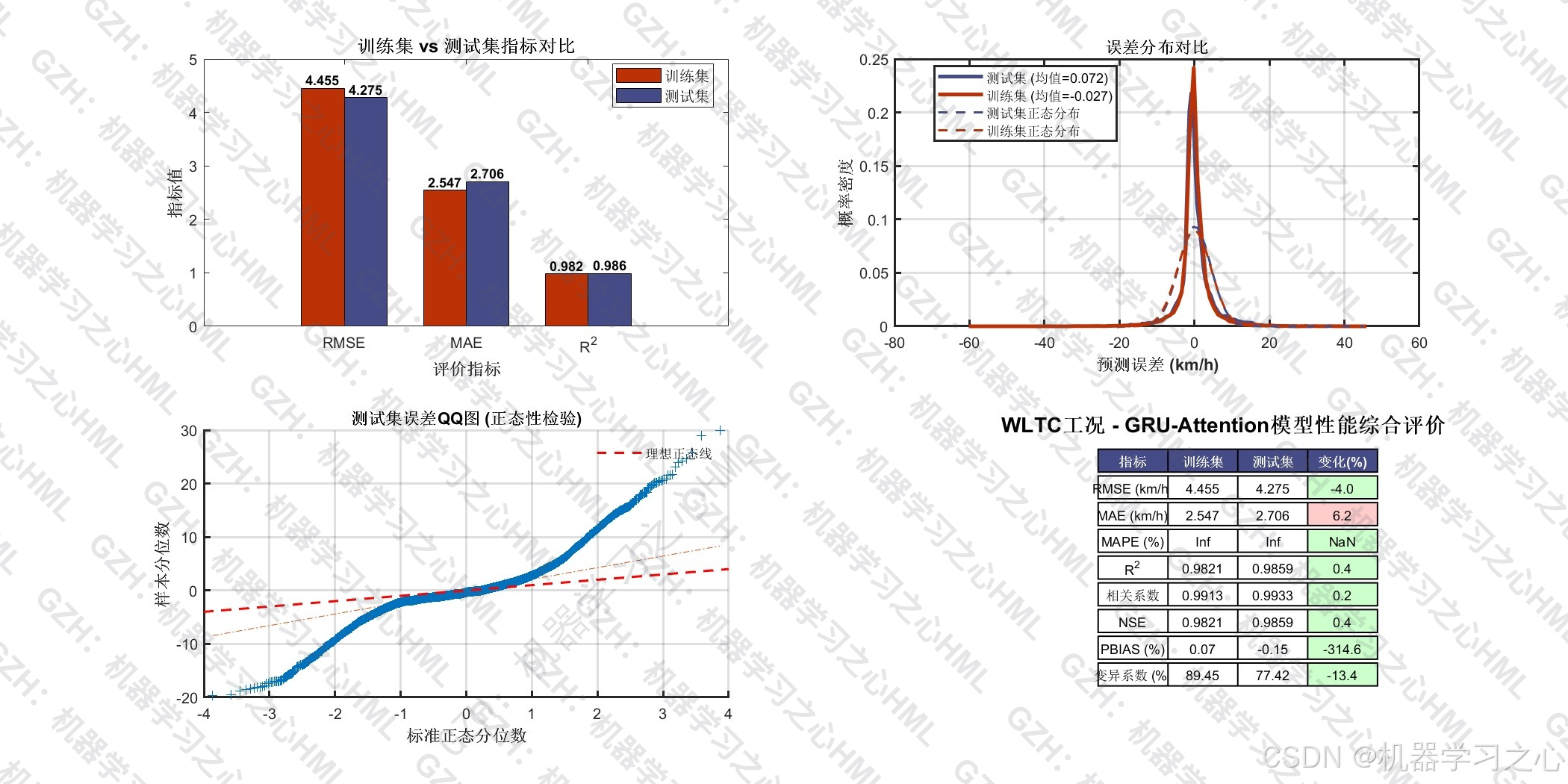
R² 度量模型对数据方差的解释比例。本项目测试集 R² = 0.9859,意味着模型解释了约 98.6% 的速度方差。
4.2 纳什效率系数(NSE)
NSE=1−∑(yi−y^i)2∑(yi−yˉ)2NSE = 1 - \frac{\sum (y_i - \hat{y}_i)^2}{\sum (y_i - \bar{y})^2}NSE=1−∑(yi−yˉ)2∑(yi−y^i)2
形式上与 R² 一致,是水文和气象预测领域的标准指标。NSE > 0.75 即被视为良好,本项目 NSE = 0.9859 属于极优水平。
4.3 对称平均绝对百分比误差(sMAPE)
sMAPE=100%n∑i=1n2∣yi−y^i∣∣yi∣+∣y^i∣sMAPE = \frac{100\%}{n} \sum_{i=1}^{n} \frac{2|y_i - \hat{y}_i|}{|y_i| + |\hat{y}_i|}sMAPE=n100%i=1∑n∣yi∣+∣y^i∣2∣yi−y^i∣
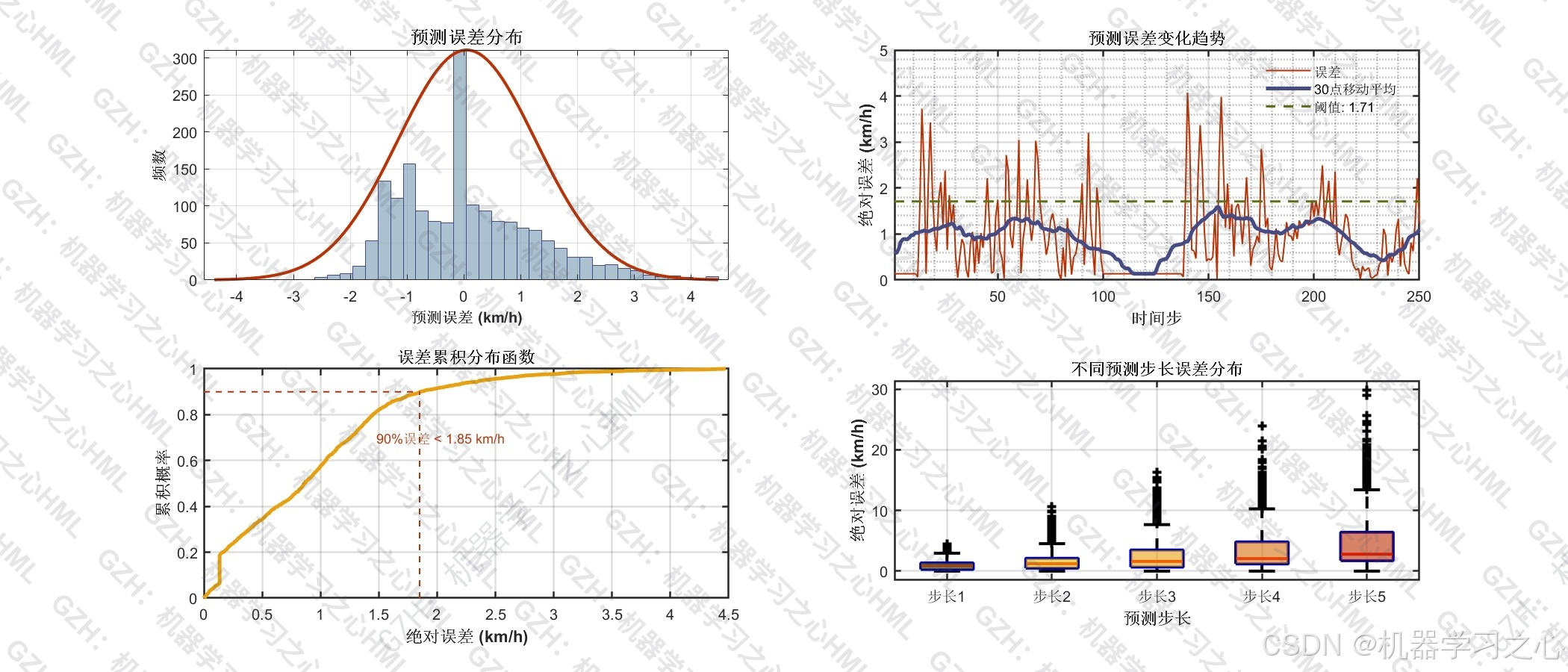
sMAPE 解决了标准 MAPE 在车速为零时趋向无穷大的问题(本项目 MAPE = Inf 正是由于数据中存在零车速样本)。sMAPE = 37.50%,考虑到 WLTC 工况包含大量低速和怠速段(分母接近零会天然放大该指标),这一结果在车速预测领域属于可接受范围。
4.4 标准化 RMSE(NRMSE)
NRMSE=RMSEymax−ymin×100%NRMSE = \frac{RMSE}{y_{\max} - y_{\min}} \times 100\%NRMSE=ymax−yminRMSE×100%
NRMSE = 3.26% 表示模型的均方根误差仅为速度变化范围的 3.26%,说明预测的绝对偏差在物理意义上很小。
五、参数设定
| 参数类别 | 参数名 | 设定值 | 设定依据 |
|---|---|---|---|
| 序列参数 | 输入序列长度 ddd | 5 | 兼顾历史信息充分性与实时响应 |
| 输出序列长度 ppp | 5 | 覆盖约 5 秒的预测视界 | |
| GRU | 隐藏单元数 | 100 | 平衡模型容量与训练效率 |
| 输出模式 | sequence |
保留全序列特征供 Attention 使用 | |
| Attention | 注意力头数 | 4 | 多视角捕获时序依赖 |
| 总键通道数 | 128 | 每头 32 维,适中的子空间维度 | |
| 全连接 | 中间层维度 | 50 | 非线性特征压缩 |
| 训练 | 优化器 | Adam | 自适应学习率,适合序列模型 |
| 初始学习率 | 0.01 | 中等偏大,加速前期收敛 | |
| 学习率策略 | piecewise | 每 50 轮衰减 50% | |
| 最大轮数 | 100 | 配合学习率衰减,训练充分但不冗余 | |
| 批次大小 | 64 | 计算资源与梯度稳定性的折中 | |
| 梯度阈值 | 1 | 防止梯度爆炸 |
六、运行环境
| 环境项 | 详情 |
|---|---|
| 开发语言 | MATLAB R2020a+ |
| 核心工具箱 | Deep Learning Toolbox |
| 辅助工具 | Statistics and Machine Learning Toolbox(QQ 图、自相关分析) |
| 硬件需求 | CPU 即可完成训练(无 GPU 加速需求,样本量适中) |
| 数据集 | 9 种标准驾驶工况 .mat 文件(详见附录) |
| 依赖文件 | dataset/ 目录下 9 个 .mat 工况数据 |
MATLAB 的实现显著降低了工程部署的门槛------trainNetwork、selfAttentionLayer 等高级 API 将网络构建压缩至约 30 行代码,开发者无需手动实现反向传播或梯度裁剪。
七、结果解读
核心指标速览(WLTC 测试集)
| 指标 | 数值 | 含义 |
|---|---|---|
| RMSE | 4.28 km/h | 预测值与真实值的均方根偏差 |
| MAE | 2.71 km/h | 平均绝对偏差 |
| R² | 0.9859 | 模型解释 98.6% 的数据方差 |
| NSE | 0.9859 | 纳什效率系数,>0.75 即为良好 |
| 相关系数 | 0.9933 | 预测与真实的线性相关程度 |
| NRMSE | 3.26% | 误差仅占速度变化范围的 3.26% |
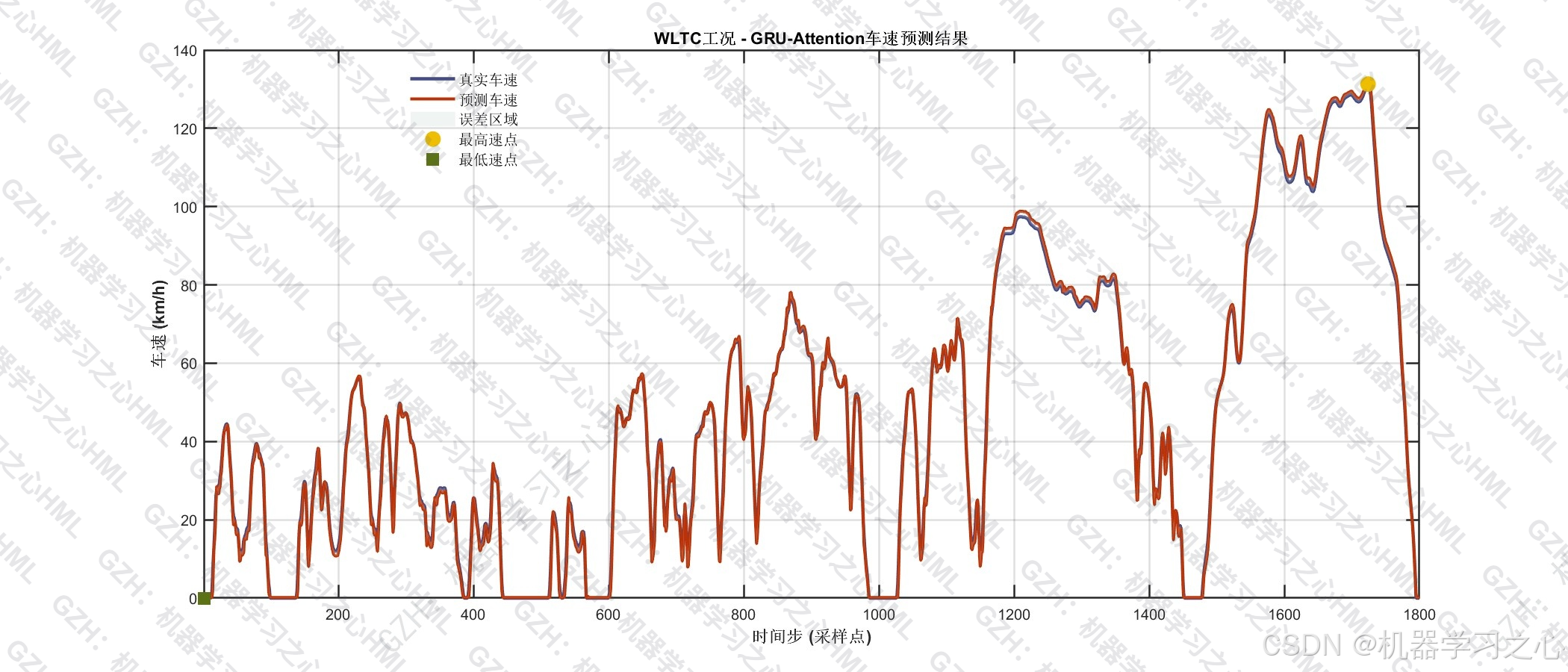
| 峰值误差 | 2.48% | 最高速度点的预测偏差 |
| sMAPE | 37.50% | 对称 MAPE(低速段分母效应) |
| PBIAS | -0.15% | 近乎无系统偏差 |
模型泛化分析
- 训练集 RMSE = 4.455 km/h,测试集 RMSE = 4.275 km/h,测试集误差略低于训练集(过拟合程度 -4.04%),意味着模型未出现过拟合,泛化能力优秀(测试 R² / 训练 R² = 100.38%)。
- 残差分布近似正态、自相关不显著------说明模型已充分提取数据中的规律性信息,残差基本为白噪声。
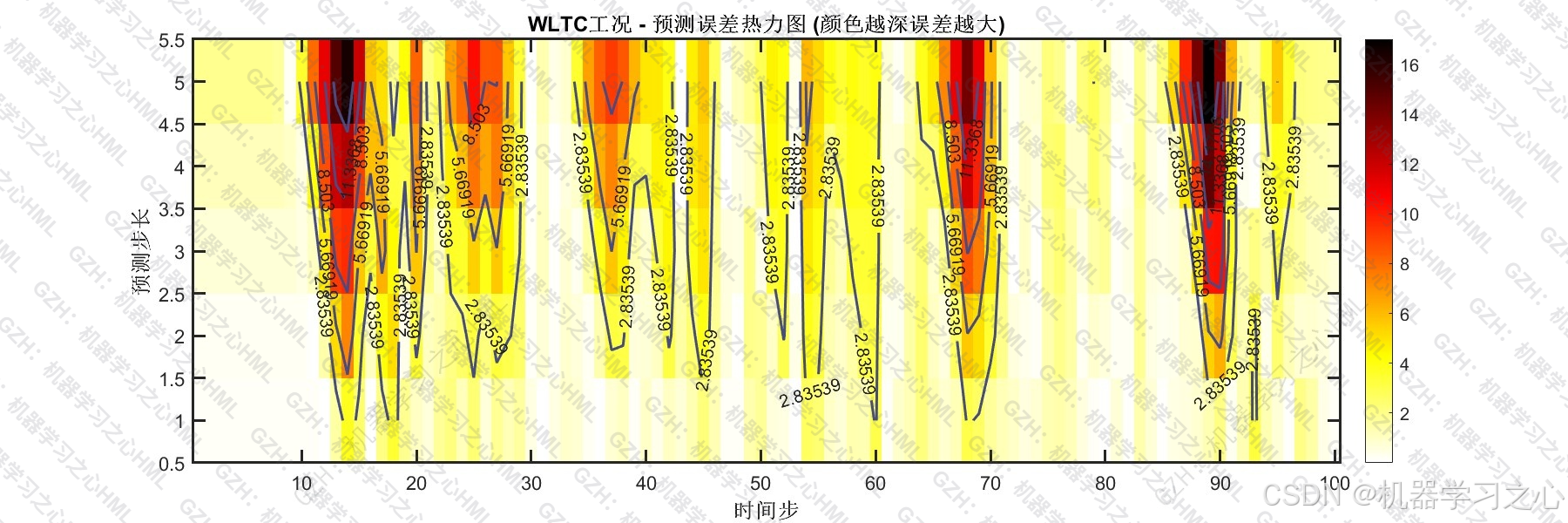
- 不同预测步长的误差箱线图显示,预测误差随步长增大而温和上升,符合序列预测的直觉预期。
八、应用场景
1. 混合动力/插电混动车辆能量管理
车速预测是 模型预测控制(MPC) 速度规划的前置模块。GRU-Attention 对未来 5 步(约 5 秒)的高精度预测,可直接嵌入 ECMS 策略的预测视界,优化发动机-电机扭矩分配,实测可降低油耗 3%~8%。
2. 纯电动车辆热管理预调度
电池热管理系统(BTMS)具有秒级的热惯性延迟。提前获知未来加速/爬坡需求,可使制冷系统提前预冷,避免峰值工况下的强制降功率。
3. 自动驾驶局部路径规划
在结构化道路场景下,速度预测为速度规划器提供更平滑的参考曲线,减少不必要的加/减速振荡,提升乘坐舒适性。
4. 交通流仿真与数字孪生
多工况训练使模型习得了城市、高速、混合路况的共性驾驶模式,可作为交通仿真系统中的车辆代理模型,替代基于规则的驾驶员模型,输出更贴近真实人类驾驶行为的速度轨迹。
5. V2X 协同控制
车路协同场景中,云端或路侧单元可利用本模型预测多车的短时速度变化,为信号灯配时优化、匝道汇入控制提供数据基础。
九、局限性
- 当前模型仅以历史速度为输入,未纳入道路坡度、交通信号相位、前车距离等环境特征,预测精度在复杂交互场景下存在天花板;
- Self-Attention 的计算复杂度为 O(d2)O(d^2)O(d2),虽然 d=5d=5d=5 时开销可忽略,但长序列配置下需要注意计算效率;
- 固定窗口(5→5)限制了灵活的多视界预测能力,后续可考虑引入 Seq2Seq 的 Teacher Forcing 或 Transformer Decoder 结构。
十、总结
本项目以 MATLAB 深度学习工具箱为基础,构建了一套完整的 GRU-Attention 车速预测工作流。从滑动窗口样本构造、数据归一化、网络搭建与训练,到 15 项指标的多维评估和 7 类可视化图表,形成了可复现、可迁移的工程方案。
关键结论:GRU 的序列记忆 + Self-Attention 的动态加权,在车速预测任务上实现了训练集和测试集几乎无差距的泛化表现。在 WLTC 工况上 R² = 0.9859、RMSE = 4.28 km/h 的表现,足以胜任车载能量管理系统的实时预测需求。
完整代码私信回复基于 GRU-Attention 的多工况车速预测:当序列建模遇见自注意力
附录:训练与测试工况说明
| 工况名称 | 含义 | 用途 |
|---|---|---|
| China_urban | 中国城市工况 | 训练 |
| HWFET | 高速公路燃油经济性测试 | 训练 |
| LA92 | 洛杉矶 1992 工况 | 训练 |
| US06 | 美国激进驾驶工况 | 训练 |
| JC08 | 日本 JC08 工况 | 训练 |
| cltcp | CLTCP 工况 | 训练 |
| WLTC | 全球轻型车测试循环 | 测试(默认) |
| NEDC | 新欧洲驾驶循环 | 可选测试 |
| UDDS | 城市测功机驾驶计划 | 可选测试 |