Craig Iaboni , 新泽西理工学院, 美国
Pramod Abichandani, 新泽西理工学院, 美国
摘要
可靠的无人机(UAV)目标检测需要对光照变化、运动模糊以及会抑制 RGB 线索的场景动态具有鲁棒性。热长波红外(LWIR)传感在低光环境下能保持对比度,而事件相机能保留微秒级的时间边缘信息,但在统一的检测器中系统性地整合这三种模态尚未得到充分研究。我们提出了一种三模态框架,该框架使用双流分层视觉 Transformer 来处理 RGB、热成像和事件数据。在选定的编码器深度,模态感知门控交换(MAGE, Modality-Aware Gated Exchange) 模块应用传感器间的通道和空间门控,而双向令牌交换(BiTE, Bidirectional Token Exchange) 模块执行带有深度-逐点(depthwise-pointwise)细化的双向令牌级注意力,从而生成保留分辨率的融合特征图,以供标准特征金字塔和两阶段检测器使用。
我们引入了一个包含 10,489 帧的无人机数据集,该数据集具有同步且预对齐的 RGB-热成像-事件流,并包含跨昼夜飞行的 24,223 个标注车辆。通过 61 次受控消融实验,我们评估了融合位置、融合机制(基线 MAGE+BiTE、CSSA、GAFF)、模态子集以及骨干网络容量。三模态融合优于所有双模态基线,其中融合深度具有显著影响,而轻量级的 CSSA 变体以极小的计算成本恢复了大部分性能收益。这项工作为三模态基于无人机的目标检测提供了首个系统性基准和模块化骨干网络。
1. 引言 (Introduction)
无人机感知系统日益需要在没有任何单一传感器可靠的条件下运行:可见光相机在低光和运动下会丢失判别性结构,热传感器在平台快速动态变化时会饱和或模糊,而事件相机仅提供稀疏且带有噪声的运动证据。尽管这些传感器具有互补的优缺点,但现有的检测流水线绝大多数围绕 RGB 构建,或最多是双模态配对。这留下了一个根本性的架构问题未解决:在现代检测器中,三种异构传感模态应如何交互,以便每种模态都能弥补其他模态的失效模式?无人机会经历独立的失效模式:光照崩溃、平台模糊、快速场景运动、大气效应和热杂波。RGB、热成像和事件传感器各自只能解决这些条件的一部分,且没有任何模态对能在所有条件下保持可靠。这促使我们设计一种检测器,使其能够随着条件在帧内和跨帧的变化,选择性地依赖仍具有信息量的模态。
三模态融合的挑战远不止于简单地堆叠通道。LWIR 图像反映的是辐射对比度而非纹理;事件流编码异步的时间变化,没有绝对强度;而 RGB 提供高分辨率结构,但在光照变化下会失效。这些模态在噪声特性、空间对齐敏感度、时间密度以及跨条件的语义可靠性方面各不相同。传统的早期融合方法忽略了这些差异,而晚期融合流水线则放弃了共同塑造中间表示的能力。Transformer 骨干网络为跨模态交换提供了自然的接口,但融合应在何种分辨率以及如何进行,尚未得到系统探索。
本工作将三模态融合视为一个架构设计空间,而非特征级的附加组件。我们的骨干网络在保留模态特定结构的地方维持独立的流,并仅在选定的中间阶段将它们耦合,从而能够对融合何时、何地以及如何生效进行受控研究。该框架支持对融合算子、融合深度、模态组合和骨干网络容量进行定量比较,而这些维度在以往的多模态检测工作中,尚未在单一、受控的设置下进行过评估。现有的 RGB-热成像和 RGB-事件数据集未提供同步的三模态帧或分辨率对齐的标注,这使得在不构建专用数据集的情况下,无法进行受控的三模态融合研究。

2. 相关工作 (Related Work)
2.1 目标检测的多模态融合
基于 RGB 图像的单模态检测器在低光照、运动模糊和恶劣环境条件下性能会急剧下降。这促使人们广泛研究将 RGB 与互补传感模态配对。RGB-热成像方法利用 LWIR 对比度在可见光线索失效时恢复目标。RGB-事件方法利用微秒级的时间变化来稳定快速运动下的检测。热成像-事件融合也得到了探索,利用事件的时间稀疏性来细化低光下的热特征。
尽管双模态工作广泛,但几乎所有先前的努力都将融合限制在针对特定操作机制(如夜间 RGB-热成像或高速 RGB-事件检测)的两种模态。据我们所知,没有现有的检测器在统一架构中整合 RGB、热成像和事件传感,也没有用于系统研究这三种模态应如何交互的三模态无人机基准。本文通过提供三模态数据集和受控融合框架来填补这一空白。
2.2 融合机制与注意力算子
多模态检测的核心挑战是确定异构传感器流应在何处以及如何交互。经典分类学区分了早期、晚期和中间融合,但大多数多模态检测器采用简单的输入通道拼接或靠近输出的高层特征合并。中间融合(模态在骨干网络内交换信息)显示出更强的性能,但设计空间仍未被充分探索,尤其是对于两种以上的模态。
已有多种算子被提出用于跨模态特征交互。通道门控机制(如 SE 和 ECA)基于全局响应调制激活,而空间注意力模块将融合引导至模态一致的位置。几种架构结合了这些思想:GAFF 使用空间引导掩码融合 RGB-热特征;CGFNet 跨尺度交替使用引导和交叉引导融合块;CMAFF 引入了不确定性感知加权;CSSA 在进行空间选择之前,用跨模态对应物替换低显著性通道。其他方法执行迭代或多阶段细化。
大多数现有算子仅解决 RGB-热成像或 RGB-事件融合,当扩展到三模态输入或分层 Transformer 骨干网络时,其行为鲜为人知。相比之下,我们的研究将多种融合家族(包括通道/空间门控和交叉注意力式交互)嵌入统一的 Transformer 框架中,使得在相同的架构和检测设置下,能够对融合深度和机制进行受控比较。
2.3 用于多模态视觉的分层骨干网络
多模态检测器通常使用独立的骨干流,因为模态特定的低级结构限制了完全的参数共享。分层 Transformer 特别适用于此设置,因为它们提供多尺度令牌表示和用于中间跨模态交互的自然接口。Mix-Transformer (MiT) 编码器由于其重叠的 patch 嵌入和多分辨率特征层次结构,特别适合分阶段融合。
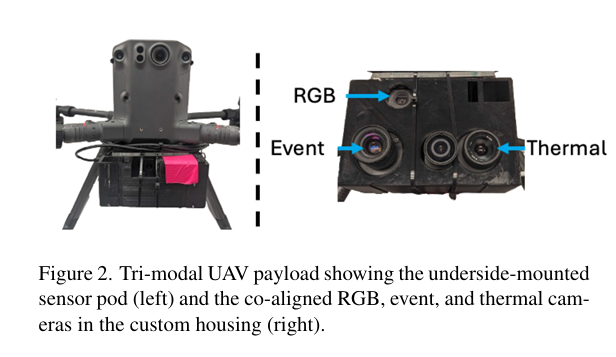
3. 系统设置 (System Setup)
3.1 硬件
三模态有效载荷包含三个同步相机,安装在一个定制的 3D 打印外壳中,具有固定的基线和近似平行的光轴,以确保视场间稳定的重叠。RGB 流由 Logitech HD 相机以 1920×10801920 \times 10801920×1080 分辨率和 30 FPS 捕获。热成像由 FLIR Duo 提供,工作在 7.5--13.5 μm7.5\text{--}13.5\ \mu\text{m}7.5--13.5 μm LWIR 波段,分辨率为 640×512640 \times 512640×512,30 FPS。事件数据由 Prophesee VGA 对比度传感传感器记录(640×480640 \times 480640×480 像素,15 μm15\ \mu\text{m}15 μm 像素间距,>120 dB>120\ \text{dB}>120 dB 动态范围)。
所有三个传感器都刚性集成在外壳中,并由板载 NVIDIA Jetson Xavier 进行时间戳记,处理采集和存储。有效载荷由专用电池组供电,并在 DJI M300 平台上飞行。每次飞行会话前进行内参和外参校准,模态间的重投影误差保持在 1.5 像素以下。
3.2 数据集
我们在上述平台上获取了一个三模态数据集用于评估融合策略。每个样本包含一个预对齐的五通道图像张量和 YOLO 格式的标签。数组 X∈RH×W×5X \in \mathbb{R}^{H \times W \times 5}X∈RH×W×5 以 .npy 格式存储,其中通道 0-2 为 RGB,通道 3 为热成像,通道 4 为事件帧;标签为每图像的 YOLO 文本文件。语料库包含 10,489 张图像和 24,223 个单类别(车辆)边界框。我们专注于单一车辆类别,以建立一个具有高质量跨模态标注的受控三模态基准。所有模态都预扭曲到公共平面和分辨率,大多数图像标准化为 301×391301 \times 391301×391 像素。流通过 Jetson 硬件时间戳同步。
数据在多种交通和光照条件下,于城市大学校园上空的多架次无人机飞行中收集。数据集跨越不同的时间段,包含 6,412 张白天图像和 4,077 张夜间图像(61.1% 白天 / 38.9% 夜间)。夜间部分用于对仅 RGB 的检测器施加压力,并突出热成像和事件线索的贡献。
采用半自动标注协议。对于白天序列,预训练的 YOLO 检测器仅在 RGB 帧上生成初始候选框。这些候选框使用跨模态校准投影到公共图像平面,然后由人工标注者进行详尽审查,添加遗漏的对象,移除假阳性,并修正框的范围。对于夜间序列,由于 RGB 提议不可靠,所有图像在投影前均在热成像平面中手动标注,然后进行第二轮质量检查。最终标签是共享图像平面中经过人工验证的标注。
事件帧通过在以每个 RGB/热成像时间戳为中心、固定时间窗口 Δt≈33.3 ms\Delta t \approx 33.3\ \text{ms}Δt≈33.3 ms(匹配 30 FPS 帧间隔)内对极性事件进行分箱(binning)生成,随后进行每窗口归一化。极性被保留,每个窗口内的事件被形成激活图,其中每个像素在归一化前信号化 ON/OFF 事件的存在。在训练前,每个通道进行仿射归一化:RGB 通道使用 ImageNet 统计信息,而热成像和事件通道使用从训练集计算的统计信息。
4. 方法 (Method)
4.1 模型架构
我们的检测器对三模态输入进行操作,结合了双流分层 Transformer、分阶段跨模态交互以及标准的基于 FPN 的两阶段检测头。每个样本是一个五通道张量 X∈RB×5×H×WX \in \mathbb{R}^{B \times 5 \times H \times W}X∈RB×5×H×W,由三个 RGB 通道、一个热成像通道和一个事件通道堆叠而成。输入被划分为 RGB 流 XrgbX_{rgb}Xrgb 和热成像-事件(TE)流 XTEX_{TE}XTE。
两个流都由具有独立权重的相同四阶段 Mix-Transformer (MiT) 骨干网络处理。各阶段执行重叠的 patch 嵌入和具有阶段依赖空间缩减的多头自注意力,生成步长为 {4,8,16,32}\{4, 8, 16, 32\}{4,8,16,32} 的多尺度特征图。在选定的阶段,骨干网络插入一个融合块,在保留空间分辨率和通道宽度的同时校正并合并这两个流。所有活跃阶段的融合输出被原样传递给五级 FPN,进而馈入标准的 Faster R-CNN 头以进行区域提议和分类。由于骨干网络在融合放置时保持固定的形状,颈部和检测头无需针对任何消融实验进行架构更改。
4.2 分层传感器间骨干网络
每个流由遵循 MiT 设计的四阶段分层 Transformer 编码。阶段 1 对原始输入应用 7×77 \times 77×7 / stride 4 的重叠 patch 嵌入;阶段 2-4 对前一阶段的输出使用 3×33 \times 33×3 / stride 2 的嵌入。令牌由 Transformer 块处理,包含预归一化 LayerNorm、空间缩减注意力和前馈网络(在两个线性层之间包含深度 3×33 \times 33×3 卷积,以恢复局部空间耦合)。
对于 224×224224 \times 224224×224 的参考输入,每阶段的空间分辨率分别为 56×5656 \times 5656×56、28×2828 \times 2828×28、14×1414 \times 1414×14 和 7×77 \times 77×7,通道宽度为 {64,128,320,512}\{64, 128, 320, 512\}{64,128,320,512}。两个流遵循相同的分辨率调度,确保每个阶段的形状对齐。在每个阶段结束时,令牌被重塑回特征图,并传递给第 4.3 节描述的传感器间交互模块。未选择进行融合的阶段仅向前传播其模态特定的图。
4.3 逐阶段校正与融合
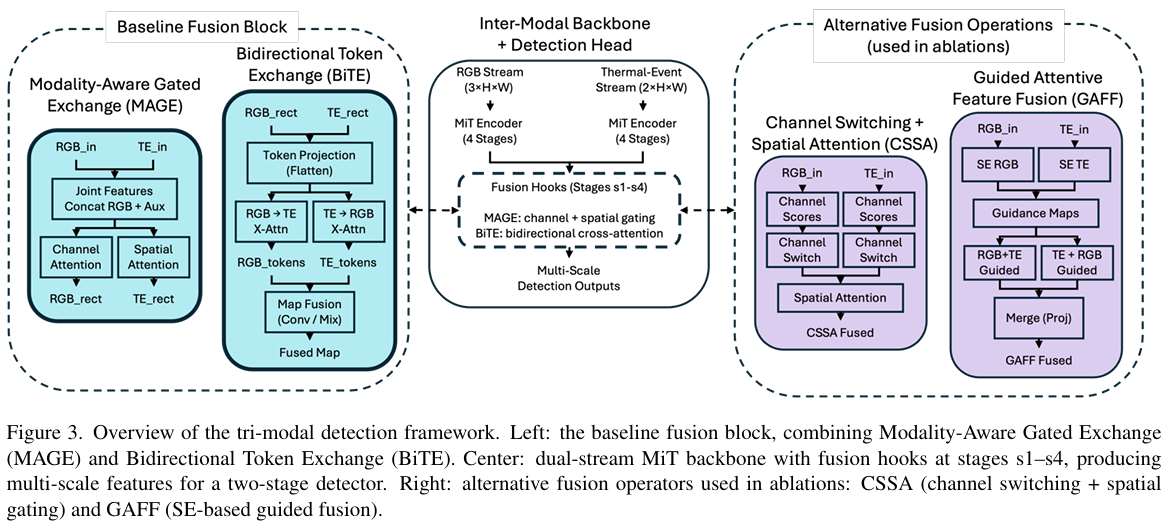
融合发生在四个骨干阶段的一个子集中。在每个选定的阶段,两个子模块在 RGB 和 TE 特征图 xrgb,xTE∈RB×C×H×Wx_{rgb}, x_{TE} \in \mathbb{R}^{B \times C \times H \times W}xrgb,xTE∈RB×C×H×W 上操作:(1) 模态感知门控交换 (MAGE) ,执行跨模态通道和空间门控;(2) 双向令牌交换 (BiTE),将门控流聚合为单一融合表示,同时保留空间大小和宽度。
4.3.1 模态感知门控交换 (MAGE)
MAGE 从拼接的描述符计算通道和空间门:
z=xrgb∥xTE∈RB×2C×H×Wz = x_{rgb} \\\| x_{TE} \in \mathbb{R}^{B \times 2C \times H \times W}z=xrgb∥xTE∈RB×2C×H×W
允许每个流基于来自两种模态的联合证据进行调制,而不是基于单流统计。
通道门控 :对 zzz 的全局平均和最大池化形成互补的全局摘要,通过两层 1×11 \times 11×1 MLP(非线性 + sigmoid)产生方向性每通道门:
wTE→rgbc,wrgb→TEc∈0,1B×C×1×1w^c_{TE \to rgb}, w^c_{rgb \to TE} \in 0, 1^{B \times C \times 1 \times 1}wTE→rgbc,wrgb→TEc∈0,1B×C×1×1
门仅调制跨流残差,保持每个流的恒等路径不变。
空间门控 :轻量级的 1×1→非线性→1×11 \times 1 \to \text{非线性} \to 1 \times 11×1→非线性→1×1 头从 zzz 预测逐像素掩码:
wTE→rgbs,wrgb→TEs∈0,1B×1×H×Ww^s_{TE \to rgb}, w^s_{rgb \to TE} \in 0, 1^{B \times 1 \times H \times W}wTE→rgbs,wrgb→TEs∈0,1B×1×H×W
这些掩码仅缩放跨残差更新,将空间转移限制在模态表现出一致证据的位置,并抑制在噪声或模态特定区域的转移。MAGE 的输出是校正后的特征图:
x^rgb=xrgb+wTE→rgbs⋅(wTE→rgbc⋅xTE)\hat{x}{rgb} = x{rgb} + w^s_{TE \to rgb} \cdot (w^c_{TE \to rgb} \cdot x_{TE})x^rgb=xrgb+wTE→rgbs⋅(wTE→rgbc⋅xTE)
x^TE=xTE+wrgb→TEs⋅(wrgb→TEc⋅xrgb)\hat{x}{TE} = x{TE} + w^s_{rgb \to TE} \cdot (w^c_{rgb \to TE} \cdot x_{rgb})x^TE=xTE+wrgb→TEs⋅(wrgb→TEc⋅xrgb)
4.3.2 双向令牌交换 (BiTE)
BiTE 通过对称交叉注意力和轻量级空间细化来融合校正后的图。将 x^rgb,x^TE\hat{x}{rgb}, \hat{x}{TE}x^rgb,x^TE 展平为令牌序列 Trgb,TTE∈RB×N×CT_{rgb}, T_{TE} \in \mathbb{R}^{B \times N \times C}Trgb,TTE∈RB×N×C(其中 N=HWN = HWN=HW),我们形成投影:
Qs=TsWQs,Ksˉ=TsˉWKsˉ,Vsˉ=TsˉWVsˉ,s∈{rgb,TE}Q_s = T_s W_{Q_s}, \quad K_{\bar{s}} = T_{\bar{s}} W_{K_{\bar{s}}}, \quad V_{\bar{s}} = T_{\bar{s}} W_{V_{\bar{s}}}, \quad s \in \{rgb, TE\}Qs=TsWQs,Ksˉ=TsˉWKsˉ,Vsˉ=TsˉWVsˉ,s∈{rgb,TE}
并通过交叉注意力更新每个流:
T~s=Ts+Softmax(QsKsˉ⊤d)Vsˉ\tilde{T}s = T_s + \text{Softmax}\left(\frac{Q_s K{\bar{s}}^\top}{\sqrt{d}}\right) V_{\bar{s}}T~s=Ts+Softmax(d QsKsˉ⊤)Vsˉ
更新是残差的,保留了模态特定的内容,同时引入了跨模态上下文。
拼接更新后的令牌 Z=T\~rgb;T\~TE∈RB×N×2CZ = \\tilde{T}_{rgb}; \\tilde{T}_{TE} \in \mathbb{R}^{B \times N \times 2C}Z=T\~rgb;T\~TE∈RB×N×2C 并重塑为图,得到 U0∈RB×2C×H×WU_0 \in \mathbb{R}^{B \times 2C \times H \times W}U0∈RB×2C×H×W。深度 3×33 \times 33×3 卷积恢复局部性,1×11 \times 11×1 投影混合通道并将宽度压缩回 CCC,生成融合图 u∈RB×C×H×Wu \in \mathbb{R}^{B \times C \times H \times W}u∈RB×C×H×W。
4.4 融合位置
融合钩子被插入到四个分辨率对齐的骨干阶段(步长 {4,8,16,32}\{4, 8, 16, 32\}{4,8,16,32})。在选定的阶段,骨干网络用 MAGE 和 BiTE 产生的单一融合图替换两个模态特定的输出。由于融合保留了空间步长和通道宽度,所有配置(单阶段、多阶段或全阶段融合)都为 FPN 和两阶段检测器提供相同的接口。
4.5 特征金字塔颈部 (FPN)
我们使用标准的自顶向下特征金字塔网络,将阶段输出投影到 256 个通道,并在步长 {4,8,16,32,64}\{4, 8, 16, 32, 64\}{4,8,16,32,64} 处生成五级金字塔。颈部在所有融合配置中保持固定。
4.6 两阶段检测头
检测使用标准的 Faster R-CNN 头在五个 FPN 级别上执行,包括 RPN、RoIAlign 和框/类别预测分支。锚点、提议分配、损失函数和头设置在所有实验中保持固定。
4.7 消融协议
我们将融合视为可在四个骨干阶段中任意插入的可插拔算子。对于给定配置,我们在选定的阶段子集激活融合,同时保持所有下游组件相同。这隔离了两个变量:(1) 哪些阶段执行融合,(2) 在这些阶段使用哪种融合机制。
4.7.1 CSSA:通道切换与空间注意力
CSSA 提供了基线融合块的轻量级替代方案。它首先使用全局平均池化、短 1D 卷积和 sigmoid 激活对每个流中的通道进行评分。得分低于阈值 τ\tauτ 的通道被替换为另一流中同索引的对应物。然后通过小型卷积头从拼接的切换张量预测空间门,并在每个像素处进行选择。
4.7.2 GAFF:引导式注意力特征融合
GAFF 是一种更高容量的替代方案,结合了通道重新校准和空间引导的跨模态更新。每个流首先由 squeeze-excitation (SE) 块处理以强调信息丰富的通道。然后预测方向引导图,以便每种模态通过残差注入接收来自另一种模态的位置感知校正。
5. 实验评估与结果 (Experimental Evaluation and Results)
5.1 训练设置
所有模型使用随机梯度下降(动量 0.9,权重衰减 1×10−41 \times 10^{-4}1×10−4)训练 15 个 epoch,并采用余弦学习率调度,在前 500 次迭代中线性预热。基础学习率为 0.02(全局批大小为 16),并随批大小线性缩放。输入使用预对齐的本地分辨率(301×391301 \times 391301×391),并在每侧填充到 32 的最近倍数以兼容 FPN。
5.2 骨干网络容量
表 1 报告了在标准 MAGE+BiTE 基线和三模态输入下,MiT 骨干网络(B0-B4)的编码器大小影响。性能呈非单调变化。MiT-B1 获得了最佳的 mAP (84.24%),参数量仅为 B4 的三分之一。更大的骨干网络(B2-B4)并未将额外容量转化为检测性能的提升,B4 甚至低于 B0。因此,MiT-B1 提供了最佳的精度-效率权衡,被用作后续研究的默认骨干网络。
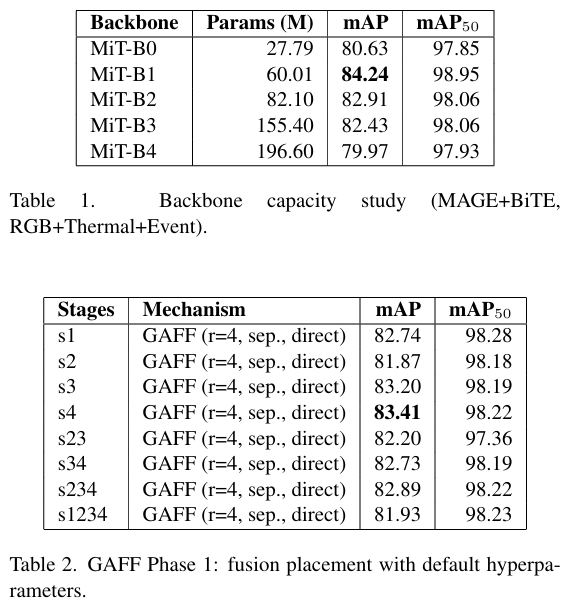
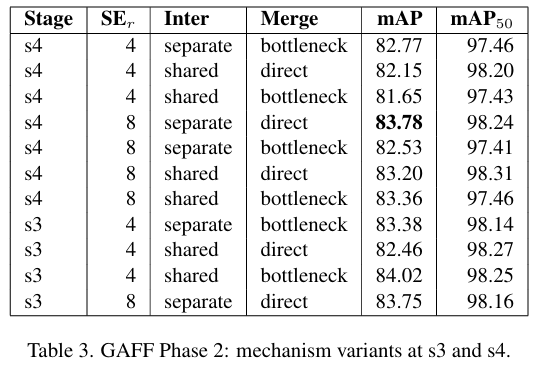
5.3 GAFF 消融
表 2 和表 3 报告了 GAFF 的放置和机制变体研究。GAFF 在较深阶段(如 s4)单次插入时表现最佳。在 s4 处,最佳配置使用 r=8r=8r=8、独立引导和直接合并(83.78% mAP)。在所有设置中,GAFF 匹配或略微落后于基线 MAGE+BiTE 融合。
5.4 CSSA 消融
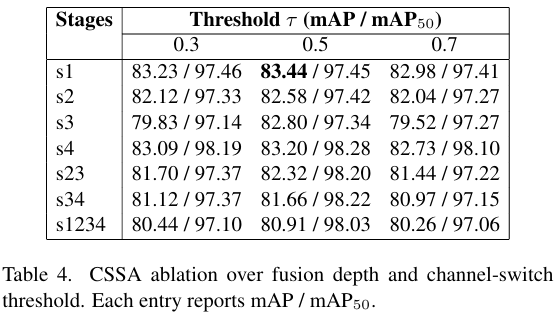
表 4 评估了 CSSA 作为 MAGE+BiTE 的轻量级即插即用替换。CSSA 表现出对早期融合的偏好。最佳配置仅在阶段 1 应用 CSSA 且 τ=0.5\tau=0.5τ=0.5,达到 83.44% mAP。跨尺度的重复通道切换似乎会侵蚀模态特定的结构,而不是增强它。
5.5 模态消融与外部基线
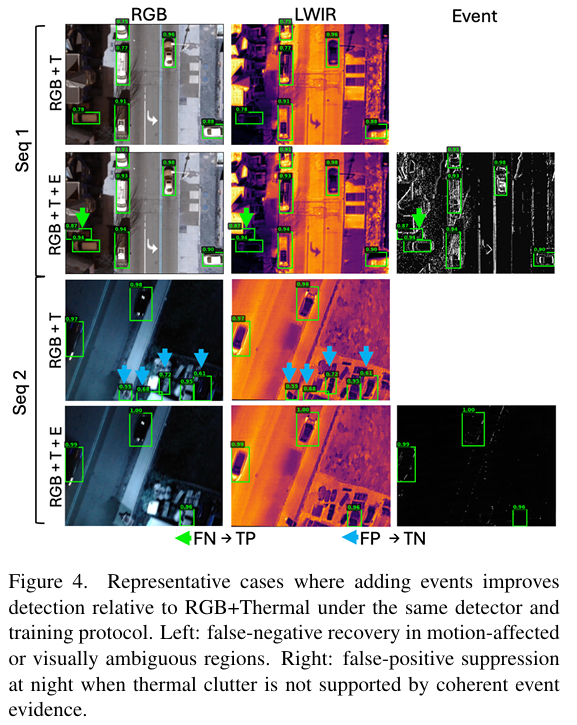
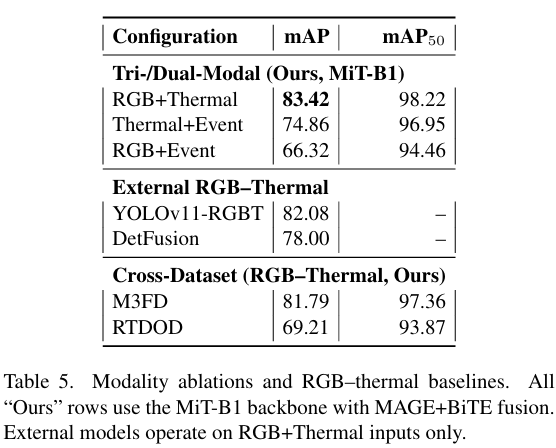
为了量化每个传感器的贡献,我们训练了三个双模态变体(表 5)。在双模态变体中,RGB+Thermal 是最强的配对(83.42% mAP),而最佳三模态设置产生了适度的额外增益,表明大部分收益来自于将 RGB 与热成像结合,而事件主要在特定的失效机制下提供补充价值。Thermal+Event (74.86% mAP) 明显较弱,RGB+Event 表现最差(66.32% mAP),这与热成像作为无人机检测中最具信息量的次要模态的结论一致。
5.6 白天与夜间训练
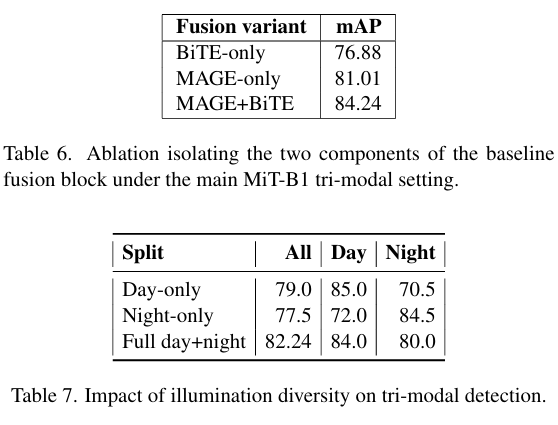
表 7 量化了训练中光照多样性的影响。在单一光照机制下训练的模型会对该机制过拟合:仅白天训练的模型无法泛化到夜间场景,仅夜间训练的模型在白天图像上表现不佳。在全天候(白天+夜间)语料库上训练可获得最佳的整体性能,并在白天和夜间精度之间取得更平衡的权衡,强调了多样化光照对三模态无人机检测的重要性。
6. 结论 (Conclusion)
我们提出了一种三模态 RGB-热成像-事件检测框架和一个同步的无人机数据集,使得能够对跨模态融合进行受控评估。系统性的消融实验表明,三模态 consistently 优于双模态,且融合深度和机制是决定性因素,轻量级的 CSSA 在早期阶段有效,而更高容量的 GAFF 在较深层选择性应用时最有用。该框架和数据集为未来关于时间三模态融合和自适应模态选择的工作奠定了可重复的基础。