大家好,我是上好佳佳佳呀。今天我们开始拆解 LangChain 里那条最经典的 RAG 流程。今天的学习内容从Document 对象开始,到上游流程的 Loader 和 Splitter 是怎么一步一步把原始文档变成可检索的小块。我们把这些环节理顺,后面再去学习和串联 Embedding、VectorStore 和 Retriever 就会从容许多啦,那我们开始吧~
文章目录
- [前言:我们为什么需要 RAG?](#前言:我们为什么需要 RAG?)
- [1. RAG 的核心概念与工作流程](#1. RAG 的核心概念与工作流程)
-
- [1.1 RAG 是什么?](#1.1 RAG 是什么?)
- [1.2 RAG 的标准流程](#1.2 RAG 的标准流程)
- [1.3 LangChain 中的 RAG](#1.3 LangChain 中的 RAG)
- [2. Document 对象](#2. Document 对象)
-
- [2.1 什么是 Document?](#2.1 什么是 Document?)
- [2.2 认识 metadata](#2.2 认识 metadata)
- [2.3 Document 实践](#2.3 Document 实践)
- [3. Document Loader](#3. Document Loader)
-
- [3.1 Loader 与 Document 的关系](#3.1 Loader 与 Document 的关系)
- [3.2 Loader 的统一接口](#3.2 Loader 的统一接口)
- [3.3 常用 Loader](#3.3 常用 Loader)
- [3.4 各类 Loader 详解](#3.4 各类 Loader 详解)
-
- [① TextLoader](#① TextLoader)
- [② PyPDFLoader / PyMuPDFLoader](#② PyPDFLoader / PyMuPDFLoader)
- [③ WebBaseLoader](#③ WebBaseLoader)
- [④ CSVLoader](#④ CSVLoader)
- [⑤ JSONLoader](#⑤ JSONLoader)
- [⑥ DirectoryLoader](#⑥ DirectoryLoader)
- [4. Text Splitter](#4. Text Splitter)
-
- [4.1 为什么要切?](#4.1 为什么要切?)
- [4.2 RecursiveCharacterTextSplitter](#4.2 RecursiveCharacterTextSplitter)
- [4.3 基本用法](#4.3 基本用法)
- [4.4 参数逐一详解](#4.4 参数逐一详解)
-
- [4.4.1关于 length_function 的深入理解](#4.4.1关于 length_function 的深入理解)
- [4.4.2 chunk_overlap 到底解决了什么问题?:](#4.4.2 chunk_overlap 到底解决了什么问题?:)
- [4.4.3 chunk_size 和 chunk_overlap 到底设多少?](#4.4.3 chunk_size 和 chunk_overlap 到底设多少?)
- [4.4.4 中文场景的优化配置](#4.4.4 中文场景的优化配置)
- [4.5 两个切分方法对比](#4.5 两个切分方法对比)
前言:我们为什么需要 RAG?
在正式进入 LangChain 的技术细节之前,有必要先搞清楚一个根本性的问题:RAG 到底解决了什么痛点?
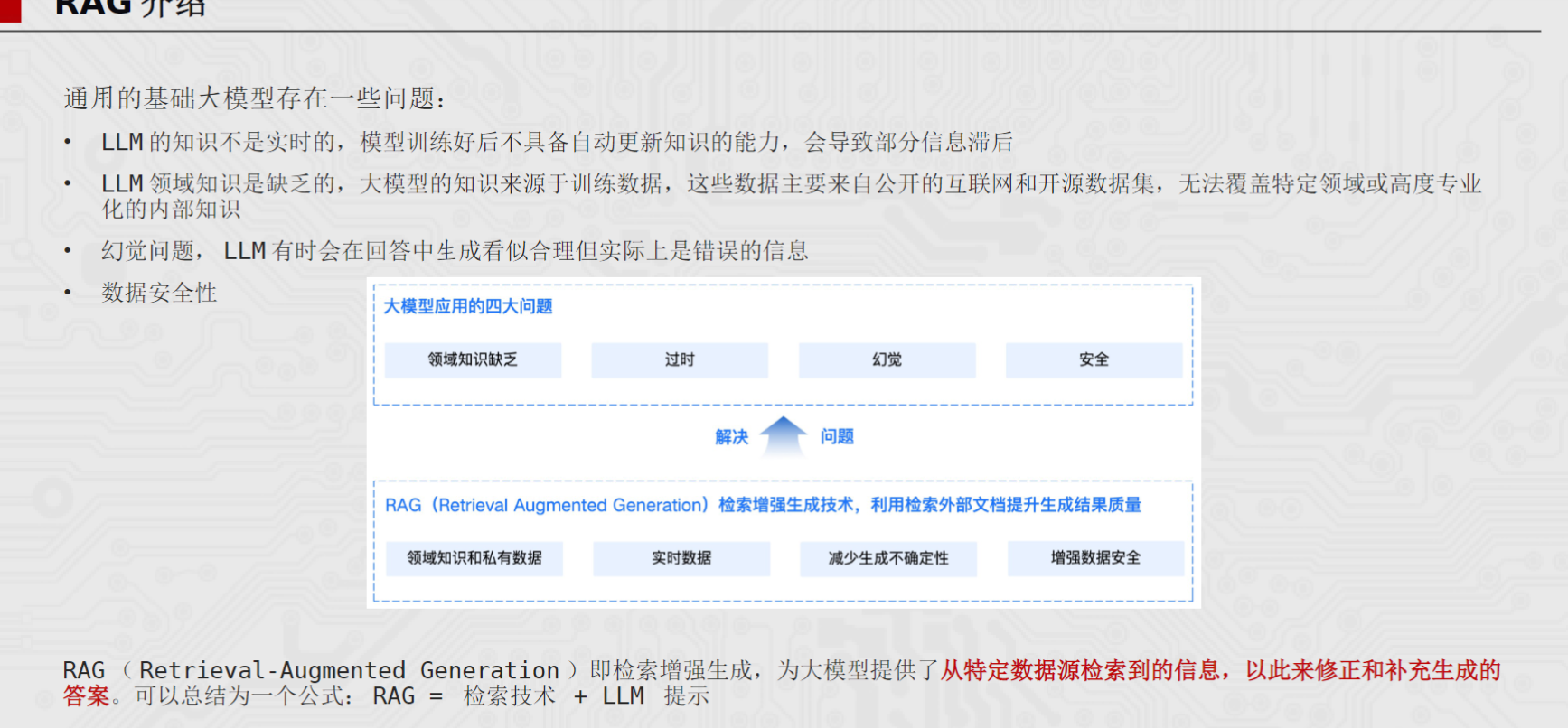
大语言模型(LLM)虽然能力强大,但它存在四个"先天不足":
| 痛点 | 具体表现 | 通俗理解 |
|---|---|---|
| 🕐 知识滞后 | 模型训练完成后就不再具备自动更新知识的能力。比如你用 大模型 问"2026 年世界杯冠军是谁",它答不上来,因为训练数据截止在某个时间点之前 | 模型是一本"历史书",不是"新闻联播" |
| 📚 领域知识缺乏 | 大模型的训练数据主要来自公开互联网和开源数据集,无法覆盖企业内部的高度专业化知识(如公司内部规章制度、产品技术文档、行业专属术语等) | 模型是"通才",不是你公司的"行业专家" |
| 🤥 幻觉问题 | LLM 有时会生成看似合理但实际上是错误的信息,更可怕的是,它说错了还说得头头是道,让人难以分辨 | 模型会"不懂装懂",而且装得很逼真 |
| 🔒 数据安全性 | 把企业内部敏感数据上传给第三方模型做微调或直接提问,存在严重的合规和安全风险 | 你不敢把公司的"机密文件"直接发给外人看 |
vs 传统解法 微调(Fine-tuning): 也能让模型学到新知识,但成本高昂,需要准备高质量标注数据、消耗大量 GPU 算力、每次知识更新都要重新训练。而且微调是"把知识写入模型参数",更新不灵活,还可能导致灾难性遗忘(模型原有能力退化)。
** RAG 它最大的优势是:无需重新训练模型,就能让 LLM 回答它"本不知道"的问题。**
1. RAG 的核心概念与工作流程
1.1 RAG 是什么?
RAG(Retrieval-Augmented Generation),全称"检索增强生成"。这个命名本身就精准道出了它的本质:
RAG = 检索技术(Retrieval)检索 + LLM 提示(Prompt)增强生成
它不像微调那样"把知识写进模型的脑子里",而是给模型配了一个**"外挂知识库"**。用户提问时,先从知识库中检索出最相关的信息 检索,然后把"问题 + 检索到的资料" 增强生成 一起发给 LLM,让 LLM 参照资料来生成回答。
用一个生活化场景来感受一下 RAG 到底做了什么:
❌ 没有 RAG(纯 LLM):
你:「公司今年的年假政策是什么?」
LLM:「抱歉,我没有贵公司的内部政策信息......」(或者开始瞎编)
✅ 有 RAG 后:
你:「公司今年的年假政策是什么?」
系统:先从《员工手册.pdf》中搜到第 15 页的"休假制度"段落
↓
然后发给 LLM:
「请根据以下资料回答用户问题:
【参考资料】员工每年享有 5 天带薪年假,工作满 10 年的员工增加至 10 天......
【用户问题】公司今年的年假政策是什么?」
↓
LLM:「根据公司规定,员工每年享有 5 天带薪年假......」✅ 有据可查!本质上,RAG 做了一件事:在用户问题和 LLM 之间,插入了一个"知识检索"环节,让 LLM 从"凭记忆闭卷答题"变成"带着参考资料开卷考试"。
1.2 RAG 的标准流程
RAG 的完整工作流程可以拆成"一静一动"两条线:
-
离线知识库构建
-
在线问答检索
┌──────────────────────────────────────────────────────────────────┐
│ 离线知识库构建(提前做好,一劳永逸) │
│ │
│ 📄 文档加载 → ✂️ 文档切分 → 🧮 向量化 → 💾 存入向量数据库 │
│ (Loader) (Splitter) (Embedding) (VectorStore) │
└──────────────────────────────────────────────────────────────────┘
↓ (构建完成后,随时可以问答)
┌──────────────────────────────────────────────────────────────────┐
│ 在线问答流程(用户提问时实时运行) │
│ │
│ 🙋 用户提问 → 🔍 向量检索 → 🔗 Prompt融合 → 🤖 LLM生成回答 │
│ │ │
│ 【问题 + 检索到的相关文档片段 → 一起发给LLM】 │
└──────────────────────────────────────────────────────────────────┘
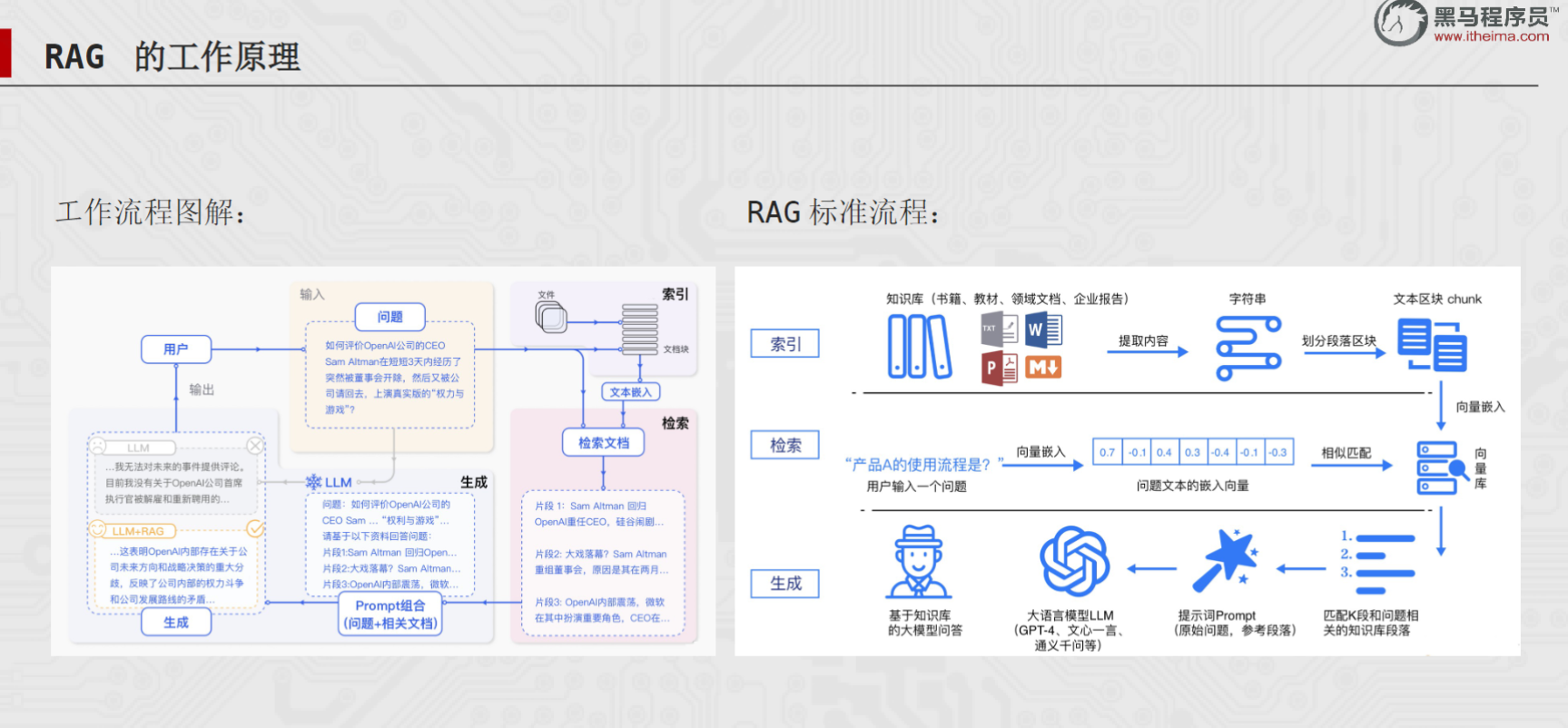
学术上通常将这三个阶段概括为:Indexing(索引构建)→ Retrieval(检索)→ Generation(生成) 。
1.3 LangChain 中的 RAG
在 LangChain 框架中,RAG 被抽象设计为一条数据处理管道(Pipeline):
把各种格式的文档 → 加载进来 → 切成小块 → 编码成向量存起来 → 用户提问时搜出最相关的几块 → 塞给 LLM 生成回答。
这条管道中流转的"基本货币"是 Document 对象 。无论你的原始数据是 PDF、网页、CSV 还是 JSON,进入 LangChain 之后都统一变成 Document,在 Loader → Splitter → VectorStore → Retriever 各个环节中无缝传递。
💡 关键认知: RAG 不是一个组件,而是一套流程。LangChain 的价值就是把这条流程中的每个环节都标准化了,你可以像搭积木一样自由组装自己的 RAG 管道。而理解
Document对象是理解这一切的前提,它就是管道中流转的"水",后面的 Loader、Splitter、VectorStore、Retriever 都是围绕它来工作的。
2. Document 对象
2.1 什么是 Document?
文档加载器提供了一套标准接口,用于将不同来源(如 CSV、PDF 或 JSON 等)的数据读取为 LangChain 的文档格式。这确保了:无论数据来源如何,后续的所有处理(切分、向量化、检索)都能以一致的方式对待它。
在 LangChain 的世界里,Document 是所有文本数据的统一包装盒。Document 定义在 langchain_core.documents 模块下,所有文档加载器最终返回此类的实例:
python
from langchain_core.documents import Document
# Document 的核心结构(简化版源码)
class Document:
page_content: str # 必填:文档的文本内容
metadata: dict = {} # 可选:附属信息(来源、页码、作者等)
id: str | None = None # 可选:文档唯一标识(v0.2.11 新增)
type: str = "Document" # 固定值,标识类型每个 Document 就是一个"文本块 + 附属信息"的组合。 用一个贴切的类比来理解:
| 类比 | Document 字段 | 含义 |
|---|---|---|
| 📦 包裹里的物品 | page_content |
真正的文本内容(必填),这就是"货物"本身 |
| 🏷️ 快递面单 | metadata |
附属信息:来源文件、页码、作者等(可选),"面单"用来追溯和过滤,不参与核心语义处理 |
| 📍 快递单号 | id |
唯一标识,用于去重和追踪(可选,v0.2.11+) |
2.2 认识 metadata
Embedding 模型只对
page_content做向量化,不看metadata。 metadata 的唯一用途是:当检索命中某个 chunk 之后,告诉用户"这条信息来自哪个文件的哪一页等信息",方便溯源和引用。
这意味着什么?来看一个例子:
python
doc = Document(
page_content="火锅底料配方:牛油 500g、花椒 50g、干辣椒 200g",
metadata={"source": "秘制配方库", "secret_level": "top"}
)只有 page_content("火锅底料配方:牛油 500g......")会参与语义检索。 即使用户问"top 级别的配方",检索系统也不会自动去匹配 secret_level 这个 metadata 字段。metadata 只是"标签",不参与语义匹配。
metadata 常用键名速查表
虽然不是强制规范,但社区约定了一套常用 metadata 键名,保持一致能让后续所有处理链路更顺滑:
| 键名 | 含义 | 示例 |
|---|---|---|
source |
文件来源路径或 URL | "./员工手册.pdf" |
page |
页码 | 42 |
source_type |
文档类型 | "pdf" / "txt" / "html" |
author |
作者 | "张三" |
title |
文档标题 | "2024 年度总结报告" |
chapter |
所属章节 | "第三章 休假制度" |
row |
CSV 行号 | 128 |
2.3 Document 实践
python
from langchain_core.documents import Document
# 创建一条 Document
doc = Document(
page_content="根据公司规定,员工每年享有 5 天带薪年假。工作满 10 年的员工,年假增加至 10 天。",
metadata={
"source": "员工手册.pdf",
"page": 15,
"chapter": "休假制度"
}
)
# 查看内容
print(doc.page_content)
# 输出:根据公司规定,员工每年享有 5 天带薪年假。工作满 10 年的员工,年假增加至 10 天。
print(doc.metadata)
# 输出:{'source': '员工手册.pdf', 'page': 15, 'chapter': '休假制度'}3. Document Loader
3.1 Loader 与 Document 的关系
在学习具体 Loader 之前,先理清最核心的概念关系:
Loader 的全部职责就是:把外部数据源(文件、URL、数据库......)"转换"为
List[Document]。**
用一张图来直观感受:
┌──────────────────────┐ .load() 方法 ┌────────────────────────┐
│ 外界数据源 │ ──────────────────→ │ List[Document] │
│ .pdf / .txt / .csv │ │ │
│ URL / .json 等 │ │ [doc1, doc2, doc3, ...] │
└──────────────────────┘ └────────────────────────┘
↑ ↑
唯一输入 唯一输出形式3.2 Loader 的统一接口
LangChain 所有 Loader(上百种!)都实现了同一套基类接口,这是理解 Loader 的核心:
python
class BaseLoader:
def load(self) -> List[Document]:
"""加载文档,返回 Document 列表(一次性全加载到内存)"""
...
def lazy_load(self) -> Iterator[Document]:
"""懒加载,逐条返回 Document 迭代器(适合超大文件,边读边处理,不爆内存)"""
...所有 Loader 都继承自 BaseLoader,因此 .load() 和 .lazy_load() 这两个方法在所有 Loader 上都可以使用。
| 方法 | 返回值 | 适用场景 |
|---|---|---|
.load() |
List[Document] |
常规场景,文件不大,一次性全加载到内存 |
.lazy_load() |
Iterator[Document] |
超大文件(如几百 MB 的日志),逐条产出 Document,边读边处理,内存友好 |
💡 核心结论:无论什么 Loader,用法模式完全一致:
pythonloader = XXXLoader(数据源路径或URL) docs = loader.load()差异仅在于初始化时需要传什么参数,因为不同数据源的连接方式不同。
3.3 常用 Loader
LangChain 提供了上百种 Loader,覆盖几乎所有能想到的数据源。下面是最常用的几个:
| Loader | 数据源 | 一句话概括 | 所属包 |
|---|---|---|---|
TextLoader |
.txt 纯文本 |
最基础,读文本文件,默认整个文件作为一个 Document | langchain_community |
PyPDFLoader |
.pdf |
每页生成一个 Document(底层 pypdf) | langchain_community |
PyMuPDFLoader |
.pdf |
每页一个 Document(底层 PyMuPDF/fitz,速度更快、中文解析更准) | langchain_community |
WebBaseLoader |
网页 URL | 抓取网页的文本内容,返回 Document | langchain_community |
CSVLoader |
.csv 表格 |
每一行生成一个 Document,自动带 row 行号 |
langchain_community |
JSONLoader |
.json 文件 |
用 jq 语法提取 JSON 中的指定字段作为 page_content |
langchain_community |
UnstructuredFileLoader |
通用格式 | 自动识别 PDF/DOCX/HTML/PPTX 等(依赖 unstructured 库) |
langchain_community |
DirectoryLoader |
整个文件夹 | 批量加载一个目录下的所有文件(可指定文件类型匹配模式) | langchain_community |
3.4 各类 Loader 详解
共同点(接口层------所有 Loader 都一样):
- 都通过构造函数接收数据源配置(文件路径/URL 等)
- 都通过
.load()返回List[Document] - 都通过
.lazy_load()返回Iterator[Document]
差异点(参数层):
- 不同 Loader 的构造函数参数各不相同,因为连接不同数据源所需的信息不同
| Loader | 特有的关键参数 | 典型写法 |
|---|---|---|
TextLoader |
encoding(编码) |
TextLoader("a.txt", encoding="utf-8") |
PyPDFLoader |
只需文件路径,几乎不需要额外参数 | PyPDFLoader("a.pdf") |
WebBaseLoader |
web_paths(URL 或 URL 列表) |
WebBaseLoader("https://...") |
CSVLoader |
csv_args(CSV 解析选项,如分隔符) |
CSVLoader("a.csv", csv_args={"delimiter": ","}) |
JSONLoader |
jq_schema(jq 语法,指定提取哪个字段) |
JSONLoader("a.json", jq_schema=".[].content") |
DirectoryLoader |
glob(文件匹配模式)、loader_cls(委托哪个 Loader 类) |
DirectoryLoader("./dir", glob="**/*.pdf", loader_cls=PyMuPDFLoader) |
① TextLoader
最基础、最常用的起点:
python
from langchain_community.document_loaders import TextLoader
loader = TextLoader("./员工手册.txt", encoding="utf-8")
docs = loader.load()
print(f"加载了 {len(docs)} 个 Document") # 加载了 1 个 Document
print(docs[0].page_content[:200]) # 看看前 200 个字符重要参数:
| 参数 | 默认值 | 说明 |
|---|---|---|
file_path |
必填 | 文件路径 |
encoding |
None |
文件编码 |
autodetect_encoding |
False |
设为 True 后会自动检测编码(对未知编码的文件非常实用) |
⚠️ 踩坑提醒:
TextLoader默认将整个文件作为一个 Document(而非一行一个)。如果你希望一行一个 Document,更推荐的做法是:不要在 Loader 阶段过早切碎,而是在 Splitter 阶段统一处理切分逻辑,保持流程的职责清晰。
② PyPDFLoader / PyMuPDFLoader
两种 PDF Loader 的用法几乎完全一致:
python
# 方案 A:PyPDFLoader(轻量,只依赖 pypdf)
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./员工手册.pdf")
docs = loader.load()
print(f"PDF 共 {len(docs)} 页,每页一个 Document")
# 看看每一页带了什么 metadata
for i, doc in enumerate(docs[:3]): # 只看前 3 页
print(f"第 {i+1} 页:source={doc.metadata['source']}, page={doc.metadata['page']}")
print(f" 内容前 80 字: {doc.page_content[:80]}...")
print()
python
# 方案 B:PyMuPDFLoader(推荐!解析质量更好)
from langchain_community.document_loaders import PyMuPDFLoader
loader = PyMuPDFLoader("./员工手册.pdf")
docs = loader.load() # 用法和 PyPDFLoader 完全一致!PyPDFLoader vs PyMuPDFLoader 对比:
| 维度 | PyPDFLoader | PyMuPDFLoader |
|---|---|---|
| 底层依赖 | pypdf(原 PyPDF2) | PyMuPDF(fitz) |
| 解析质量 | ⭐⭐⭐ 良好 | ⭐⭐⭐⭐⭐ 优秀 |
| 中文支持 | 一般,偶有乱码 | 更好,中文解析更准确 |
| 复杂排版处理 | 较弱 | 强(多栏布局、表格、图片等都能较好处理) |
| 速度 | 一般 | 更快 |
| 安装方式 | pip install pypdf |
pip install pymupdf |
| 推荐场景 | 简单纯文本英文 PDF | 复杂排版、中英文混合 PDF |
🧐 注意: 这两个 PDF Loader 都是每一页生成一个 Document 。一本 50 页的 PDF 加载出来后,就是包含 50 个
Document的列表。每个 Document 的metadata自动带上source(文件路径)和page(页码)。有了这些信息,检索到某个 chunk 后就能精确定位到原文档的具体页码。
③ WebBaseLoader
python
from langchain_community.document_loaders import WebBaseLoader
# 单个 URL
loader = WebBaseLoader("https://baike.baidu.com/item/机器学习")
docs = loader.load()
print(docs[0].page_content[:300]) # 打印前 300 个字符看看
# 也可以一次加载多个 URL
loader = WebBaseLoader([
"https://example.com/page1",
"https://example.com/page2",
])
docs = loader.load()
print(f"共加载 {len(docs)} 个网页的内容")⚠️ 注意:
WebBaseLoader默认不能抓取需要登录认证的页面,也不能执行 JavaScript。对于动态渲染的网页(如 React/Vue 构建的 SPA 单页应用),需要考虑使用SeleniumURLLoader或PlaywrightURLLoader来模拟浏览器行为。通常每个 URL 返回一个 Document。
④ CSVLoader
python
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader(
file_path="./员工信息.csv",
encoding="utf-8",
csv_args={
"delimiter": ",", # 列分隔符
"quotechar": '"', # 引号字符
}
)
docs = loader.load()
print(f"CSV 有 {len(docs)} 行数据,每行一个 Document")
# 看看第一行长什么样
print(docs[0].page_content)
# 输出类似:工号: 001, 姓名: 张三, 部门: 研发部, 入职日期: 2020-03-15
print(docs[0].metadata)
# 输出:{'source': './员工信息.csv', 'row': 0}💡 CSVLoader 的工作原理:CSV 文件的每一行转换成一个 Document 对象, 把 CSV 的每一行 拼接成一个字符串,作为
page_content;同时在 metadata 中自动添加source和row(行号)。后续检索命中某个 chunk 后,就能追溯到 CSV 文件的第几行。
⑤ JSONLoader
JSON 跟 CSV 不一样,JSON 有嵌套结构(对象嵌套对象、数组嵌套数组),不能简单地"一行一个"。所以 JSONLoader 使用 jq 语法来指定你想提取哪个字段作为正文。
jq 语法速成: jq 是一种轻量的 JSON 查询语言,几个核心语法:
| jq 表达式 | 含义 | 示例作用 |
|---|---|---|
. |
取当前对象 | 定位到根层级 |
.字段名 |
取对象的某个字段 | .name 取当前对象的 name 属性 |
.[] |
遍历数组 | .[] 把数组"展开",逐个处理每个元素 |
| `.[] | .字段名` | 遍历数组,从每个元素中取字段 |
更具体的 jq 示例(对照 JSON 结构理解):
json
// === 示例 1:顶层为数组的 JSON(最常见) ===
[
{"title": "火锅底料", "content": "牛油 500g、花椒 50g", "author": "老王"},
{"title": "红烧肉", "content": "五花肉 300g、酱油 20ml", "author": "老李"}
]
python
jq_schema = ".[].content"
# 含义:先遍历数组(.[]),再取每个元素里的 content 字段
# 结果依次提取:"牛油 500g、花椒 50g"、"五花肉 300g、酱油 20ml"
json
// === 示例 2:顶层为对象,数据在嵌套数组里 ===
{
"status": "ok",
"data": {
"articles": [
{"title": "文章A", "body": "这是正文内容A"},
{"title": "文章B", "body": "这是正文内容B"}
]
}
}
python
jq_schema = ".data.articles[].body"
# 含义:先进入 data → 再进入 articles → 遍历数组 → 取 body
# 结果依次提取:"这是正文内容A"、"这是正文内容B"
json
// === 示例 3:简单 JSON 对象(非数组,只有一个对象) ===
{
"title": "火锅秘籍",
"description": "家庭版火锅底料配方大全",
"full_text": "牛油 500g、花椒 50g、干辣椒 200g、豆瓣酱 100g......"
}
python
jq_schema = ".full_text"
# 含义:直接取根对象的 full_text 字段
# 结果:"牛油 500g、花椒 50g、干辣椒 200g、豆瓣酱 100g......"完整代码实战:
python
from langchain_community.document_loaders import JSONLoader
# 假设 data.json 内容如下:
# [
# {"title": "火锅底料", "content": "牛油 500g、花椒 50g...", "author": "老王"},
# {"title": "红烧肉", "content": "五花肉 300g、酱油 20ml...", "author": "老李"}
# ]
# 定义一个 metadata 提取函数
def metadata_func(record, metadata):
"""record 是 JSON 中的每条原始记录,metadata 是 Loader 自动创建的字典"""
metadata["title"] = record.get("title")
metadata["author"] = record.get("author")
return metadata
loader = JSONLoader(
file_path="./data.json",
jq_schema=".[].content", # jq 语法:提取数组中每个对象的 content 字段作为正文
text_content=True, # content 是纯文本(而非 JSON 字符串)
metadata_func=metadata_func, # 自定义 metadata 提取逻辑
)
docs = loader.load()
print(docs[0].page_content)
# 输出:牛油 500g、花椒 50g...
print(docs[0].metadata)
# 输出:{'source': './data.json', 'seq_num': 1, 'title': '火锅底料', 'author': '老王'}JSONLoader 关键参数:
| 参数 | 说明 |
|---|---|
jq_schema |
核心参数! jq 语法字符串,指定 JSON 中哪个路径是你要提取的正文内容 |
text_content |
True = 提取的内容是纯文本;False = 内容是 JSON 对象,会被 json.dumps 转成字符串 |
metadata_func |
可选。自定义函数 (record, metadata) -> metadata,让你从每条 JSON 记录中提取自定义 metadata |
metadata_func 的作用和写法详解:
metadata_func 让你在加载 JSON 的同时,把原始 JSON 中的其他字段(如标题、作者、日期等)保存到 Document 的 metadata 中,方便后续溯源。
python
def metadata_func(record, metadata):
# record:JSON 中的一条原始数据(dict)
# metadata:Loader 自动创建的初始 metadata 字典(已包含 source、seq_num 等)
# 你的任务:把需要的字段写入 metadata 并返回
# 基本写法:直接映射字段
metadata["字段名"] = record.get("JSON中的键", "默认值")
# 进阶写法:做条件判断、组合字段等
if record.get("score") and record["score"] > 80:
metadata["level"] = "高分"
else:
metadata["level"] = "普通"
metadata["display_name"] = f"{record.get('name')}({record.get('dept')})"
return metadata💡
metadata_func的内容完全可以根据自己的业务需求自由定义,你想从原始 JSON 中提取哪些字段、做什么处理,都由你来定。
⑥ DirectoryLoader
python
from langchain_community.document_loaders import DirectoryLoader, TextLoader, PyMuPDFLoader
# 场景 1:加载 docs/ 目录下所有 .txt 文件
loader = DirectoryLoader(
path="./docs/",
glob="**/*.txt", # glob 模式:匹配所有 .txt 文件
loader_cls=TextLoader, # 用 TextLoader 处理每个匹配到的文件
loader_kwargs={"encoding": "utf-8"}, # 传给 TextLoader 的额外参数
show_progress=True, # 显示进度条
)
docs = loader.load()
print(f"共加载 {len(docs)} 个 Document")
# 场景 2:加载 docs/ 目录下所有 .pdf 文件
loader = DirectoryLoader(
path="./docs/",
glob="**/*.pdf",
loader_cls=PyMuPDFLoader, # 换一个 Loader 类即可
)
docs = loader.load()DirectoryLoader 参数:
| 参数 | 说明 |
|---|---|
path |
目标文件夹路径 |
glob |
文件匹配模式,如 "**/*.txt" 匹配所有 txt、"**/*.pdf" 匹配所有 pdf |
loader_cls |
处理每个文件的 Loader 类 (注意:传类名 TextLoader,不是实例 TextLoader()) |
loader_kwargs |
传给 loader_cls 的额外参数字典 |
show_progress |
是否显示进度条(True 开启) |
use_multithreading |
是否多线程并行加载(设为 True 可大幅加速大量文件的加载) |
🔑 小技巧:
DirectoryLoader是一个"元 Loader",它本身不做实际加载,而是把任务委托 给loader_cls指定的 Loader 去处理每一个匹配到的文件。你可以灵活组合,比如glob="**/*.pdf"+loader_cls=PyMuPDFLoader来批量加载一个文件夹里的所有 PDF。
到这里,我们已经走完了 RAG 管道的第一个阶段:数据加载 。
下一步,我们进入第二个阶段:用 Text Splitter 把加载好的 Document 切成合适的小块(chunk),为向量化和精准检索做好准备。
4. Text Splitter
4.1 为什么要切?
Loader 产生的 Document 可能非常大,PDF 一页可能有两三千字,一个 TextLoader 加载整本书只产出一个 Document。
如果直接拿这么大的文本块去做 Embedding 和检索,会遭遇三个严重问题:
| 问题 | 具体后果 | 通俗类比 |
|---|---|---|
| 🚫 超出模型输入限制 | Embedding 模型有最大输入长度限制(通常几百到几千 token)。超长文本无法直接做向量化,需要截断或报错 | 一张 100MB 的高清图塞不进 50KB 的头像框 |
| 🔍 检索不精准 | 一整章内容做成一个向量,信息被过度"压缩"和"平均化"。用户问其中某句话,这个向量的相似度可能算出来很低,导致检索不到 | 在整本字典里找一句特定的诗,像大海捞针 |
| 💰 Token 浪费 | 跟用户问题相关的可能就那两三句话,却要把整页内容都发给 LLM 生成回答,白白增加成本 | 别人问你一个问题,你把整本书复印给 TA 看 |
标准解法:把大文档切成一个个小块(chunk),每个小块独立做 Embedding、独立参与检索。用户问什么,只召回最相关的几个小块。
4.2 RecursiveCharacterTextSplitter
RecursiveCharacterTextSplitter(递归字符文本分割器),是 LangChain 官方推荐的最常用的文本分割器。它的名字里"Recursive"(递归)这个词已经暗示了它的核心策略。
核心思路:"段落 → 句子 → 词语 → 字符"逐级降级切割
切割优先级(separators 默认值):
第 1 轮:尝试用 "\n\n"(段落分隔符)切
↓ 切完后某些块还是太长?→ 进入下一轮继续
第 2 轮:尝试用 "\n"(换行符)切
↓ 还是太长?→ 继续
第 3 轮:尝试用 " "(空格)切
↓ 还是太长?→ 继续
第 4 轮:尝试用 ""(逐字符硬切)最后的兜底手段这种策略最巧妙的地方在于:尽可能保持大的语义单元(段落)完整,只在万不得已时才拆分到更细的粒度。 这样可以确保每个 chunk 语义比较完整,检索质量自然更高。
用一个具体例子直观感受(假设 chunk_size=100 字符):
原始文本(共 250 字符):
"第一段:这里是完整的段落内容......\n\n第二段:另一段内容......\n\n第三段:还有一段内容......"
Round 1,用 "\n\n" 分割:
→ 分成 3 块:[段落1(80字)], [段落2(90字)], [段落3(80字)]
→ 每块都 ≤100,✅ 全部通过!不再需要后续轮次切割
但如果段落2有 200 字符,超出 chunk_size=100:
→ Round 2,用 "\n" 对段落2再切 → 分成更小的句子
→ 如果还超 → Round 3,用空格切
→ 如果还超 → Round 4,逐字符硬切(确保绝对不超上限)4.3 基本用法
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个块最大 1000 字符
chunk_overlap=200, # 相邻块之间重叠 200 字符
)
# 把 Loader 加载的 Document 列表切成小块
chunks = text_splitter.split_documents(docs)
print(f"原来 {len(docs)} 个 Document,切成了 {len(chunks)} 个小块")4.4 参数逐一详解
| 参数 | 类型 | 默认值 | 含义 |
|---|---|---|---|
chunk_size |
int |
4000 |
每个文本块的最大"尺寸",默认按字符数计算 |
chunk_overlap |
int |
200 |
相邻两个块之间重叠多少字符,保持语义连贯,防止关键信息刚好卡在切割边界上 |
separators |
List[str] |
["\n\n", "\n", " ", ""] |
分隔符优先级列表,越靠前优先级越高 |
length_function |
callable |
len |
如何度量"尺寸",默认用 Python 内置的 len(),即按字符数算 |
keep_separator |
bool |
True |
是否在切分结果中保留分隔符(保留标点有助于维持语义) |
4.4.1关于 length_function 的深入理解
默认 len 按字符数来度量大小 ,但在 LLM 的世界里,"字数"的真正单位是 Token。
- 英文:一个单词 ≈ 1~2 个 token
- 中文:一个字 ≈ 1~3 个 token
你可能想:设 chunk_size=800 就是 800 个字符,一段中文 800 个字符,实际对应的 token 数大约在 1500~2400,远超你以为的 800。如果你用的 Embedding 模型的输入上限是 512 token,那你的 800 字符实际对应 1500+ token,已经远超模型窗口,会导致截断或报错。
这就是为什么推荐用 tiktoken 做精确的 Token 级控制 。
tiktoken 是 OpenAI 开源的一个 Token 计数/编码库。它的作用就是把文本字符串转换成模型能理解的 Token 序列,或者告诉你"这段文本一共多少个 Token"。每个大模型都有自己的"分词字典"和"分词规则",所以同样的文本,用不同模型的 Tokenizer 编码,得到的 Token 数量可能不一样。
举个例子:
GPT-4 / GPT-3.5 / text-embedding-ada-002 使用的编码器叫 cl100k_base
早期的 GPT-3 某些模型用的是 p50k_base 或 r50k_base
如果你用 cl100k_base 去编码,中文"我喜欢吃火锅"可能是 6 个 token,但换另一个分词器(比如某个中文专有模型的分词器)可能就是 3 个 token。
python
import tiktoken
# 获取 OpenAI 标准编码器
enc = tiktoken.get_encoding("cl100k_base")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=800, # 最多 800 token
chunk_overlap=100, # 重叠 100 token
length_function=lambda text: len(enc.encode(text)), # 🎯 关键:用 token 数来算尺寸!
)在 RAG 管道的文本分割阶段,你设 chunk_size 是为了让每个 chunk 能安全地喂给 Embedding 模型,而不是直接喂给 LLM。所以你应该关心的是 Embedding 模型的 Token 限制,以及它的分词方式。
4.4.2 chunk_overlap 到底解决了什么问题?:
原始文本:
"......员工每年享有5天带薪年假。|(切割线)| 工作满10年的员工,年假增加至10天。"
chunk_1: "......员工每年享有5天带薪年假。"
chunk_2: "工作满10年的员工,年假增加至10天。"用户问"工作满 10 年的员工有多少天年假?",正确答案"10 天"在 chunk_2 里。但假如用户的提问向量跟 chunk_1 更相似(比如用户先说了一大堆关于"每年 5 天"的背景描述),chunk_2 可能根本不会被召回,正确答案就这样丢了!
开了 chunk_overlap=50 之后:
chunk_1:"......员工每年享有5天带薪年假。工作满10年..." ← 包含后半句的开头
chunk_2:"员工每年享有5天带薪年假。工作满10年的员工,年假增加至10天。" ← 完整上下文无论用户的问题向量更靠近 chunk_1 还是 chunk_2,两个块里都能看到完整信息。overlap 是语义的"安全带",防止关键信息刚好卡在切割边界上导致永久丢失。
4.4.3 chunk_size 和 chunk_overlap 到底设多少?
chunk_size 的设置思路:
| 场景 | 推荐 chunk_size | 理由 |
|---|---|---|
| 🎯 高精度问答(如客服 FAQ、规章制度查询) | 256~512 token | 小块=高精度检索,每个 chunk 聚焦一个知识点。用户问"年假几天",直接命中对应的那个小块 |
| 📄 通用文档检索(如企业知识库、技术文档) | 512~1024 token | 精度和上下文的平衡点。既能精确定位,又有足够上下文让 LLM 理解 |
| 📚 长文理解(如论文分析、合同审查) | 1024~2048 token | 需要完整上下文才能理解的场景:法律条款、学术论证等不能断章取义 |
| 🧠 摘要/综述生成 | 2048+ token | 需要大的上下文窗口才能概括全局内容 |
chunk_overlap 的设置思路:
| 推荐比例 | 说明 |
|---|---|
| chunk_size 的 10%~20% | 最常用的经验比例。比如 chunk_size=500 → chunk_overlap=50~100 |
| 下限建议:至少 50 token | 太小的 overlap 起不到"语义安全带"的作用 |
| 上限建议:不超过 chunk_size 的 30% | overlap 太大 → 信息冗余 → 浪费存储空间和检索效率 |
可以在你的实际数据上测试,观察切出来的 chunk 是否语义完整。如果发现回答经常断章取义 → 调大 chunk_size;如果发现检索不精准 → 调小 chunk_size。
💡 核心心法总结:
chunk_size越小 → 检索越精准,但每个 chunk 包含的上下文信息越少,LLM 可能看不全背景chunk_size越大 → 每个 chunk 的上下文越完整,但检索精度下降,且每次发给 LLM 的 token 更多(更贵)chunk_overlap是相邻块之间有重叠,保证不会有信息因为刚好被拦腰截断而永久丢失- 不存在完美的"最佳数值",需要根据实际场景和数据特点来调参,这和所有机器学习任务一样。
4.4.4 中文场景的优化配置
中文文本有独特的标点符号,应该被加入到分隔符优先级中,让切分器优先在中文句子边界切割:
python
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
# 🔑 关键:把中文标点加到分隔符列表中!
separators=[
"\n\n", # 段落边界(最强优先级)
"\n", # 换行
"。", # 中文句号
"!", # 感叹号
"?", # 问号
";", # 分号
",", # 逗号(谨慎使用,可能切得太碎)
".", # 英文句号
" ", # 空格
"" # 逐字符(最后手段)
],
keep_separator=True, # 保留标点,维持语义连贯
)💡 加上中文标点后,切分器就能优先在天然的中文句子边界切割,而不是把一句话生生从中间劈开。这样做出来的 chunk 语义更完整,检索质量自然更好。
4.5 两个切分方法对比
| 方法 | 输入 | 输出 | 什么时候用 |
|---|---|---|---|
split_documents(docs) |
List[Document] |
List[Document] |
有 metadata 需要保留时(绝大多数情况)------切分后每个子块自动继承父块的 metadata |
split_text(text) |
str |
List[str] |
只有裸文本,不需要溯源信息,简单场景用 |
python
# 场景 1:有 Document(来自 Loader),用 split_documents
docs = loader.load()
chunks = text_splitter.split_documents(docs)
# 每个 chunk 自动保留了父 Document 的 metadata(source、page 等)
# 场景 2:只有纯文本字符串------用 split_text
raw_text = "这是一段很长的文本......需要被切分成小块"
texts = text_splitter.split_text(raw_text)
# 返回的就是纯字符串列表,没有 metadata回顾整条 RAG 数据处理管道,我们把知识串联起来:
📄 各类文档(PDF / TXT / CSV / JSON / 网页)
│
▼
┌─────────────────────────────────────┐
│ ① Document Loader(数据加载层) │
│ · 上百种 Loader,统一输出 Document │
│ · .load() 全量 / .lazy_load() 懒加载 │
│ · 不同 Loader 只是参数不同 │
└─────────────────────────────────────┘
│ List[Document]
▼
┌─────────────────────────────────────┐
│ ② Text Splitter(文本切分层) │
│ · RecursiveCharacterTextSplitter │
│ · 段落→句子→词语→字符 逐级降级切割 │
│ · chunk_size: 控制精度与成本平衡 │
│ · chunk_overlap: 语义安全带 │
│ · 推荐用 tiktoken 按 token 精确控制 │
└─────────────────────────────────────┘
│ List[Document](小块)
▼
┌─────────────────────────────────────┐
│ ③ Embedding(向量化) │
│ · 只对 page_content 做向量化 │
│ · metadata 不参与,仅用于溯源 │
└────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ ④ VectorStore(向量存储 + 检索) │
│ · 用户提问 → 向量检索 → 召回 top-K │
│ · 问题 + 相关文档 → Prompt 融合 │
└─────────────────────────────────────┘
│
▼
🤖 LLM 生成回答以上为个人学习总结,旨在梳理个人理解。如有疏漏或不当之处,欢迎指正与交流。如果文章对你有帮助,别忘了点个赞、留个言,让更多的小伙伴看到~ 下一篇将继续深入 Embedding(向量化)和 VectorStore(向量数据库),完成从"数据准备好"到"被 LLM 成功检索并回答"的完整闭环。我们下篇再见!