📖标题:Gemini Embedding 2: A Native Multimodal Embedding Model from Gemini
🌐来源:arXiv, 2605.27295v1
🛎️文章简介
🔸研究问题:如何构建一个能够统一处理文本、图像、视频和音频,并在跨模态检索及垂直领域任务中实现状态最先进性能的原生多模态嵌入模型?
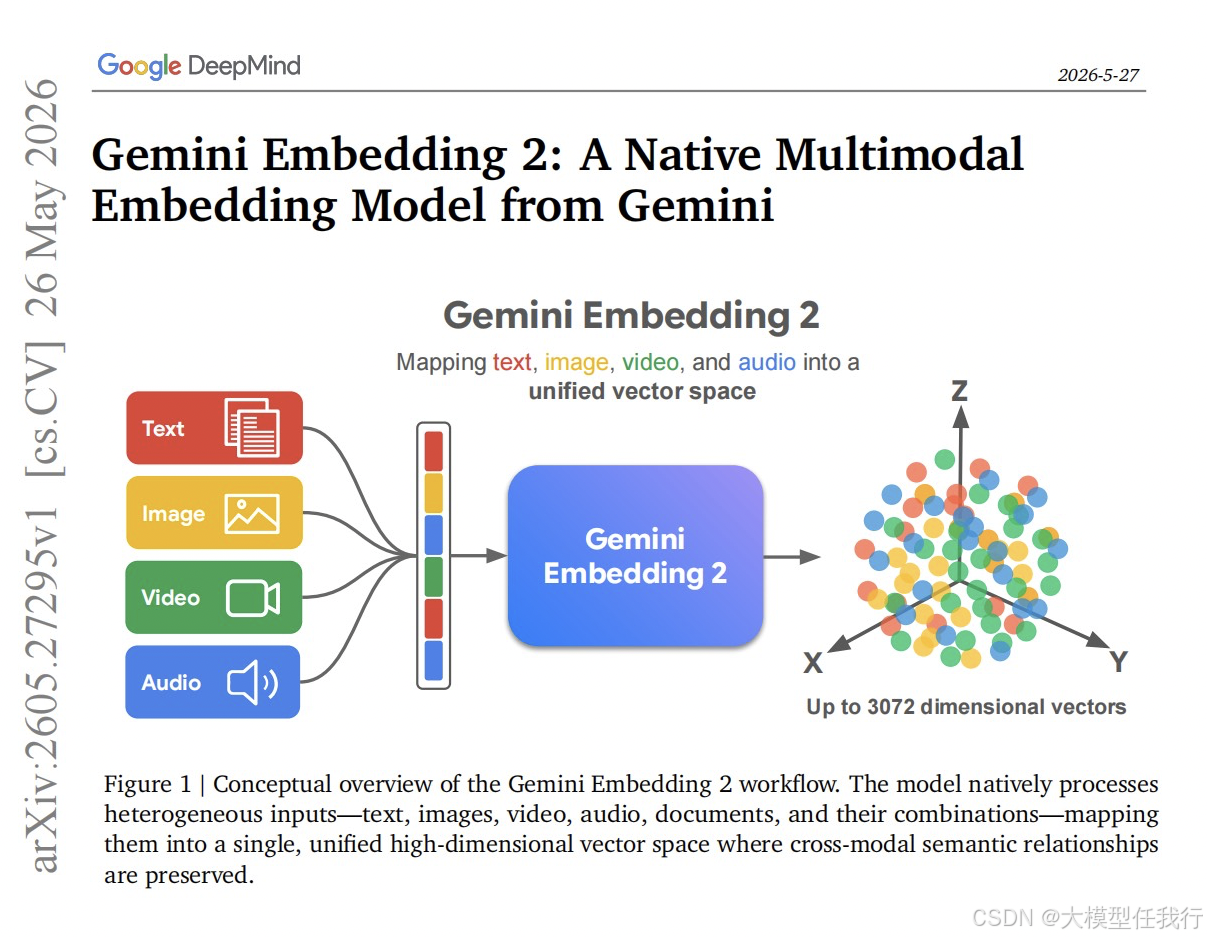
🔸主要贡献:论文提出了基于Gemini架构的Gemini Embedding 2,通过多阶段对比学习和合成数据增强,实现了全模态统一表示及SOTA性能。
📝重点思路
🔸模型架构:利用Gemini的双向注意力Transformer作为骨干,将不同模态输入映射到统一向量空间,采用平均池化和线性投影生成固定维度嵌入。
🔸训练策略:实施多任务多阶段训练,包括预微调(PFT)以适配编码任务,以及微调(FT)阶段引入硬负样本和多样化模态组合,使用噪声对比估计损失。
🔸数据增强:利用Gemini生成高质量合成数据,特别是在代码检索任务中显著提升了模型性能,并采用Model Soup技术整合检查点以增强泛化能力。
🔸原生音频处理:摒弃传统的ASR转录流水线,直接对原始音频信号进行编码,保留了声学细微特征,避免了转录错误传播。
🔎分析总结
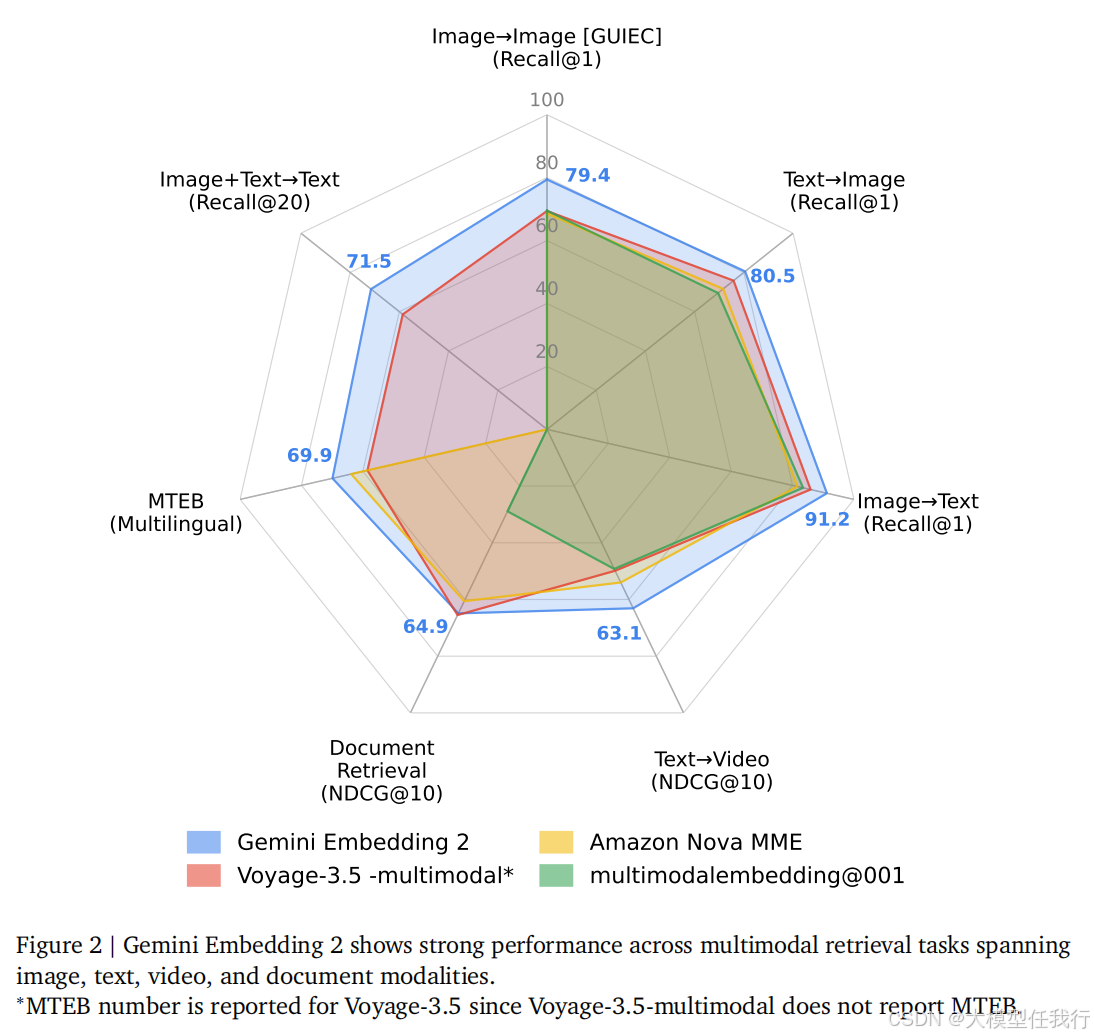
🔸通用性能卓越:在MSCOCO、Vatex等多模态检索基准上取得SOTA结果,且在MTEB多语言和代码基准上超越专用模型,证明其强大的通用性。
🔸垂直领域鲁棒性:在显微镜、天文学、艺术等零样本专业领域表现优异,相比基线模型有大幅提升,且在不同领域间性能波动小,稳定性强。
🔸原生音频优势:在MSEB基准测试中,原生音频嵌入比ASR转录方案在跨语言检索中提升约5个百分点,验证了端到端多模态理解的有效性。
🔸训练消融实验:微调阶段显著提升了视频理解能力;加入领域特定数据可提升域内性能但可能轻微损害域外性能,而Model Soup能有效平衡这一矛盾。
💡个人观点
论文打破了传统"双塔"或后期融合的多模态限制,实现了原生多模态交互。