📖标题:Toward Native Multimodal Modeling: A Roadmap
🌐来源:arXiv, 2605.25343v1
🛎️文章简介
🔸研究问题:如何定义并系统化从晚期融合向原生多模态建模(NMM)的架构转型,以解决当前设计空间碎片化及缺乏统一标准的问题?
🔸主要贡献:论文提出了NMM的形式化定义与分类体系,并提供了涵盖架构、数据、训练、推理及评估的全栈工业级技术路线图。
📝重点思路
🔸形式化定义原生性:区分中期融合(保留模态边界但深层交互)与早期融合(统一嵌入空间,所有模态等价处理),排除仅靠投影器连接的晚期融合非原生范式。
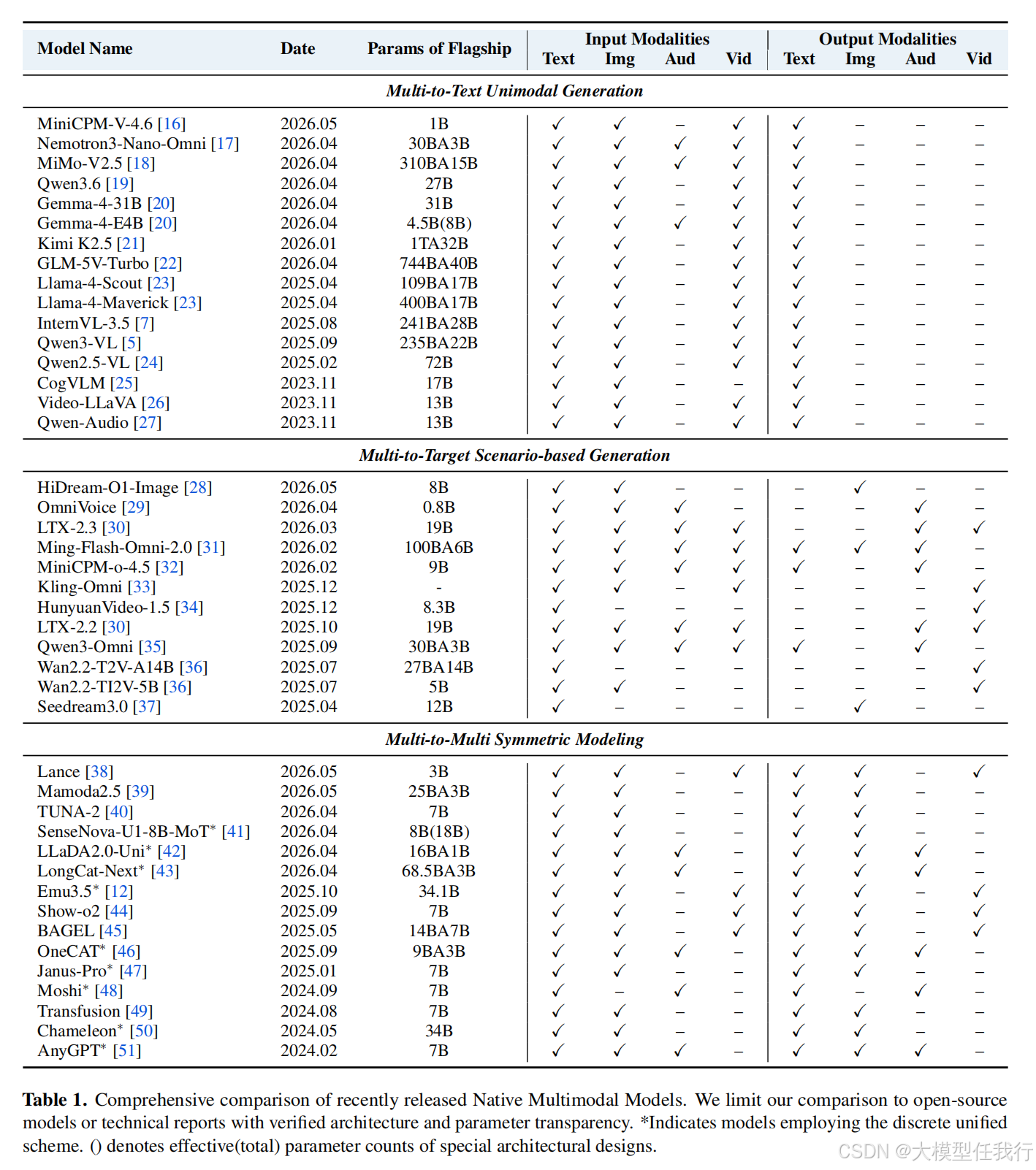
🔸功能分类体系:基于输入输出对偶性,将现有模型分为三类:多到文本(M2T,侧重理解推理)、多到目标(M2G,侧重特定模态生成如音视频)、多到多(M2M,对称建模,理解与生成共存)。
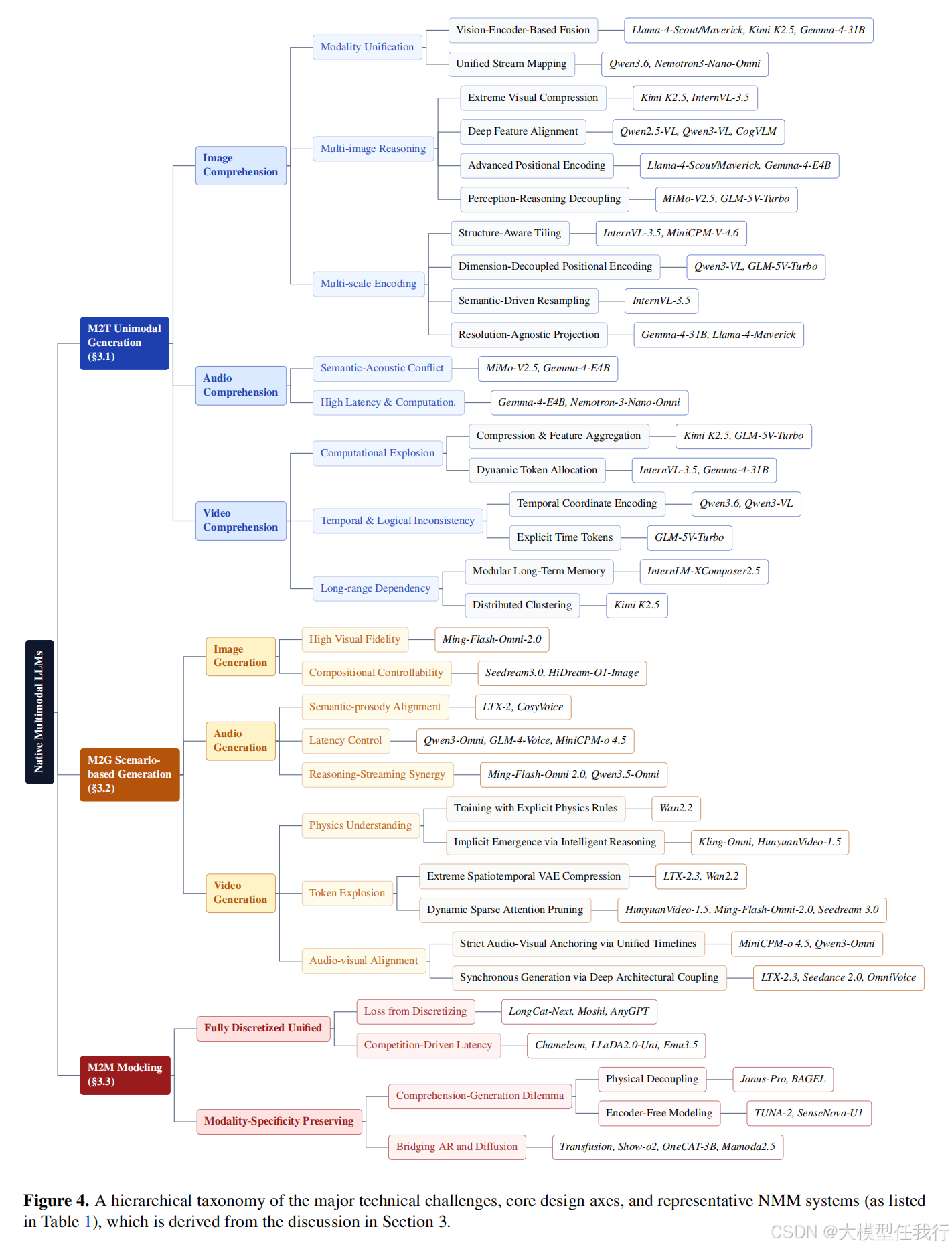
🔸全栈技术拆解:系统梳理了从架构协调(如离散化统一或保留模态特异性)、大规模异构数据策展(理解/生成/交互/偏好数据混合)、分阶段训练策略(预训练冻结拓扑、SFT重布线、RL范围界定)到推理部署(长上下文压缩、流式全双工)的关键技术瓶颈与解决方案。
🔸评估与展望:建立了跨模态理解与生成的综合评估基准,并指出未来应向架构收敛、自生成数据流、联合训练配方及原生世界模型方向演进。
🔎分析总结
🔸架构演进趋势:早期融合通过统一Transformer实现真正的模态协同,但需解决离散化信息损失及不同模态在统一Softmax下的竞争问题,Z-loss和QK-Norm成为稳定训练的必要条件。
🔸训练策略差异:中期融合依赖差异学习率和解耦损失来平衡编码器与主干网络;早期融合则强调从头联合训练及严格的模态混合调度,以防止模型退化或遗忘语言能力。
🔸数据核心作用:数据混合比例随训练阶段动态变化,理解型数据奠定基础,生成型与交互型数据提升能力,偏好数据用于校准幻觉与安全性,SFT阶段需重新平衡模态分布。
🔸推理挑战应对:针对长上下文引发的序列爆炸,采用视觉重采样、动态分辨率及稀疏注意力机制;为实现实时交互,转向增量解码、全双工状态管理及自适应比特率控制。
💡个人观点
论文界定了"原生多模态"的架构边界,提出的"输入-输出对偶性"分类法,准确捕捉了从单向理解到双向对称生成的演进逻辑。