Reflexion 到底是什么?
Reflexion 是一种面向语言智能体的学习框架。它把环境反馈转写成自然语言形式的 self-reflection ,再将这些经验加入后续上下文。
这里的"学习"主要发生在上下文与记忆中,不等于更新 LLM 的权重。因而它比重新训练或 Fine-tuning 更轻量,也更容易观察 Agent 是如何修正策略的。
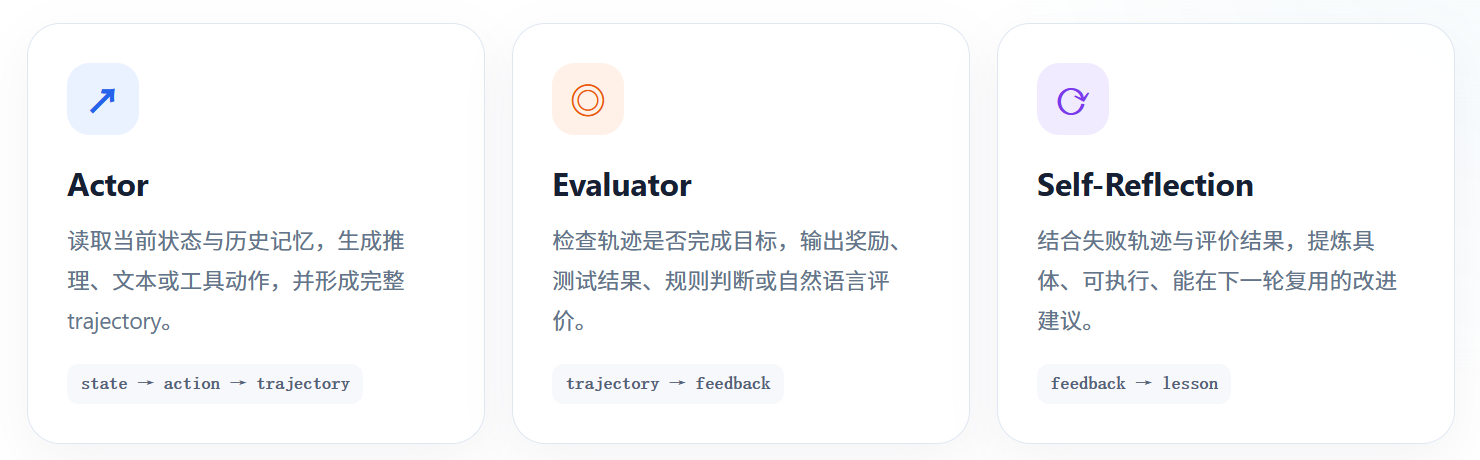
三个角色,加上一段记忆
Reflexion 将一次任务拆成执行、评价和反思三个职责。它们可以由不同模型承担,也可以由同一个 LLM 使用不同 Prompt 分别扮演。
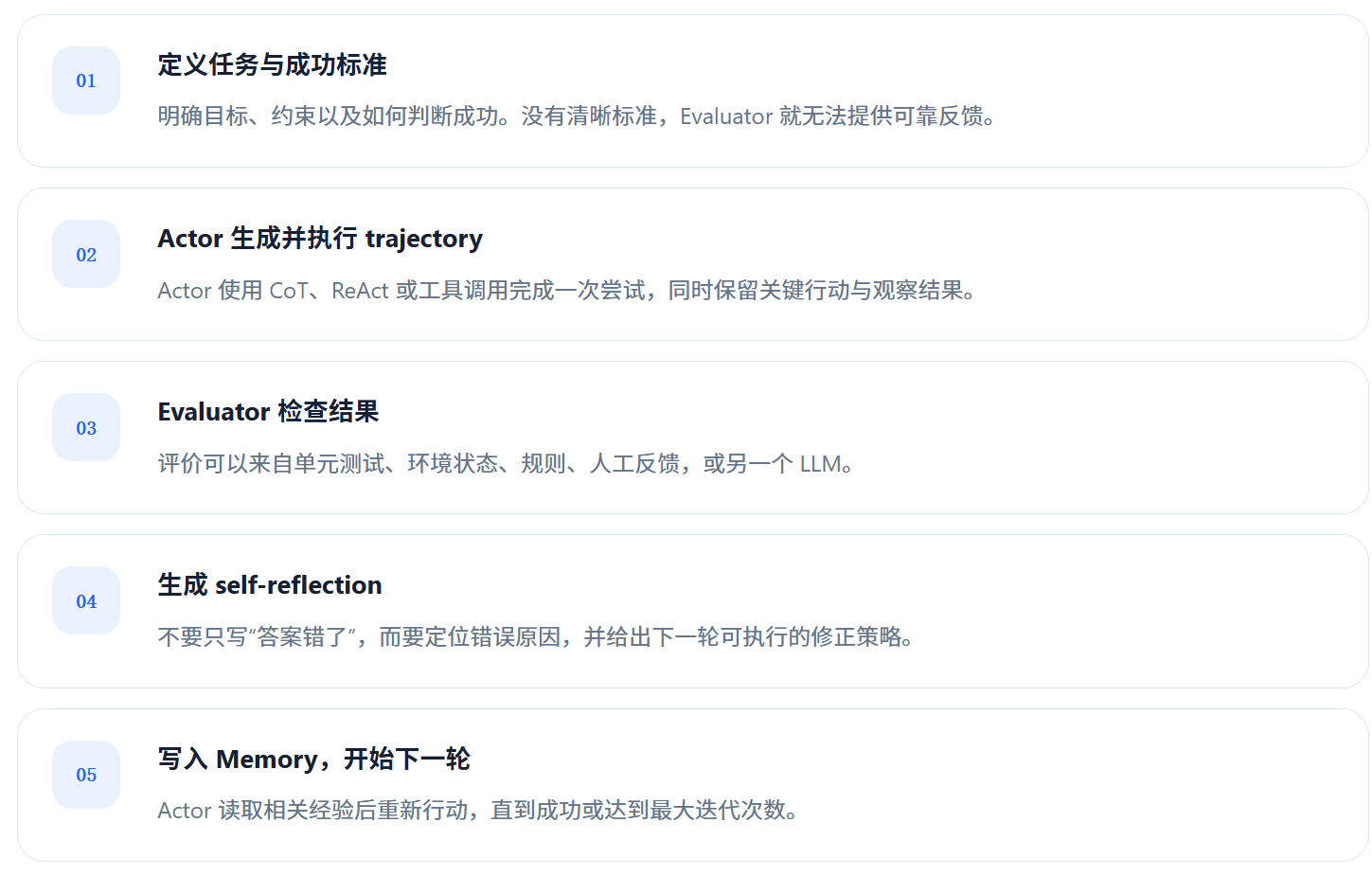
一次完整迭代怎样运行?
可以把 Reflexion 理解成一个带复盘能力的 Agent loop。
它与 ReAct、传统 RL 有什么区别?
| 方法 | 核心机制 | 是否更新模型参数 | 主要优势 |
|---|---|---|---|
| ReAct | 交替进行 Reasoning 与 Acting | 通常不更新 | 能够边思考边调用工具、观察环境 |
| Reflexion | 在 ReAct/CoT 之外增加评价、反思和记忆 | 通常不更新 | 利用语言经验纠正后续策略 |
| Traditional RL | 根据奖励信号优化策略参数 | 通常需要 | 适合大规模、可重复训练的环境 |