手写字母识别
基于深度学习的手写字母识别 模型,用户可在画布上绘制大写字母(A-Z) ,由训练好的 CNN 模型进行预测识别。
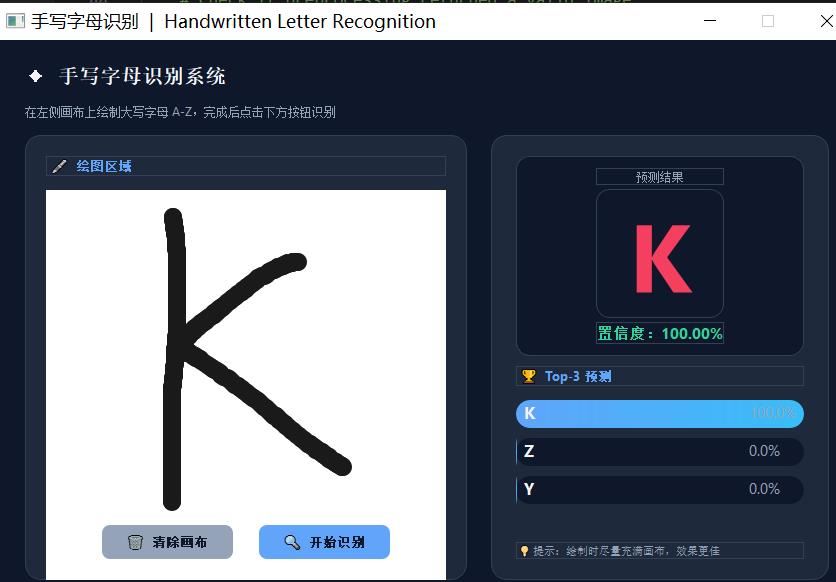
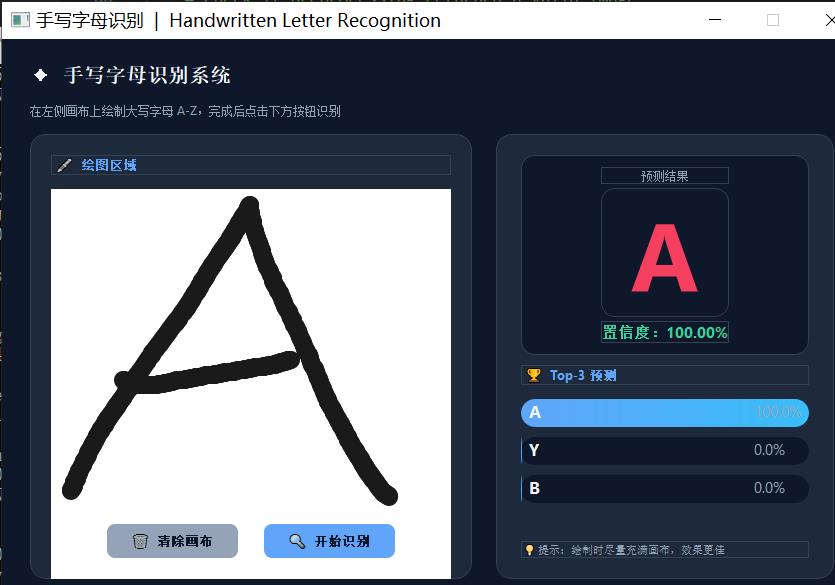
✅ 功能特性
✔ 用户可在交互式画布上绘制字母
✔ 使用 OpenCV 进行图像预处理 ,提升识别效果
✔ 基于**训练好的卷积神经网络(CNN)**进行预测
✔ 模型在 EMNIST 数据集上训练
安装
1️⃣ 克隆仓库
bash
git clone firc-projects
cd handwritten_letter_recognition2️⃣ 安装依赖
bash
pip install -r requirements.txt使用方法
运行应用
bash
python3 app.py- 在弹出的窗口中绘制大写字母(A-Z)。
- 按 's' 键进行字母识别。(按 'q' 退出)
- 程序将输出识别结果及置信度。
📊 输出示例
Predicted Letter: W
Confidence: 96.85%🧠 模型详情
- 架构: 卷积神经网络(CNN)
- 数据集: 在 EMNIST Letters 数据集上训练(28x28 灰度图像)
- 类别数: 26 个大写字母(A-Z)
📊 模型性能
测试准确率与损失
- 测试准确率: 94.57%
- 测试损失: 0.1703
📜 分类报告
precision recall f1-score support
A 0.93 0.96 0.95 800
B 0.98 0.97 0.98 800
C 0.97 0.96 0.97 800
D 0.97 0.96 0.96 800
E 0.97 0.98 0.97 800
F 0.98 0.97 0.98 800
G 0.91 0.81 0.86 800
H 0.95 0.96 0.96 800
I 0.78 0.73 0.76 800
J 0.97 0.95 0.96 800
K 0.98 0.97 0.98 800
L 0.75 0.79 0.77 800
M 0.99 1.00 0.99 800
N 0.96 0.97 0.96 800
O 0.96 0.98 0.97 800
P 0.98 0.99 0.99 800
Q 0.85 0.90 0.88 800
R 0.97 0.96 0.97 800
S 0.98 0.98 0.98 800
T 0.97 0.98 0.97 800
U 0.95 0.94 0.95 800
V 0.93 0.94 0.93 800
W 1.00 0.98 0.99 800
X 0.97 0.98 0.98 800
Y 0.95 0.96 0.96 800
Z 0.99 1.00 0.99 800
accuracy 0.95 20800
macro avg 0.95 0.95 0.95 20800
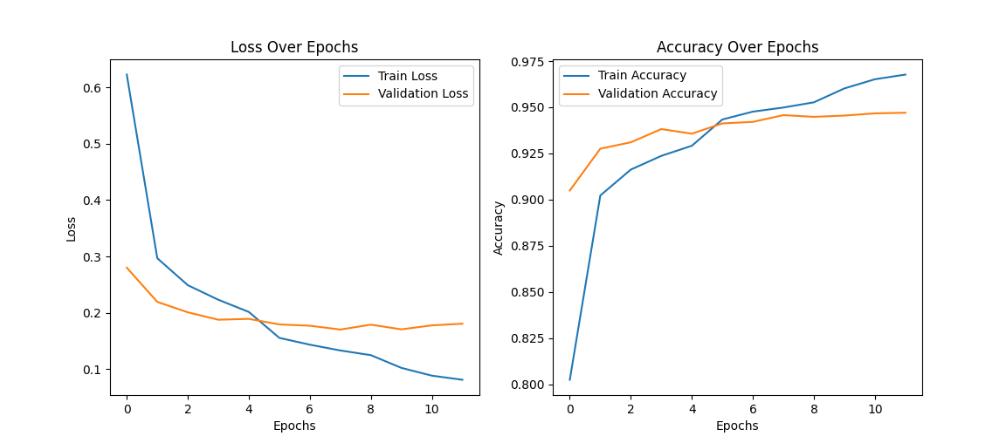
weighted avg 0.95 0.95 0.95 20800📈 训练过程可视化
以下为模型的训练准确率与损失曲线图:
!
🛠 模型配置
yaml
model:
type: "CNN"
layers:
- Conv2D: {filters: 64, kernel_size: [3,3], activation: "LeakyReLU", input_shape: [28, 28, 1], kernel_initializer: "he_normal"}
- MaxPooling2D: {pool_size: [2,2]}
- Conv2D: {filters: 128, kernel_size: [3,3], activation: "LeakyReLU", kernel_initializer: "he_normal"}
- MaxPooling2D: {pool_size: [2,2]}
- Conv2D: {filters: 256, kernel_size: [3,3], activation: "LeakyReLU", kernel_initializer: "he_normal"}
- Flatten: {}
- Dense: {units: 512, activation: "LeakyReLU", kernel_initializer: "he_normal"}
- Dropout: {rate: 0.4}
- Dense: {units: 26, activation: "softmax"}
training:
optimizer: "adam"
loss_function: "categorical_crossentropy"
batch_size: 64
epochs: 30
learning_rate_schedule: "ReduceLROnPlateau (patience=1, factor=0.5, min_lr=1e-5)"
dataset:
name: "EMNIST Letters"
input_shape: [28, 28, 1]
classes: 26
preprocessing: # 数据预处理
- "逆时针旋转 90°"
- "水平翻转"
- "将像素值归一化至 [0,1] 范围"
augmentation: # 数据增强
- "RandomAffine: degrees=6, translate=(0.05, 0.05), scale=(0.98, 1.02)"
- "RandomApply: ElasticTransform(alpha=2.0, p=0.2)"
- "RandomApply: GaussianBlur(kernel_size=3, p=0.05)"开发过程中遇到的挑战
在开发过程中,我遇到了多个技术挑战,并逐一进行了系统性解决:
1️⃣ 数据预处理与方向校正
- 挑战: EMNIST 数据集中的图像存在顺时针旋转 90° 并镜像的问题,导致预测不准确。
- 解决方案: 实现了自定义预处理 步骤,包括逆时针旋转 90° 和水平翻转,确保图像在输入模型前方向正确。
2️⃣ 使模型适应真实手写输入
- 挑战: 模型在 EMNIST 上表现良好,但由于数据集偏差,对真实手写输入的识别能力较弱。
- 解决方案: 引入了数据增强 ,包括弹性变换、高斯模糊及轻微仿射变换 ,有效提升了模型对不同书写风格的泛化能力。
3️⃣ 解决相似字母的误分类问题(I、L、G、Q)
- 挑战: 模型经常将外形相似的字母混淆,例如 I 与 L 、G 与 Q。
- 解决方案: 引入了针对性数据增强 ,包括对 I 和 L 进行轻微旋转调整。
4️⃣ 防止过拟合与模型优化
- 挑战: 模型在训练约 9 个 epoch 后开始出现过拟合,泛化能力下降。
- 解决方案: 调整了 Dropout 层(0.4)、提前触发 ReduceLROnPlateau 以及优化 batch size,从而提升了在未见数据上的表现。
5️⃣ 使用早停法提升训练效率
- 挑战: 难以确定最佳训练轮数,模型在超过最优 epoch 后继续训练,导致不必要的计算开销和严重过拟合。
- 解决方案: 实现了 EarlyStopping(早停) ,监控验证损失,在其不再改善时停止训练,确保模型保持最佳性能。
完整源码地址:https://download.csdn.net/download/FL1623863129/90010786