📚 目录
- [1. Java哈希前置知识](#1. Java哈希前置知识)
- [1.1 哈希定义](#1.1 哈希定义)
- [1.2 哈希冲突](#1.2 哈希冲突)
- [1.3 负载因子](#1.3 负载因子)
- [2. 手动实现Hash桶](#2. 手动实现Hash桶)
- [2.1 底层数组结构](#2.1 底层数组结构)
- [2.2 链表节点封装](#2.2 链表节点封装)
- [2.3 put插入逻辑](#2.3 put插入逻辑)
- [2.4 get 逻辑](#2.4 get 逻辑)
- [2.5 remove移除逻辑](#2.5 remove移除逻辑)
前言:
哈希表是 Java 集合底层核心数据结构,HashMap、HashSet 的实现都离不开哈希桶。
1. Java哈希前置知识
在动手手写哈希桶之前,我们先理清三个核心概念,后文put、get、remove所有代码逻辑都基于这三点实现。
1.1 哈希定义
哈希(Hash)本质是哈希函数 :接收任意类型的key ,通过固定算法运算转换成整数,再对数组长度取模,映射成数组的下标。
它的核心优势是理想查询效率O(1):仅通过哈希计算就能直接定位存储下标,无需逐个遍历比较,直接建立key与存储位置的映射关系。
公式简化 :下标 = hash(key) % table.length(存储容量大小)
[🔙 返回目录](#🔙 返回目录)
1.2 哈希冲突

简单来说: 不同 key 经过哈希计算后,得到同一个数组下标 ,该现象就是哈希冲突或者哈希碰撞 。
我们把具有不同关键码 而具有相同哈希地址 的数据元素称为"同义词 "
冲突避免:
首先: 哈希冲突是无法避免的,我们只能尽可能降低它发生的概率;
冲突原因 : 哈希函数设计的不够合理;
常见的哈希函数:
| 方法名称 | 核心原理 | 适用场景 | 优缺点 | 掌握程度 |
|---|---|---|---|---|
| 直接定制法 | H a s h ( K e y ) = A ∗ K e y + B Hash(Key) = A*Key + B Hash(Key)=A∗Key+B,线性函数映射 | 关键字连续、数量少;字符串首字符哈希场景 | 优:计算简单均匀 缺:需提前知晓关键字分布 | 常用,重点掌握 |
| 除留余数法 | H a s h ( k e y ) = k e y % p Hash(key) = key \% p Hash(key)=key%p, p p p 取≤表长的质数 | 通用所有场景,手写Hash桶/HashMap底层使用 | 优:实现极简、适配所有数据 缺: p p p 非质数会加剧冲突 | 核心重点(必学) |
| 平方取中法 | 关键字平方后截取中间数位为哈希地址 | 不清楚关键字分布、数字位数较短 | 优:无需预判数据分布 缺:大数平方计算有性能损耗 | 了解即可 |
| 折叠法 | 关键字分段求和,取后几位作为哈希地址 | 关键字数字位数极多(长编号) | 优:长数据哈希分布均衡 缺:分段求和逻辑复杂 | 了解即可 |
| 随机数法 | 通过随机函数映射关键字为哈希地址 | 关键字长度长短不一、差距大 | 优:冲突概率低 缺:哈希结果不可复现,工程不实用 | 了解即可 |
| 数学分析法 | 筛选字符分布均匀的数位作为哈希地址 | 大批量格式统一的关键字,可提前统计 | 优:冲突概率最低 缺:前期统计工作量巨大 | 了解即可 |
[🔙 返回目录](#🔙 返回目录)
1.3 负载因子
负载因子 = 哈希桶内总元素数量 s i z e 底层数组 t a b l e 长度 负载因子 = \frac{哈希桶内总元素数量size}{底层数组table长度} 负载因子=底层数组table长度哈希桶内总元素数量size
核心作用
负载因子用来衡量数组的填充程度,直接决定哈希冲突的密集程度:
1. 数值越大:数组空位越少,每条链表挂载的节点变多,查询、遍历效率大幅下降;
2. 数值越小:数组大量空间闲置,内存资源浪费严重。
扩容触发规则 (和JDK HashMap保持一致)
我们设定阈值默认0.75,执行put插入元素后,若 负载因子 ≥ 0.75,会触发扩容逻辑:
1. 底层数组长度翻倍;
2. 遍历原有全部链表节点,重新哈希计算下标,迁移到新数组;
3. 打散过长链表,缩短遍历长度,恢复O(1)查询效率。
为什么阈值选0.75?
0.75是时间效率与内存占用的平衡点:阈值过高冲突暴增,阈值过低频繁扩容浪费内存。
[🔙 返回目录](#🔙 返回目录)
2. 手动实现Hash桶
接下来我们使用Java代码来模式实现简易版的Hash桶;
采用和 JDK HashMap 一致的数组 + 单向链表(链地址法) 结构,核心实现put插入、get查询、remove删除三大方法。
[🔙 返回目录](#🔙 返回目录)
2.1 底层数组结构
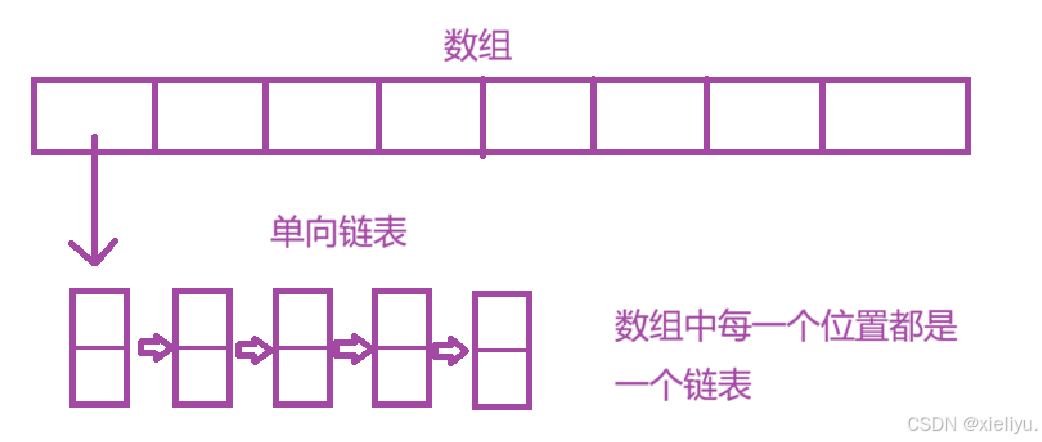
哈希桶最外层是一个数组 ,数组中每一个位置存储一条单向链表 的头节点;不同 key 哈希取模后落到同一个数组下标时,全部挂载到对应链表上。
size :哈希桶中实际存储的键值对总数量;
LOAD_FACTOR负载因子大小 = 0.75f;
java
public class HashBuck<K,V> {
//负载因子
public static final float LOAD_FACTOR = 0.75f;
//大小
public int size;
}[🔙 返回目录](#🔙 返回目录)
2.2 链表节点封装
数组每一格存放的链表节点需要保存key、value,以及下一个节点的引用next,我们静态内部类封装 Node 节点:
- key:存储映射唯一标识,用于对比判断重复元素;
- value:key 对应的存储数据;
- next:指向下一个冲突节点,形成单向链表。
java
public class HashBuck<K,V> {
//自己定义的hash桶
static class Node<K,V> {
public K key;
public V value;
public Node<K,V> next;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
}
//负载因子
public static final float LOAD_FACTOR = 0.75f;
//开始定义自己的hash数组
public Node<K,V>[] array;
//大小
public int size;
//默认大小为10
public HashBuck() {
array = (Node<K,V>[])new Node[10];
}
}[🔙 返回目录](#🔙 返回目录)
2.3 put插入逻辑
如果我们只用我们要插入的元素的值进行计算:
举个例子,我们存入自定义对象 Student s = new Student(18,"张三");,直接调用 map.put(s,"学生信息");。
此时如果我们没有重写 Student 类的 hashCode() 方法,会出现严重问题:
我们新建两个属性完全一致的学生对象:
java
Student s1 = new Student(18,"张三");
Student s2 = new Student(18,"张三");逻辑上这两个对象是同一个 key,但因为是两块不同内存 , 经过取模计算数组下标后,s1、s2 会落到数组两个完全不相同的格子里 ,本该判定为重复 key、覆盖 value,结果变成两条独立链表 ,哈希桶里同时存两份一模一样的 key,违背 HashMap "键唯一" 的核心规则.
弊端:
1. 内容相同的对象会生成不同哈希值,落到数组不同下标,出现重复 key;
2. 使用属性一致的新对象 get 查询,无法匹配到已存储数据;
3. 违背 Java 哈希契约,搭配重写后的equals直接失效;
4. 哈希分布不均,链表堆积,哈希桶查询性能暴跌。
所以我们必须 在自定义实体类中同时重写hashCode()与equals() ,基于对象业务属性生成哈希值,保证属性相同的对象哈希值完全一致,才能让 Hash 桶 put、get 逻辑正常运行。
我们只保证这些就行了吗? - > 答案是否定的;
负载因子 = 哈希桶内总元素数量 s i z e 底层数组 t a b l e 长度 负载因子 = \frac{哈希桶内总元素数量size}{底层数组table长度} 负载因子=底层数组table长度哈希桶内总元素数量size
我们知道负载因子的计算公式知道 : Hash桶内元素越多 ,我们后续添加数据的过程中,出现哈希冲突的概率就越高 ;
我们不能保证Hash桶内的元素个数
但是我们能保证底层数组的长度,当我们自己计算负载因子的值大于等于0.75的时候 ,我们能做到的是让数组进行扩容 ;
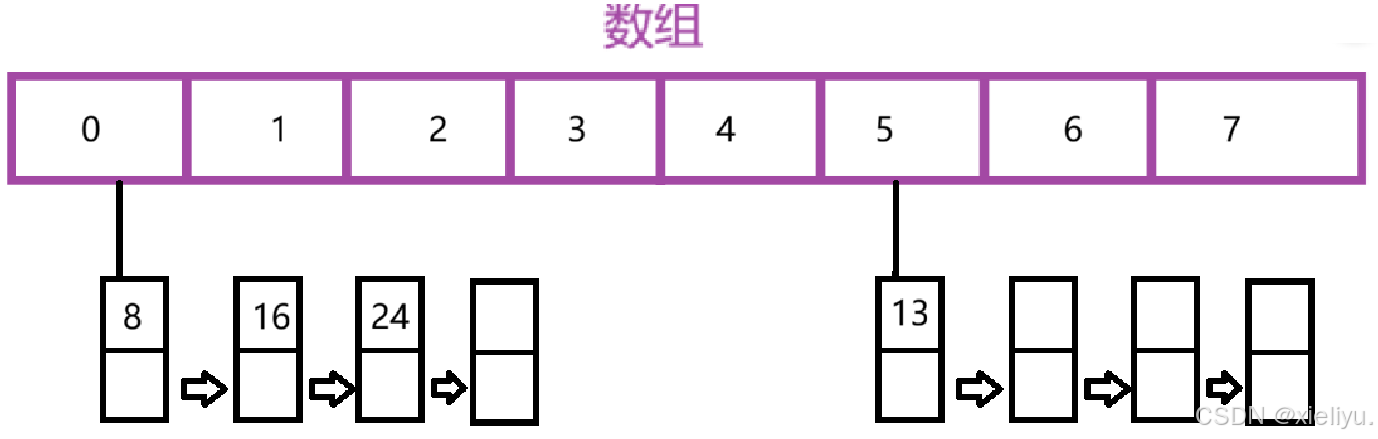
假如 : 我们数组放着元素,当数组中个数/长度满足负载因子的时候,我们就需要对数组进行重新扩容;
此时 : 每一个位置上的元素可能都不会在原来数组中对应下标的位置 ,我们需要重新拿出数组中的所有元素进行重新哈希;
- 哈希寻址:通过 key 的哈希值对数组长度取模,算出目标数组下标,锁定插入位置;
- 链表操作:
- 若数组该下标无链表,直接将新键值对节点存入数组;
- 若已存在链表,则遍历整条链表:
- 存在相同 key:覆盖原有 value,返回旧值;
- 无相同 key:将新节点挂载到链表尾部,解决哈希冲突。
java
//添加
public void push(K key,V value) {
if (key == null) {
throw new IllegalArgumentException("key cannot be null");
}
//拿到对应哈希值
int hash = key.hashCode();
//计算插入下标
int index = hash % array.length;
//拿到下标位置的链表
Node<K,V> cur = array[index];
//判断当前链表中是否存在Key
while (cur!=null) {
if(cur.key.equals(key)) {
cur.value = value;
return;
}
cur = cur.next;
}
//进行头插
Node<K,V> node = new Node<>(key,value);
node.next = array[index];
array[index] = node;
size++;
//扩容 ; 满足条件时进行重新哈希
if((float) size/array.length >= LOAD_FACTOR) {
resize();
}
}
//扩容需要重新哈希
private void resize() {
//进行二倍扩容
Node<K,V>[] newArray = (Node<K,V>[])new Node[array.length<<1];
//重新哈希
for (int i = 0; i < array.length; i++) {
Node<K,V> cur = array[i];
while (cur!=null) {
Node<K,V> curN = cur.next;
//重新计算哈希值
int hash = cur.key.hashCode();
int index = hash % newArray.length;
cur.next = newArray[index];
newArray[index] = cur;
cur = curN;
}
}
array = newArray;
}[🔙 返回目录](#🔙 返回目录)
2.4 get 逻辑
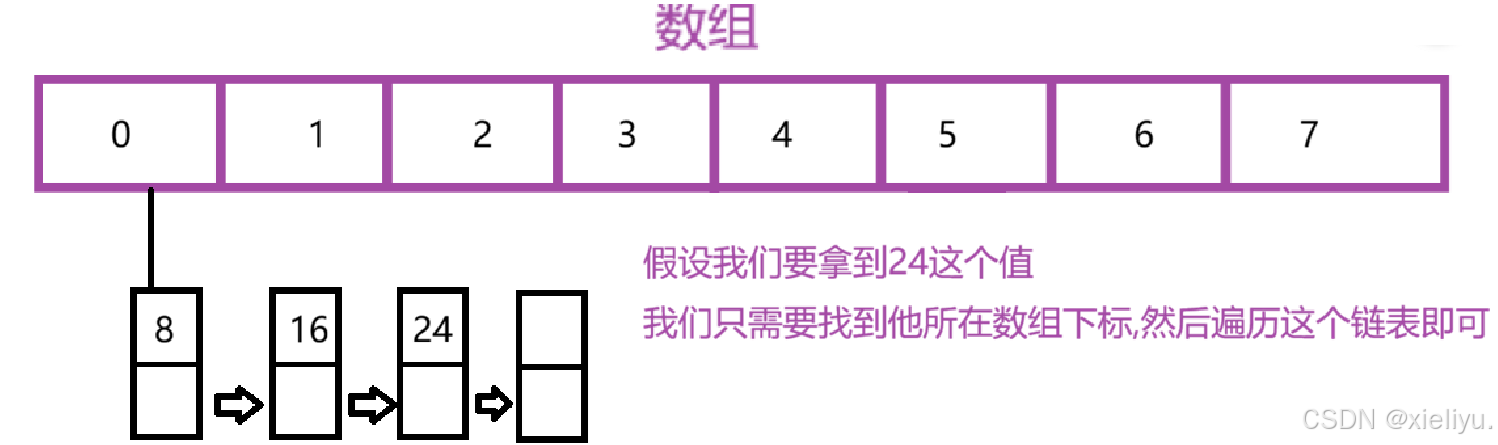
相较于put方法,get方法是比较简单的,我们既不需要重新哈希也不需要对数组进行任何改变;
原理: 就是获取我们想要key中在数组中下标位置的链表,对链表进行遍历即可.
- 哈希寻址定位数组下标:对目标 key 做 hash 运算,和 put 插入时完全一致,算出它存放在数组哪一格;
- 遍历对应链表匹配 key:取出该下标下的整条单向链表,从头节点逐个比对 key;
- 匹配到完全相同 key:直接返回对应的 value;
- 整条链表遍历完都无匹配 key:返回null代表元素不存在。
相较于put插入方法,get逻辑极简:不会修改数组、不会新增节点、无需处理扩容重哈希,只做查询只读操作。底层原理就是:先定位数组槽位,再线性遍历槽内链表完成匹配。
java
//查找
public V get(K key) {
if (key == null) {
return null;
}
int hash = key.hashCode();
int index = hash % array.length;
Node<K,V> node = array[index];
while (node!=null) {
if(node.key.equals(key)) {
return node.value;
}
node = node.next;
}
//找不到我们则返回null
return null;
}[🔙 返回目录](#🔙 返回目录)
2.5 remove 移除逻辑
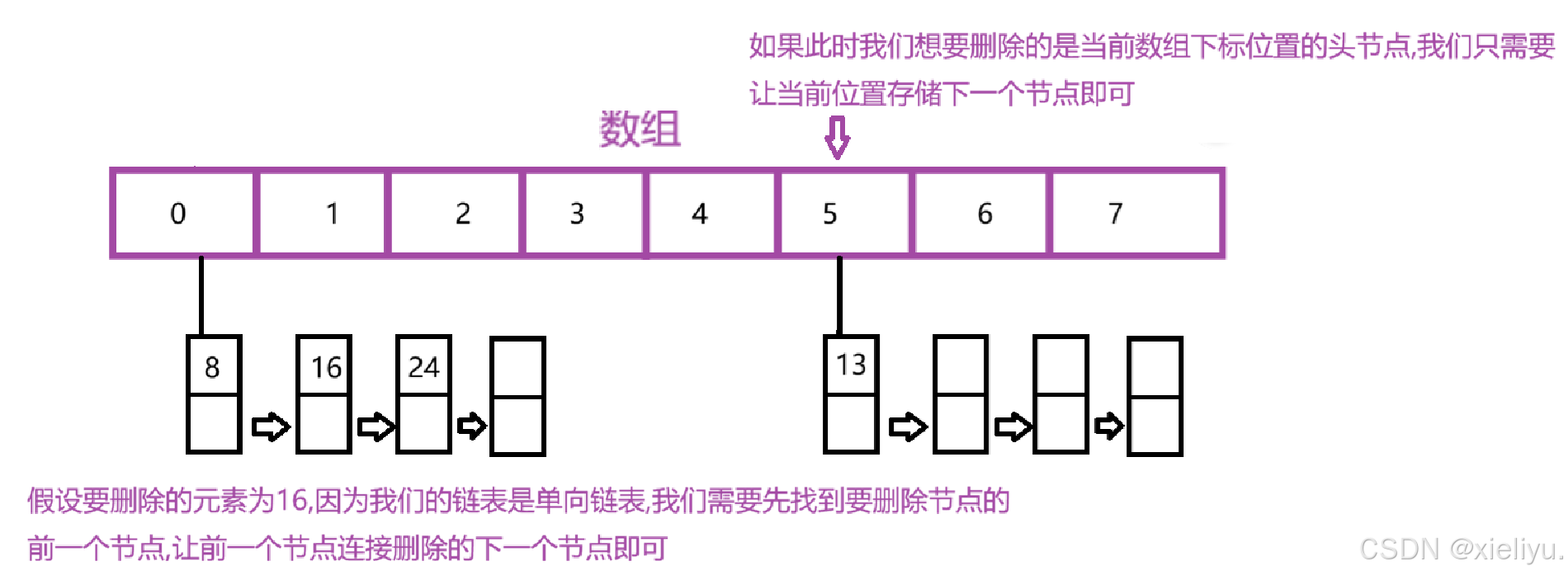
场景 1:要删除的节点是链表头节点(图右侧示例)
数组槽位直接指向当前节点的下一个节点。
场景 2:要删除的是链表中间 / 尾部节点(图左侧示例,删除 16)
单向链表无法反向查找前驱,所以遍历链表时必须用 prev 记录上一个节点;
找到目标节点后,让前驱节点的 next 直接跳过待删节点、连接到它的下一个节点,断开待删节点的链路完成删除。
整体流程:哈希寻址 → 遍历链表并记录前驱节点 → 区分头 / 中间节点执行断开逻辑 → 元素总数 size 减一 → 返回被删除节点的 value;key 不存在则返回null。
java
//删除
public V remove(K key) {
if(key == null) {
return null;
}
int hash = key.hashCode();
int index = hash%array.length;
Node<K,V> cur = array[index];
Node<K,V> prev = null;
while (cur!=null) {
if(cur.key.equals(key)) {
if(prev == null) {
array[index] = cur.next;
}else {
prev.next = cur.next;
}
size--;
return cur.value;
}
prev = cur;
cur = cur.next;
}
return null;
}面试核心考点汇总
- 哈希冲突解决:链地址法(数组+单向链表);
- 负载因子0.75的设计平衡:时间查询效率 & 内存占用;
- 自定义对象作为key,必须重写hashCode()和equals()底层原因;
- put插入流程:哈希寻址、冲突链表挂载、扩容重哈希逻辑;
- remove删除两种场景:链表头节点 / 中间节点的断开方式;
- 扩容时旧链表全部重哈希迁移,为什么不能直接复制下标。
[🔙 返回目录](#🔙 返回目录)