一、这个工具到底是干嘛的?
简单来说,这就是一个**"猜域名"**的工具。
想象一下,你想摸清一家公司到底有多少台服务器暴露在公网上。最直接的办法就是:把常见的子域名前缀(比如 www、mail、admin、api、test 等)一个个拼到主域名前面,然后去问DNS服务器:"这个域名存在吗?" 如果DNS说"存在,IP是xxx",那恭喜你,挖到了一个活靶子。
这个工具干的就是这件事,但它比你自己手动猜快了几万倍。
它能帮你发现什么?
- 公司的主站:
www.example.com - 邮件服务器:
mail.example.com - 测试环境:
test.example.com、staging.example.com - 管理后台:
admin.example.com、manage.example.com - API接口:
api.example.com、api-v2.example.com - 各种奇奇怪怪的子域名:
jenkins、gitlab、kibana、grafana......
这些东西在渗透测试里统称为**"攻击面"**------攻击面越大,找到漏洞的机会就越多。而子域名枚举,就是绘制这张攻击面地图的第一步。
二、为什么需要专门写个工具?我自己写个脚本不行吗?
当然可以,但你会遇到几个头疼的问题:
问题1:速度太慢
如果你用普通的 requests 库或者 socket.gethostbyname() 一个个查,那速度简直感人。假设字典有8万条,每秒查10个,得跑两个多小时。而这款工具通过多进程 + 异步协程的组合拳,能把速度提到每秒几百甚至上千次查询。
问题2:泛解析陷阱
很多域名配置了泛解析 (Wildcard DNS),意思是:不管你猜什么子域名,DNS都会给你返回一个IP。比如 abcdefg.example.com、123456.example.com,全都能解析到同一个IP。如果不处理这个问题,你的结果里会充斥着几万个"假阳性"域名,根本没法用。
问题3:深层子域名
发现了 api.example.com 之后,里面可能还藏着 v1.api.example.com、dev.api.example.com。普通工具扫完一级就停了,而好的工具会递归深挖。
问题4:跨平台兼容
你的脚本在Linux上跑得飞起,放到Windows上可能就崩了。因为Windows和Linux的异步IO机制完全不同。
这款工具把这些坑全填平了。
三、核心设计思路:怎么做到又快又准?
3.1 并发模型:多进程 × 协程的双层架构
这是整个工具的灵魂设计。
第一层:多进程(multiprocessing)
- 默认启动6个进程,每个进程独立运行
- 进程之间通过共享内存交换状态(扫描计数、发现计数等)
- 绕过Python的GIL(全局解释器锁),真正利用多核CPU
第二层:协程/多线程(asyncio / threading)
- 每个进程内部再开500个协程(Python 3)或线程(Python 2)
- 协程的优势在于:当一个DNS查询在等待网络响应时,CPU不会干等着,而是切换到下一个协程继续干活
- 这样就把网络IO的等待时间充分利用起来了
打个比方:多进程就像开了6个窗口同时办业务,每个窗口里又有500个业务员在轮班。客户(DNS查询)来了不用排队,总有人能接待。
3.2 泛解析检测:先试探,再动手
这是避免结果"注水"的关键。
工具在正式扫描前,会先做一个泛解析测试:
- 生成几个完全随机的子域名,比如
a8x9k2.example.com - 去查这些随机域名的DNS记录
- 如果它们都指向同一个IP,说明这个域名开启了泛解析
- 把这个IP加入黑名单,后续所有指向这个IP的结果都视为无效
这个策略虽然简单粗暴,但非常有效。它的逻辑是:随机字符串不可能是一个真实的子域名,如果它都能解析,那说明所有不存在的子域名都会被解析到同一个IP。
3.3 递归扫描:挖地三尺
发现 api.example.com 之后,工具不会就此罢休。它会把这个新发现的子域名当作新的"主域名",继续拼接字典进行扫描:
v1.api.example.comdev.api.example.comstaging.api.example.com
这样就能挖出很多隐藏得更深的资产。递归字典和初始字典是分开的,通常递归字典会更精简,避免无限膨胀。
3.4 HTTPS证书提取:另辟蹊径
除了DNS爆破,工具还会尝试连接目标的HTTPS端口,从SSL证书里提取**Subject Alternative Name(SAN)**字段。这个字段里往往包含了证书所覆盖的所有域名,有时候能发现DNS爆破漏掉的子域名。
四、代码实现原理图解
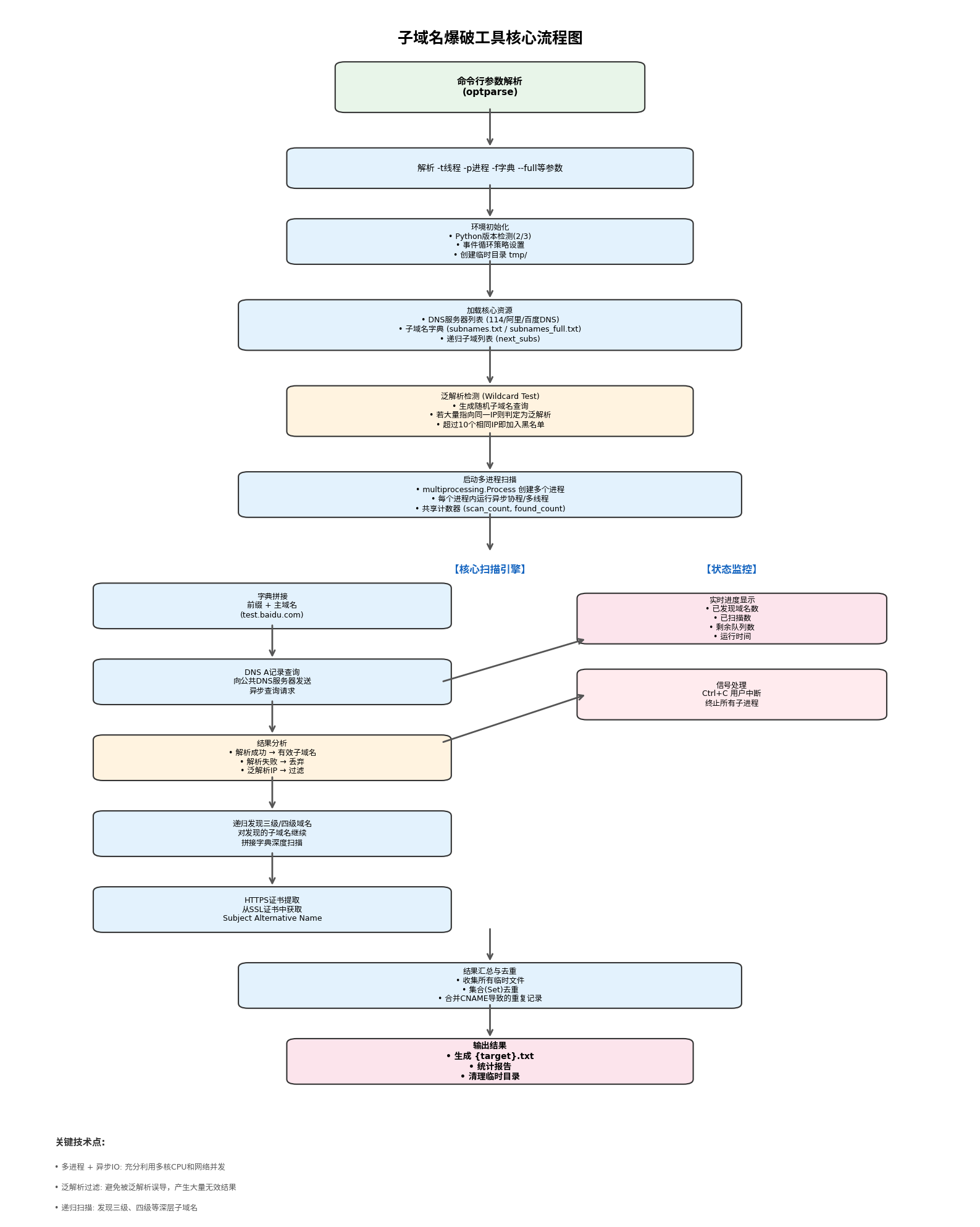
4.1 整体流程图
If you need the complete source code, please add the WeChat number (c17865354792)
从这张图可以看出,整个扫描流程分为几个阶段:
- 参数解析 :通过
optparse处理命令行参数,包括线程数、进程数、字典路径、是否全量扫描等 - 环境初始化:检测Python版本、设置事件循环策略、创建临时目录
- 资源加载:读取DNS服务器列表、子域名字典、递归扩展字典
- 泛解析检测:生成随机子域名测试,建立IP黑名单
- 多进程启动:创建多个扫描进程,每个进程内运行协程/线程
- 核心扫描循环:拼接域名 → DNS查询 → 结果判断 → 递归扩展 → HTTPS证书提取
- 结果汇总:收集临时文件、去重、生成最终报告
4.2 架构设计图
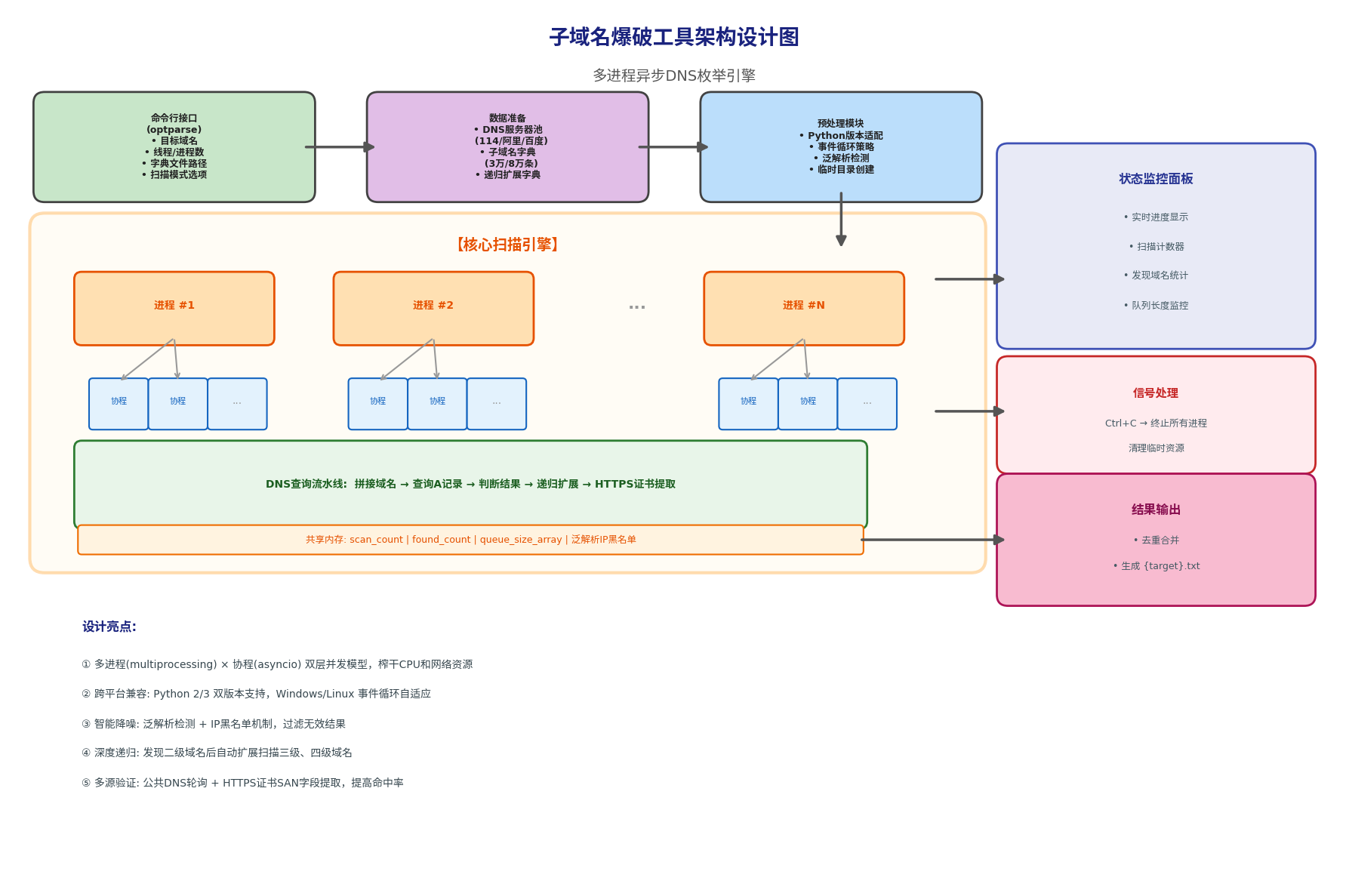
这个架构图更清晰地展示了双层并发模型:
- 输入层:命令行接口接收用户参数
- 数据层:准备DNS服务器池、子域名字典、递归扩展字典
- 预处理层:版本适配、泛解析检测、临时目录创建
- 核心引擎层:多进程 × 协程的扫描引擎,共享内存状态
- 监控层:实时进度显示、信号处理(Ctrl+C优雅退出)
- 输出层:去重合并、生成结果文件
4.3 代码模块结构图
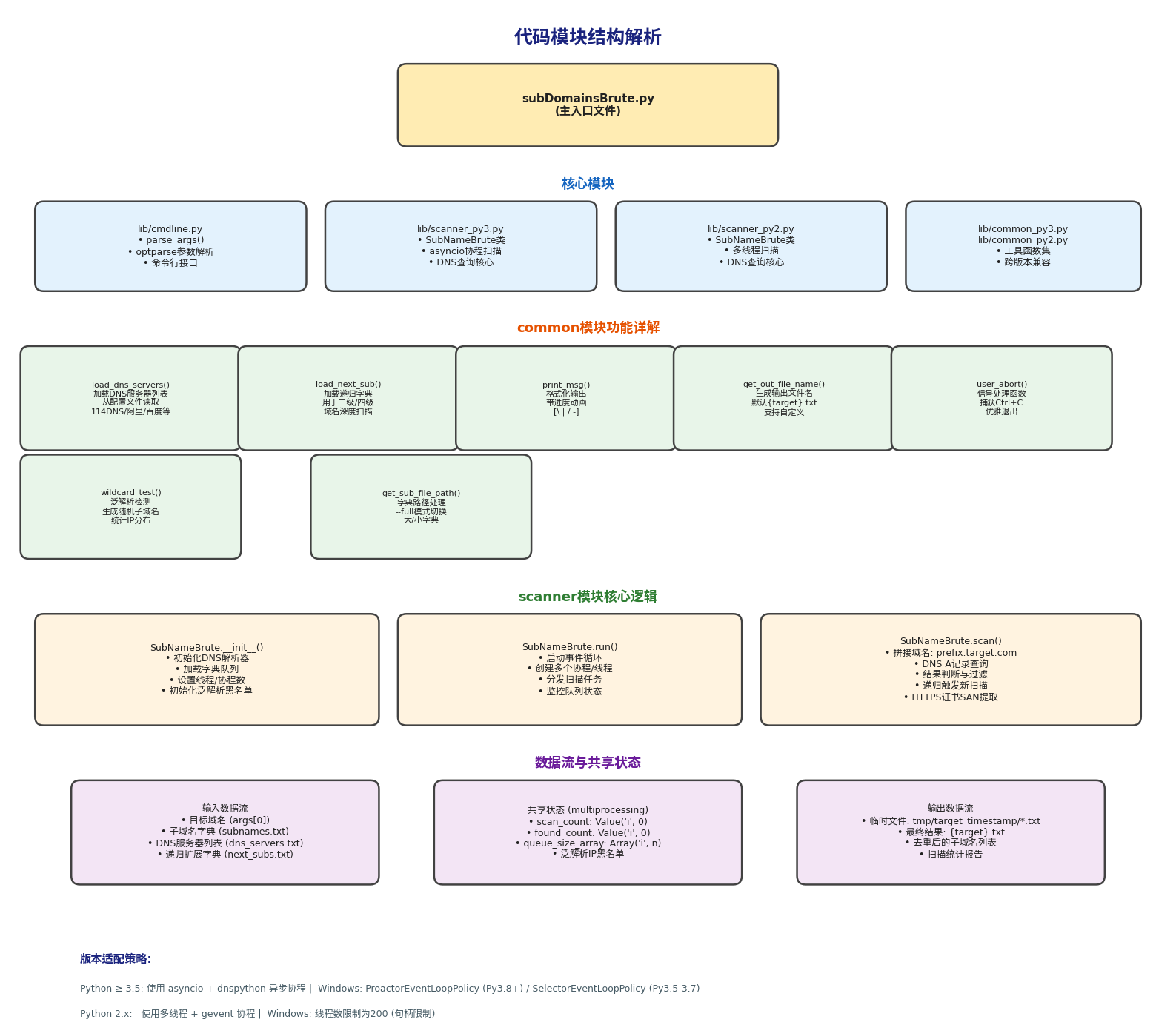
代码采用模块化设计,主要分成几块:
cmdline.py:命令行参数解析,用optparse库实现scanner_py3.py / scanner_py2.py:核心扫描类SubNameBrute,分别用asyncio协程和多线程实现common_py3.py / common_py2.py:工具函数集,包括DNS服务器加载、泛解析检测、输出文件名生成等
五、关键代码片段解读
5.1 命令行参数解析
python
def parse_args():
parser = optparse.OptionParser('usage: %prog [options] target.com')
parser.add_option('-f', dest='file', default='subnames.txt',
help='File contains new line delimited subs')
parser.add_option('--full', dest='full_scan', default=False, action='store_true',
help='Full scan, NAMES FILE subnames_full.txt will be used')
parser.add_option('-t', '--threads', dest='threads', default=500, type=int,
help='Num of scan threads, 500 by default')
parser.add_option('-p', '--process', dest='process', default=6, type=int,
help='Num of scan process, 6 by default')
# ...这里用 optparse 定义了各种参数,比较有意思的是:
-t控制每个进程的协程/线程数(默认500)-p控制进程数(默认6)--full切换到大字典模式(8万条 vs 3万条)--no-https可以跳过HTTPS证书提取,省点时间
5.2 Python版本适配
python
if sys.version_info.major >= 3 and sys.version_info.minor >= 5:
import asyncio
from lib.scanner_py3 import SubNameBrute
from lib.common_py3 import load_dns_servers, load_next_sub, ...
if platform.system() == 'Windows':
if sys.version_info.minor >= 8:
asyncio.set_event_loop_policy(asyncio.WindowsProactorEventLoopPolicy())
else:
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
else:
from lib.scanner_py2 import SubNameBrute
from lib.common_py2 import ...这段代码体现了跨版本、跨平台的设计思想:
- Python 3.5+ 用
asyncio协程 - Python 2.x 用多线程
- Windows下需要特殊设置事件循环策略(Proactor/Selector)
- Windows下线程数限制为200(系统句柄限制)
5.3 多进程启动与状态共享
python
scan_count = multiprocessing.Value('i', 0) # 已扫描数
found_count = multiprocessing.Value('i', 0) # 已发现数
queue_size_array = multiprocessing.Array('i', options.process) # 各进程队列长度
for process_num in range(options.process):
p = multiprocessing.Process(
target=run_process,
args=(domain, options, process_num, dns_servers, next_subs,
scan_count, found_count, queue_size_array, tmp_dir)
)
all_process.append(p)
p.start()这里用 multiprocessing.Value 和 multiprocessing.Array 实现进程间共享状态 。Value('i', 0) 表示一个整数类型的共享变量,所有进程都能读写,用来统计全局的扫描进度。
5.4 实时进度显示
python
char_set = ['\\', '|', '/', '-']
count = 0
while all_process:
for p in all_process:
if not p.is_alive():
all_process.remove(p)
groups_count = 0
for c in queue_size_array:
groups_count += c
msg = '[%s] %s found, %s scanned in %.1f seconds, %s groups left' % (
char_set[count % 4], found_count.value, scan_count.value,
time.time() - start_time, groups_count)
print_msg(msg)
count += 1
time.sleep(0.3)这段代码实现了一个旋转进度条 ([\] | / - 循环),同时显示:
- 已发现的子域名数
- 已扫描的域名数
- 运行时间
- 剩余队列长度
每0.3秒刷新一次,让用户能实时看到扫描进展。
5.5 结果汇总与去重
python
all_domains = set() # 用集合去重
domain_count = 0
with open(out_file_name, 'w') as f:
for _file in glob.glob(tmp_dir + '/*.txt'):
with open(_file, 'r') as tmp_f:
for domain in tmp_f:
if domain not in all_domains:
domain_count += 1
all_domains.add(domain)
f.write(domain)这里用 set() 来去重,因为:
- 多个进程可能发现同一个子域名
- CNAME记录可能导致同一个域名被多次记录
- 递归扫描可能重复发现已存在的域名
去重后输出到 {target}.txt,并清理临时目录。
六、涉及的技术领域知识点总结
6.1 DNS协议基础
- A记录:将域名映射到IPv4地址,这是工具查询的核心记录类型
- CNAME记录:别名记录,一个域名指向另一个域名,可能导致重复结果
- 泛解析(Wildcard DNS) :
*记录匹配所有不存在的子域名,是子域名爆破的最大干扰源 - DNS服务器类型:递归解析器(如公共DNS)vs 权威名称服务器
6.2 Python并发编程
- GIL(全局解释器锁):Python多线程无法真正并行,所以需要用多进程绕过
- asyncio:Python 3.5+ 的异步IO库,用协程实现高并发网络操作
- 事件循环(Event Loop):协程的调度中心,Windows和Linux的实现不同
- multiprocessing:Python的多进程库,支持共享内存
6.3 网络编程
- DNS查询原理:UDP 53端口,一问一答的查询响应模式
- SSL/TLS证书:HTTPS证书中的SAN字段可以暴露多个子域名
- 超时与重试:网络查询需要设置合理的超时时间,避免无限等待
6.4 渗透测试方法论
- 信息收集:渗透测试的第一步,子域名枚举是信息收集的核心环节
- 攻击面测绘:通过子域名发现目标的所有暴露资产
- 字典攻击:基于预定义列表的暴力枚举,字典质量直接决定发现率
6.5 工程实践
- 跨版本兼容:同时支持Python 2和Python 3,代码需要两套实现
- 跨平台兼容:Windows和Linux的异步IO机制差异
- 信号处理:捕获用户中断(Ctrl+C),优雅地终止所有子进程
- 临时文件管理:扫描过程中产生大量临时文件,需要及时清理
七、使用建议
7.1 字典选择
- 日常扫描用默认字典(约3万条),速度快
- 深度扫描用
--full模式(约8万条),覆盖面广但耗时 - 可以自定义字典,把行业常见词汇、目标公司相关词汇加进去
7.2 线程与进程调优
- 默认500线程/6进程在大多数机器上表现不错
- 如果机器配置高、网络带宽足,可以适当提高
- Windows下线程数不要超过200(系统限制)
7.3 泛解析处理
- 如果目标开启了泛解析,工具会自动过滤,但可能漏掉一些真实子域名
- 可以先用
-w参数强制扫描,再手动筛选结果
7.4 结果验证
- 爆破出来的子域名建议再用
nmap或httpx做存活探测 - 重点关注测试环境(
test、staging、dev)和管理后台(admin、manage)
总结
这款工具的设计精髓在于"用工程手段解决性能问题"。它没有用什么高深算法,而是把几个成熟技术组合在一起,发挥出了1+1>2的效果:
| 技术手段 | 解决的问题 |
|---|---|
| 多进程 | 绕过GIL,利用多核CPU |
| 协程/多线程 | 充分利用网络IO等待时间 |
| 泛解析检测 | 过滤无效结果,提高准确率 |
| 递归扫描 | 发现深层子域名 |
| HTTPS证书提取 | 补充DNS爆破的盲区 |
| 共享内存 | 多进程状态同步 |
| 跨版本兼容 | 扩大用户群体 |
Welcome to follow WeChat official account【程序猿编码】