😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本文讲解【强化学习】MDP、贝尔曼方程与CartPole 编程,20W字总结(二),期待与你一同探索、学习、进步,一起卷起来叭!
🎯 把我的博客装进你的 Claude Code,它就是你的 AI 学习搭子想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code------它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动存任何文件。
text请为这个 CSDN 博客创建一个本地 SKILL(存到 .claude/skills/csdn-blog/SKILL.md): RSS 源:https://rss.csdn.net/m0_51517236/rss/map 支持三件事:① 列出最新文章(标题+链接+摘要);② 按关键词搜索; ③ 抓取指定文章全文,作为 AI 学习助手 / 面试官深度讲解并出题考核我。 SKILL.md 里写清楚 RSS URL、调用方式和示例。生成完就能用自然语言搜文章了。一键订阅,长期可用。🚀
目录
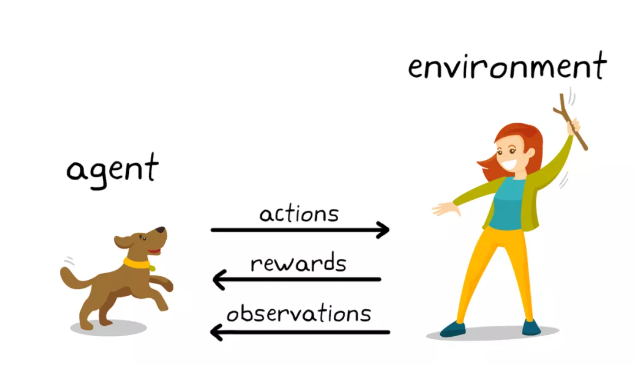
在上一篇中,我们用直觉理解了强化学习的核心概念:智能体、环境、状态、动作、策略、回报、价值函数。这篇文章要给这些直觉穿上数学的铠甲------用马尔可夫决策过程(MDP)和贝尔曼方程把框架搭严实,然后直接上手写代码,在 CartPole 环境里验证所学。
马尔可夫决策过程(MDP)
什么是 MDP?
强化学习需要一个形式化的数学框架来描述智能体与环境的互动。这个框架就是马尔可夫决策过程(Markov Decision Process,MDP)。
MDP 通过三个要素来建模整个系统:
| 要素 | 数学表示 | 含义 |
|---|---|---|
| 状态迁移 | p ( s ′ ∣ s , a ) p(s' \mid s, a) p(s′∣s,a) | 在状态 s s s 执行动作 a a a 后,迁移到 s ′ s' s′ 的概率 |
| 奖励函数 | r ( s , a , s ′ ) r(s, a, s') r(s,a,s′) | 从状态 s s s 执行动作 a a a 迁移到 s ′ s' s′ 时获得的奖励 |
| 策略 | π ( a ∣ s ) \pi(a \mid s) π(a∣s) | 在状态 s s s 下选择动作 a a a 的概率 |
马尔可夫性质
MDP 最核心的假设是马尔可夫性质:
下一个状态 s ′ s' s′ 只取决于 当前状态 s s s 和动作 a a a,不需要任何历史信息。
就像下棋------理论上你应该考虑整盘棋的走势,但如果当前棋盘状态已经包含了所有必要信息,那你只需要看眼前的局面就能做出最优决策。马尔可夫性质就是:"当前状态已经够用了,过去的不用管。"
为什么需要这个假设?因为如果不加这个约束,就得考虑之前所有状态和动作的组合,数量呈指数级爆炸,问题根本解不了。
注意 :马尔可夫性质是对环境的约束,不是对智能体的。它要求环境在当前状态中保持足够的信息,使得智能体只看当前状态就能做出最佳选择。
MDP 的目标
智能体根据策略 π ( a ∣ s ) \pi(a \mid s) π(a∣s) 采取动作,环境根据 p ( s ′ ∣ s , a ) p(s' \mid s, a) p(s′∣s,a) 决定状态迁移,奖励由 r ( s , a , s ′ ) r(s, a, s') r(s,a,s′) 给出。在这个框架下,MDP 的目标是找到最优策略------让期望回报最大的那个策略。
回报与价值函数
收益的递推关系
回顾回报的定义:
G t = R t + γ R t + 1 + γ 2 R t + 2 + ⋯ G_t = R_t + \gamma R_{t+1} + \gamma^2 R_{t+2} + \cdots Gt=Rt+γRt+1+γ2Rt+2+⋯
把 t + 1 t+1 t+1 时刻开始的回报记为 G t + 1 G_{t+1} Gt+1:
G t + 1 = R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ G_{t+1} = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \cdots Gt+1=Rt+1+γRt+2+γ2Rt+3+⋯
你会发现一个优美的递推关系:
G t = R t + γ R t + 1 + γ 2 R t + 2 + ⋯ = R t + γ ( R t + 1 + γ R t + 2 + ⋯ ) = R t + γ G t + 1 \begin{aligned} G_t &= R_t + \gamma R_{t+1} + \gamma^2 R_{t+2} + \cdots \\ &= R_t + \gamma(R_{t+1} + \gamma R_{t+2} + \cdots) \\ &= R_t + \gamma G_{t+1} \end{aligned} Gt=Rt+γRt+1+γ2Rt+2+⋯=Rt+γ(Rt+1+γRt+2+⋯)=Rt+γGt+1
这个递推公式在整个强化学习中反复出现,后面推导贝尔曼方程时会直接用到它。
状态价值函数与最优策略
由于智能体的动作和环境的状态迁移都有随机性,即使从相同状态出发,不同回合的回报也不一样。所以要用期望值来衡量:
v π ( s ) = E π G t ∣ S t = s v_\pi(s) = \mathbb{E}_\piG_t \\mid S_t = s vπ(s)=EπGt∣St=s
策略 π \pi π 的好坏决定了 v π ( s ) v_\pi(s) vπ(s) 的大小。使期望回报最大的那个策略叫最优策略 ,对应的状态价值函数叫最优状态价值函数 ,记为 v ∗ ( s ) v_*(s) v∗(s)。
贝尔曼方程
贝尔曼方程是 MDP 中最重要的方程,几乎所有强化学习算法的理论基础都源于此。
从期望说起
先快速过一下期望值的基本概念。掷一个公平的六面骰子,每个面出现的概率是 1 6 \frac{1}{6} 61,期望值:
E x = 1 × 1 6 + 2 × 1 6 + ⋯ + 6 × 1 6 = 3.5 \mathbb{E}x = 1 \times \frac{1}{6} + 2 \times \frac{1}{6} + \cdots + 6 \times \frac{1}{6} = 3.5 Ex=1×61+2×61+⋯+6×61=3.5
更一般地, E x = ∑ x x ⋅ p ( x ) \mathbb{E}x = \sum_x x \cdot p(x) Ex=∑xx⋅p(x)。对于联合概率 p ( x , y ) = p ( x ) p ( y ∣ x ) p(x,y) = p(x)p(y|x) p(x,y)=p(x)p(y∣x),奖励期望:
E r ( x , y ) = ∑ x ∑ y p ( x ) p ( y ∣ x ) ⋅ r ( x , y ) \mathbb{E}r(x,y) = \sum_x \sum_y p(x)p(y|x) \cdot r(x,y) Er(x,y)=x∑y∑p(x)p(y∣x)⋅r(x,y)
推导贝尔曼方程
把递推公式 G t = R t + γ G t + 1 G_t = R_t + \gamma G_{t+1} Gt=Rt+γGt+1 代入状态价值函数:
v π ( s ) = E π G t ∣ S t = s = E π R t + γ G t + 1 ∣ S t = s = E π R t ∣ S t = s + γ E π G t + 1 ∣ S t = s \begin{aligned} v_\pi(s) &= \mathbb{E}\piG_t \\mid S_t = s \\ &= \mathbb{E}\piR_t + \\gamma G_{t+1} \\mid S_t = s \\ &= \mathbb{E}\piR_t \\mid S_t = s + \gamma \mathbb{E}\piG_{t+1} \\mid S_t = s \end{aligned} vπ(s)=EπGt∣St=s=EπRt+γGt+1∣St=s=EπRt∣St=s+γEπGt+1∣St=s
分别推导两项。
第一项 E π R t ∣ S t = s \mathbb{E}_\piR_t \\mid S_t = s EπRt∣St=s:考虑所有可能的动作和状态迁移,把概率和奖励乘起来求和:
E π R t ∣ S t = s = ∑ a ∑ s ′ π ( a ∣ s ) ⋅ p ( s ′ ∣ s , a ) ⋅ r ( s , a , s ′ ) \mathbb{E}\piR_t \\mid S_t = s = \sum_a \sum{s'} \pi(a|s) \cdot p(s'|s,a) \cdot r(s,a,s') EπRt∣St=s=a∑s′∑π(a∣s)⋅p(s′∣s,a)⋅r(s,a,s′)
第二项 γ E π G t + 1 ∣ S t = s \gamma \mathbb{E}_\piG_{t+1} \\mid S_t = s γEπGt+1∣St=s:
E π G t + 1 ∣ S t = s = ∑ a , s ′ π ( a ∣ s ) ⋅ p ( s ′ ∣ s , a ) ⋅ v π ( s ′ ) \mathbb{E}\piG_{t+1} \\mid S_t = s = \sum{a,s'} \pi(a|s) \cdot p(s'|s,a) \cdot v_\pi(s') EπGt+1∣St=s=a,s′∑π(a∣s)⋅p(s′∣s,a)⋅vπ(s′)
把两项合在一起,就得到了贝尔曼方程:
v π ( s ) = ∑ a , s ′ π ( a ∣ s ) ⋅ p ( s ′ ∣ s , a ) ⋅ { r ( s , a , s ′ ) + γ ⋅ v π ( s ′ ) } \boxed{ v_\pi(s) = \sum_{a,s'} \pi(a|s) \cdot p(s'|s,a) \cdot \left\{r(s,a,s') + \gamma \cdot v_\pi(s')\right\} } vπ(s)=a,s′∑π(a∣s)⋅p(s′∣s,a)⋅{r(s,a,s′)+γ⋅vπ(s′)}
这个方程说的是:当前状态的价值 = 所有可能的"动作→状态迁移"路径上,(即时奖励 + 打折后的下一状态价值)的期望。
它建立了状态 s s s 和下一个可能状态 s ′ s' s′ 之间的价值关系。对所有状态 s s s 和所有策略 π \pi π 都成立。
码住,此处应该加鸡腿🍗------贝尔曼方程是整个强化学习的基石,后面 PPO、RLHF 都是在这个基础上发展出来的。
CartPole 编程实践
理论讲完了,直接上手写代码。

环境搭建
🔨 环境选用:
bash
pip install gym==0.25.2
pip install pygame
pip install numpy创建倒立摆环境
python
import gym
env = gym.make('CartPole-v0')就这样,一个倒立摆环境就生成了。CartPole-v0 的上限是 200 步(v1 是 500 步)。
查看环境信息
python
state = env.reset() # 重置环境,获取初始状态
print(state) # [位置, 速度, 角度, 角速度]
action_space = env.action_space
print(action_space) # Discrete(2) → 两个动作:0=向左,1=向右💡 代码解析:输出是一个 4 维数组,对应推车的位置、速度、杆子的角度和角速度。动作空间是 Discrete(2),表示有两个离散动作可选。
采取一步动作
python
action = 0 # 0=向左推, 1=向右推
next_state, reward, done, info = env.step(action)env.step() 返回四个值:
| 返回值 | 含义 |
|---|---|
next_state |
下一个状态(4 维数组) |
reward |
奖励(float,保持平衡就得 1.0) |
done |
游戏是否结束(bool) |
info |
调试信息(一般不用) |
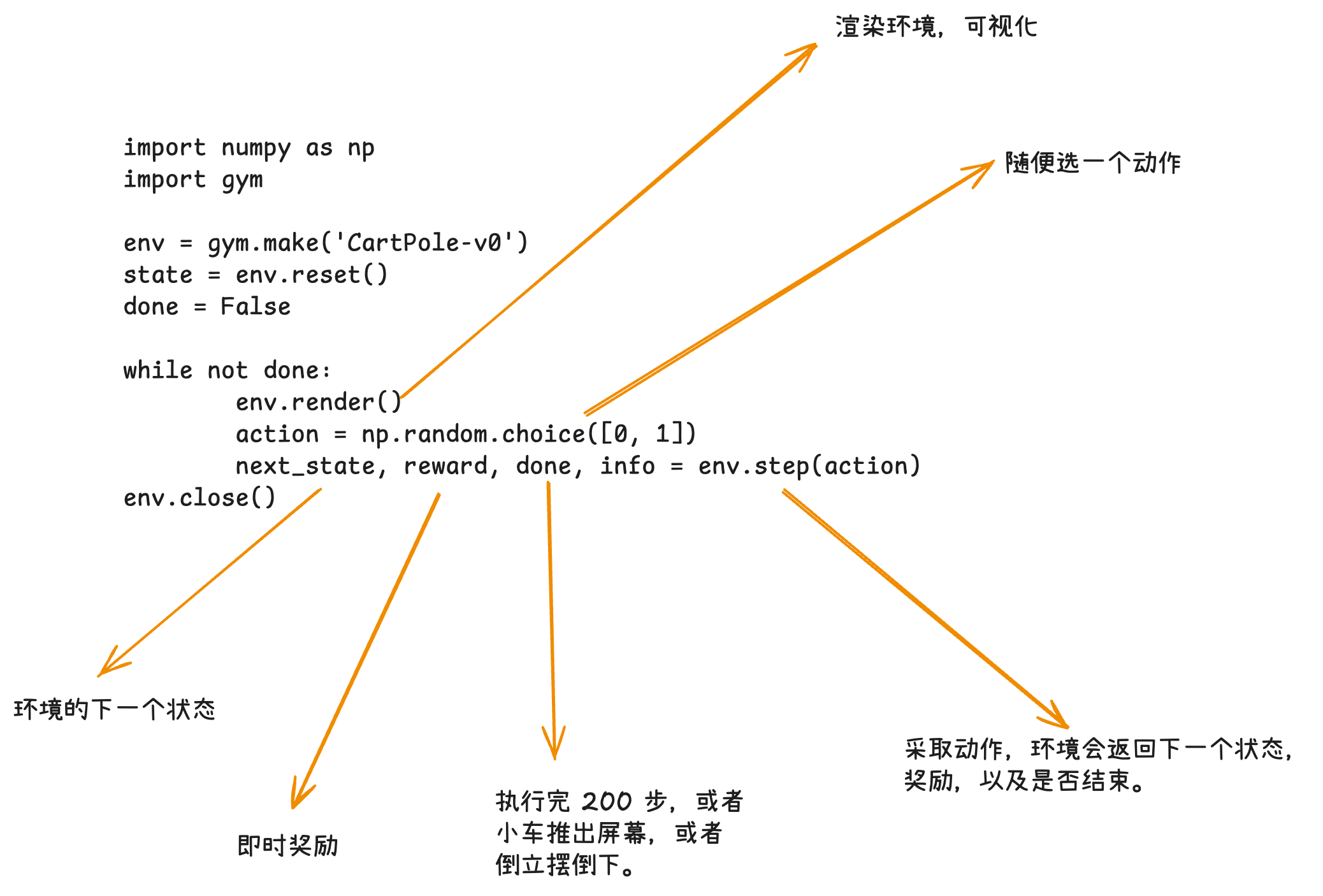
实现随机智能体
💬 参考代码:
python
import numpy as np
import gym
import time
env = gym.make('CartPole-v0')
state = env.reset()
done = False
action_desc = {0: "向左推", 1: "向右推"}
total_reward = 0.0
reward_list = []
gamma = 0.99
while not done:
env.render()
action = np.random.choice([0, 1])
next_state, reward, done, info = env.step(action)
print(f"采取动作:{action_desc.get(action, '未知')},"
f"获得奖励:{reward},下一个状态:{next_state}")
reward_list.append(reward)
time.sleep(0.1)💡 代码解析:这就是一个随机策略------没有任何学习能力,纯粹瞎推。倒立摆很快就会倒下。
计算回报(逆序法)
回报的计算有个巧妙的方法。从定义出发:
G t = R t + γ R t + 1 + γ 2 R t + 2 + ⋯ G_t = R_t + \gamma R_{t+1} + \gamma^2 R_{t+2} + \cdots Gt=Rt+γRt+1+γ2Rt+2+⋯
注意到递推关系 G t = R t + γ G t + 1 G_t = R_t + \gamma G_{t+1} Gt=Rt+γGt+1,所以从最后一个奖励开始倒着算:
python
total_reward = 0.0
for r in reward_list[::-1]: # 逆序遍历
total_reward = r + gamma * total_reward
print('回报(收益):', total_reward)
env.close()为什么逆序? 因为 G 3 = R 3 G_3 = R_3 G3=R3,然后 G 2 = R 2 + γ G 3 G_2 = R_2 + \gamma G_3 G2=R2+γG3, G 1 = R 1 + γ G 2 G_1 = R_1 + \gamma G_2 G1=R1+γG2......从后往前递推,每步只需一次加法和一次乘法。这其实是秦九韶算法 (也叫霍纳法则)的应用------把 a 0 + a 1 x + a 2 x 2 + ⋯ a_0 + a_1 x + a_2 x^2 + \cdots a0+a1x+a2x2+⋯ 变成嵌套形式 a 0 + x ( a 1 + x ( a 2 + ⋯ ) ) a_0 + x(a_1 + x(a_2 + \cdots)) a0+x(a1+x(a2+⋯)),减少重复计算。

由于用的是随机策略,倒立摆游戏很快就结束了,回报不会高。
总结
这篇文章做了三件事:
- MDP :用状态迁移概率 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a)、奖励函数 r ( s , a , s ′ ) r(s,a,s') r(s,a,s′)、策略 π ( a ∣ s ) \pi(a|s) π(a∣s) 三个要素,给强化学习搭了严格的数学框架
- 贝尔曼方程 :推导了 v π ( s ) = ∑ a , s ′ π ( a ∣ s ) p ( s ′ ∣ s , a ) { r ( s , a , s ′ ) + γ v π ( s ′ ) } v_\pi(s) = \sum_{a,s'} \pi(a|s)p(s'|s,a)\{r(s,a,s') + \gamma v_\pi(s')\} vπ(s)=∑a,s′π(a∣s)p(s′∣s,a){r(s,a,s′)+γvπ(s′)},建立了当前状态价值与下一状态价值的关系
- CartPole 编程:用随机策略跑了倒立摆环境,用逆序法计算回报,验证了理论推导
随机策略的表现当然很差------但它是个起点。下一篇开始,我们会让智能体真正学会做决策:用策略梯度法训练一个神经网络,让它从瞎推变成会推。

📌 笔者 文艺倾年
📃 更新 2026.06.13
❌ 勘误 /* 暂无 */
📜 声明 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!
