
👨💻程序员三明治 :个人主页
🔥 个人专栏 : 《设计模式精解》 《重学数据结构》
《AI探索日志》 《从0带你学深度强化学习》
🤞先做到 再看见!
目录
-
- 关键词检索的困境:为什么文本匹配不够用
-
- [1. 场景:在线教育课程预约知识库的检索难题](#1. 场景:在线教育课程预约知识库的检索难题)
- [2. 关键词匹配的三个典型问题](#2. 关键词匹配的三个典型问题)
-
- [2.1 同义表达问题](#2.1 同义表达问题)
- [2.2 一词多义问题](#2.2 一词多义问题)
- [2.3 上下文理解问题](#2.3 上下文理解问题)
- [3. RAG 需要的是语义检索,而不是字面匹配](#3. RAG 需要的是语义检索,而不是字面匹配)
- 向量:让计算机比较语义的一种方式
-
- [1. 什么是向量:用坐标表示含义](#1. 什么是向量:用坐标表示含义)
- [2. 从二维到高维:真实文本向量是什么样](#2. 从二维到高维:真实文本向量是什么样)
- [3. Embedding 的核心思想](#3. Embedding 的核心思想)
- [Embedding 模型:文本到向量的转换器](#Embedding 模型:文本到向量的转换器)
-
- [1. Embedding 模型做了什么](#1. Embedding 模型做了什么)
- [2. Embedding 模型选型时看什么](#2. Embedding 模型选型时看什么)
- [3. 常见 Embedding 模型对比](#3. 常见 Embedding 模型对比)
- [4. 中文课程知识库如何选型](#4. 中文课程知识库如何选型)
- [5. 向量维度怎么选](#5. 向量维度怎么选)
- 相似度计算:如何判断两个向量是否相近
-
- [1. 余弦相似度](#1. 余弦相似度)
- [2. 余弦相似度的计算逻辑](#2. 余弦相似度的计算逻辑)
- [3. Java 示例:手动计算余弦相似度](#3. Java 示例:手动计算余弦相似度)
- [4. 相似度分数怎么解读](#4. 相似度分数怎么解读)
- [5. 检索阈值怎么设](#5. 检索阈值怎么设)
- [6. 其他相似度度量方式](#6. 其他相似度度量方式)
- [动手实践:用通用 Embedding API 跑通向量化流程](#动手实践:用通用 Embedding API 跑通向量化流程)
-
- [1. 请求格式](#1. 请求格式)
- [2. 响应格式](#2. 响应格式)
- [3. Maven 依赖](#3. Maven 依赖)
- [4. EmbeddingClient 工具类](#4. EmbeddingClient 工具类)
- [5. 相似度工具类](#5. 相似度工具类)
- [6. 完整示例:从 chunk 到向量检索](#6. 完整示例:从 chunk 到向量检索)
- [7. 运行结果分析](#7. 运行结果分析)
- 实际项目中的关键决策
-
- [1. 云端 API vs 本地部署](#1. 云端 API vs 本地部署)
- [2. 什么时候选择云端 API](#2. 什么时候选择云端 API)
- [3. 什么时候选择本地部署](#3. 什么时候选择本地部署)
- [4. 抽象 EmbeddingClient,避免绑定具体平台](#4. 抽象 EmbeddingClient,避免绑定具体平台)
- 批量向量化的性能优化
-
- [1. 分批处理](#1. 分批处理)
- [2. 并发控制](#2. 并发控制)
- [3. 错误重试](#3. 错误重试)
- 向量化和元数据的关系
- 向量数据库中通常存什么
- 什么时候需要重新向量化
-
- [1. 更换 Embedding 模型](#1. 更换 Embedding 模型)
- [2. 文档内容更新](#2. 文档内容更新)
- [3. 分块策略调整](#3. 分块策略调整)
- [4. 模型版本升级](#4. 模型版本升级)
- 小结
上一篇文章讨论了元数据管理:如何给每个 chunk 补充来源、权限、课程类型、章节位置等信息,让它不再只是一段孤立文本,而是一段可以被追踪、过滤和管理的知识片段。
到这一步,知识库里的每个 chunk 已经有了清晰的上下文信息。但还有一个核心问题没有解决:这些内容仍然是自然语言,计算机并不能真正理解它们的含义。
比如系统需要比较下面两句话:
- "体验课开课前 24 小时可免费取消预约"
- "明天的试听课临时去不了怎么办?"
从字面上看,这两句话重合的词并不多。但任何一个人都能看出来,它们都在讨论"课程预约取消或改期"这件事。
问题是:怎样让计算机也能理解这种语义上的相似性?
答案是把文本转换成一组数字,也就是向量。这个转换过程,就叫向量化,也叫 Embedding。
关键词检索的困境:为什么文本匹配不够用
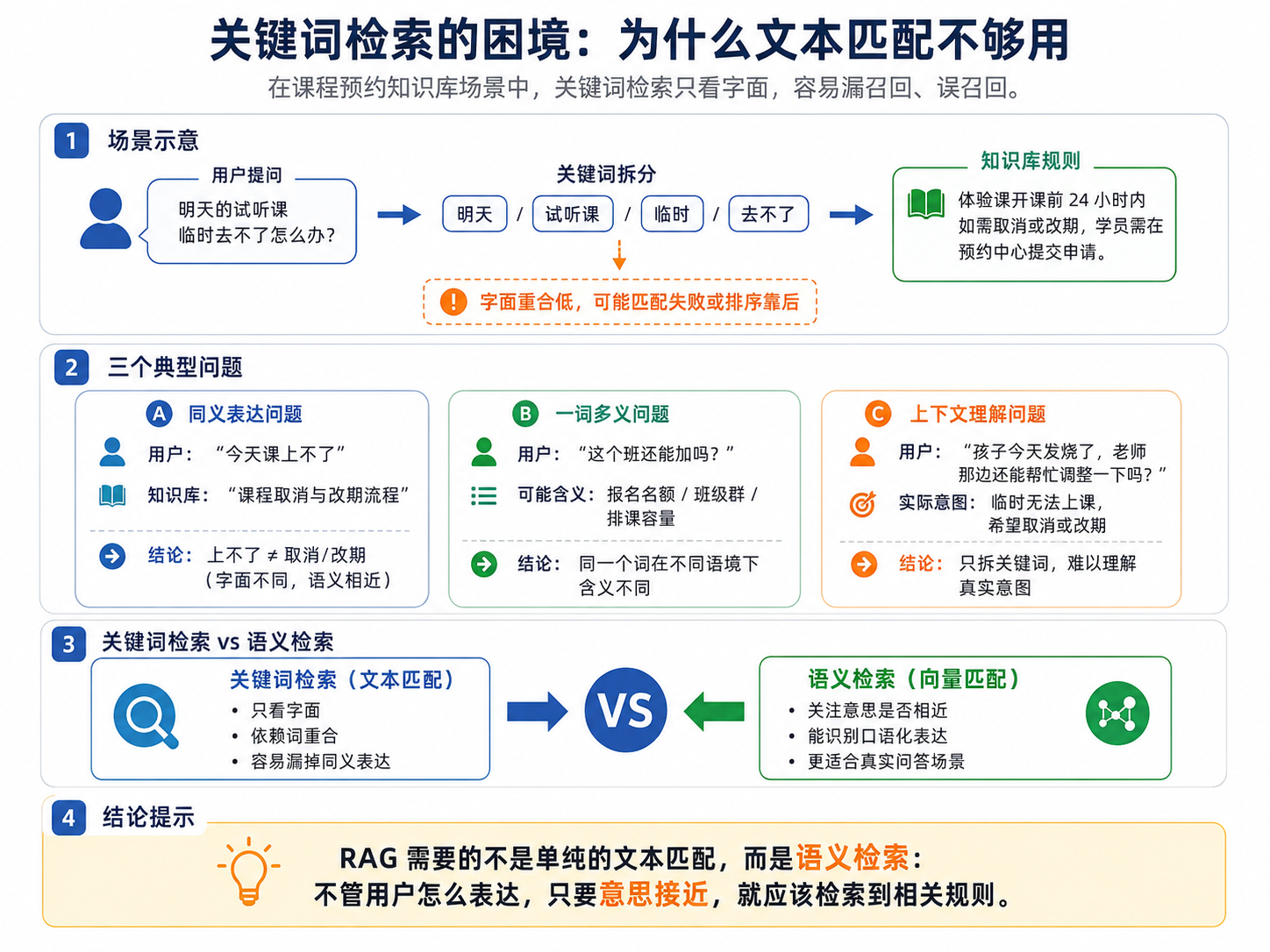
1. 场景:在线教育课程预约知识库的检索难题
假设一个在线教育平台维护了一套课程预约知识库,其中有这样一条规则:
体验课开课前 24 小时内如需取消或改期,学员需在预约中心提交申请,系统将根据教师档期重新安排上课时间。
现在用户问:
明天的试听课临时去不了怎么办?
如果使用传统关键词检索,例如 Elasticsearch 的全文搜索,系统通常会把用户问题拆成若干关键词:
plain
明天 / 试听课 / 临时 / 去不了然后再去知识库中查找包含这些关键词的文本块。
问题在于,知识库里的标准表达是:
plain
体验课 / 开课前 24 小时 / 取消 / 改期 / 教师档期用户说的是"试听课""去不了",知识库写的是"体验课""取消或改期"。两边语义接近,但字面重合度不高。关键词检索很可能找不到正确规则,或者把它排在较靠后的位置。
但从业务含义上看,这两句话明显讨论的是同一类问题。
2. 关键词匹配的三个典型问题
这个例子暴露的是关键词检索的共性问题。主要可以归纳为三类。
2.1 同义表达问题
用户口语化表达和知识库标准表达往往不同。
| 用户的说法 | 知识库的写法 | 关键词能否稳定匹配 |
|---|---|---|
| 今天课上不了 | 课程取消与改期流程 | 不稳定,"上不了"不等于"取消/改期" |
| 想换个老师 | 教师调整申请规则 | 不稳定,"换老师"不等于"教师调整" |
| 孩子错过直播怎么办 | 课程回放观看说明 | 不稳定,"错过直播"不等于"回放" |
| 还能补课吗 | 缺勤补课处理规则 | 不稳定,"补课"可能能匹配,但语义仍需判断 |
这些表达在用户咨询中非常常见,但纯关键词检索只能看字面,无法理解"上不了课"和"取消预约"之间的语义关系。
2.2 一词多义问题
同一个词在不同语境里可能代表完全不同的含义。
比如用户问:
这个班还能加吗?
这里的"班"可能指:
- 一个直播班级是否还能报名
- 某个课程班型是否还有名额
- 已报名学员是否能加入班级群
- 老师排课表里是否能插入新的课时
关键词检索只会返回包含"班"的文本,但无法判断用户真正想问的是"报名名额""班级群"还是"排课容量"。
再比如"余额"这个词,在在线教育场景里可能指账户余额、课时余额、优惠券余额,也可能指机构内部的结算余额。关键词检索很难仅凭字面完成语义区分。
2.3 上下文理解问题
有些问题需要理解整句话,而不是拆成几个词。
比如用户问:
孩子今天发烧了,老师那边还能帮忙调整一下吗?
关键词检索可能只看到"孩子""今天""老师""调整",然后匹配到教师介绍、课程安排、班主任服务等内容。
但这句话真正想表达的是:
学员因临时原因无法上课,希望取消或改期。
这类问题如果只靠关键词,系统很容易召回不相关内容。
3. RAG 需要的是语义检索,而不是字面匹配
关键词检索的问题,本质上是它只看文本表面,不理解语义。
一个可用的课程预约问答系统,需要具备语义检索能力:
- "试听课"和"体验课"意思接近,应该能匹配
- "去不了"和"取消/改期"语义相关,应该能匹配
- "课时余额"和"账户余额"虽然都包含"余额",但不能混在一起
- "孩子发烧了"虽然没出现"取消课程",但应能关联到课程调整规则
要实现这种能力,就需要先把文本转换成计算机可以比较语义的形式,也就是向量。
向量:让计算机比较语义的一种方式
向量听起来像一个数学概念,但在语义检索里,可以先把它理解成"文本在语义空间中的坐标"。
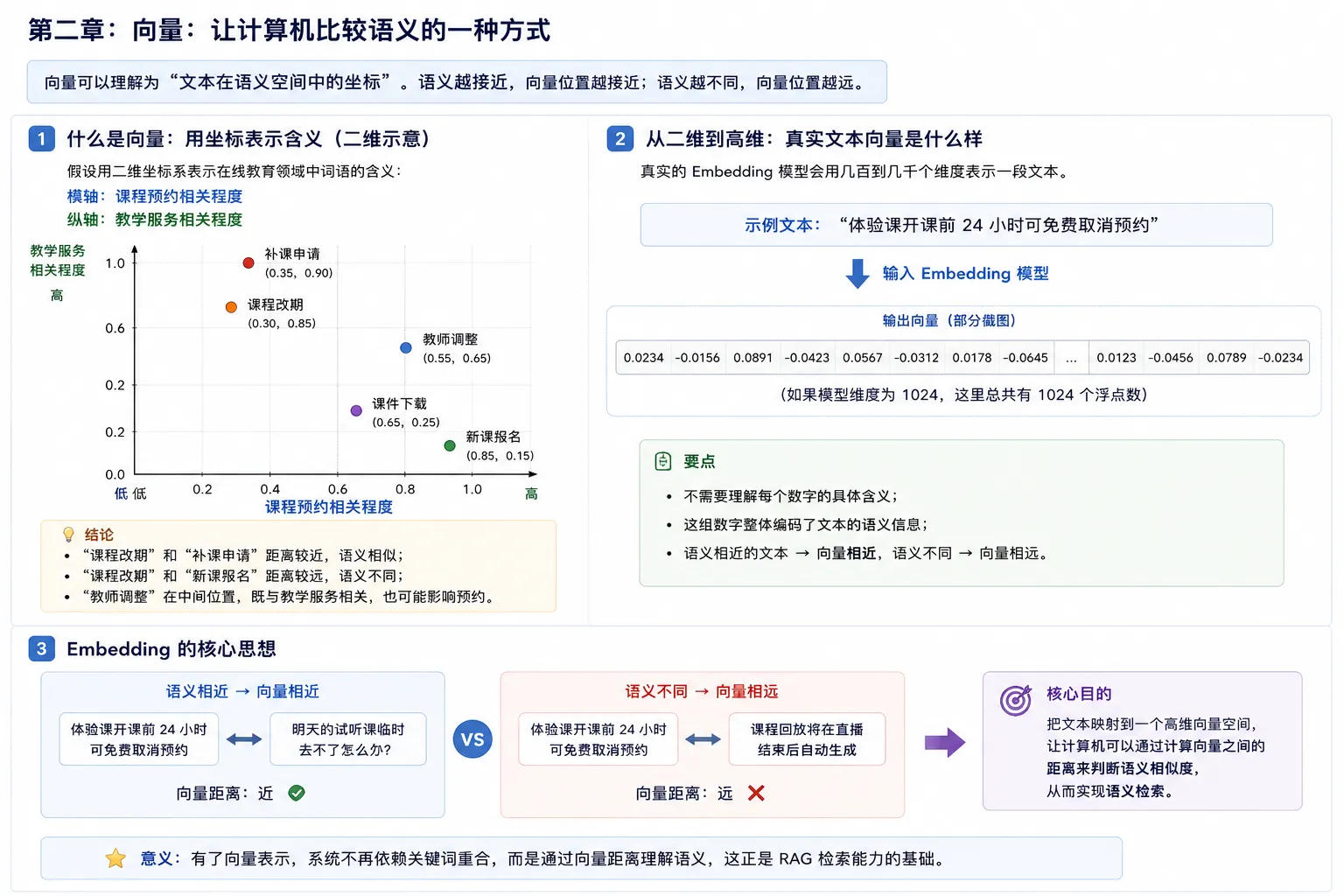
1. 什么是向量:用坐标表示含义
假设用一个二维坐标系来表示在线教育领域中的一些词语:
- 横轴表示"课程预约相关程度"
- 纵轴表示"教学服务相关程度"
plain
教学服务相关 ↑
|
1.0 | ● 补课申请(0.35, 0.90)
| ● 课程改期(0.30, 0.85)
0.8 |
|
0.6 | ● 教师调整(0.55, 0.65)
|
0.4 |
| ● 课件下载(0.65, 0.25)
0.2 |
| ● 新课报名(0.85, 0.15)
0.0 +-----|-----|-----|-----|---→ 课程预约相关
0 0.2 0.4 0.6 0.8 1.0在这个坐标系里:
- "课程改期"和"补课申请"距离较近,因为它们都和上课安排变化有关
- "课程改期"和"新课报名"距离较远,因为它们属于不同业务动作
- "教师调整"处在中间位置,既涉及教学服务,也可能影响预约安排
每个词或句子在坐标系中的位置,就是它的向量。向量本质上就是一组数字,用来表示文本的语义特征。
语义越接近,向量位置越接近;语义越不同,向量位置越远。
2. 从二维到高维:真实文本向量是什么样
上面的二维例子只是为了方便理解。真实语言的含义远比两个维度复杂,实际的 Embedding 模型通常会用几百到几千个维度来表示一段文本。
例如,把下面这句话送入 Embedding 模型:
plain
体验课开课前 24 小时可免费取消预约模型可能输出类似这样的向量:
plain
[0.0234, -0.0156, 0.0891, -0.0423, 0.0567, -0.0312, 0.0178, -0.0645,
0.0923, -0.0089, 0.0456, -0.0234, 0.0712, -0.0567, 0.0345, -0.0198,
... 省略若干维度 ...
0.0123, -0.0456, 0.0789, -0.0234]如果模型输出 1024 维,那么这段文本就会被表示成 1024 个浮点数。
不需要理解每一个数字具体代表什么。只需要知道:这组数字整体编码了这段文本的语义信息。两段语义相近的文本,它们对应的向量也会更接近。
3. Embedding 的核心思想
Embedding 的核心可以概括为一句话:
把文本映射到一个高维向量空间中,让语义相近的文本在空间中距离更近。
回到前面的例子:
- "体验课开课前 24 小时可免费取消预约"
- "明天的试听课临时去不了怎么办?"
这两句话字面不同,但语义接近,所以它们在向量空间中的距离应该比较近。
而下面这句话:
plain
课程回放将在直播结束后自动生成虽然同样属于在线教育业务,但主题是回放,不是取消预约,因此它和"试听课临时去不了"的距离应该更远。
有了向量表示,系统就不再只依赖关键词,而是可以比较语义距离。这正是 RAG 检索阶段的重要基础。
Embedding 模型:文本到向量的转换器
知道了向量是什么,接下来需要解决另一个问题:谁来把文本变成向量?
答案就是 Embedding 模型。
1. Embedding 模型做了什么
Embedding 模型的工作非常明确:
plain
输入:一段文本
输出:一组浮点数向量可以把它理解成一种"语义翻译器"。普通翻译器把中文翻成英文,而 Embedding 模型把自然语言翻译成计算机可以比较的数字表示。
它有几个关键特性。
第一,输入长度有限制。每个模型都有最大输入 token 数,超过限制的文本会被截断或无法处理。这也是 RAG 系统需要分块的原因之一:长文档必须先切成较小的 chunk,再送入模型。
第二,输出维度固定。同一个模型输出的向量维度是固定的。例如某个模型输出 1024 维,那么无论输入是一句话还是一段话,输出都是 1024 个浮点数。
第三,同一模型生成的向量才能直接比较。模型 A 和模型 B 的向量空间通常不兼容。即使两个模型都输出 1024 维,也不能假设它们可以混合计算相似度。
这一点非常重要:
数据入库阶段用什么 Embedding 模型处理 chunk,查询阶段就必须用同一个模型处理用户 query。
换模型通常意味着所有已入库向量都要重新生成。
2. Embedding 模型选型时看什么
实际项目中,Embedding 模型很多,不能只看模型名字。通常需要关注以下指标。
| 指标 | 含义 | 为什么重要 |
|---|---|---|
| 向量维度 | 输出向量包含多少个浮点数 | 维度越高,表达能力通常越强,但存储和检索成本也越高 |
| 最大输入 token 数 | 单次可处理的最大文本长度 | 决定 chunk 最大长度和截断风险 |
| 中文效果 | 对中文语义、口语表达、业务术语的理解能力 | 中文知识库必须重点关注 |
| 调用成本 | API 或本地推理成本 | 大规模向量化时成本差异明显 |
| 部署方式 | 云端 API 或本地部署 | 影响数据安全、延迟、运维成本 |
| 生态兼容性 | 是否兼容常见向量库和 OpenAI 风格接口 | 影响工程接入成本 |
3. 常见 Embedding 模型对比
下面是一些常见模型的选型维度示例。实际项目中还需要结合最新版本、服务稳定性和业务评测结果来决定。
| 模型 | 提供方 | 常见向量维度 | 常见输入长度 | 中文效果 | 部署方式 | 适用说明 |
|---|---|---|---|---|---|---|
| text-embedding-3-small | OpenAI | 1536 | 8191 左右 | 中等 | 云端 API | 成本较低,适合英文或多语言通用场景 |
| text-embedding-3-large | OpenAI | 3072 | 8191 左右 | 中等 | 云端 API | 精度更高,成本也更高 |
| text-embedding-v3 | 通义系列 | 1024/768 等 | 8192 左右 | 较好 | 云端 API | 中文知识库常见选择 |
| BGE-large-zh | BAAI | 1024 | 512 左右 | 较好 | 本地/API | 中文效果稳定,适合较短文本 |
| BGE-M3 | BAAI | 1024 | 8192 左右 | 较好 | 本地/API | 多语言、多粒度场景常用 |
| Qwen3-Embedding 系列 | 通义系列 | 取决于具体版本 | 较长上下文 | 较好 | 本地/API | 适合中文和长文本场景 |
| GTE-large-zh | 通义系列 | 1024 | 8192 左右 | 较好 | 本地/API | 中文检索任务常见选择 |
4. 中文课程知识库如何选型
如果系统主要处理中文文本,例如课程预约规则、教师排课说明、课时消耗规则、学员服务手册,可以按下面思路选型。
如果项目处在验证阶段,数据量不大,可以优先选择云端 API。这样可以快速跑通效果,不需要准备 GPU 环境。
如果项目已经进入生产阶段,并且涉及用户咨询记录、学员信息、内部排课规则等敏感数据,则需要优先考虑本地部署或私有化部署。
如果内容以中文为主,建议优先选择中文语义效果较好的模型,并用自己的业务数据做评测。不要只看通用榜单,因为课程预约场景里存在大量业务表达,例如"约课""排课""改期""课消""冻结课时"等,这些词在通用语料中的含义未必和业务语义完全一致。
5. 向量维度怎么选
向量维度可以理解成"描述文本语义时使用了多少个特征"。
维度越高,理论上可以表达更丰富的信息,但存储成本、内存占用和检索计算成本也会增加。
| 维度范围 | 适用场景 | 100 万条向量的粗略存储成本 |
|---|---|---|
| 256~512 | 文本较短、业务分类较少、精度要求一般 | 约 1~2 GB |
| 768~1024 | 大多数中文 RAG 生产场景 | 约 3~4 GB |
| 1536~4096 | 对召回精度要求较高、语义差异细微的场景 | 约 6~16 GB |
对于大多数在线教育知识库,768 到 1024 维通常是比较稳妥的选择。它能提供较好的语义区分能力,同时存储和检索成本也相对可控。
如果场景对准确率要求极高,例如合同条款检索、医学教育内容审核、强监管考试题库检索,才更有必要考虑更高维度的模型,并配合重排序模型进一步提升结果质量。

相似度计算:如何判断两个向量是否相近
文本变成向量之后,就可以比较它们之间的相似程度。
在 RAG 检索中,典型流程是:
plain
用户问题 → 转成 query 向量 → 与知识库 chunk 向量比较 → 找出最相似的 Top-K chunk这个"比较"过程,就需要相似度计算。
1. 余弦相似度
Embedding 检索中最常用的度量方式之一是余弦相似度。
可以把每个向量想象成从原点出发的一支箭头。余弦相似度关注的是两支箭头的方向是否接近。
plain
方向接近:语义相似度高
方向差异大:语义相似度低
方向相反:语义可能相反或差异很大理论上,余弦相似度的取值范围是 [-1, 1]:
- 接近 1:方向高度一致,语义高度相似
- 接近 0:方向接近垂直,语义相关性弱
- 接近 -1:方向相反,语义差异极大
在实际 Embedding 检索中,很多模型和向量库会对向量做归一化处理,因此常见分数更多集中在 0 到 1 之间。
2. 余弦相似度的计算逻辑
余弦相似度的计算可以拆成三步:
- 计算两个向量的点积
- 分别计算两个向量的模
- 用点积除以两个模的乘积
公式不需要死记,但理解这个过程有助于后面读代码。
3. Java 示例:手动计算余弦相似度
下面保留 Java 语言,但将方法名和变量名改成 snake_case 风格。
java
public class CosineSimilarity {
/**
* 计算两个向量的余弦相似度
*
* @param vector_a 向量 A
* @param vector_b 向量 B
* @return 余弦相似度,理论范围为 [-1.0, 1.0]
*/
public static double calculate_similarity(double[] vector_a, double[] vector_b) {
if (vector_a.length != vector_b.length) {
throw new IllegalArgumentException(
"两个向量的维度必须相同,vector_a: "
+ vector_a.length + ", vector_b: " + vector_b.length
);
}
double dot_product = 0.0;
double norm_a = 0.0;
double norm_b = 0.0;
for (int i = 0; i < vector_a.length; i++) {
dot_product += vector_a[i] * vector_b[i];
norm_a += vector_a[i] * vector_a[i];
norm_b += vector_b[i] * vector_b[i];
}
norm_a = Math.sqrt(norm_a);
norm_b = Math.sqrt(norm_b);
if (norm_a == 0 || norm_b == 0) {
return 0.0;
}
return dot_product / (norm_a * norm_b);
}
public static void main(String[] args) {
// 模拟三个文本的向量。真实项目中维度通常是 768、1024 或更高。
double[] cancel_rule = {0.8, 0.1, 0.9, 0.2, 0.7};
double[] cancel_query = {0.75, 0.15, 0.85, 0.25, 0.65};
double[] material_rule = {0.1, 0.9, 0.2, 0.8, 0.1};
double sim_1 = calculate_similarity(cancel_rule, cancel_query);
double sim_2 = calculate_similarity(cancel_rule, material_rule);
System.out.println("「体验课可取消预约」vs「明天试听课去不了」:"
+ String.format("%.4f", sim_1));
System.out.println("「体验课可取消预约」vs「课件下载说明」:"
+ String.format("%.4f", sim_2));
}
}可能输出:
plain
「体验课可取消预约」vs「明天试听课去不了」:0.9972
「体验课可取消预约」vs「课件下载说明」:0.5765这说明语义接近的两段文本相似度更高,不相关文本的相似度更低。
这里的向量只是为了演示手写的模拟数据。真实系统中,向量由 Embedding 模型生成,但相似度计算逻辑是一致的。
4. 相似度分数怎么解读
相似度分数没有绝对统一的标准,不同模型、不同数据集、不同向量库的分布都可能不同。下面只是经验参考。
| 相似度范围 | 可能含义 | 在线教育场景示例 |
|---|---|---|
| 0.9~1.0 | 高度相关,几乎同义 | "取消体验课"和"试听课去不了" |
| 0.7~0.9 | 明显相关,主题一致 | "课程改期"和"临时换上课时间" |
| 0.5~0.7 | 有一定关联,但需要进一步判断 | "补课规则"和"课程服务说明" |
| 0.3~0.5 | 关联较弱 | "课程改期"和"课程详情页展示" |
| 0.0~0.3 | 基本无关 | "课程预约"和"系统登录验证码" |
5. 检索阈值怎么设
在 RAG 系统中,通常有两种常见做法:
第一种是设置阈值,只返回相似度高于某个分数的结果。例如只返回大于 0.6 的 chunk。
第二种是不设固定阈值,只取 Top-K。例如每次返回最相似的前 5 条。
生产中更常见的是组合策略:
plain
先取 Top-K,例如 Top-5
再过滤低于阈值的结果,例如过滤掉低于 0.6 的 chunk这样既能保证召回,又能减少明显不相关内容进入后续 LLM 生成环节。
不过阈值不能照搬。换了模型、换了数据、换了 chunk 策略,分数分布都可能变化。因此阈值需要通过业务样本评测来调。
6. 其他相似度度量方式
除了余弦相似度,还有两种常见方式。
| 度量方式 | 核心思想 | 与余弦相似度的区别 | 常见使用场景 |
|---|---|---|---|
| 欧氏距离 | 计算两个向量之间的直线距离 | 值越小越相似,受向量长度影响 | 向量已归一化时可用 |
| 点积 | 对应维度相乘后求和 | 值越大越相似,同时受方向和长度影响 | 向量已归一化时常与余弦相似度等价 |
如果没有明确经验,优先使用余弦相似度通常更稳妥,因为它对向量长度不敏感,适用范围较广。

动手实践:用通用 Embedding API 跑通向量化流程
下面用一个通用的 OpenAI-compatible Embedding API 作为示例。它可以是云端模型服务,也可以是企业内部封装的模型网关。
为了降低业务耦合,代码中不写死具体平台,而是通过环境变量配置:
plain
EMBEDDING_API_URL
EMBEDDING_API_KEY
EMBEDDING_MODEL这样以后从云端 API 切换到本地部署,只需要改配置,不需要重写业务代码。
1. 请求格式
示例请求:
bash
curl -X POST "$EMBEDDING_API_URL" \
-H "Authorization: Bearer $EMBEDDING_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "BAAI/bge-m3",
"input": ["体验课开课前 24 小时可免费取消预约"],
"encoding_format": "float"
}'关键字段说明:
| 字段 | 含义 |
|---|---|
| model | 使用哪个 Embedding 模型 |
| input | 待向量化文本,可以是字符串,也可以是字符串数组 |
| encoding_format | 返回向量格式,float 表示浮点数组 |
2. 响应格式
响应通常类似:
json
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [0.0123, -0.0456, 0.0789]
}
],
"model": "BAAI/bge-m3",
"usage": {
"prompt_tokens": 8,
"total_tokens": 8
}
}data 数组中的每个元素对应 input 中的一段文本。真正需要保存的是 embedding 字段,它是一组浮点数。
3. Maven 依赖
Java 11 以后自带 HttpClient,这里只需要额外引入 Jackson 解析 JSON。
xml
<dependencies>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.17.0</version>
</dependency>
</dependencies>4. EmbeddingClient 工具类
java
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class EmbeddingClient {
private final String api_url;
private final String api_key;
private final String model_name;
private final HttpClient http_client;
private final ObjectMapper object_mapper;
public EmbeddingClient(String api_url, String api_key, String model_name) {
this.api_url = api_url;
this.api_key = api_key;
this.model_name = model_name;
this.http_client = HttpClient.newHttpClient();
this.object_mapper = new ObjectMapper();
}
/**
* 将多段文本批量转成向量
*
* @param texts 待向量化文本列表
* @return 每段文本对应的向量
*/
public List<double[]> embed_texts(List<String> texts) throws Exception {
Map<String, Object> request_body = new HashMap<>();
request_body.put("model", model_name);
request_body.put("input", texts);
request_body.put("encoding_format", "float");
String json_body = object_mapper.writeValueAsString(request_body);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(api_url))
.header("Authorization", "Bearer " + api_key)
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(json_body))
.build();
HttpResponse<String> response = http_client.send(
request,
HttpResponse.BodyHandlers.ofString()
);
if (response.statusCode() != 200) {
throw new RuntimeException(
"Embedding API 调用失败,状态码:" + response.statusCode()
+ ",响应:" + response.body()
);
}
JsonNode root_node = object_mapper.readTree(response.body());
JsonNode data_array = root_node.get("data");
List<double[]> embeddings = new ArrayList<>();
for (JsonNode item_node : data_array) {
JsonNode embedding_node = item_node.get("embedding");
double[] vector = new double[embedding_node.size()];
for (int i = 0; i < embedding_node.size(); i++) {
vector[i] = embedding_node.get(i).asDouble();
}
embeddings.add(vector);
}
return embeddings;
}
/**
* 将单段文本转成向量
*/
public double[] embed_text(String text) throws Exception {
return embed_texts(List.of(text)).get(0);
}
}这段代码的核心流程是:
plain
构造请求体 → 发送 HTTP POST → 解析 JSON → 提取 embedding 数组5. 相似度工具类
java
public class CosineSimilarity {
public static double calculate_similarity(double[] vector_a, double[] vector_b) {
if (vector_a.length != vector_b.length) {
throw new IllegalArgumentException("向量维度不一致");
}
double dot_product = 0.0;
double norm_a = 0.0;
double norm_b = 0.0;
for (int i = 0; i < vector_a.length; i++) {
dot_product += vector_a[i] * vector_b[i];
norm_a += vector_a[i] * vector_a[i];
norm_b += vector_b[i] * vector_b[i];
}
norm_a = Math.sqrt(norm_a);
norm_b = Math.sqrt(norm_b);
if (norm_a == 0 || norm_b == 0) {
return 0.0;
}
return dot_product / (norm_a * norm_b);
}
}6. 完整示例:从 chunk 到向量检索
下面构造一个课程预约知识库示例。先对所有 chunk 做向量化,再对用户问题做向量化,最后计算相似度并排序。
java
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class EmbeddingSearchDemo {
public static void main(String[] args) throws Exception {
String api_url = System.getenv("EMBEDDING_API_URL");
String api_key = System.getenv("EMBEDDING_API_KEY");
String model_name = System.getenv("EMBEDDING_MODEL");
EmbeddingClient client = new EmbeddingClient(api_url, api_key, model_name);
List<Map<String, Object>> chunks = new ArrayList<>();
chunks.add(Map.of(
"content", "体验课开课前 24 小时内如需取消或改期,学员需在预约中心提交申请,系统将根据教师档期重新安排上课时间。",
"metadata", Map.of("doc_id", "course_policy_001", "title", "体验课预约规则")
));
chunks.add(Map.of(
"content", "正式课临时请假后,系统会根据班型规则判断是否消耗课时,具体以课程服务协议为准。",
"metadata", Map.of("doc_id", "course_policy_002", "title", "请假与课时规则")
));
chunks.add(Map.of(
"content", "直播课结束后,课程回放通常会在 2 小时内生成,学员可在学习中心查看。",
"metadata", Map.of("doc_id", "learning_guide_001", "title", "课程回放说明")
));
chunks.add(Map.of(
"content", "优惠券可在报名结算时抵扣部分课程费用,单笔订单仅支持使用一张优惠券。",
"metadata", Map.of("doc_id", "payment_guide_001", "title", "优惠券使用说明")
));
chunks.add(Map.of(
"content", "一对一课程支持根据教师可用时间进行改期,但距离开课不足 2 小时的预约可能无法调整。",
"metadata", Map.of("doc_id", "course_policy_003", "title", "一对一课程改期规则")
));
List<String> chunk_texts = new ArrayList<>();
for (Map<String, Object> chunk : chunks) {
chunk_texts.add((String) chunk.get("content"));
}
System.out.println("正在向量化 " + chunk_texts.size() + " 个 chunks...");
List<double[]> chunk_vectors = client.embed_texts(chunk_texts);
System.out.println("向量化完成,向量维度:" + chunk_vectors.get(0).length);
String query_text = "明天的试听课临时去不了怎么办?";
System.out.println("\n用户提问:" + query_text);
double[] query_vector = client.embed_text(query_text);
List<Map<String, Object>> results = new ArrayList<>();
for (int i = 0; i < chunks.size(); i++) {
double similarity = CosineSimilarity.calculate_similarity(
query_vector,
chunk_vectors.get(i)
);
Map<String, Object> result = new HashMap<>();
result.put("index", i);
result.put("content", chunks.get(i).get("content"));
result.put("metadata", chunks.get(i).get("metadata"));
result.put("similarity", similarity);
results.add(result);
}
results.sort((a, b) -> Double.compare(
(double) b.get("similarity"),
(double) a.get("similarity")
));
System.out.println("\n--- 相似度排名 ---");
for (int i = 0; i < results.size(); i++) {
Map<String, Object> result = results.get(i);
Map<String, Object> metadata = (Map<String, Object>) result.get("metadata");
System.out.printf(
"Top-%d [相似度: %.4f] [来源: %s]%n",
i + 1,
(double) result.get("similarity"),
metadata.get("title")
);
System.out.println(" 内容: " + result.get("content"));
System.out.println();
}
}
}7. 运行结果分析
可能输出类似:
plain
正在向量化 5 个 chunks...
向量化完成,向量维度:1024
用户提问:明天的试听课临时去不了怎么办?
--- 相似度排名 ---
Top-1 [相似度: 0.7921] [来源: 体验课预约规则]
内容: 体验课开课前 24 小时内如需取消或改期,学员需在预约中心提交申请,系统将根据教师档期重新安排上课时间。
Top-2 [相似度: 0.7384] [来源: 一对一课程改期规则]
内容: 一对一课程支持根据教师可用时间进行改期,但距离开课不足 2 小时的预约可能无法调整。
Top-3 [相似度: 0.6815] [来源: 请假与课时规则]
内容: 正式课临时请假后,系统会根据班型规则判断是否消耗课时,具体以课程服务协议为准。
Top-4 [相似度: 0.4297] [来源: 课程回放说明]
内容: 直播课结束后,课程回放通常会在 2 小时内生成,学员可在学习中心查看。
Top-5 [相似度: 0.3152] [来源: 优惠券使用说明]
内容: 优惠券可在报名结算时抵扣部分课程费用,单笔订单仅支持使用一张优惠券。这个排序符合直觉:
- 用户问"试听课临时去不了",最相关的是体验课取消或改期规则
- 一对一课程改期规则也相关,但业务范围更窄,所以排在第二
- 请假与课时规则和"无法上课"有关,但不一定直接回答体验课问题
- 回放说明、优惠券说明和问题关系较弱,因此排名靠后
需要注意的是:语义相似不等于最终答案正确。
例如"一对一课程改期规则"可能和用户问题相似,但如果用户问的是"体验课",最终回答仍应优先引用体验课规则。RAG 系统通常会把这些候选 chunk 交给 LLM,再结合上下文生成最终答案。
实际项目中的关键决策
跑通 demo 只是第一步。生产环境中,还需要考虑模型部署方式、批量处理、错误重试、元数据过滤和重新向量化等问题。
1. 云端 API vs 本地部署
| 对比维度 | 云端 API | 本地部署 |
|---|---|---|
| 部署成本 | 接入快,基本不需要维护模型服务 | 需要 GPU 或高性能推理环境 |
| 使用成本 | 按 token 或调用量计费 | 硬件折旧、电费和运维成本 |
| 延迟 | 受网络和平台稳定性影响 | 内网调用,延迟更可控 |
| 数据安全 | 文本需要发送到外部服务 | 数据不出内网,安全性更高 |
| 模型维护 | 平台负责升级和运维 | 需要团队自行维护 |
| 切换灵活性 | 平台内模型切换方便 | 需要下载、部署和测试模型 |
2. 什么时候选择云端 API
适合以下情况:
- 项目处于早期验证阶段
- 知识库数据量不大
- 团队暂时没有 GPU 或模型运维能力
- 数据安全要求不高,例如内容主要是公开课程介绍
云端 API 的优势是快,适合快速验证"语义检索是否有效"。
3. 什么时候选择本地部署
适合以下情况:
- 每天需要处理大量课程文档、咨询记录或学习资料
- 数据包含学员信息、内部排课规则、教师资料等敏感内容
- 对延迟要求较高
- 需要长期控制调用成本
- 企业有模型部署和运维能力
本地部署前期成本更高,但在数据安全和长期成本方面通常更可控。
4. 抽象 EmbeddingClient,避免绑定具体平台
无论使用云端 API 还是本地服务,都建议把向量化能力封装在一个独立的客户端中。
业务代码只依赖:
plain
输入文本 → 返回向量不要让业务层感知具体平台、请求格式和鉴权方式。这样后续从云端切换到本地,或者从模型 A 切换到模型 B,改动范围会更小。
批量向量化的性能优化
demo 中只有 5 个 chunk,可以一次性发送给 API。但真实课程知识库可能有几万、几十万甚至更多 chunk。
这时不能简单地一次性提交全部文本,也不能一个一个串行提交。需要考虑分批、并发和重试。
1. 分批处理
最基本的优化方式是把 chunk 按固定大小分批处理。
java
import java.util.ArrayList;
import java.util.List;
public class BatchEmbeddingService {
private final EmbeddingClient embedding_client;
public BatchEmbeddingService(EmbeddingClient embedding_client) {
this.embedding_client = embedding_client;
}
/**
* 分批向量化
*
* @param texts 所有待向量化文本
* @param batch_size 每批大小,建议从 20~50 开始压测
* @return 所有文本对应的向量
*/
public List<double[]> embed_in_batches(List<String> texts, int batch_size) throws Exception {
List<double[]> all_embeddings = new ArrayList<>();
for (int i = 0; i < texts.size(); i += batch_size) {
int end_index = Math.min(i + batch_size, texts.size());
List<String> batch_texts = texts.subList(i, end_index);
System.out.printf("向量化进度:%d/%d%n", end_index, texts.size());
List<double[]> batch_embeddings = embedding_client.embed_texts(batch_texts);
all_embeddings.addAll(batch_embeddings);
if (end_index < texts.size()) {
Thread.sleep(200);
}
}
return all_embeddings;
}
}分批大小需要结合模型服务限制来调。批次太小,请求次数多;批次太大,可能触发请求体大小限制或超时。
2. 并发控制
如果 API 或本地服务支持并发,可以使用线程池提高吞吐量。
java
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class ConcurrentEmbeddingService {
private final EmbeddingClient embedding_client;
public ConcurrentEmbeddingService(EmbeddingClient embedding_client) {
this.embedding_client = embedding_client;
}
/**
* 并发批量向量化
*
* @param texts 所有待向量化文本
* @param batch_size 每批大小
* @param max_concurrency 最大并发数
*/
public List<double[]> embed_concurrently(
List<String> texts,
int batch_size,
int max_concurrency
) throws Exception {
ExecutorService executor_service = Executors.newFixedThreadPool(max_concurrency);
List<Future<List<double[]>>> futures = new ArrayList<>();
for (int i = 0; i < texts.size(); i += batch_size) {
int start_index = i;
int end_index = Math.min(i + batch_size, texts.size());
List<String> batch_texts = texts.subList(start_index, end_index);
futures.add(executor_service.submit(() -> embedding_client.embed_texts(batch_texts)));
}
List<double[]> all_embeddings = new ArrayList<>();
for (Future<List<double[]>> future : futures) {
all_embeddings.addAll(future.get());
}
executor_service.shutdown();
return all_embeddings;
}
}并发数不要盲目设置过高。对于外部 API,过高并发容易触发 Rate Limit;对于本地模型服务,过高并发可能导致显存不足或排队延迟升高。
生产环境中建议通过压测确定合理参数,例如:
plain
batch_size = 32
max_concurrency = 3然后逐步调整。
3. 错误重试
向量化过程涉及网络请求或模型推理,失败是正常情况。生产系统需要重试机制。
java
import java.util.List;
public class RetryableEmbeddingService {
private final EmbeddingClient embedding_client;
public RetryableEmbeddingService(EmbeddingClient embedding_client) {
this.embedding_client = embedding_client;
}
/**
* 带重试的向量化方法
*/
public List<double[]> embed_with_retry(
List<String> texts,
int max_retries
) throws Exception {
Exception last_exception = null;
for (int attempt = 1; attempt <= max_retries; attempt++) {
try {
return embedding_client.embed_texts(texts);
} catch (Exception exception) {
last_exception = exception;
System.err.printf(
"第 %d 次向量化失败:%s,%s%n",
attempt,
exception.getMessage(),
attempt < max_retries ? "准备重试..." : "已达到最大重试次数"
);
if (attempt < max_retries) {
long sleep_millis = 1000L * (1L << (attempt - 1));
Thread.sleep(sleep_millis);
}
}
}
throw new RuntimeException(
"向量化失败,已重试 " + max_retries + " 次",
last_exception
);
}
}这里使用的是指数退避:
plain
第 1 次失败后等待 1 秒
第 2 次失败后等待 2 秒
第 3 次失败后等待 4 秒这样可以避免在服务短暂抖动时持续打满接口。
向量化和元数据的关系
这个问题在 RAG 系统中很容易被混淆。
一句话概括:
默认情况下,元数据不参与向量化,但会和向量一起存储。
例如课程知识库里的一个 chunk 可能长这样:
json
{
"id": "chunk_001",
"content": "体验课开课前 24 小时内如需取消或改期,学员需在预约中心提交申请。",
"metadata": {
"doc_id": "course_policy_001",
"title": "体验课预约规则",
"course_type": "trial_course",
"permission": "student_visible",
"updated_at": "2026-06-01"
}
}通常只把 content 送入 Embedding 模型生成向量,而 metadata 用于后续过滤、展示和追踪。
检索流程可以理解为:
plain
用户 query
↓
query 向量化
↓
向量数据库做相似度检索
↓
返回候选 chunks
↓
根据 metadata 做二次过滤
↓
返回最终结果例如:
- 只返回学员有权限查看的内容
- 只返回某个课程类型下的规则
- 只返回最近一年更新过的文档
- 只返回某个校区或业务线适用的内容
需要注意的是,有些系统会把标题、分类等重要元数据拼接进文本一起向量化。例如:
plain
标题:体验课预约规则
正文:体验课开课前 24 小时内如需取消或改期,学员需在预约中心提交申请。这种做法可以增强语义信息,但它已经不再是"元数据不参与向量化"的默认做法,而是显式把部分元数据变成了向量化文本的一部分。
向量数据库中通常存什么
每个 chunk 入库时,通常会保存以下内容。
| 字段 | 内容 | 作用 |
|---|---|---|
| id | chunk 唯一标识 | 用于更新、删除和追踪 |
| vector | Embedding 模型输出的向量 | 用于相似度检索 |
| text | 原始 chunk 文本 | 用于返回给 LLM 或展示 |
| metadata | JSON 格式元数据 | 用于过滤、权限控制和溯源 |
示例:
json
{
"id": "chunk_001",
"vector": [0.0123, -0.0456, 0.0789],
"text": "体验课开课前 24 小时内如需取消或改期,学员需在预约中心提交申请。",
"metadata": {
"doc_id": "course_policy_001",
"title": "体验课预约规则",
"course_type": "trial_course",
"permission": "student_visible",
"embedding_model": "BAAI/bge-m3",
"embedding_model_version": "v1"
}
}把原始文本也存入向量数据库,可以减少二次查询成本。否则系统检索到向量 id 后,还需要再去 MySQL、PostgreSQL 或对象存储中查原文。
什么时候需要重新向量化
向量化不是一次完成后永远不用管。以下情况都可能需要重新生成向量。
1. 更换 Embedding 模型
不同模型的向量空间通常不兼容。
如果从模型 A 切到模型 B,那么原来的 chunk 向量不能继续和新 query 向量混用。
plain
换模型 = 所有 chunk 重新向量化 + 旧向量替换或新旧索引并行灰度生产系统中可以考虑新旧索引并行:
plain
旧索引继续服务线上流量
新索引后台构建
小流量切到新索引验证效果
验证通过后全量切换2. 文档内容更新
如果课程规则发生变化,原始 chunk 的语义也变了,对应向量必须更新。
例如:
plain
原规则:体验课开课前 24 小时可免费取消
新规则:体验课开课前 12 小时可免费取消这不是简单的元数据变化,而是正文语义变化,因此需要重新向量化。
常见处理流程:
- 根据
doc_id找到旧文档下的所有 chunk - 删除旧 chunk 或标记为失效
- 对新文档重新分块
- 调用 Embedding 模型生成新向量
- 写入向量数据库
这也是为什么元数据里一定要有 doc_id。没有它,就很难知道哪些 chunk 属于同一份文档。
3. 分块策略调整
如果从"每 500 字一个 chunk,重叠 100 字"改成"每 300 字一个 chunk,重叠 50 字",chunk 内容发生了变化,向量也必须重新生成。
分块策略调整通常影响全量数据,因此成本较高。建议在项目早期通过样本评测尽量确定合理策略,避免频繁大规模重跑。
4. 模型版本升级
即使模型名称类似,不同版本生成的向量也可能不兼容。
例如从某个 embedding-v2 升级到 embedding-v3,需要查看模型说明,确认:
- 输出维度是否变化
- 向量是否归一化
- 新旧向量是否兼容
- 旧索引是否需要重建
一个实用建议是:在元数据中记录模型信息。
json
{
"embedding_model": "BAAI/bge-m3",
"embedding_model_version": "v1",
"embedding_dimension": 1024
}这样后续排查效果问题、做灰度切换或重建索引时,都会更方便。
小结
本文从课程预约知识库的检索问题出发,解释了为什么关键词匹配不足以支撑语义问答。
核心内容包括:
- 关键词检索只能看字面,难以处理同义表达、一词多义和上下文理解
- Embedding 可以把文本转换成向量,让语义相近的文本在向量空间中更接近
- Embedding 模型的选型需要关注中文效果、向量维度、输入长度、成本和部署方式
- 余弦相似度是常见的向量相似度度量方式,适合大多数语义检索场景
- Java 可以通过 HttpClient 直接调用通用 Embedding API,完成文本向量化
- 生产环境中需要考虑分批处理、并发控制、失败重试和限流策略
- 元数据默认不参与向量化,但会和向量一起存储,用于过滤、权限控制和溯源
- 换模型、改正文、调分块策略、升级模型版本,都可能需要重新向量化
到这里,RAG 的数据准备链路已经基本完整:
plain
原始文档 → 文档分块 → 元数据管理 → 文本向量化下一步需要解决的是:向量生成之后存到哪里?如何在几十万、几百万甚至更多向量中快速找到最相似的 Top-K?普通关系型数据库能不能承担这个任务?
这些问题就会引出下一部分内容:向量数据库。
如果我的内容对你有帮助,请辛苦动动您的手指为我点赞,评论,收藏。感谢大家!!
