假设我们有下面这个看起来简单的表达式:

其中 xx 和 yy 定义如下:
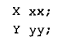
class Y 的定义是:

class X 的定义是:

很简单,对吧?好,我们来看看这个表达式到底是如何被处理的。
首先,我们需要确定实际使用的是哪个相等运算符实例。这里解析到了 Y 类重载的成员运算符。这是表达式的第一次转换:

Y 的相等运算符需要一个 Y 类型的参数。但 getValue() 返回的却是 X 类型的对象。那么,要么存在一种将 X 对象转换为 Y 对象的方法,否则表达式就是错误的。在本例中,X 提供了一个转换运算符,可以将 X 对象转换为 Y 对象。这个转换需要应用到 getValue() 的返回值上。这是表达式的第二次转换:

到目前为止,编译器所做的只是将表达式中隐含的类语义显式地加入到程序文本中。不过,如果我们愿意,也完全可以按这种形式直接写出表达式(不,我不是在推荐这么做,但这样做确实能让编译稍微快一点)。
虽然这段程序文本在语义上是正确的,但在指令层面还不正确。接下来,我们需要生成临时对象来保存函数调用的返回值:
1.生成一个 X 类型的临时对象,用于保存 getValue() 的返回值:
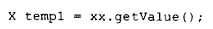
2.生成一个 Y 类型的临时对象,用于保存 operator Y() 的返回值:
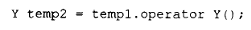
3.生成一个 int 类型的临时对象,用于保存相等运算符的返回值:
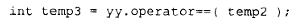
最后,语言要求我们对每个类类型的临时对象调用适当的析构函数。于是,上述条件表达式会被转换成下面这种形式:

哇,这可真不少东西。C++ 的难点之一就在于:光看源代码很难知道一个表达式背后有多复杂。本章我们将探讨一些发生在运行时的转换。关于临时对象的生成问题,我还会在第 6.3 节详细讨论。
6.1 对象的构造和结构(Object Construction and Destruction)
一般来说,构造函数和析构函数的插入位置正如你所料:

当代码块或函数存在多个出口时,情况会稍微复杂一些。析构函数必须放在对象"还活着"的每一个出口点上。例如:

在这个例子中,point 的析构函数必须在 switch 语句内部的四个出口点------每个 return 之前------生成。虽然在代码块末尾的右花括号之前通常也会生成析构函数,但分析该代码块可以发现,程序流程根本不可能从 switch 语句落到那个位置。
类似地,goto 语句的存在也可能需要多次调用析构函数。例如,下面这段代码:

析构函数调用必须分别放在最后两个 return 语句之前。最开头的那个 return 之前不需要调用析构函数,因为此时对象尚未定义。
一般而言,应尽量将对象定义在使用它的代码段附近。这样做可以避免不必要的对象创建和销毁------比如,如果我们把 Point 对象定义在检查缓存之前,就会多出不必要的开销。这个道理看起来不言自明,但许多从 Pascal 和 C 转过来的 C++ 程序员仍然习惯把所有对象定义在函数或局部代码块的开头。
全局对象(Global Objects)
如果我们有以下程序片段:

语言保证:identity 会在 main() 的第一条用户语句之前构造完成,并在 main() 的最后一条语句之后析构。像 identity 这样带有构造函数和析构函数的全局对象,被称为需要静态初始化和静态释放。
C++ 中所有全局可见的对象都被放在程序的数据段中。如果指定了显式的初始值,则对象用该值初始化;否则,与对象关联的内存被初始化为 0。因此,在下面的代码片段中:
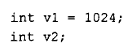
v1 和 v2 都被分配在程序的数据段内------v1 初值为 1024,v2 初值为 0(这与 C 语言不同,在 C 中 v2 被视为暂定性定义)。在 C 语言中,全局对象只能用常量表达式(即能够在编译期求值的表达式)来初始化。而构造函数显然不是常量表达式。尽管类对象在编译时可以被放入数据段并将其内存清零,但它的构造函数必须等到程序启动时才能执行。对于存储在程序数据段内的对象,需要对其初始化表达式进行求值------这就是所谓的静态初始化。
在 cfront 还是唯一 C++ 实现、跨平台可移植性比效率更重要的年代,他们提供了一种可移植但昂贵的静态初始化(及释放)方法,被亲切地称为 munch。cfront 受限于一个约束:它的解决方案必须能在所有 UNIX 平台上运行------从 Cray 到 VAX、Sun,再到 AT&T 短暂推出的 UNIX PC。它不能对运行环境中的链接编辑器或目标文件格式做任何假设。由于这一限制,下面这套 munch 策略应运而生:
1.在每个需要静态初始化的文件中,生成一个 __sti() 函数,其中包含必要的构造函数调用或内联展开。例如,identity 会导致在 matrix.c 文件中生成如下 __sti() 函数:

其中 __matrix_c 是文件名的编码,__identity 代表该文件中定义的第一个静态对象。将这两个名字附加到 __sti 后面,就可以在可执行文件中得到一个唯一标识符(Andy Koenig 和 Bjarne 为了应对 Jim Coplien 报告的名称冲突问题,设计了这个"伪静态"编码方案)。
2.类似地,在每个需要静态释放的文件中,生成一个 __std() 函数,其中包含必要的析构函数调用或内联展开。在我们的例子中,会生成一个 __std() 函数,用于对 identity 调用 Matrix 的析构函数。
3.提供一组运行时库中的 munch 函数:一个 _main() 函数,用于调用可执行文件中的所有 __sti() 函数;以及一个 exit() 函数,用于类似地调用所有 __std() 函数。
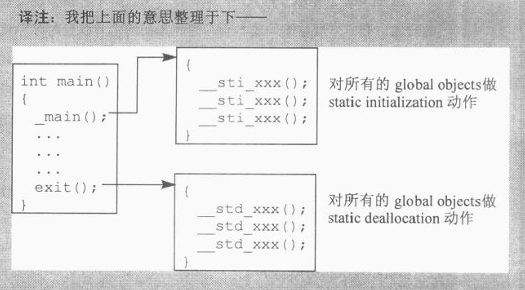
cfront 会将一个 _main() 调用作为第一条语句插入 main() 内部。链接时,cfront 的 CC 命令通过把 C++ 标准库放在命令行最前面,从而链接了自己的 exit() 函数,而不是 C 标准库的 exit()。(这套做法通常能工作,但每次把 cfront 移植到新平台时,仍然要祈祷并默念几句咒语,例如,惠普工作站的编译系统最初拒绝引入 munch 的 exit() 例程------原因我已经记不清了,只记得当时非常抓狂,抓狂是因为有用户发现他的静态析构函数根本没被调用)。
最后一个要解决的问题是:如何在可执行文件的各个目标文件中收集相关的 __sti() 和 __std() 函数。记住,这必须做到可移植------尽管当时的可移植性只限于运行 UNIX 的机器。你不妨想想该怎么解决这个问题。它在技术上并不难,但当时 cfront(以及 C++)能否成功分发,却依赖于此。
我们的解决方案是使用 nm 命令(nm 能转储目标文件中的符号表条目)。先用 .o 文件生成可执行文件,然后对得到的可执行文件运行 nm,输出结果再通过管道传给 munch 程序(我印象中是 Rob Murray 写的 munch,但现在已经没人记得清楚了)。munch 会处理这些符号表的名字,寻找以 __sti 或 __std 开头的名字(没错,我们偶尔会自娱自乐地以 __sti 开头定义一个函数,比如 __sti_ha_fooled_you)。然后它把这些函数名加入一个由 __sti() 和 __std() 函数组成的跳转表,再把该表写到一个小的程序文本文件中。接下来------听起来可能有点古怪------CC 命令会再次被调用,用来编译含有这个生成表的文件。最后把整个可执行文件重新链接。_main() 和 exit() 会遍历各自的表,依次调用表中的每一项。
这个方法确实能完成任务,但天哪,感觉离计算机科学实在太远了。在 Release 1.0 版本中,为 System V 实现了一个补丁方案,作为 munch 的快速替代品(我想是 Jerry Schwarz 实现的)。该补丁方案假定可执行文件采用 System V 的 COFF(通用目标文件格式)。它会检查可执行文件,找到那些包含指向 __sti() 和 __std() 函数指针的、每个文件特有的 __link 节点,并将它们链接起来。接着,该方案会将这些链表的头指向新的补丁运行时库中定义的一个全局 __head 对象。补丁库中包含了 _main() 和 exit() 的替代实现,它们会遍历以 __head 为起点的链表(移植时典型的坑是:编译 cfront 生成了补丁方案的输出,却在链接时用了 munch 库,我记得 Steve Johnson 离开贝尔实验室后把 cfront 移植到 Sun 工作站时就被这个问题坑过)。后来,针对 Sun、BSD 和 ELF 的替代补丁库由用户社区贡献出来,并整合到了各个 cfront 版本中。
一旦出现了针对特定平台的 C++ 编译器,就可以采用一种效率高得多的方法:扩展链接编辑器和目标文件格式,使其直接支持静态初始化和释放。例如,System V 的可执行链接格式(ELF)被扩展,增加了 .init 和 .fini 段,分别存放需要静态初始化和静态释放的对象信息。平台特定的启动例程(通常叫作 crt0.o 之类)完成了对静态初始化和释放的平台特定支持。
在 2.0 版之前,C++ 不支持非类对象的静态初始化------也就是说,保留了 C 语言的这一限制。因此,下面这些定义都会被标记为非法初始化:

后来添加对非类对象静态初始化的支持,在某种程度上是支持虚基类带来的一个副作用。虚基类怎么会牵扯到这个问题呢?因为通过派生类指针或引用访问虚基类子对象,属于非常量表达式,需要在运行时求值。例如,下面这些地址在编译时是已知的:

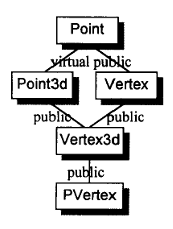
虚基类 Point 子对象的位置会随着后续每个派生类的不同而发生变化,因此无法在编译期间确定。下面这个初始化:


要求编译器提供内部扩展来支持类对象的静态初始化------至少得覆盖类对象的指针和引用。例如:

从这儿再往前走一步,就能提供覆盖所有非类对象所需的支持了。
使用静态初始化的对象有几个缺点。例如,如果支持异常处理,这些对象不能放在 try 块内。对于静态调用的构造函数来说,这一点尤其令人不满意,因为任何 throw 都会不可避免地触发异常处理库中的默认 terminate() 函数。另一个缺点是:对于需要跨模块进行静态初始化的对象,控制它们的顺序依赖性非常复杂(关于这个问题的首次讨论以及现在所谓的 Schwarz 计数器(Schwarz counter)的引入,参见 SCHWARZ89,对该问题的全面讨论,参见 CARROLL95)。我建议你不要使用需要静态初始化的全局对象。实际上,我建议你根本不要使用全局对象(尽管这个建议似乎被普遍忽视,尤其是被 C 语言程序员)。
局部静态对象(Local Static Objects)
假设我们有下面这段代码:

局部静态类对象的保证语义是什么?
1.mat_identity 的构造函数只应被调用一次,即使该函数可能被调用多次。
2.mat_identity 的析构函数也只应被调用一次,同样即使函数可能被调用多次。
一种实现策略是在程序启动时无条件地构造该对象。但这会导致所有局部静态类对象在程序启动时都被初始化------即便它们所属的函数从未被调用过。更好的做法是:只在 identity() 第一次被调用时才构造 mat_identity(这也是标准 C++ 现在的要求)。我们该怎么做呢?
以下是 cfront 的做法。首先,引入一个临时标志来守卫 mat_identity 的初始化。第一次进入 identity() 时,该标志求值为 false;然后调用构造函数,再把标志设为 true。这样构造问题就解决了。反过来,析构函数需要有条件地应用到 mat_identity 上------仅当 mat_identity 确实被构造过时才调用。判断是否构造过很简单:如果标志为 true,就表示已经构造了。困难在于:由于 cfront 生成的是 C 代码,mat_identity 仍然是函数内部的局部变量,而在静态释放函数中无法以 C 的合法方式访问它。"哦,真麻烦,"------正如小熊维尼会说的那样。解决方案------说来也怪------恰恰是块结构语言中深恶痛绝的做法:我取了局部对象的地址(当然,因为对象是静态的,它在下游组件中的地址会被转移到全局程序数据段)!总之,以下是 cfront 的输出(稍作美化):


最后,析构函数需要在与当前程序文件(本例中为 stat_0.c)相关联的静态释放函数中有条件地调用:

请记住,使用指针是 cfront 特有的做法;但有条件的析构是所有实现都必须遵守的(在我写这段话的时候,标准委员会似乎正打算修改局部静态类对象的析构语义,新规则要求:编译单元内的局部静态类对象应按照构造的逆序进行析构,由于这些对象是按需构造的(即每个函数首次进入时构造),在编译期间无法预知它们被构造的集合和顺序,因此,支持这一规则很可能需要在运行时维护一个已创建的静态类对象链表)。
对象数组(Array of Objects)
假设我们有下面这个数组定义:
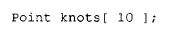
需要做什么?如果 Point 既没有定义构造函数也没有定义析构函数,那么我们只需要做与内置类型数组相同的事即可------即分配足以容纳 10 个连续 Point 元素的内存。
然而,Point 确实定义了默认构造函数,因此必须依次应用到每个数组元素上。通常,这是通过一个或多个运行时库函数来完成的。在 cfront 中,我们使用一个名为 vec_new() 的函数来支持类对象数组的创建和初始化。较新的实现(包括 Borland、Microsoft 和 Sun)则提供了两个版本:一个用于处理不含虚基类的类,另一个用于处理含有虚基类的类(后者通常命名为 vec_vnew())。虽然各实现的签名略有不同,但大致如下:

其中 constructor 和 destructor 分别指向类的默认构造函数和析构函数。array 要么存放具名数组的地址(本例中的 knots),要么为 0。如果为 0,则数组是通过 operator new 在堆上动态分配的(Sun 将具名数组和动态分配的类对象数组分别交由两个独立的库函数处理------_vector_new2 和 _vector_con------每个也都有对应的虚基类版本)。
elem_size 参数表示每个元素的大小(我将在 6.2 节讨论 new 和 delete 运算符时再回到这个话题)。在 vec_new() 内部,构造函数会被依次应用到每个元素上。析构函数的存在是为了支持异常处理(当某个元素的构造函数抛出异常时,需要析构之前已构造好的元素)。对于我们的 10 个 Point 元素的数组,编译器调用 vec_new() 的方式大致如下:

如果 Point 还定义了析构函数,那么当 knots 的生命周期结束时,析构函数也需要依次应用到每个元素上。不出所料,这是通过类似的运行时库函数 vec_delete()(对于含有虚基类的类则用 vec_vdelete())来完成的(Sun 将具名数组和动态分配数组的释放分开处理)。其签名大致如下:

不过,有些实现会额外增加一个参数,用于携带可选的值来有条件地指导 vec_delete() 的逻辑(与之相反的做法是繁殖出多个各自专门的函数)。在 vec_delete() 内部,析构函数会被依次应用到每个元素上。
如果程序员为类对象数组提供了一个或多个显式初始值,例如:

那么对于显式提供了初始值的元素,无需使用 vec_new()。对于其余未初始化的元素,则和没有显式初始化列表的类对象数组一样,使用 vec_new() 来处理。上面这个定义很可能会被翻译成如下形式:

Default Constructors和数组(默认构造函数和数组)
在程序员层面,取构造函数的地址是不允许的。然而,这恰恰是编译器在支持 vec_new() 时所做的事情。通过指针调用构造函数会阻止默认实参的访问。这导致类对象数组的初始化一直无法得到一流的处理。
例如,在 cfront 2.0 版之前,声明一个类对象数组要求该类要么不声明任何构造函数,要么声明一个不带参数(即无实参)的默认构造函数。带一个或多个默认实参的构造函数是不允许的。这显然违反直觉,并导致了下面这个失误。下面是 Release 1.0 中 complex 库的声明。你能看出它有什么问题吗?

按照当时通行的语言规则,使用我们所发布的 complex 库的用户无法声明 complex 类对象的数组。显然,我们自己也被语言的这个陷阱绊倒了。Release 1.1 中,我们修正了该类库。到了 Release 2.0,我们修正了语言本身。
再想一想,你该如何实现对下面这个构造函数的支持:
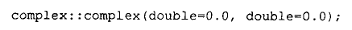
当程序员写下:
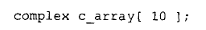
而编译器最终需要调用:

时,vec_new() 如何获取这些默认实参?
显然,有几种可能的实现方式。我们在 cfront 中选择的做法是:生成一个内部的桩构造函数,它不带任何参数。在该函数体内,调用用户提供的构造函数,并显式传递默认实参(由于要取构造函数的地址,因此构造函数不能是内联的)。

在内部,编译器又一次违反了语言的一条显式规则:该类实际上支持了两个不需要实参的构造函数。当然,这个桩实例只有在实际创建了类对象数组时才会被生成并使用。
6.2 new和delete运算符
表面上使用 new 运算符只是一步操作,比如:
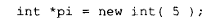
实际上它分成两个独立的步骤:
1.通过调用合适的 operator new 实例来分配所需内存,并把对象大小传给它:

2.对分配好的对象进行初始化:
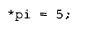
此外,只有当 operator new 成功分配了对象时,才会执行初始化:

delete 运算符的处理方式类似。当程序员写下:
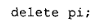
语言规定:如果 pi 为 0,则不应调用 operator delete。因此,编译器必须在该调用外加上一个保护判断:

请注意,pi 不会被自动重置为 0。随后对它进行解引用,比如:

虽然行为未定义,但结果有可能是真也有可能假。这是因为 pi 所指向的存储空间可能已经被修改或重新使用了,也可能没有。
pi 所指向的对象的生命周期在 delete 执行时即告结束。因此,此后任何通过 pi 访问该对象的行为都不再有良好定义,通常被视为糟糕的编程习惯。然而,将 pi 作为一个指向某存储地址的指针来使用仍然是良好定义的,尽管用途有限。例如:

这里需要区分:指针 pi 的使用与 pi 所指向的对象的使用(该对象的生命周期已经结束)。虽然该地址上的对象已不再有效,但地址本身仍然指向有效的程序存储空间。因此,pi 可以继续使用,但只能以有限的方式------类似于把它当作 void* 指针来用。
带有构造函数的类对象的分配也以类似方式处理。例如:
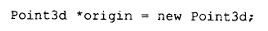
会被转换为:

如果实现了异常处理,上述转换会变得稍微复杂一些:

在这里,如果用 operator new 分配的对象在构造过程中抛出异常,那么已分配的内存会被释放,然后该异常会再次被抛出。
析构函数的应用与之类似。表达式:
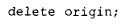
会变为:

在异常处理机制下,析构函数会被包裹在一个 try 块内。异常处理代码会调用 delete 运算符,然后重新抛出异常。
operator new 的通用库实现相对简单,不过有两个细微之处值得探讨(注意:以下版本未考虑异常处理)。

虽然下面的写法是合法的:
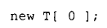
但语言要求 operator new 的每次调用都必须返回一个唯一的指针。传统解决方法是返回一个指向默认 1 字节内存块的指针(这就是为什么把 size 设置为 1 的原因)。实现中的另一个有趣之处在于:需要允许用户提供的 _new_handler()(如果存在)有机会释放内存。这就是每次实际调用 _new_handler() 时都要循环的原因。
在实践中,operator new 总是基于标准 C 的 malloc() 来实现的,尽管语言并未强制要求这样做(因此不应假定总是如此)。类似地,operator delete 在实践中也总是基于标准 C 的 free() 来实现:

针对数组的new语意
当我们写下:
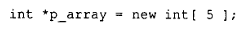
实际上并不会调用 vec_new(),因为它的主要作用是将默认构造函数应用到类对象数组的每个元素上。这里只是调用了 operator new 实例:
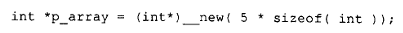
类似地,如果写下:
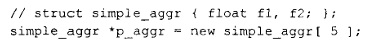
同样不太可能调用 vec_new()。为什么?因为 simple_aggr 既没有定义构造函数也没有定义析构函数,所以分配和删除 p_aggr 所指向的数组只涉及获取和释放实际的存储空间。这通过更简单、更高效的 new 和 delete 运算符就能妥善处理。
然而,如果一个类定义了默认构造函数,那么就会调用某个版本的 vec_new() 来分配和构造类对象数组。例如,表达式:
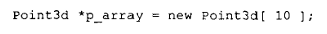
通常会被转换为:

回想一下,之所以要把析构函数传给 vec_new(),是为了应对在构造数组各个元素时抛出异常的情况。只有那些已经构造完成的元素才需要调用析构函数。由于数组的内存在 vec_new() 内部分配,因此一旦抛出异常,vec_new() 也负责释放这块内存。
在 2.0 版之前,程序员需要自己提供 delete 运算符所删除数组的实际大小。比如,如果我们之前写了:

那么我们必须写成:
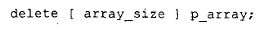
并且还得寄希望于 p_array 的原始数组没有被delete过、也没有被重新赋值为元素个数不同的新数组。从 2.1 版开始,语言做了修改:用户不再需要指定要删除的数组元素个数。因此,我们现在可以写成:
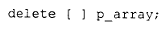
不过为了向后兼容,两种形式通常仍然都被接受。当然,第一个实现来自 cfront。Jonathan Shopiro 完成了实际的库实现。支持这一特性需要先存储、再取回与指针关联的元素个数。
由于担心搜索数组维度会影响 delete 运算符的性能,人们达成了如下折衷方案:编译器只在方括号存在时才去查找维度大小。否则,它假定删除的是单个对象。如果程序员没能提供必要的方括号,比如写成了:
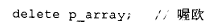
那么只有数组的第一个元素会被析构,其余元素虽然它们关联的内存被回收了,但自身并不会被析构。那种更不易出错的做法------即检查所有 delete 操作是否可能作用于数组------因为代价太高而被否决了。
不同实现之间的一个有趣差异在于:当用户显式提供了元素个数时,是否应该使用这个值。在 Jonathan 的原始版本代码中,他优先采用用户显式给出的值。下面是他所写代码的伪代码版本,附带注释:

如今,几乎所有新的 C++ 编译器都选择忽略用户显式给出的数组大小(如果提供了的话)。例如:

为什么 Jonathan 当初选择优先采用用户指定的值,而新编译器却不这么做呢?因为在他引入这个特性时,还不存在不显式提供数组大小的用户代码。如果 cfront 继续发展到 4.0 版,我们也会把这个用法标记为"时代错误"(anachronism),并很可能发出类似的警告。
那么,元素个数的缓存是如何实现的呢?一种显而易见的方法是在 vec_new() 运算符返回的每一块内存前面多分配一个字的空间,把元素个数塞进这个字里(这个被藏起来的值通常称为 cookie)。不过,Jonathan 和 Sun 的实现选择了维护一个由指针值和数组大小构成的关联数组(关联的含义是通过指针值为key来获取数组大小value)(Sun 还会额外存下析构函数的地址------参见 CLAM93n)。
cookie 策略普遍令人担忧的是:如果有一个错误的指针值被传给了 delete_vec(),那么取出的 cookie 自然也是无效的。错误的元素个数加上错误的起始地址,会导致析构函数被反复应用在任意内存区域上------次数也是任意的。而采用关联数组策略时,传入错误地址的后果很可能只是取不到元素个数而已。
在最初的实现中,增加了两个主要函数来支持元素个数 cookie 的存储与检索:

下面是 cfront 对 vec_new() 原始实现的简化呈现,附带注释:
cpp
PV __vec_new(PV ptr_array, int elem_count, int size, PV construct )
{
// 如果 ptr_array 为 0,则从堆上分配数组
// 如果已设置,说明程序员写了以下两种形式之一:
// T array[ count ];
// 或
// new ( ptr_array ) T[ 10 ]
int alloc = 0; // 我们是否在 vec_new 内部分配了内存?
int array_sz = elem_count * size;
if ( alloc = ptr_array == 0)
// 调用全局 operator new ...
ptr_array = PV( new char[ array_sz ] );
// 在异常处理机制下,此处会抛出 bad_alloc 异常
if ( ptr_array == 0 )
return 0;
// 将 (数组地址, 元素个数) 放入缓存
int status = __insert_new_array( ptr_array, elem_count );
if (status == -1) {
// 异常处理机制下,此处会抛出 bad_alloc 异常
if ( alloc )
delete ptr_array;
return 0;
}
if (construct) {
register char* elem = (char*) ptr_array;
register char* lim = elem + array_sz;
// PF 是函数指针类型的别名
register PF fp = PF(construct);
while (elem < lim) {
// 通过 fp 调用构造函数,作用于 elem 所指向的当前元素
(*fp)( (void*)elem );
// 然后前进到下一个元素
elem += size;
}
}
return PV(ptr_array);
}vec_delete() 的工作方式类似,但其行为并不总是 C++ 程序员所期望或要求的。例如,考虑下面两个类声明:

分配一个包含 10 个 Point3d 对象的数组,会如预期那样调用 10 次 Point 和 Point3d 的构造函数,每个数组元素各一次:

然而,当我们删除 ptr 所指向的这 10 个 Point3d 元素的数组时,会发生什么?显然,我们需要虚机制发挥作用,以期 Point 和 Point3d 的析构函数各被调用 10 次,每个数组元素一次:

正如我们所见,将要应用到数组上的析构函数是根据被删除指针的类型传递给 vec_delete() 的。在这个例子中,传递的是 Point 的析构函数。这显然不是我们想要的。此外,每个元素的大小也会被传递------vec_delete() 正是靠它来遍历数组元素的。而在本例中,传递的是 Point 类对象的大小,而不是 Point3d 类对象的大小。糟糕。整个操作会彻底失败:不仅调用了错误的析构函数,而且从第一个元素之后,它就会被应用到错误的内存块上。
那么程序员应该怎么做呢?最好的办法是:如果派生类对象的大小大于基类对象,就不要用基类指针去指向派生类对象的数组。如果你真的非得这么编程,那么解决方案只能由程序员自己来实现,而不是依赖语言:

本质上,程序员需要自己遍历数组,对每个元素单独应用 delete 运算符。这样一来,调用就是通过虚机制进行的,Point3d 和 Point 的析构函数会各自正确地应用到每个对象上。
Placement Operator new的语意
operator new 有一个预定义的重载版本,称为 placement operator new。它接受一个 void* 类型的第二参数,调用形式如下:
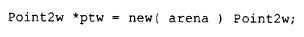
其中 arena 是一个内存位置的地址,新的 Point2w 对象将被放置在该位置上。这个预定义的 placement operator new 的实现简单得几乎令人不好意思------它只是返回传进来的指针地址:

既然它只做了返回第二参数地址这件事,那为什么还要用它呢?换句话说,为什么不直接写成:
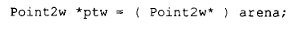
因为实际发生的效果不就是这个吗?嗯,实际上这只是事情的一半,而另一半是程序员无法显式重现的。请思考下面两个问题:
1.placement operator new 展开式的另一半是什么?正是这一半让它正常工作(而显式赋值 arena 无法提供这一半)。
2.arena 所代表的指针的实际类型是什么?该类型意味着什么?
placement new 运算符展开式的另一半是:自动将 Point2w 的构造函数应用到 arena 所指向的内存区域上:

这正是 placement new 运算符如此强大的原因。该实例决定了对象将被放置在哪里;而编译系统则保证对象的构造函数会被应用到该内存上。
不过,这里有一个小小的不当行为。你能看出来是什么吗?例如,考虑下面这个程序片段:

如果 placement new 运算符在现有对象的"上方"构造新对象,而现有对象又带有析构函数,那么这个析构函数并不会被调用。一种调用析构函数的方法是对该指针应用 delete 运算符。但在这种情况下,这样做完全是错误的:

delete 运算符确实会调用析构函数------这正是我们想要的。但它同时也会释放 p2w 所指向的内存------这绝对不是我们想要的,因为下一条语句还要尝试重用它。相反,我们需要显式调用析构函数,同时保留存储空间以便重用(标准 C++ 已经纠正了这个问题,提供了一个 placement delete 运算符,它会对对象调用析构函数,但不释放内存。因此,直接调用析构函数的方式已不再必要):

剩下的唯一问题是设计层面的:在我们的例子中,第一次调用 placement new 运算符时,是在现有对象的"上方"构造新对象,还是 arena 指向的是"原始"内存?也就是说,如果我们写下:
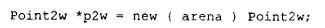
我们怎么知道 arena 所指向的区域是否需要先被析构?语言并没有提供解决方案,你应该自己判断。
第二个问题涉及 arena 所代表的指针的实际类型。标准规定,该指针必须指向相同类型的类对象,或者指向足以容纳该类对象的原始存储空间。请注意,标准明确不支持指向派生类。对于派生类或其他不相关的类型,其行为虽然并非非法,但属于未定义。
原始存储空间可以这样分配:
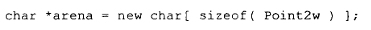
相同类型的对象则如你所料:
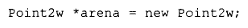
在这两种情况下,新 Point2w 的存储空间恰好覆盖了 arena 的存储位置,行为是良好定义的。不过一般来说,placement new 运算符并不支持多态。传递给 new 的指针所指向的内存很可能是预先分配好的特定大小。如果派生类大于其基类,例如:
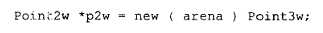
那么 Point3w 构造函数的应用将会造成严重破坏,此后大多数对 p2w 的使用也会如此。
在 Release 2.0 引入 placement new 运算符时,Jonathan Shopiro 提出了一个相当"阴暗角落"的问题。示例如下:

由于这两个类的大小相同,将派生类对象放在基类对象所占用的内存区域中是安全的。然而,支持这种用法很可能需要放弃一项通用优化:即通过对象静态地调用所有虚函数(例如 b.f())。因此,标准也不支持这种 placement new 的用法(参见 3.8 节)。该程序的行为是未定义的:我们无法确定到底会调用哪个 f() 实例(大多数实现如果编译这段代码,可能会调用 Base::f(),而大多数用户可能期望调用 Derived::f())。