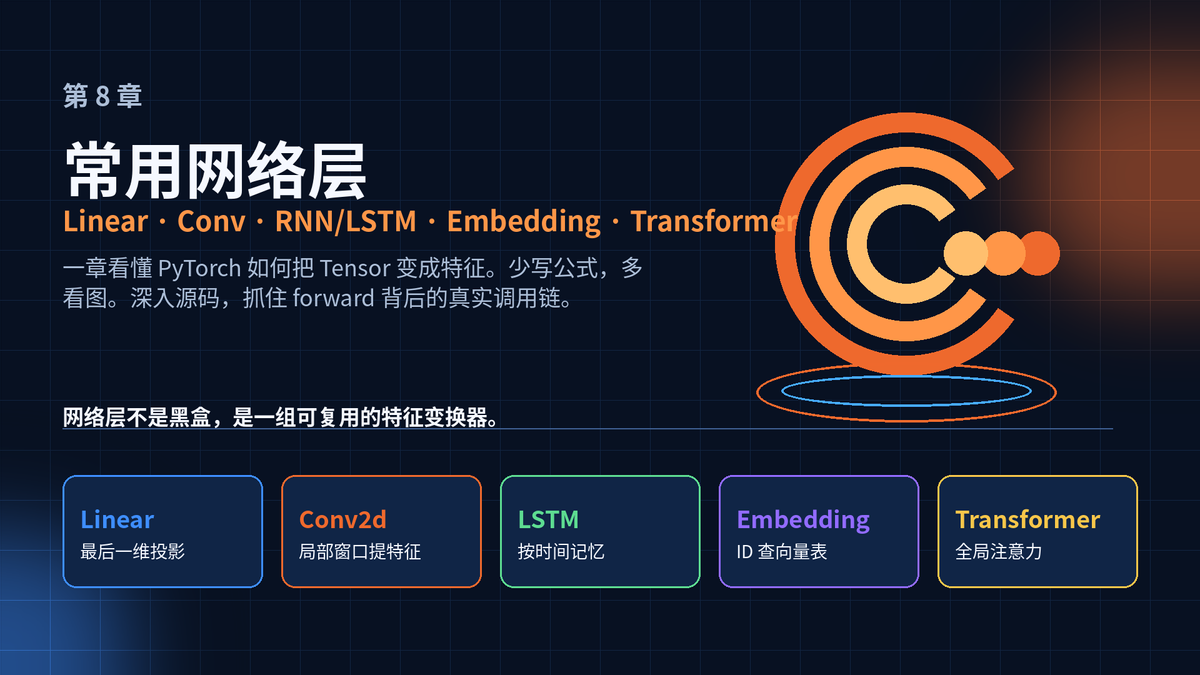
1. 网络层的本质:把一种 Tensor 变成另一种 Tensor
PyTorch 的网络层,都是 nn.Module。它们有参数,有 forward,有状态,也能被递归注册到模型里。
但从计算角度看,层只有一句话:输入 Tensor,输出新的 Tensor。
区别在于:每一层"看数据"的方式不同。Linear 看最后一维,Conv 看局部窗口,RNN/LSTM 看时间顺序,Embedding 查表,Transformer 做全局注意力。
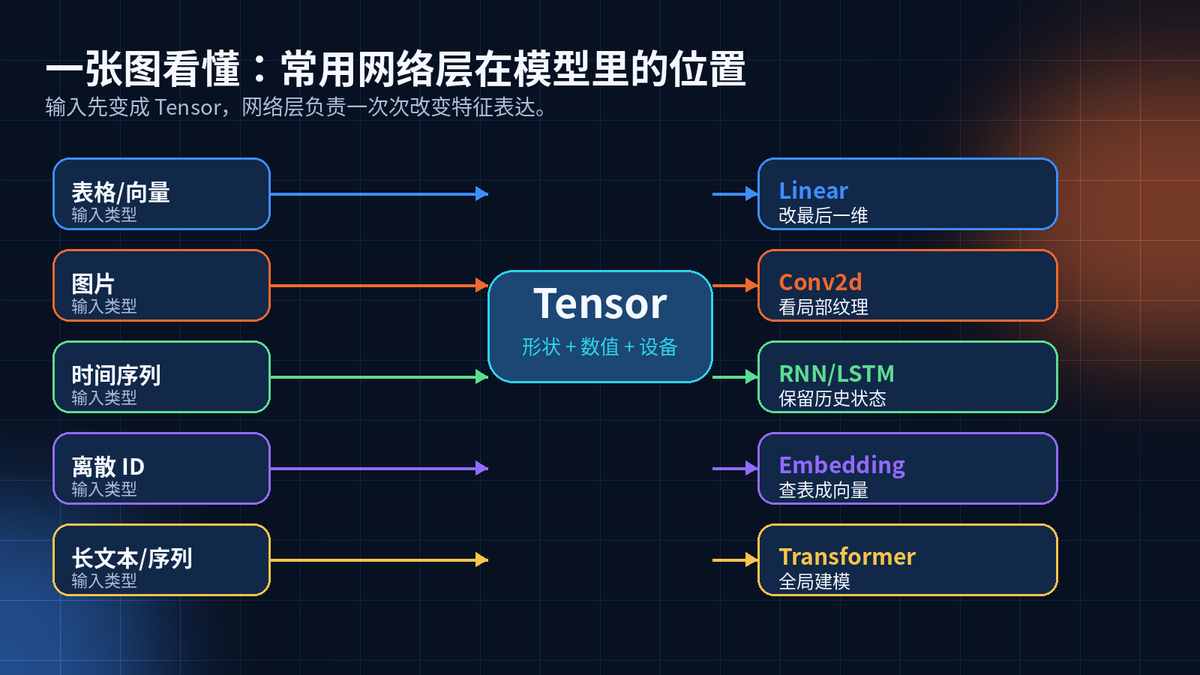
2. Linear:最朴素,也最常用
Linear 就是全连接层。它不关心图片、文本、时间。它只关心最后一维。
输入最后一维是 in_features,输出最后一维就是 out_features。其它维度保持不变。
layer = nn.Linear(128, 64)
y = layer(x) # x: (..., 128) -> y: (..., 64)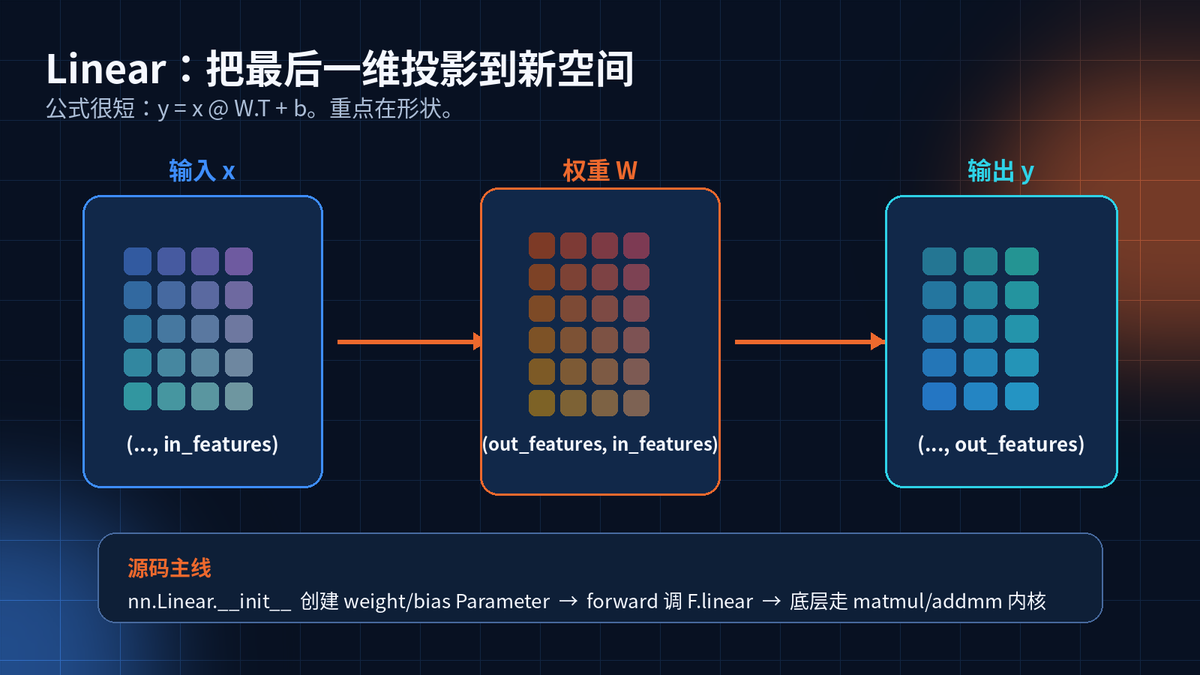
Linear 的 Python 层很薄。初始化时创建两个 Parameter:weight 和 bias。
weight 的形状是 out_features x in_features。forward 时调用 F.linear。
真正重活不在 Linear 类里,而在 functional 和更底层的 ATen 算子里。
# 源码主线(简化)
self.weight = Parameter(torch.empty(out_features, in_features))
self.bias = Parameter(torch.empty(out_features))
forward(x) -> F.linear(x, weight, bias)**抓重点:**Linear 不是"压平层"。它只处理最后一维。是否 flatten,要你自己决定。
3. Conv2d:从整张图里抠局部模式
图片有空间结构。相邻像素更相关。Conv2d 就是利用这个特点。
卷积核像一个小窗口,在 H 和 W 两个方向滑动。每次只看一块局部区域。
一组卷积核产生一组输出通道。out_channels 越大,提取的特征种类越多。
conv = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1)
y = conv(x) # x: (N, 3, H, W) -> y: (N, 32, H, W)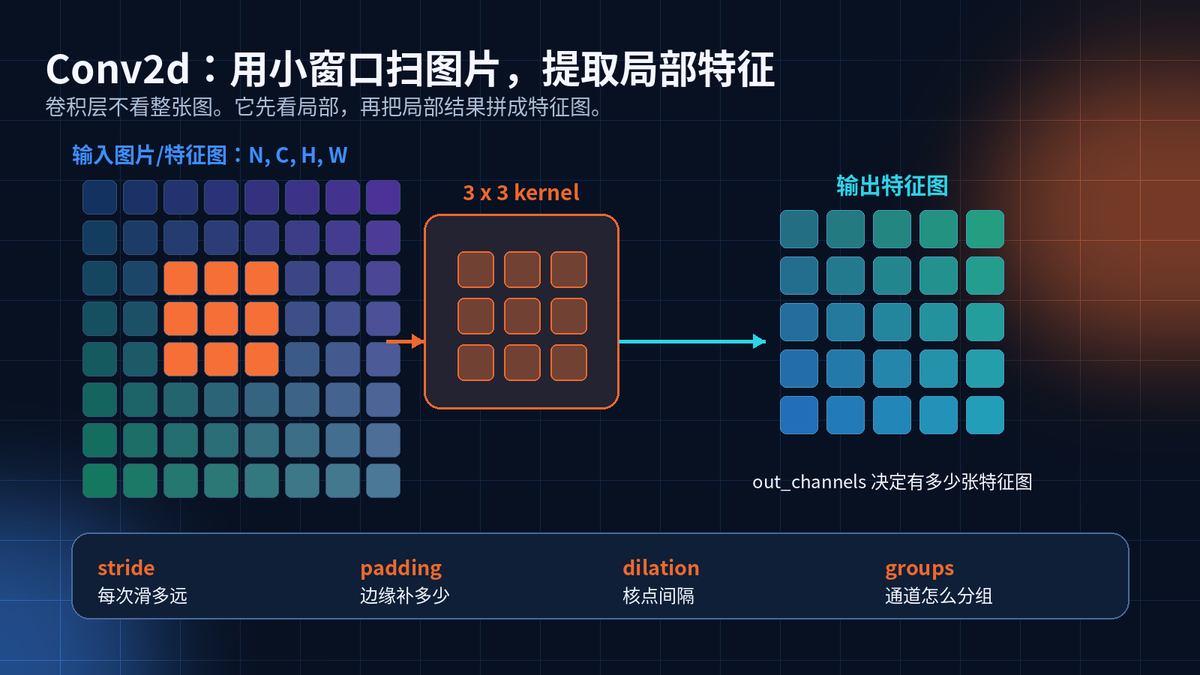
Conv2d 继承自 _ConvNd。初始化时会把 kernel_size、stride、padding、dilation 统一转成二维 tuple。
forward 不直接计算卷积。它进入 _conv_forward,再调用 F.conv2d。
如果 padding_mode 不是 zeros,会先 F.pad,再 conv2d。
源码主线(简化)
Conv2d.init -> _pair(kernel_size / stride / padding)
forward(x) -> _conv_forward(x, weight, bias) -> F.conv2d(...)
**抓重点:**PyTorch 的图像张量默认是 NCHW,不是 NHWC。形状错,卷积一定报错。
4. RNN / LSTM:让模型记住前面发生了什么
序列数据有先后顺序。今天的温度和昨天有关,一个词和前面的词有关。
RNN 的思路很直接:每个时间步都接收当前输入 x_t,同时接收上一步 hidden state。
LSTM 比 RNN 多一个 cell state,并用四个门控制记忆的写入、遗忘和输出。
lstm = nn.LSTM(input_size=128, hidden_size=256, batch_first=True)
y, (h, c) = lstm(x) # x: (batch, seq, feature)
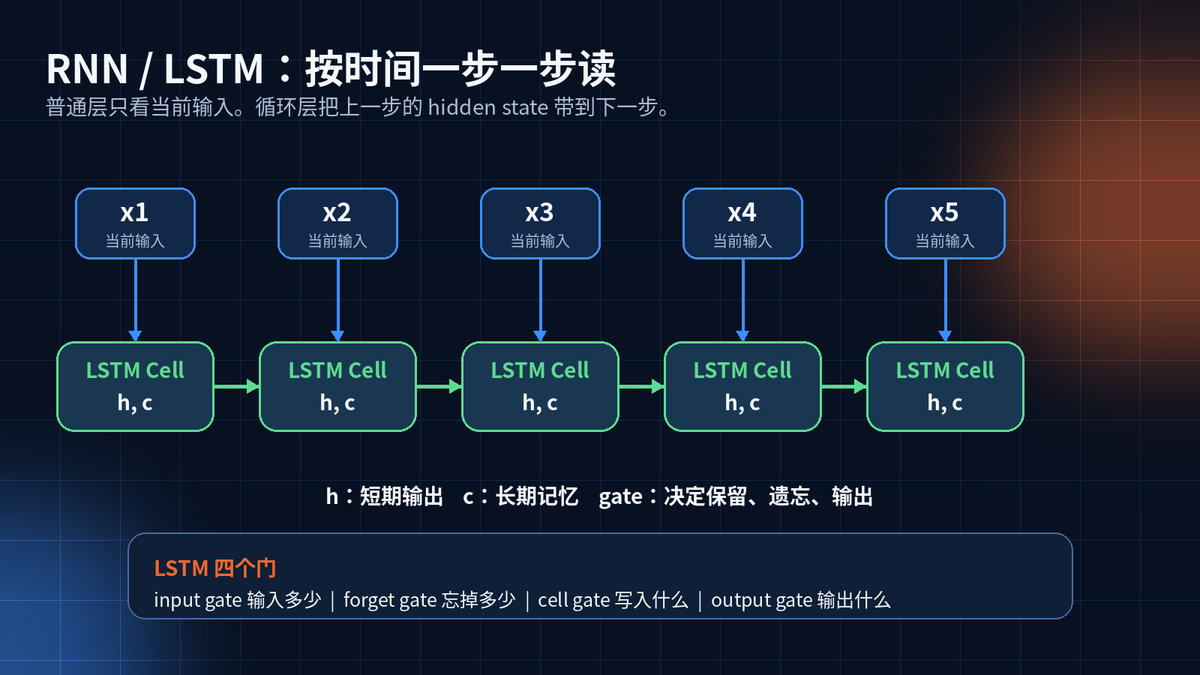
LSTM 继承自 RNNBase。RNNBase 负责参数管理:weight_ih、weight_hh、bias_ih、bias_hh。
LSTM 每层的 input-hidden 权重是 4 * hidden_size,因为它要同时服务四个门。
forward 会检查输入维度,准备 h0/c0,然后把 flat weights 交给底层 RNN 算子。GPU 上会尽量走 cuDNN 快路径。
# 源码主线(简化)
RNNBase.__init__ -> 创建每层每方向的门控权重
LSTM.forward -> 检查 input/hx/cx -> 底层 LSTM 算子**抓重点:**batch_first=True 只改变 input/output 的 batch 位置,不改变 h0/c0 的形状规则。
5. Embedding:把离散 ID 变成连续向量
词 ID、用户 ID、商品 ID,本身只是编号。编号之间没有天然大小关系。
Embedding 做的事很简单:维护一张可训练表。输入 ID,取出对应行。
训练时,反向传播会更新这些向量,让相似对象在向量空间里更接近。
emb = nn.Embedding(num_embeddings=50000, embedding_dim=768)
y = emb(token_ids) # token_ids: (batch, seq) -> y: (batch, seq, 768)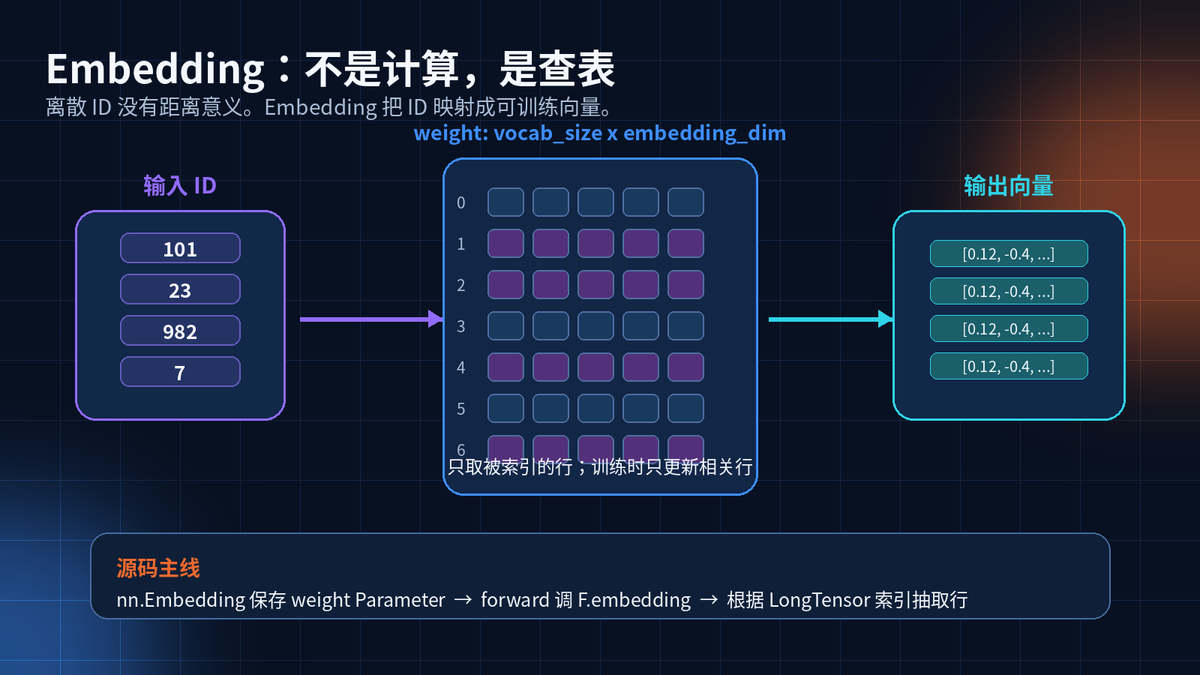
Embedding 内部保存一个 weight Parameter,形状是 num_embeddings x embedding_dim。
forward 进入 F.embedding。输入必须是 IntTensor 或 LongTensor,因为它是索引,不是连续特征。
padding_idx 对应的行不参与梯度更新,适合处理补齐 token。
# 源码主线(简化)
self.weight = Parameter(num_embeddings, embedding_dim)
forward(input_ids) -> F.embedding(input_ids, weight, padding_idx, ...)**抓重点:**Embedding 不会理解文字。它只学习 ID 到向量的映射。语义来自训练目标。
6. Transformer:让序列里的每个位置互相看见
RNN 是一步一步读。Transformer 是同时看全局。
每个 token 会生成 Q、K、V。Q 用来问,K 用来匹配,V 是被汇总的信息。
Multi-Head Attention 让模型从多个角度关注序列,再用 FeedForward 做逐位置变换。
block = nn.TransformerEncoderLayer(d_model=768, nhead=12, batch_first=True)
y = block(x) # x: (batch, seq, 768)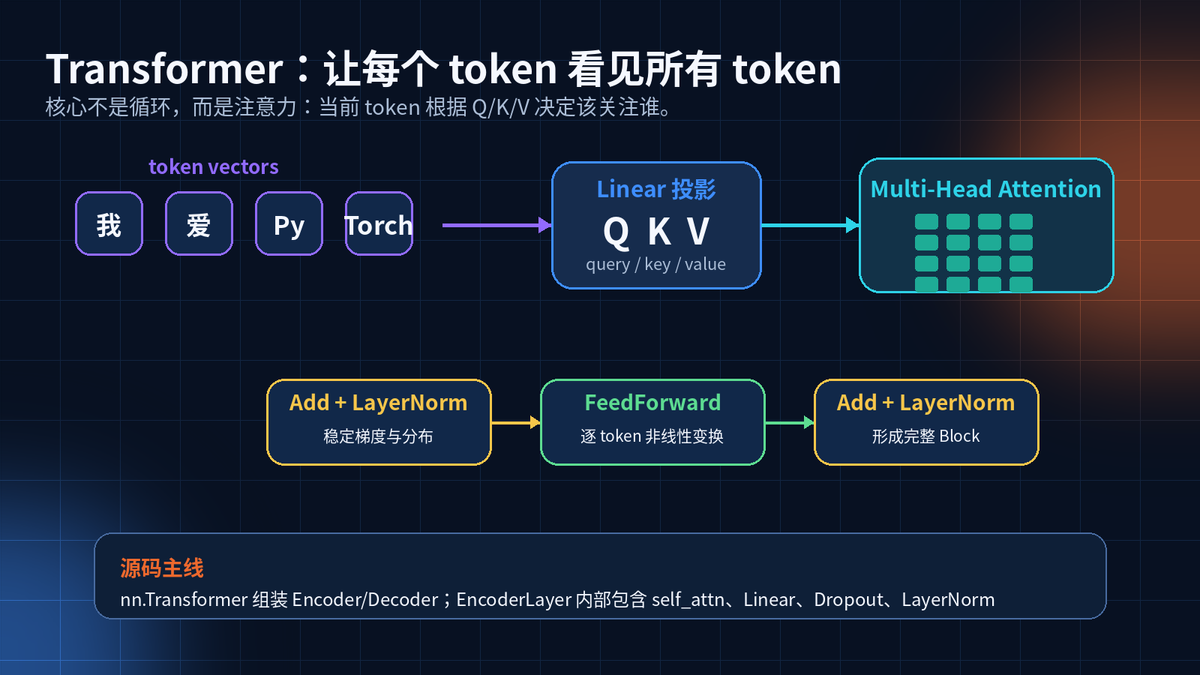
nn.Transformer 是参考实现。它会组装 TransformerEncoder 和 TransformerDecoder。
EncoderLayer 内部通常包含 self_attn、两个 Linear、Dropout、LayerNorm。
MultiheadAttention 在可能时会使用 scaled_dot_product_attention 的优化实现。
# 源码主线(简化)
Transformer.__init__ -> EncoderLayer / DecoderLayer
EncoderLayer.forward -> self_attn -> Linear -> Dropout -> LayerNorm**抓重点:**新项目建议显式写 batch_first=True,别让 seq 和 batch 的位置靠记忆。
7. 五类层怎么选
选层不是追热点。先看输入数据结构。
向量用 Linear,图片用 Conv,离散 ID 先 Embedding,短序列可用 LSTM,长序列和全局依赖优先 Transformer。

8. 从 Module 到底层算子:一条源码主线
上一章讲过 nn.Module。现在把它和具体层连起来。
model(x) 会触发 Module.call。call 处理 hook、状态和上下文,然后进入 forward。
forward 再调用 functional API。functional API 再进入 ATen / CUDA / cuDNN 等后端实现。
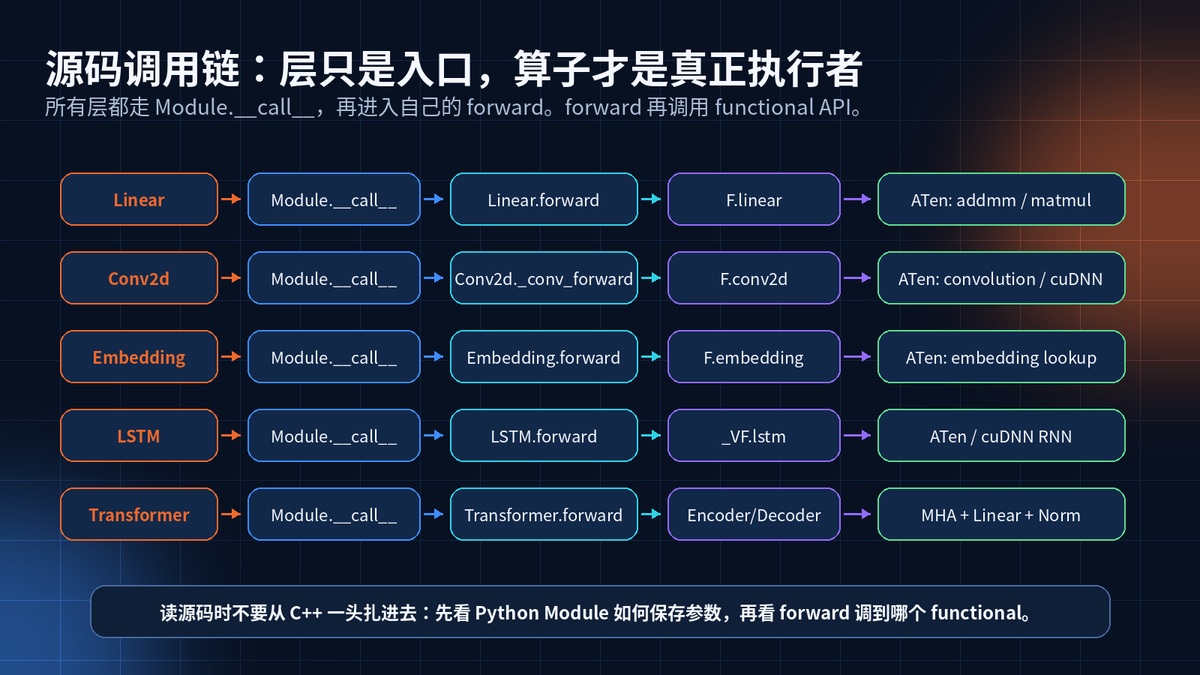
读源码的顺序
第一步,看 init 保存了什么参数。
第二步,看 forward 调了哪个 functional。
第三步,看 functional 背后对应哪个底层算子。
第四步,再看设备后端:CPU、CUDA、cuDNN、MPS、ROCm。
9. 常见坑:先查 shape,再查源码
绝大多数网络层报错,第一原因都是 shape 不匹配。
写模型时,别靠猜。每经过一个关键层,就打印一次 shape。

def hook(name):
def fn(module, inputs, output):
print(name, output.shape if hasattr(output, 'shape') else type(output))
return fn
model.layer.register_forward_hook(hook('layer'))**工程习惯:**复杂模型不要一口气写完。先跑通一层,再堆下一层。
10. 总结
Linear、Conv2d、LSTM、Embedding、Transformer,不是五个孤立 API。它们是一套特征变换语言。
你真正要记住的是它们各自处理什么结构、改变什么形状、源码最终调到哪里。
一句话带走
Linear 改维度,Conv 抓局部,LSTM 记历史,Embedding 查向量,Transformer 建全局关系。
下一章继续:激活函数、归一化、Dropout。层负责表达,训练稳定性靠它们撑住。
内容来源:常用网络层:Linear、Conv、RNN、Embedding、Transformer:功能变化与行业影响解析_热闻岛