面向子图查询的神经优化器 (NeuSO) 完整分析
论文全称 :NeuSO: Neural Optimizer for Subgraph Queries
作者 :Linglin Yang, Lei Zou, Chunshan Zhao(北京大学)
发表 :ACM SIGMOD 2026(CCF-A / SCI 一区)
arXiv :2509.23775
核心命题:用神经网络替代传统动态规划 + 启发式规则,为图数据库的子图查询生成近似最优的 Join 顺序。
目录
- 问题背景与研究动机
- [NeuSO 整体架构概览](#NeuSO 整体架构概览)
- [核心组件一:查询图编码器与 TriAT](#核心组件一:查询图编码器与 TriAT)
- 核心组件二:多任务基数与代价预测
- 核心组件三:自顶向下计划枚举器
- 完整执行流程(端到端串讲)
- 训练策略与数据构造
- 实验与评估
- 可扩展性与讨论
- 总结与展望
一、问题背景与研究动机
1.1 什么是子图查询?
子图查询(Subgraph Query)是图数据库中最基础、最核心的查询类型。它的任务可以这样描述:
给定一个数据大图 (可能有几千万甚至上亿个节点)和一个查询小图 (通常只有几个到几十个节点,带有标签约束和拓扑约束),找出数据图中所有与查询小图同构的局部子结构。
如果你熟悉关系型数据库(如 MySQL),可以把子图查询理解为:
子图查询 ≈ 关系型数据库中的多表 Join 操作只是图数据库中不写 SQL,而写 CQL(Cypher Query Language)。例如:
cypher
-- 查找两个互相认识、且在同一家公司工作的人
MATCH (a:Person)-[:FRIEND]->(b:Person),
(a)-[:WORK_AT]->(c:Company),
(b)-[:WORK_AT]->(c)
RETURN a, b, c这条查询对应的查询图是一个三角形结构:
Company(c)
/ \
WORK_AT WORK_AT
/ \
Person(a)--FRIEND--Person(b)数据库内部会将 CQL 解析为查询图(Query Graph),然后去数据图中找出所有满足条件的匹配。
1.2 子图查询的三个阶段
一次完整的子图查询执行分为三个阶段:
| 阶段 | 做什么 | 类比 SQL |
|---|---|---|
| Filtering(过滤) | 为每个查询节点快速生成候选集,排除不可能匹配的数据节点 | 索引扫描 + WHERE 过滤 |
| Planning(计划生成) | 确定匹配顺序(Matching Order / Join Order) | Join Order 优化 |
| Enumeration(枚举执行) | 按匹配顺序在数据图上做 DFS + 回溯搜索 | 实际执行 Join |
其中,匹配顺序的选择对性能影响巨大------不同的顺序可能导致执行时间相差几个数量级。
直观理解:假设查询图是 A-B-C-D,你可以先匹配 A 再 B 再 C 再 D,也可以先匹配 C 再 D 再 A 再 B。不同顺序下,中间结果集(partial embedding)的大小天差地别。
1.3 传统优化方法的三大困境
困境一:动态规划 ------ 状态爆炸
传统的关系型数据库优化器(如 DP-based)采用自底向上 策略,需要枚举所有可能的连通子图状态。对于一个 24 个顶点的查询图,可能的连通子查询状态数可达百万级。
为什么是百万级?
n 个顶点的所有子集数量是 2ⁿ。24 个顶点就是约 1677 万个子集。即使只有 10% 是连通的,也有约 167 万个连通子查询状态。动态规划需要为每个状态计算最优子方案,优化耗时远超查询本身的执行耗时,完全无法满足实时需求。
困境二:启发式规则 ------ 局部最优
现有的图匹配方法大多依赖启发式规则(如优先匹配度数大或候选集小的节点),但这些规则:
- 基于人工经验设计,无法适应复杂多变的数据分布
- 只看眼前,缺乏全局视角,容易陷入局部最优
- 对于不同数据图上的同一个查询图,产生完全相同的匹配顺序(无视数据分布特征)
困境三:现有 ML 方法 ------ 在线推理太慢
以 NeurSC(Neural Subgraph Counting, SIGMOD 2022)为代表的学习型基数估计方法,需要在过滤后的大图上运行 GNN 来提取特征。这在在线推理时延迟极高,无法满足实时查询优化的需求。此外,这些方法只做基数估计,无法端到端生成执行计划。
1.4 NeuSO 的应对思路
论文提出了一个全新的端到端神经优化器,核心思想是:
- 把大图的信息"压缩"到小图上 ------ 通过 Filter 快速统计候选集大小,拼接到查询图节点特征中,避免在大图上跑 GNN
- 用更强的 GNN 理解查询图结构 ------ 设计 TriAT 编码器,突破传统 MPNN 的 1-WL 表达能力上限
- 多任务学习同时预测基数和代价 ------ 相互监督,提升鲁棒性
- 自顶向下贪心搜索替代穷举 ------ 用预测的最小总代价作为启发式函数,将指数级搜索降到多项式级
二、NeuSO 整体架构概览
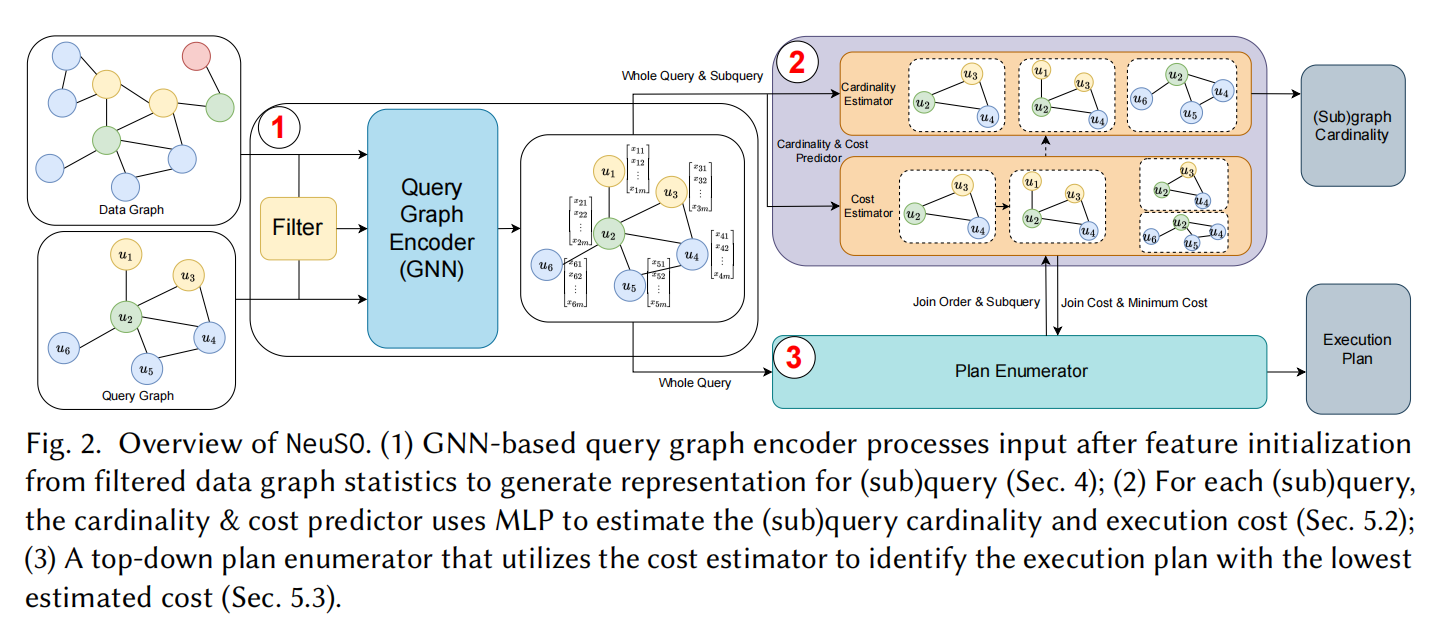
2.1 三大模块
NeuSO 的架构由三个核心模块组成,对应传统优化器的三大组件但全部由神经网络驱动:
┌──────────────────────────────────────────────────┐
│ NeuSO │
│ │
│ ┌──────────┐ ┌──────────────┐ ┌───────────┐ │
│ │ 查询图 │ │ 多任务 MLP │ │ 自顶向下 │ │
│ │ 编码器 │──▶│ 基数 & 代价 │──▶│ 计划枚举器 │ │
│ │ (TriAT) │ │ 预测器 │ │ │ │
│ └──────────┘ └──────────────┘ └───────────┘ │
│ ▲ │
│ ┌────┴─────┐ │
│ │ Filter + │ │
│ │ 特征组装 │ │
│ └──────────┘ │
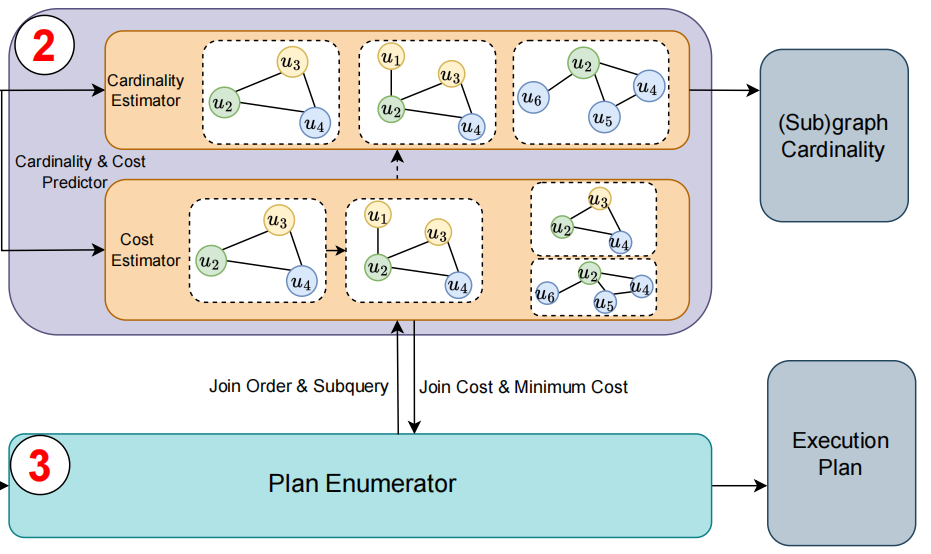
└──────────────────────────────────────────────────┘- 模块一(查询图编码器):Filter 快速统计候选集大小 → 拼接到查询图节点初始特征 → TriAT 编码器计算最终节点特征 → Pooling 得到任意子查询的特征向量
- 模块二(多任务预测器):三个并行的 MLP,共享 TriAT 提取的特征,分别预测基数(cardinality)、单步代价(cost)、最小总代价(minimum cost)
- 模块三(计划枚举器):从完整查询出发,自顶向下贪心回溯,每步用 MLP 预测的代价选择最优前驱状态
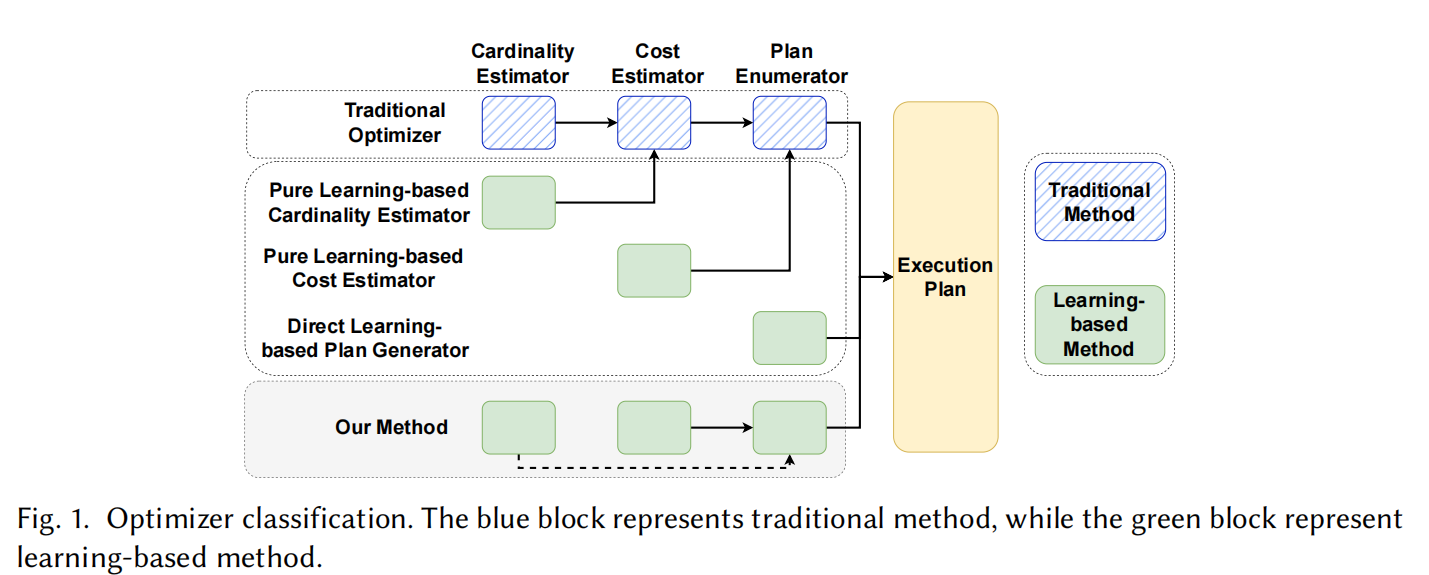
2.2 与关系型数据库学习型优化器的区别
论文将现有学习型优化器分为三类:
| 类型 | 做法 | 代表工作 | 局限性 |
|---|---|---|---|
| 纯基数估计器 | ML 估计基数 + 传统代价模型 + DP 枚举 | MSCN, NeuroCard | 仍依赖传统枚举器 |
| 纯代价估计器 | ML 直接估计代价 + 传统枚举器 | Bao, LOGER | 仍依赖传统枚举器 |
| 直接计划生成 | RL 直接输出执行计划 | RTOS, L2O | 不稳定,可解释性差 |
NeuSO 不属于以上任何一类------它同时学习基数和代价,并用新的枚举策略生成计划,是一种混合型方法。
三、核心组件一:查询图编码器与 TriAT
3.1 前置问题:特征、向量、矩阵是什么?
在深入 TriAT 之前,先明确几个基本概念。很多人在这里卡壳,但其实非常简单:
- 特征(Feature):一个具体的属性值,比如"节点 A 的标签是 Person"、"候选集大小是 100"
- 特征向量(Feature Vector) :把一个节点的所有特征排成一排组成数组,代表一个节点 的全部信息。比如
[0.2, 0.5, 0.1, ..., 100] - 特征矩阵(Feature Matrix) :把所有节点的特征向量叠在一起形成表格,代表整张图 的全部信息。维度为
n × d(n 个节点,每个 d 维)
3.2 特征初始化:把大图信息"搬"到小图上
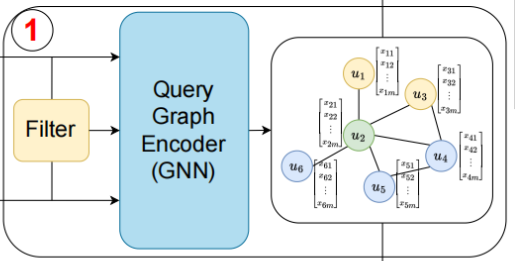
这是 NeuSO 最巧妙的设计之一。整个流程分三步:
第一步:Filter 快速统计
当查询图 Q 到来时,首先使用传统的图过滤技术(如 GQL 中的候选集生成算法),快速得出:
- 节点候选集大小
|C(u)|:查询节点 u 在数据图中有多少个可能的匹配候选 - 边候选集大小
|C(u₁, u₂)|:查询边 (u₁, u₂) 在数据图中有多少条可能的匹配边
这些统计数字的计算代价极低,却能反映数据图的分布特征(比如某个标签在大图中很稀缺、某条边的约束很难满足)。
第二步:标签 Embedding
查询节点最基础的特征是它的标签 (如 Person、Company)。论文不使用简单的 one-hot 编码(太稀疏、不包含数据图信息),而是在标签增强图 (在原数据图上为每个标签增加一个虚拟节点,并将所有属于该标签的节点连接到它)上预训练 embedding,得到每个标签的稠密向量表示 x_{L(u)}。
第三步:拼接组装
将标签 embedding 和 Filter 统计数字拼接,形成每个查询节点的初始特征向量:
x_u^(0) = x_{L(u)} ⊕ |C(u)|边的初始特征也类似:
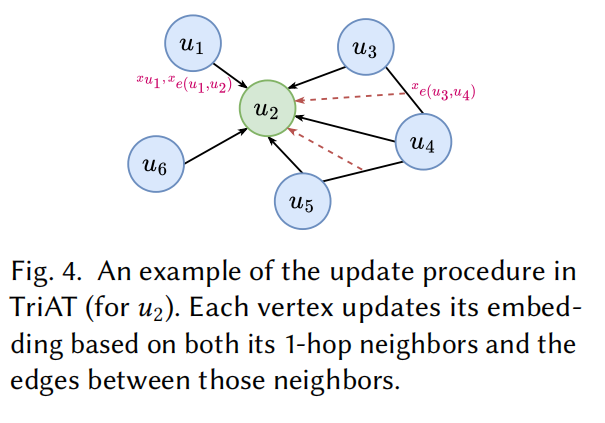
x_{e(u₁,u₂)}^(0) = x_{u₁}^(0) ⊕ x_{u₂}^(0) ⊕ |C(u₁,u₂)|关键洞察 :此时查询图的每个节点兜里已经揣着"情报纸条"了------"我在大图里有 100 个替身"、"我和隔壁节点的关系在大图中很难满足"。但这些信息还只是节点自己知道,邻居之间还没有交流。
3.3 为什么还要过 TriAT 编码器?
刚才得到的初始特征只包含节点自己 的信息(我的标签、我的候选数)。但查询优化的核心在于 Join(连接)------我们需要知道节点之间的拓扑关系。
TriAT 的作用就是特征融合:让每个节点去"看"周围邻居,以及邻居之间的三角形连接。经过 TriAT 处理后,每个节点的特征向量已经吸收了整个查询图的拓扑结构信息。
类比:初始特征就像每个人兜里的名片(自己的信息),TriAT 就像大家坐在一起开会交流,互相了解之后,每个人对"整个团队"都有了认知。
而且,借助 GNN 的消息传递机制,大图信息在小图内部互相碰撞、融合:
- 第 1 层:节点 A 看到邻居 B 兜里的纸条------"B 在大图里只有 2 个替身"。A 立刻明白:"虽然我替身多,但 B 很难找,我俩组合的中间结果肯定不大!"
- 第 2 层:A 通过 B 知道了 C 的情报,再加上 TriAT 独有的三角形机制,知道了 A-B-C 构成闭环。论文指出这种信息的重叠传递有助于捕获子查询之间的关系。
这就是 NeuSO 的绝招:用极快的 Filter 把大图信息压缩成几个数字塞进小图,然后只在小图上跑 GNN。 而 NeurSC 等传统方法是直接在大图上跑 GNN,在线延迟不可接受。
3.4 传统 GNN 的理论天花板:1-WL 测试
什么是 1-WL?
1-WL(1-dimensional Weisfeiler-Lehman test)是一个经典的图论算法,用于判断两张图是否同构。它的工作流程和 GNN 的消息传递几乎一模一样:
- 给每个节点涂上初始颜色(基于标签)
- 每个节点收集邻居的颜色
- 用"自己的颜色 + 邻居颜色集合"生成新颜色
- 不断迭代,直到颜色分布稳定
关键结论 :数学上已证明,所有标准消息传递神经网络(MPNN,包括 GCN、GraphSAGE、GAT、GIN)的表达能力不超过 1-WL 测试。
1-WL 的致命缺陷
1-WL 最大的盲区是:只关心"我和谁连着",完全无视"邻居之间连不连"。
论文中给出了一个直观的例子。以下两张图在 1-WL / 传统 GNN 眼中是完全相同的:
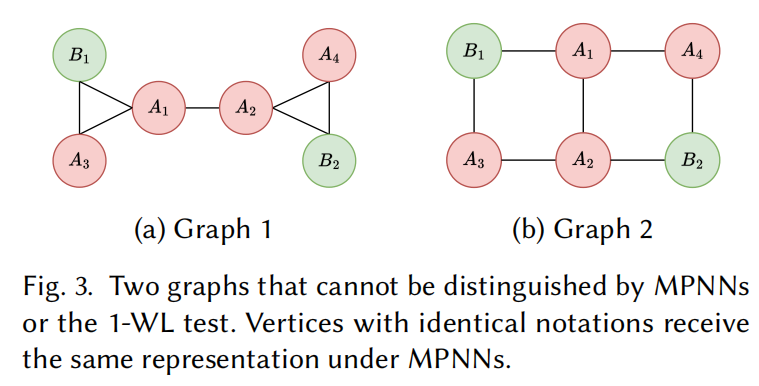
- 图 1:A₁ 连着三个邻居------绿色 B₁、红色 A₂、红色 A₃。邻居标签集合:两红一绿。A₂ 和 A₃ 之间有线(构成三角形)
- 图 2:A₁ 连着三个邻居------绿色 B₁、红色 A₂、红色 A₄。邻居标签集合:同样是两红一绿。但邻居之间没有连线
传统 GNN 会给图 1 和图 2 中所有 A 节点和 B 节点输出一模一样的特征向量------因为它只看邻居标签,不看邻居之间的关系。
朋友圈类比:传统 GNN 知道"我认识张三和李四",但不知道"张三和李四互相也是好友"。TriAT 两者都知道。
有没有 2-WL?
有。 不仅有 2-WL,还有 k-WL:
- 1-WL 视角:关注单个节点
- 2-WL 视角:关注节点对(两个节点的元组),能识别三角形和更复杂的环
但 2-WL / 2-FWL 的 GNN 计算代价太大------每层计算的时间和空间复杂度呈指数级飙升,在实时查询优化中根本跑不动。
3.5 TriAT:三角形感知注意力网络
核心创新
TriAT 在消息传递中引入邻居之间连边(三角形闭环)的注意力机制。更新公式的本质是:
节点新特征 = 自身特征 + 邻居特征聚合 + 邻居间连边特征聚合| 传统 GNN(如 GCN、GAT) | TriAT | |
|---|---|---|
| 看到的信息 | 自身 + 邻居 | 自身 + 邻居 + 邻居之间的边 |
| 能否识别三角形 | ❌ | ✅ |
| 表达能力上限 | 1-WL | 1-WL < TriAT < 2-FWL |
为什么 TriAT 的表达能力介于 1-WL 和 2-FWL 之间?
论文在附录中给出了形式化证明。简单理解:
- TriAT 比 1-WL 强:因为它能看到三角形(邻居之间的边),而 1-WL 不行
- TriAT 比 2-FWL 弱:2-FWL 考虑所有节点对的高阶关系,TriAT 只专门关注三角形这一种特殊结构
这正是 TriAT 的高明之处:针对图查询中最常见的三角形结构做增强,在表达能力和计算效率之间取得最优平衡。 论文统计发现,超过 90% 的含环查询图至少包含一个三角形子结构。
注意力机制
TriAT 中的注意力分为两部分:
- 邻居注意力 α:决定"这个邻居有多重要"(与传统 GAT 类似)
- 三角形边注意力 β:决定"邻居之间的这条边有多重要"(TriAT 独有)
通过可学习的注意力权重,模型自动判断哪些三角形结构对查询优化更关键。
3.6 从节点特征到子查询特征:Pooling
TriAT 编码完成后,每个查询节点都有一个高维 embedding。但枚举器在实际搜索时需要评估的是各种子查询(如 AB、ABC 等子图),而不是单个节点。
解决方法是 Pooling(池化):将属于某个子查询的所有节点的特征向量聚合为一个代表该子查询的向量。论文支持多种池化策略(如求和、平均、注意力加权求和),这个向量随后送入 MLP 进行预测。
重要:Pooling 是"按需"进行的。TriAT 只在完整查询图上运行一次,得到所有节点的 embedding。当枚举器需要评估某个子查询时,直接从内存中取出对应节点的 embedding 做 Pooling,无需重新编码。
四、核心组件二:多任务基数与代价预测
4.1 什么是 MLP?
MLP(多层感知机,Multilayer Perceptron) 是最经典、最基础的前馈神经网络。
- 输入层:接收特征向量
- 隐藏层(可多层):每层有多个神经元,对输入做加权求和 + 非线性激活
- 输出层:吐出预测结果(一个数字)
在 NeuSO 中,TriAT 负责处理复杂的图结构数据 ,输出的是精炼过的特征向量(一排数字)。既然数据已经被压缩成了标准的数字向量,就不需要再用复杂的图神经网络了------这时最擅长"把一排数字映射成一个结果"的 MLP 登场。
类比:TriAT 是"视觉皮层",负责理解复杂的图形;MLP 是"决策皮层",根据理解的结果拍板算数。
4.2 三个 MLP 的分工
NeuSO 并行运行三个独立的 MLP,它们共享 TriAT 编码得到的子查询特征向量:
| MLP | 全称 | 预测目标 | 用途 |
|---|---|---|---|
| MLP_card | Cardinality MLP | 子查询的基数(中间结果集大小) | 训练时的监督信号,增强特征学习 |
| MLP_cost | Cost MLP | 单步执行代价(从子查询扩展一个节点的耗时) | 枚举器决策的核心依据 |
| MLP_mc | Minimum Cost MLP | 最小总代价(从空状态走到该子查询的理论最优代价) | 启发式函数,引导贪心搜索方向 |
4.3 深入理解 Cardinality 和 Cost
这是很多读者容易混淆的概念,我们用具体例子说明。
假设查询图是 A-B-C-D,当前正在评估子查询状态"AB"(已经匹配了 A 和 B)。
基数(Cardinality) 表示:当前 partial embeddings 的数量。比如数据图中有 200 万个 (a, b) 组合满足 A-B 的关系约束,那么状态"AB"的基数就是 200 万。基数越大,意味着后续 Join 产生的中间结果越多,执行越贵。
单步代价(Cost) 表示:从状态"AB"扩展到"ABC"(增加节点 C)的预计耗时。这个耗时取决于"AB"的基数、C 的候选集大小、索引查找效率等因素。
最小总代价(Minimum Cost, MC) 是 NeuSO 引入的新指标:从空状态到当前子查询状态,在所有可能路径中的理论最优总代价。这是整个枚举器的"灵魂"------它让贪心搜索有了全局视野。
4.4 多任务学习的四大优势
论文详细阐述了为什么同时学习基数和代价(而非分别独立训练):
- 增强表示学习:共享子查询表示让模型天然捕获基数与代价之间的内在联系,学出更高质量的特征
- 提升鲁棒性:两个任务的监督信号相互补充,一个任务的噪声可以被另一个任务修正
- 增加可解释性:当基数估计大时,代价估计也应该大;中间估计值可以用于诊断次优计划
- 灵活部署:有经验的用户可以只使用基数估计器搭配自定义代价模型;需要端到端方案的用户可以直接使用代价预测
五、核心组件三:自顶向下计划枚举器
5.1 传统方法的致命缺陷
传统 DP 优化器采用自底向上策略:
先算所有 size=1 的子查询最优代价
→ 再算所有 size=2 的子查询最优代价
→ 再算所有 size=3 ...
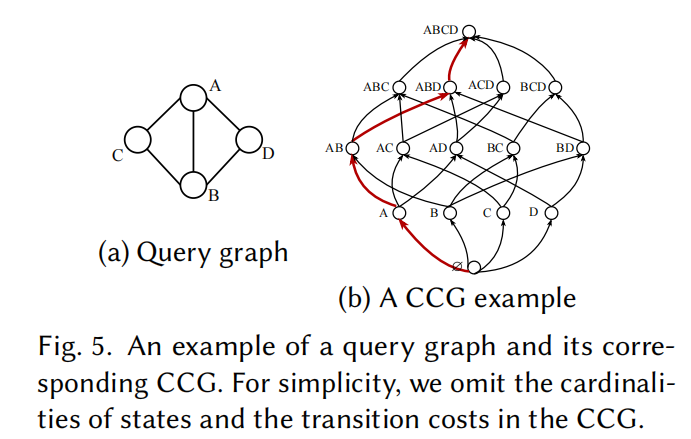
→ 直到完整查询这意味着必须穷举整个 CCG(Cardinality-Cost Graph,基数-代价状态图)。
CCG 本质:一种"状态图",每个节点是一个连通子查询状态,每条边表示"加一个点"的转移。对于 24 个顶点的查询,状态数可达百万级。
复杂度接近指数级,优化耗时远超查询执行耗时。
5.2 NeuSO 的突破:启发式引导的贪心搜索
NeuSO 改用自顶向下策略:
从完整查询 Q 出发
→ 每步看"少了哪个节点的前驱状态最好"
→ 逐步回溯到空状态
→ 反转移除顺序得到 Join 计划核心创新在于:用 MLP_mc 预测的最小总代价作为启发式函数,引导贪心搜索。将全局最优搜索转化为每一步的局部最优决策,同时通过 MLP_mc 的全局预判避免严重的局部最优。

类比:
- 传统 DP:暴力搜索迷宫的所有路径
- NeuSO:AI 启发式寻路(类似 A* 算法),用 MLP_mc 预测"哪条路更可能最优",不用全搜
5.3 五步循环执行流程
Step 1:状态初始化
以完整查询 Q = {A, B, C, D} 为起点,初始化空列表记录回溯移除的顶点顺序。
Step 2:生成候选动作
枚举当前状态的所有合法前驱。例如对于 {A, B, C, D},合法的前驱是少一个点的连通子图:{A, B, C}、{A, B, D}、{A, C, D}、{B, C, D}。注意:不是任意删一个点,删完后剩余子图必须保持连通。
Step 3:调用代价 API
对每个候选前驱,从 TriAT 算好的节点特征中提取对应节点做 Pooling,得到该子查询的特征向量,送入两个 MLP:
- MLP_mc:预测从空状态到该前驱的全局最小路径代价
- MLP_cost:预测该前驱到当前状态的单步连接转移代价
Step 4:贪心决策
计算 总代价 = 前驱全局代价 + 单步转移代价,选择总代价最低的前驱。记录被移除的顶点,将当前状态更新为该前驱。
Step 5:终止与输出
重复 Step 2--4,直到回溯至空状态。将记录的移除顺序反转,得到最终的自底向上 Join 执行计划。
5.4 一个完整的枚举例子
假设查询图 A-B-C-D 是一条链:
初始状态:{A, B, C, D}
候选前驱:{A,B,C}(删D), {A,B,D}(删C), {A,C,D}(删B), {B,C,D}(删A)
MLP 评估后选 {A,B,D}(总代价最低),记录"删了 C"
↓
当前状态:{A, B, D}
候选前驱:{A,B}(删D), {A,D}(删B), {B,D}(删A)
MLP 评估后选 {A,B},记录"删了 D"
↓
当前状态:{A, B}
候选前驱:{A}(删B), {B}(删A)
MLP 评估后选 {B},记录"删了 A"
↓
当前状态:{B}
候选前驱:∅(空状态)
MLP 评估后选 ∅,记录"删了 B"
↓
终止。
移除顺序:[C, D, A, B] → 反转 → Join 顺序:[B, A, D, C]最终执行计划:先匹配 B → 再 A → 再 D → 最后 C。
5.5 复杂度分析
| 方法 | 复杂度 | 24 顶点查询 |
|---|---|---|
| 传统 DP(自底向上穷举) | 近似指数级 | 百万级状态,不可行 |
| NeuSO(自顶向下贪心) | **O( | V_Q |
5.6 执行时序:TriAT 和 MLP 到底谁先运行?
这是一个非常容易混淆的问题。答案是:
TriAT 先一次性算完所有节点特征,然后枚举器开始工作,在枚举过程中"按需"调用 MLP。
具体时序:
- 预处理阶段(仅一次):当查询图 Q 到来时,TriAT 在完整查询图上运行一次,得到所有顶点的最终 embedding 矩阵,存入内存备用
- 确认起点:"完整查询"就是用户输入的那个查询图 Q 包含的所有节点------天然已知
- 枚举循环:枚举器站在"完整查询"上,找出所有合法前驱状态。对每个前驱,从内存中取出对应节点的 embedding 做 Pooling,组装出该子查询的特征向量,送入 MLP 预测代价
- 决策与回溯:选最小代价的前驱,更新状态,重复 Step 3,直到空状态
- 输出计划:反转移除顺序
总结:TriAT 是一次性的基建工作,枚举器是总指挥,MLP 是枚举器的顾问------枚举器每面临一个岔路口就询问 MLP "这条路代价多少",然后做出贪心决策。
六、完整执行流程(端到端串讲)
现在我们把所有模块串联起来,看看 NeuSO 从接收查询到输出计划的完整流程:
用户输入 CQL
↓
Parser 解析 → 生成查询图 Q(Query Graph)
↓
┌─────────────────────────────────────────────────┐
│ NeuSO 优化器 │
│ │
│ 1. Filter:快速统计候选集大小 |C(u)|, |C(u₁,u₂)| │
│ ↓ │
│ 2. 特征组装:标签 embedding ⊕ 候选集统计 │
│ ↓ │
│ 3. TriAT 编码:在查询小图上运行 GNN │
│ (吸收大图统计信息 + 捕获三角形拓扑结构) │
│ ↓ │
│ 4. 枚举器自顶向下搜索: │
│ - 每步提取子查询特征(Pooling) │
│ - MLP_cost + MLP_mc 预测代价 │
│ - 贪心选择最优前驱 │
│ ↓ │
│ 5. 反转移除顺序 → 输出最优 Join 顺序 │
└─────────────────────────────────────────────────┘
↓
执行引擎:按 Join 顺序在数据图上 DFS + 回溯 + 剪枝搜索
↓
返回匹配结果关键认知 :NeuSO 本身不执行子图匹配。它只是一个"导航系统"------学习"什么 Join 顺序能让搜索树最小",然后输出最优路线。真正开车的是底层的图匹配执行引擎(Enumerator/Executor),它按照 NeuSO 给出的顺序在数据图上做 DFS + 回溯 + 剪枝搜索。
七、训练策略与数据构造
7.1 训练数据生成
NeuSO 的训练数据来自真实数据图和从中抽取的查询图:
- 从数据图中随机抽取连通子图作为查询图 Q(大小 4~32 个顶点)
- 对于每个 Q,使用 Filter 生成候选集统计
- 对于 Q 的每个连通子查询 q ,真实执行并记录:
- 基数(cardinality):q 在数据图中的匹配数
- 单步代价(cost):从 q 到 q+{v} 的执行耗时
- 最小总代价(MC):到达 q 的最优路径代价(通过 DP 精确计算或搜索得到)
- 训练集 / 测试集按查询图划分(而非子查询划分,避免数据泄露)
7.2 损失函数
三个任务各有损失,联合优化:
- 基数预测:Q-error 损失(预测值与真实值的比值取对数)
- 代价预测:MSE 或 Q-error
- 最小总代价预测:MSE
总损失 = λ₁ · L_card + λ₂ · L_cost + λ₃ · L_mc
通过反向传播,TriAT 编码器和三个 MLP 同时更新。
7.3 训练技巧
- 标签预训练:在标签增强图上用 ProNE(稀疏矩阵分解 + embedding 传播)预训练标签 embedding
- 梯度裁剪与学习率调度:防止训练不稳定
- 批处理:按查询图级别批处理(同一查询图的子查询在同一批中)
八、实验与评估
8.1 实验设置
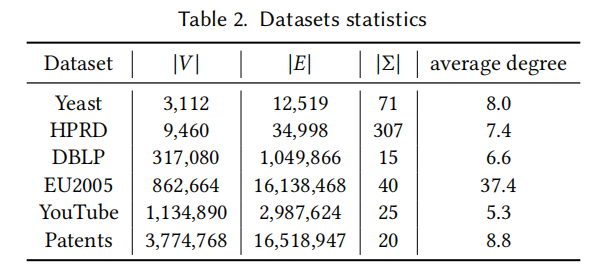
数据集:六个真实数据集,覆盖生物网络、社交网络、Web 图、引文网络等不同领域:
| 数据集 | 领域 | 节点数 | 边数 | 标签数 | 平均度 |
|---|---|---|---|---|---|
| Yeast | 生物 | 3,112 | 12,519 | 71 | 8.0 |
| HPRD | 生物 | 9,460 | 34,998 | 307 | 7.4 |
| DBLP | 社交 | 317K | 1.05M | 15 | 6.6 |
| EU2005 | Web | 863K | 16.1M | 40 | 37.4 |
| YouTube | 社交 | 1.13M | 2.99M | 25 | 5.3 |
| Patents | 引文 | 3.77M | 16.5M | 20 | 8.8 |
此外,还在 LSQB(有向边标签基准,1130 万节点 / 6620 万边)上进行了扩展实验。
查询图:大小 4、8、16、24、32 个顶点,分稀疏和稠密两类。每个类别约 200 个查询。Q4--Q24 的 80% 作为训练集,剩余 20% + 全部 Q32 作为测试集(测试模型对未见大查询的泛化能力)。
硬件:Intel Xeon Gold 6326, NVIDIA A100 40GB GPU, 256GB RAM, Ubuntu 20.04。
8.2 对比基线
| 基线 | 类型 | 策略 |
|---|---|---|
| QSI | 静态启发式 | 基于边权重的排序 |
| GQL | 静态启发式 | 最小候选集优先 |
| RI | 静态启发式 | 最大化新产生连接数 |
| RM (RapidMatch) | 静态启发式 | 区域分解排序 |
| DPiso | 动态规划 | 基于候选集/路径大小的 DP |
| RLQVO | 学习型(RL+GCN) | 唯一先前的学习型子图查询优化器 |
公平对比原则:所有方法使用完全相同的 Filter(GQL)和执行引擎(QSI) ,仅匹配顺序不同。差异完全来自优化器的质量。
8.3 核心实验结果
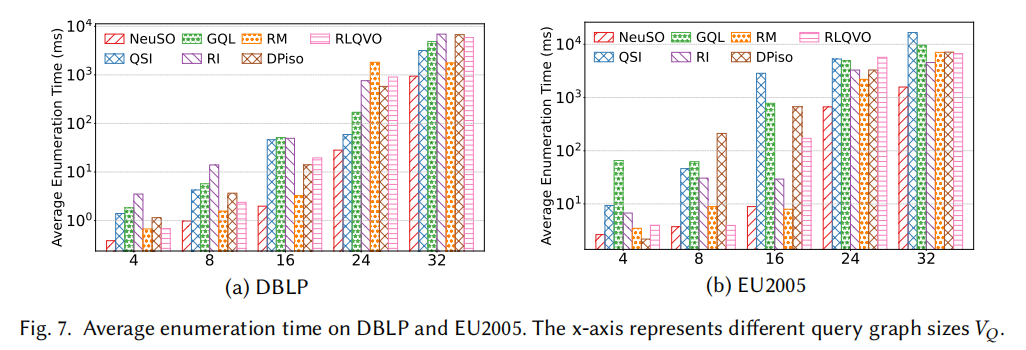
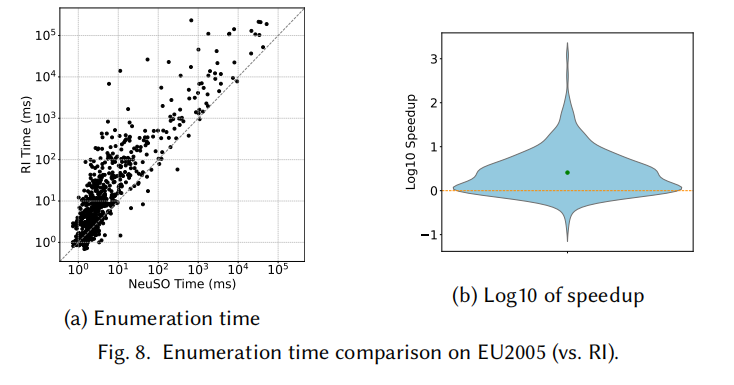
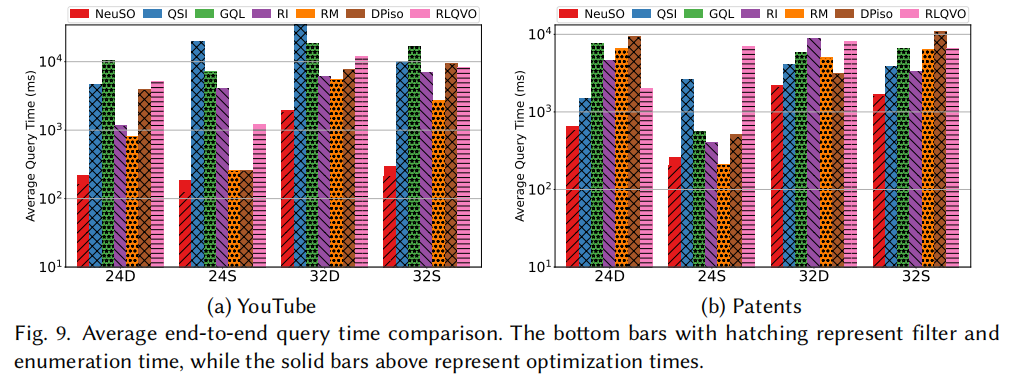
枚举时间加速
NeuSO 生成的匹配顺序在所有 6 个数据集上全面优于所有基线方法:
- 相比启发式方法加速:1.63× ~ 47.93×
- 相比 RLQVO(唯一学习型基线):在 DBLP 上加速 4.40× ~ 11.62×(大查询差距更大,因为 RLQVO 不看子查询整体结构)
- 最大收益出现在大查询(Q24、Q32)上,正是传统方法状态爆炸最严重的区域
优化开销
NeuSO 的在线推理时间:
| 查询大小 | Q4 | Q8 | Q16 | Q24 | Q32 |
|---|---|---|---|---|---|
| NeuSO | 9.49 ms | 18.22 ms | 35.71 ms | 56.38 ms | 82.55 ms |
| RLQVO | 12.94 ms | 24.18 ms | 49.14 ms | 81.88 ms | 125.48 ms |
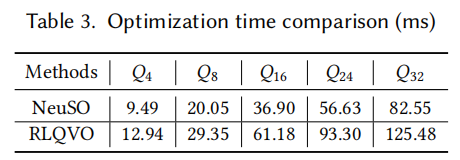
NeuSO 在所有规模上优化耗时都更短,且远低于查询执行耗时(秒级到数十秒),完全满足实时要求。
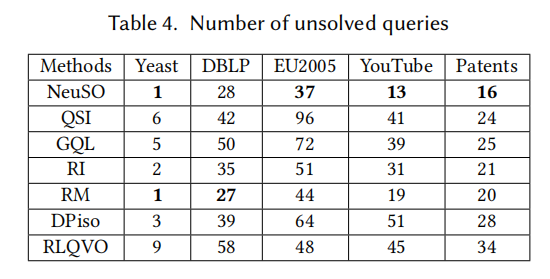
超时查询数量(>350s 未完成)
NeuSO 在大多数数据集上超时最少:
| 方法 | Yeast | DBLP | EU2005 | YouTube | Patents |
|---|---|---|---|---|---|
| NeuSO | 1 | 28 | 37 | 13 | 16 |
| QSI | 6 | 42 | 96 | 41 | 24 |
| GQL | 5 | 50 | 72 | 39 | 25 |
| RI | 2 | 35 | 51 | 31 | 21 |
| RM | 1 | 27 | 44 | 19 | 20 |
| DPiso | 3 | 39 | 64 | 51 | 28 |
| RLQVO | 9 | 58 | 48 | 45 | 34 |
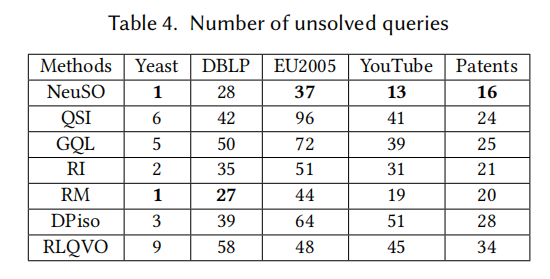
这说明 NeuSO 生成的计划不仅更快,而且更稳定------避免了启发式方法在某些极端查询上"翻车"的窘境。
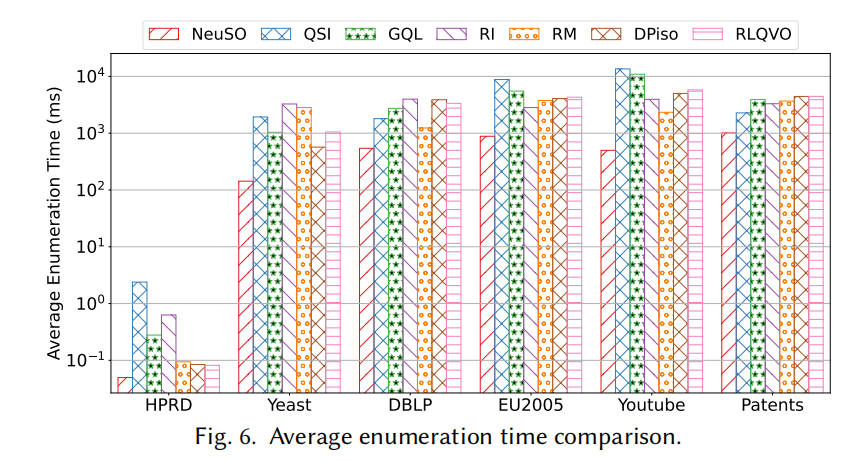
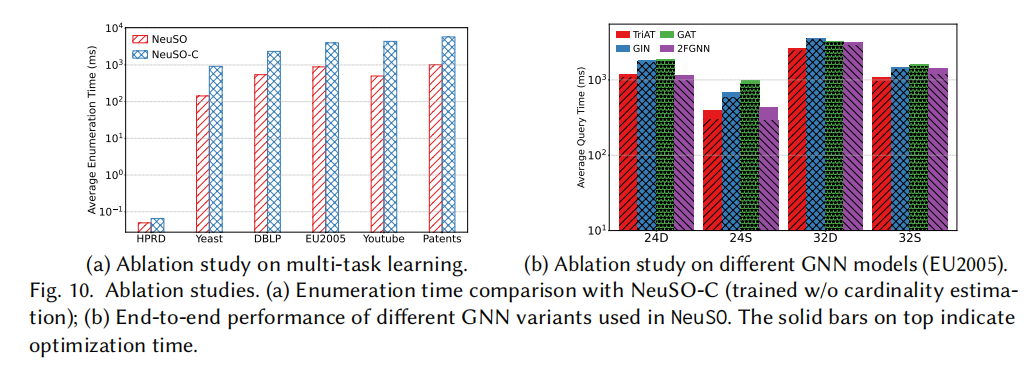
8.4 消融实验
多任务学习的重要性
| 配置 | vs NeuSO(完整) |
|---|---|
| NeuSO-C(仅学习代价,无基数监督) | NeuSO 加速 1.31× ~ 8.78× |
联合学习基数和代价能显著提升子查询表示的质量和鲁棒性。
GNN 编码器的选择
| 编码器 | 表达能力 | 效果 |
|---|---|---|
| GIN | 1-WL | 基线,效果最差 |
| GAT | 1-WL | 略好于 GIN |
| TriAT | 1-WL < TriAT < 2-FWL | 最优 |
| 2FGNN | 2-FWL | 准确率与 TriAT 接近,但计算耗时最高达 8.16×,且有时产生次优计划 |
关键发现:"过度的结构感知未必带来更好的优化效果"------2-FWL 的额外表达能力在查询优化任务中可能成为"噪音",而 TriAT 专攻三角形的设计恰恰命中要害。
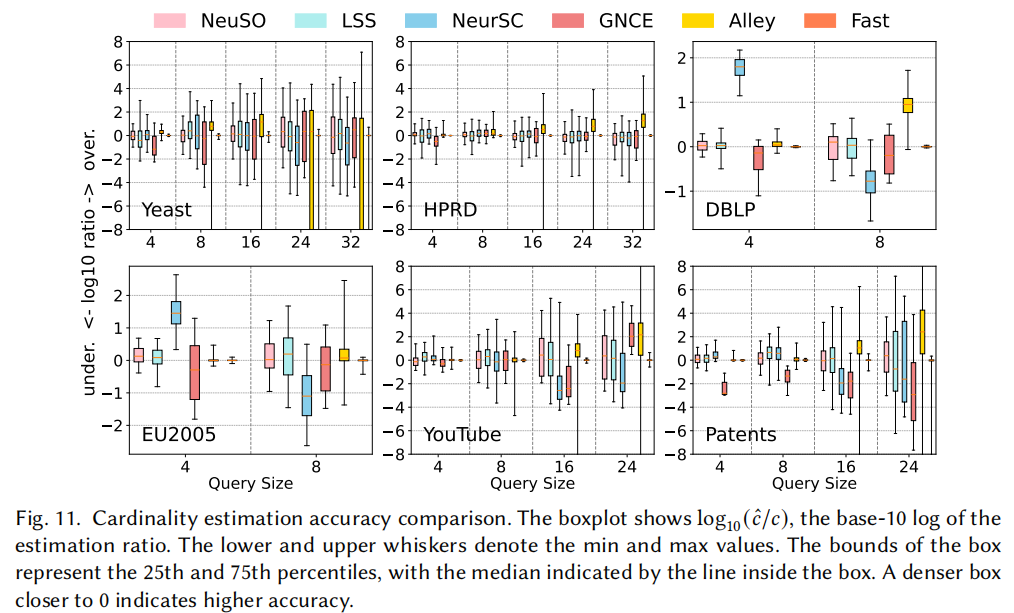
8.5 基数估计精度
在基数估计的对比中,NeuSO 表现优于 LSS、NeurSC、GNCE 等专门设计的子图计数方法。值得注意的是:
- 采样方法(Fast)精度最高但在大查询上存在采样失败问题
- NeuSO 相比 Fast 实现了 1.75× ~ 222.12× 的速度提升(且无需采样)
8.6 LSQB 集成实验
为了验证实用性,论文将 NeuSO 集成到开源图数据库 Kùzu 0.10.0 中:
- NeuSO 生成的计划比 Kùzu 内置 DP 优化器的计划执行快 1.31×
- 优化本身比 Kùzu 的优化器快 1.41×
这证明了 NeuSO 不仅是一个学术原型,可以真正集成到工业级图数据库系统中。
8.7 鲁棒性与迁移性
图更新(动态图):
- 更新比例 ≤ 10% 时:NeuSO 仍能生成高质量计划
- 更新比例 > 10% 时:性能下降,需要重新训练
- 这是当前方法的局限性之一,论文将在线自适应作为未来工作
工作负载迁移:
- 当训练集与测试集的查询大小分布不同时(如训练集以小查询为主、测试集以大查询为主),NeuSO 的估计仍保持稳定
- 而 LSS、NeurSC、GNCE 等方法在负载偏移时系统性地低估大查询的基数
九、可扩展性与讨论
9.1 其他匹配语义
论文的核心设计不限于子图同构(Isomorphism)语义,可以通过简单调整支持:
- 同态匹配(Homomorphism,用于 SPARQL/RDF):移除执行引擎中的单射性检查,重新采集训练数据,模型自动适应
- Cypher 匹配(Cyphermorphism):类似调整
9.2 有向图与边标签
现实中的图很多是有向且带边标签的(如知识图谱中的"转账""任职"等关系):
- 方向处理:TriAT 将邻居拆分为"出边邻居"和"入边邻居",分别使用独立的聚合函数
- 边标签:将边标签做 one-hot 或 embedding 编码,拼接到边特征中
论文在 LSQB 基准(天然带方向和边标签)上成功验证了扩展的有效性。
9.3 对关系型数据库的适用性
NeuSO 不能直接用于传统关系型数据库,原因有三:
- 输入特征不同:NeuSO 依赖图特有的 Filter 统计作为初始特征,关系型数据库的基数估计更关注单表选择率和复杂 WHERE 谓词
- 拓扑结构不同:TriAT 专攻三角形结构,而关系型 Join 查询大多是星型或雪花型,环状 Join 较少
- 执行计划形态不同:NeuSO 输出顶点匹配顺序,关系型数据库需要选择 Left-deep/Bushy tree 以及物理算子(Hash Join / Nested-Loop / Merge Join)
不过,关系型数据库领域有自己的学习型优化器(如 Bao、LOGER、JGMP),它们与 NeuSO 的理念相通但设计不同。
十、总结与展望
10.1 论文核心贡献
- 首个端到端的子图查询神经优化器:同时学习基数和代价,能直接输出高质量执行计划
- TriAT 图编码器:三角形感知注意力机制,突破传统 MPNN 的 1-WL 天花板,表达能力为 1-WL < TriAT < 2-FWL
- 自顶向下枚举器:用最小总代价(MC)作为启发式函数,将指数级搜索降到多项式级
- "大图信息搬小图"的巧妙设计:Filter 统计 + 特征组装 + TriAT 消息传递,避免在大图上跑 GNN
- 全面的实验验证:6 个数据集 + LSQB,枚举加速最高 47.93×,优化开销仅数十毫秒
10.2 方法论启示
这篇论文的方法论对做"AI + 数据库"方向的研究者很有启发:
- 不一定要端到端黑盒:NeuSO 保留了 Filter、Pooling、枚举器等结构化组件,神经网络只负责其中最难的"预测"部分
- "够用"的表达能力比"最强"更好:2-FWL 理论上更强但实际效果未必好,TriAT 针对三角形做文章反而最有效
- 多任务学习在系统优化中的价值:基数 + 代价联合学习相互增强,比独立训练更鲁棒
10.3 局限性
- 训练数据需要真实执行采集,初始训练成本较高(但这是一次性的)
- 对图更新敏感,超过 10% 的结构变化需要重训练(论文将其列为未来工作)
- 目前仅支持无向标签图上的子图同构语义(虽然有扩展讨论,但未在实验中大规模验证)
- 在极大规模的稠密查询图(如 64+ 顶点完全图)上的表现尚未探索
10.4 未来工作方向
论文指出的未来方向包括:
- 加权图与时间图:将 TriAT 扩展到带权边和时序图查询
- 在线自适应:处理动态图更新而无需完全重训练
- 分布式集成:与分布式图处理引擎结合
- 跨领域迁移:将多任务学习框架应用于关系型 Join 优化
附录:关键概念速查表
| 概念 | 一句话解释 |
|---|---|
| 子图查询 | 在大图中找出所有与查询小图匹配的子结构 |
| CQL / Cypher | 图数据库查询语言(类比 SQL) |
| Join Order / Matching Order | 匹配顶点的顺序,决定执行效率 |
| 候选集 C(u) | 数据图中可能匹配查询节点 u 的顶点集合 |
| 基数 Cardinality | 某子查询在数据图中的匹配数(中间结果集大小) |
| 单步代价 Cost | 从子查询扩展一个节点的执行耗时 |
| 最小总代价 MC | 从空状态到达某子查询的理论最优路径代价 |
| 1-WL 测试 | 图同构测试算法,也是所有 MPNN 的表达能力上限 |
| TriAT | 三角形感知注意力网络,能识别邻居之间的连线 |
| MLP | 多层感知机,最基础的前馈神经网络 |
| CCG | 基数-代价状态图,所有连通子查询状态及其转移 |
| 自底向上枚举 | 传统 DP:从小状态逐步构建到大状态 |
| 自顶向下枚举 | NeuSO:从完整查询逐步回溯到空状态 |
| Pooling | 将多个节点的特征向量聚合为一个图表征 |
文档说明:本文基于对 NeuSO 论文原文(arXiv:2509.23775,SIGMOD 2026)的深入阅读与分析整理而成,采用了"问题驱动 + 概念拆解 + 逐步串联"的引导式结构,适合第一次接触图查询优化和 GNN 交叉领域的读者。文中所有技术细节均来自论文正文及附录,实验数据来自论文第 6 节。