摘要
大模型重构数据消费模式,AI 发起的数据分析将成主流。但行业普遍采用的 "AI 直连数据仓库" 模式,存在性能灾难、安全失控、质量不可信、治理缺失四大系统性缺陷。本文以 Spring AI Alibaba DataAgent 为实践案例,梳理 AI 访问数仓的六大核心形态,对比直连与微服务化模式的适用边界,为传统 Spring Cloud 企业提供最小侵入式升级方案与 AI 可调用 API 设计规范。
引言
据 Gartner 预测,2026 年超 70% 的企业数据分析请求将由 AI 发起,数据消费模式从 "人找数据" 彻底转向 "AI 找数据"。
这一转变给企业数据基础设施带来巨大挑战。当前主流的 "AI 直连数仓" 模式看似简单快速,但上线 3 个月后普遍暴露出四大问题:AI 生成低效 SQL 拖垮数仓、粗粒度权限导致数据泄露、脏数据使 AI 输出失真、缺乏统一管控引发调用混乱。
本文系统梳理 AI 访问数仓的六大形态,建立选型标准;重点讲解微服务化模式如何解决直连痛点,以 DataAgent 为例详解两种模式的落地步骤;针对传统 Spring Cloud 企业提供平滑升级方案,并制定 AI 可调用 API 的标准化规范。
一、AI 访问数据仓库的六大形态
AI 访问数据仓库的本质是 "AI 作为数据消费者,从数据仓库获取已加工数据进行分析推理"。根据访问路径和治理方式的不同,行业内形成了六种主流形态。
1.1 形态分类总述
- 按访问层级划分 :直连层(直接访问数据库)→ API 层(访问标准化接口)→ 代理层(通过中间代理访问)→ 工具层(复用现有工具能力)
- 按成熟度划分 :POC 级(快速验证)→ 部门级(小范围使用)→ 企业级(生产部署)
1.2 六大形态核心指标
|-----------------|----------------------------------------|------------------------------|-----------------------------------------------------|--------------------------|
| 形态名称 | 核心定义 | 访问路径 | 典型实现 | 适用场景 |
| 直连 JDBC 访问 | AI 通过数据库标准协议直接连接数仓,生成并执行 SQL | AI → JDBC 驱动 → 数仓 | DataAgent 直连、LangChain SQL Database Chain | 快速 POC、小团队内部使用、非核心业务 |
| 数仓原生 API 访问 | 通过云厂商提供的数仓官方 HTTP API 获取数据 | AI → 数仓 HTTP API → 数仓 | Snowflake REST API、阿里云 AnalyticDB API、BigQuery API | 云原生数仓、跨平台调用、无数据库驱动场景 |
| 微服务化 API 访问 | 将数仓能力封装为标准化微服务接口,AI 通过服务调用获取数据 | AI → API 网关 → 数据服务 → 数仓 | Spring Cloud 数据服务、DataAgent+Spring AI 工具调用 | 企业级生产部署、核心业务数据、高并发访问 |
| 统一查询引擎代理 | AI 连接统一查询引擎,由引擎代理访问多个异构数据仓库 | AI → Trino/Presto → 多数据仓库 | Trino 联邦查询、StarRocks 跨源查询 | 多数据源并存、数据孤岛场景、跨库联合分析 |
| BI 工具 API 访问 | 复用现有 BI 系统的指标计算能力,AI 调用 BI 接口获取已计算好的数据 | AI → BI 工具 API → BI 服务器 → 数仓 | Tableau REST API、Power BI REST API、Quick BI OpenAPI | 已有成熟 BI 体系、指标定义统一、无需重复开发 |
| 向量检索访问 | 通过向量相似度检索,从支持向量存储的数仓中获取语义相关数据 | AI → 向量检索 API → 向量数仓 | ClickHouse 向量引擎、StarRocks 向量索引、PostgreSQL+pgvector | RAG 知识库、语义搜索、非结构化数据检索 |
1.3 选型决策 速览
- 短期 POC 验证 :优先选择直连 JDBC 或 BI 工具 API,1-2 天即可完成部署
- 长期生产部署 :优先选择微服务化 API 访问,安全可控且可扩展性强
- 多数据源场景 :优先选择统一查询引擎代理,解决数据孤岛问题
- 语义查询场景 :优先选择向量检索访问,支持更智能的自然语言理解
二、微服务化 API 访问
2.1 AI 直连数据仓库的本质性痛点
AI 直连模式看似简单快速,却存在四个无法通过提示工程或模型优化解决的根本性问题:
- 性能灾难 :AI 生成低效 SQL(全表扫描、多表嵌套),其高并发随机查询与数仓 T+1 批处理架构不匹配,易拖垮数仓,阻塞正常 ETL 和报表任务。
- 安全失控 :直接给 AI 开数仓账号等于暴露全量数据。传统数仓仅支持库 / 表级权限,无法实现行 / 列级细粒度隔离,也缺乏 AI 操作审计能力。
- 质量不可信 :数仓中的脏数据、重复数据、不一致数据直接输入 AI,AI 无法区分数据可信度,导致 "垃圾进垃圾出",输出错误且不可追溯。
- 治理缺失 :缺乏统一入口和管控机制,各业务线 AI 应用各自直连数仓。无法进行流量控制、熔断降级和全链路监控,单点故障易扩散至整个数据平台。
2.2 微服务化 API 访问的核心理念
微服务化 API 访问的核心是 "数据即服务(DaaS)",将数据仓库的查询、计算、分析能力封装为标准化的 RESTful 微服务接口。所有上层应用(包括 AI)只能通过这些接口访问数据,不能直接连接数据仓库。
其核心设计理念包括:
- 治理上移 :将数据治理规则从数仓层上移至服务层,实现更细粒度、更灵活的管控
- 统一入口 :所有数据访问必须通过 API 网关进行,实现集中式治理
- 能力解耦 :数据消费与数据生产完全分离,数据仓库只负责存储和计算,数据服务负责业务逻辑和数据治理
- 弹性伸缩 :数据服务可以独立扩容,应对 AI 的高并发查询需求
2.3 分层架构原理
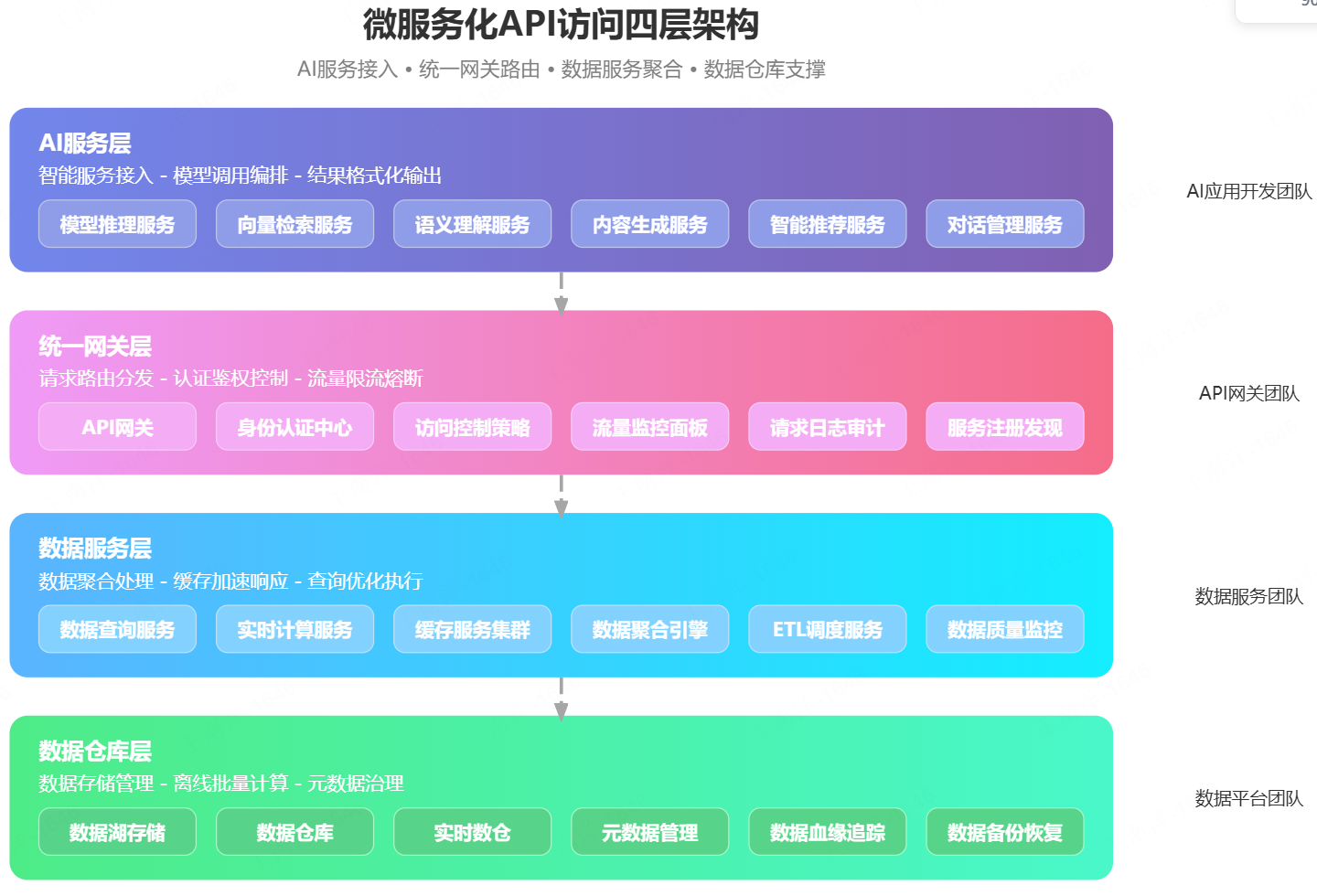
- AI 服务层 :负责自然语言理解、意图识别、工具调用和结果生成
- 统一网关层 :提供统一入口,实现鉴权、限流、熔断、路由和日志审计
- 数据服务层 :按业务域划分,负责数据清洗、校验、转换和业务逻辑封装
- 数据仓库层 :负责数据的存储、计算和管理,只对数据服务层暴露接口
2.4 核心治理能力原理
微服务化架构为 AI 数据访问提供了完整的治理能力:
- 接口级权限控制 :基于 OAuth2.0 实现细粒度的接口权限控制,支持行级、列级数据隔离
- 流量整形 :通过网关层的限流和熔断机制,平滑 AI 的突发流量,保护数仓稳定性
- 数据质量前置 :在数据服务层统一进行数据清洗、校验和转换,保证输出的数据都是高质量的
- 全链路可观测 :通过 Micrometer 和 SkyWalking 实现全链路监控,追踪每一次数据访问的完整链路
三、模式一:AI 直连数据仓库(DataAgent 原生模式)
DataAgent 是阿里云的开源项目,具备完整思考、分析、执行和报告生成能力的虚拟 AI 数据分析师平台。其原生支持直连数据仓库模式,是企业快速验证 AI 数据分析价值的最佳选择。
3.1 模式定义与适用场景
- 定义 :AI 直接通过 JDBC 连接数据仓库,复用数仓原生的权限、审计和资源管控能力
- 核心优势 :部署速度极快、运维成本极低、功能完整开箱即用
- 适用场景 :
- 1-2 周内快速验证 AI 数据分析的业务价值
- 小团队内部使用
- 非核心业务数据,无敏感信息
- 数据量较小(单表 < 100 万行,查询复杂度低)
3.2 架构设计图
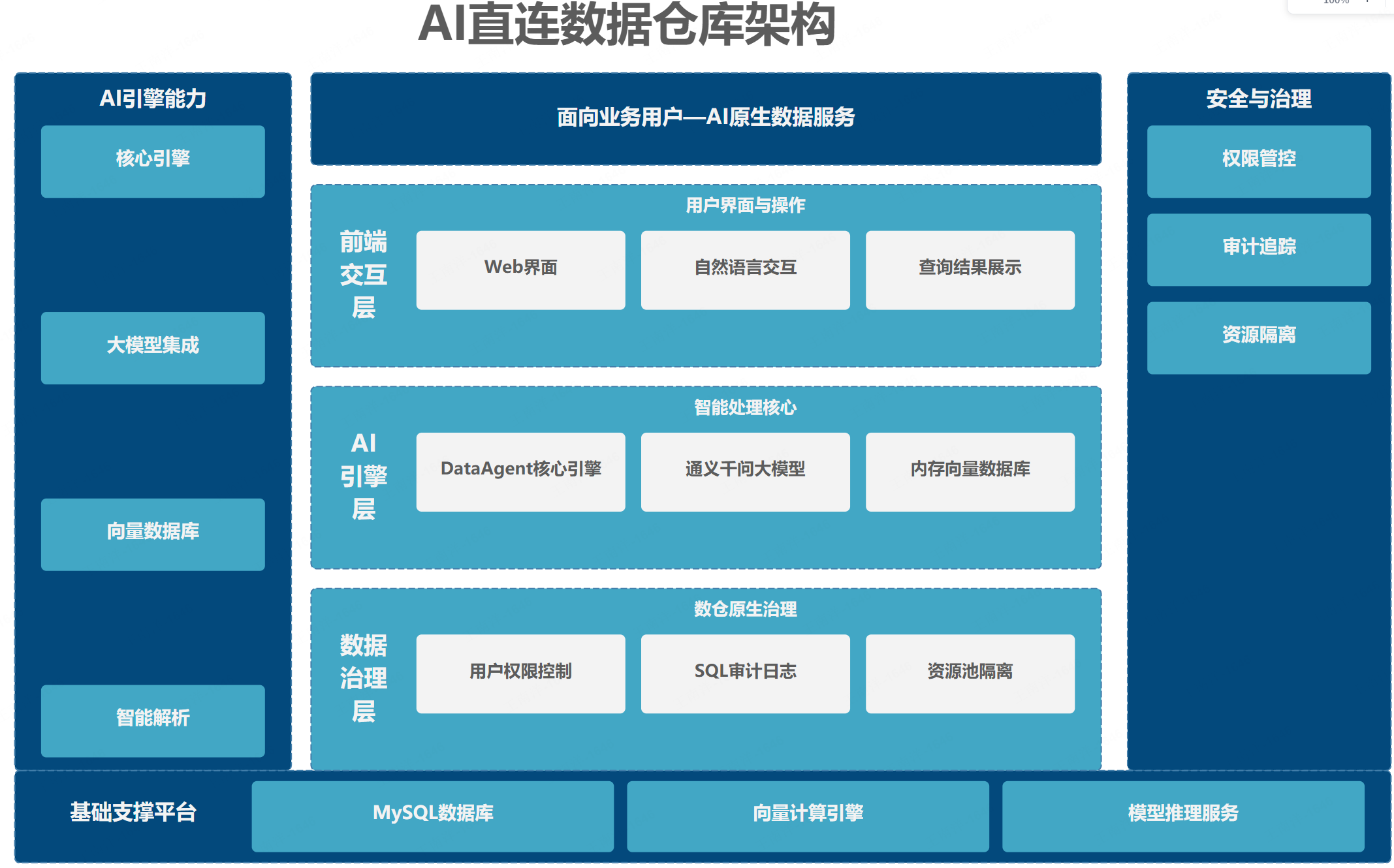 3.3 核心能力与执行流程
3.3 核心能力与执行流程
DataAgent 直连模式的执行流程如下:
- 元数据自动发现 :DataAgent 自动读取数据仓库的表结构、字段信息和数据类型
- 元数据向量化 :将表结构和字段描述向量化存入向量数据库
- 自然语言理解 :用户输入问题后,大模型解析用户意图
- Schema 召回 :通过向量检索找到与问题相关的表和字段
- NL2SQL 生成 :大模型根据召回的 Schema 生成 SQL 语句
- SQL 安全校验 :DataAgent 内置 SQL 安全引擎,过滤 DROP、DELETE 等危险操作
- 数据查询 :执行 SQL 查询数据仓库
- 结果生成 :大模型根据查询结果生成自然语言回答和可视化图表
3.4 快速落地步骤
见文档:DataAgent
3.5 优缺点与局限性分析
- 优点 :
- 运维成本低,无需额外部署中间件
- 功能完整,支持自然语言查询、图表生成和报告导出
- 缺点 :
- 性能风险高,AI 生成的低效 SQL 可能拖垮数仓
- 安全等级低,只能做到表级权限控制
- 可扩展性差,难以支持高并发和多数据源
- 局限性 :
- 无法实现行级、列级数据脱敏
- 表结构变更需要重新初始化元数据和修改提示词
四、模式二:AI 融合微服务底座(DataAgent+Spring Cloud)
当企业完成 POC 验证,需要将 AI 数据分析应用推广到生产环境时,直连模式的局限性就会凸显。此时,采用 "DataAgent+Spring Cloud" 的微服务化架构,是构建安全、稳定、可控的企业级 AI 数据访问平台的最佳选择。
4.1 模式定义与适用场景
- 定义 :AI 不直接连接数据仓库,而是通过 Spring Cloud 微服务接口获取数据。所有数据治理规则都在服务层统一实施。
- 核心优势 :安全可控、性能稳定、可扩展性强、可维护性好
- 适用场景 :
- 企业级生产部署
- 核心业务数据,包含敏感信息
- 多数据源并存,数据分散在多个系统
- 长期演进需求,需要持续迭代和扩展功能
4.2 架构设计图
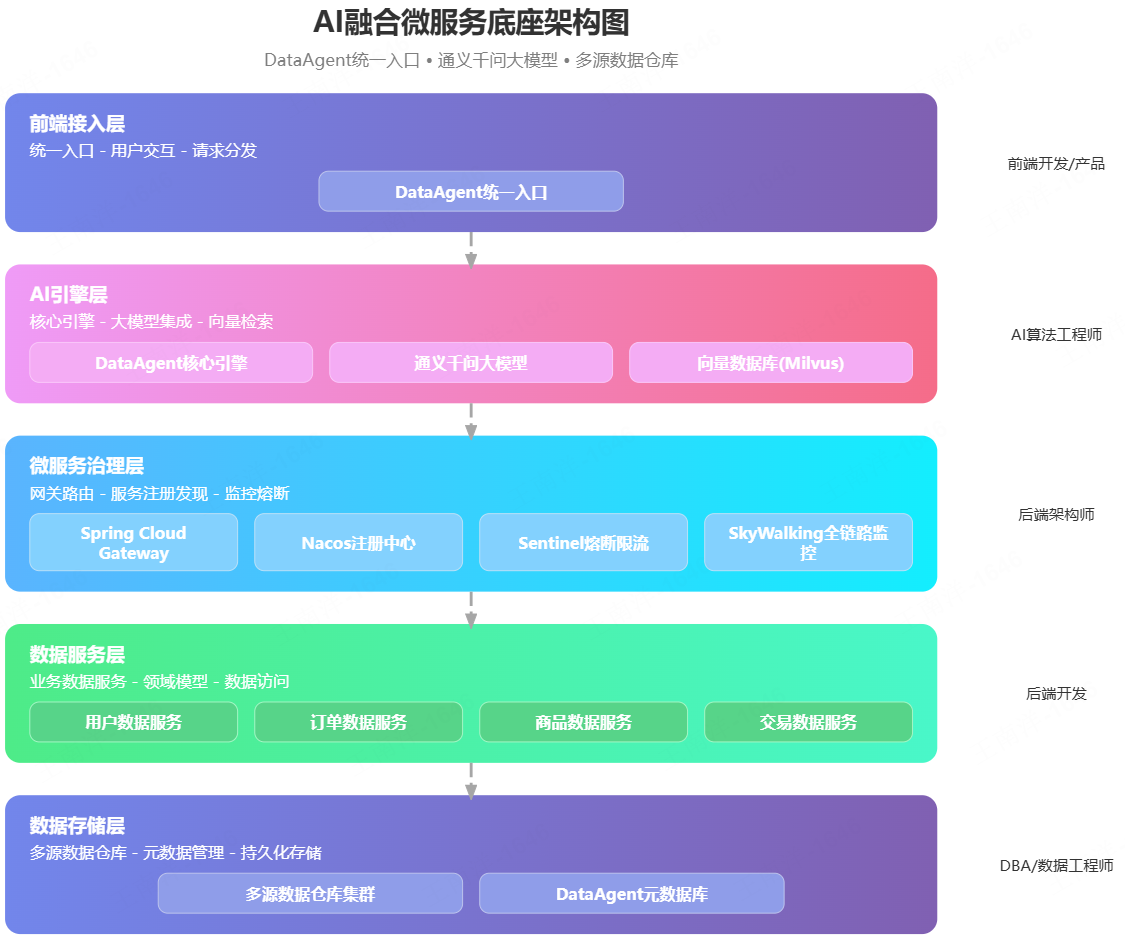
核心设计:AI 不直接连接数据仓库,所有数据请求通过 Spring Cloud 网关统一管控,复用微服务生态的所有治理能力。
4.3 核心能力与执行流程
微服务化模式的执行流程与直连模式有本质区别:
- 自然语言理解 :用户输入问题后,大模型解析用户意图
- 工具检索 :通过向量检索找到与问题相关的数据服务接口
- 参数生成 :大模型根据接口文档自动生成调用参数
- 服务调用 :DataAgent 通过 Spring AI 工具调用机制,调用对应的数据服务接口
- 网关治理 :请求经过网关,进行鉴权、限流、熔断和日志审计
- 数据处理 :数据服务层完成数据清洗、校验、转换和业务逻辑处理
- 数据查询 :数据服务执行优化后的 SQL 查询数据仓库
- 结果返回 :数据服务将标准化的结果返回给 DataAgent
- 报告生成 :大模型根据返回结果生成自然语言回答和可视化图表
4.4 关键技术实现
4.4.1 Spring AI 工具调用
将数据服务接口注册为 Spring AI 可调用的工具,是实现 AI 自动调用微服务的核心:
java
@Configuration
public class AiToolConfig {
@Bean
@Tool(
name = "getOrderStatistics",
description = "统计指定时间段内的订单总金额,按天返回。" +
"参数说明:startDate-开始日期,格式yyyy-MM-dd;endDate-结束日期,格式yyyy-MM-dd"
)
public Function<TimeRangeRequest, Result<List<OrderStatisticsVO>>> getOrderStatisticsTool(
OrderFeignClient orderFeignClient) {
return request -> orderFeignClient.getOrderStatistics(
request.getStartDate(),
request.getEndDate());
}
}4.4.2 OpenFeign 服务集成
DataAgent 通过 OpenFeign 调用数据服务接口:
java
@FeignClient(name = "order-data-service")
public interface OrderFeignClient {
@GetMapping("/api/order/statistics")
Result<List<OrderStatisticsVO>> getOrderStatistics(
@RequestParam @DateTimeFormat(pattern = "yyyy-MM-dd") String startDate,
@RequestParam @DateTimeFormat(pattern = "yyyy-MM-dd") String endDate);
}4.4.3 网关统一治理
在 Spring Cloud Gateway 中配置统一的路由和治理规则:
XML
spring:
cloud:
gateway:
routes:
# 订单数据服务路由(AI调用的核心业务接口)
- id: order-data-service
uri: lb://order-data-service # 负载均衡到Nacos注册的服务实例
predicates:
- Path=/api/order/** # 匹配所有订单相关请求
filters:
# 1. 身份令牌透传:将前端JWT传给后端,实现细粒度接口权限控制
- name: TokenRelay
# 2. AI专用限流:防止AI突发高并发拖垮数据服务和底层数仓
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 20 # 每秒稳定允许20个请求
redis-rate-limiter.burstCapacity: 50 # 最多允许50个突发请求(应对AI批量查询)
# 3. 服务熔断:数据服务异常时快速降级,避免级联故障拖垮整个系统
- name: CircuitBreaker
args:
name: orderServiceCircuitBreaker
fallbackUri: forward:/fallback/order # 熔断时返回的降级接口五、传统微服务向 AI 数据访问模式的过渡升级
对于绝大多数已经拥有传统 Spring Cloud 微服务体系的企业,无需推翻现有架构从零开始。在不影响现有业务运行的前提下,采用平滑升级方案,逐步实现 AI 数据访问能力。
5.1 传统微服务的 AI 适配性缺陷
传统微服务接口是面向人类开发者设计的,存在以下 AI 适配性问题:
- 接口语义不清晰 :大量使用缩写和行业黑话,AI 难以理解
- 参数结构复杂 :多层嵌套对象,AI 难以正确生成参数
- 返回格式不统一 :不同服务的返回格式千差万别,AI 难以统一解析
- 元数据不完整 :OpenAPI 文档缺失或描述不准确,AI 无法了解接口用途
- 缺乏 AI 专项治理 :没有针对 AI 调用的限流、熔断和监控策略
5.2 最小侵入式升级原则
- 不修改现有业务代码 :所有改造都通过新增层或配置实现
- 不影响现有业务运行 :升级过程中现有业务系统不受任何影响
- 复用现有基础设施 :充分利用已有的 Nacos、Sentinel、Gateway 等组件
- 渐进式改造 :先改造核心业务域,再逐步推广到其他域,边验证边推广
5.3 分阶段过渡升级路径
|--------------|--------------------------------------|-----------------|----------|
| 阶段 | 核心任务 | 改造范围 | 业务影响 |
| 阶段一:AI 接入层搭建 | 部署独立 AI 服务、配置 Spring AI、集成 DataAgent | 新增 AI 服务,无侵入 | 无 |
| 阶段二:存量接口封装 | 对高频 AI 调用的存量接口进行包装,补充元数据 | 新增 Facade 包装层 | 无 |
| 阶段三:治理能力增强 | 新增 AI 专用限流熔断规则、添加数据质量校验 | 网关层 + 数据服务层新增逻辑 | 无 |
| 阶段四:专项优化 | 针对 AI 调用特征优化 SQL、添加热点数据缓存 | 数据服务层优化 | 性能提升 |
| 阶段五:全面推广 | 逐步将 AI 调用从直连模式迁移至微服务模式 | 全业务线切换 | 体验提升 |
5.4 存量接口的 AI 适配改造方法
对于已有的存量接口,推荐采用以下四种改造方法,按侵入性从低到高排序:
- 补充 OpenAPI 注解 :为接口和参数添加清晰准确的中文描述,这是最简单且最有效的方法
- 网关层转换 :在网关层添加请求 / 响应转换过滤器,将复杂的参数结构转换为扁平结构
- 新增 Facade 层 :在原有接口之上新增一层 Facade 接口,统一返回格式和参数规范
- 新增 AI 专用接口 :对于高频 AI 调用的场景,专门设计符合 AI 调用习惯的专用接口
六、AI 调用微服务 API 的设计规范要求
AI 与人类开发者的思维方式存在本质差异。以下是 AI 可调用接口设计规范。
6.1 接口基础规范
- 必须遵循 RESTful 风格 :使用标准 HTTP 方法,GET 用于查询,POST 用于提交
- 路径命名语义化 :使用完整的英文单词,避免缩写和歧义。例如:/api/order/statistics而非/api/odr/sts
- 接口粒度适中 :一个接口只完成一个明确的查询任务,避免一个接口返回过多无关数据
- 必须是幂等的 :所有查询接口必须支持重复调用,不会产生副作用
- 只读优先 :数据服务接口只提供查询能力,不提供写入能力(写入走业务系统)
6.2 请求参数规范
- 参数必须扁平 :禁止多层嵌套对象,所有参数都放在第一层
html
// 好
{ "startDate": "2026-01-01", "endDate": "2026-01-31" }
// 坏
{ "query": { "timeRange": { "start": "2026-01-01", "end": "2026-01-31" } } }- 使用简单数据类型 :优先使用字符串、数字、布尔值,禁止复杂枚举和自定义类型
- 时间参数格式统一 :统一使用yyyy-MM-dd或yyyy-MM-dd HH:mm:ss格式
- 必须提供默认值 :非必填参数必须提供合理的默认值,减少 AI 的参数生成负担
- 必须有最大值限制 :分页参数的 pageSize 最大不超过 1000,时间范围最大不超过 90 天,防止全表扫描
6.3 返回结果规范
- 必须使用统一的返回格式 :所有接口都必须返回相同结构的结果
html
{
"success": true,
"code": 200,
"message": "操作成功",
"data": { ... },
"timestamp": 1718000000000
}- 数据字段命名语义化 :使用清晰准确的字段名,避免缩写
- 空值统一处理 :空值统一返回null,不返回空字符串、0或特殊标记
- 禁止返回冗余字段 :只返回 AI 需要的数据,不返回业务无关的内部字段
- 数据量控制 :单个接口返回的数据量不超过 1000 条,超过时必须分页
6.4 元数据规范
- 必须提供完整的 OpenAPI 文档 :所有接口都必须生成 Swagger/OpenAPI 文档
- 描述必须清晰准确 :接口、参数、返回字段都必须有详细的中文描述,说明其含义和取值范围
- 必须提供调用示例 :每个接口都必须提供至少一个成功调用的示例
- 必须标注参数必填性 :明确标注哪些参数是必填的,哪些是可选的
- 定期更新元数据 :接口变更时必须同步更新 OpenAPI 文档
6.5 错误处理规范
- 错误码统一 :使用全局统一的错误码体系,含义明确
- 错误信息具体 :错误信息必须具体明确,便于 AI 理解和处理。例如:"查询时间范围不能超过 90 天" 而非 "参数错误"
- 区分可重试错误 :对于网络超时、服务不可用等可重试错误,返回明确的重试建议
- 禁止返回内部细节 :错误信息中禁止包含堆栈信息、数据库表名等系统内部细节
七、核心复习要点
- AI 访问数据仓库 6 种形态 :直连 JDBC、数仓原生 API、微服务化 API(企业首选)、统一查询引擎代理、BI 工具 API、向量检索
- AI 直连的 4 大痛点 :性能灾难、安全失控、质量不可信、治理缺失
- 微服务化的核心理念 :数据即服务、治理上移、统一入口、能力解耦
- 两种模式核心区别 :
- 直连模式:AI→数仓,快但不稳,适合 POC 验证
- 微服务模式:AI→网关→数据服务→数仓,稳且安全,适合生产部署
- 传统微服务升级原则 :最小侵入、渐进式、不影响现有业务
- AI 调用 API 的 5 大规范 :RESTful 风格、扁平参数、统一返回、完整元数据、标准错误处理
总结
AI 与数据仓库融合是企业数字化转型的必然趋势,技术无优劣,关键在适配。直连模式适合快速验证 AI 价值,微服务化模式适合企业级生产部署,"先直连验证、后微服务演进" 是绝大多数企业的理性选择。
DataAgent 原生支持两种模式,提供从 POC 到生产的完整路径。遵循本文的接口规范与升级方案,企业可在不重构现有架构的前提下,安全高效地实现 AI 数据访问能力,释放数据价值。
📚 我的技术博客导航:点击进入一站式查看所有干货