PyTorch强化学习实战(14)------优先经验回放机制
0. 前言
经验回放 (Experience Replay) 通过打破样本间的时序相关性,极大地稳定了训练过程,使深度Q网络 (Deep Q-Network, DQN)能够从非平稳分布中高效学习。然而,传统经验回放采用均匀采样策略,对所有经验样本一视同仁,这引发了一个关键问题:是否所有经验都具有同等价值?2015 年,DeepMind 的研究团队发表了《Prioritized Experience Replay》,提出了一种全新的采样机制------优先级经验回放。该方法的核心是:强化学习算法可以从更重要、更有价值的经验中学习得更快、更好。论文通过将优先采样机制引入 DQN,不仅在 Atari 2600 游戏中取得了显著超越基准的效果,更重要的是,它为后续几乎所有深度强化学习算法提供了重要的性能加速组件。本节将深入探讨优先经验回放机制,解析 优先经验回放机制的原理、实现方案,并与经典 DQN 进行性能对比。
1. 优先经验回放缓冲区
2015 年,论文《Prioritized experience replay》提出了提升深度Q网络 (Deep Q-Network, DQN)训练效率的优先经验回放 (Prioritized experience replay)。该方法通过根据训练损失为缓存样本分配优先级,显著提高了回放缓冲区中样本的利用效率。
基本 DQN 使用回放缓冲区来旨在消除回合中连续转移样本之间的相关性。由于环境具有"平滑"特性(即智能体行为通常不会引发环境剧烈变化),同一回合中的经验样本往往存在高度关联性。然而随机梯度下降 (Stochastic Gradient Descent, SGD) 方法要求训练数据满足独立同分布 (independent and identically distributed, i.i.d) 特性。为了处理这个问题,经典 DQN 的解决方案是使用一个大的转移缓冲区,并通过均匀随机采样获取训练批次。
论文作者对这种均匀随机采样策略进行改进,并证实:根据训练损失为缓存样本设置优先级,再按优先级比例进行采样,能显著提升 DQN 的收敛速度与策略质量。该方法的核心思想可概括为"重点学习非常规的数据"。关键在于平衡"异常样本"与普通样本的训练强度------若过度聚焦缓存中的少数样本,不仅会破坏 i.i.d 特性,还可能导致模型在该子集上过拟合。
从数学角度来看,缓存中每个样本的优先级计算公式为 P ( i ) = p i α ∑ k p k α P(i)=\frac {p_i^\alpha}{\sum_kp_k^\alpha} P(i)=∑kpkαpiα,其中 p i p_i pi 表示第 i i i 个样本的优先级, α α α 为优先级权重系数。当 α = 0 α=0 α=0 时,采样方式退化为经典 DQN 的均匀采样; α α α 值越大,高优先级样本的选取概率就越高。该系数是需要调节的超参数,论文建议的初始值为 0.6。
论文提出了多种优先级定义方案,其中最常用的是使优先级与贝尔曼更新中的样本损失值成正比。新增至缓存的样本会被赋予最高优先级,以确保其能被快速采样。
通过调整样本优先级,我们会引入数据分布偏差(某些转移样本会被更频繁地采样),这需要通过补偿机制来维持随机梯度下降 (Stochastic Gradient Descent, SGD) 的有效性。为此,引入了样本权重系数,将每个样本的损失值乘以对应权重 w i = ( 1 N ⋅ 1 P ( i ) ) β w_i=(\frac 1N·\frac {1}{P(i)})^β wi=(N1⋅P(i)1)β。其中 β β β 是取值 0 到 1 之间的另一超参数:当 β = 1 β=1 β=1 时可完全抵消采样偏差,但实验表明最佳做法是从 0-1 之间的初始值开始,在训练过程中逐步增大至 1,这样更有利于模型收敛。
2. 实现优先经验回放缓冲区
要实现优先经验回放缓冲区,我们需要对经典深度Q网络 (Deep Q-Network, DQN)代码进行以下修改:
- 首先,我们需要一个新的经验回放缓冲区来跟踪优先级,根据优先级采样批次数据,计算权重,并在损失值已知后更新优先级
- 其次需要修改损失函数。不仅需要为每个样本加入权重,还需将损失值传回经验回放缓冲区以调整已采样转移的优先级
我们在 dqn_prio_replay.py 中实现以上修改。为保持简洁,新的优先级回放缓冲区类采用了与先前回放缓冲区非常相似的存储方案。但遗憾的是,优先级的新需求使得无法实现 O ( 1 ) O(1) O(1) 时间复杂度的采样(即采样时间会随缓冲区容量增加而增长)。若使用简单列表存储,每次采样新批次时都需要处理全部优先级数据,这使得采样时间复杂度达到 O ( N ) O(N) O(N),与缓冲区大小成正比。对于 10 万样本量级的小型缓冲区影响不大,但对于现实应用中百万级转移数据的大型缓冲区可能成为问题。
存在其他支持 O ( l o g N ) O(log N) O(logN) 高效采样的存储方案,例如采用线段树数据结构。TorchRL 等库提供了不同版本的优化缓冲区实现,我们也在 lib.experience.PrioritizedReplayBuffer 类中提供了高效优先级回放缓冲区,可以改用该高效版本并观察其对训练性能的影响。
(1) 接下来,我们以基础版本为例,首先定义 β β β 参数的增长率:
python
BETA_START = 0.4
BETA_FRAMES = 100_000(2) β β β 值将在前 10 万帧训练过程中从 0.4 线性增长至 1.0。接下来实现优先级回放缓冲区类:
python
class PrioReplayBuffer(ExperienceReplayBuffer):
def __init__(self, exp_source: ExperienceSource, buf_size: int, prob_alpha: float = 0.6):
super().__init__(exp_source, buf_size)
self.experience_source_iter = iter(exp_source)
self.capacity = buf_size
self.pos = 0
self.buffer = []
self.prob_alpha = prob_alpha
self.priorities = np.zeros((buf_size, ), dtype=np.float32)
self.beta = BETA_START优先级回放缓冲区类继承自简易回放缓冲区 ExperienceReplayBuffer (后者采用环形缓冲区存储样本,可在不重新分配列表空间的情况下保持固定容量)。我们的子类额外使用 NumPy 数组来维护优先级数据。
(3) update_beta() 方法需要定期调用,以便根据调度增加 beta 值。populate() 方法则负责从 ExperienceSource 对象提取指定数量的转移数据并存入缓冲区:
python
def update_beta(self, idx: int) -> float:
v = BETA_START + idx * (1.0 - BETA_START) / BETA_FRAMES
self.beta = min(1.0, v)
return self.beta
def populate(self, count):
max_prio = self.priorities.max() if self.buffer else 1.0
for _ in range(count):
sample = next(self.exp_source_iter)
if len(self.buffer) < self.capacity:
self.buffer.append(sample)
else:
self.buffer[self.pos] = sample
self.priorities[self.pos] = max_prio
self.pos = (self.pos + 1) % self.capacity由于我们采用环形缓冲区存储状态转移数据,在采样时会遇到两种不同情况:
当缓冲区未达最大容量时,只需追加新转移数据。
如果缓冲区已满,则需覆写由 pos 类字段追踪的最旧转移数据,并通过取模运算循环调整写入位置。
(4) 在 sample() 方法中,需利用超参数 α α α 将优先级转换为概率分布:
python
def sample(self, batch_size, beta=0.4):
if len(self.buffer) == self.capacity:
prios = self.priorities
else:
prios = self.priorities[:self.pos]
probs = np.array(prios, dtype=np.float32) ** self.prob_alpha
probs /= probs.sum()随后根据该概率分布从缓冲区抽取批次样本:
python
indices = np.random.choice(len(self.buffer), batch_size, p=probs, replace=True)
samples = [self.buffer[idx] for idx in indices]最后,计算批次样本的权重系数:
python
total = len(self.buffer)
weights = (total * probs[indices]) ** (-beta)
weights /= weights.max()
return samples, indices, np.array(weights, dtype=np.float32)该方法返回三个对象:批数据、索引及权重。其中索引用于后续更新已采样数据的优先级。。
(5) 优先级回放缓冲区的最后一个函数是允许我们更新已处理批次的新优先级:
python
def update_priorities(self, batch_indices, batch_priorities):
for idx, prio in zip(batch_indices, batch_priorities):
self.priorities[idx] = prio调用者需负责在批处理计算损失时使用此函数。
(6) 在本节中,下一个自定义函数是损失计算。由于 PyTorch 的 MSELoss 类不支持加权(因为 MSE 通常用于回归问题,而样本加权常见于分类损失),我们需要手动计算 MSE 并显式地将结果与权重相乘:
python
def calc_loss(batch: tt.List[ExperienceFirstLast], batch_weights: np.ndarray,
net: nn.Module, tgt_net: nn.Module, gamma: float,
device: torch.device) -> tt.Tuple[torch.Tensor, np.ndarray]:
states, actions, rewards, dones, next_states = common.unpack_batch(batch)
states_v = torch.as_tensor(states).to(device)
actions_v = torch.tensor(actions).to(device)
rewards_v = torch.tensor(rewards).to(device)
done_mask = torch.BoolTensor(dones).to(device)
batch_weights_v = torch.tensor(batch_weights).to(device)
actions_v = actions_v.unsqueeze(-1)
state_action_vals = net(states_v).gather(1, actions_v)
state_action_vals = state_action_vals.squeeze(-1)
with torch.no_grad():
next_states_v = torch.as_tensor(next_states).to(device)
next_s_vals = tgt_net(next_states_v).max(1)[0]
next_s_vals[done_mask] = 0.0
exp_sa_vals = next_s_vals.detach() * gamma + rewards_v
l = (state_action_vals - exp_sa_vals) ** 2
losses_v = batch_weights_v * l
return losses_v.mean(), (losses_v + 1e-5).data.cpu().numpy()在损失计算的最后部分,我们实现了均方误差损失函数,但采用显式表达式而非调用库函数。这使得我们可以纳入样本权重系数,并保留每个样本的独立损失值。这些损失值将被回传至优先级回放缓冲区用于更新优先级。为避免零损失值导致缓冲区元素优先级归零的情况,我们为每个损失值添加了一个小常量值。
(7) 在程序的主逻辑中,仅需两处修改:回放缓冲区的初始化和数据处理函数。由于缓冲区初始化过程直观明了,我们将重点分析新的数据处理函数实现:
python
def process_batch(engine, batch_data):
batch, batch_indices, batch_weights = batch_data
optimizer.zero_grad()
loss_v, sample_prios = calc_loss(
batch, batch_weights, net, tgt_net.target_model,
gamma=params.gamma, device=device)
loss_v.backward()
optimizer.step()
buffer.update_priorities(batch_indices, sample_prios)
epsilon_tracker.frame(engine.state.iteration)
if engine.state.iteration % params.target_net_sync == 0:
tgt_net.sync()
return {
"loss": loss_v.item(),
"epsilon": selector.epsilon,
"beta": buffer.update_beta(engine.state.iteration),
}主要变化如下:
- 批次现在包含三个实体:批数据、采样项的索引以及样本权重
- 调用新的损失函数,该函数接收权重并返回附加项的优先级。这些优先级会被传递至
buffer.update_priorities()函数以重新调整已采样项的优先级 - 调用缓冲区的
update_beta()方法,根据调度策略调整beta参数
3. 运行结果
训练过程与经典 DQN 相同。根据实验数据,优先回放缓冲区在解决环境问题上的耗时与经典 DQN 几乎相同,但所需的训练迭代次数和训练回合数更少。实际耗时相近的主要原因在于当前回放缓冲区的实现效率较低------这一问题完全可以通过采用 O ( l o g N ) O(log N) O(logN) 复杂度的缓冲区实现方案来解决。
下图展示了基线方法与优先回放缓冲区的奖励动态对比。横坐标表示游戏回合数:

另外需要注意的是,在 TensorBoard 中可以观察到,优先回放缓冲区的损失明显较低。下图展示了具体对比:

更低的损失值符合预期,也表明我们的实现是有效的。优先采样的核心思想是通过重点训练高损失值的样本来提升训练效率。但这里存在一个潜在风险:训练过程中的损失值并非首要优化目标------我们可能获得极低的损失值,却因探索不足导致最终学得的策略远非最优。
4. 超参数调优
针对优先级回放缓冲区的超参数调优新增了 α α α 参数(取值范围 0.3 至 0.9,步长 0.1)。最佳参数组合 ( α = 0.6 α=0.6 α=0.6) 仅用 330 个训练回合就解决了 Pong 游戏:
python
learning_rate=8.839010139505506e-05
gamma=0.99基准 DQN 与调优后的优先级回放缓冲区的对比图如下所示:
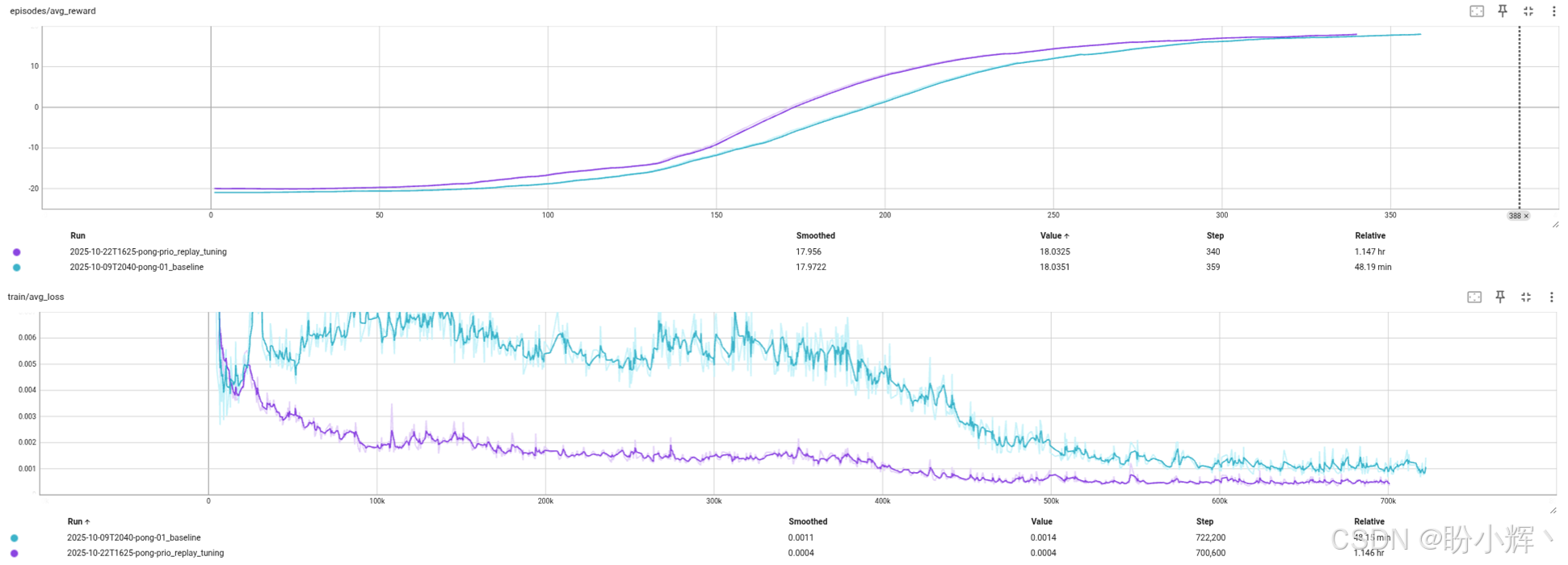
从图中可见,优先级回放缓冲区的游戏表现提升更快,但达到 21 分所需的游戏回合数几乎相同。在图(以游戏步数为单位)中可以看出,优先级回放缓冲区的表现也略胜一筹。
小结
本节深入介绍了优先经验回放机制,它通过根据样本损失值分配优先级,打破了经典 DQN 的均匀采样策略,从而提升训练效率与策略质量。详细阐述了优先级的计算公式、采样与权重补偿机制,并给出了具体代码实现,包括缓冲区设计、损失函数修改及超参数 β β β 的调度策略。实验结果显示,该方法在减少训练迭代次数的同时,能够获得更低的损失值。
系列链接
PyTorch强化学习实战(1)------强化学习(Reinforcement Learning,RL)详解
PyTorch强化学习实战(2)------强化学习环境库Gymnasium
PyTorch强化学习实战(3)------Gymnasium API扩展功能
PyTorch强化学习实战(4)------PyTorch基础
PyTorch强化学习实战(5)------PyTorch Ignite 事件驱动机制与实践
PyTorch强化学习实战(6)------交叉熵方法详解与实现
PyTorch强化学习实战(7)------表格学习与贝尔曼方程
PyTorch强化学习实战(8)------Q学习详解与实现
PyTorch强化学习实战(10)------强化学习高级组件
PyTorch强化学习实战(11)------N步DQN(N-step DQN)