C++ string 类详解:常用接口、OJ 场景与模拟实现中的深浅拷贝

🔥 星恒随风: 个人主页 ❄️ 个人专栏: 《指针合集》 | 《C语言基础》 | 《数据结构》 | 《机器学习导论》 | 《前端基础》 | 《python基础》 ✨ 数据即知识,压缩即智能
C++ string 类详解:常用接口、OJ 场景与模拟实现中的深浅拷贝
目录
- [C++ string 类详解:常用接口、OJ 场景与模拟实现中的深浅拷贝](#C++ string 类详解:常用接口、OJ 场景与模拟实现中的深浅拷贝)
- [C++ string 类详解:常用接口、OJ 场景与模拟实现中的深浅拷贝](#C++ string 类详解:常用接口、OJ 场景与模拟实现中的深浅拷贝)
- [一、string 常见构造方式](#一、string 常见构造方式)
-
- [1.1 构造空字符串](#1.1 构造空字符串)
- [1.2 用 C 字符串构造](#1.2 用 C 字符串构造)
- [1.3 拷贝构造](#1.3 拷贝构造)
- [1.4 构造 n 个相同字符](#1.4 构造 n 个相同字符)
- [二、string 的容量相关接口](#二、string 的容量相关接口)
-
- [2.1 size 和 length](#2.1 size 和 length)
- [2.2 capacity](#2.2 capacity)
- [2.3 empty](#2.3 empty)
- [2.4 clear](#2.4 clear)
- [2.5 reserve](#2.5 reserve)
- [2.6 resize](#2.6 resize)
- [2.7 reserve 和 resize 的核心区别](#2.7 reserve 和 resize 的核心区别)
- [三、string 的访问和遍历](#三、string 的访问和遍历)
-
- [3.1 operator\[\]](#3.1 operator[])
- [3.2 迭代器遍历](#3.2 迭代器遍历)
- [3.3 反向迭代器](#3.3 反向迭代器)
- [3.4 范围 for 遍历](#3.4 范围 for 遍历)
- [四、string 的修改操作](#四、string 的修改操作)
-
- [4.1 push_back](#4.1 push_back)
- [4.2 append](#4.2 append)
- [4.3 operator+=](#4.3 operator+=)
- [4.4 operator+ 为什么要少用?](#4.4 operator+ 为什么要少用?)
- [五、string 的查找和截取](#五、string 的查找和截取)
-
- [5.1 find](#5.1 find)
- [5.2 rfind](#5.2 rfind)
- [5.3 substr](#5.3 substr)
- [5.4 c_str](#5.4 c_str)
- [六、输入输出:cin、getline 和空格问题](#六、输入输出:cin、getline 和空格问题)
-
- [6.1 operator>>](#6.1 operator>>)
- [6.2 getline](#6.2 getline)
- [6.3 cin 和 getline 混用时的坑](#6.3 cin 和 getline 混用时的坑)
- [七、几个典型 OJ 字符串场景](#七、几个典型 OJ 字符串场景)
-
- [7.1 仅反转字母](#7.1 仅反转字母)
- [7.2 找第一个只出现一次的字符](#7.2 找第一个只出现一次的字符)
- [7.3 最后一个单词的长度](#7.3 最后一个单词的长度)
- [7.4 验证回文串](#7.4 验证回文串)
- [7.5 字符串相加](#7.5 字符串相加)
- [八、不同编译器下 string 的底层结构](#八、不同编译器下 string 的底层结构)
-
- [8.1 string 不是简单的 char*](#8.1 string 不是简单的 char*)
- [8.2 小字符串优化](#8.2 小字符串优化)
- [8.3 写时拷贝](#8.3 写时拷贝)
- [九、为什么要模拟实现 String?](#九、为什么要模拟实现 String?)
- [十、一个有问题的 String 类](#十、一个有问题的 String 类)
- 十一、浅拷贝的问题
-
- [11.1 什么是浅拷贝?](#11.1 什么是浅拷贝?)
- [11.2 浅拷贝为什么危险?](#11.2 浅拷贝为什么危险?)
- 十二、深拷贝解决问题
-
- [12.1 什么是深拷贝?](#12.1 什么是深拷贝?)
- [12.2 传统写法:拷贝构造](#12.2 传统写法:拷贝构造)
- [12.3 传统写法:赋值运算符重载](#12.3 传统写法:赋值运算符重载)
- 十三、现代写法:拷贝交换
-
- [13.1 拷贝构造中的交换思想](#13.1 拷贝构造中的交换思想)
- [13.2 赋值运算符的现代写法](#13.2 赋值运算符的现代写法)
- [十四、String 模拟实现的基本版本](#十四、String 模拟实现的基本版本)
- 十五、本文总结
前言
上一篇我们从 STL 的整体结构出发,介绍了 string 在 C++ 标准库中的位置。
这一篇继续深入:
string到底怎么用?
一、string 常见构造方式
1.1 构造空字符串
cpp
string s1;这会构造一个空字符串。
此时:
cpp
s1.size() == 0
s1.empty() == true1.2 用 C 字符串构造
cpp
string s2("hello bit");或者:
cpp
string s2 = "hello bit";这是最常用的构造方式。
相比 C 字符数组,string 会自己管理内部空间。
1.3 拷贝构造
cpp
string s3(s2);或者:
cpp
string s3 = s2;这会用已有的 string 对象构造新对象。
从使用层面看,就是复制一份字符串内容。
从实现层面看,现代 string 通常需要保证两个对象的内容独立管理,避免浅拷贝导致的重复释放问题。
1.4 构造 n 个相同字符
cpp
string s4(5, 'x');结果是:
cpp
"xxxxx"这种写法在刷题中比较常用。
比如要构造一个长度为 n 的初始字符串:
cpp
string ans(n, '0');二、string 的容量相关接口
容量相关接口是 string 中非常重要的一组。
常见函数有:
cpp
size()
length()
capacity()
empty()
clear()
reserve()
resize()2.1 size 和 length
cpp
s.size()
s.length()这两个函数都返回字符串中有效字符的个数。
例如:
cpp
string s = "hello";
cout << s.size() << endl; // 5
cout << s.length() << endl; // 5从使用习惯上来说,C++ 容器普遍使用 size()。
所以日常更推荐使用:
cpp
s.size()length() 更多是为了字符串语义保留的接口。
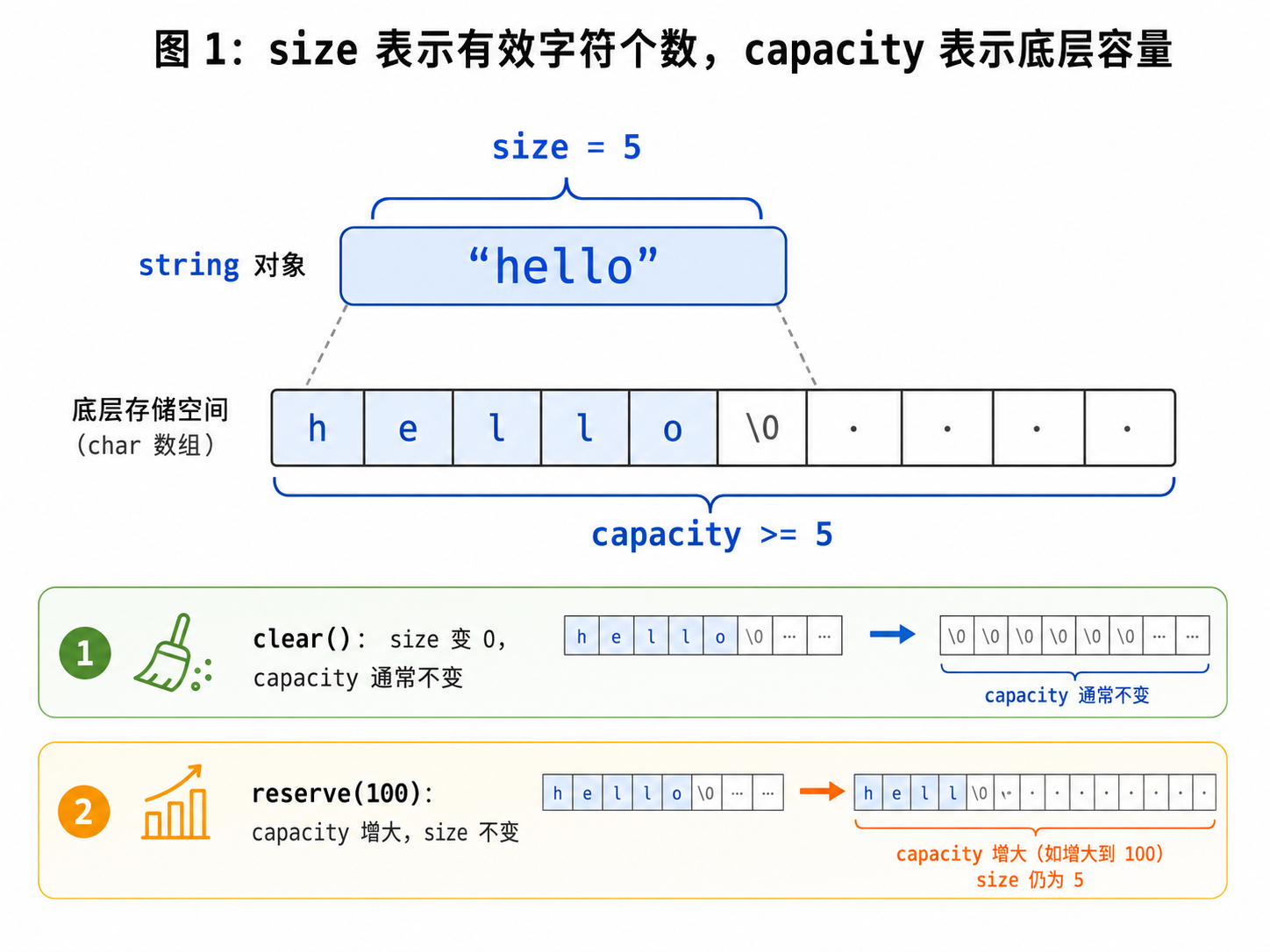
2.2 capacity
cpp
s.capacity()返回的是当前 string 底层已经分配的容量。
注意:
cpp
size != capacitysize() 表示有效字符个数。
capacity() 表示当前底层空间最多能容纳多少有效字符。
比如:
cpp
string s = "hello";size() 是 5。
capacity() 可能大于等于 5。
因为底层通常会预留一些空间,避免每次追加字符都重新申请内存。
2.3 empty
cpp
s.empty()用于判断字符串是否为空。
cpp
if (s.empty())
{
cout << "空字符串" << endl;
}它等价于判断:
cpp
s.size() == 0但语义更清晰。
2.4 clear
cpp
s.clear();clear() 会清空字符串中的有效字符。
例如:
cpp
string s = "hello";
s.clear();
cout << s.size() << endl; // 0注意:
clear 通常不会改变底层容量。
也就是说,它只是让字符串逻辑上变空,不一定释放已经申请好的空间。
这样做是为了后续继续使用时减少重新分配的开销。
2.5 reserve
cpp
s.reserve(100);reserve 的作用是预留容量。
它不会改变有效字符个数。
例如:
cpp
string s = "hello";
s.reserve(100);
cout << s.size() << endl; // 5
cout << s.capacity() << endl; // 至少能容纳 100 左右它适合在你大致知道字符串会增长到多长时提前使用。
比如频繁拼接字符串:
cpp
string ret;
ret.reserve(10000);
for (...)
{
ret += part;
}这样可以减少扩容次数,提高效率。
2.6 resize
cpp
s.resize(n);
s.resize(n, ch);resize 会改变有效字符个数。
如果 n 小于当前 size(),字符串会被截断。
如果 n 大于当前 size(),字符串会扩展。
扩展出来的位置:
cpp
resize(n)通常用 '\0' 填充。
cpp
resize(n, ch)用指定字符 ch 填充。
例如:
cpp
string s = "hello";
s.resize(8, 'x');
cout << s << endl; // helloxxx2.7 reserve 和 resize 的核心区别
这两个函数非常容易混。
cpp
reserve只管容量,不改变有效字符个数。
cpp
resize改变有效字符个数,必要时也可能改变容量。
例子:
cpp
string s = "hello";
s.reserve(100);
cout << s.size() << endl; // 5
s.resize(100, 'x');
cout << s.size() << endl; // 100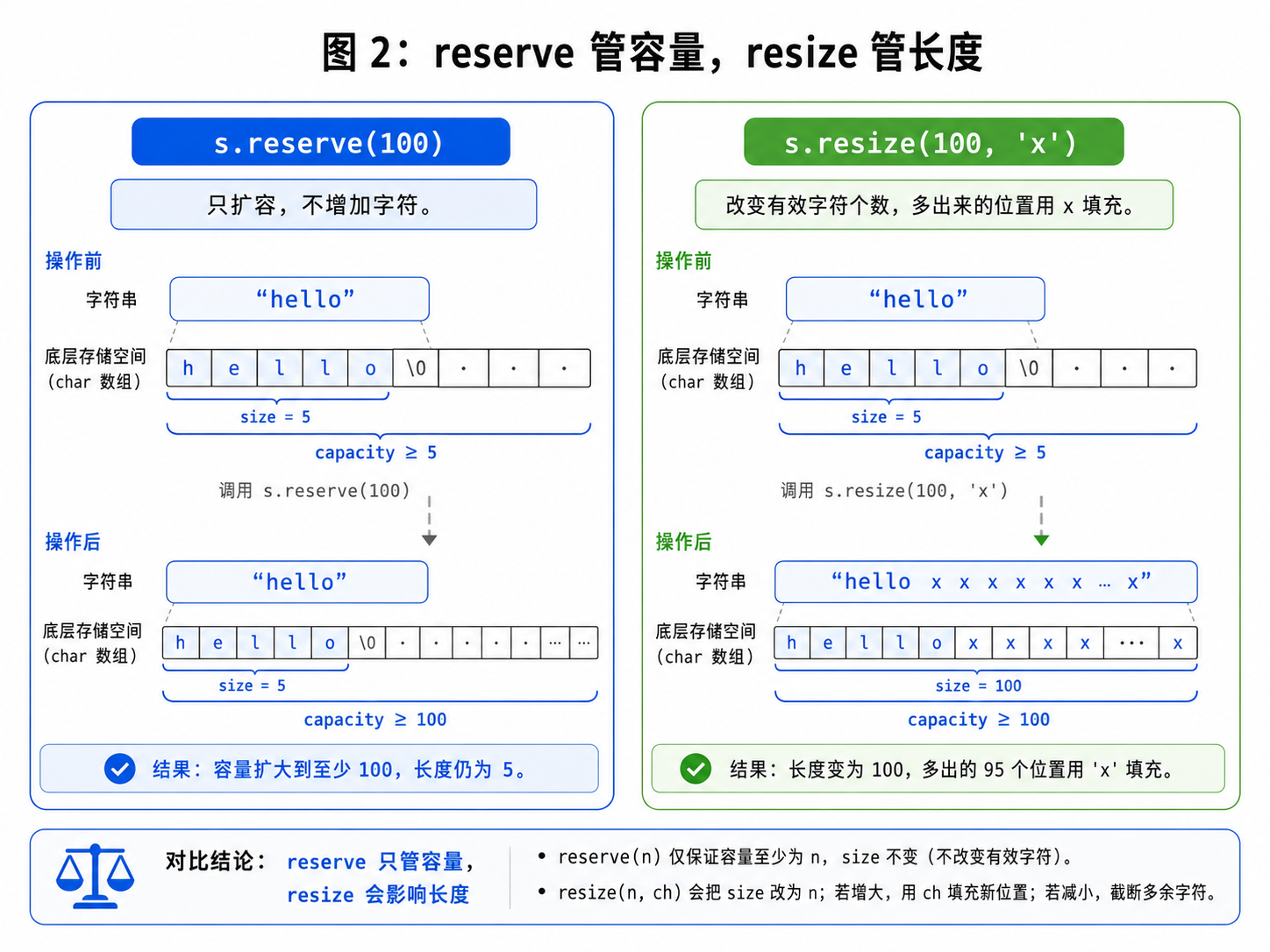
三、string 的访问和遍历
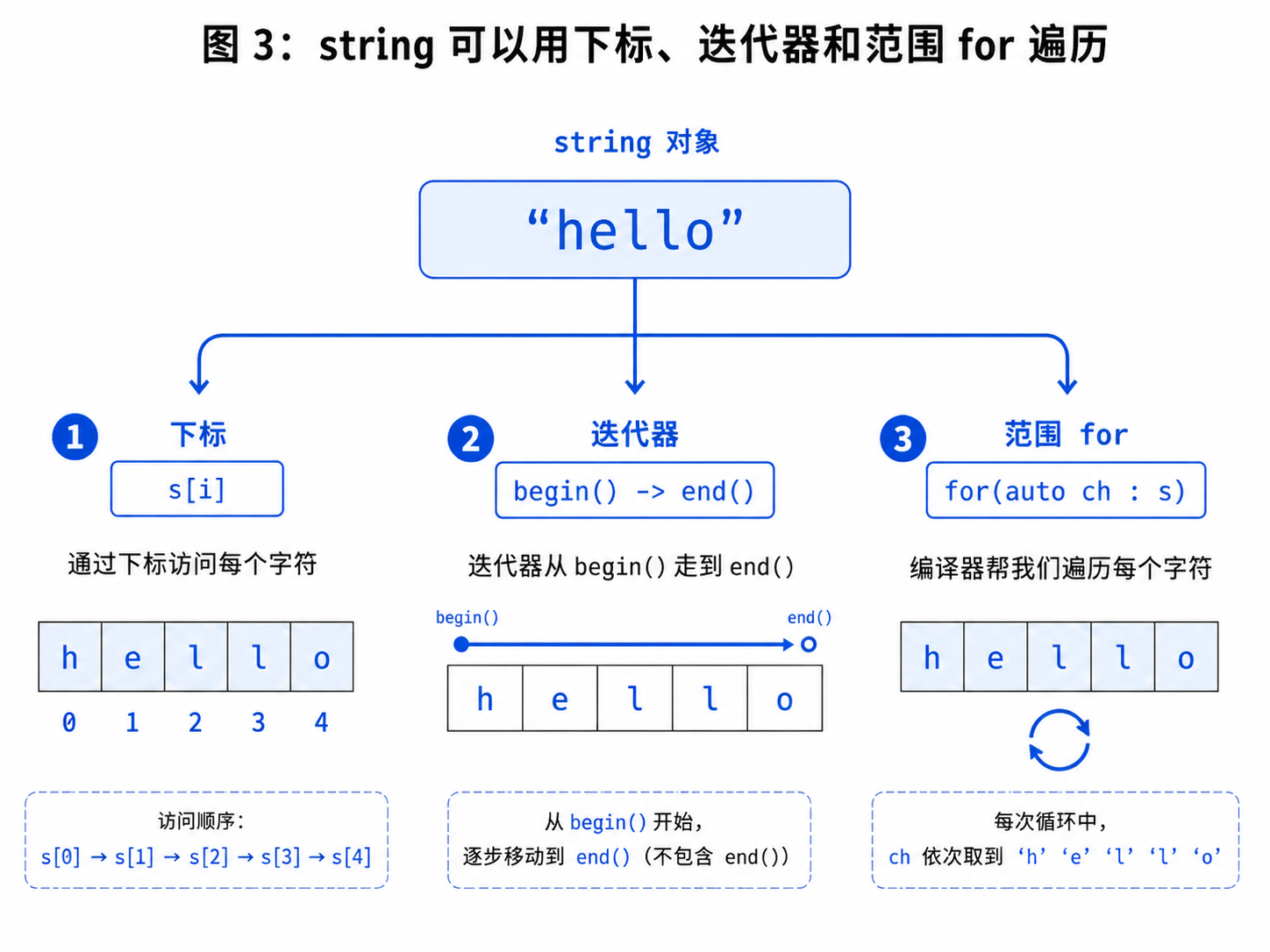
3.1 operator\[\]
最常用的访问方式是下标:
cpp
string s = "hello";
cout << s[0] << endl; // h
s[0] = 'H';operator[] 使用起来很方便,但要注意下标不能越界。
合法下标范围是:
cpp
0 ~ s.size() - 13.2 迭代器遍历
string 支持迭代器:
cpp
string s = "hello";
string::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}也可以用 auto 简化:
cpp
auto it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}begin() 指向第一个字符。
end() 指向最后一个字符的下一个位置。
注意:
end() 不是最后一个字符,而是最后一个字符后面的位置。
3.3 反向迭代器
string 也支持反向遍历:
cpp
auto rit = s.rbegin();
while (rit != s.rend())
{
cout << *rit << " ";
++rit;
}这会从后往前访问字符串。
3.4 范围 for 遍历
最简单的遍历方式是范围 for:
cpp
for (auto ch : s)
{
cout << ch << " ";
}如果要修改字符,需要引用:
cpp
for (auto& ch : s)
{
ch = toupper(ch);
}这里一定要注意:
cpp
auto ch是副本。
cpp
auto& ch才是原字符引用。
四、string 的修改操作
4.1 push_back
push_back 用于在字符串尾部追加一个字符:
cpp
string s = "hello";
s.push_back('!');
cout << s << endl; // hello!4.2 append
append 用于追加字符串:
cpp
string s = "hello";
s.append(" world");
cout << s << endl; // hello world也可以追加若干个字符:
cpp
s.append(3, 'x');4.3 operator+=
日常最常用的是 +=。
它既可以追加字符:
cpp
s += '!';也可以追加字符串:
cpp
s += " world";还可以追加另一个 string:
cpp
string t = " C++";
s += t;一般情况下,尾部追加更推荐使用 +=。
写法自然,表达清楚。
4.4 operator+ 为什么要少用?
比如:
cpp
string s1 = "hello";
string s2 = "world";
string s3 = s1 + " " + s2;这当然可以用。
但如果在循环中大量使用 + 拼接字符串,可能会产生较多临时对象。
例如:
cpp
string ret;
for (int i = 0; i < n; ++i)
{
ret = ret + part;
}这种写法可能效率较低。
更推荐:
cpp
string ret;
ret.reserve(预估长度);
for (int i = 0; i < n; ++i)
{
ret += part;
}核心思想是:
能预估长度时先 reserve,频繁拼接时优先 +=。
五、string 的查找和截取
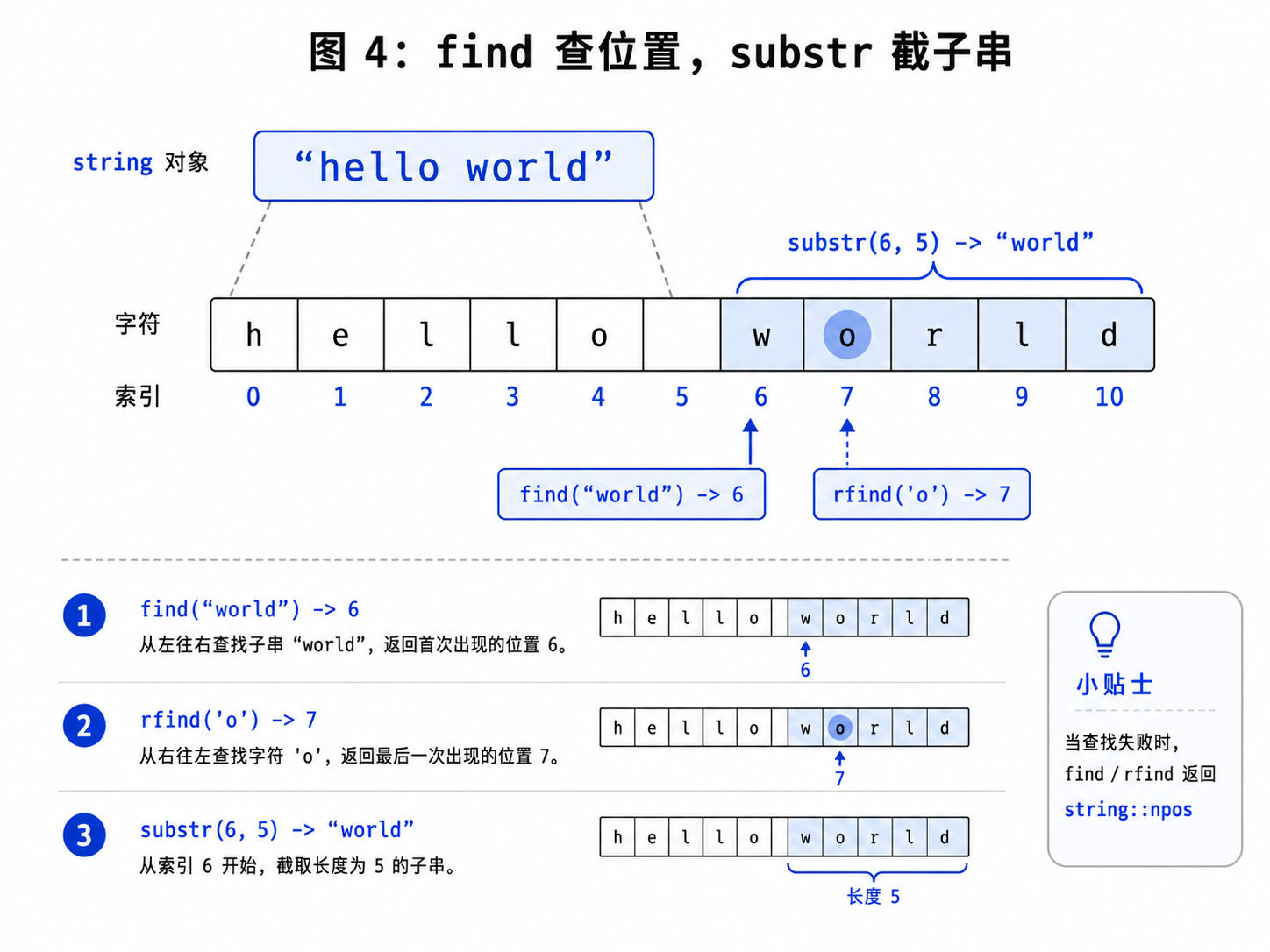
5.1 find
find 用于从字符串中查找字符或子串。
cpp
string s = "hello world";
size_t pos = s.find("world");如果找到了,返回第一次出现的位置。
如果没找到,返回:
cpp
string::npos所以使用时一定要判断:
cpp
if (pos != string::npos)
{
cout << "找到了" << endl;
}不要直接拿 npos 当正常下标使用。
5.2 rfind
rfind 从后往前查找。
比如求最后一个单词长度时,经常会用:
cpp
size_t pos = line.rfind(' ');如果字符串是:
cpp
"hello world"最后一个空格的位置就是 5。
最后一个单词长度可以写成:
cpp
line.size() - pos - 1不过实际写题时要注意没有空格的情况。
如果 rfind 返回 npos,说明整行就是一个单词。
5.3 substr
substr 用于截取子串。
cpp
string s = "hello world";
string sub = s.substr(6, 5);结果是:
cpp
"world"第一个参数表示起始位置。
第二个参数表示截取长度。
如果第二个参数省略,默认截取到字符串末尾:
cpp
string sub = s.substr(6);5.4 c_str
c_str() 用于返回 C 风格字符串。
cpp
string s = "hello";
const char* p = s.c_str();这个接口在和 C 库函数、某些系统接口交互时很有用。
但要注意:
返回的指针指向 string 内部数据。
当 string 被修改或销毁后,这个指针可能失效。
所以不要长期保存这个指针后继续使用。
六、输入输出:cin、getline 和空格问题
6.1 operator>>
可以直接输入字符串:
cpp
string s;
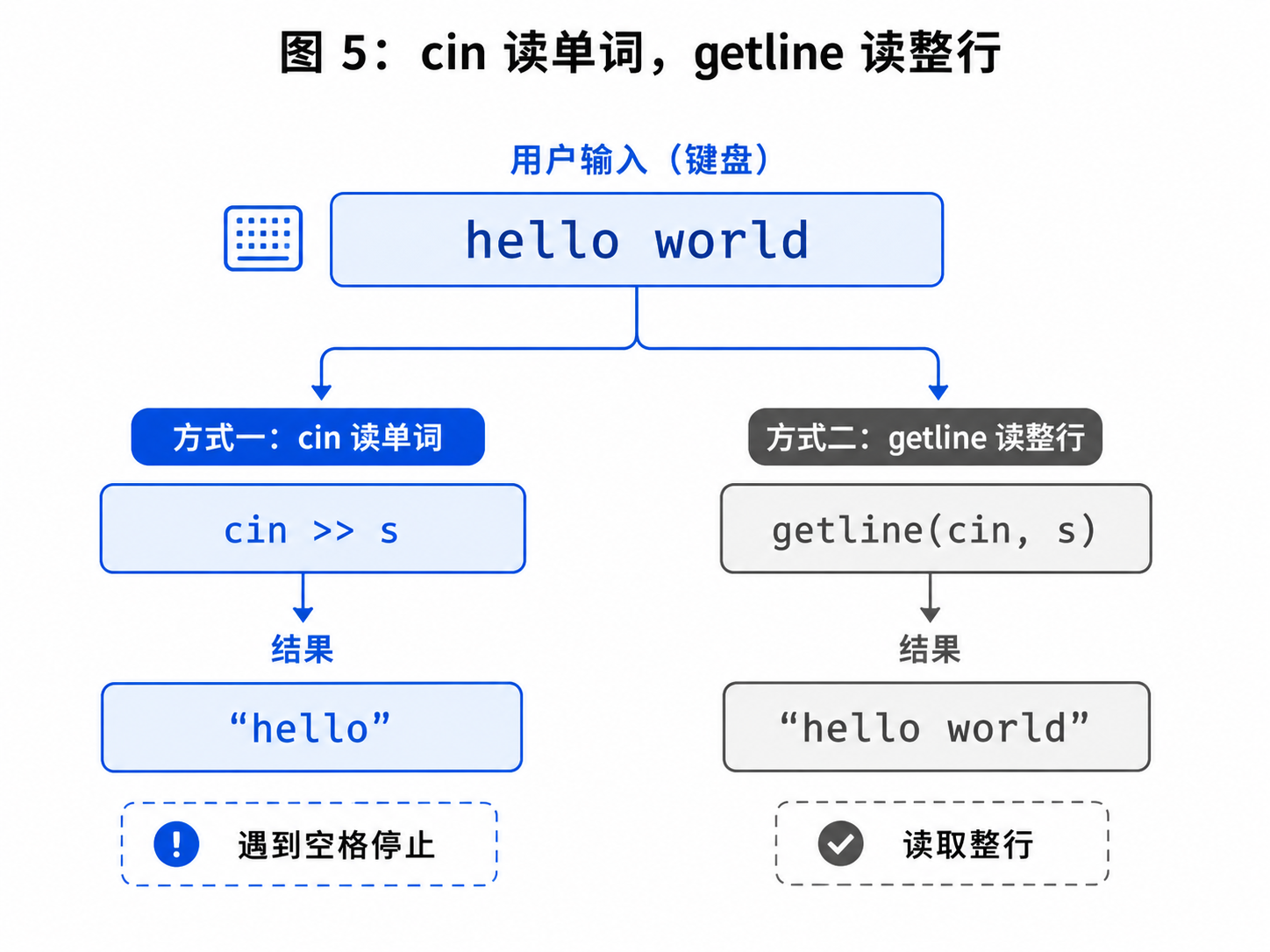
cin >> s;但它有一个特点:
遇到空白字符就停止。
比如输入:
cpp
hello worldcin >> s 只能读到:
cpp
hello6.2 getline
如果要读取一整行,应该使用:
cpp
getline(cin, line);例如:
cpp
string line;
getline(cin, line);它会读取一整行,包括中间的空格,直到换行结束。
所以处理整行文本、句子、带空格输入时,getline 更合适。
6.3 cin 和 getline 混用时的坑
如果前面用了:
cpp
cin >> n;然后立刻:
cpp
getline(cin, line);可能会读到一个空行。
原因是 cin >> n 读取数字后,换行符还留在输入缓冲区中。
getline 会把这个残留换行符当作一行结束。
常见处理方式是先消耗掉这个换行符:
cpp
cin.ignore();
getline(cin, line);更严谨时可以写:
cpp
cin.ignore(numeric_limits<streamsize>::max(), '\n');七、几个典型 OJ 字符串场景
7.1 仅反转字母
题意:
字符串中只有字母需要反转,其他字符位置不动。
思路:
用双指针。
左指针从前往后找字母。
右指针从后往前找字母。
找到后交换。
核心逻辑:
cpp
bool isLetter(char ch)
{
return (ch >= 'a' && ch <= 'z')
|| (ch >= 'A' && ch <= 'Z');
}
string reverseOnlyLetters(string s)
{
if (s.empty())
return s;
size_t left = 0;
size_t right = s.size() - 1;
while (left < right)
{
while (left < right && !isLetter(s[left]))
++left;
while (left < right && !isLetter(s[right]))
--right;
swap(s[left], s[right]);
++left;
--right;
}
return s;
}这个题适合练习:
string下标访问- 双指针
- 字符判断
swap
7.2 找第一个只出现一次的字符
思路:
先统计每个字符出现次数。
再从前往后扫描字符串。
第一个出现次数为 1 的字符,就是答案。
cpp
int firstUniqChar(string s)
{
int count[256] = {0};
for (auto ch : s)
{
++count[(unsigned char)ch];
}
for (int i = 0; i < s.size(); ++i)
{
if (count[(unsigned char)s[i]] == 1)
return i;
}
return -1;
}这个题适合练习:
- 计数数组
- 字符作为下标
- 按原字符串顺序查找答案
7.3 最后一个单词的长度
输入一整行,求最后一个单词长度。
不能用:
cpp
cin >> line;因为它遇到空格就停止。
应该用:
cpp
getline(cin, line);一种写法:
cpp
int LastWordLength(const string& line)
{
size_t pos = line.rfind(' ');
if (pos == string::npos)
return line.size();
return line.size() - pos - 1;
}不过如果字符串末尾可能有空格,需要先处理尾部空格。
7.4 验证回文串
常见题意:
只考虑字母和数字,忽略大小写。
思路:
- 双指针
- 跳过非字母数字字符
- 比较时统一大小写
cpp
bool isLetterOrNumber(char ch)
{
return (ch >= '0' && ch <= '9')
|| (ch >= 'a' && ch <= 'z')
|| (ch >= 'A' && ch <= 'Z');
}
char ToLower(char ch)
{
if (ch >= 'A' && ch <= 'Z')
return ch + 32;
return ch;
}
bool isPalindrome(string s)
{
int left = 0;
int right = s.size() - 1;
while (left < right)
{
while (left < right && !isLetterOrNumber(s[left]))
++left;
while (left < right && !isLetterOrNumber(s[right]))
--right;
if (ToLower(s[left]) != ToLower(s[right]))
return false;
++left;
--right;
}
return true;
}7.5 字符串相加
题意:
两个非负整数字符串相加,返回字符串形式的结果。
不能直接转成整数,因为数字可能非常大。
思路:
从后往前逐位相加,维护进位。
cpp
string addStrings(string num1, string num2)
{
int i = num1.size() - 1;
int j = num2.size() - 1;
int carry = 0;
string ret;
while (i >= 0 || j >= 0 || carry)
{
int x = i >= 0 ? num1[i--] - '0' : 0;
int y = j >= 0 ? num2[j--] - '0' : 0;
int sum = x + y + carry;
ret += char(sum % 10 + '0');
carry = sum / 10;
}
reverse(ret.begin(), ret.end());
return ret;
}这个题很好地体现了 string 的使用价值:
- 下标访问
- 尾插字符
reverse- 字符和数字之间的转换
八、不同编译器下 string 的底层结构
8.1 string 不是简单的 char*
很多人刚开始会把 string 理解成:
cpp
char*这不准确。
string 是一个类对象,内部通常会管理:
- 字符串数据
- 有效长度
- 当前容量
- 分配器或其他辅助信息
不同编译器和不同标准库实现,内部结构可能不同。
所以不要在代码中依赖某个实现细节。
8.2 小字符串优化
很多现代 string 实现会使用一种优化:
小字符串优化。
大致意思是:
当字符串比较短时,不一定去堆上申请空间,而是直接把字符存放在 string 对象内部的小缓冲区里。
这样可以减少小字符串频繁动态分配的成本。
比如很多名字、短单词、路径片段都比较短,直接存在对象内部效率更高。
当字符串超过内部缓冲区容量时,再转到堆上分配空间。
8.3 写时拷贝
早期某些实现中,string 可能使用写时拷贝。
写时拷贝的思想是:
拷贝时先共享资源,真正要修改时再拷贝一份。
它通常配合引用计数使用。
优点是减少不必要的拷贝。
缺点是实现复杂,在多线程和字符访问语义上会带来一些问题。
现代 C++ 标准库实现中,主流 string 已经不再把写时拷贝作为推荐实现方式。
入门阶段只需要了解:
写时拷贝是一种历史上出现过的优化思想,不是我们模拟实现 string 时的第一选择。
九、为什么要模拟实现 String?
标准库里的 string 很强大。
那为什么面试和学习中还要模拟实现?
因为模拟实现 String 能训练几个非常关键的 C++ 能力:
- 构造函数
- 析构函数
- 拷贝构造
- 赋值运算符重载
- 深拷贝
- 资源管理
- 自赋值处理
- 异常安全意识
这不是为了替代标准库 string。
而是为了理解:
一个管理动态资源的类,应该怎么写默认成员函数。
十、一个有问题的 String 类
先看一个简化版本:
cpp
class String
{
public:
String(const char* str = "")
{
if (str == nullptr)
{
assert(false);
return;
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
~String()
{
delete[] _str;
_str = nullptr;
}
private:
char* _str;
};构造函数申请空间。
析构函数释放空间。
看起来没问题。
但是如果写:
cpp
String s1("hello");
String s2(s1);这里会调用编译器默认生成的拷贝构造函数。
默认拷贝构造会把 _str 的值直接复制给 s2._str。
也就是说:
cpp
s1._str == s2._str两个对象指向同一块堆空间。
这就是浅拷贝。
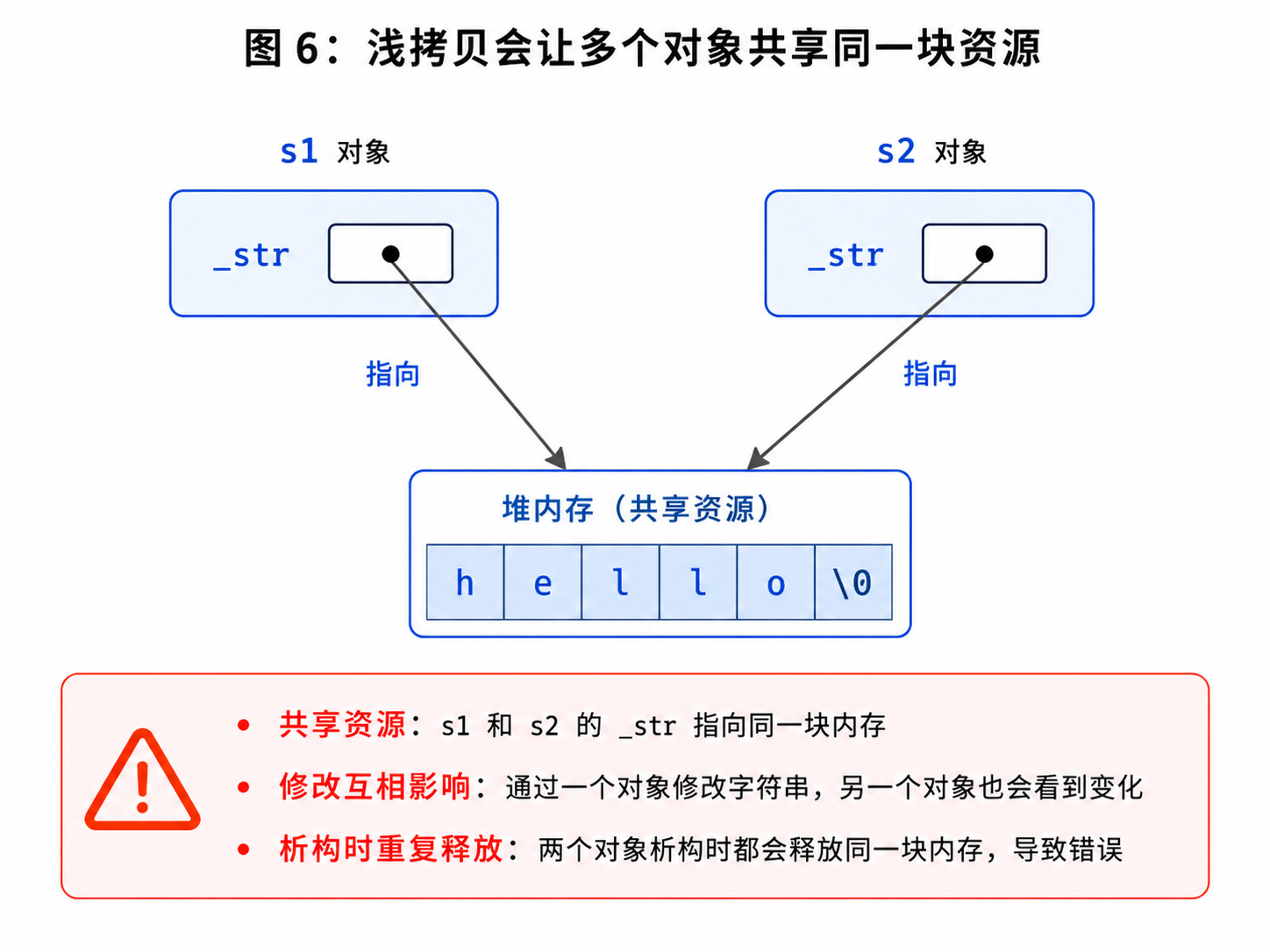
十一、浅拷贝的问题
11.1 什么是浅拷贝?
浅拷贝也叫位拷贝。
意思是:
只把对象中的成员变量值原样复制一份。
如果成员变量是普通 int,没问题。
但如果成员变量是指针,就会把地址复制过去。
结果就是多个对象共享同一块资源。
11.2 浅拷贝为什么危险?
继续看:
cpp
String s1("hello");
String s2(s1);浅拷贝后:
cpp
s1._str
s2._str都指向同一块字符数组。
当程序结束时,两个对象都会析构:
cpp
delete[] s1._str;
delete[] s2._str;同一块空间被释放两次,程序很可能崩溃。
此外,一个对象修改字符串内容,另一个对象也会受到影响。
所以对管理资源的类来说,浅拷贝通常是不够的。
十二、深拷贝解决问题
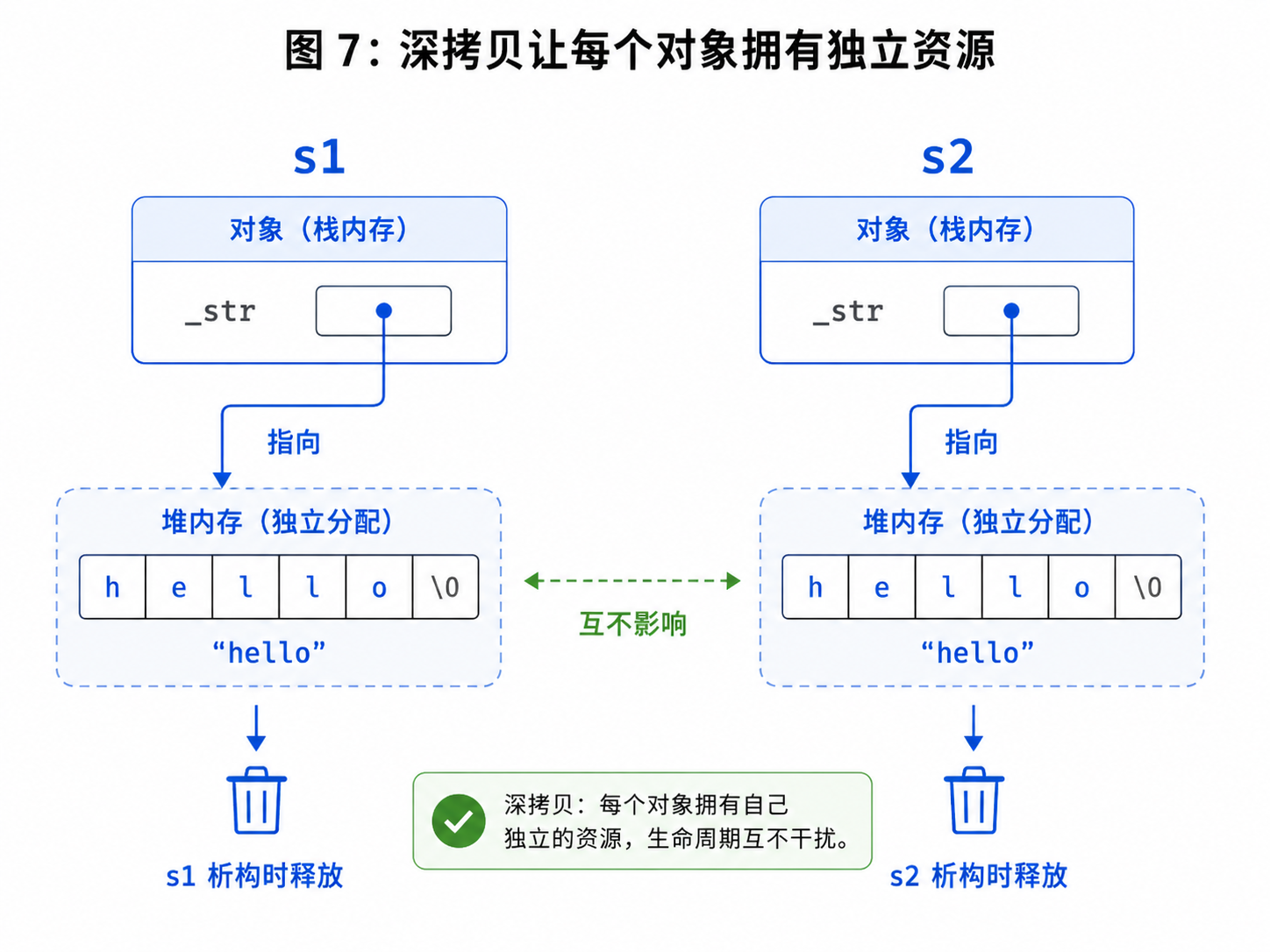
12.1 什么是深拷贝?
深拷贝的核心是:
每个对象都拥有自己独立的资源。
对于 String 来说,拷贝时不能只复制 _str 指针,而是要重新申请一块空间,再把字符串内容复制过去。
12.2 传统写法:拷贝构造
cpp
String(const String& s)
{
_str = new char[strlen(s._str) + 1];
strcpy(_str, s._str);
}这样:
cpp
String s2(s1);会让 s2 自己拥有一块新的空间。
内容和 s1 一样,但地址不同。
cpp
s1._str != s2._str析构时各自释放自己的空间,不会重复释放。
12.3 传统写法:赋值运算符重载
赋值运算符用于两个已经存在的对象之间赋值。
cpp
String& operator=(const String& s)
{
if (this != &s)
{
char* tmp = new char[strlen(s._str) + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
}
return *this;
}这里有几个细节:
第一,检查自赋值:
cpp
if (this != &s)处理:
cpp
s1 = s1;第二,先申请新空间,再释放旧空间。
这样如果申请失败,原对象还没有被破坏。
第三,返回 *this。
为了支持连续赋值:
cpp
s1 = s2 = s3;十三、现代写法:拷贝交换
13.1 拷贝构造中的交换思想
可以写成:
cpp
String(const String& s)
: _str(nullptr)
{
String tmp(s._str);
swap(_str, tmp._str);
}这段代码的思路是:
先用 s._str 构造一个临时对象 tmp。
然后交换当前对象和 tmp 的资源。
tmp 析构时,会释放当前对象原来的资源。
这种写法简洁,并且复用了构造函数。
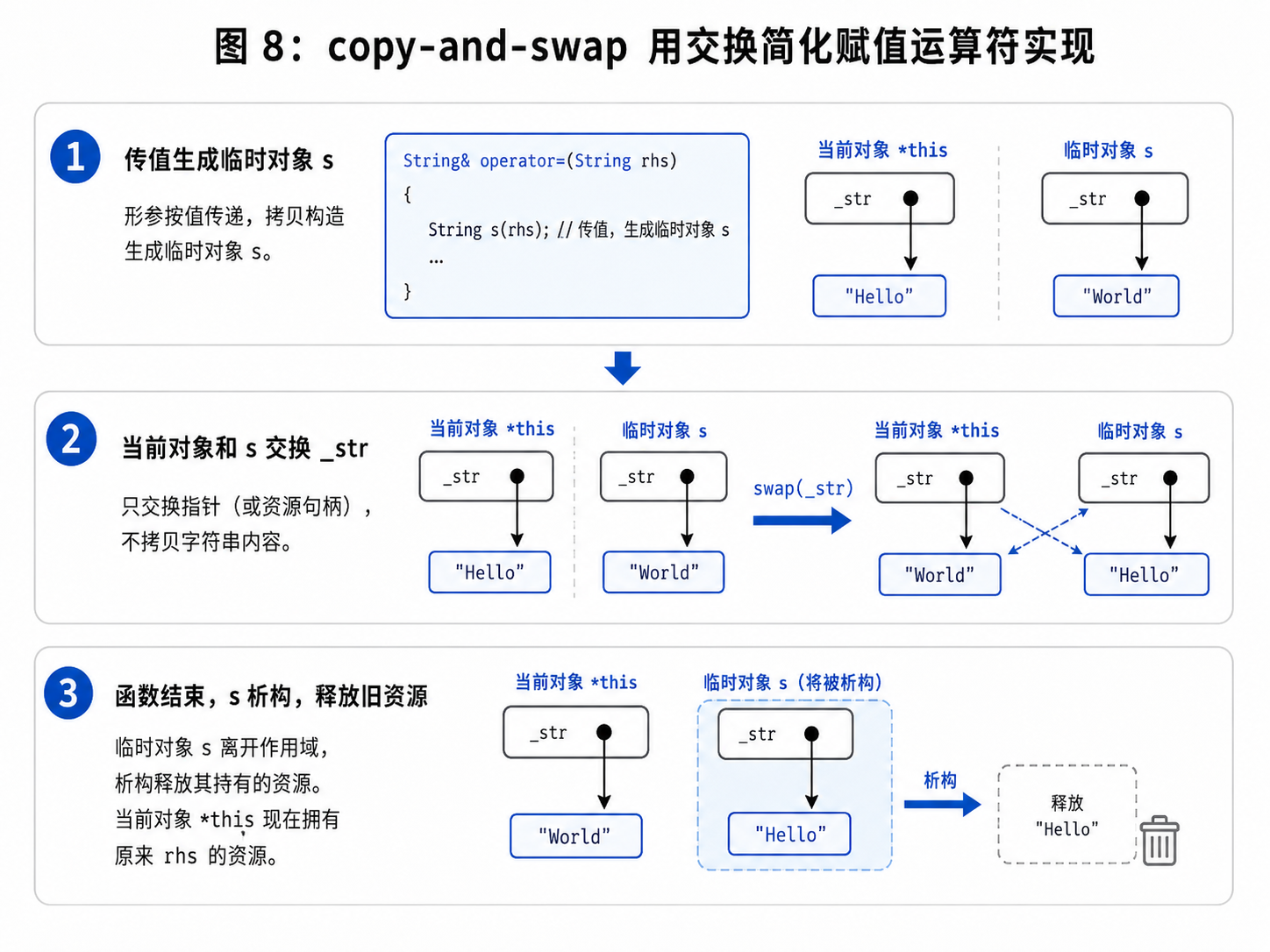
13.2 赋值运算符的现代写法
一种非常经典的写法是传值:
cpp
String& operator=(String s)
{
swap(_str, s._str);
return *this;
}这里参数 s 是按值传参。
调用时会先生成一份拷贝。
然后当前对象和这份拷贝交换资源。
函数结束时,形参 s 析构,释放当前对象原来的旧资源。
这就是 copy-and-swap 思想。
它的优点是:
- 代码短
- 自赋值也能安全处理
- 异常安全性更好
- 复用拷贝构造和析构逻辑
十四、String 模拟实现的基本版本
cpp
#include <iostream>
#include <cstring>
#include <cassert>
using namespace std;
class String
{
public:
String(const char* str = "")
{
if (str == nullptr)
{
assert(false);
str = "";
}
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
String(const String& s)
{
_str = new char[strlen(s._str) + 1];
strcpy(_str, s._str);
}
String& operator=(const String& s)
{
if (this != &s)
{
char* tmp = new char[strlen(s._str) + 1];
strcpy(tmp, s._str);
delete[] _str;
_str = tmp;
}
return *this;
}
~String()
{
delete[] _str;
_str = nullptr;
}
const char* c_str() const
{
return _str;
}
private:
char* _str;
};这个版本不是为了替代标准库。
它的重点是展示:
只要类里管理动态资源,就必须认真处理拷贝构造、赋值运算符和析构函数。
十五、本文总结
这一篇主要围绕 string 的使用和模拟实现展开。
string 的容量接口中:
size() 和 length() 都表示有效字符个数。
capacity() 表示底层容量。
clear() 清空有效字符,但通常不释放容量。
reserve() 只预留空间,不改变有效长度。
resize() 会改变有效字符个数。
string 的访问方式包括:
- 下标访问
- 迭代器
- 反向迭代器
- 范围
for
string 的修改方式中:
push_back追加单个字符append追加字符串+=更常用、更自然- 大量拼接时少用
+,优先reserve + +=
string 的查找和截取中:
find找不到返回string::nposrfind从后往前找substr用于截取子串c_str用于获得 C 风格字符串
输入时:
cin >> s遇到空格停止getline(cin, s)读取整行
模拟实现 String 时:
- 默认拷贝会导致浅拷贝
- 浅拷贝会导致资源共享和重复释放
- 深拷贝让每个对象拥有独立资源
- 管理资源的类必须认真写拷贝构造、赋值运算符和析构函数
最后用一句话总结:
string 的接口是用来解决字符串问题的,而 string 的模拟实现是用来理解 C++ 资源管理本质的。