目录
前言
学过C语言的话,对于程序地址空间分布图,想必大家都不会陌生
如下图在这里被称为进程地址空间(虚拟地址空间),他是一个系统的概念,不是语言层的概念
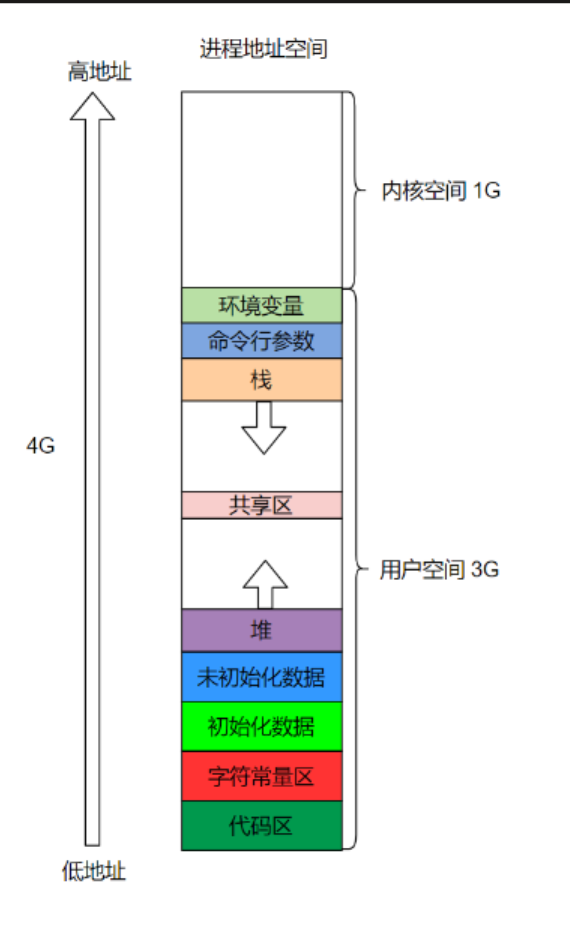
这里给出这个代码中的地址分布给展现出来
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc, char *argv[], char *env[])
{
const char *str = "helloworld";
printf("code addr: %p\n", main);
printf("init global addr: %p\n", &g_val);
printf("uninit global addr: %p\n", &g_unval);
static int test = 10;
char *heap_mem = (char*)malloc(10);
char *heap_mem1 = (char*)malloc(10);
char *heap_mem2 = (char*)malloc(10);
char *heap_mem3 = (char*)malloc(10);
printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1)
printf("test static addr: %p\n", &test); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1)
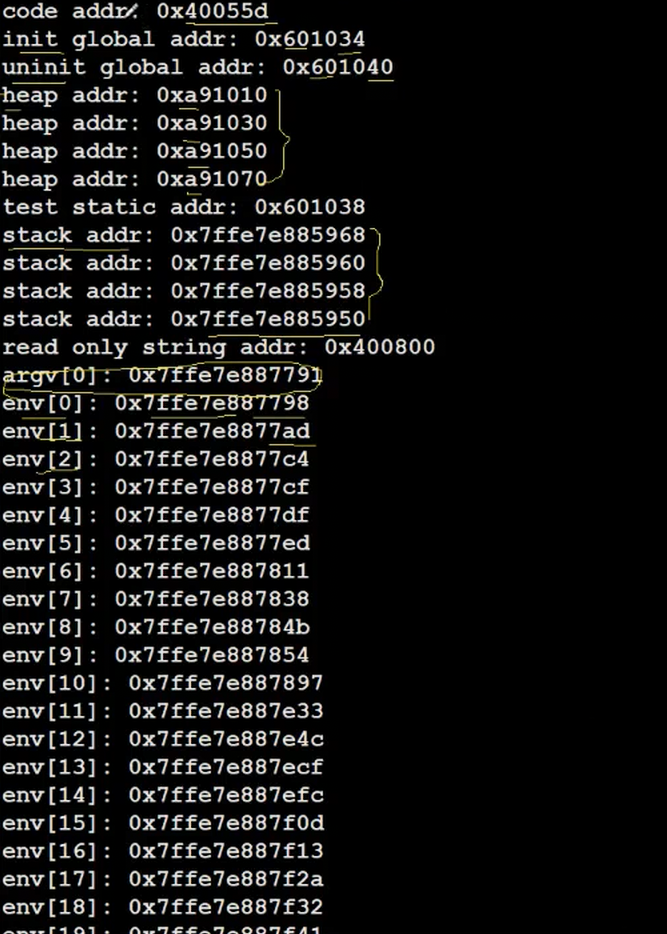
printf("read only string addr: %p\n", str);
for(int i = 0 ;i < argc; i++)
{
printf("argv[%d]: %p\n", i, argv[i]);
}
for(int i = 0; env[i]; i++)
{
printf("env[%d]: %p\n", i, env[i]);
}
return 0;
}从正文代码区网上地址是依次增大的
栈地址因为需要形成栈帧,要不断入栈,不断形成临时变量,函数结束了,要释放栈帧,临时变量就被释放,所有栈是地址越来越小
堆地址向上生长
栈和堆直接有一大段的镂空空间
这里的helloworld不能被修改,放在了字符常量区
平时我们定义的字符串,是被硬编码到代码的,因为代码是只读的,所有字符串就是只读的
test是个局部变量,默认在栈上,用static修饰作用域还是在本函数的,但是生命周期就变成全局的,被编到了已初始化数据处
程序地址空间是内存吗?
不是内存
证明不是物理内存
这里的地址是一样的,这里不是内存地址,是虚拟地址,我们所使用C/C++中指针用到的地址,都是虚拟地址
概念
一个进程,一个虚拟地址空间
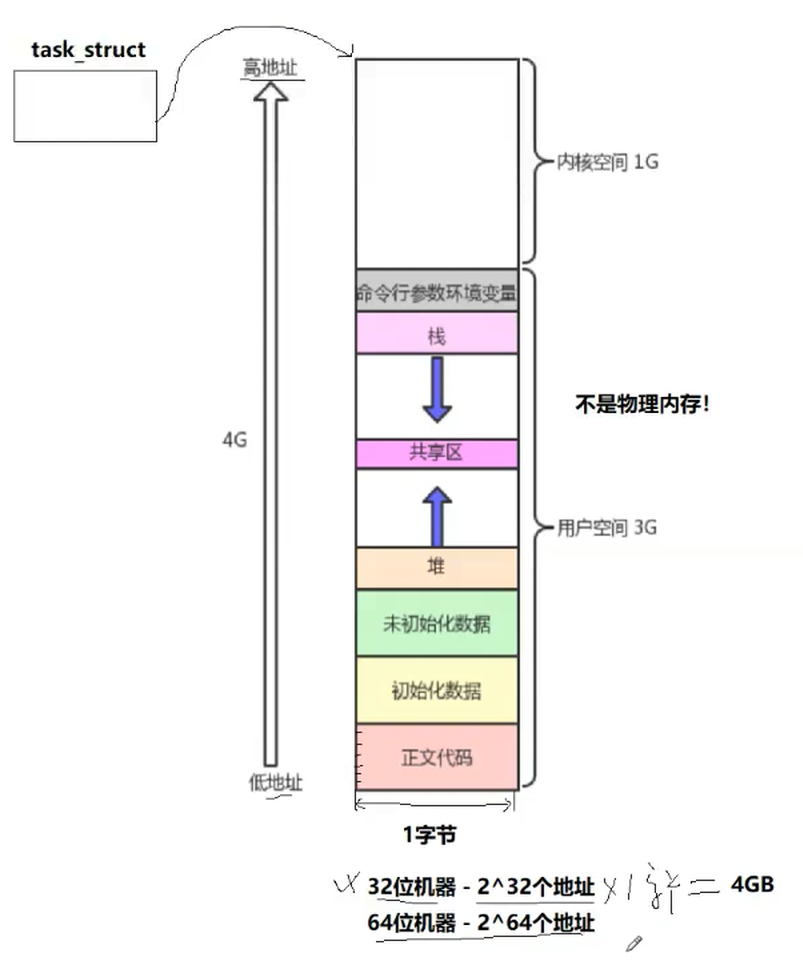
一个会有2的32次方个地址,一个地址是一个字节
前0~3GB的用户空间中只要拿到地址,就能直接访问
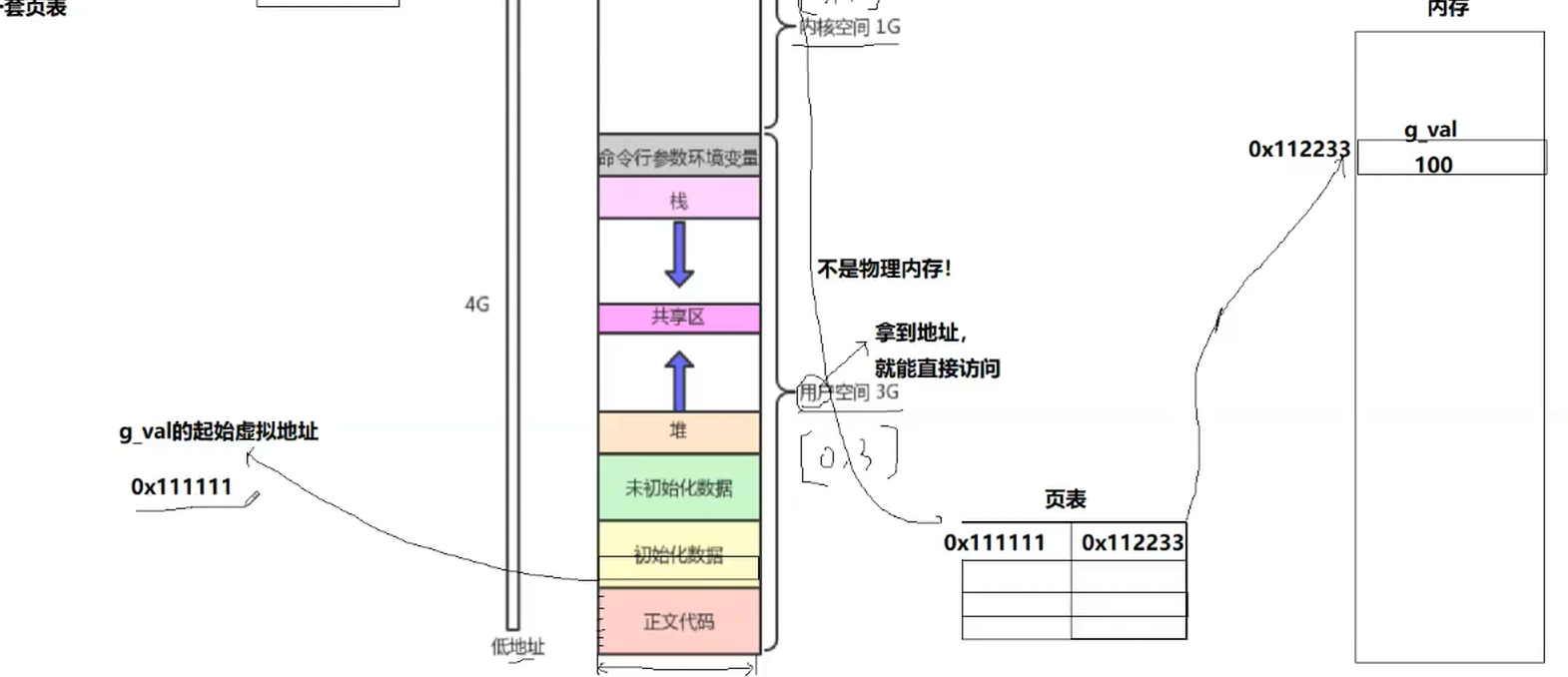
如下图,一个变量加载内存后有个物理变量(如图0x112233),同时在地址空间上存在一个虚拟地址(如图0x111111),在操作系统内为每一个进程创建的时候,构造一个页表
地址空间可以找到页表,左侧填入我们当前地址的某一个虚拟地址,右边填入的变量对应的物理地址,当我们的进程访问这个虚拟地址时,操作系统会自动把这个虚拟地址查表转化成我们物理内存中的地址,进而访问指定变量
页表是用来做虚拟地址和物理地址映射的
对于这里int有4个字节,然后地址空间的宽度是1字节,我们拿的是给整形开辟的四个字节地址中数值最小的地址,通过起始地址和偏移量便能访问
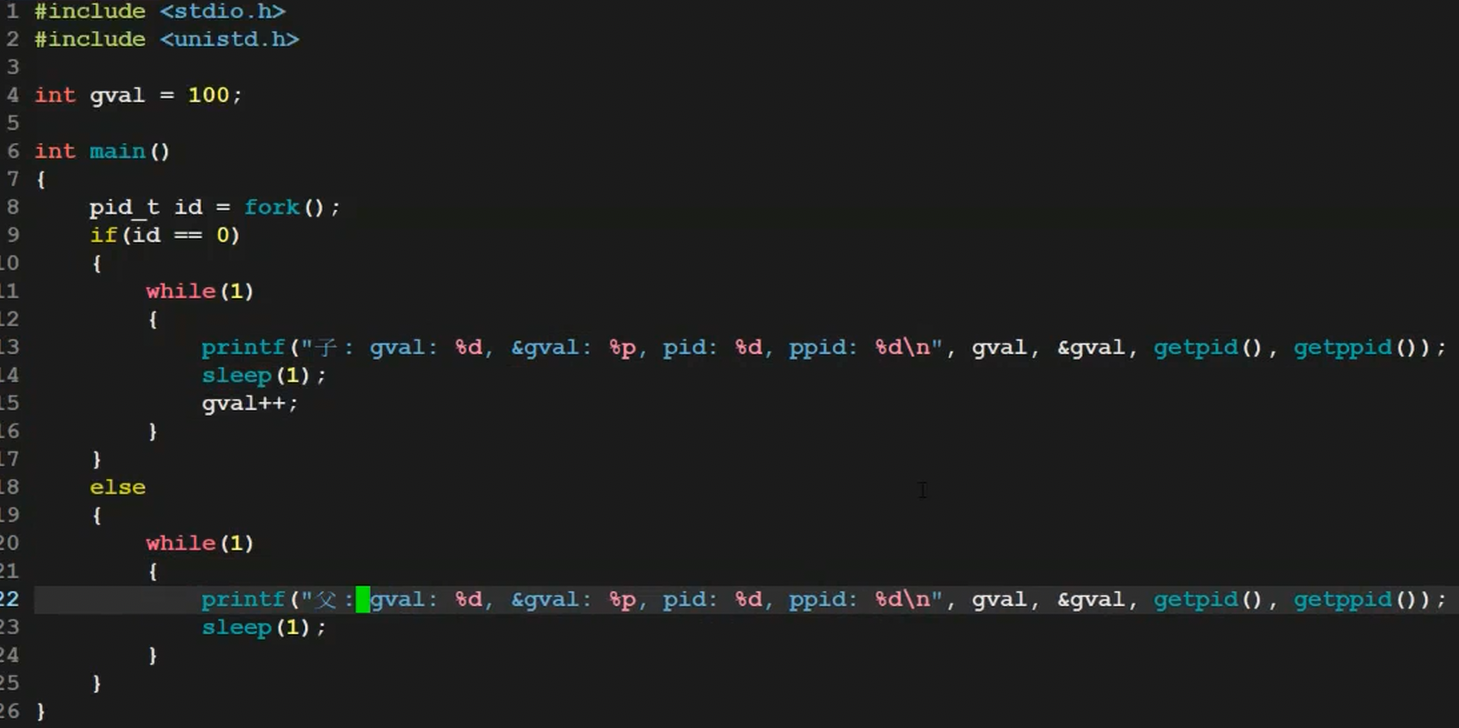
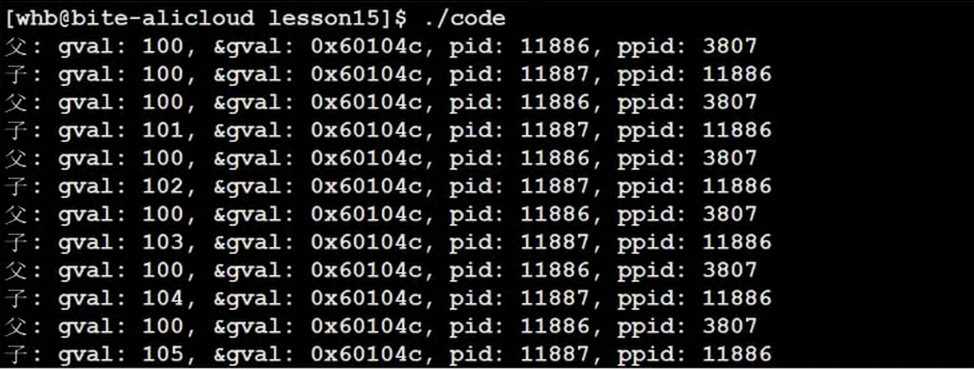
子进程的PCB,地址空间,页表都要从父进程那里拷贝(浅拷贝),拷贝也就意味着子进程初始化全局数据区里面,同样存在一个全局变量g_val
如下图,如果子进程需要对变量进行修改,操作系统就会介入,将子进程得虚拟地址进行修改成新的起始物理地址,重新构建子进程页表映射关系,这就是写实拷贝,这里也就是前面提到对应的变量为什么物理地址不同,虚拟地址相同的原因,同样也就是下图问题的答案

这些都操作系统自动做的
进程是具有独立性的
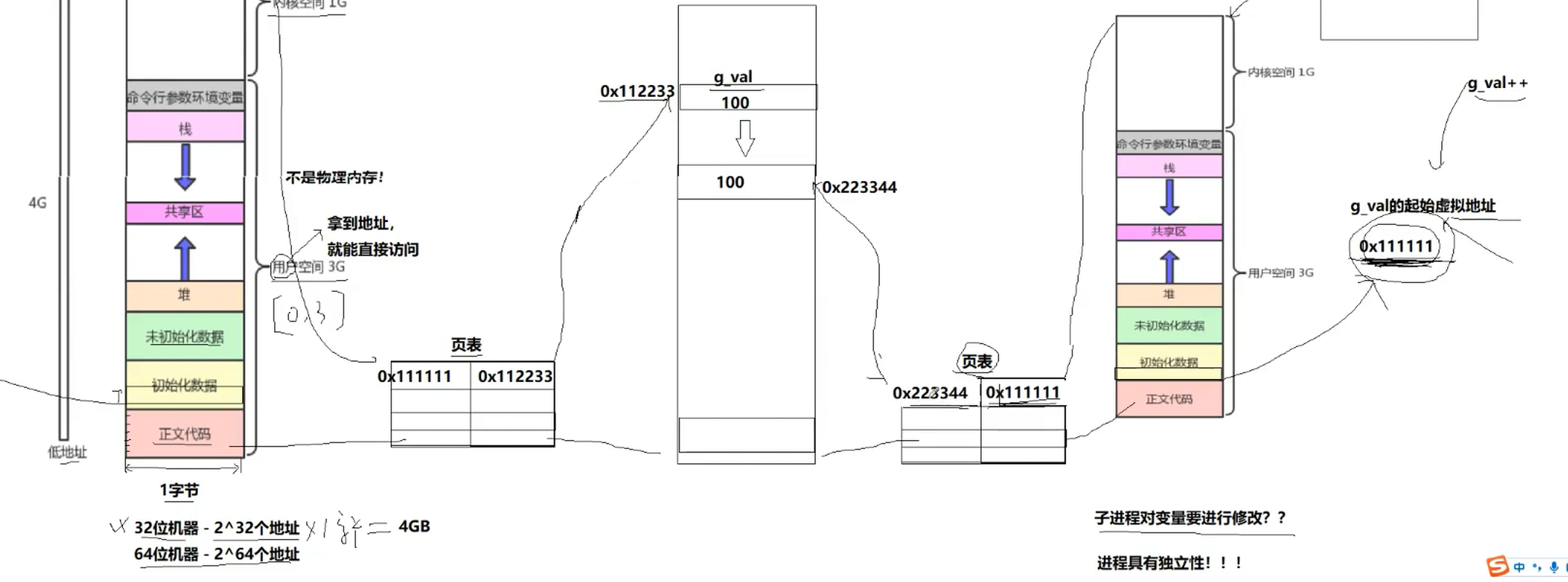
用户看不到新的物理地址,操作系统将物理地址隐藏起来了,只能看到虚拟地址
虚拟地址空间
本质是一个数据结构,在操作系统内部给进程创建的
举个例子,虚拟地址空间就是一个大饼
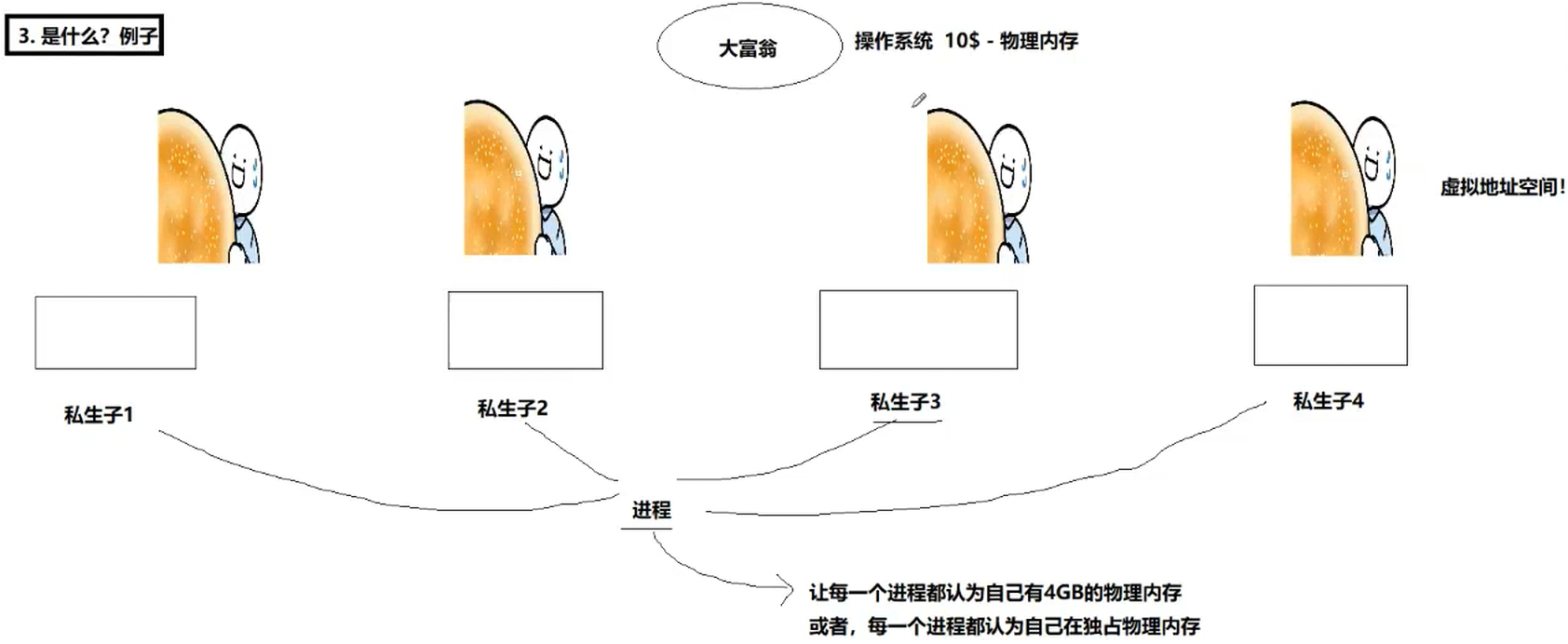
对于这些饼也需要管理起来
先描述,在组织
将饼的管理变成对链表的增删查改
区域划分
区域划分我们只需要确认区域的开始和结束即可,就可以把地址空间划分了
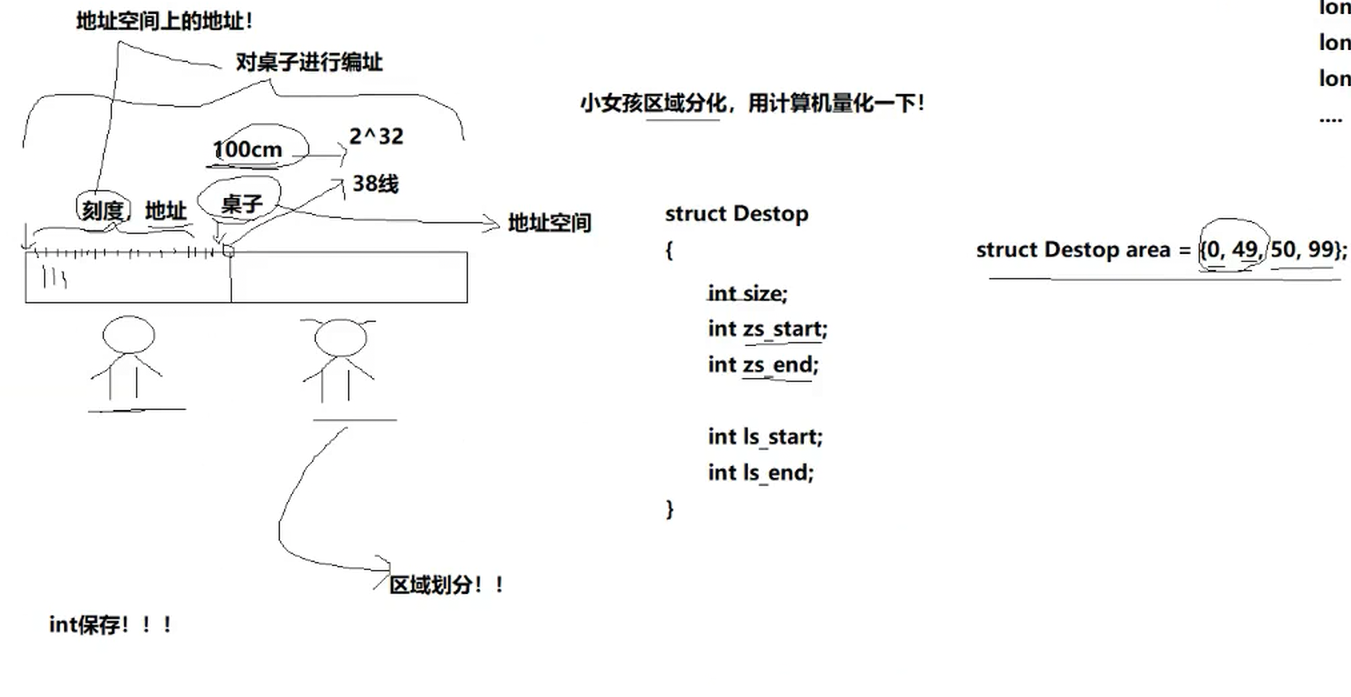
地址可以用int来保存
调整区域只需要对整数变量进行加减即可

从内核中看一下

如下图,这个过程为
1.在虚拟地址空间中申请(调整区域划分)指定大小的空间
2.加载程序,申请物理内存
最后页表进行映射,物理地址转化为虚拟地址,提供给上层用户
这也就是为什么我们上层查询看到的都是虚拟地址的原因
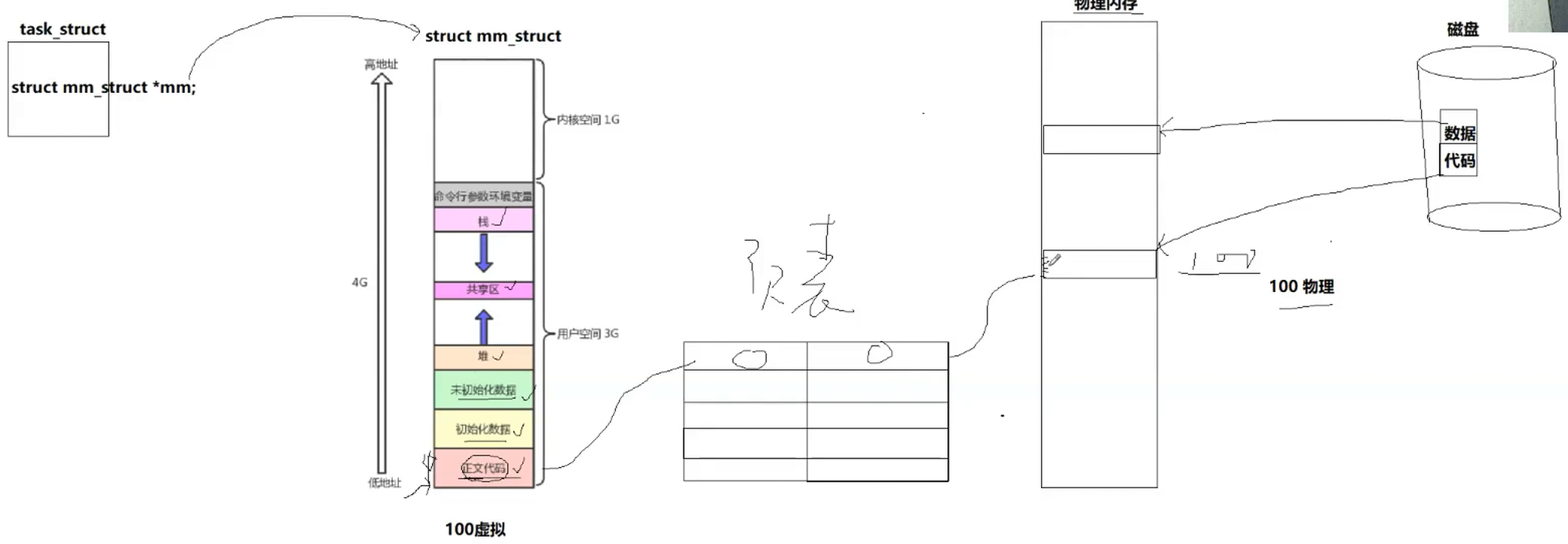
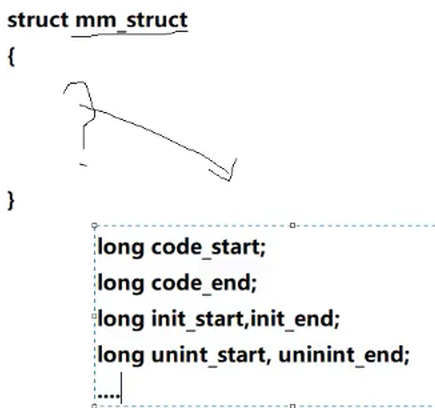
结论:地址空间(mm_struct)是个对象,但是对象需要被初始化
他是个结构体变量,在操作系统中需要开辟空间,定义出来这个结构体
那么这些初始化的值从哪里来?加载的时候,进行初始化
为什么要有虚拟地址空间和页表呢?
1.将地址从"无序",变"有序"
2.地址转换过程中,也可以对你的地址和操作进行合法性判定,进而保护物理内存

3.让进程管理和内存管理,进行一定程度解耦合
还有以下问题:
1.我们可以不加载代码和数据,只要task_struct、mm_struct、页表
2.创建进程,现有task_struct、mm_struct等,再加载代码和数据
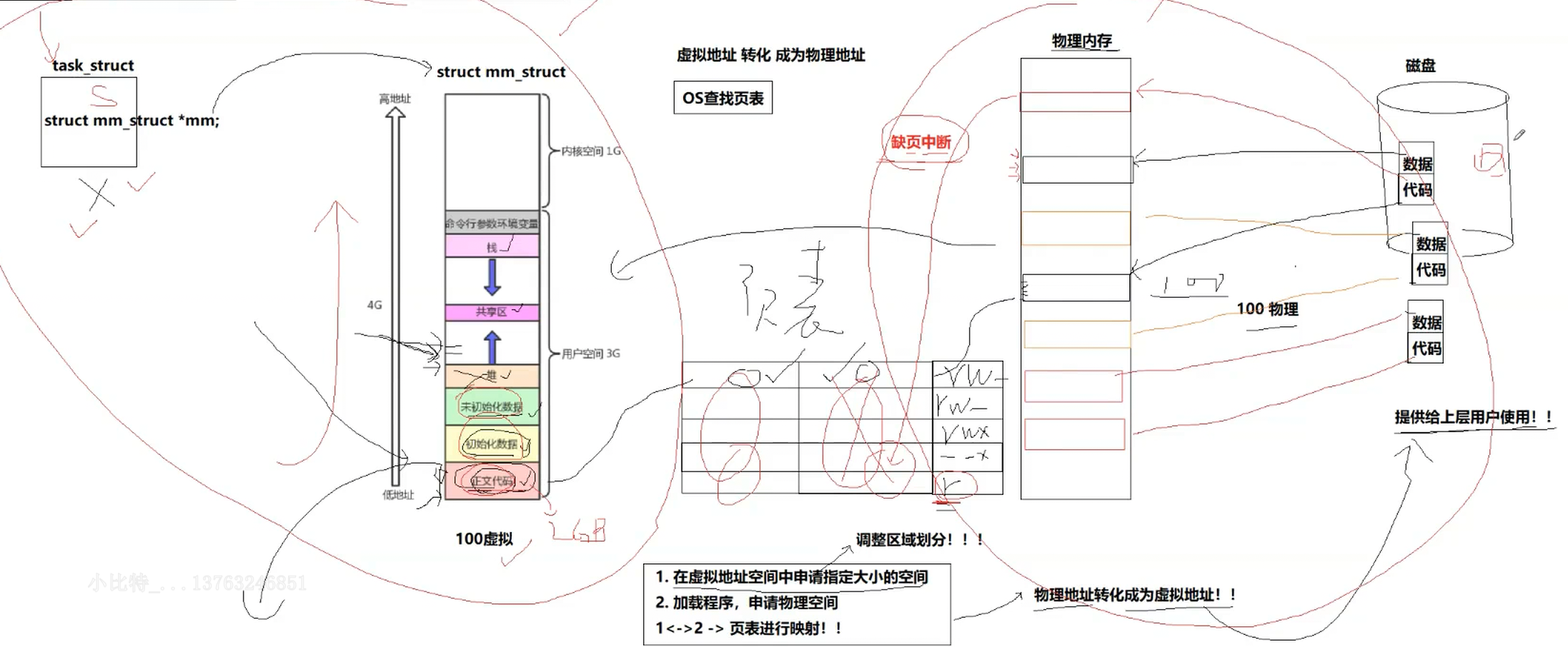
3.如上图,左半部分为进程管理,右半部分为内存IO等,此处对挂起的理解:当一个进程阻塞着,进入了阻塞队列,而且当前系统中内存资源严重不足,那么操作系统就要把当前进程的代码和数据唤出到磁盘上,需要的时候再唤入,也就是说进程挂起,先找到对应的进程状态也就是S,我们需要阻塞挂起,内存空间严重不足了,这时候操作系统查页表发现其虚拟地址和物理地址都有,就会把页表清空,指定的代码和数据都唤出到swap分区中,将保留左半部分,把右半部分唤出,内存就腾出来了
拓展
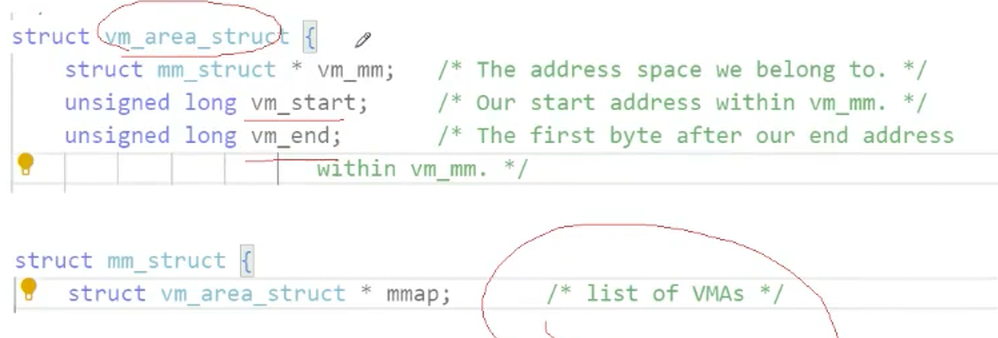
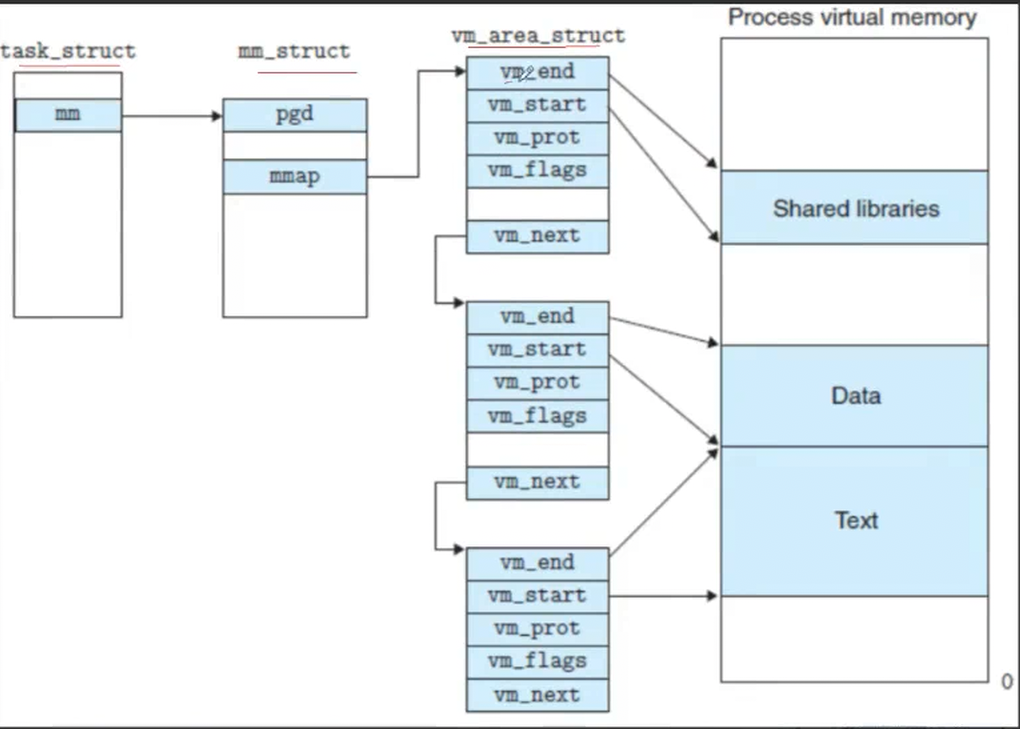
这里就可以将我们的堆区进行管理了,mm_struct会记录下来每个区域的开始和结束
描述linux下进程的地址空间的所有的信息的结构体是 mm_struct (内存描述符)。每个进程只有⼀个mm_struct结构,在每个进程的task_struct结构中,有⼀个指向该进程的结构。
可以说,mm_struct结构是对整个⽤⼾空间的描述。每⼀个进程都会有自己独立的mm_struct,这样每⼀个进程都会有⾃⼰独⽴的地址空间才能互不干扰
那既然每⼀个进程都会有自己独⽴的mm_struct,操作系统肯定是要将这么多进程的mm_struct组织起来的!虚拟空间的组织⽅式有两种:
-
当虚拟区较少时采取单链表,由mmap指针指向这个链表;
-
当虚拟区间多时采取红黑树进行管理,由mm_rb指向这棵树。
linux内核使⽤ vm_area_struct 结构来表示⼀个独⽴的虚拟内存区域(VMA),由于每个不同质的虚
拟内存区域功能和内部机制都不同,因此⼀个进程使⽤多个vm_area_struct结构来分别表示不同类型的虚拟内存区域。上⾯提到的两种组织⽅式使⽤的就是vm_area_struct结构来连接各个VMA,⽅便进程快速访问。
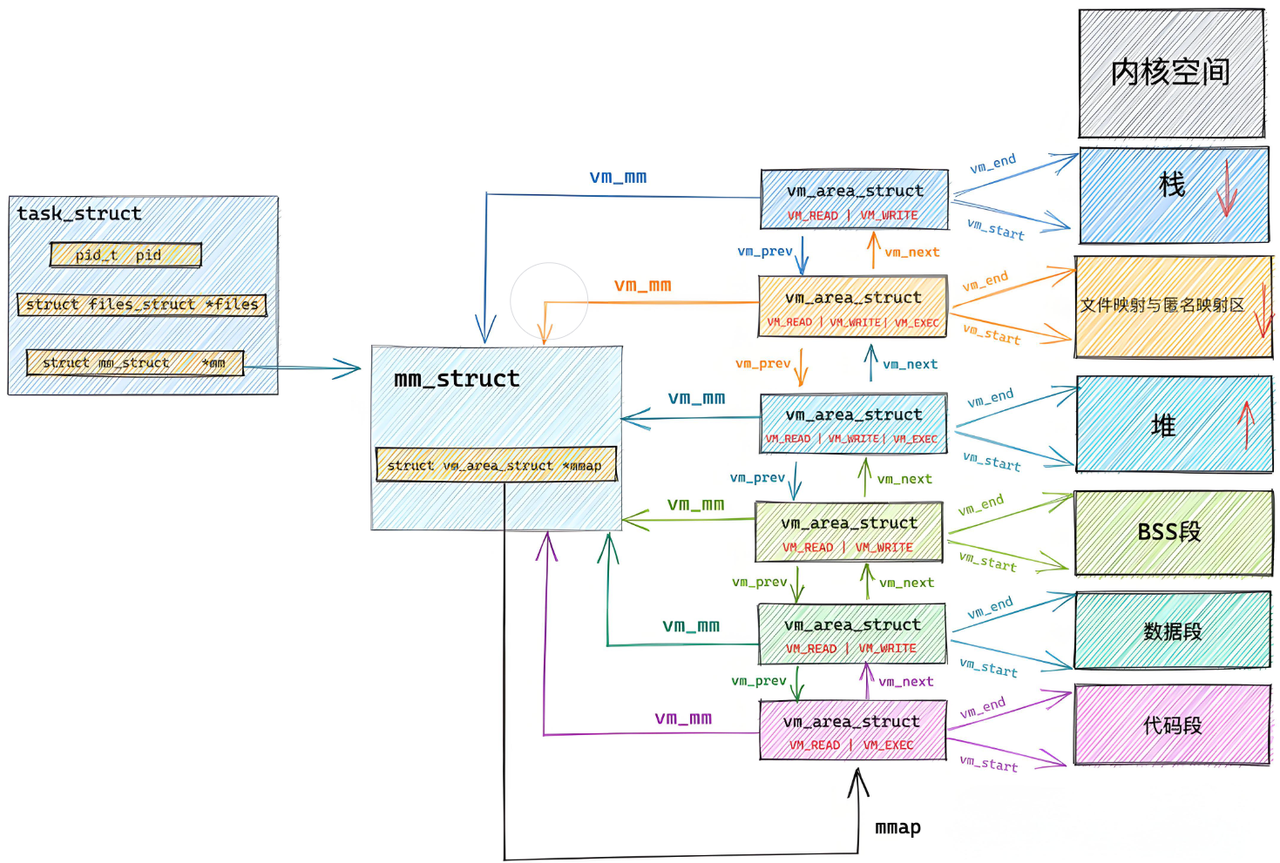
进程地址空间都是靠这一个个vm_area_struct来进行划分的
vm_area_struct如果太多了,就造成我们查找效率太低,可以列入红黑树当中
进程具有独立性:1.内核数据结构独立 2.加载进入内存的代码和数据独立