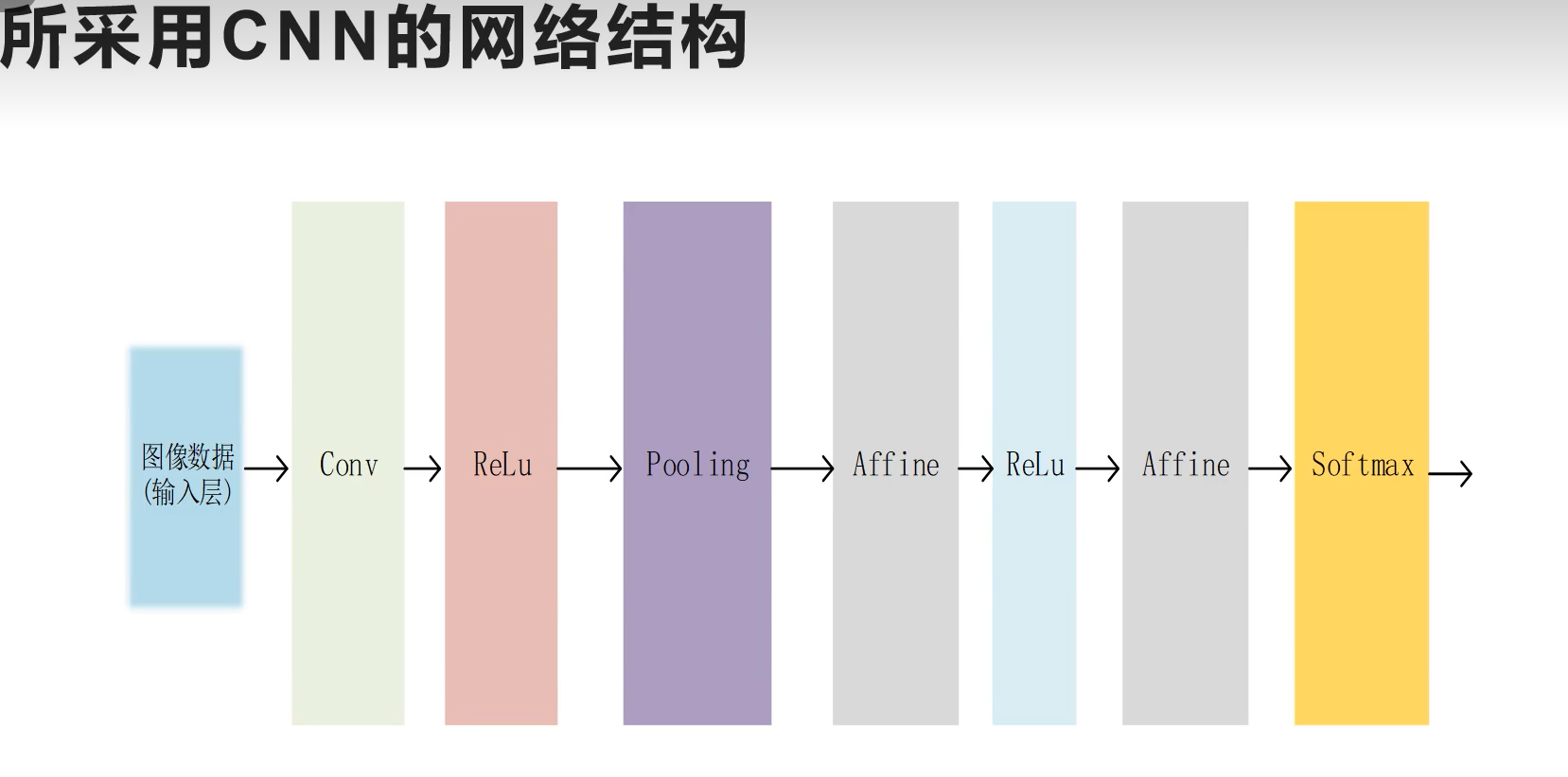
一、该 CNN 网络结构完整知识点总结
(一)整体前向传播流水线
完整数据流: 图像输入层 → Conv 卷积层 → ReLU 激活层 → Pooling 池化层 → Affine 全连接层 → ReLU 激活层 → Affine 全连接层 → Softmax 输出层 整体分为两大功能模块:
- 浅层特征提取模块:Conv+ReLU+Pooling(CNN 核心,提取图像局部视觉特征、降维)
- 高层分类拟合模块:两层全连接 + ReLU+Softmax(将提取到的特征映射为分类概率)
(二)每一层原理、作用、核心特性详解
1. 输入层:图像数据
- 数据格式:四维张量
[N, H, W, C]N:批次样本数;H/W:图像高、宽;C:通道数 - 常见形式:灰度图 C=1,RGB 彩色图 C=3
- 预处理要求:像素归一化至 0,1 或 -1,1,统一尺寸
2. Conv 卷积层(CNN 标志性核心层)
- 核心原理:用固定尺寸卷积核在图像上滑动,窗口内像素加权求和,生成特征图 Feature Map
- 三大核心优势
- 局部感受野:只关联局部像素,符合图像 "局部关联" 特性
- 权值共享:整张图共用同一套卷积核权重,极大减少参数量
- 平移不变性:物体轻微平移,依然能提取相同特征
- 可学习参数:卷积核权重、偏置 bias
- 输出尺寸计算公式: \(H_{out}=\lfloor \frac{H_{in}+2P-K}{S} \rfloor +1\) \(H_{in}\)输入高,P填充 padding,K卷积核尺寸,S步长 stride
3. ReLU 激活函数(隐藏层标准非线性激活)
- 数学表达式:\(f(x)=max(0,x)\)
- 核心作用:
- 引入非线性变换:仅靠卷积、全连接都是线性运算,多层线性等价单层,无法学习复杂图像特征;激活打破线性约束
- 缓解梯度消失:对比 Sigmoid/Tanh,梯度不会无限趋近于 0,深层网络更容易收敛
- 计算高效:仅做大小判断,无指数运算,训练速度更快
- 特性:负数值直接置 0,产生稀疏激活,轻微抑制过拟合
4. Pooling 池化层(下采样层,无训练参数)
主流两种:MaxPool 最大池化、AvgPool 平均池化
- 作用 1:压缩特征图长宽尺寸,降低后续计算量、参数量
- 作用 2:特征鲁棒性:轻微平移、缩放后依然能保留关键特征
- 作用 3:减少冗余信息,抑制过拟合
- 无权重、无偏置,纯固定运算,不参与反向传播参数更新
5. Affine 全连接层(仿射变换层)
- 数学公式:\(\boldsymbol{y}=\boldsymbol{W}\boldsymbol{x}+\boldsymbol{b}\),W 权重矩阵,b 偏置
- 前置要求:卷积输出的二维特征图必须先Flatten 展平为一维向量,才能送入全连接
- 功能:全局特征融合,把局部视觉特征映射为高层语义特征
- 缺点:参数量巨大,容易造成过拟合,是轻量化网络的瓶颈
6. Softmax 输出层(多分类任务专用)
- 公式:\(\sigma(\boldsymbol{z})i=\frac{e^{z_i}}{\sum{j=1}^C e^{z_j}}\),C 为分类类别总数
- 功能:将全连接输出的原始得分 logits,归一化为 0~1 之间概率,所有类别概率之和 = 1
- 使用场景:图像多分类任务;输出后取概率最大值对应的类别作为预测结果
- 区分:二分类任务一般用 Sigmoid,多分类统一用 Softmax
(三)该网络结构优缺点
优点
- 极简标准 CNN 基础模板,覆盖 CNN 全部核心组件,适合入门学习
- 单卷积 + 单池化轻量化,训练速度快,硬件资源消耗低
- 激活搭配行业标准:隐藏层 ReLU、输出层 Softmax,工业通用方案
- 结构逻辑清晰:先提取局部视觉特征,再融合全局特征做分类,符合图像识别逻辑
缺陷
- 仅 1 层卷积,无法提取深层语义特征,复杂图像识别精度差
- 缺少正则化层(Dropout、BatchNorm),训练极易过拟合
- 全连接层参数量庞大,内存占用高、推理速度慢
- 无多尺度特征融合,对大小差异大的物体识别效果差
二、完整工程实例:MNIST 手写数字 0~9 十分类(完全匹配图中网络)
1. 任务介绍
输入 28×28 单通道手写灰度数字图片,输出 0-9 共 10 个数字的预测概率。
2. 逐层参数配置
- 输入层 :张量尺寸
[batch, 28, 28, 1],单通道灰度图 - Conv 卷积层 :16 个 3×3 卷积核,padding=1,stride=1 尺寸计算:\((28+2×1-3)/1+1=28\),输出特征图
[batch,28,28,16] - ReLU 激活:逐元素非线性映射,过滤负值特征
- MaxPool 池化 :2×2 窗口,stride=2 尺寸计算:\(28/2=14\),输出
[batch,14,14,16] - 第一层 Affine 全连接 先展平:\(14×14×16=3136\) 个神经元,映射至 128 维隐藏向量
- ReLU 激活:给全连接结果引入非线性
- 第二层 Affine 全连接:128 维映射至 10 维(对应 0~9 十个数字 logits)
- Softmax 输出层:10 维 logits 转为 10 个类别概率
3. 完整推理实例
输入一张手写数字 "7" 图片:
- 卷积层提取笔画、拐角、轮廓等边缘纹理特征,生成 16 张特征图;
- ReLU 过滤无意义负值特征,保留有效纹理;
- 2×2 池化压缩尺寸,去掉细微噪点,保留数字核心轮廓;
- 展平后第一层全连接融合所有局部特征,压缩为 128 维高层特征;
- ReLU 再次增加非线性表达;
- 第二层全连接映射为 10 个数字原始得分;
- Softmax 归一化概率:数字 7 概率 0.97,其余数字概率均低于 0.02;
- 模型判定预测结果:数字 7。
4. 训练损失函数搭配
该网络分类任务搭配交叉熵损失 CrossEntropyLoss,Softmax + 交叉熵是图像分类标准组合。
三、配套练习题(单选 + 简答 + 计算题 + 代码填空)+ 逐题详细讲解
题型 1:单项选择题(共 6 道)
-
在该网络中,负责提取图像边缘、纹理等局部视觉特征的层是? A. ReLU B. Conv C. Pooling D. Softmax 答案:B 讲解:卷积层依靠卷积核滑动提取局部纹理;ReLU 仅做非线性激活;池化仅压缩尺寸;Softmax 输出分类概率。
-
下列哪一层不存在任何可训练权重参数? A. Conv B. Affine C. Pooling D. 第二个 Affine 答案:C 讲解:卷积、全连接都包含权重 W 和偏置 b;池化只是固定窗口取最大 / 平均值,无参数,反向传播不更新。
-
Softmax 层的核心作用是? A. 压缩特征图尺寸 B. 引入非线性变换 C. 输出归一化类别概率 D. 提取图像局部特征 答案:C 讲解:A 是池化功能;B 是 ReLU 功能;D 是卷积功能;Softmax 将原始得分转为总和为 1 的概率,用于多分类。
-
ReLU 函数数学表达式正确的是? A. \(f(x)=\frac{1}{1+e^{-x}}\) B. \(f(x)=max(0,x)\) C. \(f(x)=\frac{e^x}{\sum e^x}\) D. \(y=Wx+b\) 答案:B 讲解:A 是 Sigmoid;C 是 Softmax;D 是 Affine 全连接线性公式。
-
卷积输出的特征图送入 Affine 全连接前必须进行哪一步操作? A. ReLU 激活 B. Flatten 展平 C. 池化下采样 D. Softmax 归一化 答案:B 讲解:卷积输出是二维多通道特征图,全连接只接收一维向量,必须先展平。
-
网络两层 Affine 中间插入 ReLU 的根本目的是? A. 压缩特征维度 B. 引入非线性,提升拟合能力 C. 归一化输出概率 D. 减少参数量 答案:B 讲解:两层无激活的全连接等价于单层线性变换,无法学习复杂图像规律;ReLU 提供非线性映射。
题型 2:简答题(4 道,附完整标准答案 + 讲解)
第 1 题:简述 Conv 卷积层与 Pooling 池化层各自作用,二者配合的优势
参考答案:
- 卷积层:通过卷积核滑动遍历图像,提取边缘、纹理、轮廓等局部视觉特征;依靠权值共享大幅降低参数量,具备平移不变性。
- 池化层:对特征图下采样,缩小长宽尺寸,降低后续计算量;过滤微小噪点,增强特征对平移、缩放的鲁棒性。
- 配合优势:卷积提取精细局部特征,池化筛选保留关键有效特征并降维;在不丢失图像核心信息的前提下,大幅减少后续全连接层计算开销,同时抑制过拟合。
讲解:核心得分点要区分 "提取特征" 和 "降维筛选" 两个功能,说明二者组合是 CNN 特征提取的标准配对。
第 2 题:如果移除网络中所有 ReLU 层,模型会出现什么问题?
参考答案:
- Conv、Affine 均为纯线性变换,多层线性变换叠加等价于单层线性变换,网络失去非线性拟合能力;
- 无法学习图像中复杂的纹理、形状、语义特征,模型完全无法完成图像分类任务;
- 梯度传播全程无截断,极易出现梯度爆炸 / 梯度消失,网络无法收敛。
讲解:ReLU 的核心价值是提供非线性,是深层网络学习复杂特征的基础,所有隐藏层都不能缺少。
第 3 题:对比该单层 CNN 结构与 LeNet-5,说明本网络的优缺点
参考答案:
- 优点:结构更简单,仅 1 次卷积池化,参数量更少,训练速度更快,适合低分辨率简单图像;
- 缺点:仅单层卷积,无法提取深层语义特征,复杂图片识别精度低于多层卷积的 LeNet-5;缺少正则层,更容易过拟合;无多通道卷积堆叠,特征表达能力弱。
讲解:LeNet-5 为 2 层卷积池化,更深的特征提取主干,精度更高但计算量更大。
第 4 题:Softmax 为什么只用在网络最后一层,不能放在中间隐藏层?
参考答案:
- Softmax 会强制所有输出总和为 1,会压缩中间特征取值范围,丢失大量特征信息;
- Softmax 包含指数运算,计算开销远大于 ReLU,多层使用会大幅增加训练耗时;
- Softmax 的归一化是为分类概率设计,中间层只需要非线性映射,ReLU 更适配特征提取需求。
讲解:Softmax 是分类专用输出激活,隐藏层只需要简单、高效的 ReLU。
题型 3:计算题(基于 MNIST 实例,分步计算 + 讲解)
已知条件:输入图像 28×28×1;Conv 层 16 个 3×3 卷积核,padding=1,stride=1;后接 2×2 MaxPool,stride=2。 求解:
- 卷积层输出特征图尺寸
- 池化层输出特征图尺寸
- 池化输出展平后,输入第一层全连接的神经元总数量
分步计算与讲解
-
卷积尺寸公式: \(H_{out}=\lfloor \frac{H_{in}+2P-K}{S} \rfloor +1\) 代入数值:\(H_{out}=(28+2×1-3)/1 +1=28\) 卷积输出尺寸:28×28×16 讲解:padding=1 补一圈 0,保证卷积后长宽不变,称为 Same Padding。
-
池化下采样:无 padding,窗口 2×2,步长 2 \(H_{out}=28/2=14\) 池化输出尺寸:14×14×16 讲解:池化长宽直接除以步长,尺寸压缩为原来 1/2,总像素量压缩 1/4。
-
展平神经元总数 = 高 × 宽 × 通道数 \(14×14×16 = 3136\) 讲解:全连接输入必须是一维向量,多通道特征图所有像素全部拼接为一维。
题型 4:代码填空题(PyTorch 实现该网络,填空 + 逐行讲解)
python
运行
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
# 1. 卷积层:输入通道1,输出通道16,3×3卷积,padding=1
self.conv = nn.Conv2d(1, 16, kernel_size=3, padding=1)
# 2. 池化层 2×2最大池化
self.pool = nn.MaxPool2d(2, 2)
# 3. 第一层全连接:输入3136,输出128
self.affine1 = nn.Linear(______, 128)
# 4. 第二层全连接:输入128,输出10分类
self.affine2 = nn.Linear(128, ______)
# 激活与输出
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
# 卷积+激活+池化
x = self.conv(x)
x = self.relu(x)
x = self.pool(x)
# 展平操作,保留batch维度
x = x.view(x.size(0), -1)
# 两层全连接+激活
x = self.affine1(x)
x = self.relu(x)
x = self.affine2(x)
# 输出概率
out = self.softmax(x)
return out填空答案 + 讲解
- 第一个空:3136(计算题算出的展平神经元数量)
- 第二个空:10(MNIST 为 0~9 十分类,输出 10 维 logits)
逐行讲解:
nn.Conv2d:二维卷积,对应图中 Conv 层;nn.MaxPool2d:最大池化,对应图中 Pooling;nn.Linear:Affine 全连接层;x.view(x.size(0), -1):Flatten 展平,只保留 batch 维度,其余合并为一维;- forward 流程严格和流程图完全对应:Conv→ReLU→Pooling→Affine→ReLU→Affine→Softmax。
四、拓展核心考点总结(考试高频)
- 结构划分:Conv+Pooling = 特征提取主干;多层 Affine = 分类头;
- 激活区分:隐藏层统一 ReLU,多分类输出层 Softmax,二分类 Sigmoid;
- 数据流顺序:图像必须先卷积提取局部特征,再展平送入全连接,不可颠倒;
- 参数区分:Conv、Affine 含可训练权重;ReLU、Pooling、Softmax 无训练参数;
- 计算核心:卷积 / 池化输出尺寸公式、展平神经元数量计算是必考计算题;
- 缺陷优化拓展:该网络过拟合可添加 Dropout 层;精度不足可增加卷积堆叠;参数量过大可用全局平均池化替代全连接。