核心创新与影响
- 3×3卷积堆叠 :2个3×3=5×5感受野,3个3×3=7×7,参数更少、深度更深、特征更抽象。计算成本。假设输入输出channel均为C,3个3x3参数个数为3x(3x3xCxC)=27xC²,一个7x7参数个数为7x7xCxC=49xC²,因此用3个3x3的卷积层等于一个7x7的卷积层但是节省近一半的参数计算量。
- 深层特征提取 :从8层到16/19层,错误率显著下降,网络深度至关重要:16--19 层显著优于浅层(如 8 层 AlexNet)
- 简洁通用 :模块化设计,易复现、易迁移 ,仅使用 3×3 卷积 + 2×2 最大池化,无复杂模块,易于理解、复现与修改
- 局限性 :参数量大、训练慢、显存占用高;
原始论文PDF
论文地址:https://arxiv.org/pdf/1409.1556.pdf
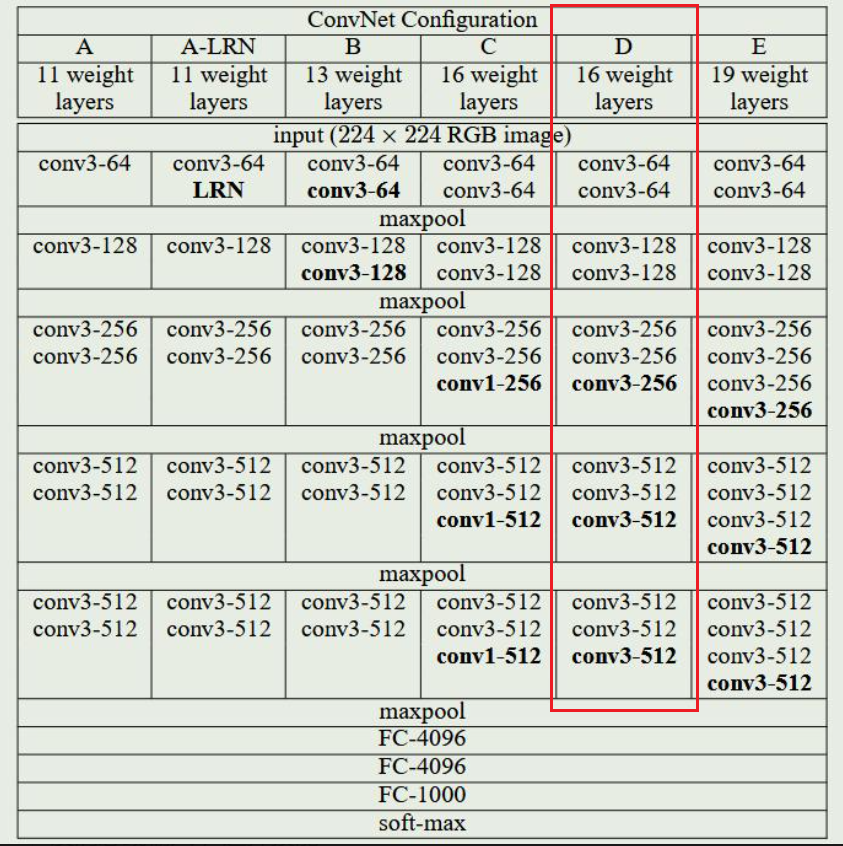
VGG16 模型结构(16层:13 conv + 3 FC)
输入:224×224 RGB 图像,
1)卷积块(5组,每组 Conv→ReLU→MaxPool)
- Block1 :2×Conv3×3,64 → ReLU → MaxPool2×2
输出:224→112,通道64 - Block2 :2×Conv3×3,128 → ReLU → MaxPool2×2
输出:112→56,通道128 - Block3 :3×Conv3×3,256 → ReLU → MaxPool2×2
输出:56→28,通道256 - Block4 :3×Conv3×3,512 → ReLU → MaxPool2×2
输出:28→14,通道512 - Block5 :3×Conv3×3,512 → ReLU → MaxPool2×2
输出:14→7,通道512
2)全连接层(FC)
- FC1:7×7×512 → 4096,ReLU,Dropout
- FC2:4096 → 4096,ReLU,Dropout
- FC3:4096 → 1000(ImageNet 类别),Softmax
参数计算
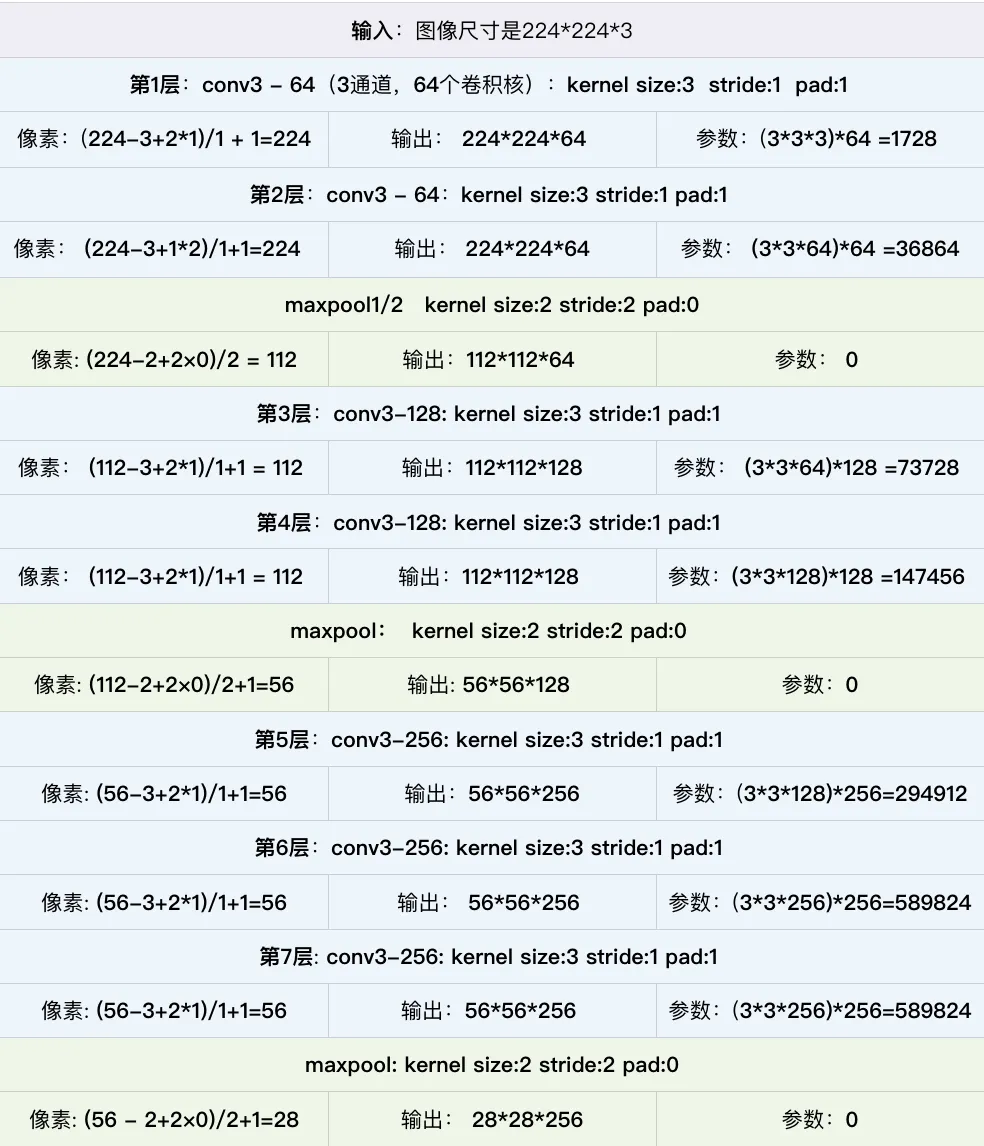
论文模型复现
使用 配置D(VGG16):13 conv(全 3×3)+3 FC,16 层(常用)
python
import torch
import torch.nn as nn
# 使用 配置D(VGG16):13 conv(全 3×3)+3 FC,16 层(常用)
class VGG16(nn.Module):
def __init__(self, num_classes=1000):
super().__init__()
self.features = nn.Sequential(
# Block1
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block2
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block3
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block4
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# Block5
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(in_features=512*7*7, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(in_channels=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(in_channels=4096, out_features=num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 测试
model = VGG16()
x = torch.randn(1, 3, 224, 224)
print(model(x).shape) # torch.Size([1, 1000])