【LLM】第一章:知识体系框架概览
大模型,具体说就是大语言模型,LLM,large language model,这个领域其实就是NLP,所以本专栏也是NLP专栏的延续,是NLP的高阶内容。
我的NLP专栏的链接是: https://blog.csdn.net/friday1203/category_12833594.html?spm=1001.2014.3001.5482
想真正学习的同学,建议从NLP看起,如果NLP也看不懂就从机器学习看起。正确的学习路径是:机器学习-深度神经网络-->卷积神经网络-->NLP-->LLM,这样一个环环相扣、逻辑链条完整的路径。本专栏不再补充底层知识点,默认你对transformer的边边角角的细节都是非常清晰的。NLP专栏中的Transformer我总共写了10万多字,相关细节数100个都不为过,所以没有Transformer底子的同学,最好是先补基础,再图进阶。
一、NLP建模范式的变化
Transformer爆火后,随之带来的就是大模型的研发和训练微调技术。大模型的建模范式和我们之前的任务都不一样 ,下面从建模范式出发梳理一下大模型的相关概念:
1、预训练模型(Pre-trained Model)、迁移学习(Transfer Learning)
何为大模型?大模型不仅仅是大语言模型这么单一的定义,从技术角度看,大模型其实就是一个预训练模型 。那么又何为预训练模型?
预训练模型是指模型已经在大规模数据集上训练好了。就是这个模型已经见过几乎所有的样本了,而且在这些样本上已经收敛的很好了。
模型已经见过几乎所有的样本 ,就是这个模型已经是这个领域的通用模型 了,因为它学习了几乎所有的样本。
模型已经在这些样本上收敛的很好了,就是说这个领域的基本的、普遍的、大众的规律,这个模型已经掌握了,就是这个模型可以提取这个领域的普适特征和规律了。
这就好比一个让一个识字的人 去看医书,这个识字的人就是一个预训练模型,或者说是一个通用模型。这个识字的人学习医术的过程就叫迁移学习 (Transfer Learning),就是把一个大型数据集上学习到的知识迁移到另一个相关但不同的任务上 。
如果你让一个不识字的人去看医书,这个人还得从先识字开始学,识完字了才能学医,那这个人就不是一个预训练模型。这个人得从0开始学习,就要费劲很多。
所以我们都喜欢预训练模型,因为让一个预训练模型去学习医学、法律、会计、计算机等等专业领域,它起步很高,能很快在这些专业方向学出规律,省劲儿并高效嘛。
2、为什么会出现预训练模型?什么是微调fine-tune?
在前面NLP专栏里,我写过两个实操项目,从中可以看出:针对不同的任务,我们要根据具体任务的特点,开发出适配这个任务的 模型,然后再训练模型,直到模型达到任务预设的精度,才算是完成了任务。而且每种任务需要的数据和标签都不一样,数据和标签又是严重依赖人工标注的,那这个时间成本和资金成本就非常高昂了。
在这个约束下,如何让大模型赋能各行各业?于是预训练+微调的建模范式进入了研究者的视线:
(1)预训练阶段 :在大规模没有标注 的语料上,通过比如挖空,让模型填坑的方式,或者通过比如前面任务中的使用滑窗自动生成特征和标签的方式,亦或者通过输入一个序列,让模型rightshift一个位置,原封不动输出这个序列的方式,让模型学习大规模语料中的词汇、句法和上下文等通用的语言规律。如此训练一个通用的语言模型的操作就是预训练阶段。
(2)微调阶段 :就是将预训练模型迁移 至具体任务,比如医疗、法律等专业领域。具体操作就是使用这些专业领域的少量标注数据微调(fine-tune)模型,直到模型效果达到预期。
目前这种建模范式已经成为当前NLP的主流技术路线,广泛应用于文本分类、问答系统、翻译、对话等任务中。
3、微调fine-tune技术有哪些?
最简单的微调就是根据你的具体任务,添加一个最后的输出层,用少量的专业标注数据进行训练调参。调参可分为全参微调 和只调你最后添加的输出层两种方式。
但是,在微调过程中,会有很多技巧,比如生物反馈式强化学习RLFH、近端策略优化PPO、奖励权重策略reward-based weighting、DeepSpeed训练引擎、有监督的微调SFT, 低阶自适应微调方法LoRA、提示词前缀微调方法Prefix Tuning、轻量级Prefix微调Prompt Tuning、百倍效率提升的微调方法P-Tuning V2、自适应预算分配微调方法AdaLoRA等。眼花缭乱,涉及的知识域非常广,后面慢慢梳理吧。。。。
二、预训练模型的分类
目前市面上的预训练模型的基础架构基本上都是Transformer。我们知道Transformer是编码器-解码器的架构,所以根据使用Transformer的不同方式,预训练模型分:
(1)解码器(Decoder-only)模型 :仅使用Transformer的解码器,代表模型为GPT,Generative Pre-trained Transforer,由OpenAI于2018年6月提出,论文是《Improving Language Understanding by Generative Pre-Training》。
(2)编码器(Encoder-only)模型 :仅使用Transformer的编码器,代表模型为BERT, Bidirectional Encoder Representations from Transformers,由Google于2018年10月提出,论文是《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》。就是一个上下文相关的词表示模型。
(3)编码器-解码器(Encoder-Decoder)模型 :同时使用Transformer的编码器和解码器,代表模型是T5 ,Text-to-Text Transfer Transformer, 由Google于2019年10月提出,论文是《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》。这里的Transfer就是迁移学习 的意思,也就是预训练模型+微调的意思。
后面我会对GPT、BERT、T5这三个模型分别整理一个篇章,详细写这三个模型的细节问题。
三、预训练模型的发展脉络
自GPT、BERT、T5等模型发布以来,基于Transforer的预训练模型呈爆发态势,大家争先恐后的在模型架构上增加层数,扩大模型深度,增加模型参数,也就是后来的Scaling竞赛,大力出奇迹,大模型的预测能力也持续提升,直到Scaling不动才销声匿迹。下图是2008年至2023年间具有代表性的模型及其发展脉络: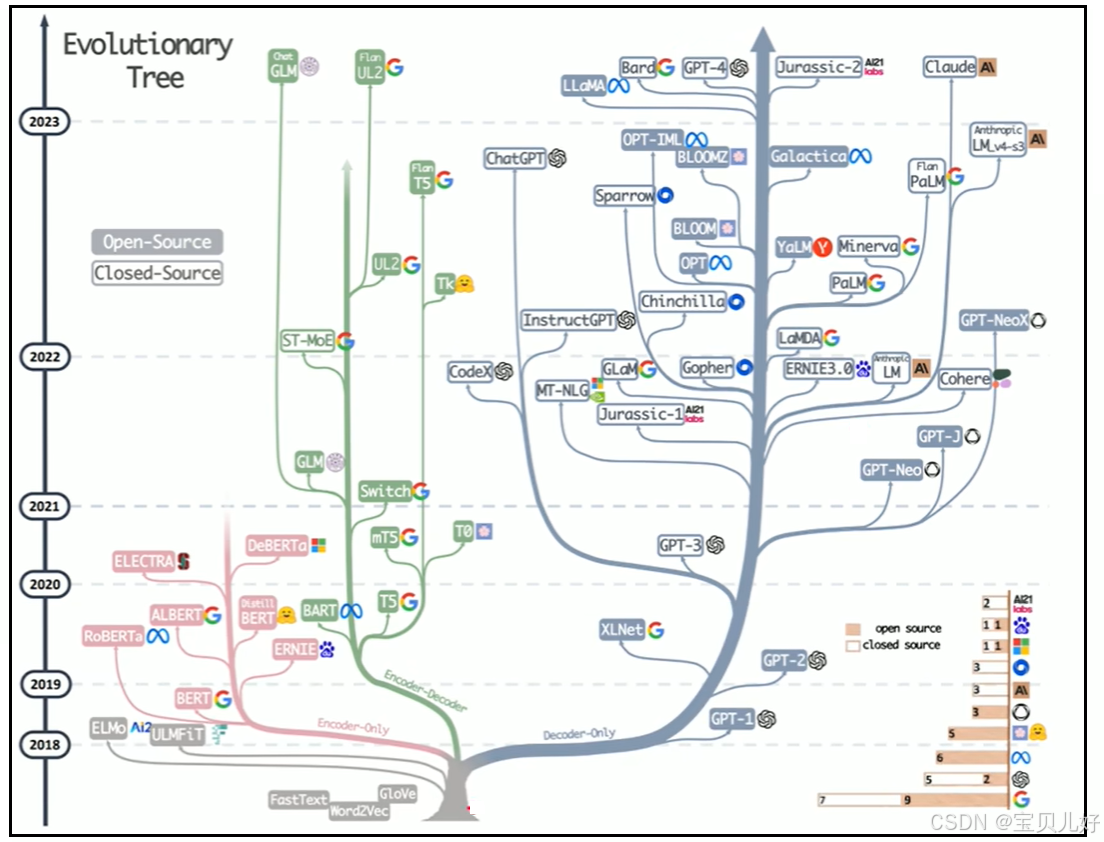
四、模型效果评价:基准任务
GLUE Benchmark是自然语言处理(NLP)领域用来给AI模型"打分"的一套标准考试题,全称为The General Language Understanding Evaluation(通用语言理解评估)。它由纽约大学等机构在2018年推出,目的是通过不同的任务,全面测试模型能不能读懂人类语言,比如判断句子情感、逻辑关系或语义相似度 。如果你想查看官方榜单 或下载数据 ,可以访问GLUE官网:GLUE Benchmark
本系列后面将讲的一些模型,比如BERT、T5等,它们的benchmark都是使用该网站上的数据集测评出来的分值: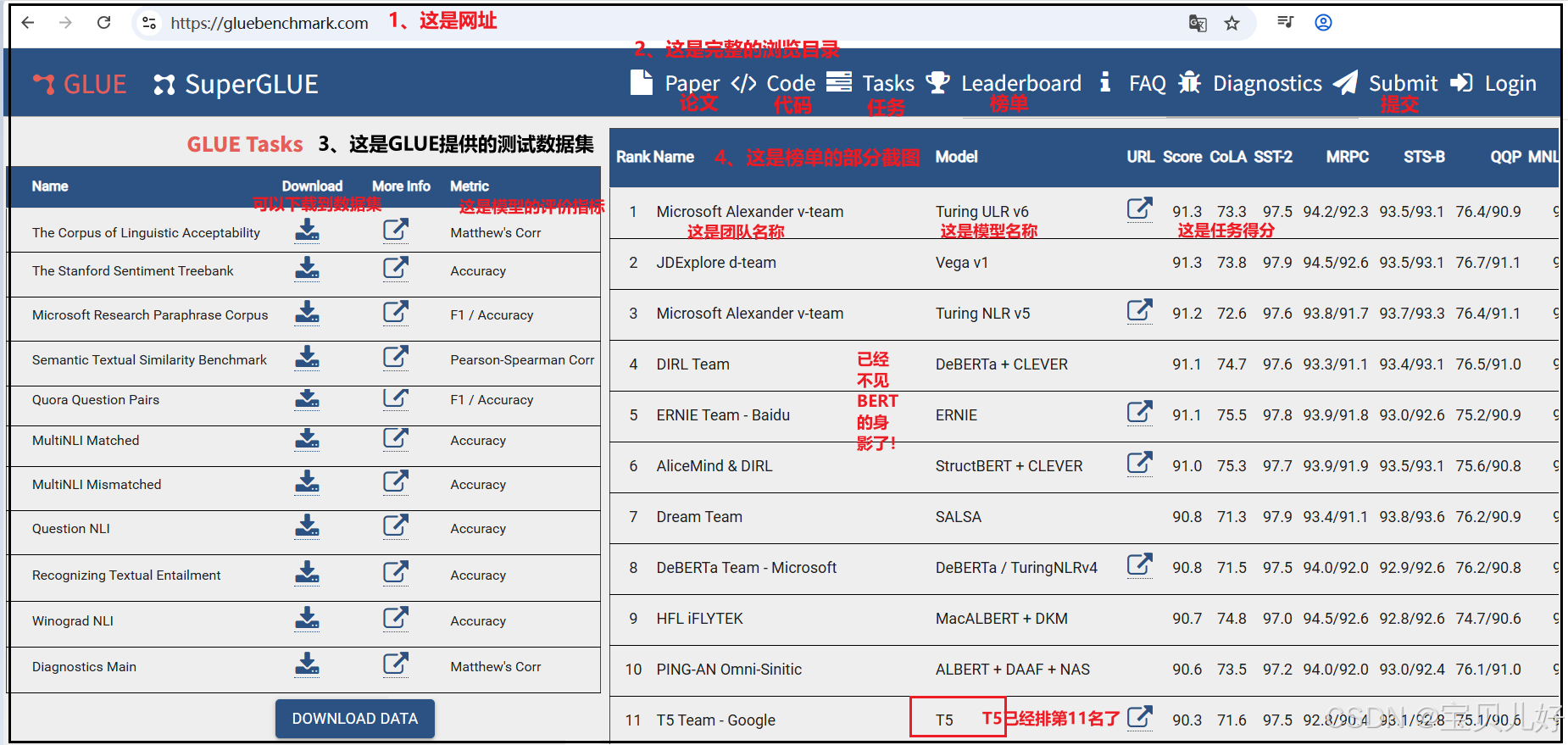 如果你对你的模型非常自信的话,就用上面的数据集去测试一下,能排到前列是非常牛的。
如果你对你的模型非常自信的话,就用上面的数据集去测试一下,能排到前列是非常牛的。
五、本系列专栏的内容介绍
1、因为预训练大模型的框架是HuggingFace,所以我们会先简单介绍一下HuggingFace的基本操作。
2、此后我们会详细讲解GPT\BERT\T5这三个经典预训练模型的架构、输入输出、根据下游具体任务的微调方式,并配上一些小案例。
3、最后介绍一些比较经典的大模型微调技术,比如RLFH、LoRA等。