第三部分:Claude Code 深度使用与进阶技巧
学习目标:在掌握安装与基础配置后,深入掌握 Claude Code 的全部用法与进阶技巧,让 AI 真正成为你的高效编程搭档
完成标志:能熟练使用 Claude Code 完成完整开发流程,并掌握高阶配置、最佳实践与进阶能力完成标志:能熟练使用 Claude Code 完成完整开发流程,并掌握高阶配置、最佳实践与进阶能力好,到这里你已经能把 Claude Code 跑起来了。前面两部分你完成了:
第零部分:准备好了开发环境(Node.js、Git、VS Code 等)
第二部分:了解了 AI 编程工具生态,安装并配置好了 Claude Code,也理解了不同模型的特点与选型策略
但很多人就停在了这一步 ------ 会用,但用得不顺手。用久了你会发现三个问题:
它怎么把文件改坏了? → 你得学会管住它
用着用着怎么变笨了? → 你得学会管理上下文
它对每个人都一样,怎么让它懂我? → 你得学会个性化配置
本部分就是解决这三个问题的。先了解全局框架,再逐个深入。
Claude Code 的能力可以按 7 层扩展(Harness) 来理解。Anthropic 官方在 2026 年 5 月的企业级指南中总结了这个框架:
-
CLAUDE.md --- 项目说明书,每次会话自动加载
-
Hooks --- 事件触发器,在特定时机自动执行
-
Skills --- 专业知识库,AI 按需加载
-
Plugins --- 把 Skills + Hooks + MCP 打包分发
-
LSP --- 给 AI 装上 IDE 级的代码导航
-
MCP --- 连接外部工具和数据源
-
子 Agent --- 独立上下文并行干活
前 3 层是基础配置,后 4 层是高级扩展。本部分和第四部分会逐个展开。
官方反复强调一个观点:模型能力是地板,配置质量才是天花板 。花时间把配置做好,比追最新模型版本更有实际收益。
3.1 模型选择与切换
配置好 API 后,你可能会问:"这么多模型,我该用哪个?" 这一节帮你解答。
| 模型 | 速度 | 代码质量 | 推理能力 | 成本 | 推荐场景 |
|---|---|---|---|---|---|
| Claude Haiku 4.5 | 极快 | 良好 | 中等 | $ 较低 | 简单代码补全、格式化、小修改 |
| Claude Sonnet 4.6 | 快 | 优秀 | 强 | $$ 适中 | 日常开发、功能实现(默认推荐) |
| Claude Opus 4.7 | 中等 | 顶级 | 极强 | $$$ 较高 | 复杂架构设计、疑难 Bug、算法难题 |
成本估算参考(2026-05-18 核对)
| 模型 | 输入费用 | 输出费用 | 一次普通编程对话费用 |
|---|---|---|---|
| Claude Haiku 4.5 | $1 / 百万 Token | $5 / 百万 Token | 低成本批量处理 |
| Claude Sonnet 4.6 | $3 / 百万 Token | $15 / 百万 Token | 日常开发主力 |
| Claude Opus 4.7 | $5 / 百万 Token | $25 / 百万 Token | 复杂问题少量使用 |
日常开发使用 Sonnet 就足够了。只在遇到特别复杂的问题时才切换到 Opus。Haiku 适合大批量处理简单的任务。
在 Claude Code 中切换模型(四种方式)
Claude Code 提供了四种模型切换方式,按优先级从高到低排列:
方法一:启动时指定(临时使用)
# 使用模型别名(推荐,自动指向最新版本)$ claude --model opus # 最强推理$ claude --model sonnet # 日常编码(默认)$ claude --model haiku # 快速轻量# 使用具体模型名时,请以当前服务商官方文档为准$ claude --model opus$ claude --model "deepseek-v4-pro[1m]"方法二:运行中切换(使用斜杠命令)
在 Claude Code 对话中直接输入:
> /model # 打开模型选择器(交互式)> /model sonnet # 直接切换到 Sonnet> /model opus # 直接切换到 Opus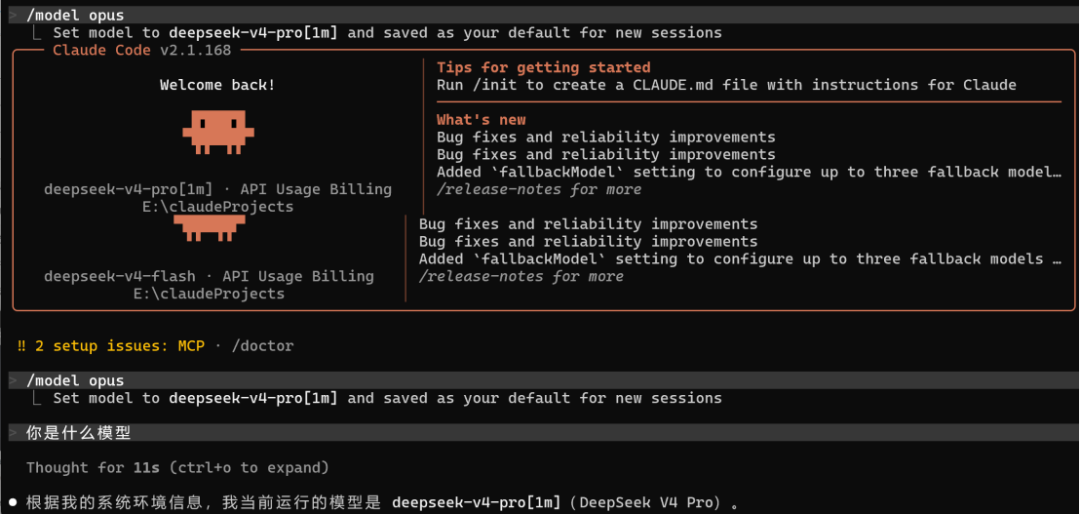
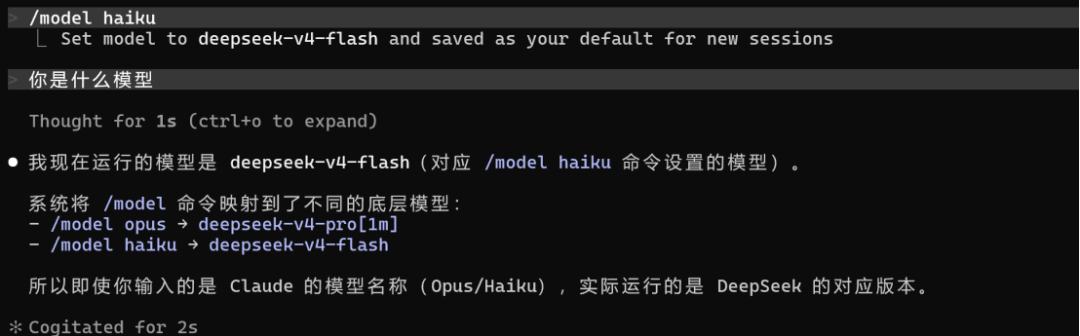
方法三:环境变量持久设置
# 设置默认使用的模型(支持别名或具体名称)export ANTHROPIC_MODEL="sonnet"方法四:配置文件持久设置(推荐)
在 settings.json 中设置 model 字段,重启即生效:
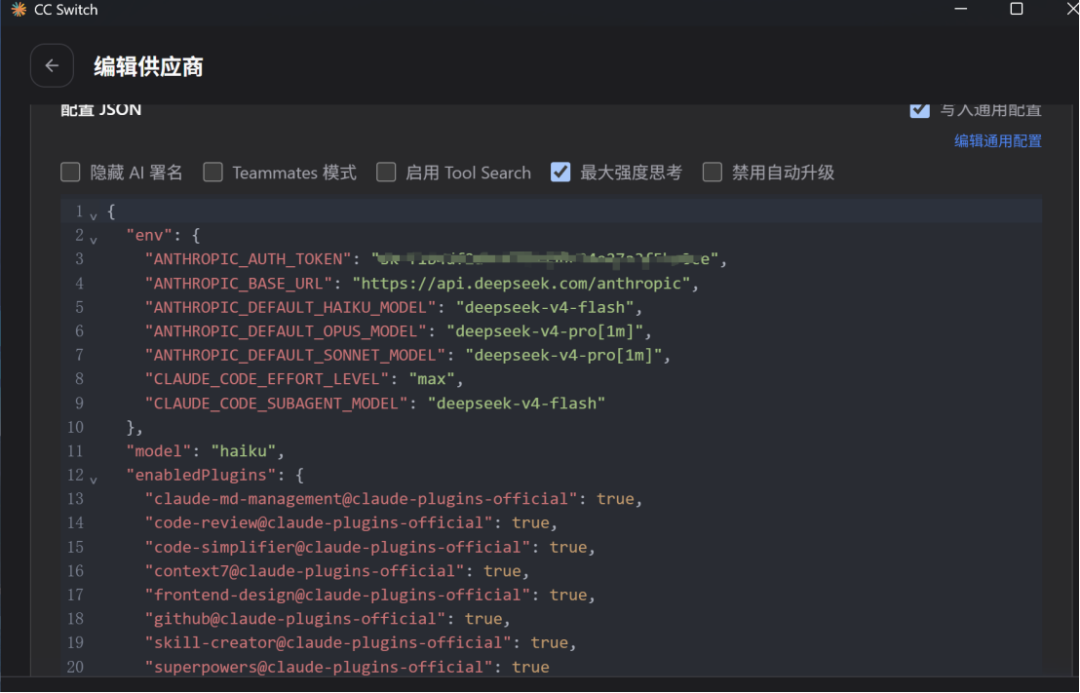
// ~/.claude/settings.json(全局生效){ "model": "sonnet" }// 项目/.claude/settings.json(仅该项目生效){ "model": "opus" }可以通过cc-switch查看
配置文件层级说明
| 配置文件位置 | 作用范围 | 是否提交 Git | 优先级 |
|---|---|---|---|
| ~/.claude/settings.json | 全局(所有项目) | 否 | 低 |
| 项目 /.claude/settings.json | 当前项目(团队共享) | 是 | 中 |
| 项目 /.claude/settings.local.json | 当前项目(个人私有) | 否(gitignore) | 高 |
不同模型的使用建议
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 日常功能开发 | Claude Sonnet | 速度和质量的最佳平衡 |
| 简单代码修改 / 格式化 | Claude Haiku | 足够胜任,成本最低 |
| 复杂架构设计 | Claude Opus | 最强推理,值得多花钱 |
| Bug 调试(简单) | Claude Sonnet | 通常够用 |
| Bug 调试(复杂) | Claude Opus 或 DeepSeek V4 Pro | 需要深度推理 |
| 中文项目文档 | Claude Sonnet / 通义千问 | 中文能力出色 |
| 预算紧张 | DeepSeek API / GLM / Kimi | 按当前价格选择性价比方案 |
| 离线 / 隐私敏感 | 本地 Ollama 模型 | 完全本地,免费 |
3.2 核心配置详解
Claude Code 有多层配置体系,从全局到项目级,层层覆盖。
配置层级
-
全局配置(影响所有项目):
~/.claude/settings.json -
项目级配置(只影响当前项目):项目根目录 /.claude/settings.json
-
项目上下文文件(告诉 AI 项目背景信息):项目根目录 /CLAUDE.md ← 最重要!
3.2.1 settings.json 配置文件
Claude Code 的配置文件位于 ~/.claude/settings.json(全局)或项目目录下的 .claude/settings.json(项目级)。复制到文件时,把注释删掉。
{ // 允许 Claude Code 执行的操作(不再需要每次确认) "permissions": { "allow": [ "Read", // 读取文件 "Write", // 写入文件 "Bash(npm *)", // 执行 npm 命令 "Bash(git *)", // 执行 git 命令 "Bash(node *)" // 执行 node 命令 ], "deny": [ "Bash(rm -rf *)" // 禁止执行危险的删除命令 ] }, // 默认使用的模型 "model": "sonnet", // 自动紧凑阈值(上下文使用超过此比例时自动压缩) "autoCompactThreshold": 80}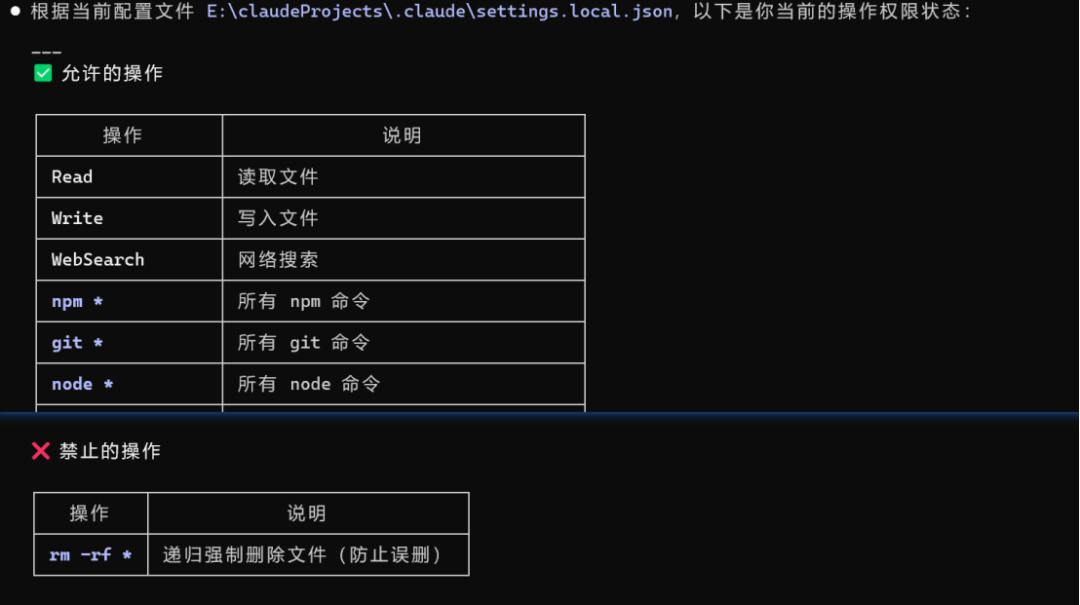
注意:权限设置要谨慎。过于宽松的权限可能导致 AI 执行你不期望的操作。建议初学者保持默认设置,让Claude Code 在执行每个操作前都询问你确认。
Setting.json 相关总结
-
在用户自己的 setting.json 中配置 env 不对外暴露
-
使用CCSwitch管理 env 不对外
-
在工作目录里面创建
.claude/setting.json或者.claude/setting.local.json添加允许的操作和禁止的操作
3.2.2 CLAUDE.md:你的项目 "说明书"
CLAUDE.md 是 Claude Code 中最重要的配置文件之一。它就像你给新来的实习生写的 "项目入职手册"------ 告诉 AI 这个项目的背景、技术栈、编码规范和当前进度。
为什么 CLAUDE.md 如此重要?
没有 CLAUDE.md 时,Claude Code 每次开始工作都要花时间 "重新认识" 你的项目。有了 CLAUDE.md,它一启动就知道项目的全部背景,效率大幅提升。
CLAUDE.md 文件模板
## 项目名称## 项目概述一句话描述这个项目做什么。## 技术栈- 前端:Next.js 14 + TypeScript + Tailwind CSS- 后端:Next.js API Routes- 数据库:Prisma + SQLite- 部署:Vercel## 项目结构```textsrc/├── app/ # Next.js App Router 页面│ ├── api/ # API 路由│ ├── layout.tsx # 全局布局│ └── page.tsx # 首页├── components/ # React 组件│ ├── ui/ # 通用UI组件│ └── features/ # 业务组件├── lib/ # 工具函数和配置├── prisma/ # 数据库 schema 和迁移└── types/ # TypeScript 类型定义## 编码规范 - 使用函数式组件 + React Hooks- 组件文件使用 PascalCase 命名(如 BookmarkCard.tsx)- 工具函数使用 camelCase 命名- API 路由返回统一格式:{ success: boolean, data?: any, error?: string }- 所有数据库操作通过 Prisma Client 执行## 当前开发状态- 项目初始化完成- 数据库 Schema 设计完成- 书签 CRUD API 开发中- 前端页面待开发- 搜索功能待开发## 注意事项- SQLite 数据库文件在 prisma/dev.db,不要提交到 Git- 环境变量在 .env 文件中,不要提交到 Git- 所有新功能先创建 Git 分支再开发对于claude非常重要,但是不一定要手写,可以通过AI生成。
CLAUDE.md 的三个层级(由顶向下叠加生效)
很多人只知道 CLAUDE.md 可以放在项目根目录,其实官方设计了 3 个层级的 CLAUDE.md,它们会同时生效、不冲突:
| 层级 | 路径 | 作用范围 | 适合写什么 |
|---|---|---|---|
| 全局级 | ~/.claude/CLAUDE.md |
所有项目都会读 | 个人习惯、身份、翻译偏好(如 "永远用中文回答"、"我是 xx、从事 xx") |
| 项目级 | 项目根目录 /CLAUDE.md |
仅本项目 | 项目技术栈、架构、规范、进度(可提交 Git,团队共享) |
| 文件夹级 | 子目录 /CLAUDE.md |
仅该子目录 | 模块专属约定(如 src/payment/CLAUDE.md 写支付模块踩过的坑) |
三层叠加生效,不冲突。优先级:文件夹级 > 项目级 > 全局级。
全局配置的claude.md模板参看
## 沟通方式- 默认中文回复;代码、命令、变量名、文件路径保持英文- 结论先行,简洁直接,不先铺垫背景- 不谄媚,不夸"这是个很好的问题",不以"当然可以"开头- 给真实判断------方案有问题直接指出,发现更好做法主动说明## Git- 不自动 `git commit` 或 `git push`,除非我明确要求- 提交前先展示将要提交的变更摘要- commit message 使用简洁英文## 红线操作以下操作即使在 auto-accept 模式下也必须先问我:- 删除文件、目录或 git 历史- 修改 `.env`、密钥、token、证书、CI/CD 配置- `git push`、`git rebase`、`git reset --hard`、强制推送- 公开发布(`npm publish`、生产部署等)两个官方推荐的创建姿势:
-
/init 创建项目级:在项目根目录下运行 claude 后输入
/init,CC 会自动扫描项目并生成一份 CLAUDE.md 初稿,你再调整。官方建议:项目有一定规模再/init效果更好(太空它扫不出什么东西)。 -
/memory 编辑全局级:在 CC 会话里输入
/memory选择 "全局 CLAUDE.md",会用默认编辑器打开该文件供你修改。修改全局后需重启 CC 才生效。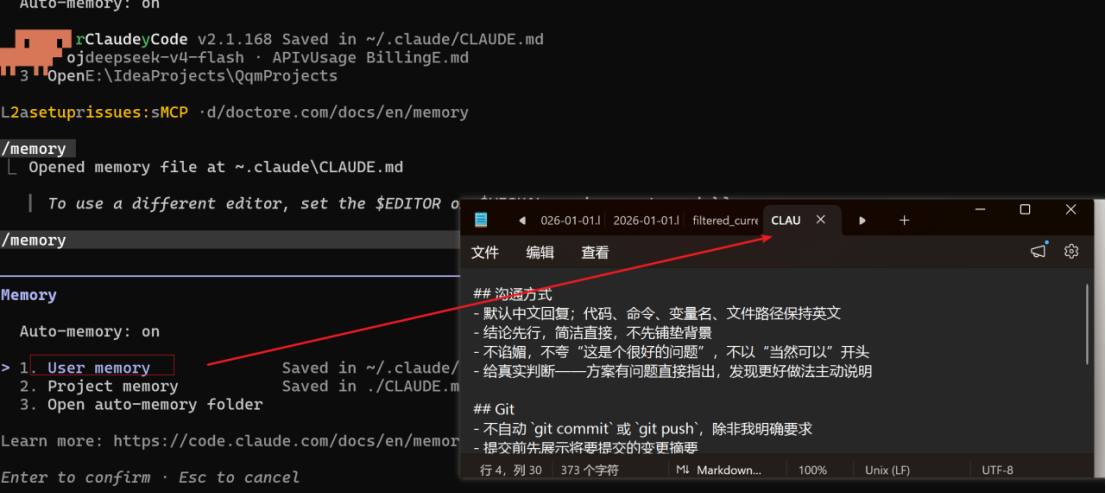
最佳实践:
-
保持更新:项目级 CLAUDE.md 应该是动态的 ------ 项目加了功能、踩了坑,就同步更新
-
足够具体:技术栈写明具体版本号,目录结构要与实际一致
-
写明禁忌:把 "不要做什么" 也写清楚(如 "不要修改数据库迁移文件")
-
适度简洁:不要写成论文,AI 需要的是关键信息而非赘述
-
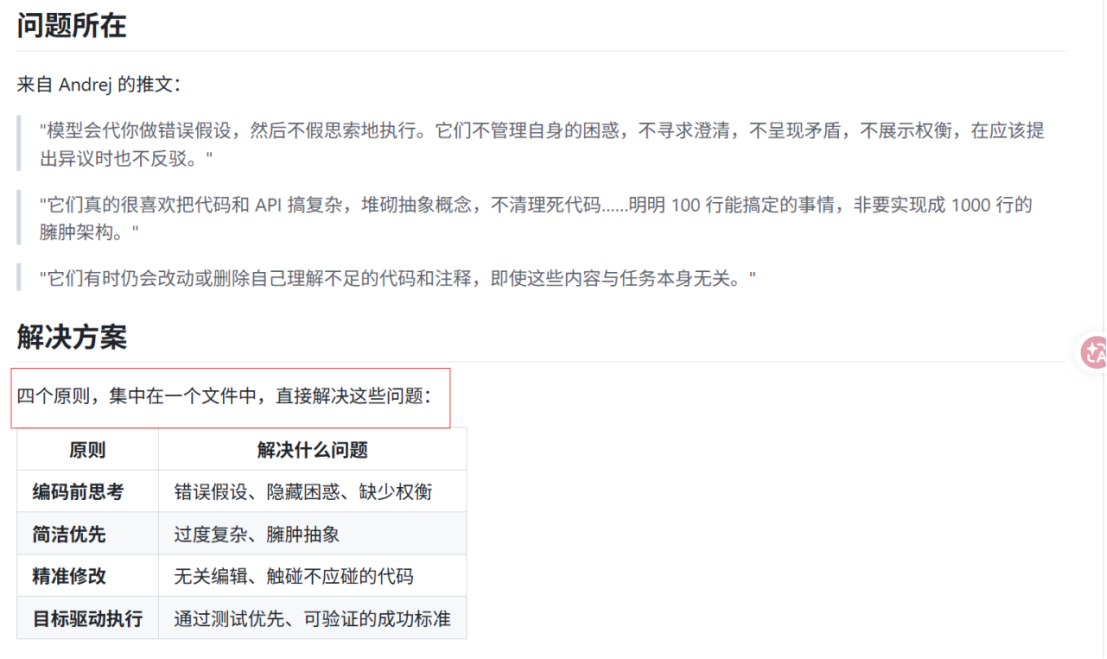
只放 "顶层不变原则":随着实践你会发现,CLAUDE.md 不该塞太多。卡帕西发布的「claude.skills」几百行通用规则就能拿 10 万 + 的 Star------ 写点 "顶层、不变、须严守" 的东西就够了。
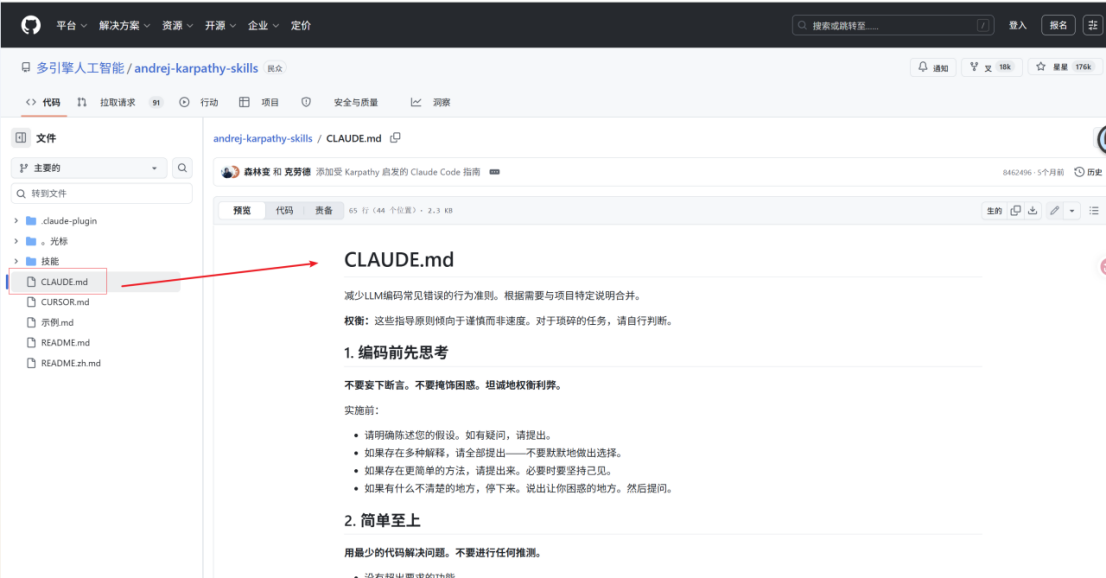
大牛的github路径:https://github.com/multica-ai/andrej-karpathy-skills
3.2.3 第二层记忆:Auto Memory (cc 自己的笔记本)
如果说 CLAUDE.md 是你主动立下的规矩,那 Auto Memory 就是 cc 在干活过程中默默记下的设计笔记。你没显式写进 CLAUDE.md 的习惯、反馈、项目踩坑,会被一个后台 agent 静静记录。
如何启用
-
在 cc 会话中输入
/memory -
在弹出的菜单里选第一个选项「启用 Auto Memory」
-
启用后菜单里会多出「打开自动记忆文件夹」选项
Auto Memory 会记录的内容分类
| 类型 | 含义 | 举例 |
|---|---|---|
| user | 关于你本人 | 你的角色、偏好(如 "不喜欢深色 UI") |
| feedback | 你给出的操作反馈 | "不要这样做"、"就这样" |
| project | 项目相关信息 | 项目进度、技术决策、技术选型 |
| reference | 外部资源索引 | "某份设计文档在 docs/design.md" |
使用手感(重要)
-
作用范围限制:仅在当前项目生效,记忆文件保存在项目目录,切换项目后需要重新积累记忆。
-
Token 占用优化逻辑:启用后 CC 不会一次性加载全部记忆到上下文,仅读取
memory.md索引文件;只有处理对应业务问题时,才加载匹配的子记忆文件,大幅减少 Token 消耗。 -
记忆查看快捷键:会话内按下 Ctrl+O,可直接查看本次对话实际调取过的记忆内容。
-
错误记忆清理方式:直接用自然语言指令删除错误记录,示例指令:忘掉刚刚说的不喜欢深色主题,工具会自动删除对应记忆条目。
提示:CLAUDE.md 与 Auto Memory 核心区分
一句话总结两者定位: CLAUDE.md 属于第一优先级、全量注入的显性规则;Auto Memory 属于第二优先级、按需加载的隐性记忆。两者搭配使用,CC 会持续适配你的个人开发习惯。
3.2.4 第三层记忆:自建参考文档(渐进式披露)
除了 CLAUDE.md、Auto Memory 两层记忆,还可以仿照 Skill 的「渐进式披露」机制,手动为 CC 搭建专项外部参考文档。
应用场景
部分规范内容篇幅过长、专业性强,不适合全部写入 CLAUDE.md,但 CC 处理对应业务时必须读取查阅,例如产品开发场景拆分如下:
-
品牌视觉规范(颜色、字体、间距)→
docs/brand-visual.md -
产品文本风格(语调、统一术语表)→
docs/copywriting-style.md -
API 交互约定(请求响应格式、错误码定义)→
docs/api-conventions.md
CLAUDE.md 内配置指引模板
## 外部参考文档- 修改前端视觉、调整颜色 / 间距时,必读 docs/brand-visual.md- 撰写产品文案、按钮文字、页面提示语时,必读 docs/copywriting-style.md- 编写 API、定义接口返回格式时,必读 docs/api-conventions.md个人理解:一个项目有一个整体的CLAUDE.md 文档,针对一个项目的各个功能流程可以不断补充自建参考文档并在 CLAUDE.md 中引入,当后续需要修改该功能的时候,CC 就会读取指定的功能自建文档,并不断优化扩展该文档,让 CC 更了解。我们就不用写代码,只要不断优化该文档即可。
核心优势
CC 仅在处理对应业务需求时,才加载完整外部文档,既能保证输出规范准确,又不会占用多余上下文 Token。
3.2.5 三层记忆总览
Claude Code 三层记忆体系流程: 第一层 CLAUDE.md (手动编写,会话全量加载)→ 第二层 Auto Memory (CC 自动记录,按需读取)→ 第三层自建参考文档(手动编写,匹配任务时读取)
| 层 | 位置 | 优先级 | 加载方式 | 维护方 |
|---|---|---|---|---|
| 1 | CLAUDE.md(三级目录) | 高 | 会话启动全量加载 | 手动维护 |
| 2 | Auto Memory | 中 | 先读取索引,按需加载对应子文件 | CC 自动生成,人工校对修改 |
| 3 | 自建参考文档 | 按需 | CC 触发对应任务才读取 | 手动维护 |
本质认知
Agent 全部记忆机制的底层逻辑:在合适时机向大模型注入压缩后的上下文。简单来说,三层记忆本质属于提示词工程,只是由 CC 完成分层、结构化管理。
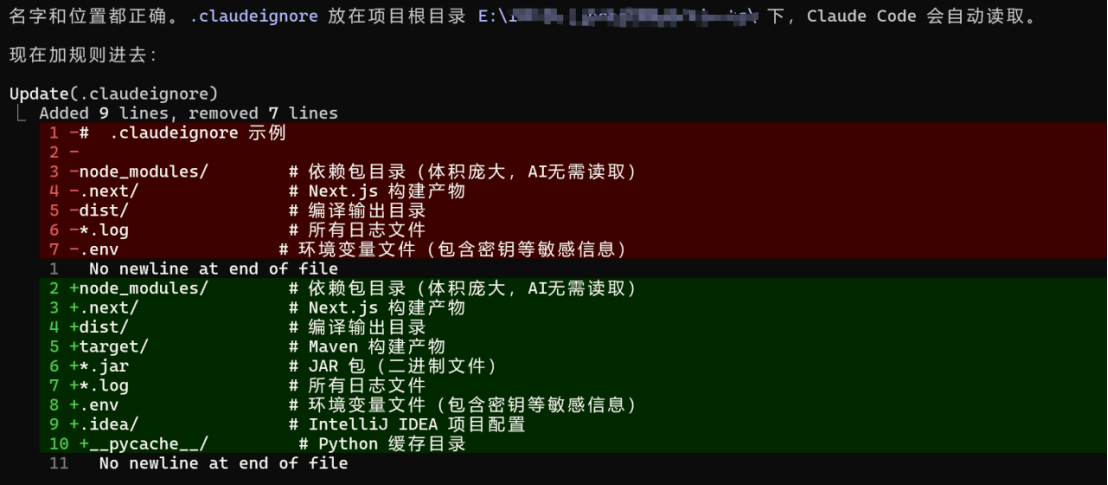
3.2.6 .claudeignore 文件
功能说明
作用类似 .gitignore,用于配置过滤规则,告知 Claude Code 哪些文件、目录无需读取、扫描。
基础配置示例
# .claudeignore 示例node_modules/ # 依赖包目录(体积庞大,AI无需读取).next/ # Next.js 构建产物dist/ # 编译输出目录*.log # 所有日志文件.env # 环境变量文件(包含密钥等敏感信息)CC帮我优化后内容