很多AI产品、转行求职者、初级研发都有一个通病:只会笼统说"我做过RAG项目",但不会选型、分不清架构层级。
面试一问就露馅:为什么你的知识库准确率低?为什么不支持追问?什么场景用朴素RAG、什么场景必须上多轮RAG?绝大多数人答不到点子上。
在真实企业落地中,RAG不是一套通用架构:简单场景硬上高阶架构,会造成资源浪费、成本冗余;复杂场景只用基础RAG,会导致幻觉泛滥、问答崩掉。
市面上所有商用AI知识库、企业问答、Agent对话产品,基本都逃不开三类架构:朴素RAG、进阶RAG、多轮RAG。
本文用通俗语言+实战架构+对比表格+落地案例,完整拆解三类RAG的核心差异、优缺点、适用场景、踩坑点,全文适配项目复盘、产品设计、面试备考、转行提升✅
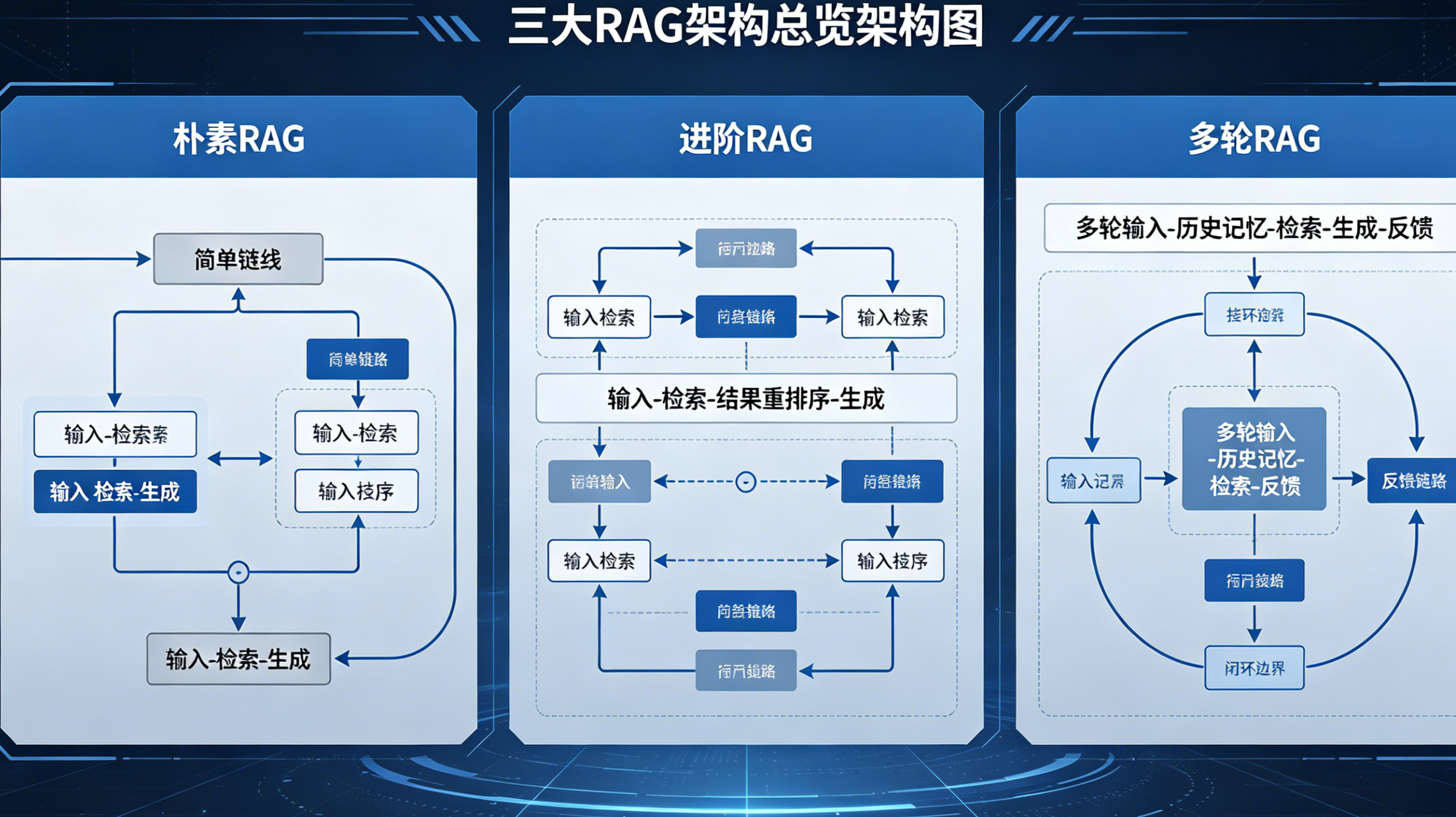
一、通俗认知:三类RAG到底是什么?
先零基础建立核心认知,不讲晦涩公式,所有人都能看懂:
-
朴素RAG:最基础的单轮检索问答,只实现「检索文档+生成答案」,主打快速落地、低成本。
-
进阶RAG :在朴素RAG基础上做精度优化,增加重排、多路召回、切片优化,是企业商用知识库主流方案。
-
多轮RAG:具备对话记忆、问题改写、上下文关联,专门解决连续追问、交互式对话场景,是Agent、数字员工的底层架构。
一句话高度总结:朴素保能用、进阶保精准、多轮保交互。
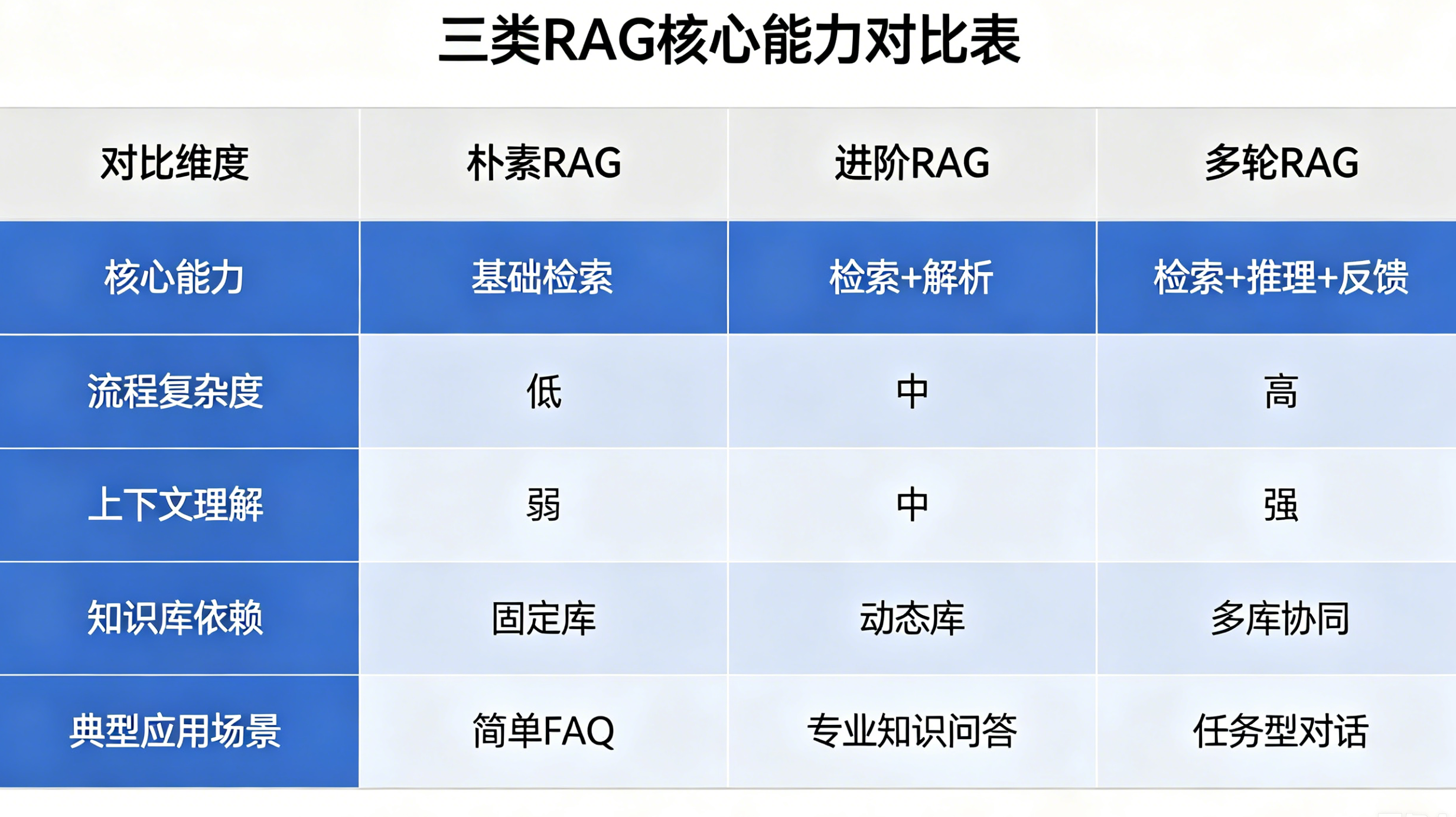
| 对比维度 | 朴素RAG | 进阶RAG | 多轮RAG |
|---|---|---|---|
| 对话能力 | 单轮无记忆 | 单轮无记忆 | 多轮上下文记忆 |
| 核心优势 | 简单、快速、低成本 | 准确率高、幻觉低、可商用 | 支持追问、语义连贯、交互自然 |
| 核心短板 | 召回杂乱、精度差、易出错 | 无法连续对话、不支持追问 | 架构复杂、算力成本高 |
| 落地成本 | 极低 | 中等 | 偏高 |
| 适用场景 | Demo、轻量化FAQ、静态查询 | 企业知识库、私有化问答、商用落地 | 智能客服、Agent、连续对话产品 |
二、朴素RAG:最基础的入门架构
2.1 核心流程
文档切片 → 向量化存储 → 用户提问 → 向量检索 → 拼接Prompt → 模型生成答案
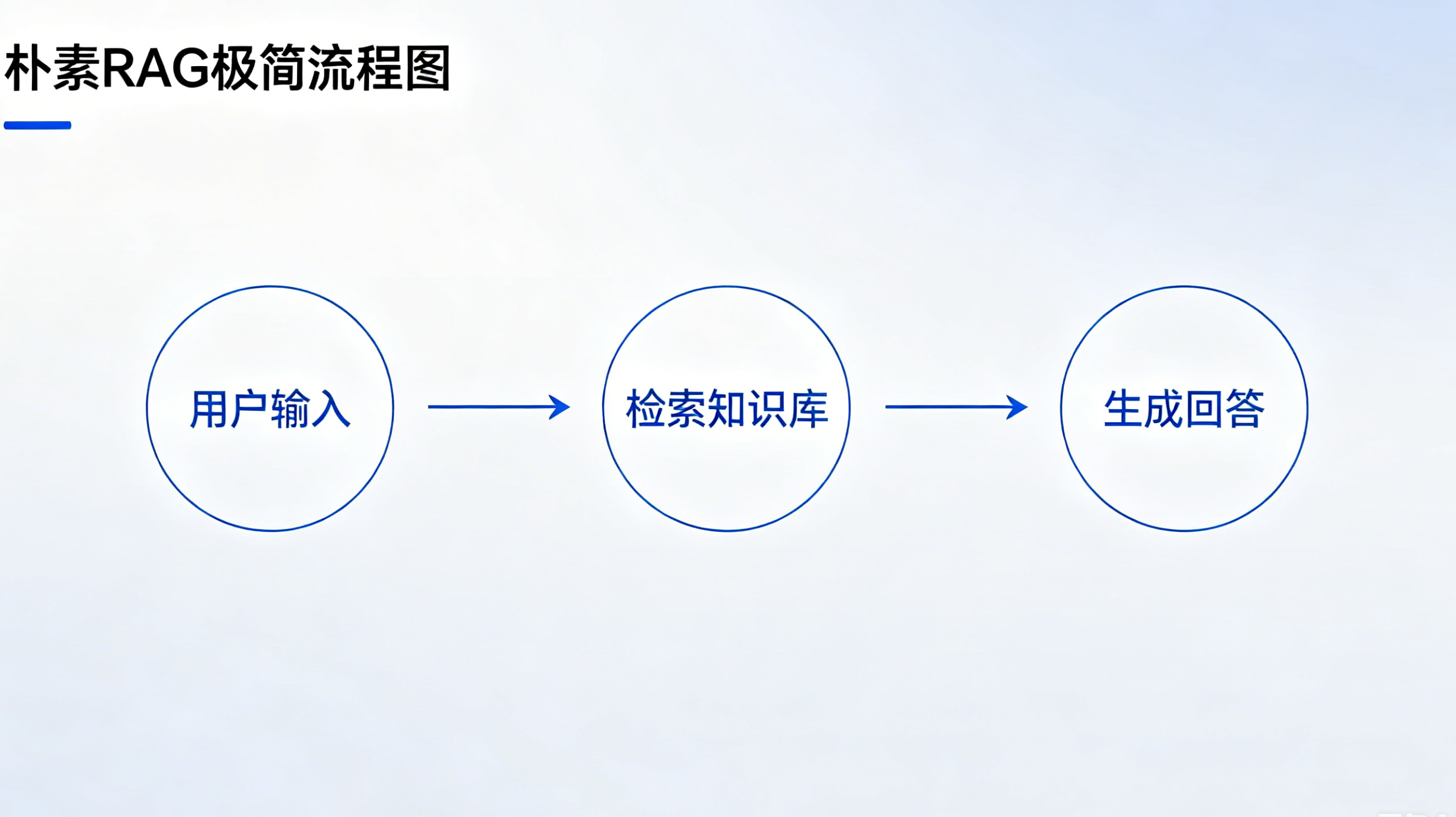
2.2 适合场景
-
项目初期快速验证可行性、搭建Demo
-
简单静态文档查询、FAQ固定问答
-
内部轻量化工具、低成本临时需求
2.3 致命缺陷(面试高频)
-
仅靠向量相似度召回,容易召回语义相似但内容无关的片段
-
无重排、无过滤,答案冗余、重点模糊
-
完全无上下文,用户无法追问,只能一问一答
三、进阶RAG:企业商用主流架构
进阶RAG是目前企业私有化落地的标准方案,也是AI产品简历、面试最核心的考察点。
3.1 在朴素RAG基础上的四大升级
-
切片优化:重叠切片、自适应切片,避免语义断裂
-
多路召回:向量检索 + 关键词检索组合,兼顾语义与精准词条
-
重排机制:对召回片段二次打分筛选,过滤低相关内容
-
后置过滤:去重、去冗余、清洗无效内容
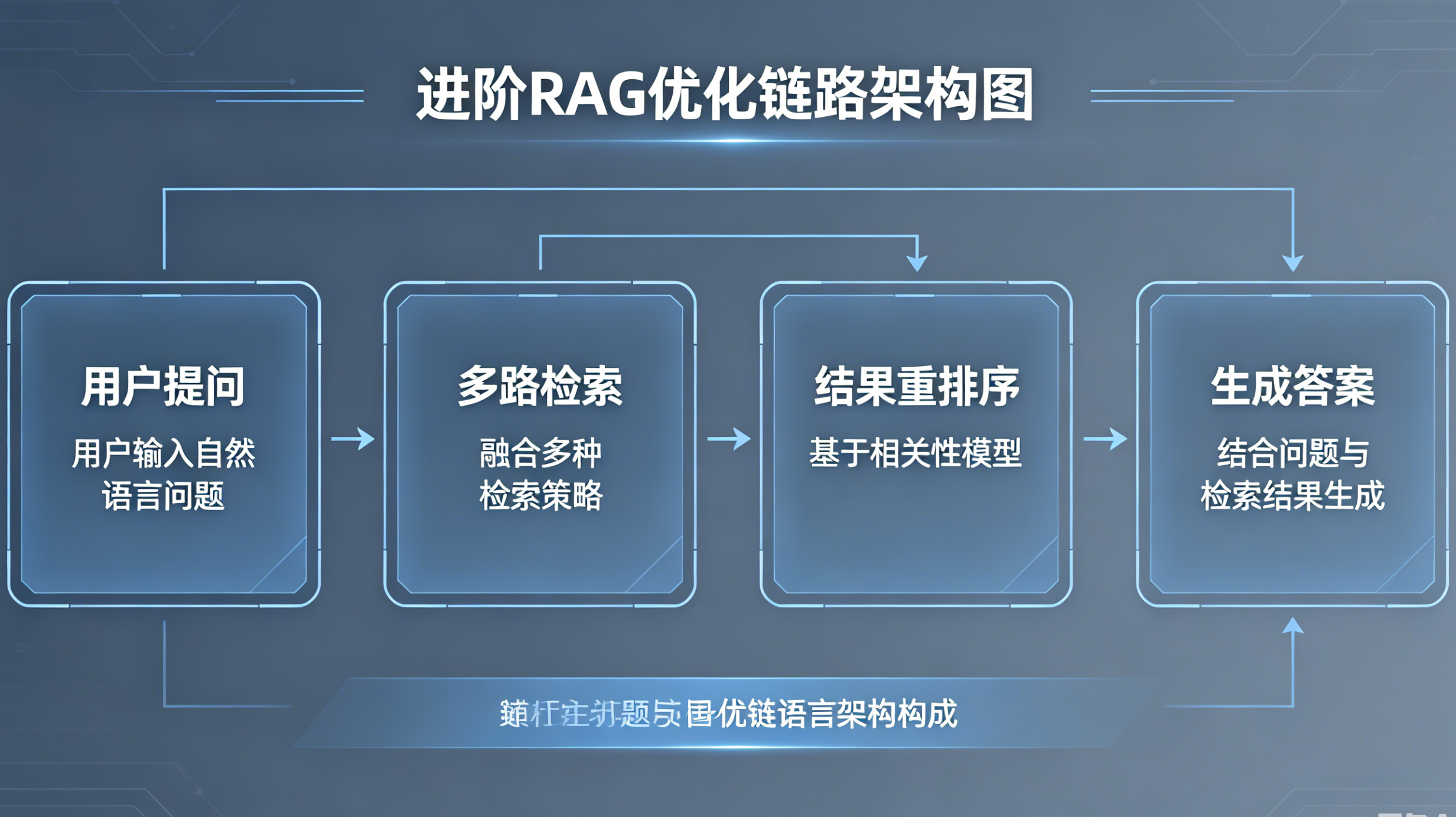
3.2 核心价值
解决了朴素RAG召回不准、内容杂乱、幻觉频发的核心问题,让知识库问答达到商用标准。
3.3 适用场景
-
企业私有化知识库、内部制度、流程、手册查询
-
产品帮助中心、客户答疑、资料检索系统
-
需要高精度、低幻觉、稳定输出的AI问答产品
四、多轮RAG:Agent与智能对话核心架构
朴素RAG、进阶RAG都属于「单轮问答」,无法满足真实用户的连续对话习惯,而多轮RAG才是真正的智能对话形态。
4.1 核心新增能力
-
对话记忆管理:保存历史会话上下文,识别用户对话语境
-
问题改写:自动补全省略词、代词、模糊提问,生成标准检索问题
-
动态检索策略:判断是否需要重新检索,避免无效重复召回
-
上下文融合生成:结合历史对话+新检索内容统一输出答案
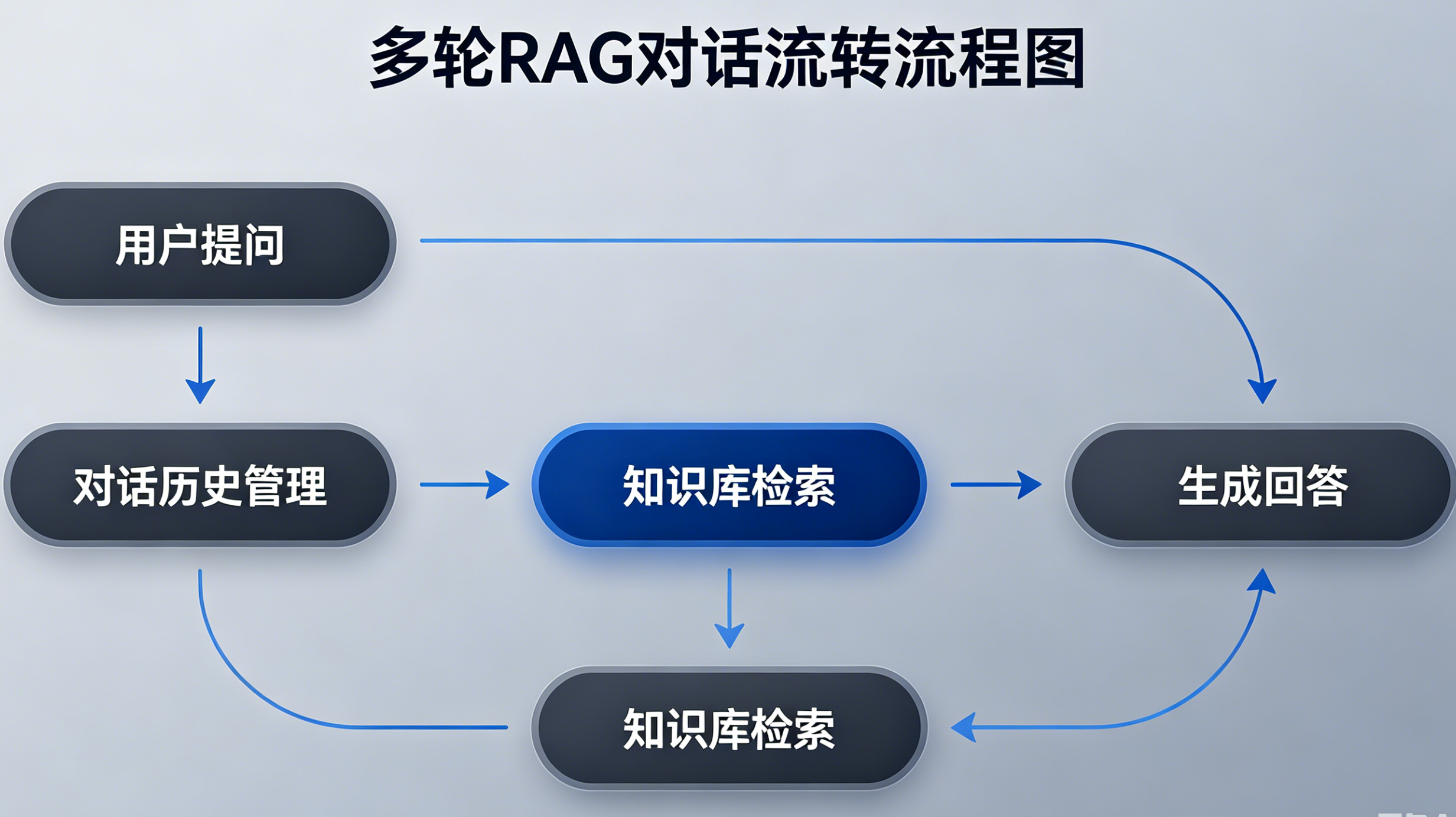
4.2 解决的行业痛点
用户日常提问往往不完整:"那下一步呢?""这个怎么操作?""还有别的方案吗?" 单轮RAG完全无法识别,多轮RAG可以精准承接追问。
4.3 适用场景
-
AI智能客服、在线咨询机器人
-
AI Agent、数字员工、自动化对话任务
-
需要连续交互、多轮沟通的AI产品
五、极简代码:三类RAG逻辑差异实战对比
用于PRD撰写、面试口述、和研发对齐逻辑,极简易懂:
python
# 1. 朴素RAG:一次检索直接输出
def simple_rag(user_query):
chunks = vector_search(user_query)
return llm.generate(chunks, user_query)
# 2. 进阶RAG:检索+重排+过滤
def advance_rag(user_query):
chunks = vector_search(user_query)
rank_chunks = rerank_model.rank(chunks, user_query)
clean_chunks = filter_redundant(rank_chunks)
return llm.generate(clean_chunks, user_query)
# 3. 多轮RAG:上下文改写+动态检索
def multi_turn_rag(user_query, history_context):
# 根据历史改写模糊问题
new_query = query_rewrite(user_query, history_context)
chunks = vector_search(new_query)
# 融合上下文生成答案
return llm.generate(history_context + chunks, user_query)六、企业项目选型标准(产品落地核心)
6.1 选朴素RAG的场景
预算有限、快速验证、内部小工具、静态FAQ、无追问需求。
6.2 选进阶RAG的场景
企业商用知识库、私有化部署、高精度问答、低幻觉要求、纯查询类产品。
6.3 选多轮RAG的场景
用户交互式产品、客服咨询、Agent任务、需要连续追问与沟通的AI系统。
七、面试高频真题(直接背诵)
-
Q:进阶RAG相比朴素RAG核心提升是什么? A:通过多路召回、重排、切片优化,大幅提升检索精准度,降低模型幻觉,满足企业商用标准。
-
Q:多轮RAG解决了什么单轮RAG无法解决的问题? A:解决用户模糊提问、省略提问、连续追问、上下文关联的对话断裂问题。
-
Q:企业知识库为什么不推荐朴素RAG上线? A:召回杂乱、精度低、输出不稳定、幻觉严重,无法满足商用合规要求。
八、全文总结
三类RAG架构不存在绝对的优劣,只有场景适配的区别。
朴素RAG负责快速落地、进阶RAG负责商用精准、多轮RAG负责智能交互。作为AI产品经理,核心能力就是根据业务需求合理选型、规避成本浪费、解决落地痛点。