在上一篇中,我们完成了标准化数字模板库的构建,得到了 0-9 每个数字的标准化匹配基准,为后续的字符识别准备好了「标准答案」。本模块是整个银行卡数字识别流程的核心执行部分,是连接模板库与最终识别结果的核心桥梁,负责将原始银行卡图像,转化为可直接与模板库匹配的标准化单个字符。
目录
整体流程概述
- 形态学预处理:通过顶帽操作、闭操作、自适应二值化等操作,消除银行卡背景干扰,突出数字区域
- 卡号区域粗定位:通过轮廓检测与特征筛选,从所有候选区域中过滤出 4 组卡号的精确位置,并按顺序排列
- 组内单字符精分割:对每组卡号做精细化处理,分割出单个数字并统一尺寸,得到和模板库完全匹配的待识别字符
本模块完成后,即可进入最终的模板匹配环节,输出完整的卡号与发卡行识别结果。
图像读取与基础预处理
python
# 读取输入图像,预处理
image = cv2.imread(args["image"])
cv_show('image', image)
image = myutils.resize(image, width=300) # 统一图像尺寸
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv_show('gray', gray)读取命令行参数传入的银行卡图像,调用自定义工具函数,显示原始输入图像。

将图像等比例缩放到宽度 300 像素,高度自动计算。自定义myutils.resize()函数是等比例缩放 ,不会拉伸变形图像。(没有任何参数可以让cv2.resize()自动按原图比例缩放)
后续所有形态学操作、轮廓筛选的参数都是基于宽度 300 的尺寸设计的,不同分辨率的图像参数通用,如果不统一尺寸,不同分辨率的银行卡图像会导致轮廓筛选的宽高比、尺寸阈值完全失效,识别失败。
转灰度图,消除颜色通道干扰,所有形态学操作、阈值处理、轮廓检测都只能基于单通道图像,直接用彩色图做形态学操作会导致每个通道单独处理,结果完全错误。
显示灰度图

形态学预处理,突出数字区域,消除背景干扰
python
# 初始化形态学操作卷积核
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, ksize=(9, 3)) # 宽扁型卷积核,用于提取横向数字区域
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, ksize=(5, 5)) # 正方形卷积核,用于闭操作填充孔洞
# 顶帽操作:突出亮区域,消除暗背景
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
cv_show('tophat', tophat)
# 闭操作:将同组内分散的数字像素连接成整体
closeX = cv2.morphologyEx(tophat, cv2.MORPH_CLOSE, rectKernel)
cv_show('closeX', closeX)
# OTSU自动二值化:自动计算最优阈值,转为黑底白字
thresh = cv2.threshold(closeX, thresh=0, maxval=255, type=cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show('thresh', thresh)
# 二次闭操作:填充二值图内的孔洞,让数字区域更完整
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel)
cv_show('close2', thresh)创建宽扁型的矩形形态学核
cv2.getStructuringElement():创建形态学操作的卷积核,第一个参数MORPH_RECT:核的形状是矩形,适合提取横向排列的区域
形态学操作(腐蚀、膨胀、开闭运算、顶帽等)的核心是结构元素(也就是常说的形态学核) ,它就像图像处理的 "模具"------ 核的形状、尺寸直接决定了操作会保留什么特征、消除什么特征。cv2.getStructuringElement()就是用来创建这个模具的函数。
python
cv2.getStructuringElement(shape, ksize)shape 核的形状 决定了核的像素分布形态,OpenCV 提供三种基础形状:
cv2.MORPH_RECT:矩形核,核内所有像素值均为 1,实心矩形,对直线、矩形区域的提取效果最优,是工业界最常用的形态学核。cv2.MORPH_ELLIPSE:椭圆形核,适合提取圆形、椭圆形目标。cv2.MORPH_CROSS:十字形核,仅十字交叉位置像素为 1,适合提取交叉线条。
本项目选择MORPH_RECT,是因为银行卡号是规整的横向矩形数字区域,矩形核的匹配度最高,特征提取最精准。
ksize 核的尺寸 格式为(宽度, 高度),单位为像素。核的宽高比例,直接决定了它对哪个方向的区域更敏感:
- 宽 > 高(宽扁型):对横向长条区域敏感,横向连接 / 抑制能力强,纵向弱
- 宽 < 高(瘦高型):对纵向长条区域敏感
- 宽 = 高(正方形):各方向作用均匀,适合通用降噪、填充
ksize=(9, 3):核的尺寸是宽 9 像素、高 3 像素,宽扁型核适配银行卡号横向排列的特征,能更好地提取横向的数字区域,ksize=(5,5)正方形核,用于后续填充二值图的孔洞,让数字区域更连续。
两个核分工不同:宽扁核用于提取横向区域,正方形核用于填充孔洞。
python
cv2.morphologyEx(src, op, kernel)形态学通用处理函数:cv2.morphologyEx() src 输入图像,必须是单通道灰度图 op 形态学操作类型 kernel 自定义形态学结构核
对灰度图执行顶帽形态学操作,cv2.MORPH_TOPHAT
顶帽操作公式:顶帽结果 = 原始图像 - 开运算结果
开运算 = 先腐蚀后膨胀:作用是消除图像中细小的亮区域,保留大的亮区域
顶帽操作的效果:保留比背景亮的细小区域(数字),消除大面积的暗背景 ,完美解决银行卡底色渐变、反光导致的数字不清晰问题。搭配(9,3)宽扁矩形核,只会提取横向长条亮区域,过滤垂直方向噪点,完美适配横向排列的银行卡卡号。
显示顶帽操作结果
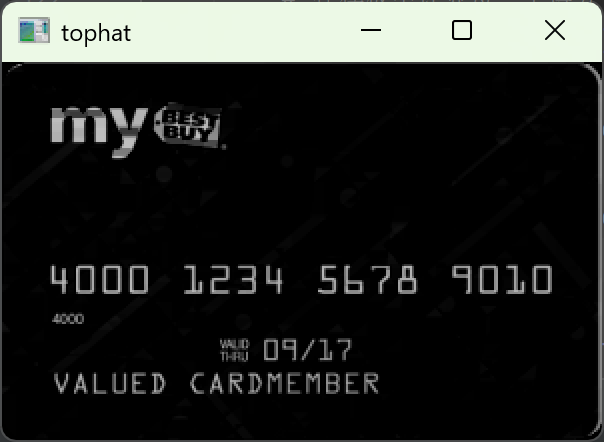
对顶帽结果执行闭操作cv2.MORPH_CLOSE,闭操作公式:闭操作结果 = 先膨胀,后腐蚀
膨胀:让白色区域扩大,腐蚀:让白色区域缩小
闭操作的效果:填充白色区域内部的孔洞,将相邻的白色小区域连接成一个大区域------ 把同组内 4 个分散的数字,连接成一个连续的矩形区域,方便后续一次性提取整组卡号的轮廓。(必须用和顶帽一样的宽扁核做闭操作,才能保证横向的数字被正确连接。)
显示闭操作结果

执行 OTSU 自动二值化,转为黑底白字的二值图
普通手动二值化逻辑:手动定一个阈值 T,像素灰度>T 变白,≤T 变黑; 但银行卡图像明暗不均匀、反光、底色深浅不一,需要手动调整 T ,所以用 OTSU 自动阈值。
OTSU 算法核心原理(大津法)
- 统计整张灰度图所有像素的灰度直方图(0~255 每个亮度有多少个像素);
- 算法自动遍历 0~255 所有可能阈值,计算每一个阈值分割后的类间方差;
- 找到类间方差最大的那个灰度值,作为最优分割阈值;
- 类间方差越大,代表 "前景(白色数字)" 和 "背景(黑色底色)" 区分越干净
第一个参数:输入单通道图像
thresh=0:手动阈值设为 0,因为用 OTSU 自动计算阈值,手动阈值无效
maxval=255:满足阈值条件的像素赋值为 255(纯白)
type=cv2.THRESH_BINARY | cv2.THRESH_OTSU:同时开启二值化 + OTSU 自动阈值计算
OTSU 原理:自动根据图像的灰度直方图,计算出最优的分割阈值,适合明暗不均、没有固定合适阈值的场景。(如果画面灰度分布杂乱无明显明暗两类,OTSU 效果会变差;本项目经过顶帽预处理,天然形成双峰,完美适配。)
返回值取[1]:函数返回(最优阈值, 二值图),我们只需要二值图,所以取索引 1 ,用 OTSU 时必须把thresh参数设为 0,否则手动阈值会覆盖 OTSU 的自动计算,二值化结果错误。
消除图像明暗差异,每张银行卡反光、亮度不同,不用人工反复调整阈值,分离数字与背景,把浅灰色底色统一压成纯黑,数字统一变为纯白,轮廓检测更容易识别卡号区域;为后续闭操作、轮廓筛选提供干净的黑白二值图。
显示二值化结果

一次闭操作无法完全填充数字内部的孔洞,二次闭操作做精细化补全
本次使用sqKernel=(5,5)的正方形核,和第一次闭操作的宽扁核分工不同:
- 第一次宽扁核:负责横向连接分散的数字
- 第二次正方形核:负责填充数字区域内部的细小孔洞,让白色区域更完整连续
消除二值图中数字区域的小黑点,避免后续轮廓检测把一个数字拆成多个轮廓 (不能用太大的核做二次闭操作,否则会把相邻的卡号组也连在一起,导致轮廓检测错误)。
显示二次闭操作结果

卡号区域定位,轮廓检测与筛选
python
# 提取所有外轮廓
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2]
cnts_img = image.copy()
cv2.drawContours(cnts_img, cnts, -1, color=(0, 0, 255), thickness=3)
cv_show('cnts_img', cnts_img)
# 筛选符合卡号特征的轮廓
locs = []
for c in cnts:
(x, y, w, h) = cv2.boundingRect(c)
ar = w / float(h) # 计算轮廓宽高比
# 银行卡号每组4个数字,宽高比固定在2.5-4.0之间,尺寸在固定范围
if 2.5 < ar < 4.0:
if (40 < w < 55) and (10 < h < 20):
locs.append((x, y, w, h))
# 按从左到右排序,对应卡号的顺序
locs = sorted(locs, key=lambda x: x[0])检测二值图中所有白色区域的外轮廓
- 第一个参数
thresh.copy():传入二值图的副本,避免修改原图 cv2.RETR_EXTERNAL:只检测最外层轮廓,忽略轮廓内部的孔洞(比如数字 0、8 中间的洞),我们只需要卡号区域的外框cv2.CHAIN_APPROX_SIMPLE:压缩轮廓点,只保留轮廓的关键点(比如矩形只保留 4 个角),大幅减少数据量
创建原图的副本,用来画轮廓,把所有检测到的轮廓画在副本上
- 第二个参数
cnts:轮廓列表 - 第三个参数
-1:绘制所有轮廓,填 0 就是画第 0 个轮廓,以此类推 color=(0,0,255):OpenCV 是 BGR 格式,所以这个是纯红色thickness=3:轮廓线的粗细,单位像素
显示画了轮廓的图
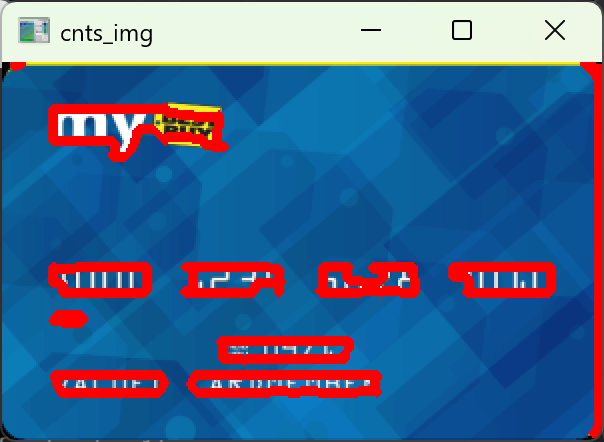
创建空列表,用来存符合条件的卡号轮廓的外接矩形参数。
遍历所有检测到的轮廓,给每个轮廓套最小外接矩形,返回矩形的左上角坐标 (x,y)、宽 w、高 h。
计算轮廓的宽高比(宽 ÷ 高),这是筛选卡号最核心的特征。(银行卡号每组是 4 个横向排列的数字,所以宽远大于高,宽高比是最稳定的筛选特征,比绝对尺寸更抗干扰,绝对尺寸完全依赖图像分辨率、拍摄远近,图像大小一变,像素数值立刻变,阈值就失效。)
双重条件筛选,只保留符合卡号特征的轮廓
- 第一重筛选(宽高比):2.5 < 宽高比 < 4.0,过滤掉正方形、竖长方形的无关轮廓(比如银行卡 logo、芯片、磁条)
- 第二重筛选(绝对尺寸):针对 resize 到宽度 300 的图像,每组卡号的宽在 40-55 像素,高在 10-20 像素,过滤掉太小的噪点、太大的背景区域
不能只靠宽高比筛选,必须加绝对尺寸过滤,否则会把银行卡的长边、签名条等宽扁区域也误判为卡号。
把筛选后的轮廓,按左边界 x 坐标从小到大排序,得到卡号从左到右的顺序。
sorted()的key=lambda x: x[0]:按每个轮廓元组的第 0 个元素(x 坐标,左边界)排序- 为什么要排序:
findContours返回的轮廓顺序是乱的,不排序会导致识别出来的卡号顺序颠倒
必须按 x 坐标排序,不能按 y 坐标排序,银行卡号是横向排列的,y 坐标基本一致,只有 x 坐标有顺序差异。
单组数字分割,提取组内单个数字
python
output = []
# 遍历每一组卡号
for (gX, gY, gW, gH) in locs:
groupOutput = []
# 抠出卡号组区域,向外扩5像素避免截断数字
group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]
cv_show('group', group)
# 组内二值化
group = cv2.threshold(group, thresh=0, maxval=255, type=cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
cv_show('group', group)
# 提取组内每个数字的轮廓,从左到右排序
digitCnts = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2]
digitCnts = myutils.sort_contours(digitCnts, method="left-to-right")[0]
# 计算每一组中的每一个数值
for c in digitCnts:
# 找到当前数值的轮廓,resize成合适的的大小
(x, y, w, h) = cv2.boundingRect(c)
roi = group[y:y + h, x:x + w]
roi = cv2.resize(roi, dsize=(57, 88))
cv_show('roi', roi)初始化空列表,用来存储最终识别出来的所有数字
遍历排序后的所有卡号组轮廓,g前缀代表 group(组),区分全局的 x/y/w/h
初始化组内结果列表,存储当前这一组 4 个数字的识别结果。
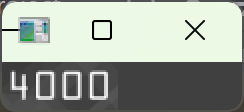
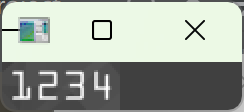
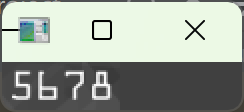
从灰度图中抠出当前卡号组的区域,向外各扩 5 像素,numpy 切片规则:图像[y方向范围, x方向范围],先写上下(y),后写左右(x),向外扩 5 像素的原因:轮廓检测得到的外接矩形是紧贴数字边缘的,直接抠图容易截断数字的边缘笔画,外扩 5 像素保证数字完整,不能扩太多(超过 10 像素),否则会把相邻组的数字也抠进来
显示抠出来的卡号组
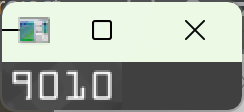
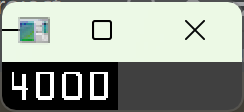
对当前卡号组单独执行 OTSU 自动二值化。(必须用 OTSU 自动阈值,不能手动设阈值,不同组的亮度差异会导致手动阈值失效。)
- 每组卡号的明暗程度可能不同,全局二值化的阈值不一定适合所有组
- 组内单独二值化,会根据当前组的灰度分布计算最优阈值,保证每个组的数字都清晰,抗干扰能力更强
显示组内二值化结果
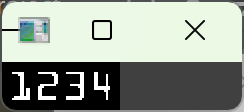
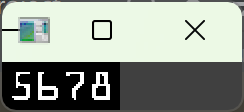
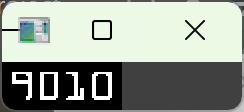
提取当前组内所有数字的外轮廓,把组内的 4 个数字轮廓,按从左到右的顺序排序(和全局排序的区别:全局排序是组和组之间的顺序,这里是组内单个数字之间的顺序)
sort_contours原理:按每个轮廓外接矩形的 x 坐标从小到大排序,保证 4 个数字的顺序和卡号一致。必须做组内排序!findContours返回的组内轮廓顺序也是乱的,不排序会导致同一组内的数字顺序颠倒,识别结果错误。
遍历组内排序后的 4 个数字轮廓,逐个处理,嵌套循环逻辑:外层循环遍历 4 组卡号,内层循环遍历每组内的 4 个数字,实现 16 个数字的逐个识别。
给单个数字的轮廓套最小外接矩形,得到位置和尺寸,和之前的轮廓外接矩形逻辑一致,获取单个数字的精确位置。
从组内二值图中抠出单个数字的区域,numpy 切片规则:[y方向范围, x方向范围],先上下后左右,和之前的抠图规则一致。
将单个数字统一 resize 为和模板库完全一致的尺寸。
- 这是模板匹配的核心前提:待识别数字的尺寸必须和模板库 100% 一致,差 1 像素都会导致匹配完全失效
- 这里的
(57, 88)和我们构建模板库时cv2.resize(roi, dsize=(57, 88))的尺寸完全相同,宽高顺序也完全一致
显示抠出来的单个标准化数字
