
一、模型吃的不是文件,是 Batch Tensor
很多人刚学 PyTorch,会把数据加载理解成"读文件"。这个理解太浅。
训练模型时,真正进入模型的不是图片路径,不是 JSON,不是数据库记录,而是整理好的 Batch Tensor。
Dataset 负责回答一个问题:一个样本怎么取。DataLoader 负责回答另一个问题:怎样高效、稳定、成批地把样本送到训练循环。
所以 DataLoader 不是一个普通 for 循环。它是一条数据流水线。它管顺序、管批次、管拼接、管多进程、管预取、管内存搬运。

二、Dataset:不是数据本身,而是"取样规则"
Dataset 不是把所有数据都塞进内存。更准确地说,Dataset 是一套取样规则。
你告诉它:给我一个索引,我能拿到一个样本;或者你告诉它:我能持续吐出一条条样本流。
PyTorch 官方把 Dataset 分成两类:Map-style Dataset 和 Iterable-style Dataset。前者像一本有页码的书,后者像一条正在流动的河。

三、Map-style:最常见,也最适合入门
Map-style Dataset 的核心是两个协议:getitem 和 len。
getitem 负责按 key 或 index 取一个样本。len 负责告诉外部数据集有多大。
图片分类、离线文本分类、CSV 样本、已经落盘的训练集,大多数都适合 Map-style。
它的好处是顺序可控。DataLoader 可以基于它自动构造 SequentialSampler 或 RandomSampler,也可以接受自定义 sampler。
四、Iterable-style:适合流式数据,但多进程容易踩坑
Iterable-style Dataset 的核心是 iter。它不强调"第几个样本",而强调"持续吐出样本"。
它适合数据库游标、日志流、消息队列、远程数据流、实时生成数据。
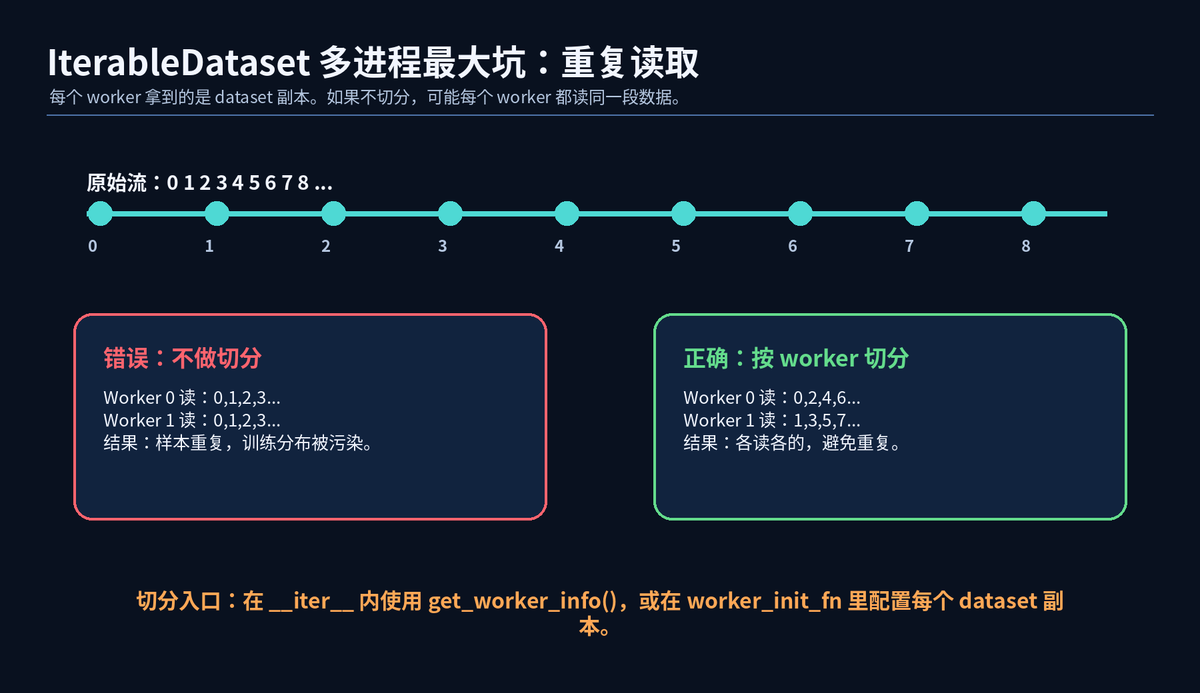
但它有一个大坑:多进程时,每个 worker 都会拿到 dataset 的副本。如果你不切分,每个 worker 可能都读同一批数据,训练样本会重复。
因此,IterableDataset 往往要结合 get_worker_info 或 worker_init_fn,在每个 worker 中配置不同的数据范围。
五、DataLoader:真正的数据调度器
DataLoader 的职责不是"保存数据"。它的职责是把 Dataset、Sampler、BatchSampler、Fetcher、collate_fn、worker 进程串起来。
一旦你写出 for batch in dataloader,背后其实发生了一长串动作:创建迭代器,生成样本索引,读取样本,拼成 batch,必要时放进 pinned memory,再返回训练循环。
理解这一层,你才能真正排查训练慢、样本重复、shape 不对、卡死、内存暴涨这些问题。

六、Sampler:数据顺序不该写死在 Dataset 里
Dataset 只管怎么取样本。样本按什么顺序取,应该交给 Sampler。
训练时,我们希望样本顺序随机,所以常用 shuffle=True 或 RandomSampler。验证和测试时,我们希望结果稳定,所以一般不打乱。
如果要做类别均衡、难例采样、分布式切分、自定义权重采样,Sampler 就会变成关键组件。
BatchSampler 则更进一步。它不只是吐出一个 index,而是一次吐出一组 index,告诉 DataLoader 哪些样本属于同一个 mini-batch。

七、collate_fn:样本如何拼成 Batch
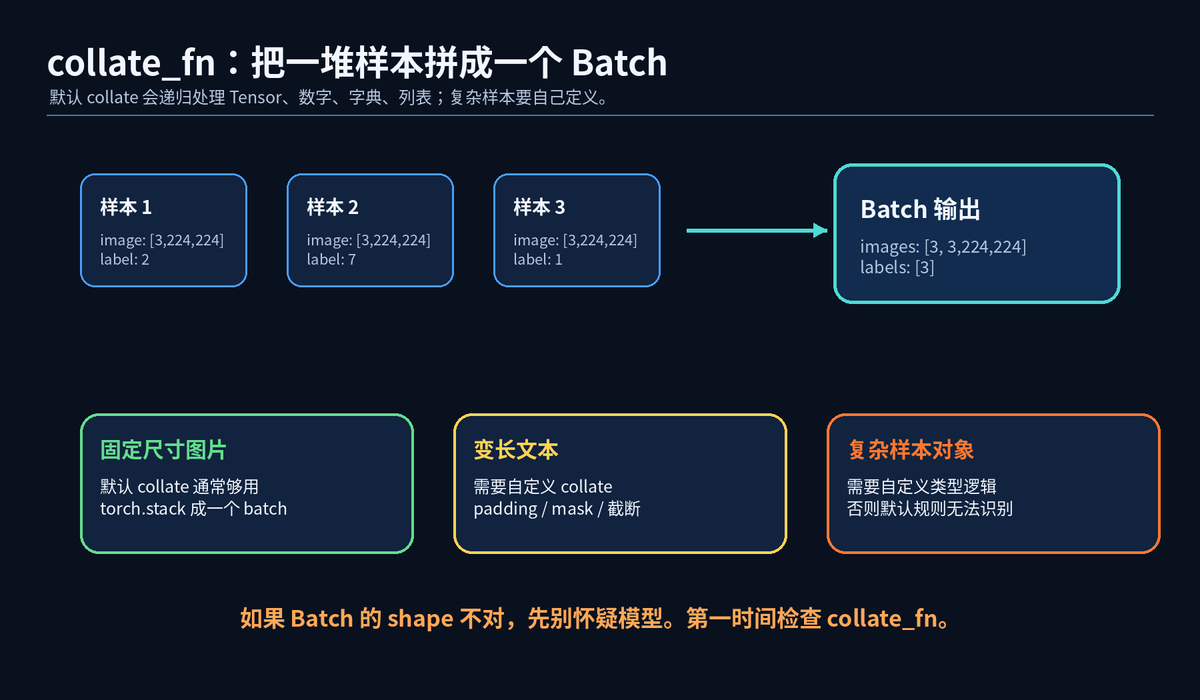
Dataset 每次返回的是一个样本。模型训练需要的是一个 batch。中间这一步,就靠 collate_fn。
默认 collate_fn 会把一组 Tensor 沿第 0 维堆叠起来,也会递归处理 tuple、list、dict 等结构。
固定尺寸图片任务通常不用改。变长文本、目标检测、多模态样本、复杂对象,几乎都要自定义 collate_fn。
如果你遇到 batch 的 shape 和预期不一致,先别怀疑模型。先看 Dataset 返回结构和 collate_fn。
八、num_workers:不是越大越好
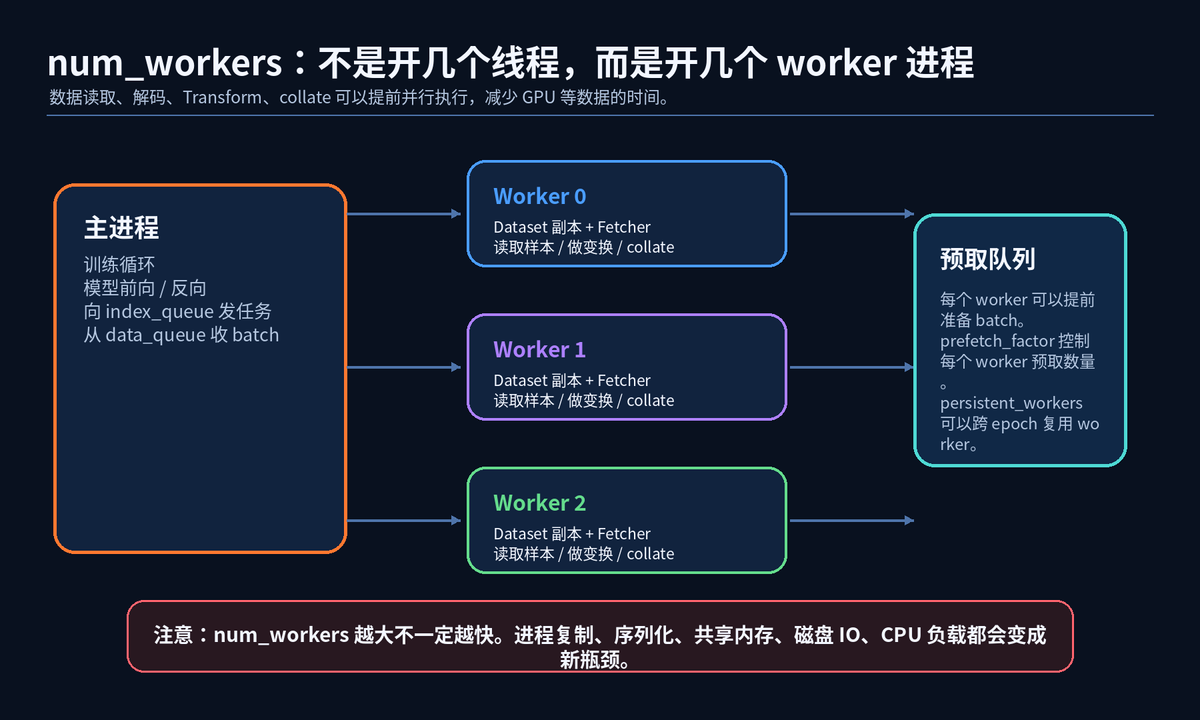
num_workers=0 时,数据读取发生在主进程里。优点是报错清楚,调试方便;缺点是读数据可能阻塞训练。
num_workers>0 时,DataLoader 会启动多个 worker 进程。它们提前读取、解码、Transform、collate,再把 batch 送回主进程。
这能提高吞吐,但不是无脑越大越好。worker 过多会带来进程开销、内存复制、共享内存压力、磁盘 IO 争用、序列化成本。
真实工程里,推荐从 num_workers=0 开始确认逻辑正确,再按 2、4、8 逐步压测。观察 GPU 利用率、CPU 利用率、磁盘 IO 和主机内存。
多进程 DataLoader 的调度结构
九、pin_memory:数据搬到 GPU 前的加速点
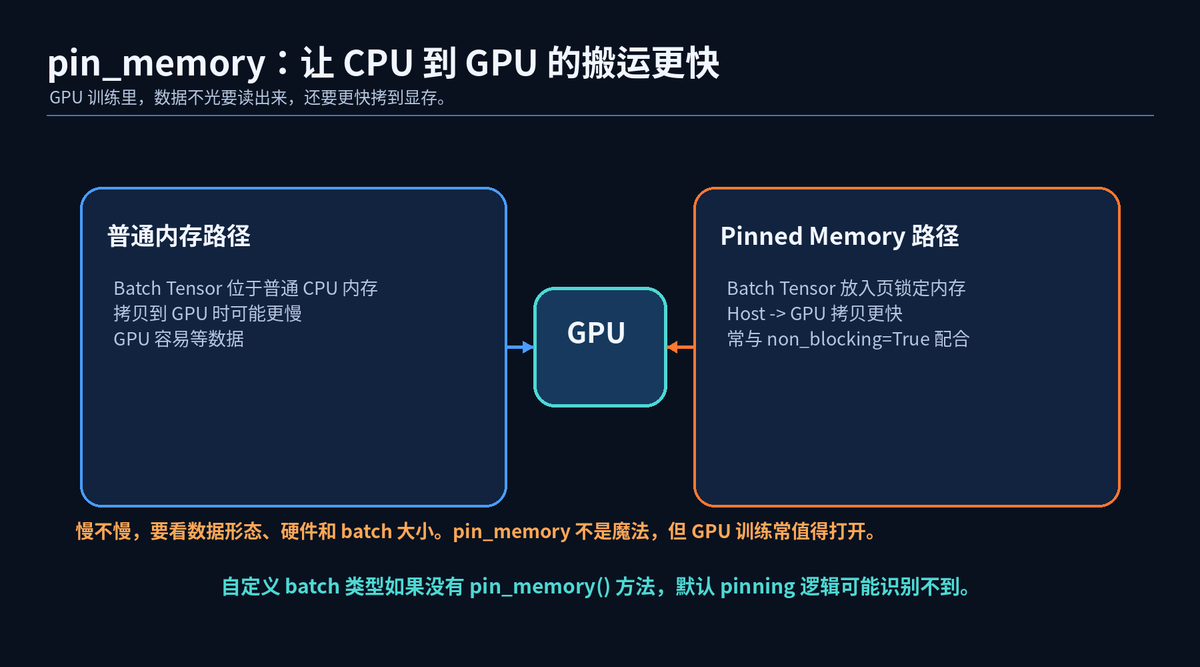
GPU 训练的瓶颈不只有模型计算。CPU 到 GPU 的数据拷贝也可能拖慢训练。
pin_memory=True 会让 DataLoader 尝试把返回的 Tensor 放进页锁定内存。这样 Host 到 GPU 的拷贝通常更快。
但它不是魔法。如果数据本身很小、训练在 CPU、或者瓶颈不在拷贝,收益就不明显。
另外,默认 pin_memory 逻辑主要识别 Tensor,以及包含 Tensor 的 map/iterable。如果 collate_fn 返回自定义 batch 类型,就要给这个类型实现 pin_memory 方法。
十、源码级讲解:一条 Batch 是怎么出来的
现在从源码视角看 DataLoader。先看 DataLoader.iter。它不会直接读取数据,而是创建一个 iterator。
DataLoader._get_iterator 会根据 num_workers 选择不同执行路径:num_workers=0 走 _SingleProcessDataLoaderIter;num_workers>0 走 _MultiProcessingDataLoaderIter。
iterator 内部会维护 sampler_iter。Sampler 负责吐出 index,BatchSampler 负责吐出 index 列表。Fetcher 拿到这些 index 后,才真正调用 Dataset。
如果是 Map-style,Fetcher 通过 dataseti 取样本。如果是 Iterable-style,Fetcher 从 iter(dataset) 中取下一个样本。
样本拿到后,collate_fn 会把样本列表组织成 batch。多进程模式下,worker 还会通过队列把结果送回主进程,并用 ExceptionWrapper 包装异常。

十一、几个源码关键点
第一,Dataset 是抽象协议。它不强制你一次性加载所有数据,只要求你定义样本怎么被取出。
第二,DataLoader 初始化时会检查参数合法性。例如 prefetch_factor 只能在多进程场景使用;persistent_workers 必须要求 num_workers>0。
第三,DataLoader 初始化后,batch_size、sampler、batch_sampler、drop_last、dataset、persistent_workers 等关键属性不应该再随便修改。源码里通过 setattr 做了限制。
第四,collate 逻辑是递归的。Tensor 会被 stack,字典会按 key 递归合并,列表和 tuple 也会继续拆开处理。复杂对象如果不符合默认规则,就要自定义。
第五,多进程 worker 里的 dataset 是副本。get_worker_info 返回当前 worker 的 id、num_workers、seed 和 dataset 副本。这就是做流式数据切分的入口。
十二、参数速查:不是背 API,而是看瓶颈

十三、常见问题:先把数据链路查清楚
训练报错,不一定是模型错。训练很慢,也不一定是模型慢。
DataLoader 的问题常常隐藏得很深:它可能让 GPU 空转,可能让样本重复,可能让 batch shape 错乱,也可能在多进程里卡住。
最稳的排查路径是:先把 num_workers 改成 0,确认 Dataset 和 collate_fn 没问题;再逐步打开多进程;最后再考虑 pin_memory、prefetch_factor、persistent_workers。

十四、总结
• Dataset 解决"一个样本怎么取"。
• DataLoader 解决"样本如何成批、高效、稳定地送进模型"。
• Sampler 管顺序,BatchSampler 管批次,collate_fn 管拼接。
• num_workers 能提升吞吐,但也会带来进程、内存和 IO 成本。
• IterableDataset 多进程要特别注意分片,否则容易重复读数据。
• pin_memory 是 GPU 训练的数据搬运优化点,但自定义 batch 需要自己适配。
• 源码主线是 DataLoader -> Iterator -> Sampler -> Fetcher -> Dataset -> collate_fn -> Batch。
|------------------------------------------------|
| 下一章:Transforms。数据增强不是锦上添花,而是训练稳定性和泛化能力的关键。 |
内容来源:《PyTorch 深度修炼》Dataset 和 DataLoader:数据如何喂给模型:功能变化与行业影响解析_热闻岛