最近见到不少团队,一头扎进「多 Agent 协作平台」里:搭编排框架、设计角色分工、调工作流引擎,恨不得让一群 Agent 自动把需求从头跑到上线。可真用起来,AI 在他们的代码库里还是老样子,该犯的错照犯,该漏的步照漏。
问题往往不在 Agent 不够强,而在工程本身没为 AI 准备好。
这就引出一个被低估的前提:AI-Ready。在它没做到之前,急着卷 Agents 平台,多半是本末倒置。
一、先分清两个词:AI-SDLC 和 AI-Ready

先把两个容易混的概念分开。
AI-SDLC,是 AI 辅助的软件研发生命周期。从需求澄清、方案设计,到编码、联调、测试、发布,每个环节都让 AI 深度介入,目标是在保证交付质量的前提下,尽量多让 Agent 干活、少让人插手。
AI-Ready 说的是另一件事:你的代码仓库、需求文档、开发流程,到底有没有为 AI-SDLC 做好准备。这个说法最早从亚马逊等公司的工程实践里冒出来,核心不是追求一个一百分的理想状态,而是识别并清掉那些「一定对 AI 不友好」的因素。
打个不太严谨的比方。AI-SDLC 是「让 AI 来干活」,AI-Ready 是「先把现场收拾到 AI 能下手」。一个是动作,一个是前提。
它还有个特点:没法靠拍脑袋打个分就说自己 Ready 了。一个仓库到底 Ready 不 Ready,得放到真实的需求交付里才验得出来。它是个后验的、需要持续改的状态,不是一次性达标的证书。
二、没 Ready 就卷 Agents 平台,是本末倒置

现在很多投入压在了「更强的 Agent 编排」上:多 Agent 怎么分工、怎么传递上下文、工作流怎么编排。这些当然有价值,但有个前提常被跳过,就是 Agent 干活的那个仓库,本身得能让 AI 跑得动。
Agent 再聪明,进到一个本地都起不来、没有编码规范、塞满无效代码、需求还写在 wiki 里的仓库,照样寸步难行。要么跑不动,要么收敛极慢,反复试错。
换个场景就清楚了:你请了个好厨师,但厨房没通电、食材没洗、菜谱写在一堆便利贴上。这顿饭做不好,不怪厨师。
所以 AI-Ready 和 AI-SDLC 的关系是:前者是后者的前提条件和改造方向。仓库结构清不清晰、技术债可不可控、需求有没有结构化到 AI 能读懂、CI 能不能让 AI 自己跑起来,这些不解决,上面搭再花哨的 Agent 协作,都是建在流沙上。
顺序错了,代价很具体:你在用昂贵的 Agent 算力,反复去撞那些花点工夫就能拆掉的工程债的墙。
有个数字能说明落差。在一些团队的实践里,把一个单领域仓库认真做一轮 AI-Ready 改造之后,AI 的代码采纳率能从六成出头提到九成以上。模型没变,变的只是它面对的环境。同一个 Agent,在收拾干净的仓库和一团乱的仓库里,产出差出一大截。
三、AI-Ready 到底要做哪些事

AI-Ready 不玄,落到地上就两件事:建知识库,和把每个交付阶段的 skill 喂厚。
先说个好用的方法论。一个团队里,大家很难对「什么是 AI-Ready」达成共识,但很容易对「什么是不 AI-Ready」达成共识。所以别一上来追求完美,先用问题驱动,把明显的卡点一个个铲掉。
照交付阶段过一遍,典型的「不 AI-Ready」长这样:
- 需求阶段:需求写在 wiki 或者口头交代,而不是结构化的 markdown;没有产品 SPEC 知识库,AI 读不懂业务语义。
- 方案阶段:没有架构文档,AI 定位不到该改哪儿;核心架构约束只存在某几个人脑子里。
- 编码阶段:仓库没有编码规范;堆着大量无效代码;命名随意、没有注释;到处是什么都管的 God Class。
- 测试阶段:服务本地起不来;核心链路没有自动化用例;测试数据怎么造没人写过文档。
这些就是优先要改的反模式。
改造的重头是知识库,它是 AI-Ready 的地基。比较成型的做法是分三层:通用知识、业务域知识、需求层知识,一层层往具体收。
知识库里该塞什么?架构设计、基础能力、基础组件库,这些是 AI 理解一个系统的地基。AI 不像老员工,脑子里没有那套「这个系统大概长这样、这类事一般这么干」的图景,你得把它显式写下来喂给它。
这里有两个反直觉但重要的认知。
一是「代码即知识」。真正准确反映系统怎么运行的,只有代码本身;wiki 既不保证完整,也不保证和现状一致。所以知识检索应该以 AI 能读懂的代码为核心,wiki 只补那些稳定的、代码里看不出来的片段。
二是知识的优先级。实测下来,各类知识对 AI 的帮助不是均等的:最佳实践类的知识帮助最大,其次是架构知识,规范和术语反而靠后。还有一个很具体的发现,命名语义化的贡献最高,因为它直接决定 AI 能不能找到该改的地方。给变量和函数起个能说明意图的名字,有时比写一堆文档还管用。
另一件事是丰厚各阶段的 skill。把「老手才知道怎么做」的东西,沉淀成 AI 能直接调用的能力:评估仓库 Ready 程度的、落地编码规范的、做接口级单测的、把需求结构化生成的。每个交付阶段都配上对应的 skill,AI 才知道这一步该怎么干、守什么标准。
四、Ready 之后,再谈工作流和 Agent 协作
把地基铺好,知识库、各阶段 skill、能起得来的服务、跑得通的测试都到位,再去优化工作流交互和多 Agent 协作,这时候才划算。
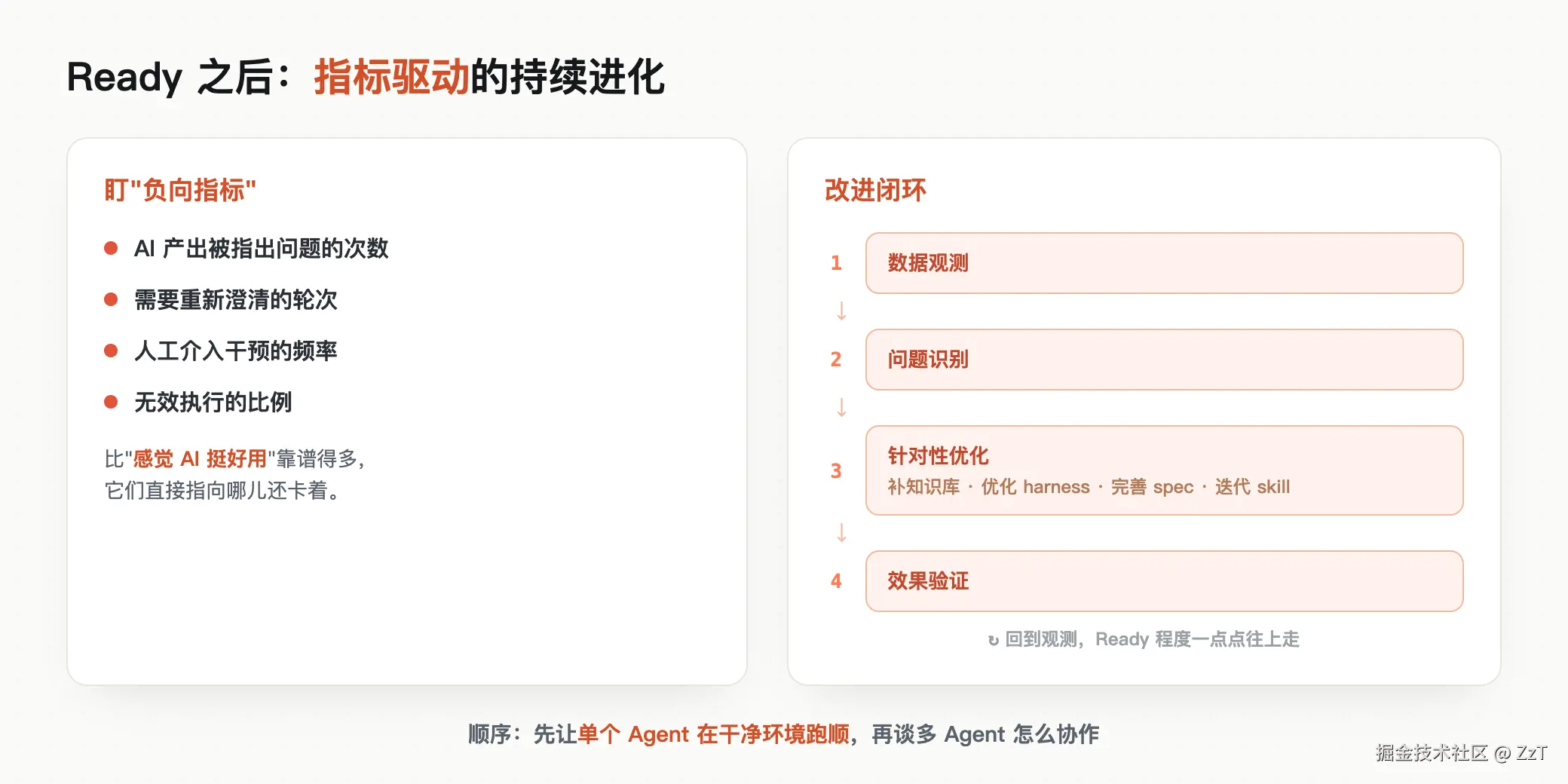
这一步进入持续进化,从「铲卡点」转向「指标驱动」。
具体做法是,对 AI-SDLC 各个环节采集过程数据,重点盯负向指标:AI 的产出被人指出问题多少次、需要重新澄清几轮、人工介入干预多频繁、有多少是无效执行。这些指标比「感觉 AI 挺好用」靠谱得多,它们直接指向哪儿还卡着。
然后用负向指标反推改进:是知识库缺了内容,是 harness 该优化,是 spec 模板不全,还是某个 skill 要迭代。改完再验证,形成「数据观测 → 问题识别 → 针对性优化 → 效果验证」的闭环,让 Ready 程度一点点往上走。
顺序在这里同样重要。先让单个 Agent 在干净环境里跑顺,再谈多个 Agent 怎么分工协作。反过来,你优化的是一套建在流沙上的协作流程,改得越多,后面返工越狠。
写在最后
回到开头那个误区。多 Agent 自动协作是个好故事,平台和框架也确实有用。但在投进去之前,值得先问一句:我的工程,AI-Ready 了吗?
AI-Ready 不性感,它没有「一群 Agent 自动把活干完」那么好讲。可恰恰是这些不起眼的活,把命名理顺、把无效代码清掉、把架构和组件沉淀成知识库、把每个阶段的 skill 补齐,决定了上面那层 Agent 到底跑不跑得动。
地基没做实就往上堆,后面返工的成本,比一开始就老老实实改造要高得多。