大家好,我是十三!欢迎来到十三Tech。
上一讲聊了语义压缩------进来了的信息怎么压才不丢工作记忆。这一讲处理的是前提失效的场景:面对陌生代码库、没看过的合同、几亿行的事故日志,Agent 不知道相关信息在哪,只能自己探索。
这一讲叫"渐进发现",但它给出的第一个判断就让我重新想了想 RAG。
一、代码库不是文档库
一个电商系统偶尔会发错订单确认邮件,混入其他客户订单条目。团队试了三种思路。

整个代码库 15000 文件全喂进 Agent------token 爆炸,切成 100 段并行喂,每段都说"没看到 bug"。换 RAG 语义检索------召回的都跟"订单""邮件"语义相关,但出问题的代码变量名是 merge_user_state,注释里没有 order 或 email,语义检索完全没命中。
最后用 grep + read:搜 send.*confirm,拿到 30 个候选,挑出 5 个最可能的,读完发现调用链 MailerWorker → Cache.get_user → render,再读 Cache.get_user,发现 cache key 用了 order_id 但没用 customer_id------bug 找到了。四轮探索,约 18K token。
这个 bug 跟语义没关系,跟代码结构有关系。 代码里的关键信息经常藏在变量名、调用链、缓存 key、配置文件、测试路径这些结构关系里,而不是藏在语义相似度里。
二、Forage / Focus / Deepen:三阶段循环
渐进发现的工程骨架是三阶段循环,背后是 Pirolli 和 Card 1999 年的信息觅食理论。
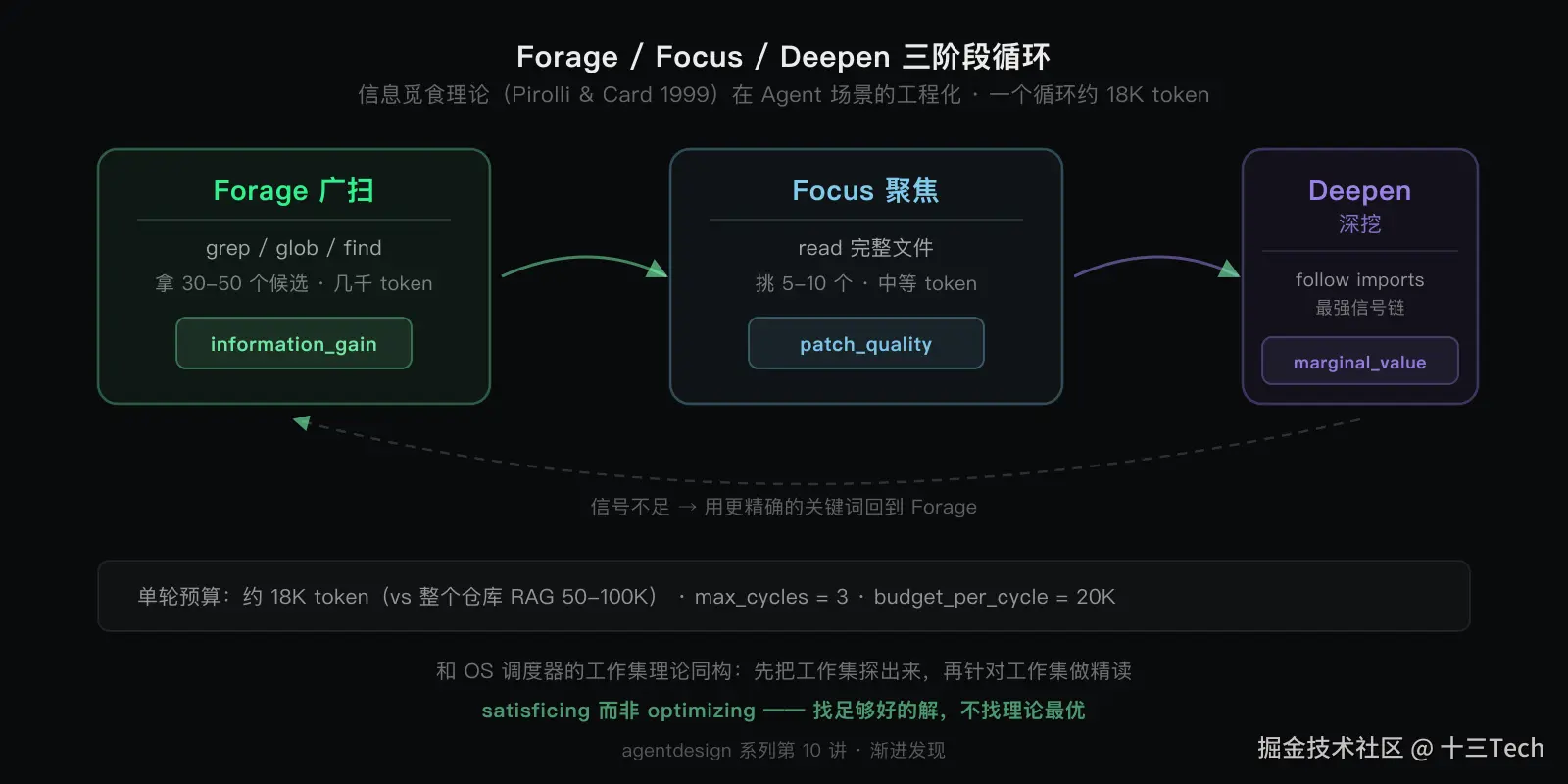 动物找食物不是把整片森林翻一遍,而是先广扫找到食物斑块,深挖已找到的斑块,斑块吃光了再换一个。这个模型先迁移到人类信息检索,现在再次迁移到 Agent 系统。
动物找食物不是把整片森林翻一遍,而是先广扫找到食物斑块,深挖已找到的斑块,斑块吃光了再换一个。这个模型先迁移到人类信息检索,现在再次迁移到 Agent 系统。
广扫阶段用低成本工具(grep / glob / find)拿候选;聚焦阶段从候选里挑 5 到 10 个完整读,建立局部理解;深挖阶段沿可疑调用链追下去,找到最强信号链。
每个阶段背后都有判断指标:广扫看 information_gain(搜一次拿到多少信号),聚焦看 patch_quality(哪个区域最值得继续挖),深挖看 marginal_value(再多花 1000 token 还能不能拿到新线索)。这三个指标让 Agent 的探索决策从"凭感觉"变成"有计算依据"。
这和 OS 调度器的工作集理论几乎同构:先把工作集探出来,再针对工作集做精读。
三、Agentic Search 反转了 RAG 常识
Claude Code 创始人 Boris Cherny 公开说过:agentic search generally works better。
这反转了整个行业关于 Agent Context 的常识------当时大家觉得"长 context 不够装就上 RAG"是天经地义,OpenAI / Pinecone / LangChain 整个生态都在这条路上推进。然后最常用的 Coding Agent 跳出来说:这条路不对。
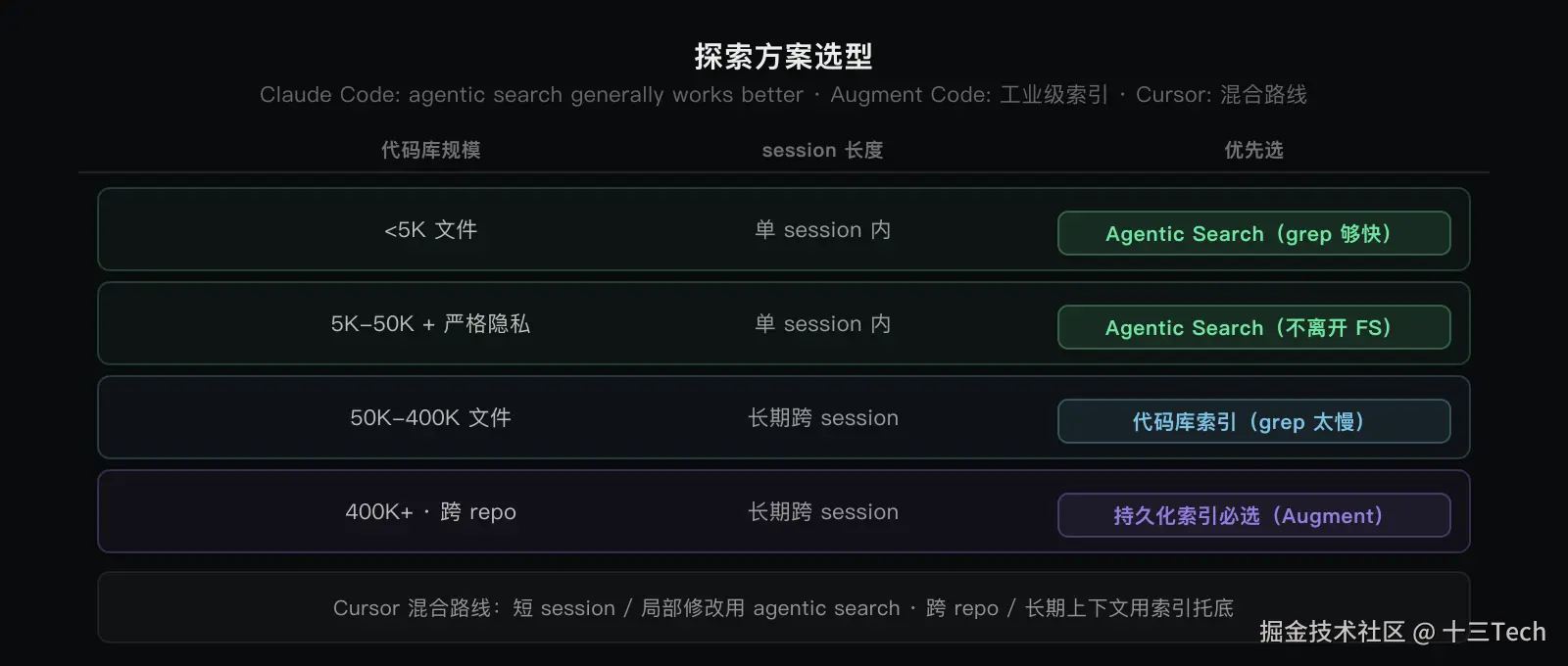
但 grep + read 不是全部。Augment Code 把 Context Engine 做成工业级代码索引系统:400K 文件、45 秒增量更新、跨 repo 依赖追踪。
这两条路线不是对立。Boris 说的是 "generally works better",generally 这个词意味着不绝对。关键判断是按规模切分:5K 文件以内用 agentic search 够了;50K 到 400K 文件需要代码库索引;400K 文件加跨 repo,持久化索引必选。Cursor 走的混合路线才是工业级答案:小库现场探索,大库索引托底。
四、Sub-Agent 隔离深挖
最后一条让我有共鸣的工程纪律:深挖过程不应该污染主 Agent 的上下文。
长期运行的 Agent 主上下文就是主进程。探索过程的中间垃圾会一路堆积,最后真正有用的信息被淹没。更成熟的做法是把深挖隔离给 Sub-Agent 或独立 search worker,主 Agent 只拿回压缩后的发现和证据链。
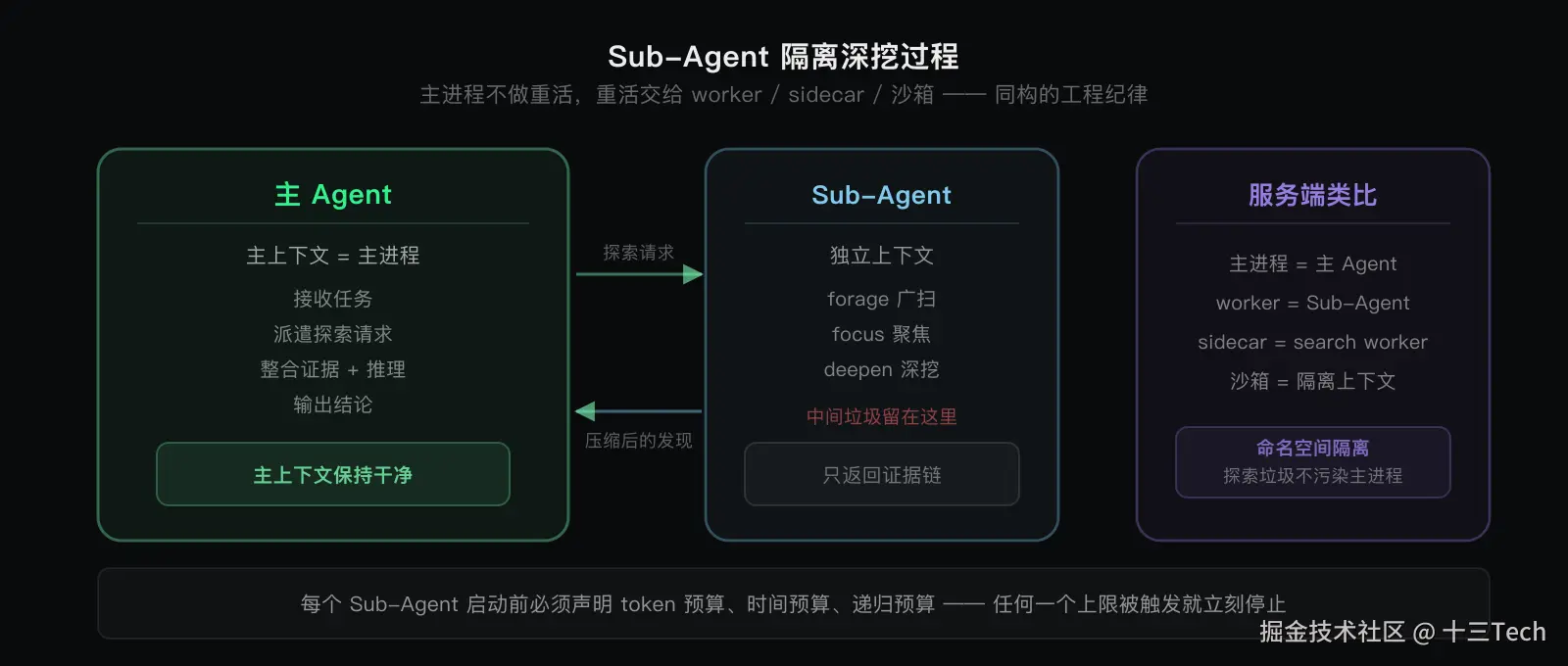
这和服务端"主进程不做重活,重活交给 worker / sidecar / 沙箱"是完全同构的工程纪律。我现在看 DeepAgents 的 subagents.py、DeerFlow 的 schema 化 Action,本质上都是在做探索过程的命名空间隔离。
还有一个让我有共鸣的判断:satisficing 而非 optimizing。探索不是寻找理论最优解,而是在有限时间、有限 token 里找到一个足够好的解。这条 Herbert Simon 的老原则------边际收益是否还覆盖边际成本------在 Agent 时代回归了。
关于十三Tech
All in AI Agent方向的架构师,专注AI工程实践。
相信AI是程序员的最佳搭档,帮助每一位开发者驾驭AI。
公众号:十三Tech
GitHub:@TriTechAI