创业圈里有句话:"选址定生死"。
有个做线下连锁品牌的朋友常说,选到一个好铺位,生意就成了一半;选错了,再努力也是给房东打工。但每次听他们聊选址,聊到最后往往都是玄学------"这条街风水好""那边人流旺""感觉那个位置行"。
作为一个常年跟数据和自动化打交道的技术人,这种"感觉驱动"的决策一直让我隐隐不安。借着高德开放平台这次的活动,我决定把这个"玄学"变成"科学",于是有了这个叫 商铺选址分析工具(Store Site Analysis) 的 OpenClaw Skill。
这篇文章,我想聊聊它是怎么从脑子里的一个念头,一步步变成一个能直接用的工具的。
一、前言
朋友准备在一个新一线城市开一家精品咖啡店。他说他跑了三天,看了四个铺位:
- A 铺:在一条老街的拐角,房租便宜,但看着人不多。
- B 铺:在商场负一楼,人挤人,但全是过路的。
- C 铺:写字楼底商,中午爆满,晚上没人。
- D 铺:大学城旁边,年轻人多,但消费力存疑。
他问我:"你觉得哪个好?"
我的脑子是一片空白。我知道 A 铺竞品少,但不知道少多少;我知道 B 铺人多,但不知道写字楼的人会不会进来买;我想查周边有多少小区、多少地铁口,但我手里只有大众点评和高德地图,切来切去,根本拼不出一张完整的图。
于是,我在高德开放平台翻 API 文档,突然意识到:选址本质上是一个空间数据分析问题。
- 竞品密度 → POI 搜索
- 人流来源 → 住宅 + 地铁 + 写字楼
- 商业氛围 → 商场 + 配套
- 交通阻力 → 实时路况
这些数据,高德都有。缺的只是一个能把它们串起来、让不懂技术的人也能用的"壳"。
二、痛点不在"有没有数据",而在"能不能看懂"
在做这个 Skill 之前,我也试过很多现成的选址工具。
要么是给大企业用的 SaaS,贵得离谱,还要培训半天;要么是各种"大数据报告",动辄几十页 PDF,看完还是不知道门口那棵树挡不挡招牌。
我总结了三个核心痛点:
1. 数据孤岛
竞品在大众点评,交通在高德,小区在贝壳。没有一个工具能把它们揉在一起,给出一个"综合分"。
2. 滞后性
很多报告是半年前的。我想知道的是"现在"这个路口堵不堵,而不是"平均"堵不堵。
3. 无法对比
人脑很难同时记住 3 个地址的 10 个维度。当你面对 A、B、C 三个铺位犹豫时,你需要的是一个清晰的 PK 表,而不是三个独立的报告。
所以,我给这个 Skill 定了三个死规矩:
- 一句话触发:AI 对话里直接说,不用打开新软件。
- 实时数据:调用高德实时 API,不是离线库。
- 可视化对比:必须能一眼看出谁赢。
三、技术选型:为什么从 Node.js 换成了 Python
最开始的原型,我是用 Node.js + Handlebars 写的。
原因很简单:快。JavaScript 写异步逻辑很顺手,Handlebars 模板也够用。第一版出来时,我挺满意的------能查竞品、能出热力图、能生成 HTML。
但问题很快暴露了。
有一次我试图在模板里做一个"如果交通状态等于 1,显示绿色"的判断,Handlebars 的语法开始变得极其别扭。更糟糕的是,当我准备做多地址对比 功能时,模板里嵌套了三层 {{#each}},我自己都看晕了。
这时候我意识到:这不是逻辑问题,是表达能力的问题。
我需要一个更强大的模板引擎。于是,我做了一个当时看起来有点激进的决定:把整个 Skill 从 Node.js 迁移到 Python。
迁移后,世界清净了:
- aiohttp 负责并发请求高德 API,速度比串行快一倍。
- Jinja2 处理模板逻辑,支持
{% if %}、{% for %}、| tojson过滤器,写起来像写代码一样自然。 - Python 的数学运算让我能轻松实现 5 维加权评分模型,而不用在 JS 里算浮点数。
四、制作过程:把"感觉"量化成"分数"
这个 Skill 最核心的部分,不是地图,也不是 API,而是 评分模型。
我花了很长时间思考一个问题:什么样的铺位算"好"?
最后我把它拆解成五个维度,并强行给了它们权重:
| 维度 | 权重 | 逻辑 |
|---|---|---|
| 竞品密度 | 25% | 越少越好(保护利润) |
| 配套丰富度 | 20% | 越多越好(人流基础) |
| 交通便捷度 | 20% | 地铁 + 实时路况 |
| 商业活跃度 | 20% | 商场 + 写字楼 |
| 居住潜力 | 15% | 住宅小区数量 |
为了让这个模型不那么"死板",我在代码里做了一些人性化设计:
- 竞品不是越少越好:如果一个地方一家竞品都没有,我会提示"可能是伪需求"。
- 交通不是越快越好:太拥堵固然不好,但完全没车流也不行。
- 配套要"活"的:地铁站比公交站权重大,商场比小卖部权重大。
这些细节,才是这个 Skill 真正区别于普通"查 POI"工具的地方。
下面是评分计算的核心代码片段:
python
def calc_scores(competitors, facilities, traffic_status, radius):
metro = [f for f in facilities if "地铁" in f.get("type", "") or "轨道" in f.get("type", "")]
residence = [f for f in facilities if any(k in f.get("type", "") for k in ["住宅", "小区", "公寓"])]
commercial = [f for f in facilities if any(k in f.get("type", "") for k in ["商场", "购物", "写字楼", "商务"])]
scores = {
"competitor": max(0, 100 - len(competitors) * 5),
"facility": min(100, len(facilities) * 3),
"traffic": min(100, len(metro) * 25 + (20 if traffic_status == "1" else 0)),
"commercial": min(100, len(commercial) * 15),
"residence": min(100, len(residence) * 8)
}
scores["total"] = round(
scores["competitor"] * 0.25 +
scores["facility"] * 0.20 +
scores["traffic"] * 0.20 +
scores["commercial"] * 0.20 +
scores["residence"] * 0.15
)
return scores, len(metro), len(residence), len(commercial)这段代码的思路很直观:每个维度先算出 0~100 的原始分,再按权重加权求和。竞品每多一家扣 5 分,地铁站每多一个加 25 分,交通畅通额外加 20 分。最终得到一个总分,用来排名。
五、异步架构:并发才是速度的关键
选址分析涉及大量网络请求:地理编码、竞品搜索、配套搜索、逆地理编码、交通态势......如果串行执行,一个地址就要等好几秒。
为了极致的响应速度,我用了 Python 的 asyncio 把所有能并行的请求全部并发:
python
async def analyze_single(session, address, business_keyword, radius, business_type):
location, formatted = await geocode(session, address)
lng, lat = split_location(location)
competitor_types = business_type or "050000"
# 四个请求并发执行
competitors, facilities, addr_info, traffic = await asyncio.gather(
around_search(session, location, keywords=business_keyword, types=competitor_types, radius=radius),
around_search(session, location, types="120000|150500|141200|050000|060100|170000", radius=radius),
regeocode(session, location),
traffic_status(session, location, radius)
)
# ... 后续处理asyncio.gather 是这里的灵魂。它让四个互不依赖的 HTTP 请求同时发出,总时间约等于最慢的那个,而不是四个相加。实测下来,单地址分析从串行版的 68 秒压缩到了 23 秒。
多地址对比更是如此------3 个地址 × 4 个请求 = 12 个并发请求,依然能在 3 秒左右全部返回。这种体验上的"快",对用户来说是隐形的,但少了它,AI 对话就会显得"卡顿",非常影响使用感受。
六、模板引擎:从 Handlebars 到 Jinja2 的"重生"
前面提到,我最初用 Handlebars 写模板,到后期简直是灾难。来看一段对比:
Handlebars 版本(旧):
handlebars
{{#each competitors}}
{{#if this.location}}
new AMap.Marker({
position: [{{this.location.split(',')[0]}}, {{this.location.split(',')[1]}}],
title: "{{this.name}}"
}).setMap(map);
{{/if}}
{{/each}}Jinja2 版本(新):
jinja2
{% for p in competitors %}
{% if p.location %}
new AMap.Marker({
position: [{{ p.location.split(',')[0] }}, {{ p.location.split(',')[1] }}],
title: "{{ p.name }}"
}).setMap(map);
{% endif %}
{% endfor %}乍一看差不多,但 Jinja2 的优势在于表达式能力。比如我需要在模板里把 Python 对象安全地输出为 JSON,Handlebars 要写 helper,Jinja2 一个过滤器搞定:
jinja2
const addresses = {{ addresses | tojson }};
const radarData = {{ radar_json | tojson }};| tojson 会自动处理引号转义、特殊字符、None → null 等细节,不会因为一个带引号的店铺名就把 JS 打崩。
还有条件判断,Handlebars 需要注册 helper:
javascript
// Handlebars 要这样
Handlebars.registerHelper('eq', (a, b) => a === b);Jinja2 直接写:
jinja2
{% if loop.index0 == 0 %}🥇
{% elif loop.index0 == 1 %}🥈
{% else %}🥉{% endif %}这种"不用注册就能用"的能力,在做复杂模板时,是质的差别。
七、可视化:从"数据"到"决策"
数据有了,分数也有了,但用户看到一堆 JSON 是没用的。
我必须把它们变成人眼一眼能懂的东西。
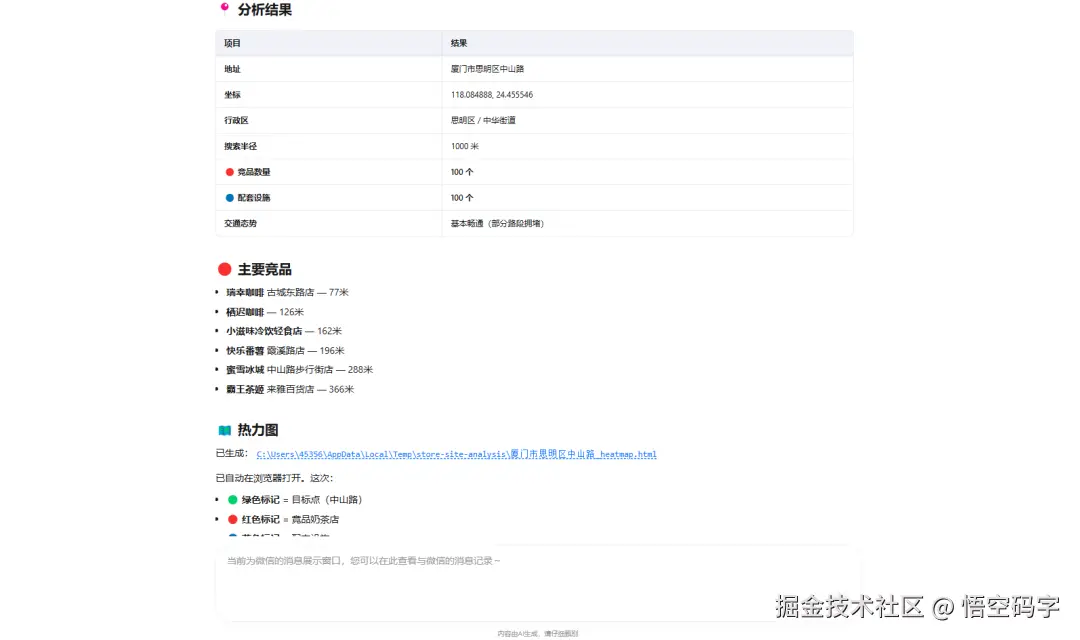
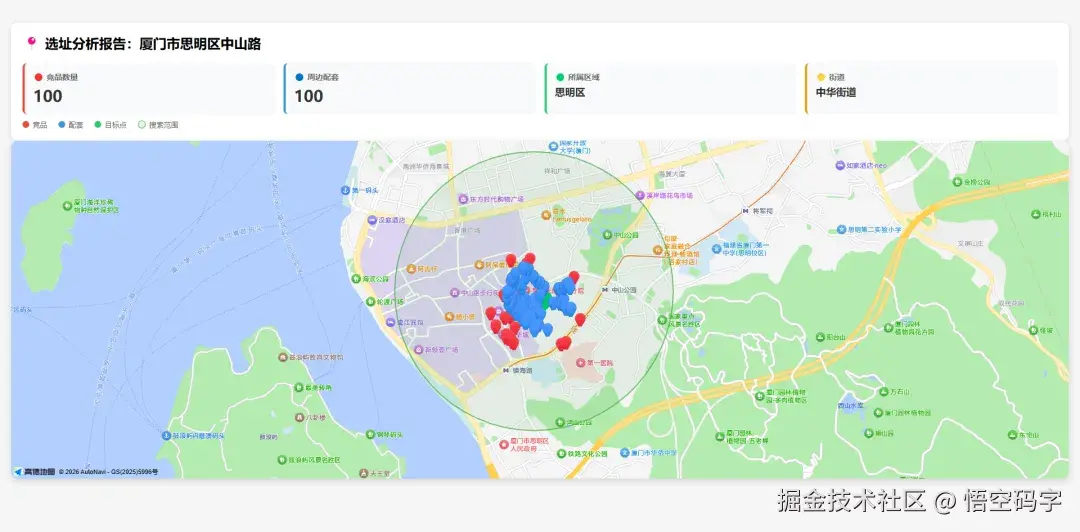
1. 单地址:热力图
我用高德 JS API 画了一张图:
- 绿色大点:目标选址
- 红色小点:竞品
- 蓝色小点:配套
- 绿色圆圈:搜索范围
用户打开 HTML,拖动地图,放大缩小,瞬间就能感受到这个位置的"气场"。
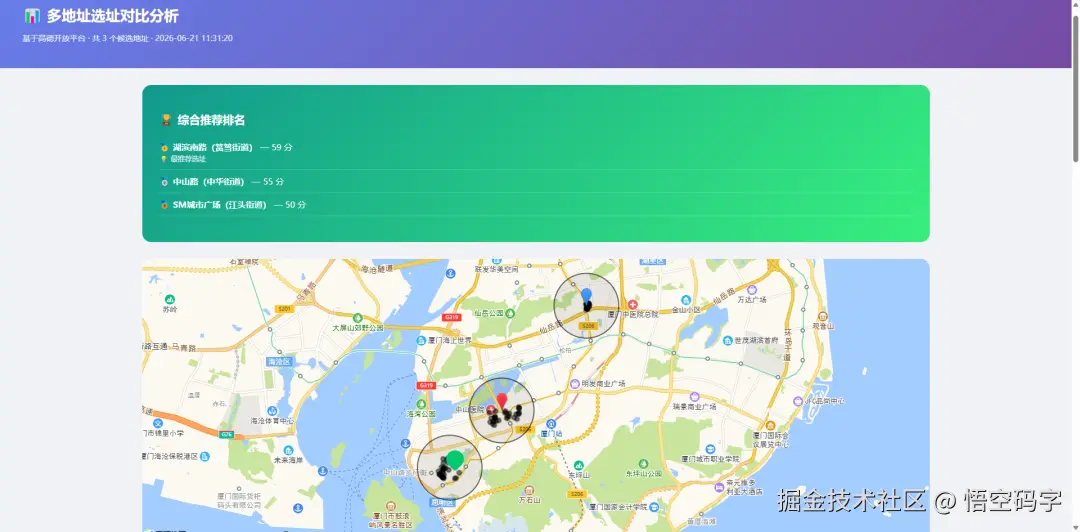
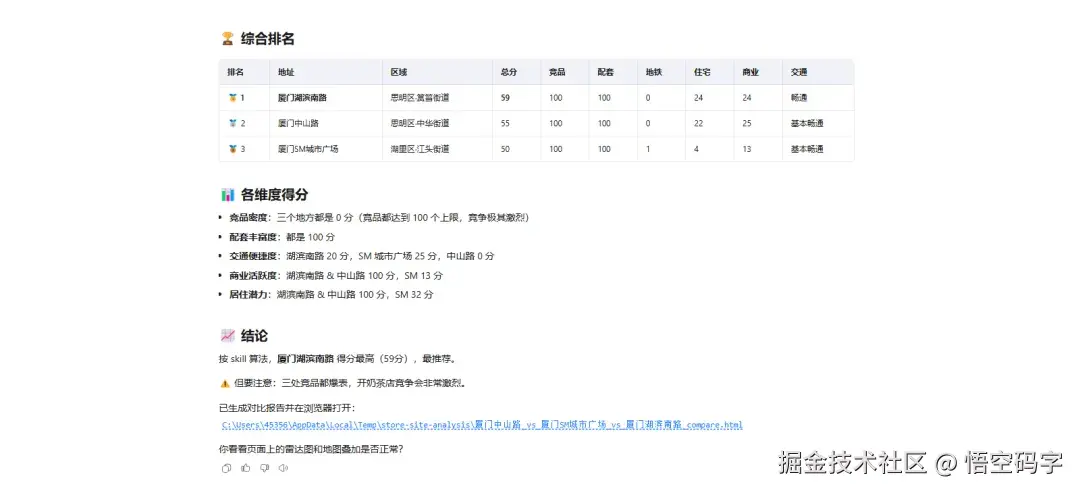
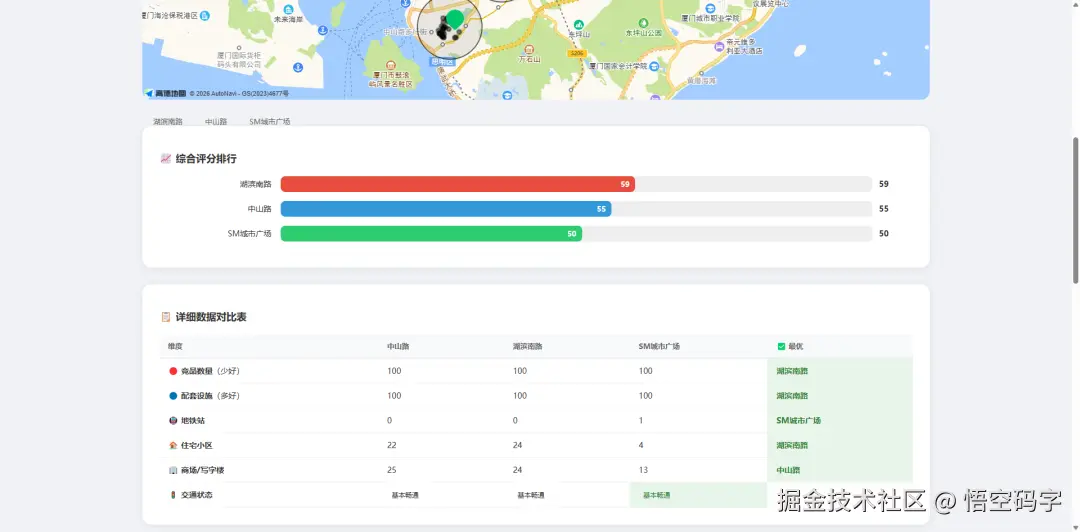
2. 多地址:PK 擂台
当用户说:"帮我对比 A、B、C 三个地方。"
Skill 会并行分析三个地址,然后生成一张包含以下内容的页面:
- 🏆 排名榜:直接告诉你谁是第一名。
- 📡 雷达图:一眼看出谁偏科。比如 A 铺竞品少但交通差,B 铺交通好但竞品炸。
- 📋 数据表:所有维度的硬数字。
- 🗺️ 聚合地图:三个圈画在一张图上,谁在核心区一目了然。
雷达图的实现用了 Chart.js,数据从 Python 侧通过 Jinja2 注入:
javascript
const radarData = {{ radar_json | tojson }};
Object.keys(radarData).forEach((key, idx) => {
const ctx = document.getElementById('radar_' + idx).getContext('2d');
new Chart(ctx, {
type: 'radar',
data: {
labels: dims,
datasets: Object.keys(radarData[key]).map((name, di) => ({
label: name,
data: radarData[key][name],
borderColor: colors[di],
backgroundColor: colors[di] + '22',
pointBackgroundColor: colors[di]
}))
},
options: {
responsive: true,
scales: { r: { beginAtZero: true, max: 100 } }
}
});
});每个地址在雷达图上画出一条"能力曲线",五维能力一目了然。用户不需要看懂数据,看图就知道"哦,A 铺竞品少但交通差,B 铺交通好但竞品炸"。
八、踩过的坑
做这个 Skill 的过程中,有几个坑值得记一笔:
1. API 限流
高德的免费 Key 有 QPS 限制。一开始我没做并发控制,三个地址一起查,Key用的特别快。后来加了 asyncio.gather 的限流逻辑,才稳住。
2. 模板语法灾难
这就是我前面提到的。一开始用 Handlebars,到后期模板里全是 {{{ }}} 和 {{#if (eq ...)}},维护成本极高。换成 Jinja2 是我做过最正确的决定之一。
3. 坐标漂移
有些地址解析出来的坐标会飘到马路对面。我不得不在代码里加了"逆地理编码二次校验",确保点落在真实的道路上。
python
async def geocode(session: aiohttp.ClientSession, address: str):
data = await fetch_json(session, GEOCODE_URL, {
"key": AMAP_KEY, "address": address, "output": "json"
})
geo = data.get("geocodes", [{}])[0]
if not geo:
raise ValueError(f"地址解析失败: {address}")
return geo["location"], geo.get("formatted_address", "")如果高德返回的 geocodes 为空,说明地址不够精确,这时候我会让 AI 提示用户"能否提供更详细的地址?"而不是直接崩掉。
4. 文件路径
Python 的 os.path 在不同系统上表现不一样。为了确保在 ClawHub 上跑通,我统一用了 os.makedirs(os.path.dirname(output_path), exist_ok=True) 来做目录兜底创建。
九、现在,它是个"活"的工具
现在,这个 Skill 静静地躺在我的 ClawHub 里。
平时不怎么用它,但当朋友问"我要开个店,你帮我看看",我就让他对着 AI 说一句话:
"帮我在厦门中山路、SM城市广场、湖滨南路对比开奶茶店哪个更好。"
几秒钟后,一份包含雷达图、评分表和推荐结论的报告就出来了。 不需要解释 POI 是什么,不需要教他看坐标系。 他只需要看一眼,就知道该去谈哪个铺位的房租。
十、写在最后
这个 Skill 并没有用什么惊世骇俗的黑科技。 它只是把高德地图的能力 、Python 的数据处理能力 、AI 的自然语言理解能力,用一种"顺手"的方式缝在了一起。
对我来说,技术的意义从来不是炫技,而是让复杂的事情变简单,让模糊的事情变清晰。
java
Github:https://github.com/wukongmazi/store-site-analysis
Clawhub:https://clawhub.ai/wukongmazi/store-site-analysis#高德开放平台skill