过去十年,数仓从"上云"走向"云原生"。然而在资源管理层面,一个根本性矛盾依然存在:业务负载具有波动性,而资源规格通常只能依据峰值提前锁定。
很多数据团队都经历过类似场景:为保障上午的 BI 报表高峰购买了 64 核计算资源,但实际高负载时间每天仅有 3-4 小时,其余时间 8 核即可满足需求。按全天 24 小时计算,超过 70% 的计算资源处于空转状态。反之,若为了省钱而调低计算资源,遇到临时大查询或突发流量时,传统云数仓的扩容涉及资源申请和数据重分布,通常需要等待 10 分钟甚至小时级,期间业务体验已受到明显影响。
阿里云设计 SelectDB Serverless 的初衷,正是为了解决这一资源供需矛盾,实现资源按需供给与按使用量计费,在负载高峰时补齐资源,在低谷时释放资源。本文将从问题出发,拆解 SelectDB Serverless 的架构设计、核心能力与适用场景。
传统云数仓的三重困境
在介绍 SelectDB Serverless 方案之前,我们先分享下传统云数仓经常遇到的三类痛点问题:
1、按峰值购买,资源空转严重
多数分析场景存在周期性的波峰波谷。例如 ToC 业务的白天流量通常是夜间的数倍,BI 报表则集中在工作日上午。在传统固定规格模式下,为了保障高负载时的 SLA,团队通常只能按峰值规划资源,导致低谷期资源闲置,实际平均利用率往往不足 30%。此外,由于业务增长的不确定性,通常还需额外预留容量,进一步加剧了资源闲置。
2、弹性慢如蜗牛,伸缩本身有风险
"不是没有弹性能力,是弹性体验太差了。"------这是我们听到最多的吐槽之一。
目前多数云数仓采用存算分离架构(计算依赖虚拟机/容器,存储依赖对象存储),并在计算节点本地引入缓存以缓解对象存储的读取延迟。然而在扩容时,该架构需要经历节点拉起、缓存预热等过程,耗时通常在 10 分钟到小时级别。在缓存未完全预热期间,新节点查询延迟飙升,高并发下甚至可能引发服务雪崩。因此,许多团队宁可承担高额成本,也不愿在紧急情况下触发弹性伸缩。
3、人工弹性兜底,运维压力居高不下
为了平衡成本与性能,不少团队采用"定时任务+人工介入"的组合运维方案:对可预测的早晚高峰配置定时扩缩容,对突发流量则依赖告警后人工处理。这类方案在实际操作中面临以下挑战:
- 无法应对非周期性负载:Ad-hoc 查询、突发流量会打破常规负载曲线,基于固定规则的脚本无法自动适应。
- 库存与容错风险:定时扩容如果恰逢云厂商底层资源库存不足,会导致扩容失败,需要人工紧急介入。
- 运维响应不及时:人工响应及资源扩容均耗时较长,流量突增时扩容很难及时完成,很容易触发生产故障。
SelectDB 的解决方案 ------ Serverless
传统云数仓面临上述三重困境的关键在于,云数仓所依赖的主要资源被绑定在同一物理节点上。例如在 Snowflake 等存算分离架构数仓中,主要依赖三类资源:负责数据处理的计算资源、提升数据访问效率的缓存资源、承载全量数据存储的对象存储,但计算资源和缓存资源深度绑定。当业务负载变化时,数仓无法快速的进行计算资源弹性、伸缩过程也伴随较大的服务抖动。
SelectDB Serverless 重新设计了云数仓的资源模型,从架构上将计算、缓存、存储三层进行独立解耦,使其各自具备独立的伸缩能力,彼此不再强绑定于同一物理节点 。这种解耦架构让计算弹性不再受缓存或存储拖累,伸缩时不会因数据重分布导致服务抖动,弹性速度也从分钟级降至秒级。 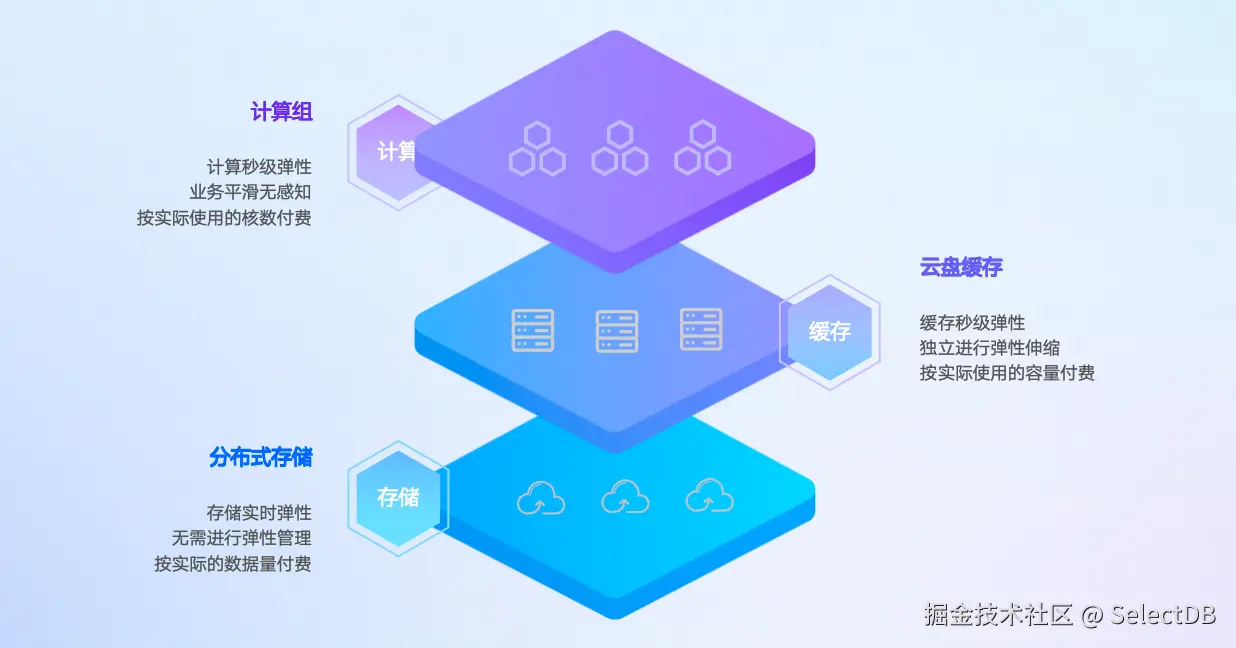
当客户使用 SelectDB Serverless 时,仅需指定计算资源的弹性区间 (例如 8 核 ~ 128 核),计算资源即可根据实时负载自动弹性伸缩,精准匹配业务需求。与此同时,存储资源根据实际数据量自动伸缩,缓存资源支持按需进行弹性,用户无需关心底层资源的分配细节,真正实现"用多少付多少"的按量计费模式。
事实上,Snowflake、StarRocks 等产品也在积极探索提升云数仓的弹性体验,但目前还没有产品化的解决方案。SelectDB Serverless 通过三层完全解耦的架构设计,将云数仓的弹性体验推进到新的层次,可实现秒级无感的数仓伸缩,真正实现弹得快、弹得稳、弹得省"。
Serverless 核心能力速览
下面我们来进一步了解 SelectDB Serverless 产品形态的核心产品能力。
1、秒级按需弹性,无需容量规划
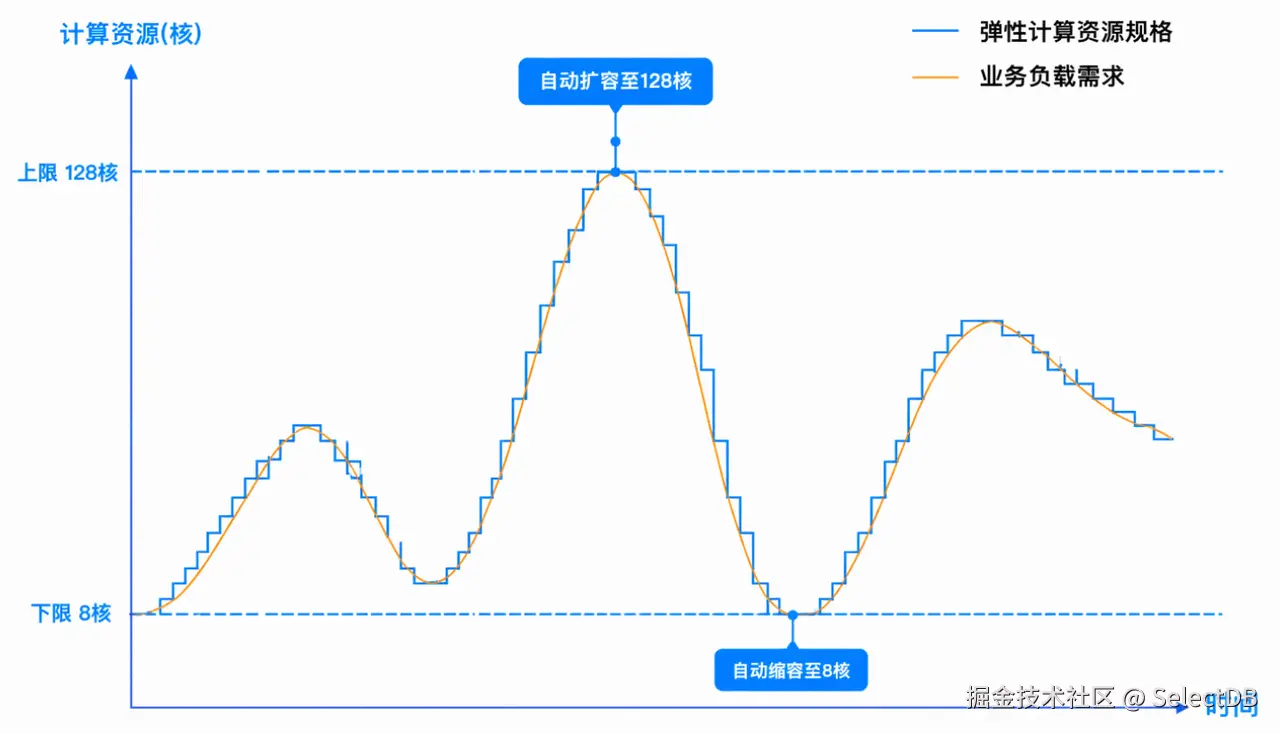
传统弹性方案的主要矛盾在于:弹性(扩缩容)的速度跟不上负载变化的速度。 SelectDB Serverless 通过如下设计思路,支持了秒级自动弹性:
- 实时监控:系统以秒级粒度采集各集群的 CPU 与内存利用率。
- 快速弹升:当 CPU 5 秒均值或内存瞬时利用率超过 60% 时,会立即触发扩容请求,实现快速响应。
- 保守弹降:当 CPU 与内存利用率同时低于 30% 且持续 1 分钟后,系统触发渐进式缩容,避免因负载短时波动导致频繁扩缩容。
- AI 辅助决策:当弹性请求触发后,系统通过 AI 辅助决策,根据业务历史负载、周期特征、当前资源水位等综合判断,实现更精准的弹性调度。相比纯规则策略,弹性准确率提升 40%。
这套产品弹性机制的设计原则是:扩容要快、要果断,缩容要慢、要稳健。 通过稳健、智能的弹性策略,保障业务持续平稳运行。
2、16 倍无感原地伸缩,显著降低抖动风险
另一关键问题:弹性过程中,正在执行的查询会不会受影响?
传统系统中弹性伸缩意味着节点增减、数据重分布、连接重建,查询延迟在伸缩窗口内可能出现数倍波动。SelectDB Serverless 通过原地纵向弹性,支持了无感伸缩能力:
- 原地资源弹性:伸缩过程在原地完成,不涉及数据迁移,不需要通过连接重建来完成资源切换,也避免了对缓存命中率的影响。
- 宽幅纵向弹性:单集群支持最高 16 倍的资源弹性区间,例如集群可在 8 核至 128 核,或 64 核至 1024 核区间内进行自动伸缩。
16 倍的伸缩跨度可以覆盖绝大多数客户的弹性需求。对于极端场景(如大促期间峰谷比超过 16 倍),可以通过控制台进行横向弹性,耗时约 3 分钟,查询延迟可能有小幅波动但整体可控。
3、计算 / 缓存 / 存储独立弹性,按使用量计费
在 Snowflake 等传统存算分离架构中,缓存通常与计算节点强绑定(例如固定核数对应固定容量的本地 SSD)。如果希望加大缓存提升命中率,必须被迫升级计算规格。
SelectDB Serverless 将三层完全解耦,提供独立伸缩能力与按使用量计费模式:
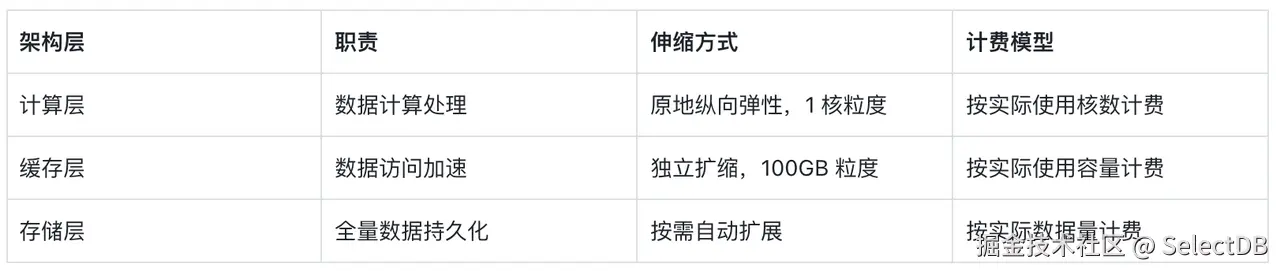
三层解耦让每一层的成本都精确映射实际使用量。 用多少算力付多少算力的钱,用多少缓存付多少缓存的钱,存多少数据付多少存储的钱。规避了资源错配带来的非必要支出,实现真正的 Pay As You Go。
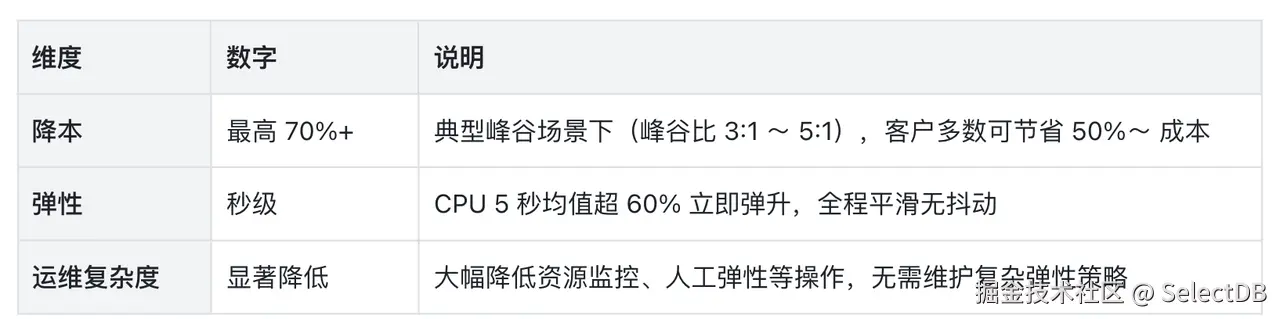
总结来说,SelectDB Serverless 的核心能力,可以为用户带来以下三点收益:
Serverless 选型指南
介绍了这么多 SelectDB Serverless 产品形态的能力及优势,哪些典型场景适合 Serverless?SelectDB 的多种产品形态如何选择?
1、Serverless 适合哪些场景
从前面介绍不难看出,负载曲线峰谷越明显、资源使用波动越大,Serverless 的价值越高。
- 场景一:计算负载具有周期性峰谷。 如 ToC 业务(白天高负载/夜间低负载)、企业内部 BI(工作日集中查询/周末空闲)以及定时段运行的轻量 ETL 任务。
- 场景二:业务负载不可预测。 如 Ad-hoc 临时分析、由 AI 智能体(Agent)触发的并发查询、以及大模型特征工程的批量计算等,无法预知下一条 SQL 的算力开销。
- 场景三:寻求降低弹性运维压力。 团队不希望投入太多精力来进行人工资源弹性,愿意将扩缩容决策托管给系统,只需要设置一个弹性区间(例如 8 核 ~ 128 核)即可。
2、SelectDB 多种产品形态如何选择
阿里云 SelectDB 提供了包年包月、按量付费和 Serverless 三种产品形态,分别适用于不同的业务负载与成本诉求。用户可结合自身业务的负载稳定性、弹性需求和成本目标,选择最合适的实例类型。
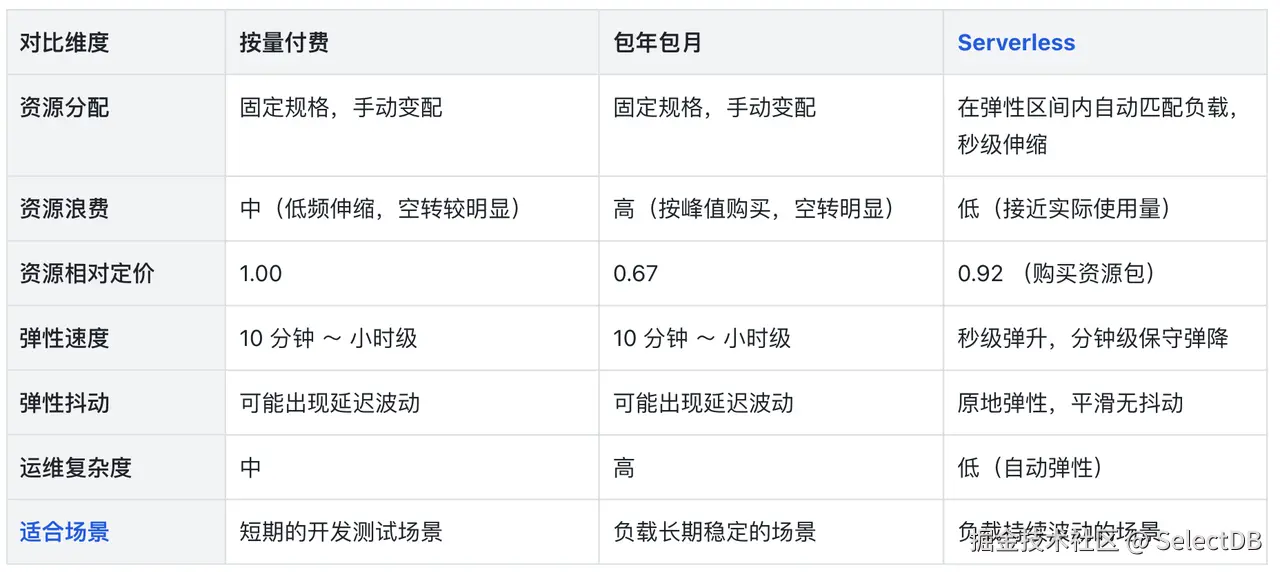
值得注意的是,对于长期生产类业务是选择包年包月还是 Serverless 产品形态?仅从成本角度评估,只有当业务的峰谷特征明显,可通过弹性释放的计算资源超过 28% 时,Serverless 产品形态才能体现出成本优势。当然,业务也需要结合弹性的速度、业务影响来综合选型。
写到最后
Snowflake 用存算分离重新定义了云数仓的架构标准,SelectDB Serverless 的目标是更进一步,让弹性从一项需要频繁人工介入的能力,变成平台内置、自动触发、秒级生效的基础能力。
目前,SelectDB Serverless 已在阿里云正式商用,后续的技术演进将主要聚焦于以下两个方向:
- 弹性边界的持续拓展: 团队正在推进全自动的水平(横向)伸缩机制,旨在突破单集群 16 倍的纵向物理限制,以适配峰谷比更极端的超大规模负载场景;同时将支持普通实例一键切换 Serverless 模式,降低存量用户的迁移门槛。
- AI 生态的深度融合: SelectDB Serverless 正全面拥抱 AI 生态 ------ 内核层原生支持 AI 函数和向量检索等特性;接入层提供 CLI、MCP、Skills 等 Agent 对接能力;应用层提供 AI 可观测等完整解决方案。SelectDB Serverless 正在致力于打造 AI Infra 架构中的统一数据分析底座。