Agent 后端地址:github.com/dxx/agent-t...
Web 前端地址:github.com/dxx/agent-t...
初衷
AI 编程正在变成一种新的开发常态。现在很多开发者已经不再完全手写代码,而是通过 Cursor、Claude Code、OpenCode、GitHub Copilot 等工具,让 AI 帮助完成需求分析、代码生成、重构和测试。 但当 AI 真正进入日常开发后,会出现一个很现实的问题:AI 可以帮我们写代码,但不一定能持续写出风格统一、结构一致、可维护的代码。 尤其是在团队协作或长期项目中,不同开发者使用的提示词不同、模型不同、编码习惯不同,最终生成出来的代码可能在这些方面产生差异:
- 目录结构不一致
- 命名风格不一致
- Agent 拆分方式不一致
- 工具调用方式不一致
- 配置和环境变量管理方式不一致
- 错误处理和日志规范不一致
对于普通业务项目来说,这些问题已经会影响维护成本;而在 Agent 项目中,问题会更加明显。 因为一个 Agent 服务通常不只是简单调用一次大模型,它还会涉及子代理协作、工具调用、路由分发、上下文管理、流式输出、人工审批、MCP 接入、Skills 技能加载等能力。如果每次都让 AI 从零开始理解这些架构,再生成对应代码,不仅容易出现实现不统一的问题,也会反复消耗大量 token。 所以这个项目的初衷很简单: 先把 Agent 项目中通用、重复、容易出错的部分沉淀成一个工程模板,让 AI 和开发者都在统一的结构下工作。 基于这个模板,开发者不需要每次都重新搭建 Agent 服务的基础能力,也不需要在提示词里反复描述项目结构、技术选型和实现规范。AI 可以直接基于已有的代码组织方式继续扩展功能,从而减少上下文解释成本,降低 token 消耗,也让项目更容易维护和演进。 agent-template 就是为这个目标而设计的。它基于 FastAPI、LangChain 和 LangGraph 构建,预置了子代理、路由代理、Skills、MCP、Human-in-the-loop、消息管理、多模态等常用能力,帮助开发者快速启动一个结构清晰、能力完整、适合持续扩展的 AI Agent 服务项目。
概述
Agent 后端基于 FastAPI + LangChain + LangGraph 构建,支持多子代理协作、路由代理协作和人工审批流程。
Web 前端是一个用于调试和演示 Agent 的项目,项目提供了会话管理、SSE 流式对话、工具调用过程展示和 Human-in-the-Loop 审批能力。
技术栈
Agent 后端
- Python: 3.12+
- Web 框架: FastAPI
- Agent 框架: LangChain + LangGraph
- LLM: OpenAI API (兼容)
- 包管理: uv
- 服务器: Uvicorn
Web 前端
- React 19
- TypeScript 6
- Vite 8
- React Router v7
- Sass
- Axios
- @microsoft/fetch-event-source
- react-markdown + remark-gfm
Agent 后端
Agent 模块
主 Agent - 通过 create_main_agent() 创建,负责整体对话协调,通过 task 工具调度子代理。
路由 Agent - 通过 create_router_agent() 创建,使用 RouteAgentMiddleware 注册 route 工具。主 Agent 调用该工具后,内部 StateGraph 会先根据用户输入选择一个或多个路由任务代理,再并发调用对应代理并合并结果。
状态与持久化:
AppAgentContext: 用户上下文,包含user_idAppAgentState: Agent 状态,继承自AgentState,包含sub_agent_calls记录调用的子代理RouterState: 路由代理状态,包含query、routers、router、results和final_resultinit_postgres_checkpointer()/close_postgres_checkpointer(): 初始化和关闭 Checkpointer 连接池init_postgres_store()/close_postgres_store(): 初始化和关闭 Store 连接池- 默认使用内存存储 (
InMemorySaver和InMemoryStore),生产环境可切换为 PostgreSQL
MCP Client 中间件:
MCPClientMiddleware: 连接 MCP (Model Context Protocol) Server,动态加载和注入工具- 支持配置多个 MCP Server 连接
- 工具名称自动添加前缀以避免冲突(格式:
servername_toolname) - 支持
ignore_tools参数屏蔽不需要的工具 - 支持
callbacks和tool_interceptors扩展功能
技能系统:
SkillLoader: 技能加载器抽象定义DirectorySkillLoader: 从本地目录加载技能RemoteSkillLoader: 从远程加载技能
Web 模块
服务:
- 基于 FastAPI 的 REST 服务
- 全局异常处理(HTTPException、RequestValidationError、Exception)
- 认证中间件
- 生命周期管理(Postgres 连接初始化/关闭)
核心路由:
| 路由 | 方法 | 功能 |
|---|---|---|
/chat/stream |
POST | SSE 流式对话(需认证) |
/chat/router/stream |
POST | SSE 路由 Agent 流式对话(需认证) |
/message/chat/create |
POST | 创建新对话 |
/message/all |
GET | 获取用户所有对话 |
/message/chat/{chat_id} |
GET | 获取指定对话的消息列表 |
/message/chat/{chat_id} |
DELETE | 删除指定对话的所有消息 |
/message/all |
DELETE | 删除用户所有对话 |
中间件:
AuthMiddleware: 基于请求头认证ChatMiddleware: 对话状态中间件
子代理调度
主 Agent 通过 task 工具调用子代理系统:
- 用户请求 → 主 Agent 处理
- 主 Agent 判断需要调用的子代理类型
- 通过
task分发给对应子代理 - 子代理执行完成后返回结果
- 主 Agent 整合结果返回给用户
路由代理调度
路由模式下,主 Agent 不直接决定子代理,而是调用 route 工具交给路由图处理:
- 用户请求 → Router Main Agent 处理
- Router Main Agent 调用
route - 工具从当前消息历史提取用户输入,构造
{"query": 用户输入} - 内部路由图根据代理描述选择一个或多个
RouteTaskAgent - 多个任务代理可并发执行
- 单个结果直接返回,多个结果由合并模型整理为
final_result
人工审批流程
某些危险操作(如文件写入)会触发人工审批:
- 工具调用 →
HumanInTheLoopMiddleware→interrupt()中断 - 返回审批请求给前端(
msg_type=approve) - 用户提交决策(
approve/reject) - 处理决策后继续或返回错误
技能系统
技能存储在 skills/ 目录下,每个技能为一个文件夹:
csharp
skills/
├── <skill-name>/
│ ├── SKILL.md # 技能描述,YAML frontmatter + 技能内容
│ └── references/ # 参考文档目录(可选)
│ └── <ref-file> # 参考文件SKILL.md 格式:
markdown
---
name: <skill-name>
description: <技能简短描述>
---
# 技能名称
技能详细描述和指令,引用参考文件。技能中间件会:
- 扫描
skills/下所有子目录的SKILL.md - 解析 YAML frontmatter 获取名称和描述
- 生成可用技能列表并注入系统提示词
- 通过
load_skill工具按需加载技能详情和来源路径
对话流程
scss
用户请求 → 认证中间件 → ChatService
↓
MainAgent.astream() 异步流式处理
↓
┌──────────────┴───────────────┐
↓ ↓
消息流 (messages) 更新流 (updates)
↓ ↓
渲染 AIMessageChunk 渲染完整消息/中断
└───────────────┬──────────────┘
↓
SSE 响应完整说明
阅读完整内容
功能演示
界面截图
流式对话
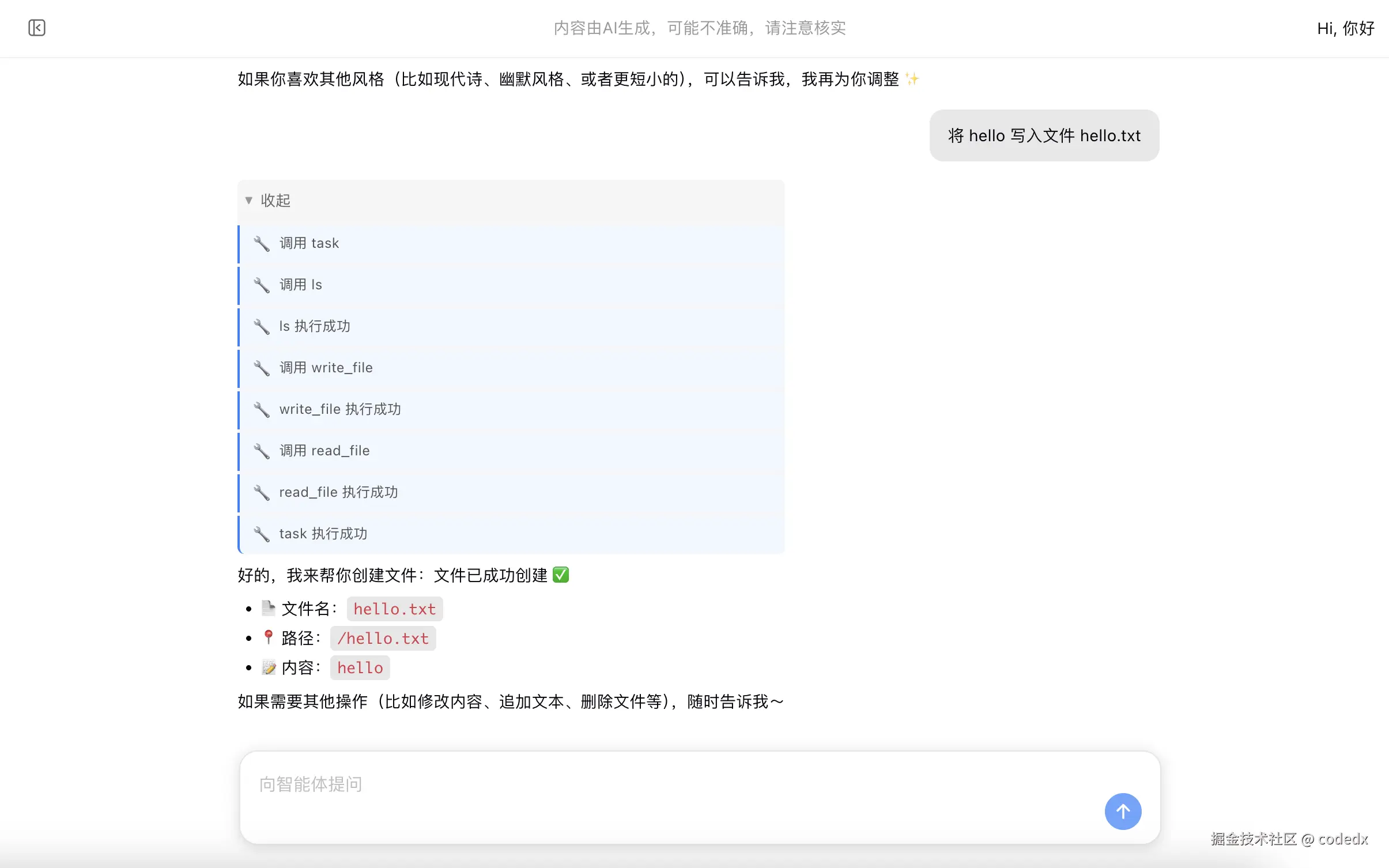
展示基础聊天流程。发起普通对话,让 Agent 执行"写一首关于 AI 的诗"的任务,界面显示工具调用处理中状态:
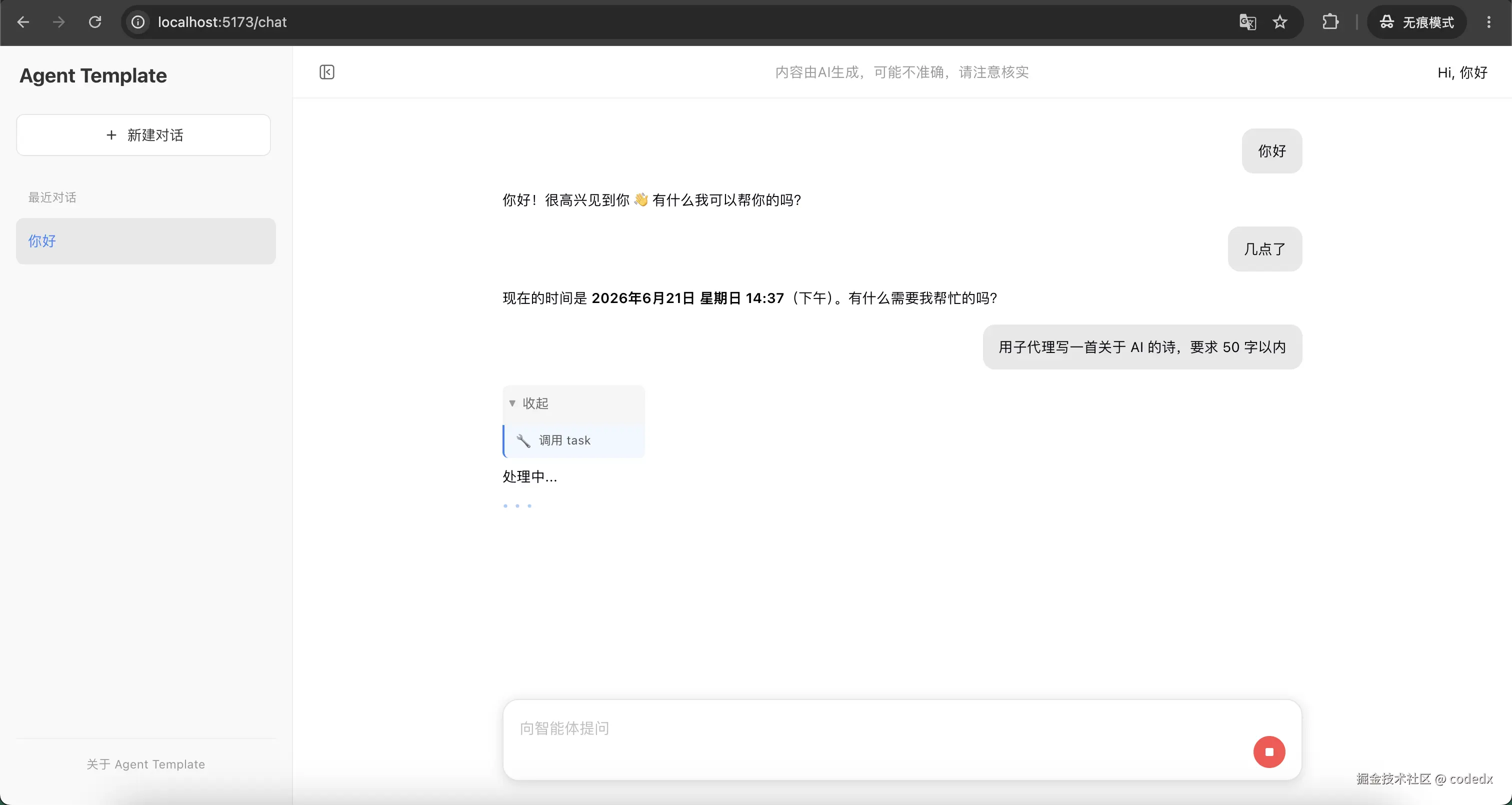
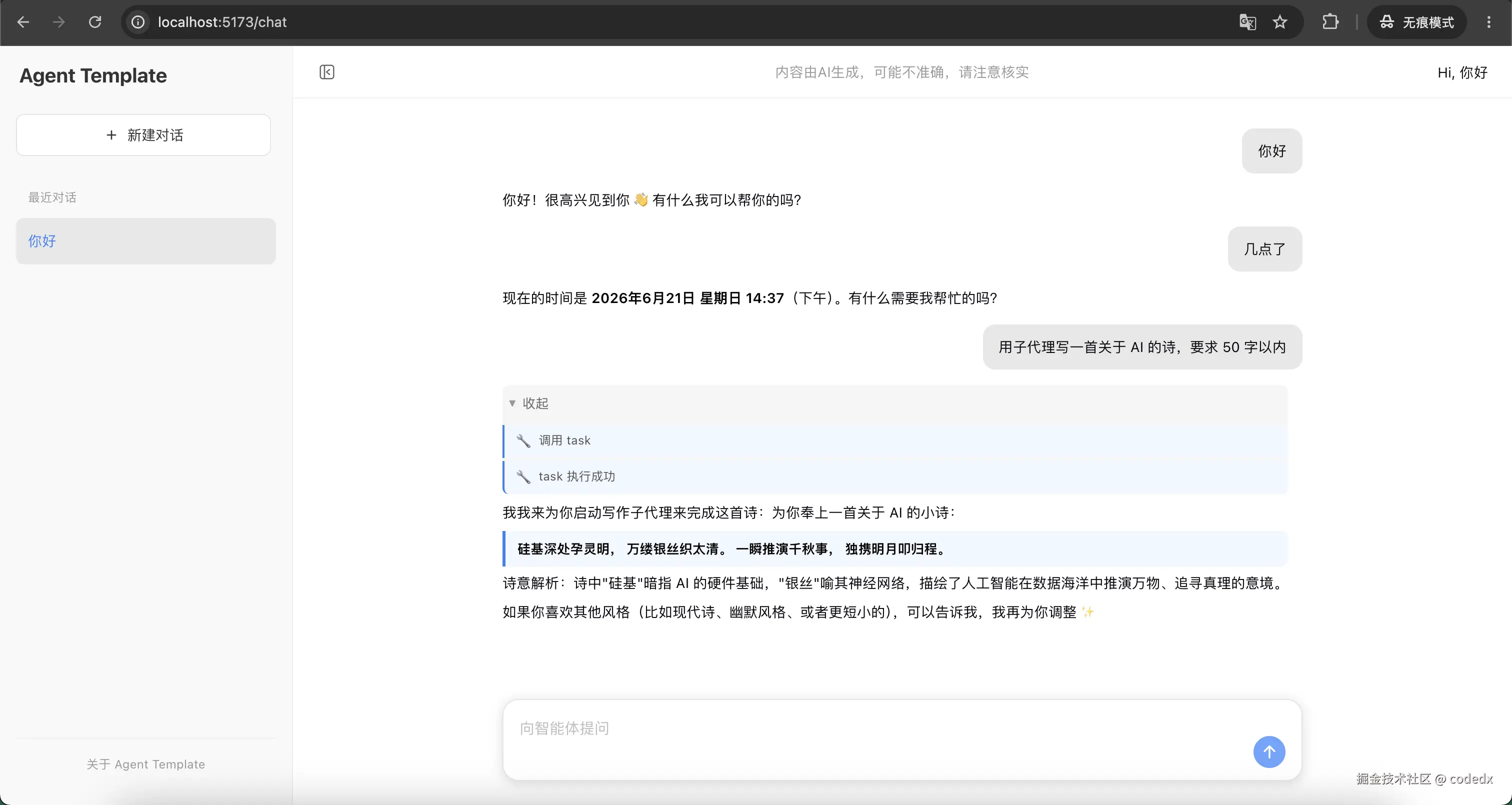
展示 Agent 工具调用完成后的结果。task 执行成功,并返回生成的诗和解释内容:
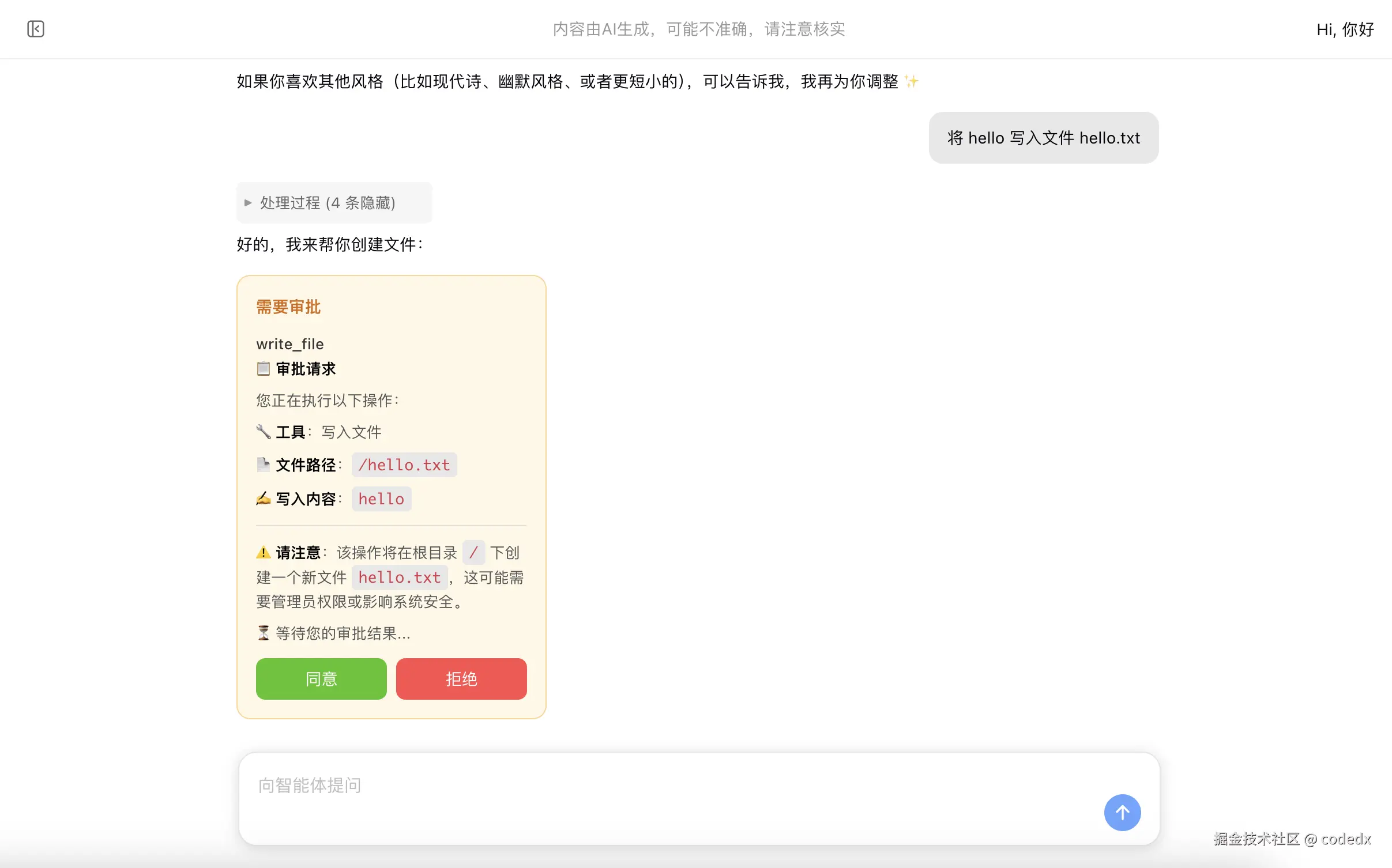
人工审批
展示 HITL 人工审批流程中的写文件审批:
展示另一种 HITL 审批场景。Agent 需要读取文件时触发审批:
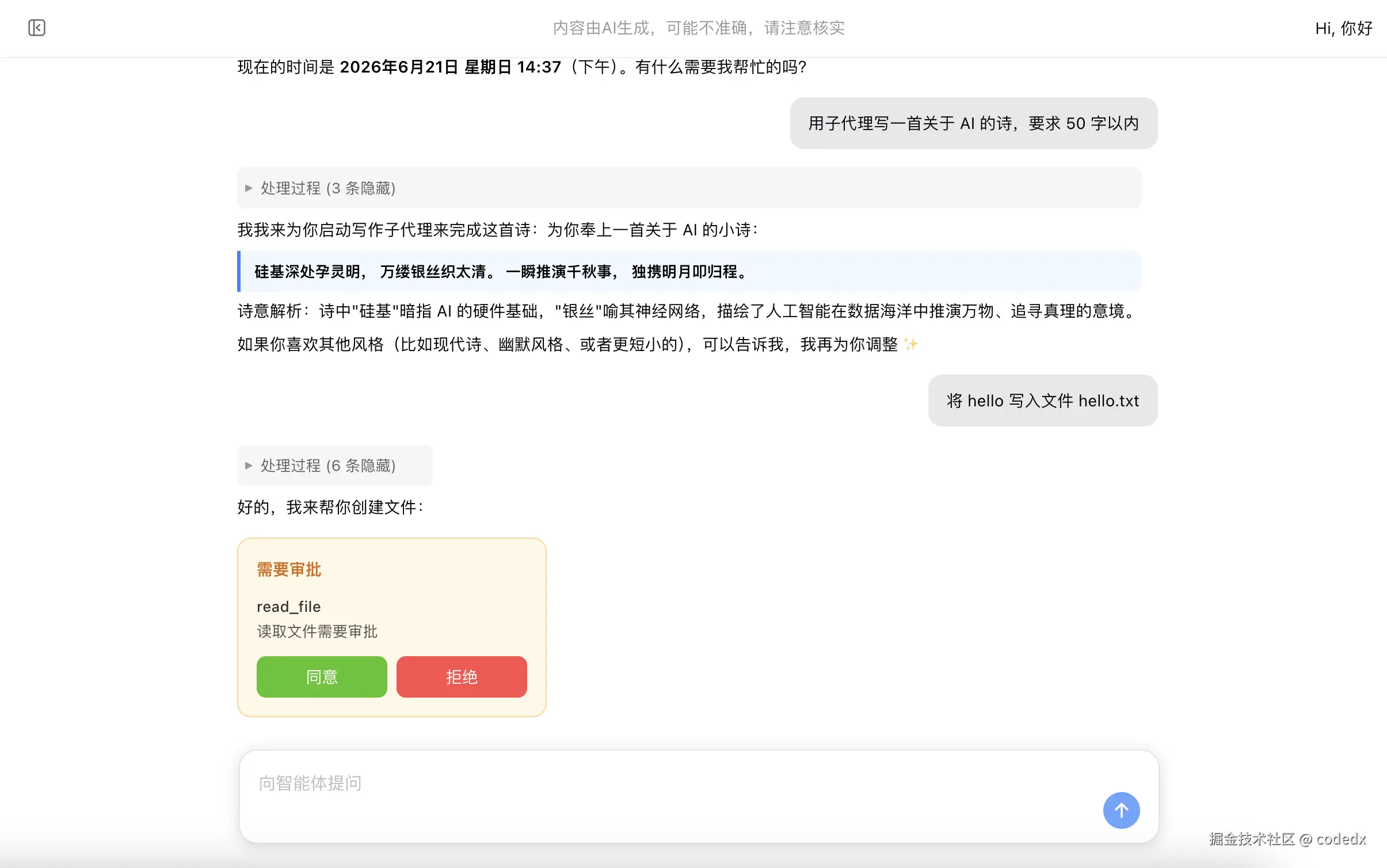
展示审批通过后的完整执行结果:
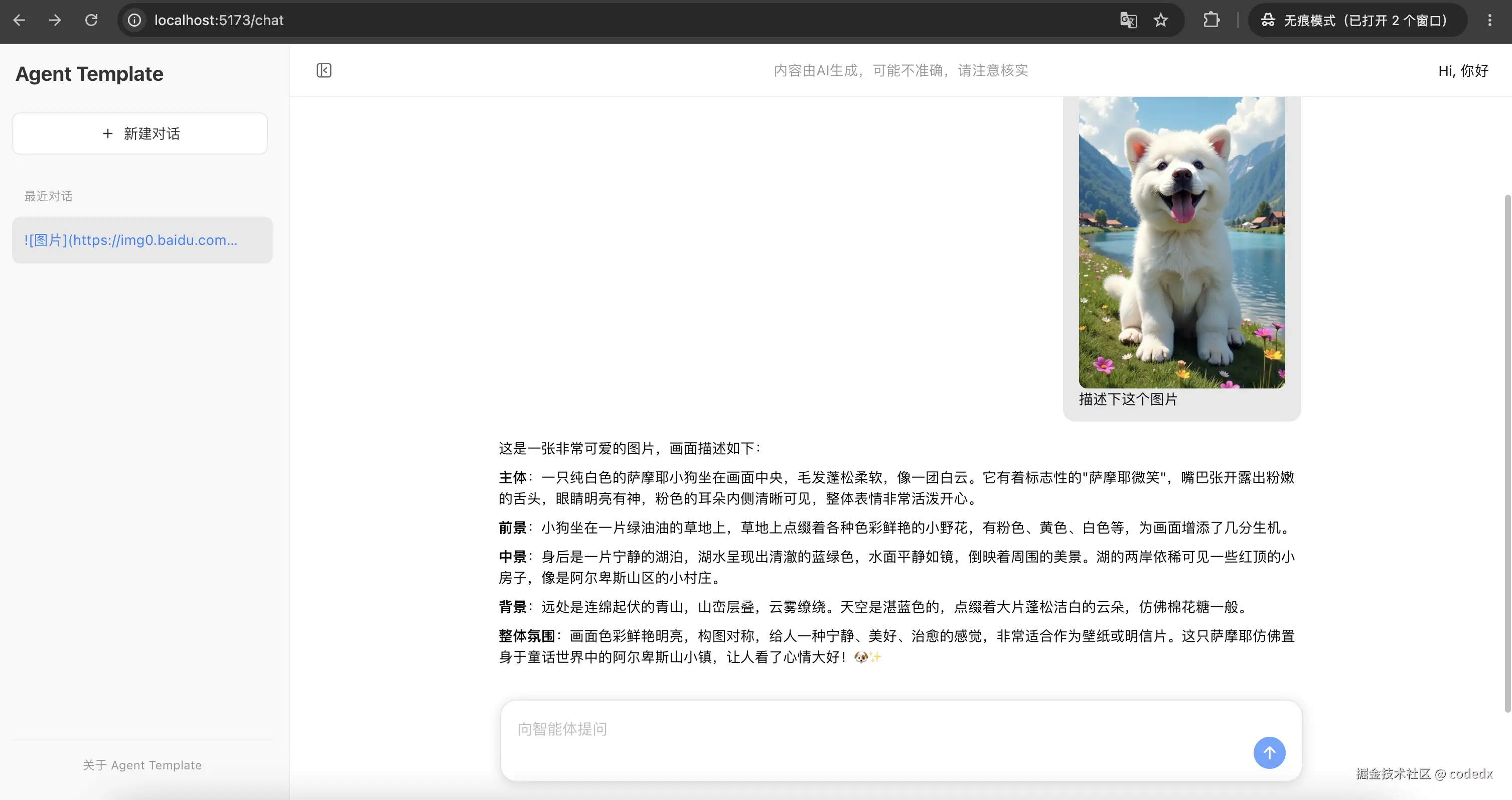
图片理解
展示图片输入的多模态理解功能。用户发送一张小狗图片并要求描述,Agent 对图片主体、前景、中景、背景和整体氛围进行文字分析:
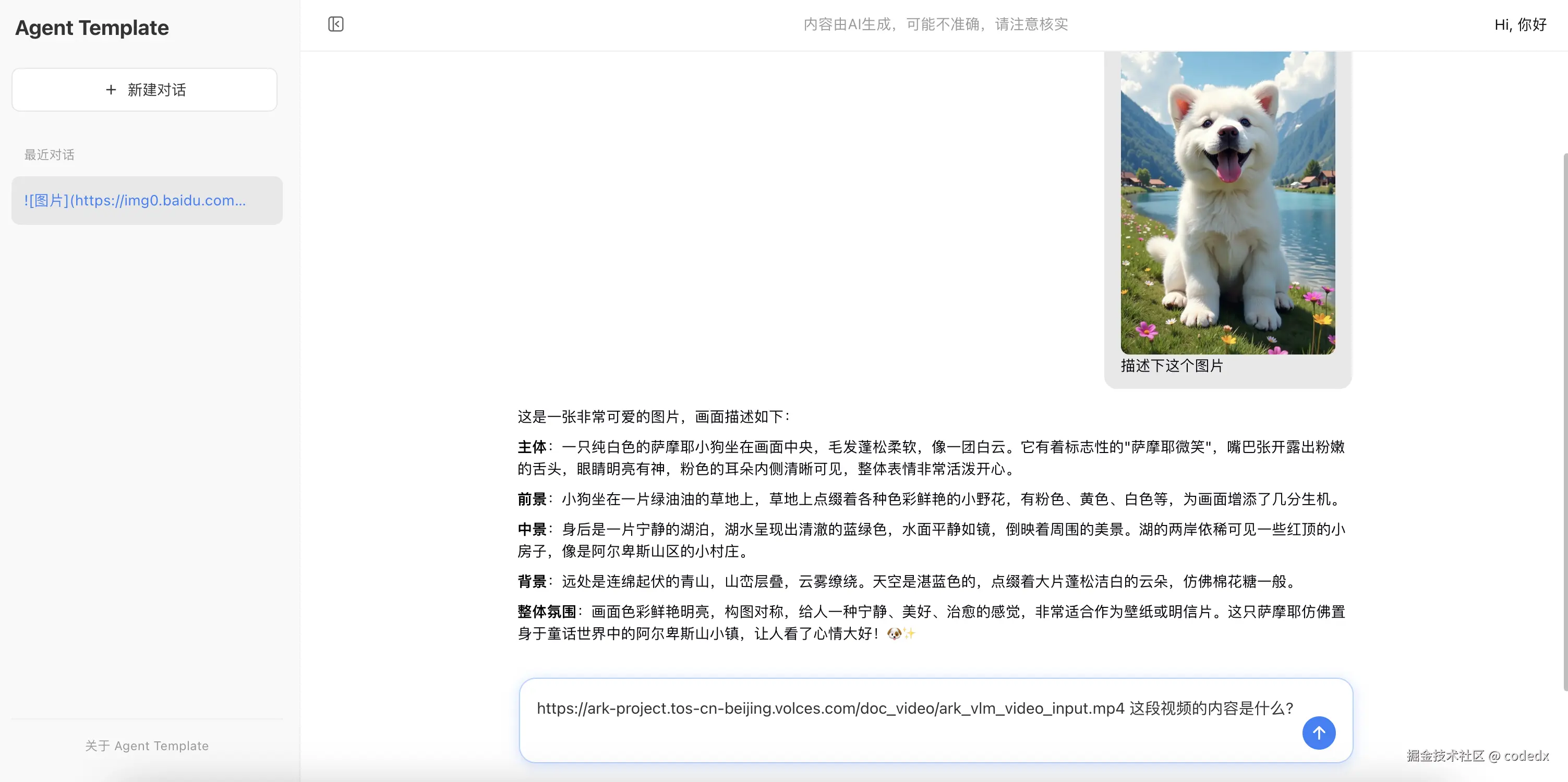
视频理解
展示视频 URL 输入准备状态。在输入框中输入视频链接,并询问"这段视频的内容是什么":
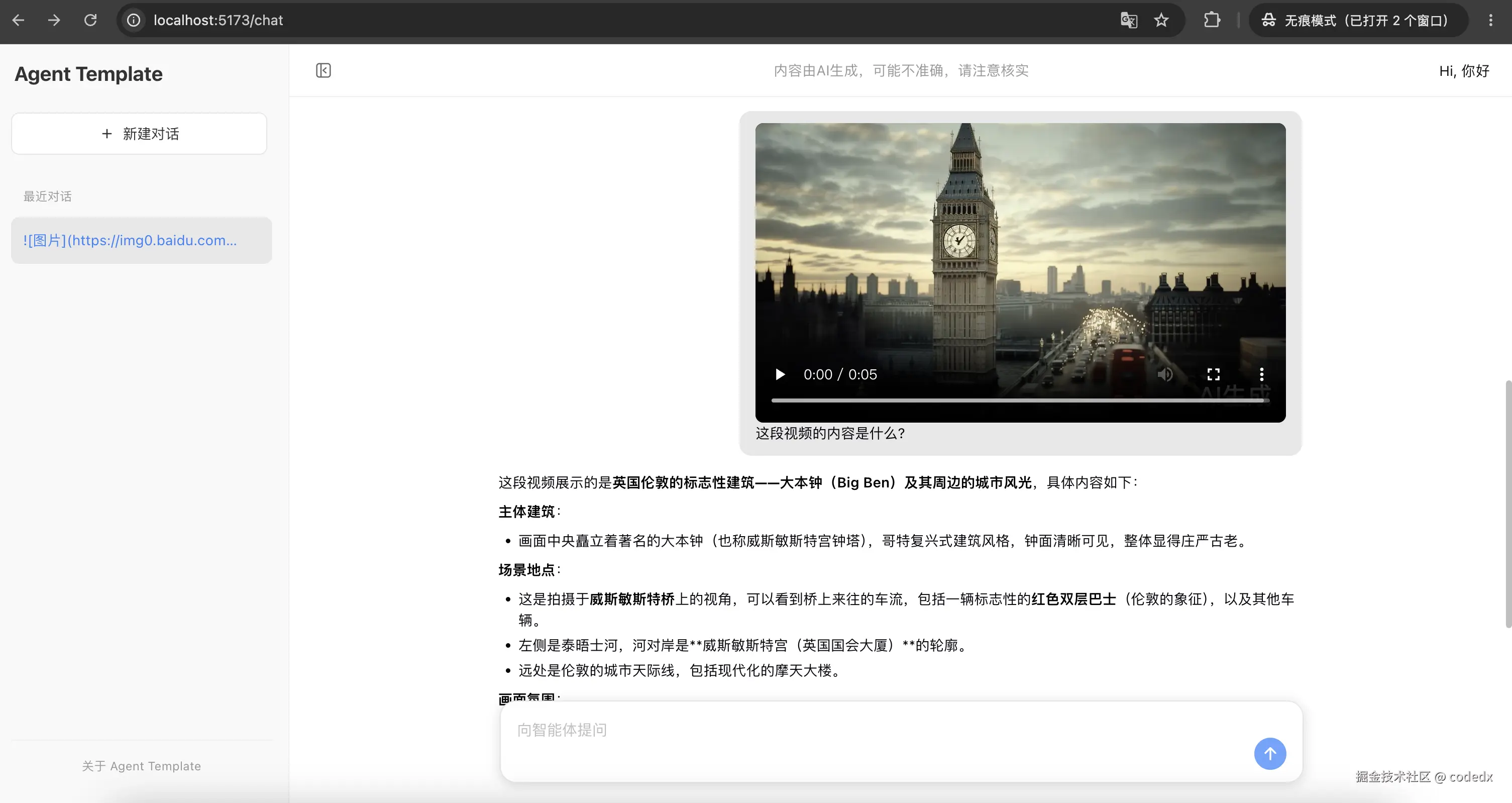
展示视频输入的视频理解结果。界面渲染视频播放器,Agent 分析视频内容,描述视频中伦敦大本钟、城市街景和场景细节:
视频演示
视频不方便放在文章内容中,烦请点击跳转观看。