我之前一直以为,那些能查天气、算实时价格的 AI 聊天机器人,是大模型自己在背后偷偷发 HTTP 请求、连数据库。直到这周我啃工具调用,对着一段跑不通的代码卡了快半小时,才发现我从根上理解错了。
先说说我最开始的离谱误解
我最开始写 Demo 的时候,想法特别天真:不就是传个 tools 配置进去吗,大模型拿到问题,自己调用函数,直接把答案返回给我不就完了。结果第一次跑完接口,我打印返回的 message 对象,当场就懵了。content 字段是空的,反而多了个从没见过的 tool_calls 数组,里面有 id、有函数名、还有一串 JSON 格式的参数。我心想这啥啊?我要的苹果 15 价格呢?怎么给我返回了段看不懂的结构?
后来我翻了文档,又对着输出琢磨了半天,才突然反应过来一件事 ------ 我们天天挂在嘴边的大模型,本质上就是个困在服务器里的「缸中大脑」。它除了坐在那预测下一个词的概率,啥都干不了。它看不见外面的世界,摸不到数据库,也发不了真实的 HTTP 请求。你问它今天上海多少度,问它苹果 15 卖多少钱,它训练数据里的信息早就过时了,硬答就是一本正经地胡说八道。那它是怎么实现「调用工具」的?说穿了,全是演的。是我们开发者和大模型联手,给用户造的一个精致的错觉。
第一步:把工具翻译成大模型听得懂的话
要让一个只会接话的模型学会用工具,第一步不是给它权限,而是给它写说明书。就像你教一个从没见过微波炉的人用微波炉,你不能甩给他一本电路原理图,你得用大白话讲:「这东西叫微波炉,你告诉它要加热什么、加热几分钟,它就能帮你把饭弄热。」
落到代码上,就是我们写的那段 tools 配置。
javascript
const tools = [
{
type: 'function',
function: {
name: 'get_closing_price',
description: '获取指定商品的实时售卖价格',
parameters: {
type: 'object',
properties: {
name: {
type: 'string',
description: '商品的名称',
},
},
required: ['name'],
}
},
},
{
type: 'function',
function: {
name: 'get_weather',
description: '获取指定城市的实时天气情况',
parameters: {
type: 'object',
properties: {
city: {
type: 'string',
description: '城市的名称',
},
},
required: ['city'],
}
},
},
]这段 JSON Schema,根本不是给运行时代码看的,是完完全全写给大模型读的「使用说明书」。我们把一个复杂的业务函数,降维成了一段纯文本描述:有什么工具、叫什么名字、能干什么、要传什么参数、参数是什么类型、哪个参数必填。这个过程,说玄乎点叫「认知植入」------ 在对话开始前,就把工具的存在和用法,悄咪咪塞进了模型的上下文里。它不知道什么是 API,也不懂什么是函数调用,但它看得懂这段文字描述。
第二步:大模型的「自言自语」------ 意图识别
当用户问出「苹果 15 手机的价格是多少?」的时候,大模型内部大概是这么思考的:第一,我脑子里的知识答不了这个问题,说出来就是瞎编。第二,刚才有人给我塞了份工具说明书,里面有个叫 get_closing_price 的东西,好像就是干这个的。第三,按照说明书上的格式,我应该把参数填好,告诉外面的人去调用这个工具。
然后它就不会再继续跟用户对话了,它会中断输出,返回一段结构化的 tool_calls 内容。说白了,它不是在「调用工具」,它是在「生成一段调用工具的指令」,等着外面的人去执行。
我当时特意做了个测试,问它「你好」,它正常回问候;问它「上海天气怎么样」,它就返回调用天气工具的指令。整个判断过程完全是模型自己做的,我们只给了说明书,没写任何判断逻辑。说起来也挺神奇的,一个只会预测下一个词的模型,靠模式识别和推理能力,居然能精准匹配到对应的工具,还能把参数填对。

第三步:真正干活的,是你的 Runtime
指令生成了,谁来执行?当然是我们写的代码。大模型负责拍板「要不要调用、调用哪个、参数填啥」,真正跑函数、查数据库、发请求的,还是 Node、Python 这些传统运行时。
这也是我踩的第一个大坑。当时我拿到 tool_calls 之后,确实调用了 get_closing_price 函数拿到了价格,但我转头就把价格当成用户消息塞回了对话里,又调了一次大模型。结果你猜怎么着?大模型一脸懵,回了我一句「你说的 1000 是什么意思?」
这里是新手 90% 会踩的坑:工具执行完的结果,不能随便塞回对话。消息的 role 必须是 tool,并且必须带上对应的 tool_call_id,不然大模型对不上刚才自己发的调用指令,根本不知道这段数字是干嘛的。尤其是多工具并行调用的时候,没 id 根本对应不上。
正确的做法是,执行完工具之后,构造一条 role 为 tool 的消息,把结果放进去,同时带上这次调用的 id,再完整塞回 messages 数组里,二次调用大模型。这时候大模型看到对应的 tool 结果,就知道「哦,我刚才让调用的工具返回结果了」,然后它会把这段干巴巴的结果,组织成通顺的自然语言,再返回给用户。
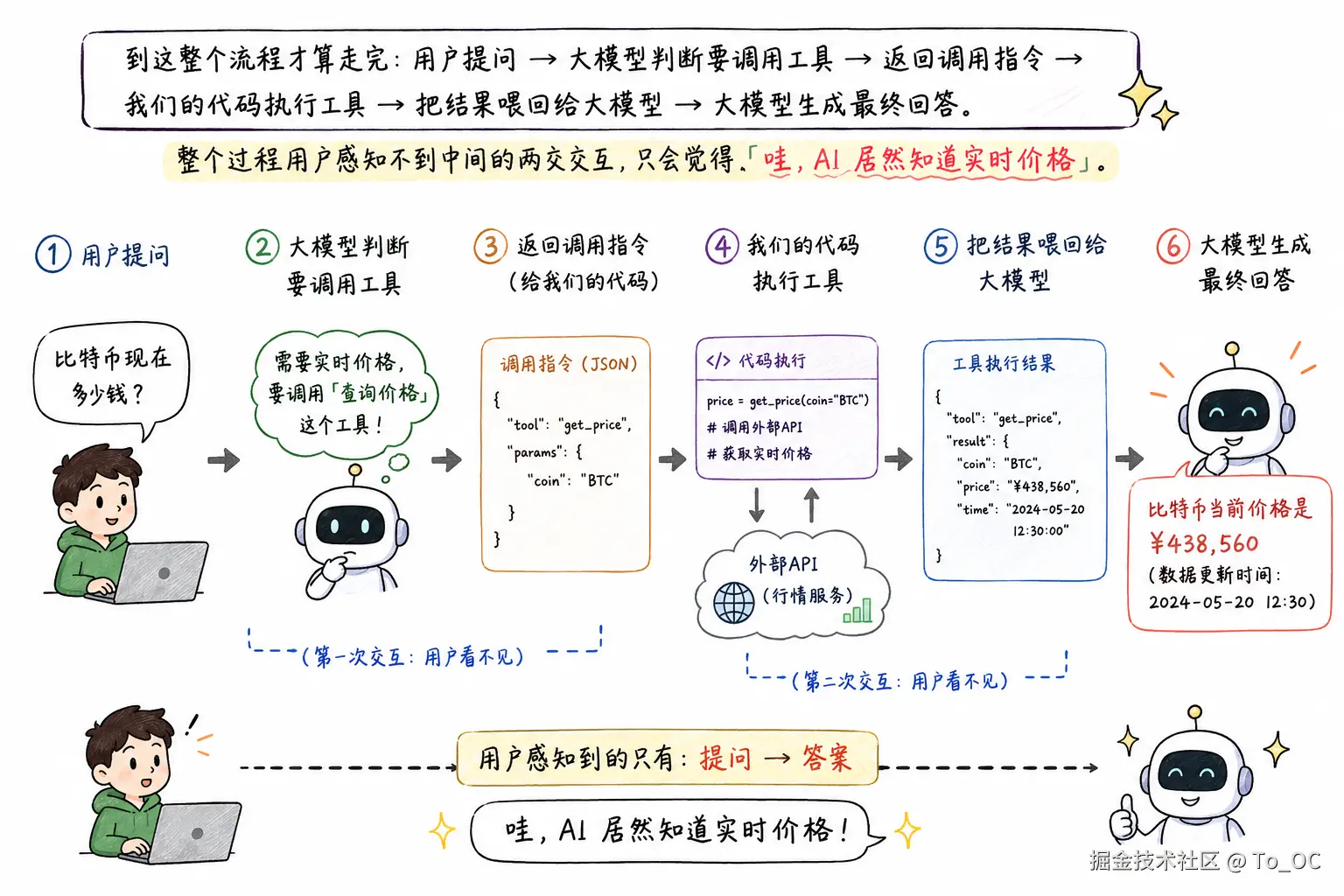
到这整个流程才算走完:用户提问 → 大模型判断要调用工具 → 返回调用指令 → 我们的代码执行工具 → 把结果喂回给大模型 → 大模型生成最终回答。整个过程用户感知不到中间的两次交互,只会觉得「哇,AI 居然知道实时价格」。
能直接跑的最小 Demo
我把当时跑通的最简代码贴在这里,用的是 DeepSeek 兼容 OpenAI 的接口,改下环境变量就能跑。
javascript
import OpenAI from 'openai';
import dotenv from 'dotenv';
dotenv.config();
// 缸中大脑:只会预测下一个词,啥实体操作都干不了
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: process.env.DEEPSEEK_API_BASE_URL,
});
// 给大模型看的工具说明书,写得越清楚越不容易乱调用
const tools = [
{
type: 'function',
function: {
name: 'get_closing_price',
description: '获取指定商品的实时售卖价格',
parameters: {
type: 'object',
properties: {
name: {
type: 'string',
description: '商品的名称',
},
},
required: ['name'],
}
},
},
{
type: 'function',
function: {
name: 'get_weather',
description: '获取指定城市的实时天气情况',
parameters: {
type: 'object',
properties: {
city: {
type: 'string',
description: '城市的名称',
},
},
required: ['city'],
}
},
},
]
// 真正执行逻辑的传统代码,精确、稳定、不会瞎编
function get_closing_price(name) {
if (name.includes('苹果15')) return '1000';
if (name.includes('小米15')) return '5000';
return '商品不存在';
}
// 封装一次大模型调用
async function sendMessage(message) {
const completion = await client.chat.completions.create({
model: process.env.DEEPSEEK_API_MODEL,
messages: message,
tools: tools,
tool_choice: 'auto',
});
return completion;
}
async function main() {
let messages = [
{
role: 'user',
content: '苹果15手机的价格是多少?',
}
]
// 第一次调用:问模型要不要用工具
const res = await sendMessage(messages);
const message = res.choices[0].message;
console.log("大模型第一次返回:", JSON.stringify(message));
// 把模型的回复塞回上下文,包括 tool_calls
messages.push(message);
if(message.tool_calls) {
const toolCall = message.tool_calls[0];
if(toolCall.function.name === 'get_closing_price') {
const args = JSON.parse(toolCall.function.arguments);
const price = get_closing_price(args.name);
console.log(`工具执行结果:${args.name} 价格是 ${price}`);
// 别问我为什么知道要加 id,试了三次才踩对
messages.push({
role: 'tool',
content: price,
tool_call_id: toolCall.id,
});
console.log('完整上下文:', JSON.stringify(messages));
// 第二次调用:把结果喂给模型,拿最终回答
const finalRes = await sendMessage(messages);
console.log('最终回答:', finalRes.choices[0].message.content);
}
}
}
main();跑出来的控制台输出大概是这样的:

我踩过的两个坑,你们别再踩
第一个坑就是刚才说的,tool 消息的 role 和 id 不对。别小看这个细节,我当时对着文档对了三遍才发现漏了 tool_call_id。之前一直以为只要把内容传回去就行,没想到大模型是靠 id 来匹配调用和结果的。
第二个坑,是工具的 description 写得太含糊。我最开始写 get_closing_price 的描述,只写了「获取商品价格」。结果我问「苹果 15 发布时间是什么时候」,它居然也去调用这个工具。后来我把描述改成「获取指定商品的实时售卖价格」,它就不会乱调用了。说白了,大模型是靠文字描述来判断工具用途的,你写得越模糊,它就越容易瞎猜。想让工具调用准,先把说明书写清楚。
最后说两句实在的
搞懂这整套流程之后,我最大的感受是,所谓的「AI 工具调用」,本质上是新旧两种编程范式的拼接。一边是大模型,擅长理解自然语言、做判断决策,但不可控、没法精确执行;另一边是传统代码,执行精确、稳定,但听不懂人话。我们用一段结构化的文本协议,把这俩东西接在了一起。大模型负责做选择题,传统代码负责做执行题,各司其职。现在火得一塌糊涂的 AI Agent,说白了就是在这套逻辑上叠了记忆、规划、多轮调用的能力,但底层的核心还是这套「大模型拍板、代码干活」的流程。
另外还有两个很实在的感悟:
第一,别神话工具调用。大模型不会真的「使用」工具,它只是按照我们给的说明书生成调用指令。真出了问题,背锅的还是写代码的我们。关键逻辑该加校验加校验,该兜底兜底,不能全信模型的判断。
第二,想让 Tool Call 好用,功夫在诗外。与其折腾模型参数,不如把工具的描述、参数的约束写得更清楚一点。这就像写接口文档,文档写得好,对接的人就少踩坑。对大模型也一样。
我当时跑通这段代码、想通整个逻辑的时候,有种豁然开朗的爽感。原来之前觉得很玄乎的工具调用,拆穿了就是这么回事。如果你之前也对工具调用稀里糊涂,建议自己亲手跑一遍这段代码,比看十篇文档都管用。有啥别的理解或者踩过的奇葩坑,评论区聊聊,我也长长见识。