就在昨天 OpenAI 发布了一个什么 GPT-5.5 的 instant 版本,我还以为 5.6 可能不会来了。
但是在 6 月 26 号这一天, GPT-5.6 终于发布了,这和网传的时间基本一致。
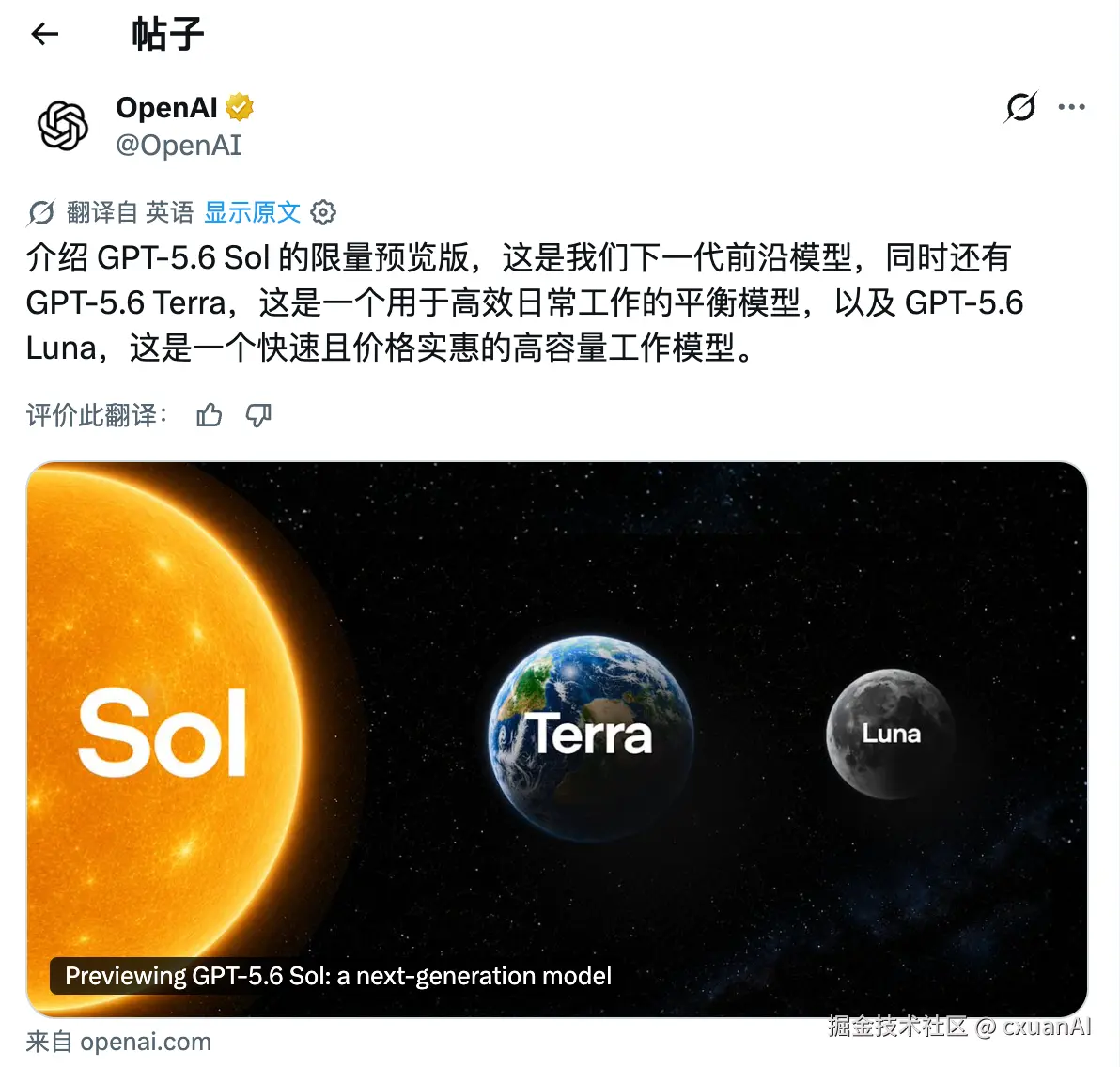
不过先说这个名字,Solo 、Terra 、Luna ,这命名方式怎么这么像 Claude Code 的 Haiku、Sonnet 和 Opus ???可千万别整这些虚的啊。
GPT 5.6 Sol 是一个限量预览版,这个模型目前是 OpenAI 最牛批的模型;GPT-5.6 Terra,这是一个比较平衡的模型; GPT-5.6 Luna,这是一个便宜快速,而且最耐用的模型。
GPT-5.6 是 OpenAI 最强大的模型了。GPT-5.6 加强了对高风险活动、敏感网络请求和重复滥用的保护,并且花费了大量时间查找漏洞、压力测试、使其能够抵御更多网络攻击。
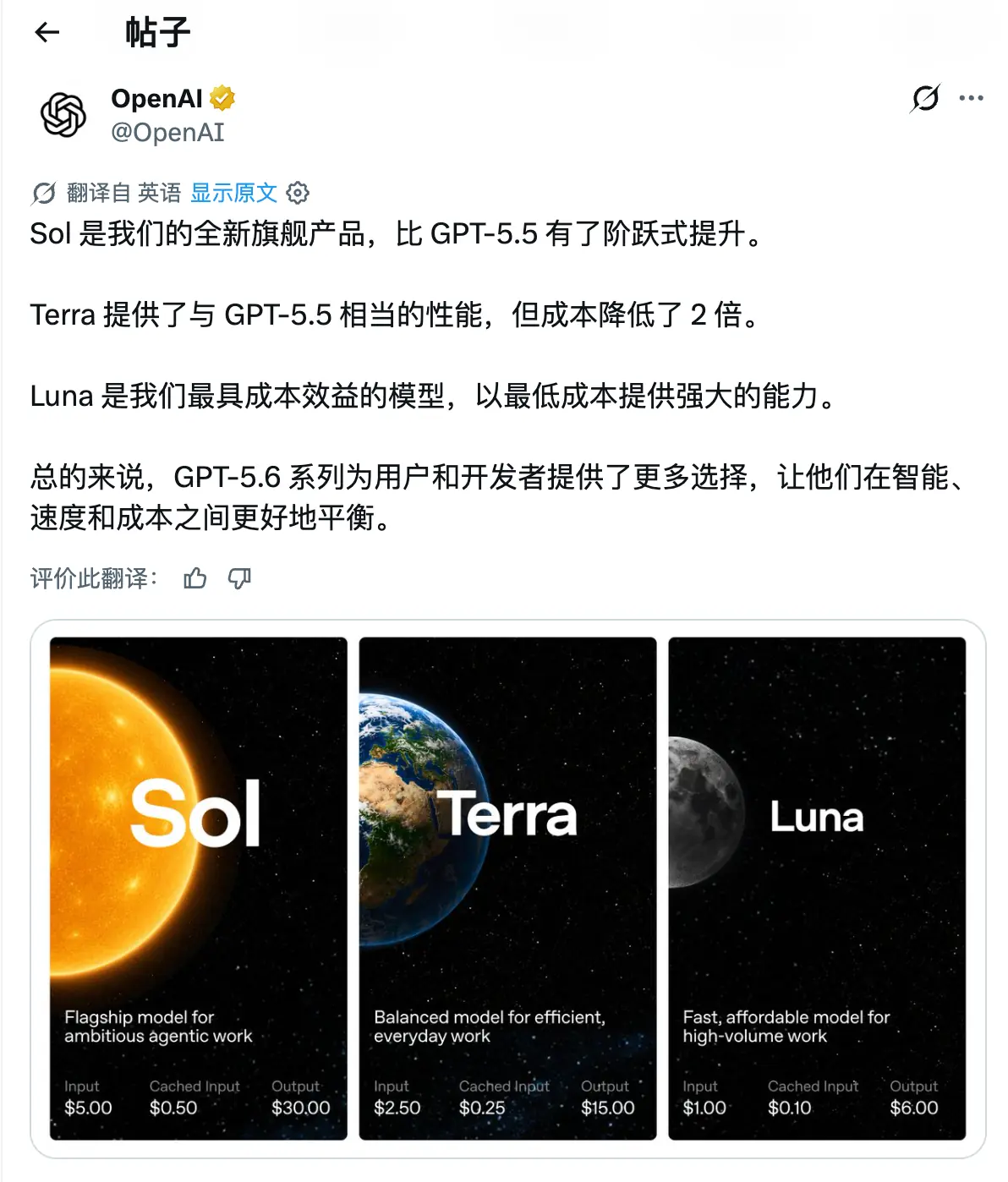
Terra 的性能与 GPT-5.5 相比性能基本差不多,但是价格便宜两倍;而且官方说 Luna 的能力仅次于 GPT-5.5 ,但是却以低成本提供了强大的功能。
这句话不用说,Terra 相当于就是 GPT-5.5 的便宜版,而 Luna 不如 5.5 ,但是胜在更便宜。
一句话区分:Sol 看智力上限,Terra 看日常性价比,Luna 看吞吐和成本。
(咱就是说,这个叫 Luna 的模型,为什么非得和币圈某个割韭菜的著名 Luna 币重名呢,其实挺晦气的。。。)
不过目前,由于政策的问题,现在还无法大范围普及给大家使用,但是大家可以先看一下模型能力。
OpenAI 这次没有把所有评测一口气全放出来。原文说,完整评测会等更广泛开放时再发。
但它先放了三个方向:编码、生物、网络安全。
在编码上,GPT-5.6 Sol 在 TerminalBench 2.1 上刷新了 OpenAI 自己给出的表现。这个 benchmark 测的是命令行工作流,需要规划、迭代和工具协调能力。
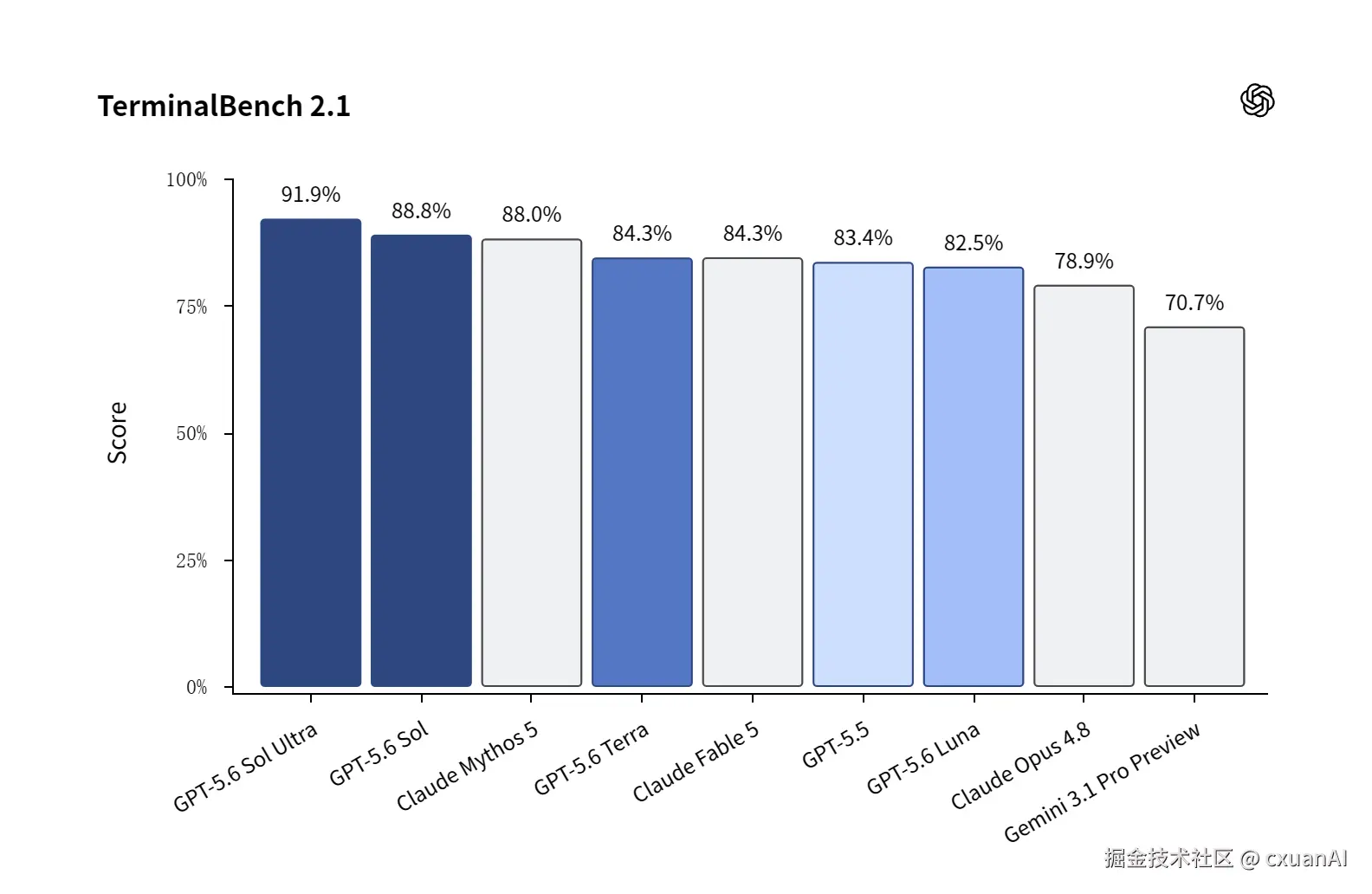
在 TerminalBench 2.1 上 ,GPT-5.6 的两个 effort 档位都把 Mythos 5 给超了,而 Terra 这个具备性价比的版本,竟然还把 Fable 5 给超了。
GPT-5.6 新增了两个能力入口:max reasoning effort 和 ultra mode。
max 的意思是给 Sol 更多时间深度推理。
ultra 更像是让模型调用子 agent,把复杂任务拆给多个子任务一起跑。
OpenAI 的表述是,它超出了单个 agent 的能力边界。
生物方向,OpenAI 提到 GeneBench v1。它用来评估长周期基因组学和定量生物分析任务。
OpenAI 的说法是,GPT-5.6 Sol 比 GPT-5.5 更强,而且用的 token 更少。
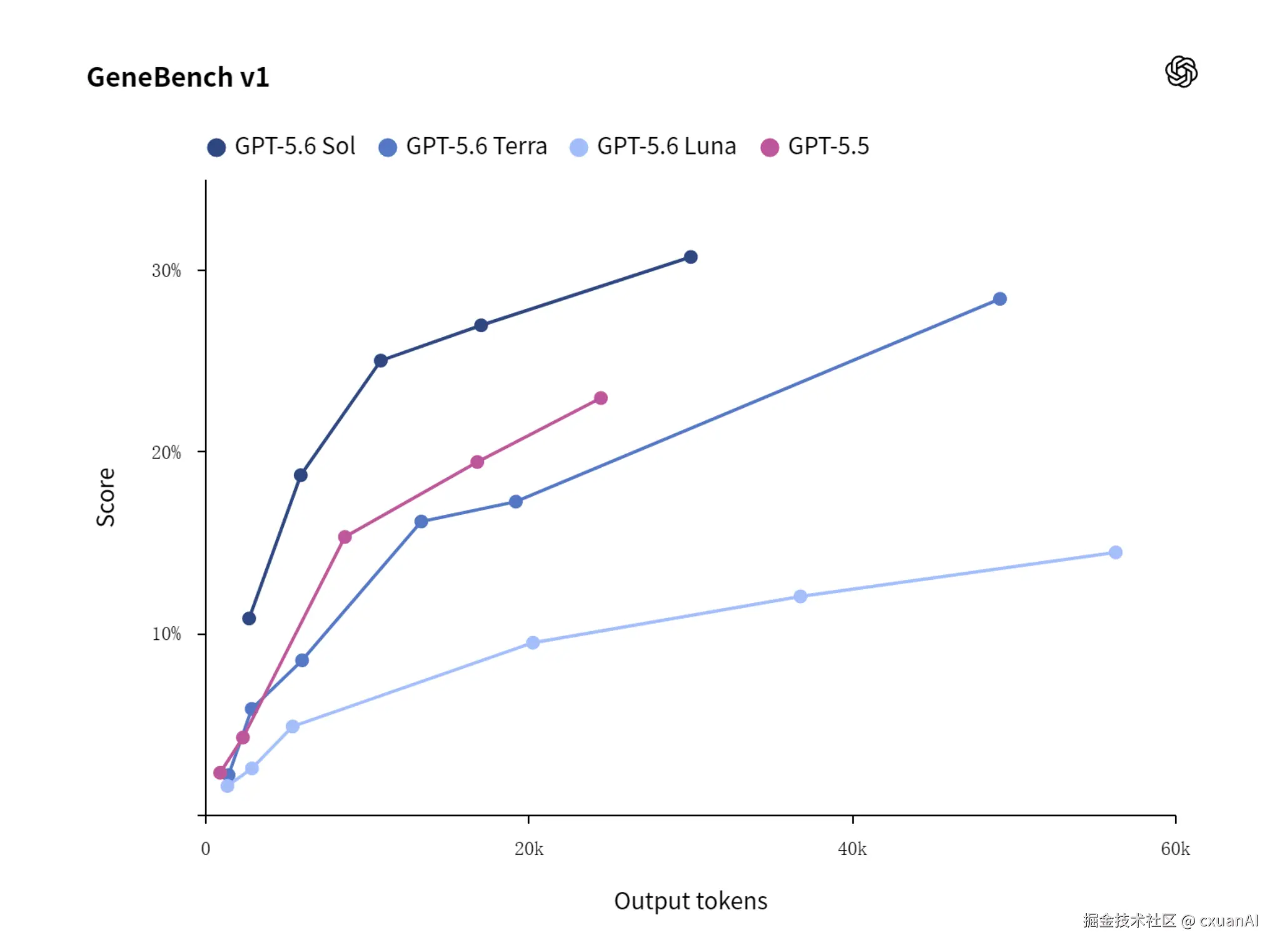
网络安全方向说的就更直白了。
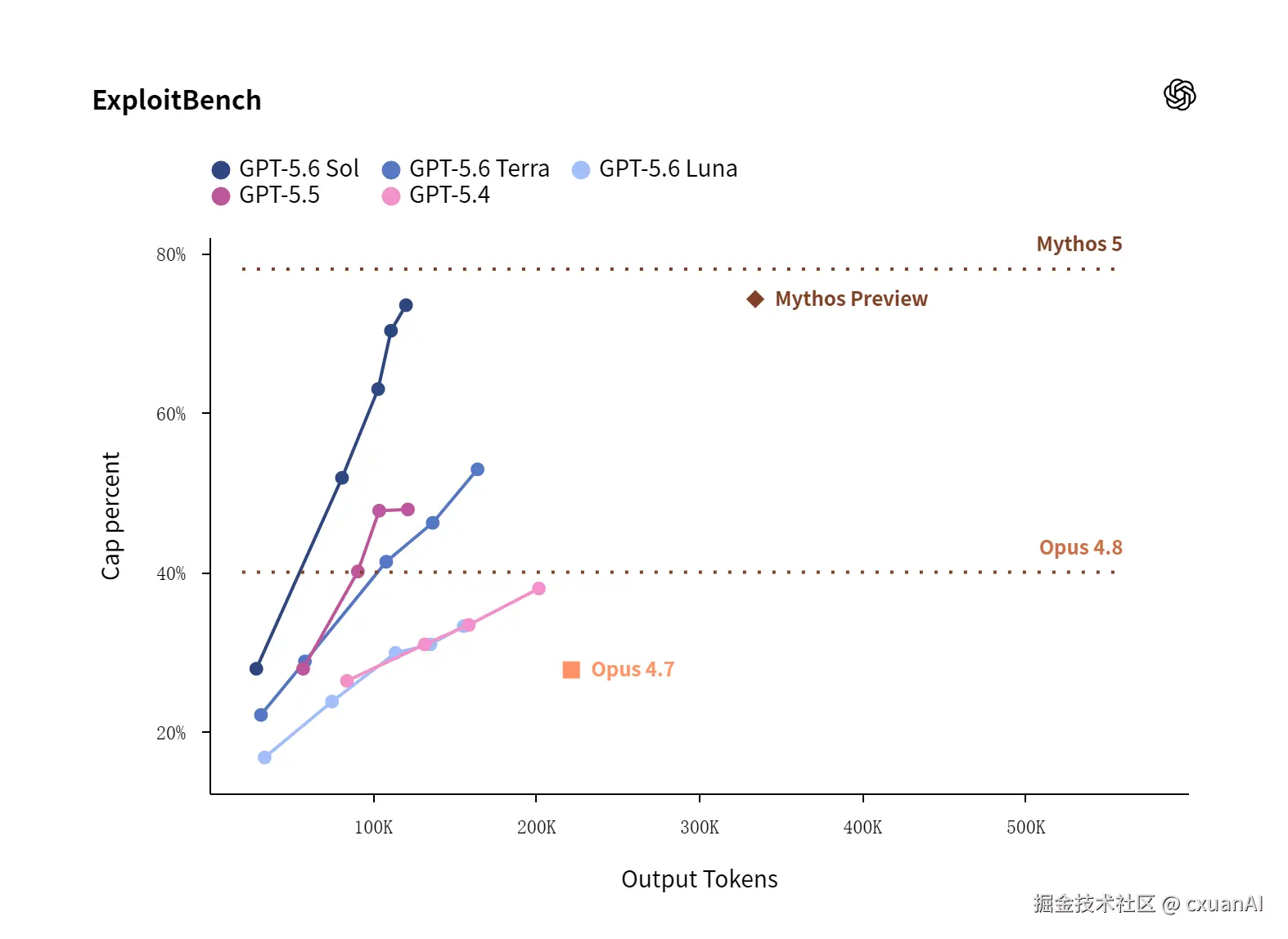
OpenAI 说,GPT-5.6 Sol 是他们目前网络安全能力最强的模型。它在漏洞研究和利用这类长周期安全任务上,在性能和效率上都有长足的进步。
而在 ExploitBench 这份测评榜单上,GPT-5.6 Sol 用了大约 1/3 的 token,就接近了 Mythos Preview 的水平。
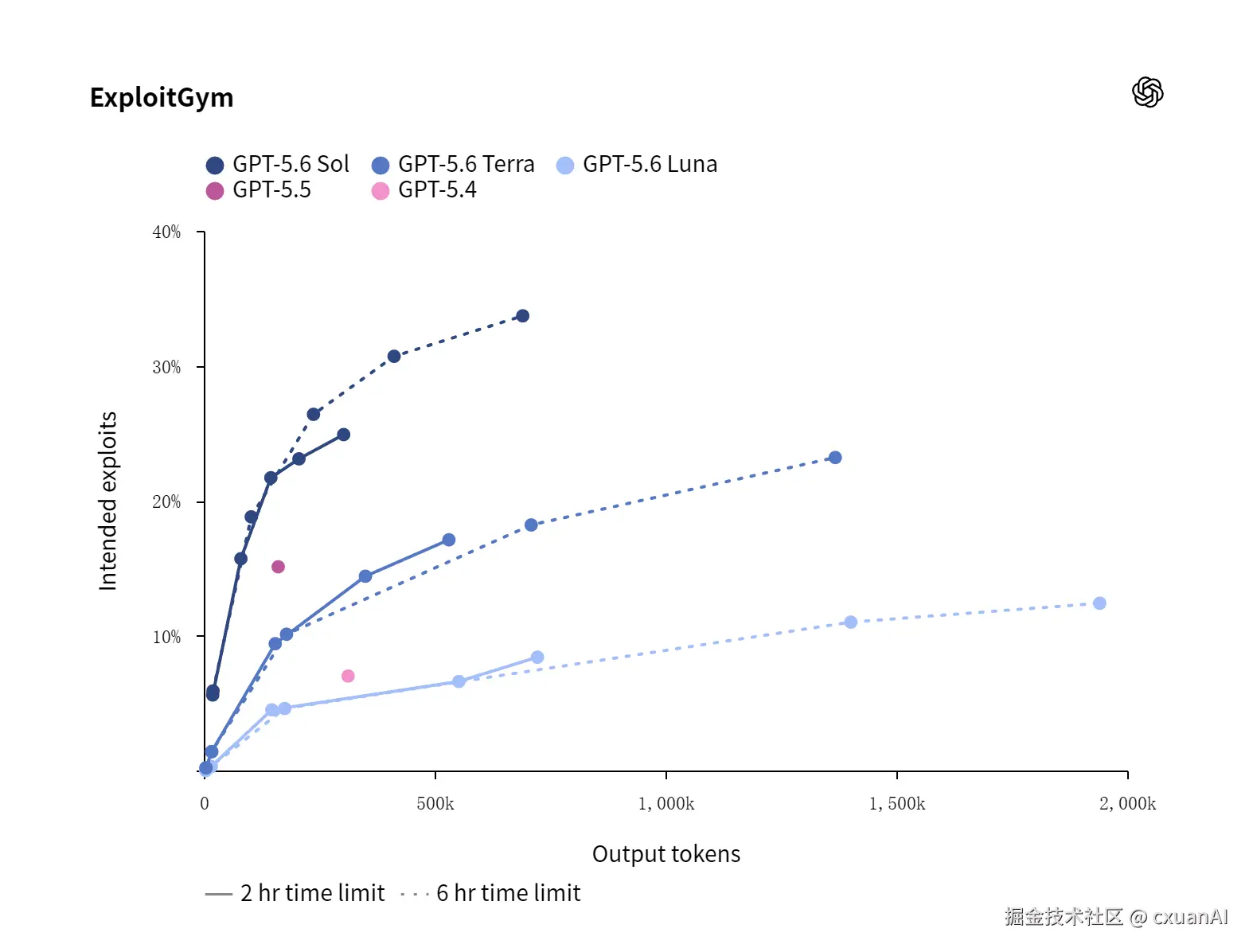
在 ExploitGym 上,Sol、Terra、Luna 随着推理的增强,均都展现出明显的网络安全能力提升。
这地方要跟大家说清楚。
原文和 system card 里都强调,Sol 主要是应对网络攻击,能够帮助网络防御者使用更合适的工具发现攻击漏洞,开发补丁,加强系统保护。
(不知道这个 GPT-5.6 和之前发布的 Daybreak 有什么区别,有可能或许就是同一个模型么。)
但在 Chromium 和 Firefox 的测试条件下,它并没有产出可自主运行的完整攻击链。按 OpenAI 当前框架设定,它还没过 Cyber Critical 的阈值。
但能力已经强到必须分阶段发布了。
OpenAI 这次发布反复在强调网络安全栈这个层面。OpenAI 说单靠某一种安全措施,挡不住有明确越狱目标、而且还会不断换方法的攻击者。
所以他们采用了多层的安全措施。不同模型具体配置不一样,而且他们针对现实世界的攻击做了压力测试。
这些措施包括:模型训练内置的保护机制、生成过程中的实时检查、账户级信号、差异化访问控制、监控、强制执行以及持续测试。
GPT-5.6 被训练为要拒绝、或者禁止提供网络安全协助,尤其是用户伪装意图、尝试模型越狱时。这个层面的保障确定了模型的安全范围边界,能帮什么,不能帮什么,都要有明确的边界限定。
大模型在生成过程中还有实时的网络安全监控和生物滥用分类器。如果判断风险高,大模型生成可能会暂停,再让更大的 reasoning model 审查整段对话和上下文。如果输出被模型评估为风险操作,则会被拦截。
你以为这就完了吗,并不会,你触发了模型风险评估之后,你很有可能被标记,被标记了之后还会触发对相关对话和风险信号的账户级审查。
也就是说,系统不仅只看你这一轮问了什么,还会看相关对话和风险信号,判断你是在做合理使用,还是持续尝试恶意使用。
估计大家关心的都是价格问题:
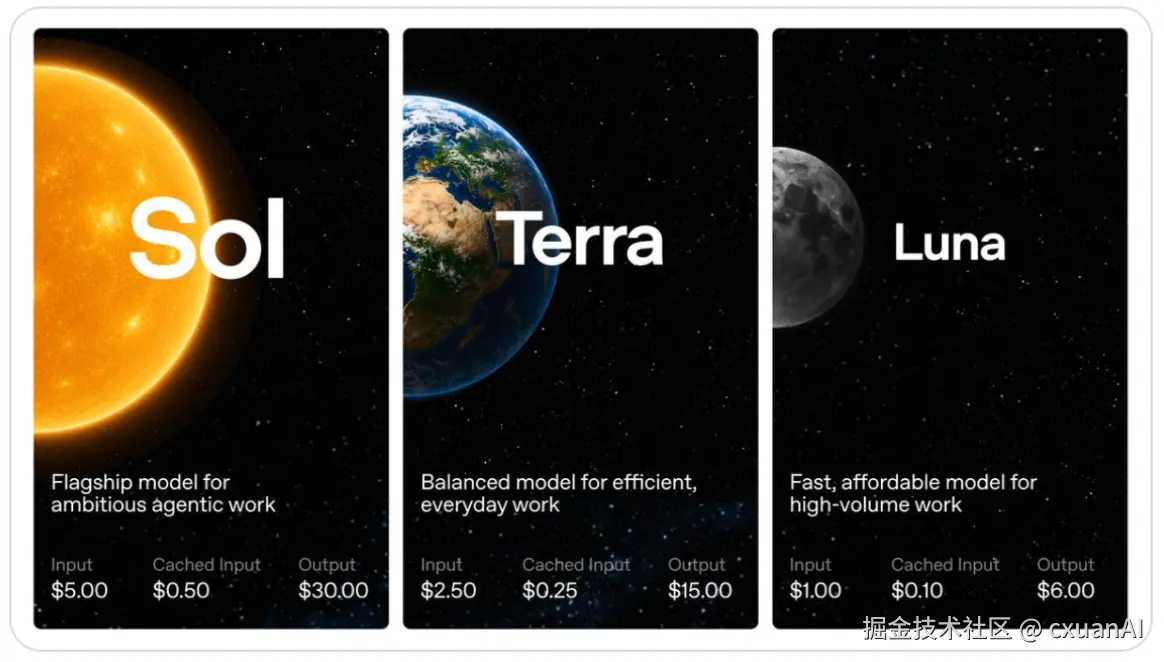
GPT-5.6 按每 100 万 token 计价:
Sol:输入 5 美元,缓存 0.5 美元,输出 30 美元。
Terra:输入 2.50 美元,缓存 0.25 美元,输出 15 美元。
Luna:输入 1 美元,缓存 0.1 美元,输出 6 美元。
另外,GPT-5.6 引入了更可预测的 prompt caching,支持显式的 cache breakpoint,缓存最短生命周期为 30 分钟。
cache write 按未缓存输入价格的 1.25 倍计费,而 cache read 继续享受 90% 的缓存输入折扣。
我是 cxuan,一个长期折腾 AI 工具和 Agent 工作流的人。更多真实使用记录、踩坑复盘和工具整理,可以在微信搜索公众号「cxuanAI」。
参考链接:
- OpenAI: Previewing GPT-5.6 Sol: a next-generation model
- OpenAI Deployment Safety Hub: GPT-5.6 Preview System Card
- arXiv: ExploitGym