SkillOpt 把 Skill 维护变成可验证训练:采样、反思、受限编辑、门禁筛选。 原文链接 :AI 小老六
很多 Agent 项目的瓶颈,最后都会落到一份文本上。
这份文本可能叫 SKILL.md,也可能是工具调用说明、流程手册、输出规范、故障补救规则。它不参与模型训练,却会持续改变 Agent 的判断路径。问题在于,我们通常把它当文档维护:专家凭经验写一版,线上出问题再补几句,偶尔让模型帮忙重写。这个过程很快会失控,因为没人能说清楚哪条规则真的改善了任务表现,哪次改动只是看起来更合理。
SkillOpt 试图把这个问题改成一个更工程化的命题:如果模型权重被冻结,能不能把 Skill 文本本身当作可优化对象,用真实任务轨迹来训练它?
答案是可以,但前提不是让模型随意重写整份文档,而是给 Skill 建一套类似训练循环的机制:采样执行、轨迹反思、受限编辑、验证门禁和版本沉淀 。最终产物不是一个新模型,而是一份经过多轮筛选的 best_skill.md。
Skill 文本为什么需要训练闭环
手写 Skill 的问题不在于人写得不够好,而在于它缺少反馈纪律。一个 Agent 出错后,维护者看到的通常是单个 case:这次没查对资料、那次输出格式错了、某个工具调用顺序反了。把这些现象直接补进文档,很容易得到一份越来越长、越来越碎的说明书。
SkillOpt 的关键判断是:Skill 应该根据一批任务的共同失败模式更新,而不是根据某次事故临场补丁。
它把 Skill 放进真实执行环境里,让目标 Agent 带着当前版本去跑任务,记录答案、工具调用、观察结果和评分。优化器不再凭空"改 Prompt",而是从这些 rollout evidence 里找稳定信号:哪些错误重复出现,哪些成功路径可以固化,哪些规则没有被 Agent 执行。
| 维护方式 | 常见做法 | 主要风险 |
|---|---|---|
| 人工手写 Skill | 专家先写流程,再靠线上经验补充 | 规则来源分散,难判断是否有效 |
| 一次性生成 Skill | 让模型根据需求直接产出完整说明 | 结构漂亮,但没有经过任务验证 |
| 松散 self-revision | 模型读失败样本后整篇重写 | 容易覆盖原本有效的约束 |
| SkillOpt 式优化 | 当前 Skill 跑任务,再基于轨迹做小步编辑 | 成本更高,但每次改动有验证门禁 |
这里最重要的变化是评价对象变了。Skill 不再只是"读起来是否完整",而是"它是否让冻结模型在任务集上做得更好"。
Textual Parameter:把 Skill 当作可编辑参数
SkillOpt 里有一个很有意思的类比:深度学习改的是模型参数,SkillOpt 改的是自然语言 Skill。两者当然不是一回事,但这个类比能帮助我们理解它为什么强调小步、验证和回滚 。 
图:目标模型冻结不动,Skill 文本作为受控状态被小步更新
这张图表达的不是"文本也能反向传播",而是 Skill 文本可以被当作受控状态来更新。目标模型 f 冻结不动,输入任务 x 和 Skill S 一起进入 Agent,得到输出 y。优化器看到轨迹和评分后,只能提出有限的文本编辑。候选版本必须通过验证集,才有资格替换当前 Skill。
| 模型训练概念 | SkillOpt 中的对应物 |
|---|---|
| parameter | Skill 文档里的自然语言规则 |
| gradient direction | 从执行轨迹推导出的修改方向 |
| learning rate | 每轮允许修改的编辑预算 |
| validation check | 独立 selection split 上的门禁 |
| stable training | 批量采样、缓冲区、长期指导和版本筛选 |
这个设计避免了一个常见坑:模型看到失败案例后,很容易写出一段"听起来更全面"的新规则,但这段规则可能让其他任务变差。SkillOpt 不接受这种凭感觉的改进。候选 Skill 必须在 held-out selection split 上严格变好,持平都不算通过。
Rollout Evidence:先让 Agent 暴露真实错误
SkillOpt 的第一步不是写建议,而是执行。
目标 Agent 带着当前 Skill 跑一批任务,系统记录输入、推理轨迹、工具调用、观察结果、最终答案和评分。这个过程相当于训练里的前向采样。它的价值不只是拿到分数,而是让优化器看到 Agent 实际是怎么偏离预期的。
单个失败样本很危险。它可能只是数据噪声、题目歧义或一次工具波动。如果优化器被单个案例牵着走,Skill 很快会变成事故备忘录。SkillOpt 采用 minibatch reflection,就是为了从一组轨迹里提炼更可迁移的规则。
常见的可迁移失败信号包括:
- Agent 总是先查不可靠来源,导致后续判断被污染。
- 任务完成后跳过验证,输出中混入格式错误或事实断层。
- 工具调用顺序长期颠倒,比如先写结论再补证据。
- 遇到不确定信息时直接猜测,没有进入补查或澄清流程。
- 输出模板满足表面结构,却漏掉关键字段。
这些信号比"某个 case 错了"更适合写进 Skill。因为它们指向的是行为模式,而不是一次性补丁。 
图:优化器需要从一批轨迹里提炼可迁移的行为规则
Patch Optimizer:只允许小步编辑
优化器看到 rollout 后,不是自由发挥写一篇新 Skill,而是输出结构化 patch。论文和实现里都强调 add / delete / replace 这类受控编辑,因为 Skill 最怕大面积重写。
一个典型 patch 可以长这样:
json
{
"reasoning": "why these edits address common failures",
"edits": [
{
"op": "append",
"content": "<markdown>"
},
{
"op": "insert_after",
"target": "<exact heading/text>",
"content": "<markdown>"
},
{
"op": "replace",
"target": "<exact text>",
"content": "<replacement>"
},
{
"op": "delete",
"target": "<exact text>"
}
]
}这段结构看起来朴素,但里面有几个工程约束很硬:
target必须命中当前 Skill 的精确文本,否则替换和删除不能执行。- 每轮编辑数量受 textual learning rate 控制,避免一次改动过大。
- 普通 step 级编辑不应该触碰受保护区域,比如长期指导或附录。
- append 和 insert 需要有明确落点,不能把规则堆到文档末尾就算完成。
受限编辑的收益在于可审计。你能知道这次到底加了什么、删了什么、为什么加、验证集是否因此变好。整篇重写也许短期看更顺,但它会掩盖因果关系:到底是哪条规则改善了任务?哪条又带来了回退?没人说得清。
Selection Gate:没有验证提升就拒绝
SkillOpt 和普通 Prompt 迭代最大的分界线,是 selection gate。
候选 Skill 生成后,系统会拿它去跑独立验证集。如果分数严格高于当前版本,编辑被接受;如果只是持平,或者某些任务变差导致总分没有提升,编辑会被拒绝。被拒绝不是简单丢掉,相关失败模式和 rejected edits 会进入后续反思上下文,提醒优化器不要重复走这条路。 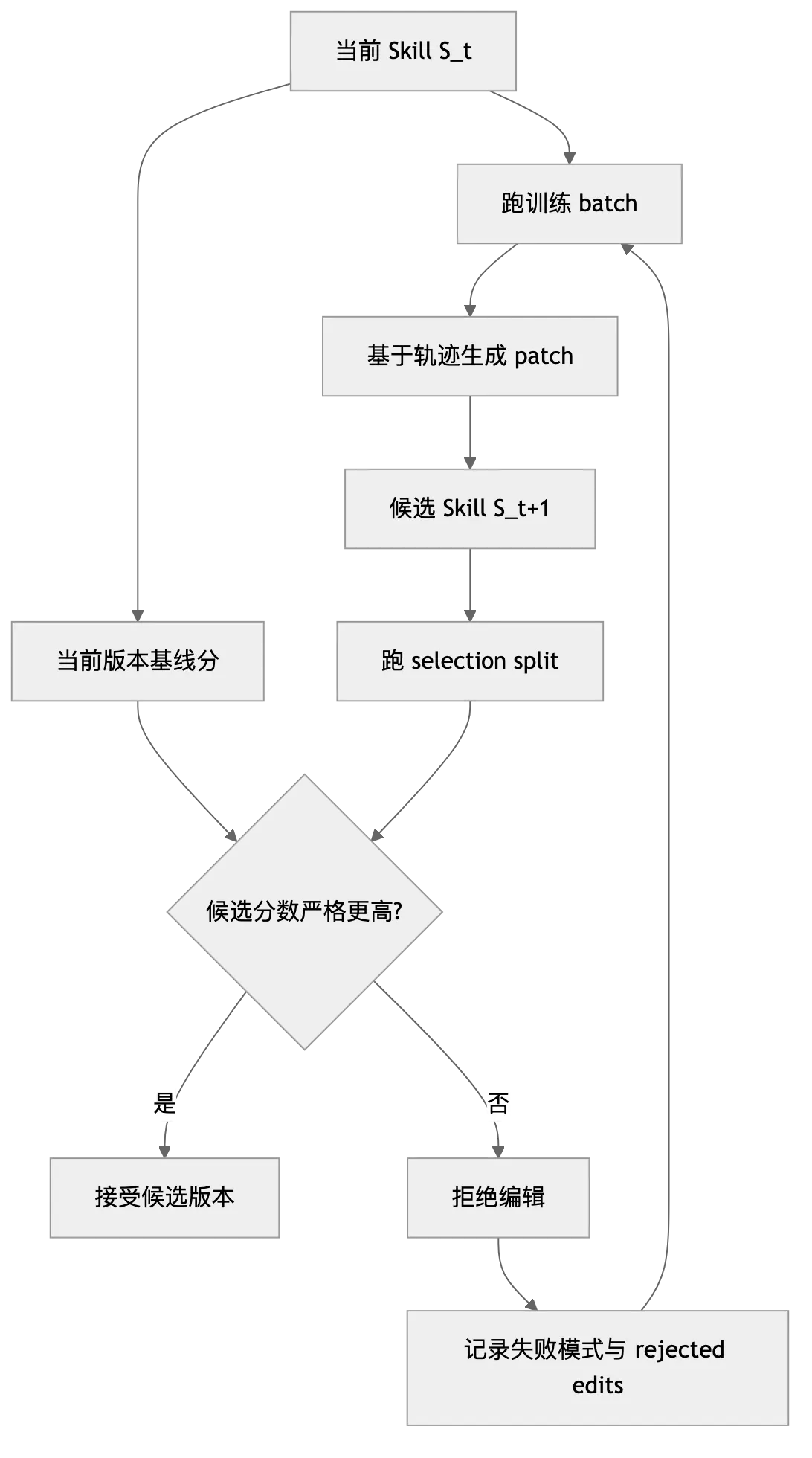
图:候选 Skill 只有在独立验证集严格提升时才会被接受
这个门禁把"合理建议"变成"可验证更新"。很多 Prompt 规则在阅读时都显得正确,比如"先确认需求再输出""必要时调用工具验证"。但只有放进任务集里,才能看到它是否真的改变了 Agent 行为,或者只是增加了文本噪声。
Step Buffer 与 Slow Update:短期纠偏,长期沉淀
SkillOpt 没有把每个 step 当成孤立事件。它设计了两层经验留存:一层处理同一 epoch 内的短期反馈,另一层处理跨 epoch 的稳定经验。
Step Buffer 记录当前 epoch 内看到的失败模式,以及被 gate 拒绝的编辑。它的作用很实际:如果某个修改方向刚被验证集证明无效,后续 step 就不要再用不同措辞重复提交一遍。它还可以追踪持续问题,帮助优化器识别哪些错误跨 batch 都存在。
Slow Update 更像长期复盘。每个 epoch 结束后,系统把上一版 Skill 和当前 Skill 放到同一批任务上比较,区分四类结果:
| 结果类型 | 含义 | 对优化的价值 |
|---|---|---|
| improved | 旧版错,新版对 | 说明某些新增规则可能有效 |
| regressed | 旧版对,新版错 | 暴露新编辑带来的副作用 |
| persistent_fail | 两版都错 | 说明当前规则还没触达问题根因 |
| stable_success | 两版都对 | 识别不应被后续编辑破坏的能力 |
Slow Update 会把这些更稳定的观察写入 Skill 的受保护区域,作为后续优化的长期指导。与此同时,Meta Skill 记录的是优化器自己的经验:哪些编辑方向更容易有效,哪些修改看似合理但常常退化。一个面向目标 Skill,一个面向 optimizer model。
Best Skill:训练结束后的可部署工件
SkillOpt 的最终输出通常是一份紧凑的 best_skill.md,而不是一堆运行时策略。论文描述的常见规模大约是 300 到 2000 tokens,重点是可读、可审计、可部署、可回滚。
这点很关键。SkillOpt 不要求线上推理时额外调用优化器,也不把优化过程塞进生产链路。训练阶段用 rollout、reflection、gate 做重活;推理阶段只加载筛选后的 Skill。对工程系统来说,这比引入复杂的动态决策器更容易落地,也更容易做版本管理。
可以把它理解成一种文本资产训练流程:
- 冻结目标模型和 Agent 运行逻辑。
- 用当前 Skill 跑任务,收集轨迹和评分。
- 优化器从 batch 轨迹里提出结构化编辑。
- 编辑受预算限制,只做小步更新。
- 候选 Skill 通过验证门禁才被接受。
- 多轮迭代后导出
best_skill.md。
图:训练阶段做重活,生产阶段只加载筛选后的 Skill 文本
工程上的启发
SkillOpt 真正有价值的地方,不是"让模型帮我们写 Skill",而是给 Skill 维护补上了实验纪律。
它提醒我们,Agent 的外部规则也是系统状态。既然这份状态会改变行为,就不能只靠主观 review 维护。至少在复杂任务里,Skill 更新应该回答三个问题:这条规则来自哪些轨迹证据?它修改了哪部分行为?它有没有在独立验证集上带来提升?
如果把这套思想放回日常工程,我会先保留三个底座:任务集、轨迹日志和版本门禁。没有任务集,优化器只能凭感觉写建议;没有轨迹,失败原因会被压缩成一句"结果不对";没有门禁,Skill 会越改越厚,最后没人敢删。
Skill 文档当然还是文本,但它不该只是说明书。更准确地说,它是一段会被模型执行的工程配置。SkillOpt 的意义就在这里:把这段配置从"经验堆叠"拉回到"证据驱动的迭代"。
推荐阅读
Multi-Agent 执行闭环:AI Coding 真正进生产,要靠模型分工和工程护栏
Agent Skill 状态机工程:Mode-Step 网格如何拆开工作流边界
Agent Skill Eval:从触发信号到 A/B 基准,如何把 Skill 做成可回归工程单元