AI 工程师知识地图:模型格式、框架、部署工具一次讲明白

作 者 : 吴佳浩 Alben
撰稿时间:2026.6.28
引言
最近这一两年,AI 圈子里冒出来的名词速度快得让人跟不上------昨天还在聊 PyTorch 和 TensorFlow,今天又出现了 GGUF、Safetensors、ONNX,明天可能又是 Ollama、vLLM、SGLang。很多人(包括我自己刚入行时)第一反应是把它们当成一个个孤立的知识点去死记硬背,结果学了很多名词,脑子里却始终拼不出一张完整的图,遇到新工具还是不知道该往哪儿归类。
其实这些名词从来都不是平级关系,而是分布在 AI 开发同一条流水线上的不同环节:模型先被训练出来,再被微调,然后保存成某种格式,被某个库加载调用,经过推理优化,最后被某种方式部署成服务,提供给真正的应用使用。只要把这条链路理清楚,几乎所有名词都能立刻找到自己的位置。
一、为什么 AI 圈总有那么多新名词?
- 为什么有 PyTorch,又有 Transformers?
- GGUF、Safetensors、ONNX 都是模型文件,为什么要三种?
- LoRA 是模型吗?
- Ollama、Llamafile、Xinference 又是什么关系?
这些名词并不是一个层级,而是 AI 开发流程中的不同环节。
二、一张图看懂 AI 工程师技术栈(全景图)
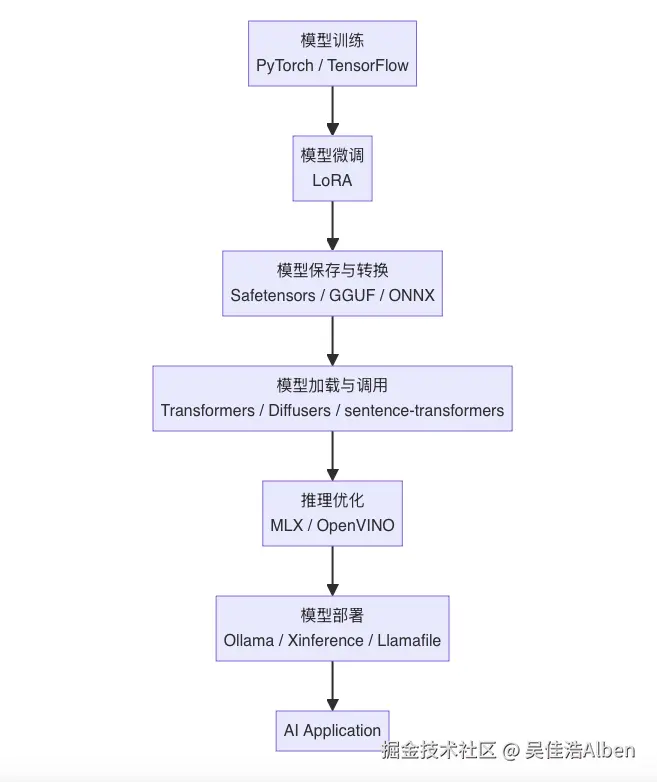
三、模型训练:模型是怎么炼成的?
3.1 PyTorch
是什么:Meta(原 Facebook)开源的深度学习框架,核心是张量(Tensor)计算 + 自动微分(Autograd)。开发者用 Python 定义网络结构、定义损失函数,PyTorch 自动算梯度、自动反向传播,不用手写求导公式。
为什么成为大模型训练事实标准:
- 动态图(Eager Execution):模型结构在运行时才确定,调试时可以像调试普通 Python 代码一样单步打断点、打印中间张量,这对研究者快速试错极其重要,而早期 TensorFlow 是静态图,必须先编译计算图再运行,调试体验差很多。
- 生态聚集效应:Hugging Face Transformers、DeepSpeed、Megatron-LM、vLLM 等几乎所有主流大模型训练 / 推理框架都首选 PyTorch 作为底层,论文代码默认发布 PyTorch 版本,导致越来越多人只学 PyTorch 就够用。
- 工业界与学术界双线渗透:从 2019 年前后开始,顶会论文中 PyTorch 实现占比反超 TensorFlow,形成了"新模型先出 PyTorch 版"的惯例。
优缺点:
- 优点:上手快、调试友好、社区资源最多、和 Hugging Face 生态无缝衔接。
- 缺点:移动端 / 嵌入式部署不如 TensorFlow Lite 成熟,需要额外转换(如转 ONNX)才能上线到某些硬件。
python
# PyTorch 最小训练示例:定义模型、算梯度、反向传播
import torch
import torch.nn as nn
model = nn.Linear(10, 1)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
loss_fn = nn.MSELoss()
x = torch.randn(32, 10)
y = torch.randn(32, 1)
for epoch in range(100):
optimizer.zero_grad()
pred = model(x)
loss = loss_fn(pred, y)
loss.backward() # 自动微分,自动算梯度
optimizer.step() # 更新参数3.2 TensorFlow
Google 出品 :2015 年由 Google Brain 团队开源,最初是静态计算图(Static Graph)设计,需要先用 tf.Graph 定义好整个网络再 Session.run() 执行,性能优化空间大,但写法繁琐。
为什么曾经最火:在 2016-2019 年间,TensorFlow 是工业界部署的代名词------TensorFlow Serving 用于生产环境推理、TensorFlow Lite 用于移动端和嵌入式设备、TensorBoard 可视化训练过程,这一整套配套设施在当时远比 PyTorch 完善,大厂(尤其依赖 Google Cloud 的公司)大规模采用。
为什么现在更多企业维护旧项目:TensorFlow 2.x 虽然引入了 Eager Execution 想追上 PyTorch 的易用性,但生态迁移成本太高,加上大模型时代开源社区集体转向 PyTorch,新项目很少再选 TensorFlow,它更多出现在已经上线多年、不便重写的存量系统里(比如某些推荐系统、移动端 CV 模型)。
最后对比
| 框架 | 定位 | 适用场景 |
|---|---|---|
| PyTorch | 主流训练框架 | LLM、CV、科研 |
| TensorFlow | 深度学习框架 | 企业、移动端、历史项目 |
四、模型微调:为什么不用重新训练几万亿参数?
4.1 LoRA
为什么出现:一个百亿、千亿参数的大模型,如果要"全参数微调"(Full Fine-tuning),意味着每个参数都要存梯度、存优化器状态(Adam 优化器要为每个参数额外保存一阶矩和二阶矩),显存占用通常是参数量的好几倍------一张消费级显卡根本塞不下。LoRA(Low-Rank Adaptation,低秩适应)2021 年由微软提出,思路是:冻结原模型所有参数不动,只在网络的关键层(比如 Attention 的 Q、V 矩阵)旁边插入两个很小的低秩矩阵 A 和 B,训练时只更新这两个小矩阵。
为什么显存需求低:假设原始权重矩阵是 d×d 的大矩阵,LoRA 把它分解成 d×r 和 r×d 两个小矩阵(r 远小于 d,通常取 4、8、16),需要训练和保存梯度的参数量从 d² 骤降到 2dr,往往只占原模型参数量的 0.1%-1%。这意味着原本需要 80GB 显存全参数微调的模型,用 LoRA 可能十几 GB 显存就能跑,个人用消费级显卡(如 RTX 4090)微调大模型成为可能。
为什么 Hugging Face 到处都是 LoRA:训练完之后,LoRA 产出的是一个很小的"增量权重文件"(通常几十 MB 到几百 MB),不需要重新分发整个几十 GB 的底座模型,使用时把 LoRA 权重叠加(merge)回原模型即可。这种"轻量、可插拔、可叠加多个 LoRA"的特性,使得 Hugging Face 上出现了海量针对不同任务、不同风格训练的 LoRA 权重(尤其是 Stable Diffusion 的风格 LoRA、大语言模型的领域微调 LoRA),生态因此迅速繁荣。
python
# 用 peft 库给大模型加 LoRA 微调(以 Hugging Face 模型为例)
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
lora_config = LoraConfig(
r=8, # 低秩矩阵的秩 r
lora_alpha=16,
target_modules=["q_proj", "v_proj"], # 只在 Q、V 矩阵上插入 LoRA
lora_dropout=0.05,
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# 输出类似:trainable params: 4,194,304 || all params: 7,615,616,512 || trainable%: 0.055%五、模型保存:为什么会有这么多模型格式?
5.1 Safetensors
为什么安全 :在 Safetensors 之前,模型权重普遍用 Python 的 pickle 格式保存(如 PyTorch 的 .bin/.pt 文件)。pickle 反序列化时会执行文件里嵌入的任意代码,这意味着下载一个来路不明的模型文件,打开它就可能在你的机器上执行恶意代码(远程代码执行漏洞)。Safetensors 由 Hugging Face 设计,文件格式上只存"纯数据"(张量的形状、类型、字节内容),不包含可执行代码,加载时只是单纯读字节,从根本上杜绝了这类供应链投毒风险。
为什么 Hugging Face 默认推荐 :除了安全性,Safetensors 还支持**零拷贝(zero-copy)和 内存映射(mmap)**加载,比 pickle 反序列化更快,尤其在加载几十 GB 的大模型时差异明显。因此 Hugging Face Hub 从 2023 年起把 Safetensors 设为模型上传和加载的默认推荐格式,新模型基本都会同时提供 .safetensors 版本。
5.2 GGUF
为什么 Ollama 都在用 :GGUF(GGML Universal Format)是 llama.cpp 项目设计的模型文件格式,专门为量化(Quantization)**和**CPU 友好推理而生。它把模型权重从 FP16/FP32 压缩到 4-bit、5-bit、8-bit 等更低精度,体积可以缩小到原来的 1/4 甚至更小,同时把分词器(tokenizer)、模型超参数等元数据也打包进同一个文件,做到"一个文件即可运行",Ollama 底层依赖 llama.cpp 做推理,自然就以 GGUF 作为标准模型格式。
为什么 llama.cpp 都支持:GGUF 本来就是 llama.cpp 作者 Georgi Gerganov 团队设计并维护的格式(前身是 GGML),两者是同一条技术血脉,所有围绕 llama.cpp 生态衍生出的工具(Ollama、LM Studio、text-generation-webui 等)天然都把 GGUF 当作一等公民支持。
为什么适合 CPU、本地部署:GGUF 配合 llama.cpp 的量化推理内核,可以在没有 GPU、仅靠 CPU(甚至手机芯片)的情况下跑起十几 B 参数的模型,这对个人开发者在笔记本电脑本地部署大模型、不依赖云端 API 极其重要。
5.3 ONNX
为什么企业部署喜欢:ONNX(Open Neural Network Exchange)由微软和 Meta 联合发起,定位是"模型的中间语言"。企业训练时往往用 PyTorch,但生产环境可能需要在 Java 后端、移动端、或专用推理芯片上跑模型,直接用 PyTorch 运行时太重、依赖太多。把模型导出成 ONNX 之后,可以用更轻量、性能更优的 ONNX Runtime 加载执行,脱离原训练框架的依赖。
为什么跨框架:ONNX 定义了一套与具体框架无关的标准算子(operator)描述,PyTorch、TensorFlow、scikit-learn 等都可以导出为 ONNX 格式,理论上"一处训练,到处部署",避免了企业被锁定在单一训练框架上。
为什么支持各种硬件:ONNX Runtime 提供了针对不同硬件后端的执行提供程序(Execution Provider),比如 CUDA EP 对接 NVIDIA GPU、OpenVINO EP 对接 Intel 芯片、CoreML EP 对接苹果设备,同一份 ONNX 模型文件可以在不同硬件上分别用最优的底层加速库执行,这也是它在企业级跨平台部署中长期占有一席之地的原因。
最后做一张对比表
| 格式 | 用途 | 最适合 |
|---|---|---|
| Safetensors | 保存训练权重 | Hugging Face |
| GGUF | 本地推理 | Ollama、llama.cpp |
| ONNX | 跨平台部署 | 企业推理 |
python
# Safetensors:安全加载,零拷贝
from safetensors.torch import save_file, load_file
tensors = {"weight": torch.randn(768, 768)}
save_file(tensors, "model.safetensors")
loaded = load_file("model.safetensors") # 只读字节,不执行任何代码
# GGUF:用 llama.cpp 的转换脚本把 Hugging Face 模型量化为 GGUF
# python convert_hf_to_gguf.py ./my-model --outfile model.gguf
# ./llama-quantize model.gguf model-q4_k_m.gguf Q4_K_M # 4-bit 量化
# ONNX:把 PyTorch 模型导出为 ONNX,用 ONNX Runtime 跨平台推理
import torch.onnx
torch.onnx.export(model, x, "model.onnx", input_names=["input"], output_names=["output"])
import onnxruntime as ort
session = ort.InferenceSession("model.onnx", providers=["CPUExecutionProvider"])
result = session.run(None, {"input": x.numpy()})六、模型加载:模型为什么能一句代码跑起来?
6.1 Transformers
负责 NLP、大语言模型。Hugging Face Transformers 库把不同架构(BERT、GPT、LLaMA、Qwen 等)的模型统一封装成一致的接口------from_pretrained() 加载权重、tokenizer 处理文本分词、generate() 完成文本生成。开发者不需要了解每个模型内部具体的网络结构差异,换模型基本就是改一行模型名字,这种"统一接口、屏蔽底层差异"的设计,是它成为 NLP/大语言模型事实标准库的核心原因。
6.2 Diffusers
负责 Stable Diffusion
负责 FLUX
负责各种图片生成模型。Diffusers 是 Hugging Face 专门为扩散模型(Diffusion Model)打造的库,把"加噪---去噪"这套生成图像(以及音频、视频)的流程封装成 Pipeline,同样提供统一接口去调用不同的文生图模型(Stable Diffusion 系列、FLUX 等),并内置了 VAE、UNet、调度器(Scheduler)等扩散模型特有组件的标准实现,省去开发者从零拼装这套数学流程的麻烦。
6.3 sentence-transformers
Embedding
RAG
向量数据库
语义搜索。sentence-transformers 专注于把一段文本转换成一个固定长度的向量(Embedding),这个向量能表达文本的语义。它是 RAG(检索增强生成)系统的关键一环:把知识库文档先用它转成向量存入向量数据库,用户提问时也转成向量,再做相似度检索找到最相关的文档片段喂给大模型回答,从而实现语义搜索(不是关键词匹配,而是"意思相近"就能搜到)。
最后再做张表
| 库 | 加载什么 |
|---|---|
| Transformers | LLM |
| Diffusers | 文生图 |
| sentence-transformers | Embedding |
python
# Transformers:加载并调用大语言模型
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
inputs = tokenizer("用一句话介绍 LoRA", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
# Diffusers:加载并调用 Stable Diffusion 文生图
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1")
image = pipe("一只在月球上弹吉他的猫").images[0]
image.save("output.png")
# sentence-transformers:把文本转成 Embedding 向量
from sentence_transformers import SentenceTransformer
embed_model = SentenceTransformer("BAAI/bge-large-zh-v1.5")
vectors = embed_model.encode(["LoRA 是什么", "什么是低秩适应"])
# 用余弦相似度比较两个向量,相似度高代表语义相近,可用于语义搜索 / RAG 检索七、推理优化:同一个模型为什么有人快十倍?
7.1 MLX
Apple Silicon 专属。MLX 是苹果官方推出的机器学习框架,专门针对 M 系列芯片(M1/M2/M3/M4)的统一内存架构(CPU 和 GPU 共享同一块内存,不需要像独立显卡那样在 CPU 内存和 GPU 显存之间来回拷贝数据)做了底层优化,可以更充分利用 Mac 的算力跑大模型推理甚至轻量训练。
为什么 Mac 用户都在讨论。因为 Mac(尤其是大内存的 M 系列芯片机型)天生没有独立 NVIDIA 显卡,传统基于 CUDA 的推理 / 训练框架在 Mac 上完全用不了,而 MLX 让 Mac 用户第一次能用接近原生效率的方式在本地跑大模型,加上语法设计上刻意贴近 PyTorch/NumPy,上手成本低,因此在 Mac 开发者和本地大模型爱好者圈子里讨论度很高。
7.2 OpenVINO
Intel 官方推出的推理优化工具套件(OpenVINO = Open Visual Inference & Neural Network Optimization)。
- CPU:针对 Intel CPU 的指令集(如 AVX-512)做计算图算子级别的优化,让模型在没有独立 GPU 的服务器或 PC 上也能跑出可用的推理速度。
- GPU:支持 Intel 集成显卡 / 独立显卡(Arc 系列)加速。
- NPU:支持新一代 Intel 酷睿 Ultra 处理器内置的神经网络处理单元(Neural Processing Unit),专为 AI 推理设计,功耗更低。
- 统一优化:开发者只需把模型转换成 OpenVINO 的中间表示(IR)格式一次,运行时可以根据当前设备自动选择在 CPU、GPU 还是 NPU 上执行,不需要为每种硬件单独写一套推理代码,这种"一次转换、多硬件适配"的能力是它在 Intel 生态里的核心价值。
python
# MLX:在 Apple Silicon 上跑大模型推理
import mlx.core as mx
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Qwen2.5-7B-Instruct-4bit")
response = generate(model, tokenizer, prompt="用一句话介绍 MLX", max_tokens=50)
print(response)
# OpenVINO:把模型转换成 IR 格式,自动选择 CPU/GPU/NPU 执行
from optimum.intel import OVModelForCausalLM
from transformers import AutoTokenizer
model = OVModelForCausalLM.from_pretrained("model_id", export=True, device="CPU")
tokenizer = AutoTokenizer.from_pretrained("model_id")八、模型部署:模型最后怎么提供服务?
8.1 Ollama
为什么现在最火 :Ollama 把"下载模型、配置环境、启动推理服务"这一整套原本对新手很繁琐的流程,简化成一条命令 ollama run llama3 就能跑起来,背后自动处理模型下载、量化、加载、本地 HTTP API 暴露,这种"开箱即用"的体验是它在个人开发者和本地部署爱好者中迅速走红的核心原因。
GGUF 为什么默认支持:Ollama 的推理内核基于 llama.cpp,因此天然原生支持 GGUF 格式,模型仓库(Ollama Library)里的模型也都是预先转换打包好的 GGUF 文件,用户不需要关心格式转换细节。
什么时候适合用:个人电脑本地跑大模型做实验、demo、隐私敏感不想调用云端 API 的场景,或者只是想快速验证某个开源模型效果,Ollama 是目前门槛最低的选择;但如果是高并发、多用户的生产环境服务,它的吞吐和并发能力不是为这种场景设计的。
bash
# Ollama:一条命令拉取并运行模型,自动暴露本地 API
ollama run llama3
# 启动后可直接用 HTTP 调用
curl http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt": "用一句话介绍 Ollama"
}'8.2 Xinference
统一部署
LLM
Embedding
Reranker
ASR
统一管理。Xinference(Xorbits Inference)的定位和 Ollama 不同,它面向的是企业 / 团队级场景:一个平台统一管理和部署多种类型的 AI 模型------不仅是大语言模型(LLM),还包括 Embedding 模型、Reranker(重排序,常用于 RAG 精排)、ASR(语音识别)等,提供统一的 API 网关和模型生命周期管理(启动、停止、扩缩容),相当于一个"私有化的模型即服务(MaaS)平台"。
为什么企业越来越喜欢:企业内部往往同时需要好几种模型协同工作(比如一个 RAG 系统需要 Embedding 模型做检索、Reranker 做精排、LLM 做最终生成),如果每种模型都用不同工具单独部署管理,运维成本很高。Xinference 把这些模型类型统一到一套部署和调用体系下,加上支持分布式部署、可以横向扩展应对高并发,更贴合企业生产环境的需求。
bash
# Xinference:启动服务,统一注册并部署 LLM / Embedding / Reranker
xinference-local --host 0.0.0.0 --port 9997
# 通过命令行启动一个 LLM 模型实例
xinference launch --model-name qwen2.5-instruct --model-format pytorch --size-in-billions 7
# 通过 Python SDK 调用
from xinference.client import Client
client = Client("http://localhost:9997")
model = client.get_model("qwen2.5-instruct")
model.chat(messages=[{"role": "user", "content": "你好"}])8.3 Llamafile
为什么一个 exe 就能运行模型 :Llamafile 由 Mozilla 旗下团队基于 llama.cpp 打造,它利用了一种叫 Cosmopolitan Libc 的技术,把模型权重和 llama.cpp 推理引擎打包进同一个可执行文件里,并且这个可执行文件采用了一种"多格式兼容"的二进制构造方式,使得同一个文件在 Windows、macOS、Linux 上都能直接双击或命令行运行,不需要用户安装 Python 环境、不需要 pip 装一堆依赖包。
底层原理:核心依赖 Cosmopolitan Libc 项目实现的"万能二进制"(Actually Portable Executable)技术,让同一份机器码在不同操作系统的可执行文件加载器看来都是合法格式,从而实现跨平台零依赖运行。
适合哪些场景:需要把一个能跑大模型的程序分发给完全不懂技术的用户(比如做内部工具、demo 演示给非技术同事),对方电脑上不用装任何环境,下载一个文件双击就能跑,这种"极致分发便利性"是 Llamafile 的核心使用场景,但相应地灵活性和可定制性不如 Ollama 或直接用 llama.cpp。
bash
# Llamafile:下载一个文件,赋予可执行权限,直接运行
chmod +x llava-v1.5-7b-q4.llamafile
./llava-v1.5-7b-q4.llamafile
# 自动在本地启动一个带 Web UI 的服务,浏览器打开 http://localhost:8080 即可对话8.4 vLLM
为什么是生产级高并发推理的首选 :vLLM 由加州伯克利大学团队提出,核心创新是 PagedAttention ------把 Attention 计算中要缓存的 KV Cache(Key-Value Cache)按照操作系统虚拟内存分页的思路管理,不要求每个请求的 KV Cache 占用连续显存空间,大幅减少显存碎片浪费。同时支持 Continuous Batching(连续批处理),新请求可以随时插入正在跑的批次,不需要等一批全部处理完,显著提升 GPU 利用率和吞吐量。
适合什么场景:面向多用户同时请求的在线服务场景(比如对外提供 Chat API、企业内部多人共用的大模型网关),相比 Ollama、Llamafile 这类面向单机本地使用的工具,vLLM 是真正为高并发生产环境设计的推理引擎,通常部署在带 GPU 的服务器上。
bash
# 安装并启动一个兼容 OpenAI API 格式的服务
pip install vllm
python -m vllm.entrypoints.openai.api_server \
--model Qwen/Qwen2.5-7B-Instruct \
--port 8000
# 用 OpenAI SDK 的方式直接调用(接口完全兼容)
curl http://localhost:8000/v1/chat/completions -d '{
"model": "Qwen/Qwen2.5-7B-Instruct",
"messages": [{"role": "user", "content": "用一句话介绍 vLLM"}]
}'8.5 SGLang
为什么号称比 vLLM 更快 :SGLang 由 LMSYS(开发了 Vicuna、Chatbot Arena 的团队)推出,除了同样支持 PagedAttention、Continuous Batching 之外,核心亮点是 RadixAttention------用基数树(Radix Tree)结构自动复用不同请求之间公共的前缀 KV Cache(比如多个用户用同一个 System Prompt,或者多轮对话中重复的历史上下文),命中前缀后可以直接复用缓存,省去重复计算,在多轮对话、Agent 工具调用等存在大量重复前缀的场景下,吞吐和延迟优势比 vLLM 更明显。
适合什么场景:复杂的结构化生成任务,比如需要多次调用模型、带大量 Few-shot 示例的 Prompt、Agent 多步推理、批量结构化输出(JSON 模式)等场景,SGLang 还提供了专门的前端语言(SGLang Language)描述这种多步生成逻辑,让复杂调用链路写起来更简洁。
bash
# 安装并启动服务(同样兼容 OpenAI API 格式)
pip install "sglang[all]"
python -m sglang.launch_server \
--model-path Qwen/Qwen2.5-7B-Instruct \
--port 30000
# Python 调用示例
import sglang as sgl
@sgl.function
def multi_turn_chat(s, question):
s += sgl.user(question)
s += sgl.assistant(sgl.gen("answer", max_tokens=100))
state = multi_turn_chat.run(question="用一句话介绍 SGLang")
print(state["answer"])最后把 vLLM 和 SGLang 与之前的部署工具放在一起对比
| 工具 | 定位 | 核心技术 | 最适合场景 |
|---|---|---|---|
| Ollama | 本地单机部署 | 基于 llama.cpp,GGUF 量化 | 个人开发者本地跑模型、demo |
| Llamafile | 单文件分发 | Cosmopolitan Libc 万能二进制 | 零依赖分发给非技术用户 |
| Xinference | 企业统一部署平台 | 统一管理 LLM/Embedding/Reranker/ASR | 团队级多模型协同生产环境 |
| vLLM | 高并发生产推理 | PagedAttention + Continuous Batching | 对外提供 API、多用户并发服务 |
| SGLang | 高并发 + 复杂调用链路 | RadixAttention 前缀复用 | 多轮对话、Agent、结构化批量生成 |
九、它们之间到底是什么关系?
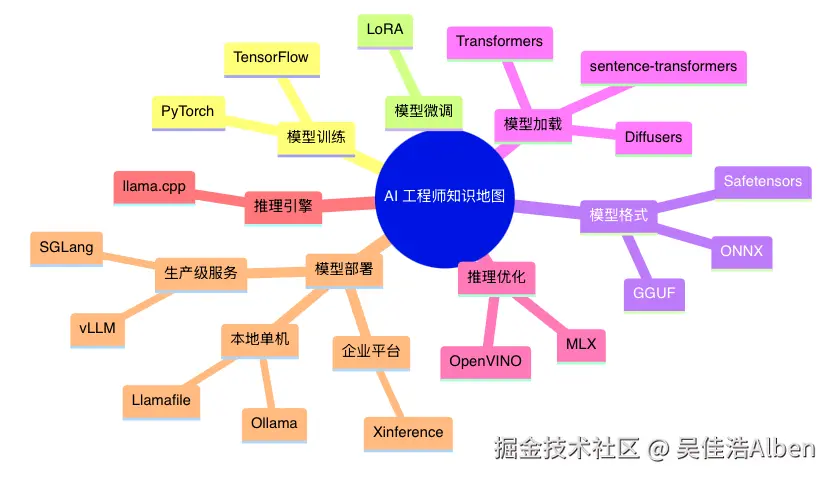
十、一张 Mindmap 总览全部知识点
十一、不同岗位,该重点学哪几层?
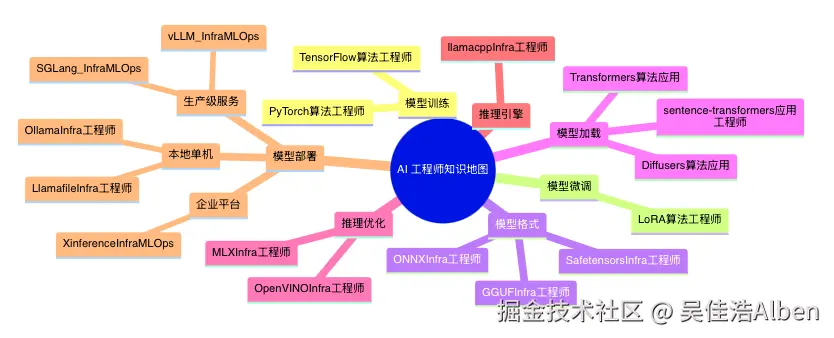
同一张技术地图,算法工程师、Infra 工程师、应用工程师、MLOps 工程师关注的层完全不一样。把岗位叠加到地图上,比单纯罗列技术更有指导意义。
11.1 算法工程师
主战场:模型训练层(PyTorch / TensorFlow)+ 模型微调层(LoRA)。
算法工程师的核心工作是设计网络结构、调超参数、跑实验、提升模型效果,因此 PyTorch 的自动微分机制、训练循环、LoRA 的低秩分解原理是必须深入掌握的部分。
次要了解:模型加载层(Transformers / Diffusers)------训完模型总要验证效果,这一层需要会用,但不需要精通。
基本不碰:模型格式转换(GGUF 量化、ONNX 导出)、推理优化(MLX / OpenVINO)、模型部署(Ollama / vLLM / SGLang / Xinference)------这些通常交给 Infra 工程师接手。
11.2 Infra / 平台工程师
主战场:模型格式与转换层(Safetensors / GGUF / ONNX)+ 推理优化层(MLX / OpenVINO)+ 模型部署层(Ollama / Llamafile / Xinference / vLLM / SGLang)。
Infra 工程师要保证算法工程师训好的模型能稳定、高效、低成本地跑起来------选择合适的量化精度、选择合适的推理引擎、根据并发量决定用 vLLM 还是 SGLang、根据硬件决定要不要接入 OpenVINO,这一整条链路是他们的核心职责。
次要了解:模型训练层的基本概念(知道 PyTorch 大致怎么训出模型即可,不需要会调参)。
基本不碰:LoRA 微调细节、Diffusers/sentence-transformers 这类面向具体业务的加载库。
11.3 应用 / 全栈 AI 工程师(RAG、Agent 等业务方向)
主战场:模型加载层里的 sentence-transformers(做 Embedding、对接向量数据库)+ 调用已部署好的模型服务 API(不管底层是 Ollama 还是 vLLM,他们只关心调用接口)。
这类工程师通常不训练模型、不做底层部署,而是把 Infra 工程师部署好的模型服务,通过 API 接入到具体业务逻辑里(搭建 RAG 检索流程、设计 Agent 工具调用链路、写 Prompt)。
次要了解:Transformers / Diffusers 的基本调用方式,方便本地做小规模实验和效果验证。
基本不碰:模型训练、LoRA 微调、底层推理优化、量化格式转换。
11.4 MLOps / 部署运维工程师
主战场:模型部署层中的生产级服务部分(vLLM / SGLang / Xinference)------监控 GPU 利用率、配置自动扩缩容、保障服务 SLA、做灰度发布和版本回滚。
这个角色夹在 Infra 工程师和应用工程师之间,更偏运维和稳定性保障,而不是性能优化本身(性能优化的具体技术选型一般由 Infra 工程师决定,MLOps 负责把选型落地成可监控、可运维的生产系统)。
次要了解:模型格式(知道 GGUF 和 Safetensors 的区别,方便排查部署问题)。
基本不碰:模型训练、微调、模型加载库的具体调用细节。
11.5 岗位 × 技术层速查表
| 技术层 | 算法工程师 | Infra 工程师 | 应用/全栈工程师 | MLOps 工程师 |
|---|---|---|---|---|
| 模型训练(PyTorch/TensorFlow) | 🔴 主战场 | ⚪ 了解即可 | ⚪ 基本不碰 | ⚪ 基本不碰 |
| 模型微调(LoRA) | 🔴 主战场 | ⚪ 基本不碰 | ⚪ 基本不碰 | ⚪ 基本不碰 |
| 模型格式(Safetensors/GGUF/ONNX) | ⚪ 基本不碰 | 🔴 主战场 | ⚪ 基本不碰 | 🟡 次要了解 |
| 模型加载(Transformers/Diffusers) | 🟡 次要了解 | ⚪ 基本不碰 | 🟡 次要了解 | ⚪ 基本不碰 |
| 模型加载(sentence-transformers) | ⚪ 基本不碰 | ⚪ 基本不碰 | 🔴 主战场 | ⚪ 基本不碰 |
| 推理优化(MLX/OpenVINO) | ⚪ 基本不碰 | 🔴 主战场 | ⚪ 基本不碰 | ⚪ 基本不碰 |
| 部署(Ollama/Llamafile/Xinference) | ⚪ 基本不碰 | 🔴 主战场 | 🟡 调用 API 即可 | 🟡 次要了解 |
| 部署(vLLM/SGLang 生产服务) | ⚪ 基本不碰 | 🔴 主战场 | 🟡 调用 API 即可 | 🔴 主战场(运维保障) |
11.6 岗位视角下的技术地图
十二、AI 工程师必备技术栈速查表
| 分类 | 技术 | 一句话定位 |
|---|---|---|
| 训练框架 | PyTorch、TensorFlow | 训练 AI 模型 |
| 微调技术 | LoRA | 低成本微调模型 |
| 模型格式 | Safetensors、GGUF、ONNX | 保存、转换和分发模型 |
| 模型库 | Transformers、Diffusers、sentence-transformers | 加载并使用不同类型模型 |
| 推理优化 | MLX、OpenVINO | 针对硬件优化模型推理 |
| 推理引擎 | llama.cpp | GGUF 模型的核心运行引擎 |
| 部署工具 | Ollama、Llamafile | 本地快速运行模型 |
| 部署平台 | Xinference | 统一部署和管理多种 AI 模型 |
| 推理服务框架 | vLLM、SGLang | 高并发生产级模型服务 |
总结
技术地图本身不是用来通篇精通的,而是用来定位自己的。算法工程师不需要懂 vLLM 的调度细节,Infra 工程师也不必深究 LoRA 的数学推导,知道地图全貌、再清楚自己该深耕哪一块,比盲目什么都学要重要得多。
如果这篇文章帮你理清了某个一直没搞懂的名词,或者帮你确认了下一步该往哪个方向深入,那就达到我写它的目的了。