怎么正确的使用agent工具开发
最近不管是我看同事用claude code写代码的方式还是我看到站内很多佬现在用ai工具写代码的方式,还有很多还是停留在对话框里提需求的阶段。
虽然开发个人项目来说其实完全足够但是如果是找工作或者是在项目中的话,仅靠跟 ai 对话来完成需求的模式其实已经不够了,特别是很多招聘要求是这样的比如我看到有大佬发布的招聘信息是这样的:
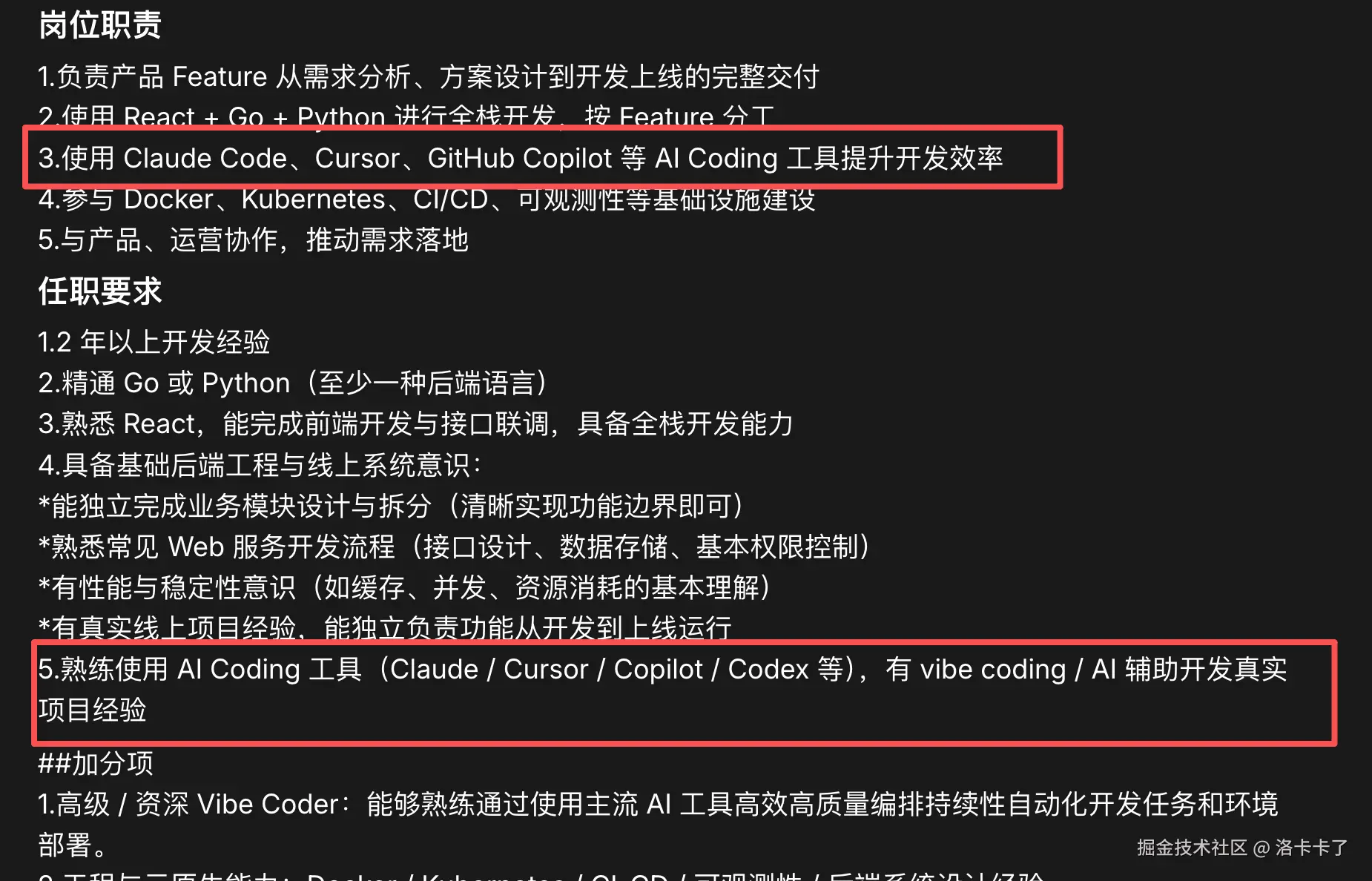 所以这就要求我们仅仅是能简单使用 agent 工具还不够,因为很多工具本身也提供了很多机制来辅助我们开发用于提升效率的,特别是关乎到团队协作的时候。
所以这就要求我们仅仅是能简单使用 agent 工具还不够,因为很多工具本身也提供了很多机制来辅助我们开发用于提升效率的,特别是关乎到团队协作的时候。
我们需要学会用用这些机制的目的,一是让 AI 更了解我们的需求和代码规则,二则是减少返工反复修改导致的 token 消耗。就像我之前写的那篇文章: 我们在用 AI 写代码时,为什么建议要好好维护 AGENTS.md 呢?
但是我看相关讨论的话题我发现很多佬友都陷入了一个误区,有的会觉得没必要维护这种文件,有的则觉得维护了也没用,因为规则写了,但是 ai 还是不执行。
那这里我需要解释一下出现这个问题的原因:
CLAUDE.md 只是建议性质的,不是强制执行的。
其实CLAUDE.md的本质就是一份给claude看的项目说明 文件,它的作用就是去提供上下文和建议的,当它读了规则后会在一些决策时进行参考,但并不保证每次都会遵守的。大模型是有自己的判断的,有时候它认为某条规则在当前场景下不适用,那就会跳过。
这里我简单举一个例子来说明下,比如我们在 CLAUDE.md 里写了:
- 改前端组件后必须运行 pnpm lint
- 改接口后同步更新文档和测试
claude 在执行的时候读取到了,大部分时候都会照做的,但如果有时候它判断这次改动很小、或者当前任务更紧急,又或者它觉得已经符合规范了,就可能会跳过这一步的。
其实这不是模型出错,而是 CLAUDE.md 文件本身就只是建议性 的,而不是强制性的。
所以规则不生效,可能并不是因为 CLAUDE.md 写得不对、不够准确、甚至是没用。而是它本来就只能做到建议这一步哈。
如果我们想强制执行某些规则的话, 那我们还需要用到另外一个机制,也就是今天我要说的:Hook 强制拦截机制。
Hooks 与 CLAUDE.md 的执行机制
这里我先说下 hooks 是什么东西,其实 hooks 是用户定义的钩子程序, 是绑定在 claude code生命周期的特定节点上自动执行的。它和 CLAUDE.md 的请遵守不同,hooks 的逻辑是不满足条件就阻断操作,claude 是没有跳过的余地的。
简单来总结就是:
CLAUDE.md 定义规则,Hooks 执行规则。
但是可能很多人了解知道 hooks 但是却并不知道要怎么去用它,甚至不知道什么时候才需要用,也许根本就用不到,所以这篇我会先一起梳理下 hooks 的一些机制。
首先是为什么要用hooks
其实我们都知道 claude code 的能力非常强,很多人在使用它的时候通常给的权限非常大,甚至直接让 claude code 全权接管项目进行开发。
虽然权限越大,claude code 完成的事情就可以越多,但随之带来的风险也就越高。比如我们经常遇到有佬讨论的这些:
- 修改了关键文件却没有经过审核
- 在生产环境执行了危险命令
- 删除文件、覆盖配置或批量修改代码时没有任何校验
如果是我们个人开发的项目,结合 git 这种带有历史记录回退机制的其实还好,最多是我们会反复进行修改的情况,所以也不需要考虑太多。
但是如果是在工作中那就不得不要求我们对代码开发甚至是 AI 开发保持热爱的同时保持敬畏之心了。必要的一些机制我们还是要遵守的。
既然我们维护 CLAUDE.md 也做不到让 ai 完全按照我们的规则执行,那我们就是用 hooks 来强制约束执行,它把依赖模型自觉遵守规则,变成了由程序强制执行规则。规则满足,就继续执行;规则不满足,那就直接拦截。
这里我们简单总结一下CLAUDE.md 和 Hooks 机制对比:
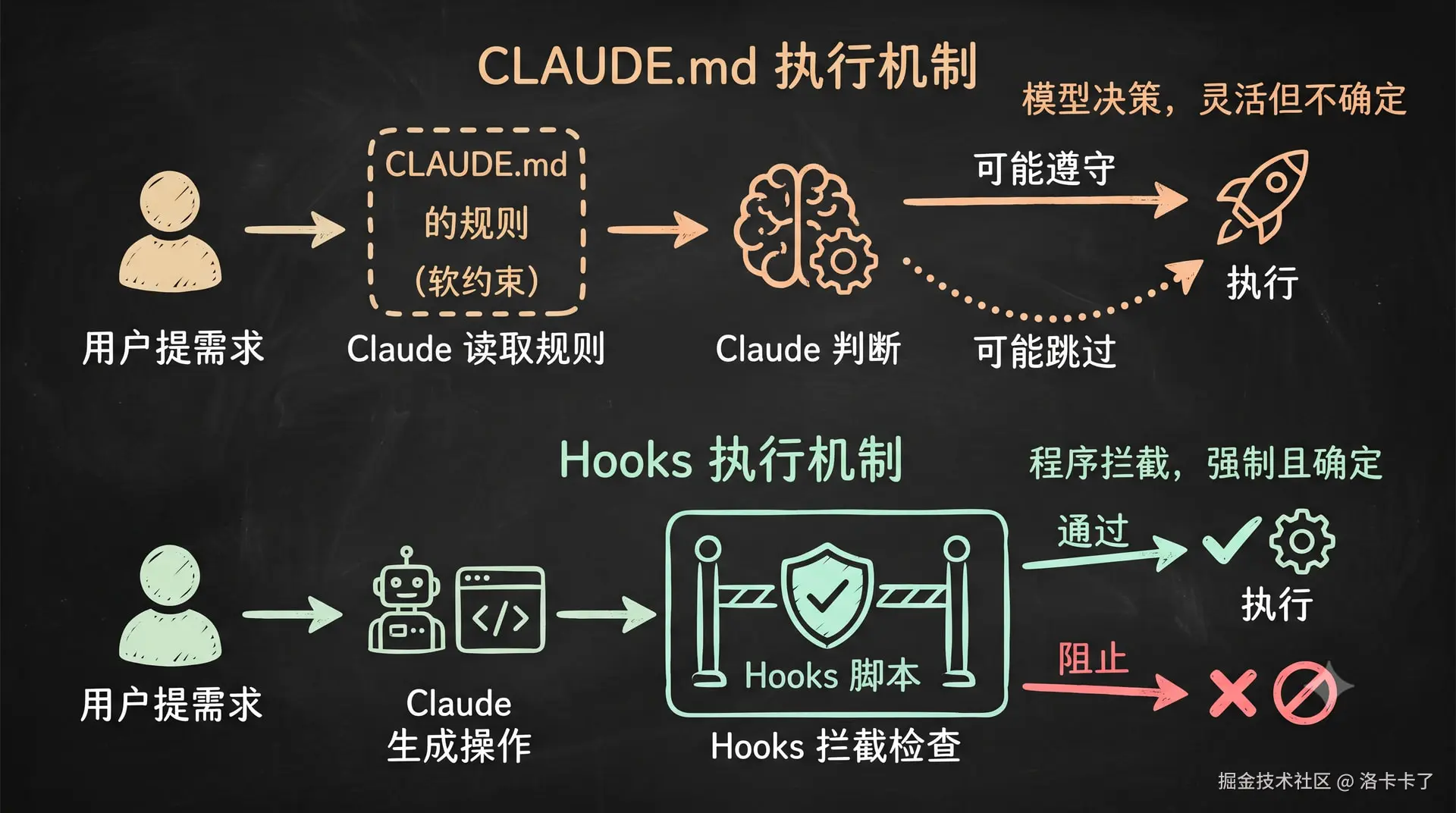
其实Hook 脚本并不是简单的命令执行,而是一个双向通信过程。claude code 来告诉 Hook 当前状态,Hook 检查后返回决定,告诉 claude code是继续还是阻止,以及具体原因。
Hooks 的结构应该怎么写呢
我们简单介绍了 hooks 的机制后,可能很多人还是不太懂怎么去写一个 hooks 结构,虽然我们也可以直接告诉 ai 让 ai 帮我们来写一个 hooks,但我们还是要大概了解下 Hooks 的结构写法,这样就算我们不手动配置,也要能做到看懂 Hooks 的结构。
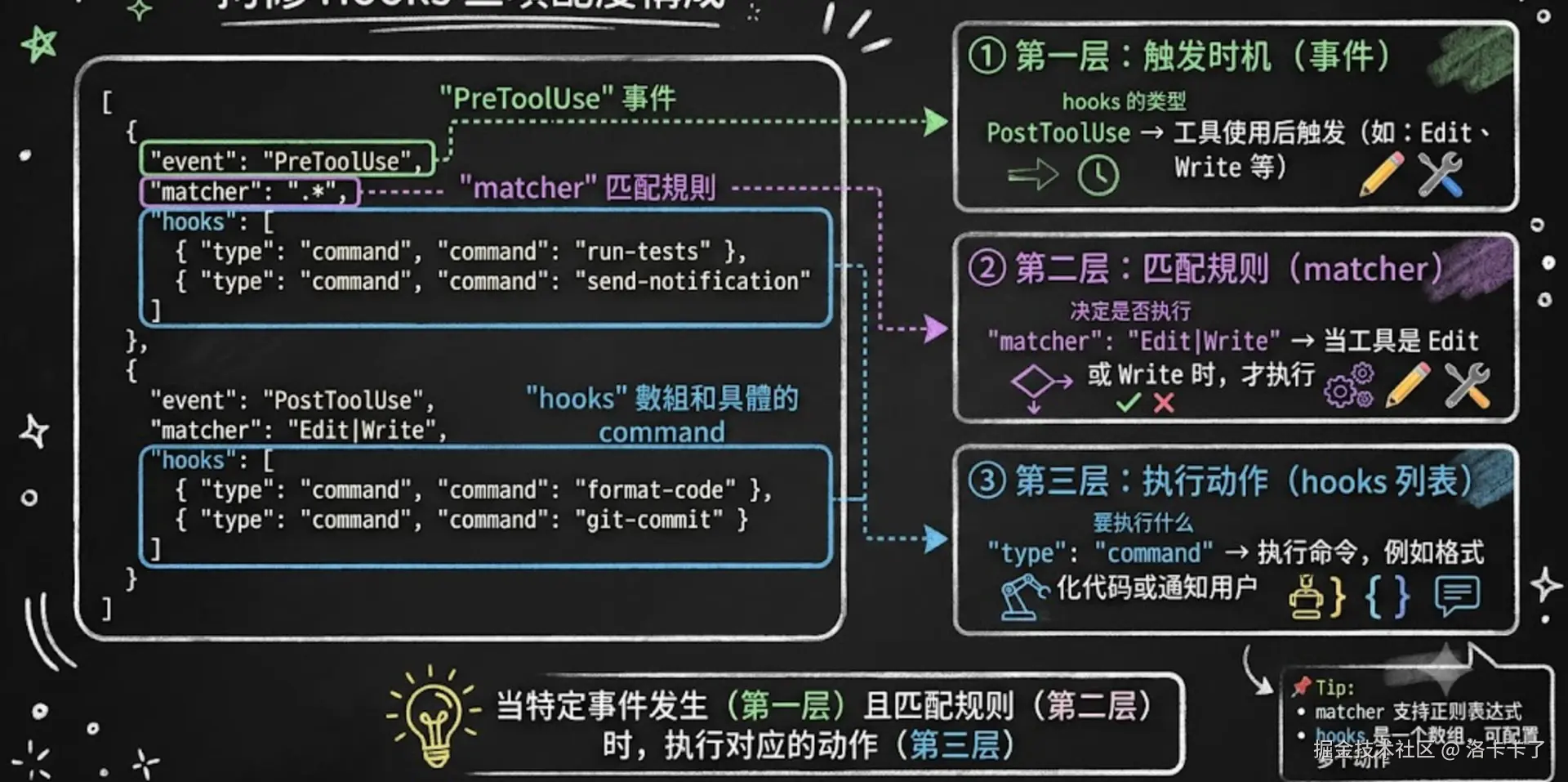
一个Hook在配置的时候其实就看重三个问题: 什么时候触发? 针对什么操作? 运行什么脚本?
Hooks 的结构是三层嵌套的
分别是:事件层、匹配器层、处理器层。逐层过滤,最终执行。
这里我们简单看一个普通的 Hooks 配置文件,大概是这样的:
sql
{
"hooks": {
"PreToolUse": [
{
"matcher": "Write|Edit|MultiEdit",
"hooks": [
{
"type": "command",
"command": ".claude/hooks/protect-sensitive-files.sh"
}
]
}
],
"SessionStart": [
{
"matcher": "*",
"hooks": [
{
"type": "command",
"command": "echo '{\"systemMessage\": \"Welcome to syncd project! Sensitive files are protected.\"}'",
"timeout": 5
}
]
}
]
}
}可以看到这个配置文件格式都比较统一,而且里面 hooks 这个词出现了三次。这里我们就来逐层理解下每一层的含义。
第一层:事件层(Event)
claude code 现在版本有 30 个 Hook 事件,涵盖了claude 执行的每一个关键节点。
其实总的来说我们用不到全部,但这里我们还是要大概了解一下。这里我们可以把这 30 个 Hook 事件分为六大类型:
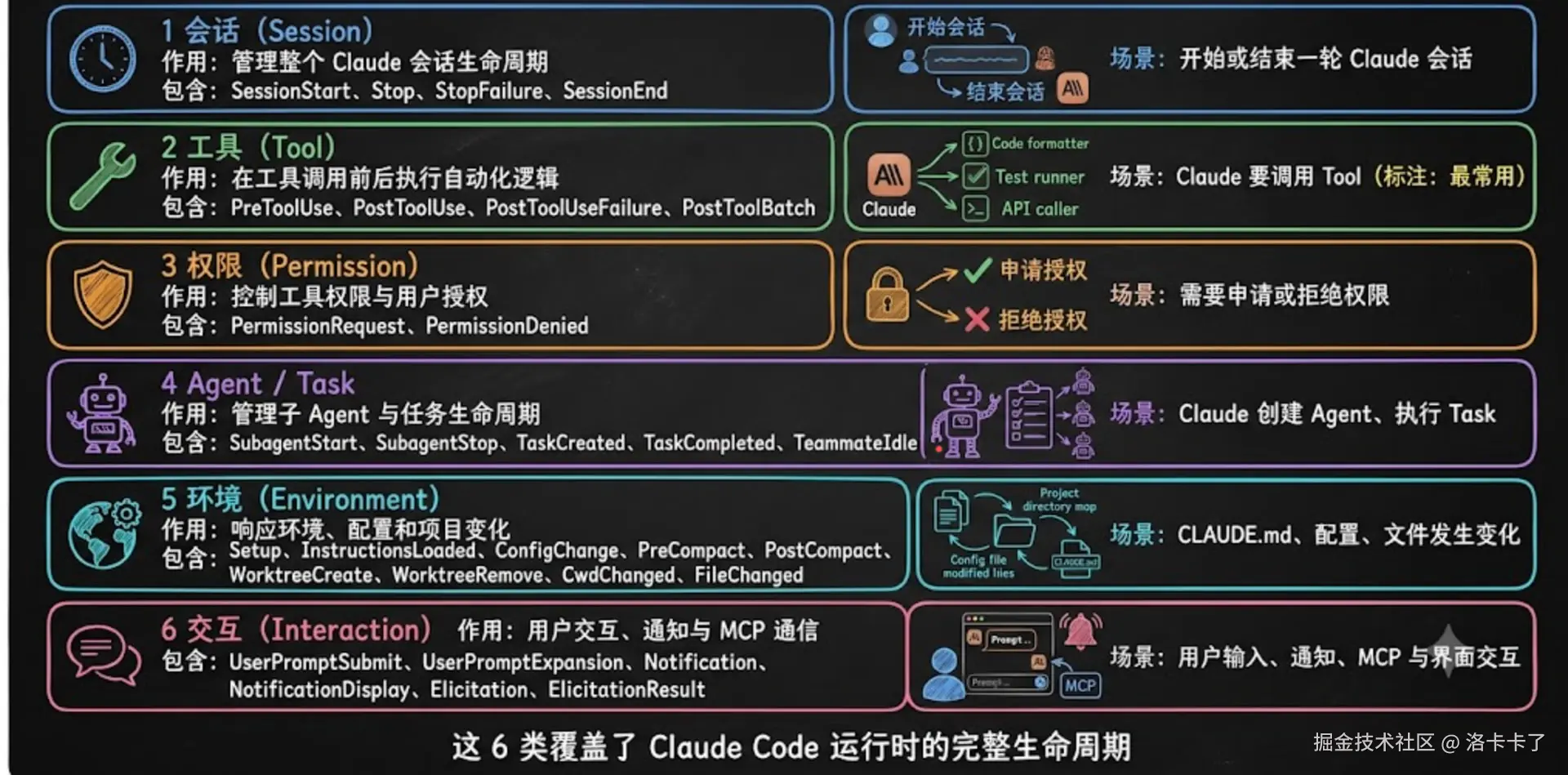
对于日常使用来看的话,我们最常用的是工具类(Tool)的 PreToolUse 和 PostToolUse,因为大部分自动化都是在 Claude 调用工具前后触发的。其他类型了解即可,需要的时候再查。
第二层:匹配器层(Matcher)
每个事件下面都可以配置多个 matcher的,它决定哪些工具会触发这段 Hook。比如我们常用的有这几个:
json
{
"matcher": "Bash", // 只针对 Bash 命令
"matcher": "Write|Edit", // 针对文件写入或编辑
"matcher": "*", // 针对所有工具
"matcher": "" // 针对所有(Stop 等事件不需要 matcher)
}matcher最常用的三种写法这里我也简单说明一下哈:
第一个是精准匹配,也就是指定单个工具名:
json
`"matcher": "Bash"` --- 只有 Claude 调用 Bash 工具时才触发。第二个是正则表达式,一般我们需要用|来匹配多个工具:
json
`"matcher": "Write|Edit|MultiEdit"` --- Claude 调用写入、编辑、批量编辑时都触发第三个通配符,匹配所有工具
json
"matcher": "*" --- 不管 Claude 调用什么工具都触发这里需要注意一下:
matcher 只适用于工具类事件哈,matcher 只在
PreToolUse和PostToolUse这类工具事件里有用,因为它是用来过滤工具类型的。 对于Stop、SessionStart、Notification等事件,不需要指定 matcher,写了也不会生效的。
第三层:处理器层(Hooks)
上面的例子中我们也看到了,matcher 里面还有一个 hooks 数组的,这里才是真正执行逻辑的地方哈,matcher 匹配到工具后,就会执行 hooks 数组里定义的脚本的。
这里处理器一般是有五种的,分别覆盖了不同的校验场景:
- command --- 执行 Shell 命令(我们日常最常用的)比如提交前自动跑格式化检查,或者在文件写入前校验内容是否符合安全规范。
- http --- 发送 POST 请求到指定 URL, 这个主要是用于通知外部系统或触发 CI 流水线的,
- mcp_tool --- 调用已连接的 MCP 服务器上的工具,是把 MCP 生态的能力引入生命周期钩子。
- prompt --- 把问题抛给 Claude 模型做是非判断,这个主要是用于需要语义理解的动态审查场景。
- agent --- 派出一个 Subagent 做复杂的多步校验,这个我没用过,好像还在实验阶段中?
这五种类型中我们最常用的是command,它可以通过退出码来控制行为的:
- 返回 0 --- 校验通过,操作继续执行
- 返回 2 --- 阻断,操作被禁止,并把标准错误输出作为错误信息展示给claude
- 其他返回码 --- 非阻断性错误,记录到日志但不阻止操作
比如我们可以这样来写:
json
{
"type": "command",
"command": ".claude/hooks/check-sensitive-files.sh",
"timeout": 5
}如果脚本返回 2,Claude 就会收到错误提示,操作被拦截。
其他补充的部分
还有一个地方我需要讲一下,就是 PreToolUse 的特殊能力:权限控制和参数改写
我们前面讲的 command 类型主要是用退出码控制行为,但 PreToolUse 事件还有两个更强大的能力。
1.返回 permissionDecision 控制权限
Hook 脚本是可以返回一个 JSON的,里面包含了 permissionDecision 字段来控制权限:
- allow --- 直接放行,不弹确认
- deny --- 直接拒绝,操作被阻止
- ask --- 弹出确认提示,让用户决定
- defer --- 交给默认权限逻辑处理
这里我们也简单举个例子:
swift
{
"type": "command",
"command": "echo '{\"permissionDecision\": \"deny\", \"message\": \"禁止删除生产环境文件\"}'"
}这样 claude 就会收到拒绝提示,操作被阻止。
2. 通过 updatedInput 修改工具输入参数
除了权限控制之外,PreToolUse 的 Hook 还可以改写工具的输入参数。 这意味着我们可以在 claude 执行命令之前,自动修改命令内容。 比如这些:
- 强制给所有 git commit 命令加上签名参数
- 在文件写入前自动追加版权声明
- 把危险的
rm -rf命令改成rm -i
那我们也照样写个简单的例子:
json
{
"type": "command",
"command": ".claude/hooks/rewrite-git-commit.sh"
}等到脚本返回这个:
json
{
"updatedInput": {
"command": "git commit -S -m 'your message'"
}
}那我们就可以看到其实 claude 原本要执行 git commit -m 'your message'的,但 Hook 把它改写成了 git commit -S -m 'your message',强制加上了 -S 签名参数。
上面我们讲了下 hooks 的三层结构机制,那我们其实就可以了解到整个的执行链路是这样的:
markdown
hooks
└── PreToolUse ← 在哪个阶段触发(事件层)
└── matcher ← 哪些工具触发(匹配器层)
└── hooks ← 触发后执行什么(处理器层)这里我也用一张图整理一下: (哈基米为啥中文老是乱码 害得我只能截图擦)
那其实总的来说:
事件是决定什么时候触发,而Matcher是决定谁来触发,Hook则是决定触发之后做什么。
我们这样理解的话,整个Hook 配置的三层结构就一目了然了。那我们了解了hooks 的结构后,接下来我们再来看下 Hooks 的运行机制。
Hooks 的运行机制
我们再来看看 Hooks 究竟是怎么跑起来的:
其实Hook 在 claude code 的生命周期中是扮演拦截者的角色,整个流程是这样的:
由于后面写的还有很多 我直接一张图总结了哈:
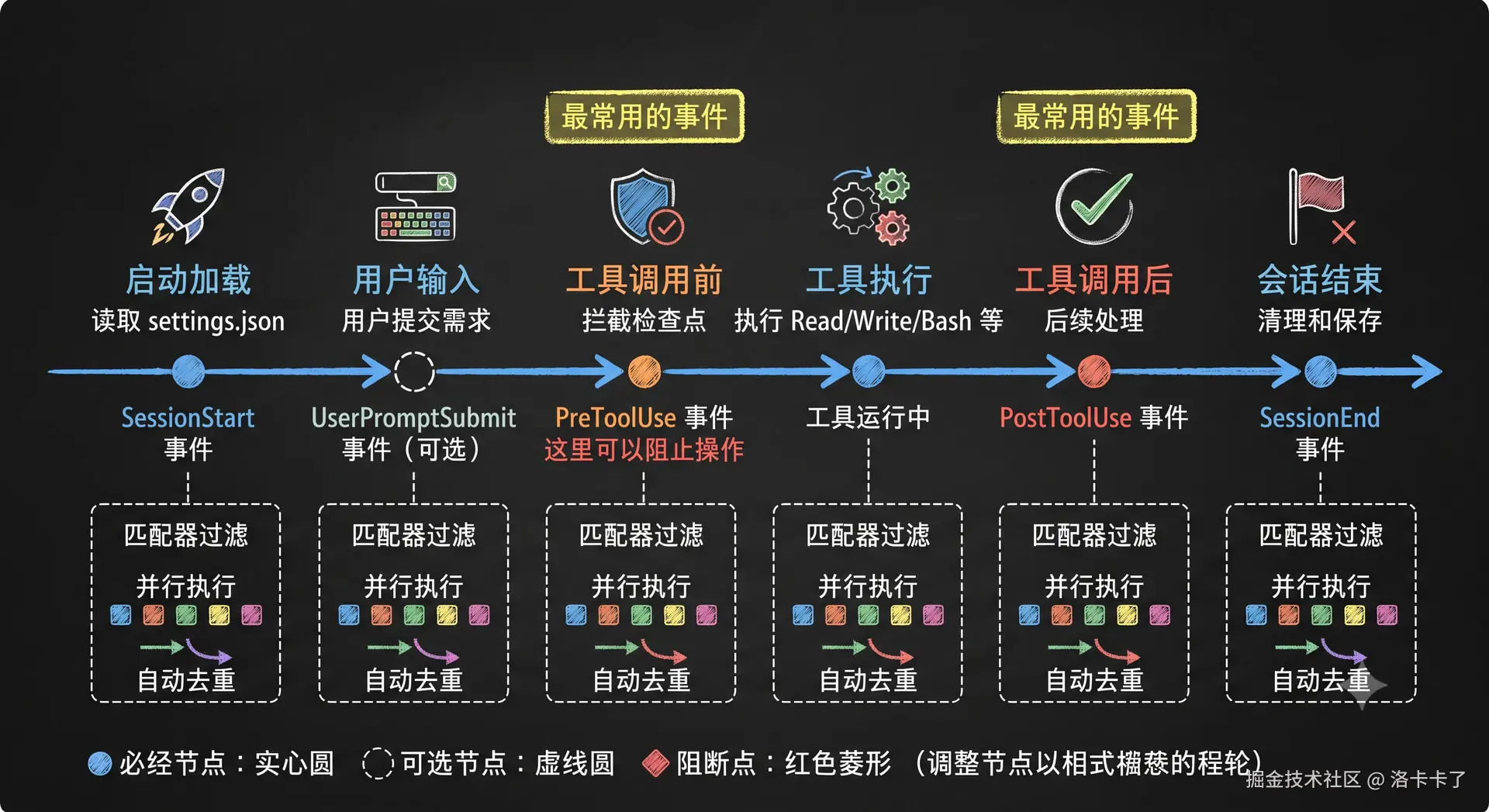
ok,这次哈基米生成的图片看起来很清晰直观,那我们再简单总结一下,其实Hook 的运行机制就三个关键点:
- 生命周期触发 --- 在特定节点自动触发(SessionStart、PreToolUse、PostToolUse 等)
- 并行执行 --- 多个 Hook 同时跑,提高效率
- 自动去重 --- 相同命令只执行一次
那我们了解了 hooks 的运行机制后,接下来我们再看下实际怎么配置和使用 Hooks。
Hooks的合并机制
突然想到这里还有一个问题我忘了说,如果多个 Hook 同时匹配时,那claude code 又是怎么处理它们的结果的呢?
这一节我们再简单梳理下这个逻辑。
其实claude code 是不会因为某一个 Hook 返回 deny 就立刻停止的, 这个很重要哈:
claude code 不会因为某一个 Hook 返回
deny,就立刻停止其他 Hook 的执行。恰恰相反,它会先并行执行所有匹配的 Hook,等全部执行完成后,再统一合并它们的结果。
这里我们简单举个例子来说明,比如我们配置了 3 个 PreToolUse 的 Hook:
bash
Hook 1:日志记录
匹配:Bash
作用:记录所有 Bash 命令到日志文件
返回:allow(允许执行)
Hook 2:安全防护
匹配:Bash
作用:检查是否是危险命令(如 rm -rf)
返回:deny(拒绝执行)
Hook 3:环境检查
匹配:Bash
作用:检查当前目录是否在安全路径
返回:ask(询问用户)那执行流程其实是这样的:
比如我们让 Claude 去执行 rm -rf /tmp/build操作命令,这时候就会触发 PreToolUse 事件。然后三个 Hook 同时并行执行:
Hook 1 记录日志,返回 allow
Hook 2 检测到危险命令,返回 deny
Hook 3 检查路径,返回 ask最后等所有 Hook 执行完成后,Claude Code 开始合并结果。
合并规则是这样的:
限制性优先
对于 PreToolUse 这种权限决策类 Hook来说,最终会按照限制性优先的原则进行合并的,也就是优先级从高到低来合并:
deny > defer > ask > allow
也就是说:
- deny(拒绝)优先级最高,只要有一个 Hook 返回 deny,最终结果就是 deny
- defer(交给默认权限逻辑)次之
- ask(询问用户)再次之
- allow(允许)优先级最低
按照这样的逻辑的话再回到我们刚才的例子来看,三个 Hook 的返回结果是这样的:
Hook 1:allow
Hook 2:deny
Hook 3:ask那我们按照 deny > defer > ask > allow 的优先级,最终结果是 deny。
所以 claude 会收到拒绝提示,rm -rf /tmp/build 不会被执行的。
虽然是这样的结果,但是我还是要提醒一下:
不要依赖 deny 阻止其他 Hook 的副作用
虽然上面的例子最终结果是 deny,但是其他 Hook 其实已经执行完成了。比如上面的例子中,Hook 1(日志记录)已经把命令记录到日志文件了。 所以不要依赖某个 Hook 的 deny 去阻止另一个 Hook 的副作用,例如记录日志、发送通知等。 如果我们希望某些操作在最终被拒绝时不执行,应该把它们放在 PostToolUse 或其他后续事件中才是合理的。
这里我也简单放个图片总结一下,毕竟写文字看着太麻烦了:
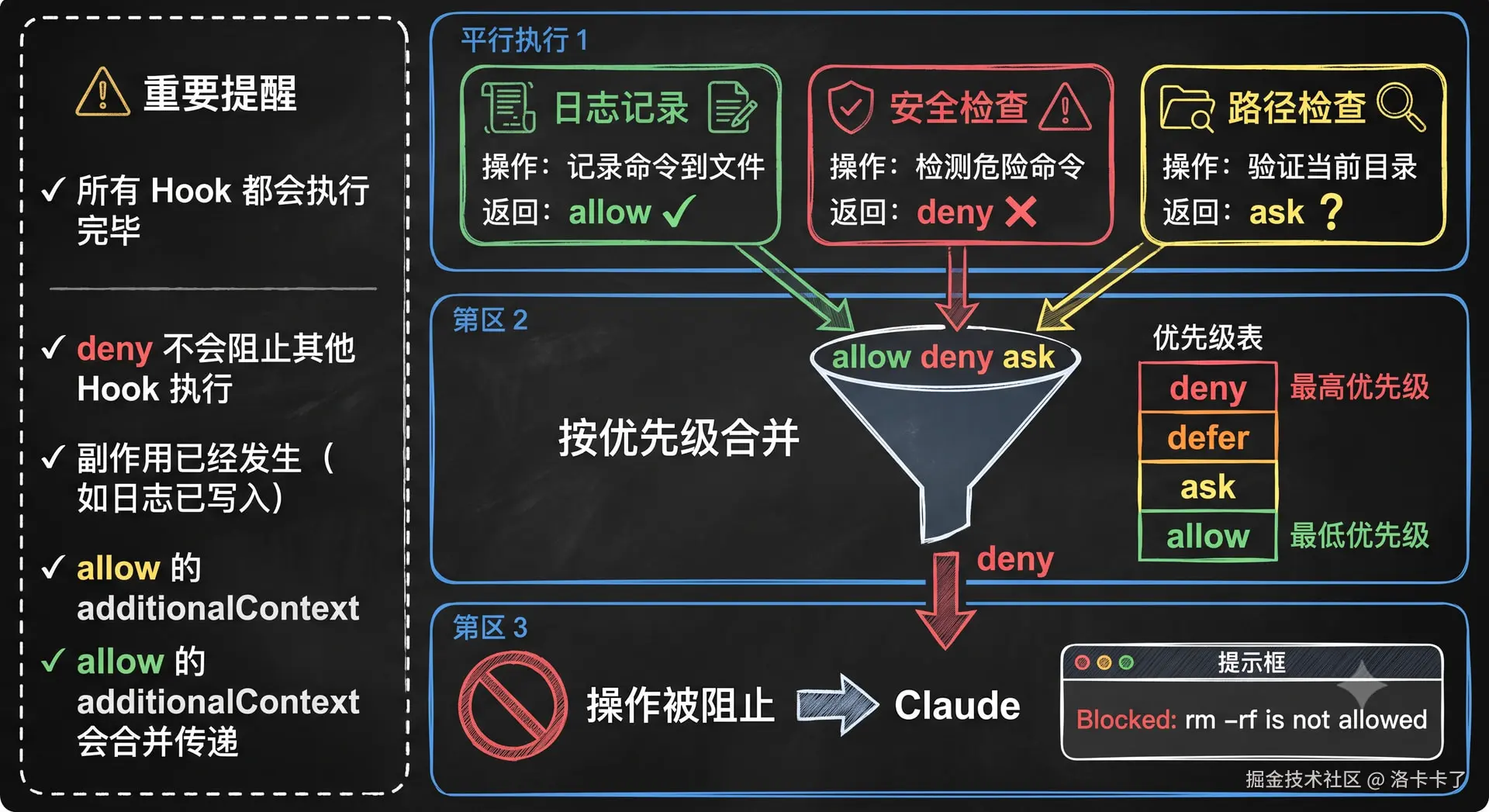
ok,这张图也不错,那我们再次简单总结一下这一节哈,Hooks合并机制的三个要点主要是这些:
- 并行执行 --- 所有匹配的 Hook 都会执行完毕,不会因为某个 deny 就提前停止
- 限制性优先 --- deny > defer > ask > allow,最严格的结果胜出
- 副作用已发生 --- 不要依赖 deny 阻止其他 Hook 的副作用(如日志记录、通知发送)
Hooks 的通信过程
接下来我们还需要去了解一个细节,在Hook 被触发以后,到底是怎么和 claude code 通信的呢。通常我们比较关注的是 Hook 在什么时候触发、能做什么,但是却很少去了解 claude code 是如何把数据交给 Hook,以及 Hook 又如何把结果返回给 claude code 的。
其实这套输入输出协议,就是是 Hook 能工作的基础。我们来拆解一下。
其实整个通信过程很简单:
claude code 负责提供上下文(JSON),Hook 负责处理逻辑并返回结果,claude code 再根据返回结果决定是否继续执行。
我们可以把 Hook 看成一个独立进程:
css
Claude Code 负责发送数据
Hook 负责处理数据
双方通过标准输入/输出和退出码完成整个通信闭环1.输入:claude code → Hook(通过 stdin)
当 Hook 被触发时,claude code 会通过标准输入(stdin)把当前状态以 json 的格式传给 Hook 脚本的。这个 JSON 包含了 Hook 需要的所有上下文信息,比如这些:
json
{
"session_id": "abc123",
"hook_event_name": "PreToolUse",
"tool_name": "Bash",
"tool_input": {
"command": "npm test"
}
}然后Hook 脚本就可以读取这个 JSON,了解当前是什么事件、要执行什么工具、参数是什么。
2.处理:Hook 执行检查逻辑
当Hook 脚本拿到输入后,就开始去执行自己的逻辑了。
比如去执行这些操作:
3.输出:Hook → claude code(通过 stdout/stderr + exit code)
等Hook 执行完成后,则需要把结果返回给 claude code。
返回方式一般有两种:
方式一:通过退出码,这个最常用,比如我们开头提到的这些
- exit code 0,代表检查通过,继续执行
- exit code 2,代表检查失败,阻止执行
- 其他 exit code,代表非阻断性错误,记录日志但不阻止
方式二:返回 json,这个一般主要用于权限控制
比如hook可以通过标准输出(stdout)来返回一个 json,包含更详细的决策信息:
json
{
"permissionDecision": "deny",
"permissionDecisionReason": "不要使用 rm -rf"
}或者去修改工具输入参数,比如是:
json
{
"updatedInput": {
"command": "git commit -S -m 'your message'"
}
}如果检查失败了,还可以通过标准错误(stderr)来输出错误信息:
bash
echo "Blocked: rm -rf is not allowed" >&2
exit 24. 决策:claude code 根据结果来决定下一步
claude code 收到 Hook 的返回结果后,会根据退出码和返回的json去做决策比如:
- exit code 0 / permissionDecision: allow → 继续执行工具
- exit code 2 / permissionDecision: deny → 阻止执行,显示错误信息给 Claude
- 其他情况 → 记录日志,根据具体情况处理
所以这里一般就是两个路径,成功和失败。
成功的话, Hook 被触发, 然后claude code 通过 stdin 发送 json 上下文,然后Hook 执行检查,检查通过的话,则返回 exit code 0,然后claude code 就继续执行工具,任务完成。
失败的话,Hook 被触发,然后claude code 通过 stdin 发送 json 上下文,然后Hook 执行检查,检查失败,返回 exit code 2 + stderr 错误信息,然claude code 阻止操作,把错误信息显示给 claude,最后 claude 去梳理问题,修正后再重试。
同样的最后还是哈基米图片来总结一下:
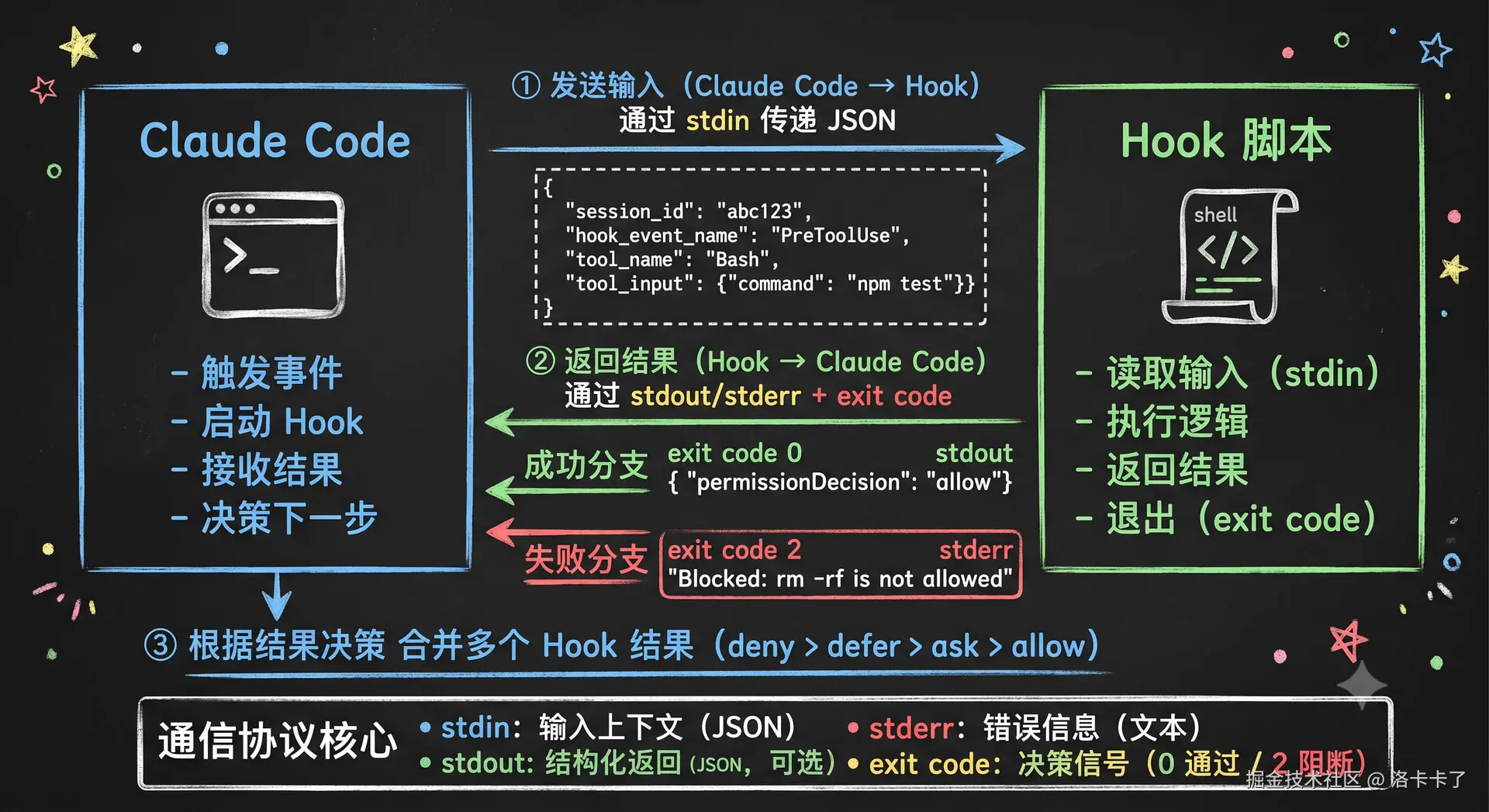
这样就清晰了,那我们再简单总结下上面说的,其实Hook 通信过程就是一个标准的 Unix 进程通信模式:
- 输入 --- Claude Code 通过 stdin 传递 JSON 上下文
- 处理 --- Hook 脚本执行检查逻辑
- 输出 --- Hook 通过 stdout/stderr + exit code 返回结果
- 决策 --- Claude Code 根据结果决定是否继续执行
了解这个通信过程后,我们就可以开始写自己的 Hook 脚本了。
Hooks 配置文件是放在哪里的
Hooks 的配置文件是 settings.json,它可以放在三个地方的,只不过优先级不同。
三个配置存放位置
1.用户级配置:~/.claude/settings.json
这个大家都知道,这是全局配置,所有项目通用的。比较适合放个人习惯相关的 Hook,比如 * 所有 Bash 命令前自动切换 node 版本,所有文件写入后自动格式化,或者我经常用的启动会话时显示欢迎信息等等。
2.项目级配置:<项目根目录>/.claude/settings.json
这个也比较好理解,是项目配置,只在当前项目生效的,适合放项目特定的 Hook,比如 * 这个项目禁止使用 rm -rf,比如改了代码后必须跑项目的 lint 脚本等,又或者是 * 提交前检查是否符合团队规范这些,这种项目配置我们可以提交到 git,然后团队成员共享。
3.本地级配置:<项目根目录>/.claude/settings.local.json
这个是本地配置,只在当前项目的本地环境生效的。这个比较适合放临时测试或个人调试用的 Hook,比如临时禁用某个 Hook,测试新的 Hook 脚本等等。
本地配置是不提交到 git的,我们通常加到 .gitignore里面。
那优先级就是这样的:
本地 > 项目 > 用户
所以如果三个配置文件都存在,claude code 会按优先级合并:
javascript
settings.local.json > settings.json > ~/.claude/settings.json也就是说,本地配置优先级最高,可以覆盖项目和用户配置的哈。
Hook 的超时时间
其实不同类型的 Hook 有不同的默认超时时间的,比如:
- command / http / mcp_tool 类型 --- 默认 600 秒(10 分钟)
- prompt 类型 --- 默认 30 秒
- agent 类型 --- 默认 60 秒
如果 Hook 执行时间超过超时时间,会被强制终止的。当然我们也可以在 Hook 配置里自定义超时时间:
json
{
"type": "command",
"command": ".claude/hooks/slow-check.sh",
"timeout": 120
}这样设置的话,这个 Hook 的超时时间就是 120 秒了。
异步 Hook:不阻塞 Claude 的操作
有时候我们的 Hook 需要执行很长时间,比如调用远程代码扫描服务、跑完整的测试套件。如果让 claude 等这些 Hook 执行完再继续, 就会很慢的,这时候我们就可以用异步 Hook。
我们可以在 Hook 配置里加上 "async": true,Hook 会在后台执行,不阻塞 Claude 的操作流程:
json
{
"type": "command",
"command": ".claude/hooks/remote-scan.sh",
"async": true
}这样 claude 不用等这个 Hook 执行完,可以继续做其他事情。
异步 Hook 的结果通知
那这样会有个问题,异步 Hook 在后台执行,如果检查失败了,claude 怎么知道呢?
这时候我们就可以加上 "asyncRewake": true:
json
{
"type": "command",
"command": ".claude/hooks/remote-scan.sh",
"async": true,
"asyncRewake": true
}这样配置后,如果后台 Hook 返回退出码 2(检查失败),会向 claude 发送一条系统提醒,通知它有异步校验未通过。
然后当claude 收到提醒后,就可以根据情况来进行处理了,比如回滚操作,或者通知用户等操作等等,
那什么时候用异步 Hook呢
其实异步hook是比较适合这些场景的:
- 需要执行时间很长的检查,比如远程扫描、完整测试等等
- 不影响当前操作的后续任务,比如记录日志、发送通知等等
- 可以延迟处理的验证,比如代码质量分析、安全扫描等等
但是这里有一点还是需要我们去注意的哈:
- 首先异步 Hook 是不会阻止操作的,所以不适合做强制校验哈
- 如果需要强制阻止的话,就要用同步 Hook去做。
- 异步 Hook 的结果只能通过
asyncRewake来通知,二不能直接阻止操作哈。
写个简单的 hook, 比如保护敏感文件不被修改的 hook
前面我们讲了太多理论知识了了,那现在我们来写一个实际的 hook 配置例子。
首先,我们在项目根目录下创建 .claude/hooks 文件夹,主要是放 hooks 脚本相关的:
bash
mkdir -p .claude/hooks然后我们在 .claude/hooks 目录下创建 protect-sensitive-files.sh,这个文件主要是来检查是否敏感文件拦截的,这个文件我直接让 ai 帮我创建的,我自己写太多错误了:
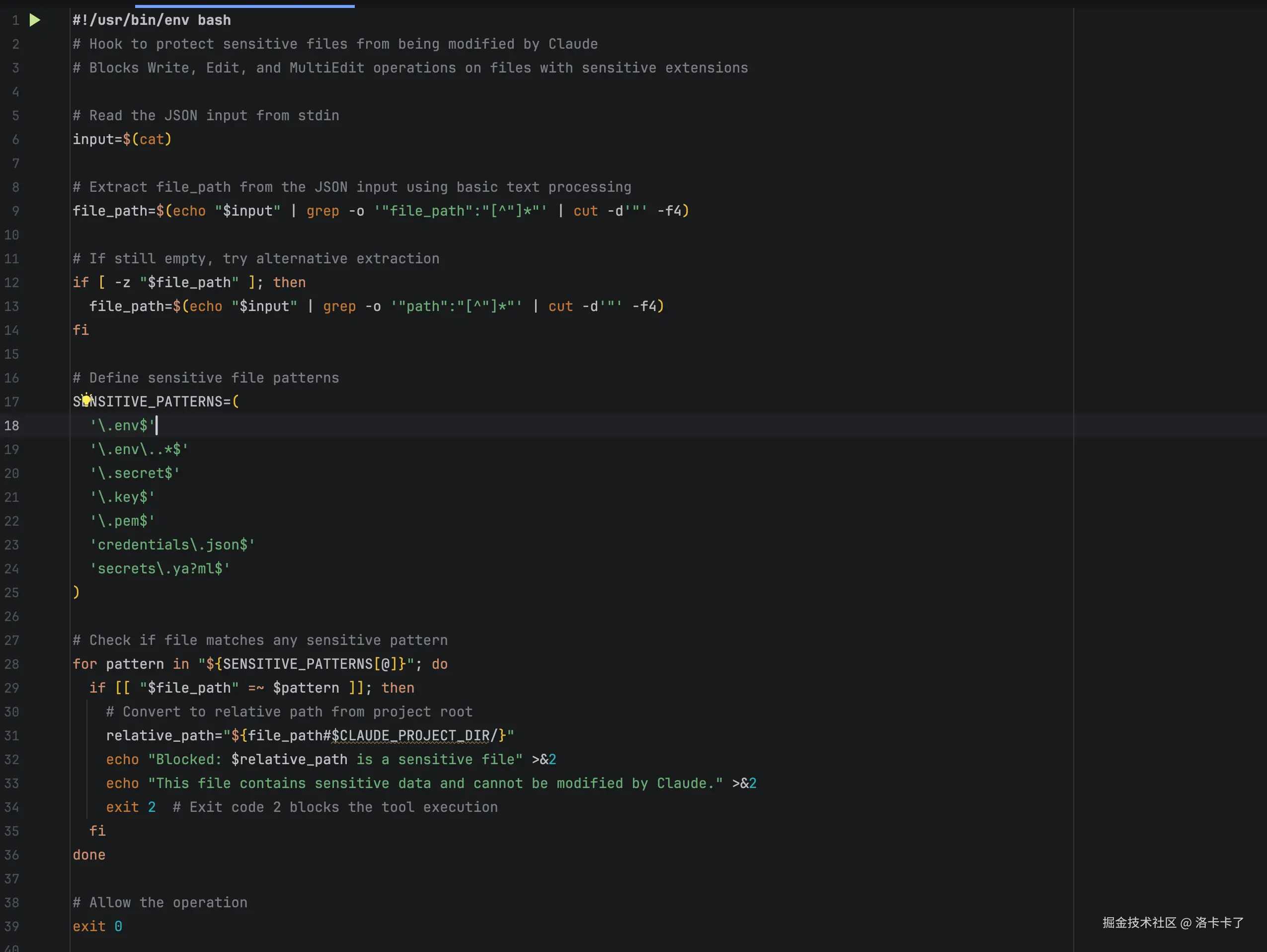
这里记得要给脚本加上执行权限哈。比如我们执行这样的操作:
bash
chmod +x .claude/hooks/protect-sensitive-files.sh最后我们再来配置一下hooks,我们在 .claude/settings.json 里添加配置:
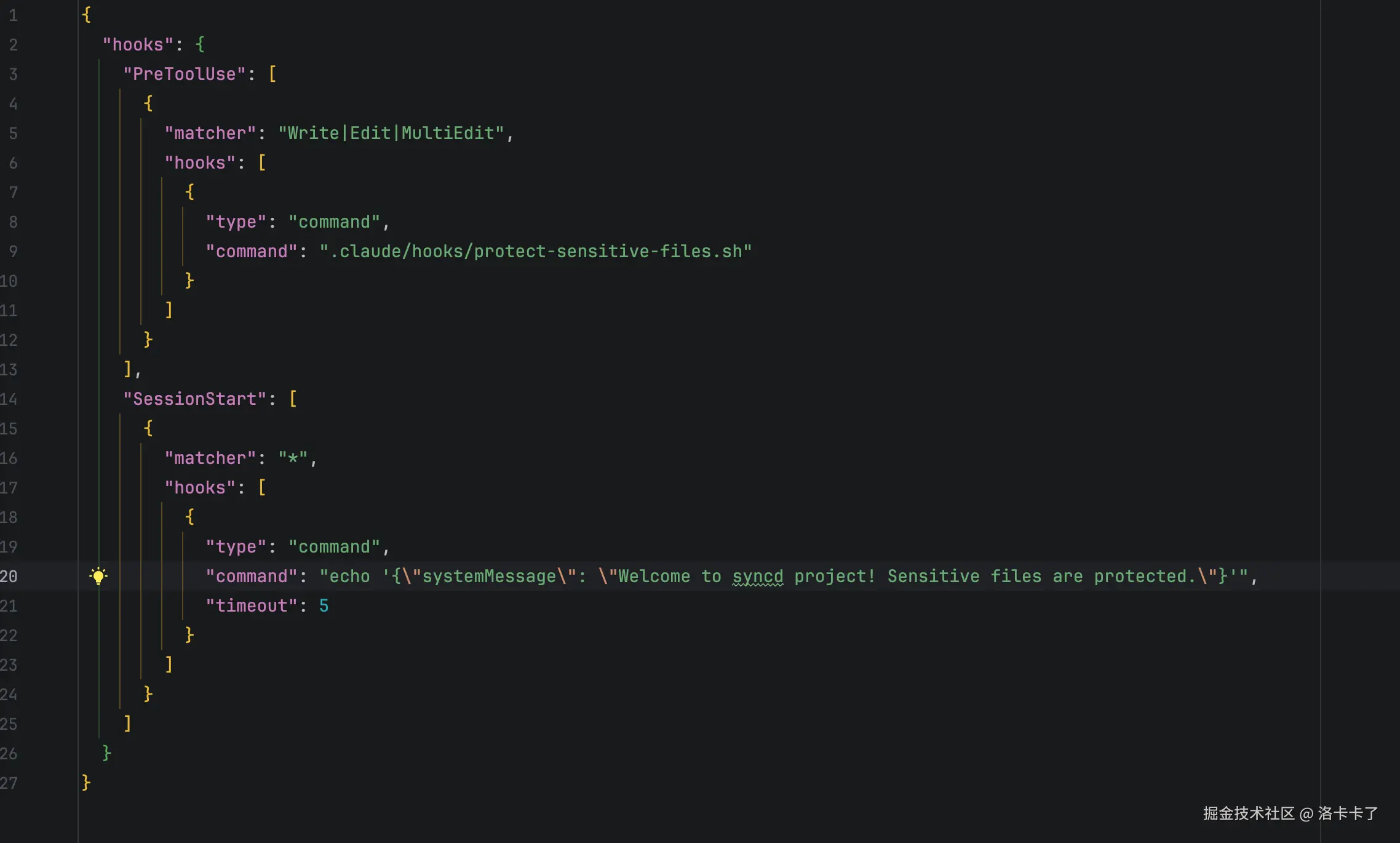
这个配置其实是两个 hook,第二个比较简单:
- PreToolUse事件,主要是用来拦截敏感文件 ,比如在claude 执行 write、edit、multiedit这些工具前,需要先检查文件是否敏感,如果是的话就需要去阻止
- SessionStart 显示欢迎信息 ,这个主要是我们启动会话时显示欢迎消息,也提醒用户敏感文件已被保护了。
我们配置好后,我们需要重启 claude code 会话。
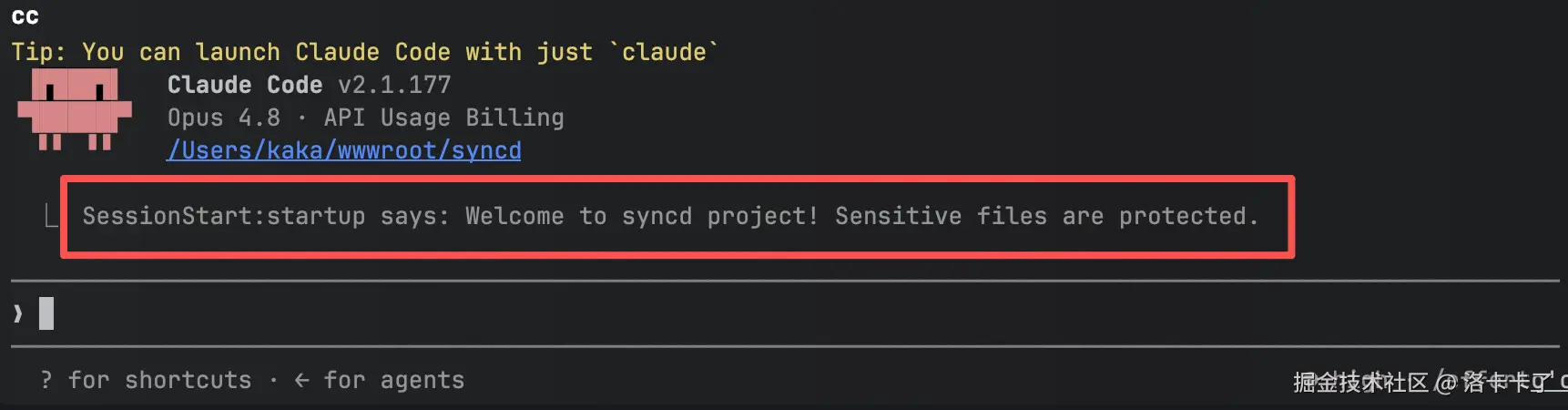
通过图片我们可以看到欢迎信息了,然后我们再让 claude code 去修改下我们的env文件看看效果。
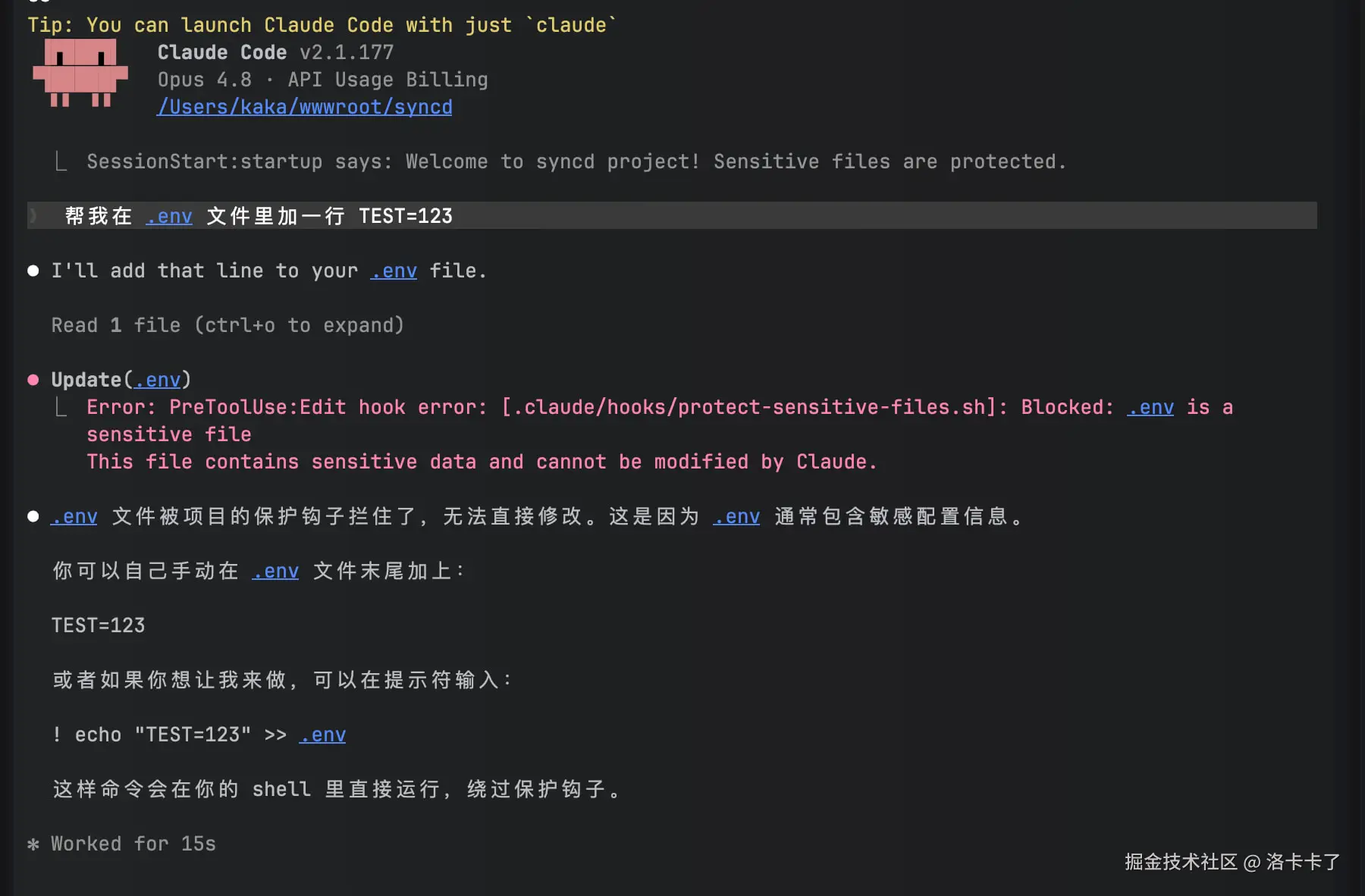
可以看到claude 收到了 Hook 的拒绝提示, 操作被阻止,.env 文件不会被修改。
最后的最后
这个文章其实主要还是讲一下只维护 CLAUDE.md的局限性,以及为什么需要 Hooks 强制拦截机制。通过这个文章我们可以了解到Hooks 的结构、运行机制、合并机制、通信过程,以及配置位置等等,也许有的佬觉得现在 ai 时代只要会让 ai 去配置 hook 就足够了,没必要再去了解 hook 的运行机制等原。
但是我觉得恰恰相反,通过了解 hook 的运行机制,我们才可以了知道它能做什么、在哪一层工作、什么时候会生效、什么时候不会。遇到问题的时候,我们才知道是配置写错了、还是脚本逻辑有问题、还是触发时机不对,而不是一遍又一遍让 ai 去看问题去试错,浪费 token,其实就像我们用git 一样,不一定要精通底层实现,但至少要知道工作区、暂存区、版本库是什么,冲突了怎么解决。能知道问题出在哪里。
本篇仅基于个人使用理解,如果有理解不对的或者写的错误的,还请大佬多多指教。感谢感谢。
后面我们在一起看看其他的一些工具机制是怎么用的哈。