DeepSeek DSpark:Confidence-Scheduled Speculative Decoding 技术解析

作 者:吴佳浩Alben
撰稿时间:2026.6.22 更新时间:2026.7.1
引言:
筒子们,老铁们当你阅读本时文俺就默认当你已经已了解 Transformer Decoder 与自回归推理流程,So 我们这里重点讨论 Draft / Verify 两阶段推理框架,不展开基础模型结构(KV Cache、Attention 机制等)。
DSpark 是 DeepSeek 发布的一套 Speculative Decoding Framework ,并非新模型架构。本文基于官方技术报告《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》及开源代码库 DeepSpec(MIT License)整理。代码为根据论文思路进行工程抽象的教学版伪代码,用于说明算法差异,并非官方实现。
DSpark Pipeline 总览
在深入细节之前,先看清楚整个推理流程的结构:
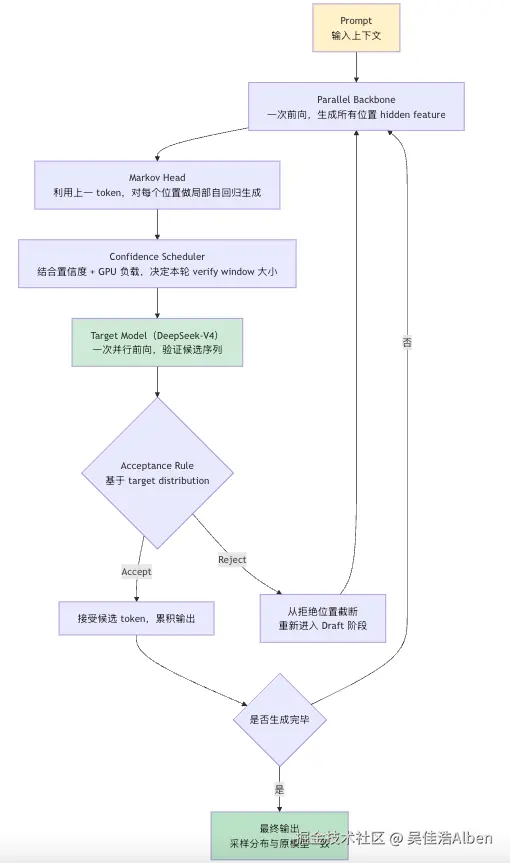
整个 Pipeline 的关键是:Target Model 不再逐 token 自回归生成,而是一次前向并行验证整段候选序列。Draft 阶段越准确(τ 越大),Target Model 每次前向能够接受(Accept)的 token 越多,延迟就越低。
一、核心公式:所有设计都服务于它
论文给出投机解码的单 token 平均延迟公式:
bash
L = (T_draft + T_verify) / τ| 变量 | 含义 | 谁控制它 |
|---|---|---|
T_draft |
Draft 模块猜一段候选 token 的耗时 | Draft 架构设计 |
T_verify |
主模型一次并行验证的耗时 | 调度策略 |
τ |
这一轮平均被接受的 token 数 | Draft 准确率 |
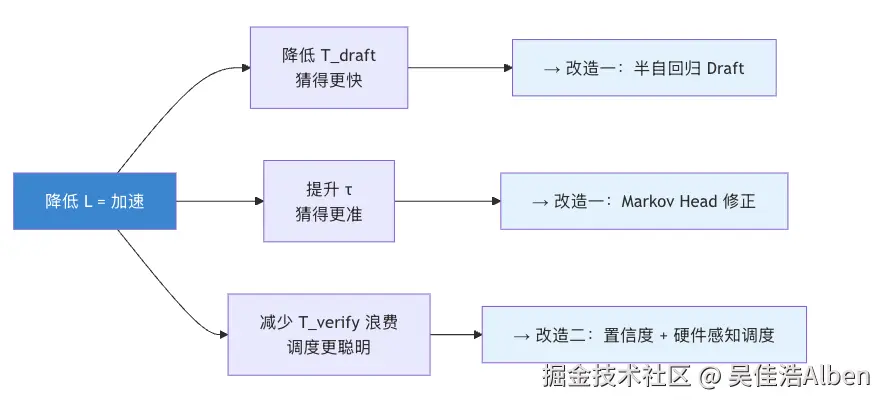
降低 L 只有三条路,分别对应 DSpark 的三个改造点:
二、投机解码基本原理
在看 DSpark 改造之前,先把"投机解码"的基础逻辑搞清楚。
关键是:主模型只跑了 1 次前向,却拿到了 4 个 token。朴素自回归生成同样 4 个 token 需要跑 4 次前向。τ 越大,节省越多。
三、业界现有方案的取舍
方案 A:朴素自回归(基线,无投机)
python
def autoregressive_decode(model, prompt, max_new_tokens):
"""每次只生成1个token,逐个前向------没有"猜"这一步"""
tokens = prompt
for _ in range(max_new_tokens):
logits = model.forward(tokens) # 主模型跑1次 = 只得1个token
next_token = sample(logits[-1])
tokens.append(next_token)
return tokens
# τ = 1,L = T_verify(单token),无加速空间生成"今天天气不错"6 个字:主模型需要前向 6 次,完全串行:
方案 B:Eagle3 风格------自回归 Draft(猜得准,但猜得慢)
python
def eagle_style_draft(draft_model, hidden_state, block_size):
"""Draft内部严格串行:每步依赖前一步的完整隐藏状态"""
candidates = []
h = hidden_state
for i in range(block_size):
logits, h = draft_model.forward_step(h) # 必须等上一步算完
candidates.append(sample(logits))
return candidates
# OK 优点:猜测质量高,τ 大
# FAIL 缺点:block_size 越大,T_draft 线性增长,Draft 本身成瓶颈
gantt
title Eagle3 Draft:猜5个候选token(串行依赖)
dateFormat X
axisFormat 步%s
section Draft(轻量但串行)
猜 token1 :0, 1
等token1→猜 token2 :1, 2
等token2→猜 token3 :2, 3
等token3→猜 token4 :3, 4
等token4→猜 token5 :4, 5
section 主模型
并行验证5个 :5, 6Draft 阶段 5 步串行后,主模型才能开始验证。block_size 越大,总等待越长。
方案 C:DFlash 风格------全并行 Draft(猜得快,但容易"漂")
python
def dflash_style_draft(draft_model, hidden_state, block_size):
"""一次前向直接吐出整个block,所有位置完全独立"""
logits_all = draft_model.forward_parallel(hidden_state, block_size)
candidates = [sample(logits_all[i]) for i in range(block_size)]
return candidates
# OK 优点:T_draft 接近常数,速度快
# 缺点:各位置缺少显式局部自回归依赖(Transformer 仍共享 hidden,
# 但没有 token→token 的逐步生成)→ 多模态碰撞 → Suffix Decay序列越往后,各位置缺少显式局部自回归依赖,语义漂移加剧。论文将这一现象称为 Suffix Decay(后缀退化):
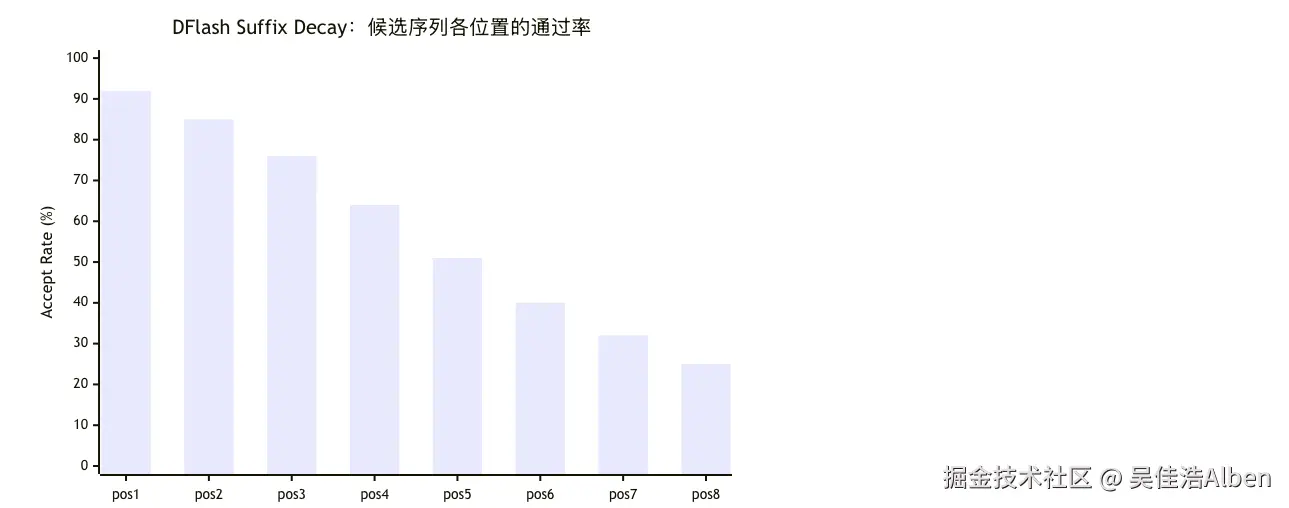
越到末尾,猜对概率越低,后几个候选几乎都是在浪费 Draft 算力。论文将这一现象定义为 Suffix Decay。
四、DSpark 的解法:半自回归 Draft
核心思想:并行主干先生成所有位置的 hidden feature,Markov Head 再利用上一个 token 对当前位置做局部自回归生成
论文原文描述:Markov Head performs autoregressive generation over local dependency,并非简单地对 logits 做后处理修正。下面的伪代码对这一步做了教学抽象。
python
def dspark_draft(parallel_backbone, markov_head, hidden_state, block_size=5):
"""
第一步:并行主干一次前向,得到所有位置的 hidden feature
第二步:Markov Head 利用上一 token 做局部自回归生成(教学抽象,并非官方实现)
"""
# ── 第一步:一次 Parallel Forward,Latency 接近常数 ─────────
base_features = parallel_backbone.forward_parallel(hidden_state, block_size)
# base_features[0..4] 同时产出,互相独立,此时仍有 Suffix Decay 风险
# ── 第二步:Markov Head 局部自回归,开销远小于完整 Draft ──────
candidates = []
prev_token = None
for i in range(block_size):
if prev_token is not None:
# Markov Head 利用上一个 token,对当前位置做局部自回归生成
# 论文描述:autoregressive generation over local dependency
# (此处为教学抽象,非官方实现细节)
adjusted_logits = markov_head.generate(base_features[i], prev_token)
else:
adjusted_logits = base_features[i]
token = sample(adjusted_logits)
candidates.append(token)
prev_token = token # 只传 token ID,不传隐藏状态
return candidates三种方案的内部结构对比:
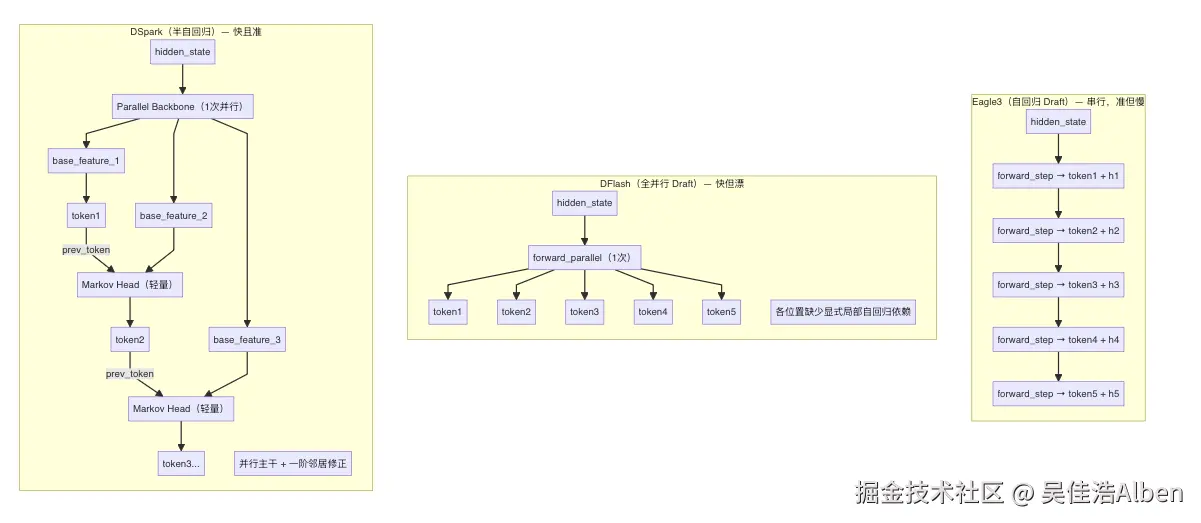
三种方案性能取舍汇总:
| 方案 | T_draft 趋势 | Suffix Decay | τ(Accept Length) |
|---|---|---|---|
| Eagle3 | 随 block_size 线性增长(慢) | 轻微 | 高 |
| DFlash | 接近常数(快) | 严重 | 中(后段骤降) |
| DSpark | 接近常数(略高于 DFlash) | 明显缓解 | 最高 |
官方 benchmark(Qwen3 三种尺寸,macro-average Accept Length 提升):
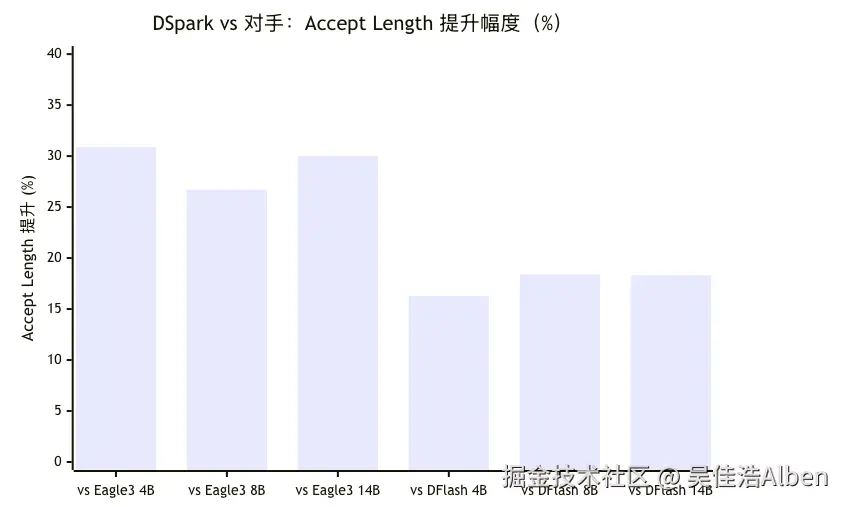
论文的一个值得标记的细节:2 层 DSpark Markov Head 打赢 5 层 DFlash,说明「局部一阶修正」的设计思路比单纯堆并行层数更有信息量。
五、改造二:置信度 + 硬件感知调度
这个改造优化公式里的 T_verify:不固定批次大小,让调度器根据当前状态动态决定。
python
def confidence_scheduled_verify(target_model, candidates, confidences, gpu_load):
"""
双输入调度(以下阈值为示意,论文未指定具体数值):
(a) Draft 给出的每位置置信度
(b) 当前 GPU 负载率
→ 动态决定这一轮验证多少个候选 token
"""
# ── 硬件感知:GPU 空闲时扩大 verify window,繁忙时收缩让路 ───
# 以下分支及阈值为原理示意,非论文给出的精确实现
if gpu_load < HIGH_THRESHOLD:
verify_len = LARGE_WINDOW # GPU 空闲,多验证几个
else:
verify_len = SMALL_WINDOW # GPU 繁忙,收缩验证窗口
# ── 置信度截断:遇到低置信位置提前截断 ──────────────────────
for i, conf in enumerate(confidences[:verify_len]):
if conf < LOW_CONF_THRESHOLD: # 具体阈值由工程配置决定
verify_len = i
break
# ── 主模型一次并行验证(只跑 1 次前向) ─────────────────────
logits = target_model.forward_parallel(candidates[:verify_len])
accepted = []
for i in range(verify_len):
# Speculative Decoding 的验证不是 sample()==candidate 的简单比对
# 而是基于目标分布(target distribution)的 acceptance rule:
# 以概率 min(1, p_target / p_draft) 接受候选 token
if acceptance_rule(candidates[i], target_logits=logits[i]):
accepted.append(candidates[i])
else:
break # 第一个被拒绝后截断,从这里重新 Draft
return accepted决策逻辑流程:
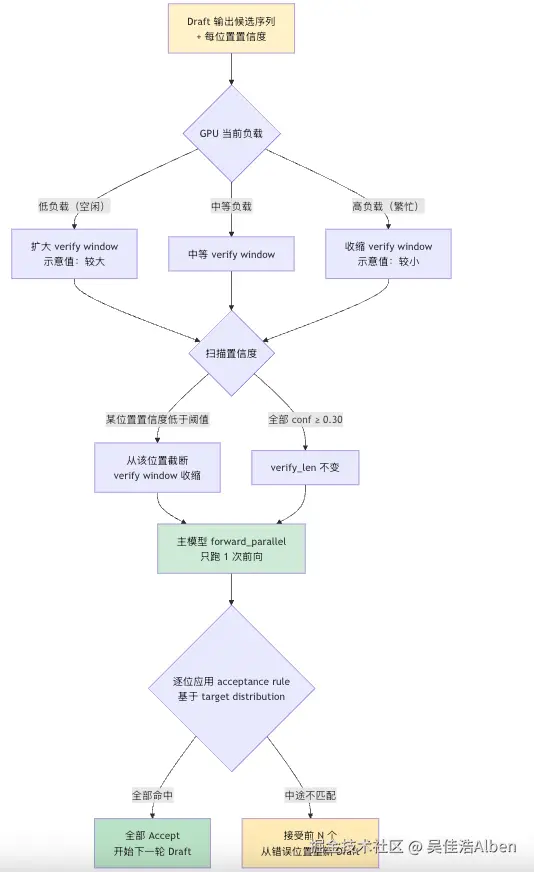
这个机制解决的核心矛盾:高并发时若每轮固定验证固定数量的 token,GPU 繁忙时大量无效排队;动态调度让 verify window 随系统压力弹性收缩,整体吞吐反而更高。(论文描述了 Hardware-aware Scheduling 的原理,具体阈值属于工程实现参数。)
六、完整案例:数字走一遍
用一个具体例子把公式、Draft、调度全串起来。
假设条件:GPU 负载 30%(空闲),DSpark-5 配置(5-token draft block)
第 1 步:Draft 阶段
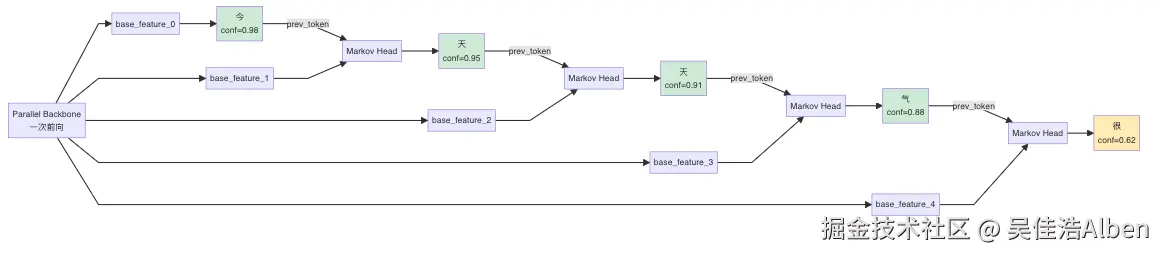
第 2 步:调度决策
bash
GPU 负载 = 30%(空闲)→ verify window 取满,验证全部 5 个候选
扫描置信度:0.98 / 0.95 / 0.91 / 0.88 / 0.62 --- 全部高于阈值
→ 不截断第 3 步:主模型一次并行验证
第 4 步:对比朴素自回归
bash
朴素自回归生成同样 4 个字:
主模型前向 ×4 次 = 4 × T_verify_per_token
DSpark:
T_draft(并行主干 + Markov,轻量)
+ T_verify(1次前向,并行验证4个,耗时≈验证1个)
若 T_draft = 0.1 × T_verify_per_token(Draft 远轻于主模型,仅为原理示意):
L_naive = 4.0 × T_verify_per_token
L_dspark = 0.1 + 1.0 = 1.1 × T_verify_per_token
理论加速示意 ≈ 3.6×
注意:此处仅为公式推导示意,实际生产加速(60~85%)由真实 τ、T_draft、
并发调度等多因素共同决定,两者不可直接对应。七、生产环境真实数据
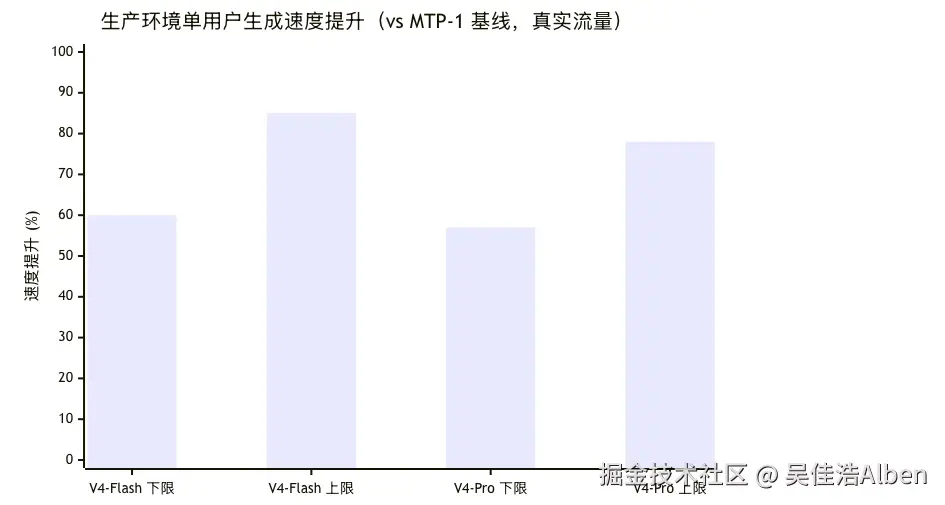
| 模型 | 对比基线 | 单用户速度提升 | 数据来源 |
|---|---|---|---|
| V4-Flash-DSpark | MTP-1 | 60% ~ 85% | DeepSeek 生产流量 |
| V4-Pro-DSpark | MTP-1 | 57% ~ 78% | DeepSeek 生产流量 |
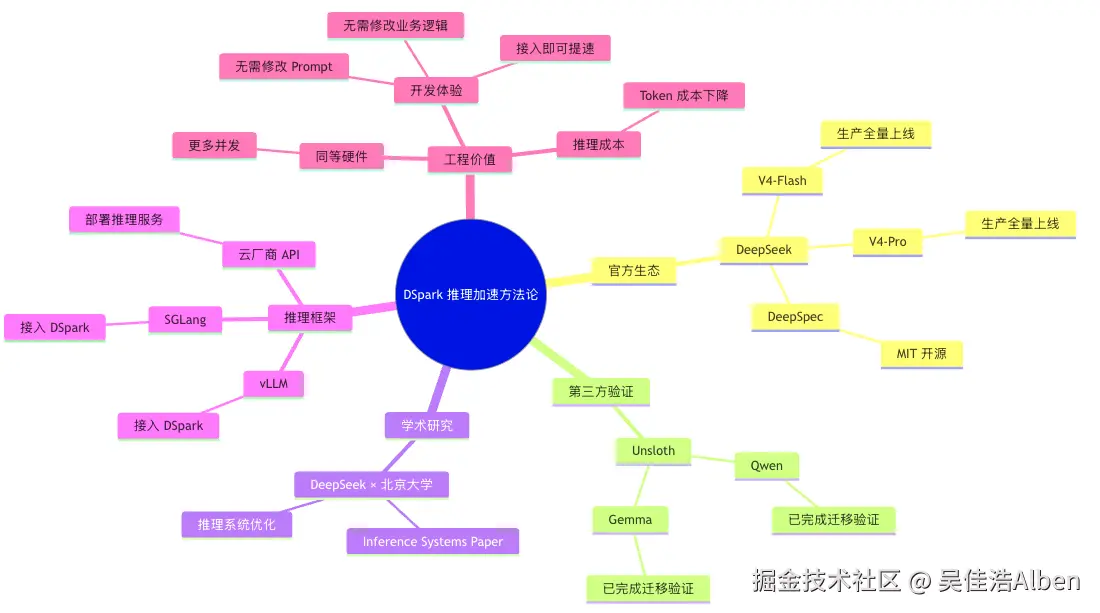
| Unsloth 第三方复现 | --- | 51% ~ 400% | Qwen/Gemma 等模型,不同 batch/GPU 配置差异较大,400% 为特定场景峰值 |
Unsloth 的复现还验证了一个重要结论:DSpark 方法论可以迁移到 Qwen、Gemma 等非 DeepSeek 模型,说明这是通用推理加速框架,不绑定 DeepSeek 自家架构。需注意 51%~400% 的区间跨度较大,400% 为特定模型、特定 batch size 和 GPU 配置下的峰值,并非普遍结果。
八、DeepSpec 开源库:自己跑起来的三步流程
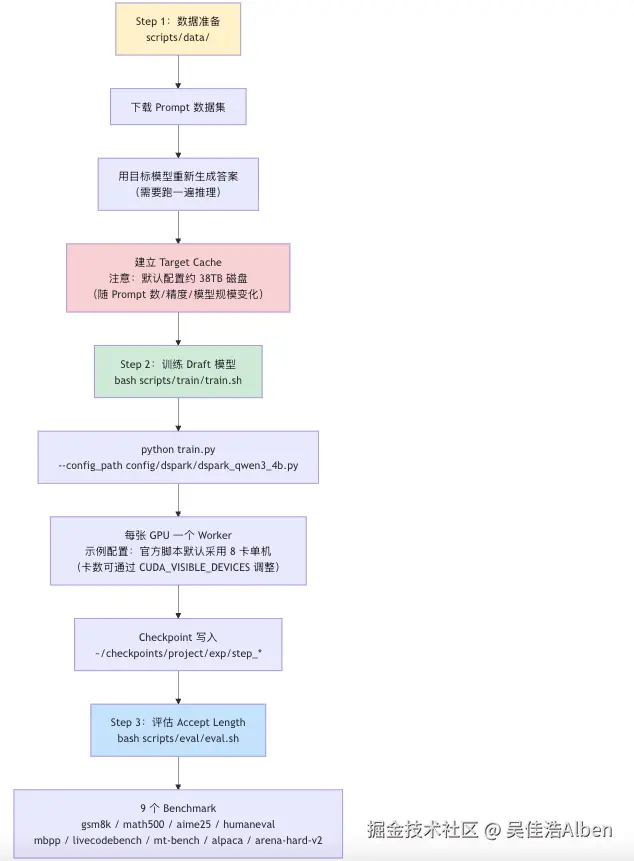
bash
# 训练 DSpark Draft 模型(针对 Qwen3-4B)
bash scripts/train/train.sh
# 内部等价于:
python train.py --config_path config/dspark/dspark_qwen3_4b.py
# 评估 Accept Length
bash scripts/eval/eval.sh \
--target_name_or_path Qwen/Qwen3-4B \
--draft_name_or_path ~/checkpoints/deepspec/dspark_block8_qwen3_4b/step_latest代码库里同时实现了 DSpark、DFlash、Eagle3 三种算法,统一框架做 apples-to-apples 对比,排除实现差异引入的噪声。
九、谁在跟进
十、所有设计动作一张图
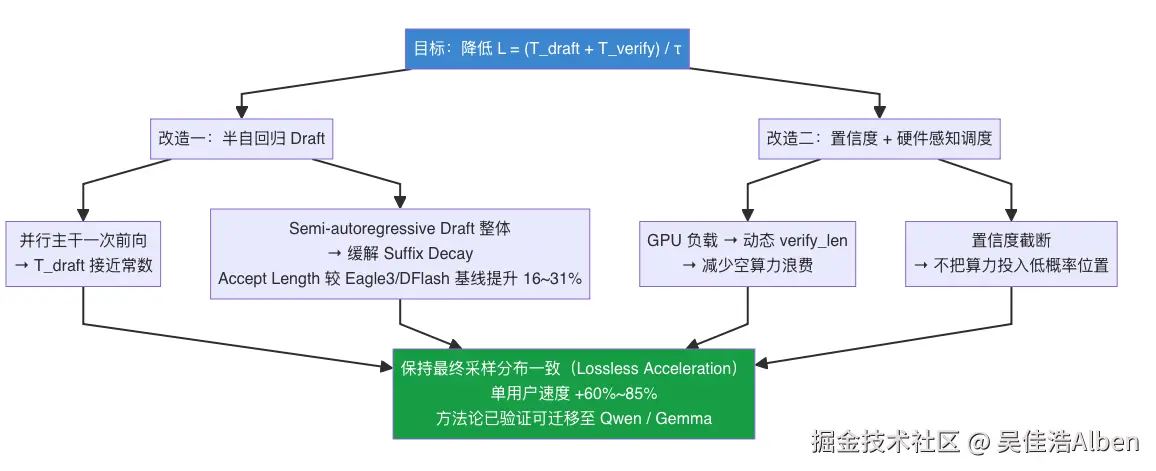
本质一句话:DSpark 针对传统 Speculative Decoding 的两个核心瓶颈------Draft 速度与准确率的权衡,以及验证调度效率------进行了系统优化,在保持最终采样分布一致(Lossless Acceleration)的前提下把生产环境推理速度提升 60~85%,训练框架以 MIT 协议开源,方法论已被第三方验证可迁移至 Qwen、Gemma 等非 DeepSeek 模型。
总结
DSpark 并没有改变模型本身,而是在推理阶段重新设计了 Draft 与 Verify 两个关键环节。它通过 Semi-Autoregressive Draft、Confidence-Scheduled Verification 与 Hardware-aware Scheduling,在保持最终采样分布一致(Lossless Acceleration)的前提下,实现了生产环境 57%~85% 的推理加速,也说明大模型推理性能的提升,越来越依赖系统工程而非模型参数本身。(这是我的观点 当然筒子们有自己的想法也可以留言交流)